
基于Hive的空气质量大数据查询优化方法
2020-08-13 14:14刘黎志张晨跃
武汉工程大学学报 2020年4期
彭 贝,刘黎志*,杨 敏,张晨跃
1.智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉430205;
2.武汉工程大学计算机科学与工程学院,湖北 武汉430205
大数据技术对环境监测数据分析和综合决策具有重要意义。我国已建成涵盖国家、省、市、县4个层级的环境质量自动监测系统,建立了环境质量实时发布系统[1]。根据全国“互联网+监管”系统建设的总体设计,在省级设立一个数据监管中心,建立各类监管数据库。县、市级环境监测机构负责编制辖区内环境质量报告,上报省环境监测中心站。省环境监测中心站汇总分析各地报告并编制全省环境质量报告。因此,省级中心站收集了全省范围内各个自动化监测站的数据,其中的空气质量监测数据库收集记录了省内各站点的SO2,NO2,PM10,CO,O3,PM2.5六类污染物的每小时监测均值及相关气象参数等数据[2-3]。随着时间的推移,省级中心站存储的数据量越来越大,形成了有着容量大、种类多、产生速度快、价值高、密度低等特征的大数据[4-5]。在对这些大数据进行统计分析时,SQL Server等传统关系数据库会出现存储空间不足、数据查询耗时长等问题,而SQL Server上的分区视图优化技术也有其局限性,已无法满足高效迅速处理这类数据的需求[6-7]。为了提高省级中心站数据处理速度,提升空气质量数据分析评价工作效率。本文基于Spark分布式集群环境和Hive数据仓库,提出了一种多维度的分区存储策略对省级中心站中的空气质量大数据查询进行了优化。
1 大数据处理平台
1.1 Spark与Hive
Spark是目前最受欢迎的分布式计算引擎之一,被广泛应用于大规模数据处理。由于其基于内存计算的特点,Spark计算速度比同样以MapReduce为核心的Hadoop要快很多倍。Spark是一个通用引擎,提供了Spark Core、Spark SQL、Mllib等组件库可完成包括SQL查询、文本处理、机器学习等各类运算。且支持Java、R、Pathon等多种语言,可以访问分布式文件系统(hadoop distributed file system,HDFS)、Hive、Hbase等多种数据源[8-10]。
Hive是基于Hadoop的分布式数据仓库,用于以结构化的形式管理存储在HDFS中的数据,它提供了类似SQL的语句HiveQL来存储、查询、分析数据。Hive将用户的HiveQL语句自动转换为MapReduce任务执行,简化了用户操作。Spark与Hive的结合具有处理数据规模大、速度快、可扩展性强等优势[11-13]。
1.2 Spark SQL
Spark SQL是Spark中用于处理结构化数据的子模块。它将SQL查询与Spark程序结合,使用户可以在Spark程序中使用SQL查询数据。它提供了DataFrames作为连接访问多种数据源的统一方式,其数据源包括Hive、Avro、Parquet、Orc、Json和Jdbc[14]。其架构如图1所示。

图1 Spark SQL架构图Fig.1 Schema diagram of Spark SQL
Spark SQL底层使用Spark Core作为执行引擎,其本身由ANSI SQL解析器、DataFrame API和Catalyst优化器组成,其中ANSI SQL解析器负责解析SQL语句。DataFrame对象是Spark SQL在弹性分布式数据集(resilient distributed dataset,RDD)的基础上封装而成的类似于数据表的数据结构。Catalyst优化器则是整个查询过程的优化引擎,配合解析器和DataFrame将关系查询优化解析为Spark可以运行的作业[15]。Spark SQL提供了对关系数据处理的支持,同时支持内部RDD数据和外部的多种数据源,也兼容Hive中的数据类型。还允许扩展以支持更加复杂的分析算法,如机器学习、图计算等。
2 数据分区优化方法
2.1 SQL Server分区视图
分区是对数据表的水平划分,将大表拆分为多个小表,执行查询时通过排除不需要扫描的分区来提高查询效率。SQL Server分区视图允许根据某一列的值在逻辑上将大表中数据划分为数值范围较小的数据分区,并将这些分区数据存储在参与分区的小表中。为此,需在所有参与的表中分区列上使用Check关键字定义约束,用以将表中的该列数值限定在一定的范围,然后再使用UNION ALL运算符将所有参与表中的数据查询结果合并为一个分区视图。执行查询时,Check约束用于指定哪个分区中包含需要的数据,从而跳过其它分区。每个参与分区的表都是独立的,在不改变分区列的前提下可以单独地添加和修改。
在SQL Server上创建分区视图有其局限性。如:分区列不能是标识列、默认列、计算列和时间戳列。分区列必须为表的主属性。分区列上只能有一个Check约束。只能对表中的一个列进行分区,即分区属性只能有一个。这些限制了分区视图的性能。面对复杂的数据和复杂的查询需求需对多个属性列进行分区的情况时,SQL Server分区视图提供的性能优化十分有限。
2.2 Hive数据分区
Hive上的数据分区也是一种对数据表的划分,采用“分而治之”的策略来管理数据。但与SQL Server分区视图不同的是Hive数据分区是基于分布式集群环境的,分区数据存在集群的各个节点上[16]。其分区属性可以有多个,可以将数据表按照多个属性列做多维度的划分。如图2所示,以空气质量数据为例,按照“地区”和“时间”两个属性列对其做数据分区。按地区划分以后根据地区属性的值划分为多个分区,相同地区的数据在一个分区内。每个地区分区内再进一步按时间划分。根据实际需求还可以继续按其他属性分区。如此一来,分区的粒度更加精细,查询时需扫描的分区更加明确,查询时间自然会减少,而能被优化的查询种类也会增多。在分布式数据仓库上的分区可以充分利用集群节点的特性,将分区存储在各个节点上有利于查询和存储的负载均衡。
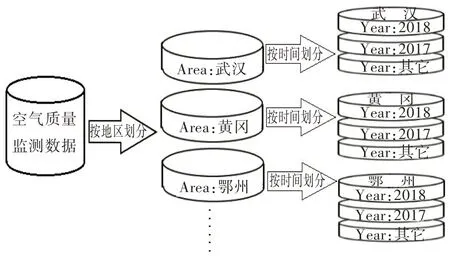
图2 Hive数据分区示例Fig.2 Examples of Hive data partition
但是不恰当的数据分区策略并不能提高查询效率。Hive上的数据分区中每一个分区都对应一个分布式文件系统上的文件目录,若选择的分区属性上的值的种类过多,分区以后产生了过多的分区,会导致集群上的文件目录过多,进而增加了集群数据节点负担。若分区以后,数据倾斜度太高,某个或某些分区上集中了大部分的数据,这样的分区方法也不一定能提高查询效率。因此需要充分了解集群环境和数据查询特性,选择恰当的分区策略才能有效地提高查询效率。
3 空气质量大数据分区优化方法
空气质量监测数据是环境监测中十分重要的一部分,经过日复一日地积累,其数据量已经十分巨大。在利用SQL Server及其上的分区视图技术对这些数据做统计分析时,查询消耗的时间长,导致分析工作效率低下。为此,采用先将数据导入Spark集群,使用Spark SQL语句在Hive中进行分区存储,然后在Spark集群环境下进行数据查询、统计和分析的方法以提高效率。
3.1 空气质量监测数据
省级环境监测中心站中的空气质量数据库收集了全省所有空气自动监测站点的监测数据。库中为每个站点建立了一张数据表。本文提出的方法用到的数据来源于湖北省环境监测中心站中的空气质量SQL Server数据库,库中记录每个站点监测数据的表结构如表1所示。其中站点编号用于区分不同的监测站点,如:编号SS4201002表示湖北省(42),武汉市(01),汉阳月湖自动化监测站(002)。污染物编号表示记录的污染物类型,如:编号EP02表示记录的是SO2。数据库中记录站点信息的数据表包含站点编号、所属地区编号、地址、站点类型等信息。
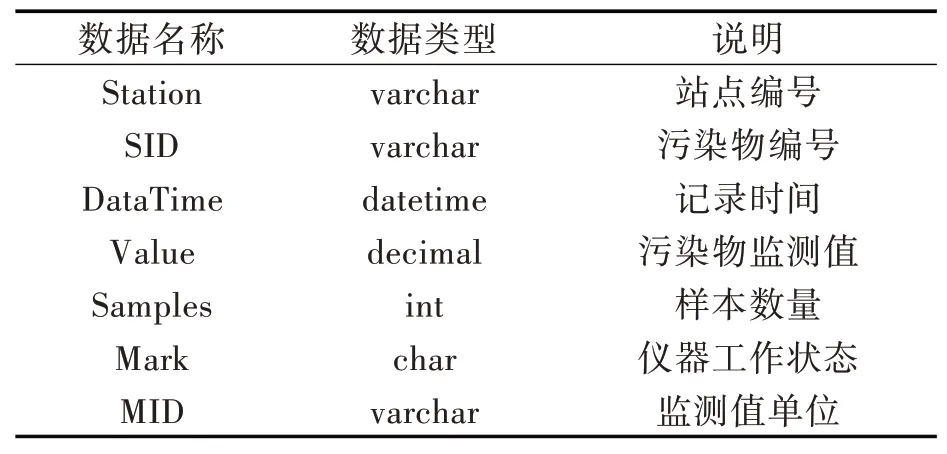
表1监测站数据记录表结构Tab.1 Recording table structure of monitoring station data
3.2 空气质量大数据分区策略
数据分区过程中,分区属性的选择将影响最终的优化效果。根据实际的数据统计分析需求,对空气质量数据的查询往往是以所监测数据的时间、地区、监测站点以及数据所属的污染物种类等属性为查询条件。因此,选择以查询条件中出现频率高的所属地区、监测站点、污染物种类、监测年份4个属性为分区属性,在Hive中进行多维度分区的策略。
该分区策略具体执行方法如下:首先,在原始SQL Server数据库中,利用各个站点监测数据表中的监测数据创建分区视图。由于每张表中记录同一站点的数据,站点编号字段已添加了约束。再使用UNION ALL操作符合并每张数据表的查询结果构成分区视图All_Air_Data。创建该视图时,查询站点信息表中的地区编号作为视图的地区编号字段,如4 201表示湖北武汉。提取数据记录表中记录时间的第1到4位作为视图的年份字段,其它需要的站点编号、污染物编号、监测时间、监测值、监测值单位、样本数量、仪器工作状态等字段直接从各个站点监测数据表中查询。创建分区视图伪代码如下:

然后,搭建Spark集群并配置能连接到集群的Eclipse开发环境。编写Spark SQL程序将上一步创建好的总数据视图All_Air_Data读取到Spark集群中。此处调用Spark SQL的入口是SparkSession,导入数据具体实现的核心伪代码如下:

最后,用SparkSession.enableHiveSupport方法打开Hive连接,用Spark SQL程序操作Hive将导入到集群的数据按照地区编号,站点编号,污染物编号,监测年份的顺序进行四维分区并存入Hive中,其在Hive中存储为airdb数据库下的AirData表。Spark SQL中的分区代码如下:

按上述方法完成空气质量大数据的分区存储以后,Hive中的每一个分区会在集群的分布式文件系统上生成一个文件目录。数据在集群上的文件存储结构如图3所示。图3中4级文件目录对应按4个属性进行的4次分区操作,最里层的“监测数据文件”为实际的数据文件。
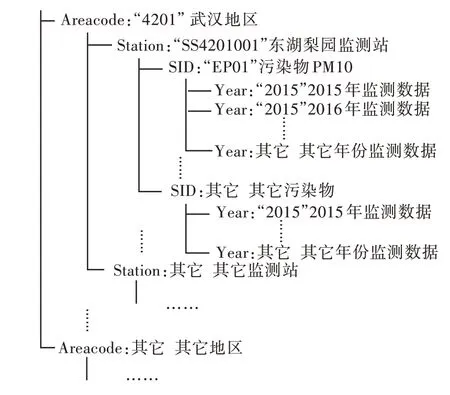
图3数据分区存储结构Fig.3 Storage structure of data partitions
4 实验部分
为评估本文提出的查询优化方法的效果。设计了对比实验,使用两台相同配置的服务器,其中一台使用SQL Server分区视图方法实验。另一台按照本文提出的方法进行实验。实验思路为:设计能充分代表实际查询需求的数据查询集,将查询集中每一个查询同时在Hive和SQL Server两种存储方法上执行,每个查询执行3次取查询时间的平均值为实验结果。
4.1 实验环境
实验用的服务器为两台一样的戴尔Power-Edge R720服务器配有两台英特尔E5-2620 V2物理CPU,每台CPU有6个内核,共12内核,主频2.10 GHz,内存32 GB,硬盘8 TB,物理网卡4个。一台安装Windows Server 2008操作系统,SQL Server 2012数据库管理系统。另一台用VMWare Vsphere将其虚拟化为4个虚拟机,安装Hadoop、Spark、Hive搭 建包 含1个Master节 点4个Worker节点(Master节点也是Worker节点)的集群环境。集群单个节点的硬件配置和软件版本如表2所示。
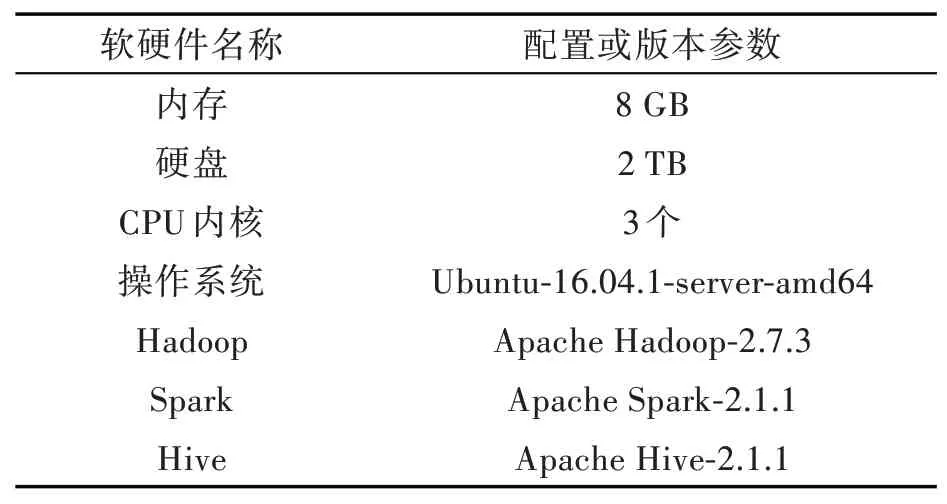
表2集群每个节点软硬件版本Tab.2 Hardware and software versions of each node of cluster
4.2 查询集
实验用的查询集从简单到复杂分为3类。第1类查询限定查某一地区的某一站点的数据,第2类限定查某一地区内的所有站点的数据,第3类无限定地查所有地区所有站点的数据。每一类查询在该类的查询限定条件下分别设计了4个查询:1)查询该类的限定条件下某污染物某一年的数值总和。2)查询该类的限定条件下某污染物所有年份的数值总和。3)查询该类的限定条件下所有污染物某一年的数值和。4)查询该类的限定条件下所有污染物所有年份的数值和。
以上3类限定条件,每类4个查询共12个查询分别用SQL编写在SQL Server上执行,用Java在Eclipse上编写再连接到集群在Hive上执行。所查询数据集的数据量分别有0.5亿条、1亿条、2亿条、4亿条4种。
4.3 结果分析
12条查询在Hive和SQL Server上的不同的数据集上执行时间如表3所示。由表3可以看出第1类查询(Q1.1至Q1.4)在SQL Server上的执行时间极短约为1~2 s,而在Hive上的执行时间却有10 s左右。究其原因,是因为这一类查询在查询条件中限定了地区和站点,由于在SQL Server上建立分区视图是使用Check约束限定了每张数据表的站点编号,在SQL Server上执行这一类查询时查询分析器只需找到所查站点的数据表并将其读入内存进行计算即可。而在Hive上执行,首先Spark集群有额外的建立线程、分配内存及销毁现场等操作,然后Hive需按照分区的层次,读入计算所需要的数据文件到内存后,才能进行计算。这些集群环境的额外时间开销使得基于Hive的方法在执行限定了具体站点的查询时耗时长。

表3 Hive和SQL Server在不同数据集上的查询时间Tab.3 Query times of Hive and SQL Server on different datasets s
对于其它几类查询,查询的限定条件少,查询目标不明确,查询复杂度增加了。此时,由于Hive上多维分区的优势,使得在Hive上的查询时间明显少于在SQL Server上的。这时即使基于Hive的方法有集群环境的额外开销也显得微不足道,优化效果明显。如图4所示的是数据量为4亿条时本文提出方法的查询的优化效果。从图中可见优化效果最好的是查询Q2.3,有96%的时间优化,最低的Q3.4也有47%的查询时间优化。
纵向分析实验结果,使用Hive和SQL Server两种方案在数据量为4亿条的数据集上的查询时间对比,如图5所示。从查询Q1.1到查询Q3.4,随着查询复杂度增加,查询用时都会增多,但是显然在Hive中的查询时间增长比在SQL Server中的时间增长要缓慢。图5中值得注意的是在Q2.3和Q2.4处的SQL Server查询时间有一个突起和突降。这是因为查询Q2.3、Q2.4是查询某一地区内所有站点里所有污染物某一年份和所有污染物所有年份的数据。在SQL Server上执行这2个查询时由于设备内存的限制,导致需扫描的文件只有轮流从内存中换入换出才能完成全部文件的扫描,这浪费了大量的时间。而在Hive上执行时则没有这样的限制,不仅查询耗时少,而且时间变化也非常平滑。这也是Hive上分区优化方法的优点之一。
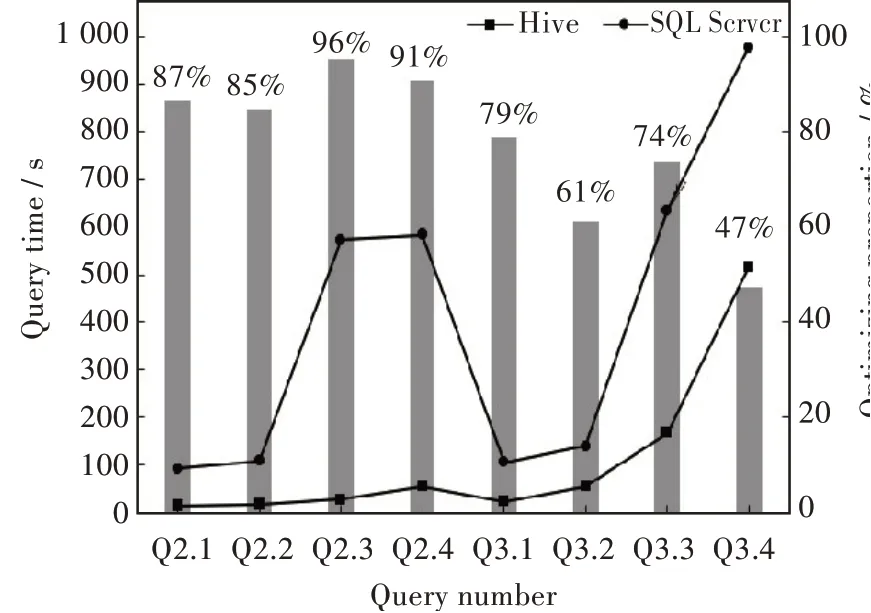
图4 Hive对不同查询的优化效果Fig.4 Optimization effects of Hive for different queries
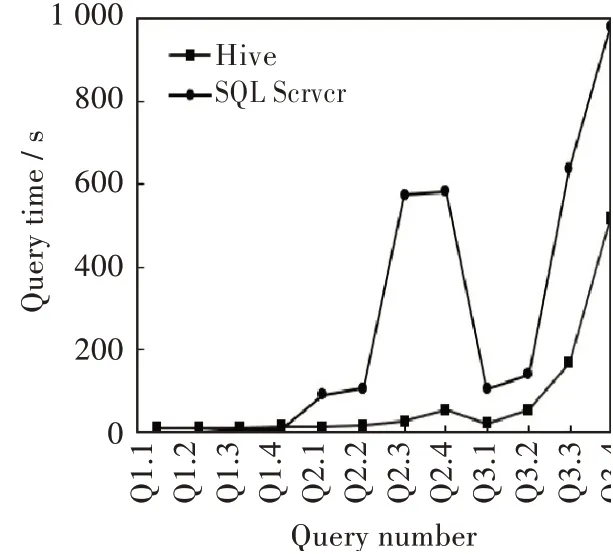
图5查询4亿条数据Hive与SQL Server用时对比Fig.5 Comparison of query time about 400 million entries of Hive and SQL Server
横向分析实验结果,如图6(a)和(b)所示,分别为Q3.4和Q2.4在4种不同数据集上查询时,Hive和SQL Server两种方案的用时对比。对于同一个查询,随着查询数据量的增加,查询用时也增加了,但在Hive上增加的时间要少于在SQL Server上增加的时间。对于其它的查询也是如此。

图6(a)查询Q3.4在不同数据集上的查询用时,(b)查询Q2.4在不同数据集上的查询用时Fig.6(a)Query times of Q3.4 on different data sets,(b)Query times of Q2.4 on different data sets
总而言之,同一查询在同一数据集上执行时,本文提出的基于Hive的方法比SQL Server要快。而同一查询在不同数据集上执行时,基于Hive的方法上查询时间的增长要比SQL Server上的时间增长慢。不同复杂度的查询在同一数据集上执行时,基于Hive的方法上查询时间的增长要比SQL Server上的增长也要慢。
5 结论
在环境空气质量自动监测系统中已产生海量数据给统计分析工作带来困难的背景下,本文基于Spark集群提出了一种在Hive上分区存储的查询优化方法,降低了空气质量大数据的查询时间消耗。通过与SQL Server上的分区视图查询方法对比得出:本文提出的方法对空气质量监测大数据的查询时间有47%到96%的优化作用。特别是当查询的限定条件越少、复杂度越高和查询数据量越大时,本文方法的优化作用越大。这一查询时间的优化将提升空气质量数据的分析和预警及预报工作的效率。
猜你喜欢
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
中国新通信(2016年11期)2016-08-09
电脑知识与技术(2016年13期)2016-06-29
