
基于模糊聚类的分布式Web日志挖掘方法
2020-08-13 13:06陈宝国
太原师范学院学报(自然科学版) 2020年3期
陈宝国,宋 旸
(淮南师范学院 计算机学院,安徽 淮南 232000)
0 引言
近些年来,随着搜索引擎、电子商务、社交媒体等互联网应用的飞速发展,使得Web信息系统已经成为目前规模最大的系统[1].在互联网中任一Web服务器上所进行的活动都会存储至日志文件中.随着现代信息技术的进一步发展,互联网中的信息已经呈现爆炸式增长,Web日志的分布也愈加广泛[2].对于互联网来说,特别是一些大型社交媒体网站与大型电子商务网站,分析分布式Web日志不仅可以明确网站运营情况,还可以挖掘用户的行为习惯,为营销计划的制定奠定基础,进而给用户推荐符合用户行为习惯的产品以及个性化服务等.为达到以上目标,需要进行分布式Web日志挖掘,因此相关的分布式Web日志挖掘和检索方法研究受到人们极大的关注[3].当前,对分布式Web日志挖掘方法主要有模糊C均值信息聚类方法和PSO进化方法等,但采用当前方法进行分布式Web日志挖掘的自适性不好,时间开销较大.为解决该问题,本文提出基于模糊聚类的分布式Web日志挖掘方法.最后进行仿真测试分析,展示了本文方法在提高分布式Web日志挖掘能力方面的优越性能.
1 分布式Web日志关联规则分布集及特征聚类
1.1 构造关联规则分布集
为了实现基于关联规则和模糊聚类的分布式Web日志挖掘,采用模糊特征检测方法进行分布式Web日志的语义特征分析,结合用户的偏好信息[4],建立分布式Web日志的关联规则分布集,表示为:
(1)

结合自适应加权方法构建分布式Web日志检测模型,以提升分布式Web日志中的用户类型评价能力[5],得到分布式Web日志用户属性表中的关联规则项定义为:
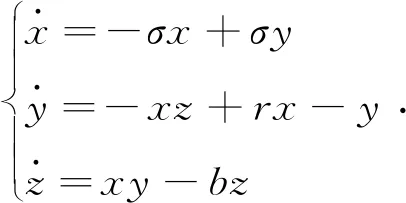
(2)
1.2 关联规则特征聚类
采用模糊信息聚类分析方法进行分布式Web日志关联规则特征聚类处理,提取分布式Web日志性的多重关联特征量[6],通过挖掘分布式Web日志的语义关联特征量,结合用户属性表分析方法,进行分布式Web日志的统计分析.其中,用户属性表分布定义为:
(3)
其中:wiN为第i个点采集的分布式Web日志信息权值,构建分布式Web日志的统计分析模型,得到用户相似度特征量,结合权向量学习方法,获取分布式Web日志挖掘的权系数(w1,j,w2,j,…,wt,j),其中t表示为分布式Web日志的关联规则系数,wtj为分布式Web日志挖掘的模糊加权系数[7],根据用户对项目的评分结果,得到分布式Web日志挖掘的相似度信息为:
(4)
其中:maxlFreqi,j为分布式Web日志的权重,假设ki为用户类别评分属性集,计算公式为:
(5)
式中
wi,j=tfi,j×Idfi
(6)
其中:fi,j为分布式Web日志挖掘的模糊规则特征量.
根据每个用户间评分向量的差异性,提取分布式Web日志的统计特征量,以此为基础进行分布式Web日志的模糊聚类[8],得到聚类特征项为:
(7)
添加了用户类别评分后,得到模糊聚类迭代式表示为:
(8)
其中:
(9)
(10)
(11)
式中,NB为分布式Web日志挖掘的嵌入维数,NS为分布式Web日志信息检测的强度.采用语义信息增强方法,进行分布式Web日志关联规则特征聚类,结果表示为[9]:
(12)
2 分布式Web日志挖掘优化
2.1 特征优化提取
以上述构建的分布式Web日志的关联规则分布集为基础,采用模糊信息聚类分析方法进行分布式Web日志关联规则特征聚类处理,结合重叠性迭代检测方法进行分布式Web日志挖掘过程中的自适应寻优,得到分布式Web日志信息的尺度信息为:
(13)
其中:
|X(f)|2=TC2Nsinc2(πfTC)|Xcode(f)|2
(14)
(15)
式中:TC为分布式Web日志信息的分布带宽;f为分布式Web日志关联信息的采样频率;|Xcode(f)|为目标用户u对其未评分用户的适应度权重[10],计算Web日志中其他用户的相似度:
(16)
(17)
采用模糊聚类分析方法,进行分布式Web日志挖掘,得到隶属度函数为:
(18)
(19)
结合粗糙集评估方法,得到分布式Web日志信息的关联规则集分布矩阵满足:
(20)
根据上述分析,进行分布式Web日志的特征优化提取,根据特征提取结果,进行Web日志挖掘和聚类分析.
2.2 分布式Web日志挖掘优化输出
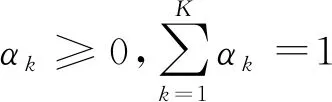
(21)
通过计算邻接点的适应度函数,对相似度高的分布式Web日志关联规则进行合并处理,根据模糊信息聚类结果实现分布式Web日志挖掘优化.实现流程如图1所示.
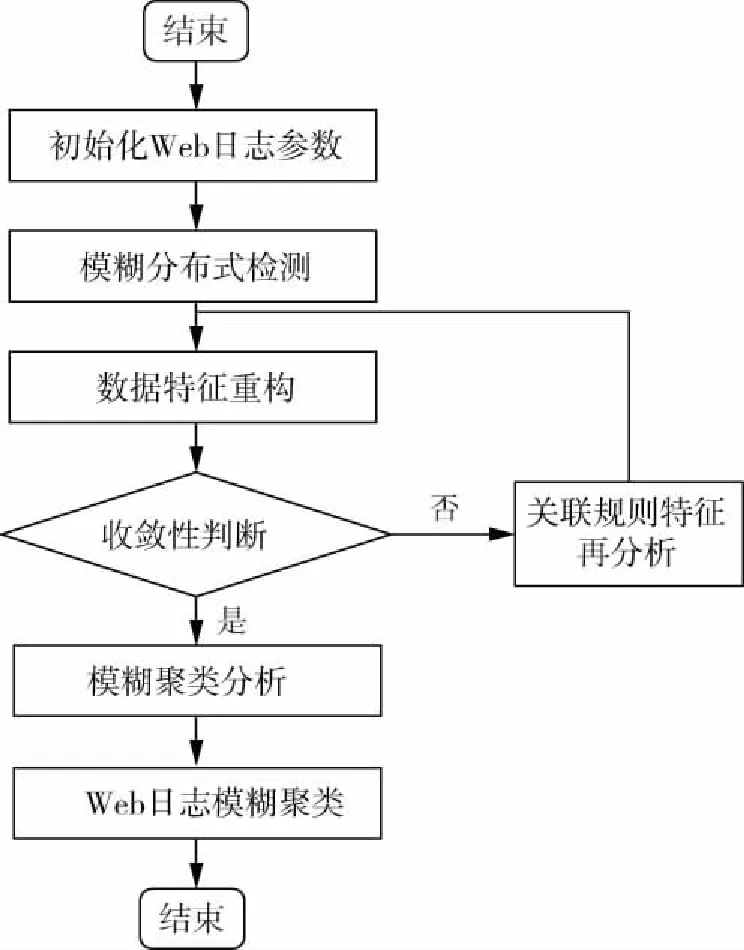
图1 分布式Web日志挖掘的实现流程
3 仿真实验与结果分析
为了验证本文方法在实现分布式Web日志挖掘中的应用性能,采用Matlab进行仿真测试分析.分布式Web日志信息采样的节点数为200,每个聚类簇的平均值为0.46,采用 100 KB的数据集作为测试集,进行分布式Web日志挖掘,得到分布式Web日志样本数据如图2所示.

图2 分布式Web日志样本数据
以图2所示的数据为研究对象,构建分布式Web日志的关联规则分布集,采用模糊信息聚类分析方法进行分布式Web日志关联规则特征聚类处理,实现分布式Web日志挖掘,得到挖掘结果如图3所示.分析图3得知,本文方法进行分布式Web日志挖掘的模糊聚类性较好.
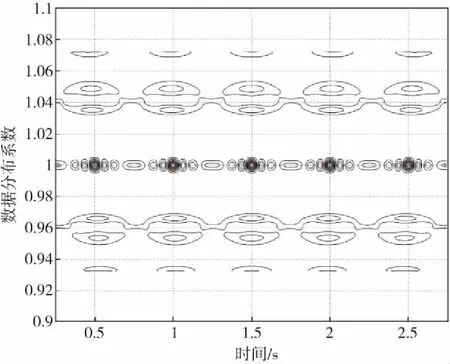
图3 分布式Web日志挖掘输出
测试不同方法进行分布式Web日志挖掘的精度,得到结果见表1,分析得知,本文方法分布式Web日志挖掘的精度较高.
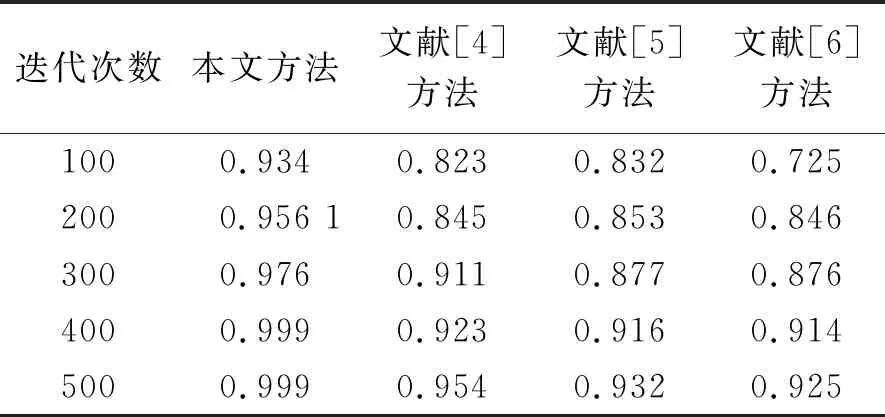
表1 挖掘精度对比
4 结语
为提升分布式Web日志挖掘精度,本文提出基于模糊聚类的分布式Web日志挖掘方法.构建分布式Web日志的关联规则分布集,采用模糊信息聚类分析方法进行分布式Web日志关联规则特征聚类处理,提取分布式Web日志性的多重关联特征量,结合重叠性迭代检测方法进行分布式Web日志挖掘过程中的自适应寻优,结合模糊关联规则调度方法进行分布式Web日志挖掘的负载均衡调度,通过计算邻接点的适应度函数,对相似度高的分布式Web日志关联规则进行合并处理,根据模糊信息聚类结果实现分布式Web日志挖掘优化.仿真实验结果表明,本文方法进行分布式Web日志挖掘的精度较高,聚类性较好.
猜你喜欢
湖南电力(2022年3期)2022-07-07
华人时刊(2021年13期)2021-11-27
新世纪智能(数学备考)(2021年9期)2021-11-24
心声歌刊(2020年4期)2020-09-07
当代陕西(2019年15期)2019-09-02
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
学苑创造·A版(2018年11期)2018-02-01
制导与引信(2017年3期)2017-11-02
读者(2017年5期)2017-02-15
