
基于深度学习的恶意风险网站过滤系统
2020-09-10 07:22朱书林李松州
客联 2020年11期
朱书林 李松州
【摘 要】本文基于轻检测、重检测与深度学习目标识别算法,利用嵌入式设备开发平台开发,以设计一个恶意风险网站过滤系统为目标进行了一个研究,并进行了测试。实验结果表明该系统满足上述要求并有较好的稳定性。
【关键词】层次化检测方法;目标识别;深度学习;网站过滤系统
Abstract: Based on the algorithm of light detection, heavy detection and deep learning target identification, this paper USES the embedded device development platform to design a malicious risk website filtering system as the target to carry out a study, and carried out a test. The experimental results show that the system satisfies the above requirements and has good stability.
Keywords: Hierarchical detection method, target recognition, deep learning, website filtering system
一、层次化检测方法简介
轻检测
轻检测算法需要轻便、快速、尽量准确,并达到最少数量的漏报,以达到对巨大输入进行预处理和数据筛选的作用。针对 A 的每一个 URL,若符合以下任意一个条件,则进入到重检测,否则丢弃。
(1)IP 地址曾经被恶意网站使用根据实践经验,一个曾经被用于恶意网站的 IP地址再次被利用做恶意的可能性较大。
(2)域名注册信息曾经用于注册过恶意网站同 IP 地址一样,同样的域名注册信息可以用来注册多个恶意网站。
(3)域名曾被恶意网站使用过如果域名之前被恶意网站使用过,那么其再次被利用的可能性也比较大。
(4)与 B 中任意 URL 含有相同的资源链接恶意网站在设计时,为了简单,其中的图片等元素经常会使用合法网站中的资源链接。
(5)与 B 中任意 URL 的标题一致恶意网站为了达到仿冒的目的,一般都会和合法网站具有相同的标题。
(6)含有 B 中某些重要的关键字
因为恶意网站是仿冒正常的合法网站,所以页面内容一般具有和合法网站一样的文字内容。
二、黑白名单技术
黑白名单的主要作用是,让GMSC有权限允许或禁止由特定源点发起,或到特定目的地的电话。简单地说,黑名单英语禁止呼叫,白名单允许呼叫。GMSC的判断标准是预先在WEM伤配置好的Trunk Group,号马前缀或属性等特性。
黑白名单有三个工作模式,黑名单,白名单
在黑名单模式下,只有设置为黑名单的配置生效,白名单同理。需要特别说明的是,在黑白模式下,黑名单和白名单的配置都生效,但是白名单的优先级高于黑名单,如果在同一个呼叫中,主叫或被叫有一方是白名单,呼叫允许。
三、深度学习模型设计
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
深度学习的概念由Hinton等人于2006年提出。基于深信度网(DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等人提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
四、实验过程
(一)实验环境
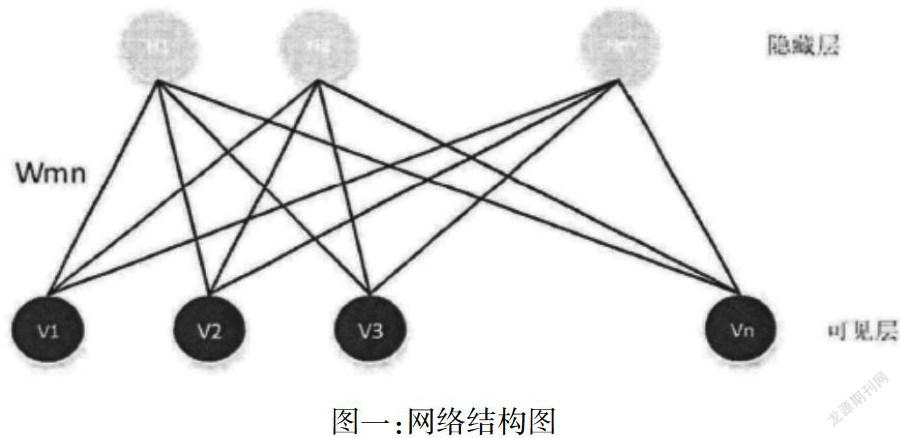
1.基于深度学习中的深度信念网络采用一种无监督训练方式使得整个网络能以最大概率来生成训练数据,我们可以使用它来进行数据分类。如下:图一为网络结构图
通过对比分歧算法逐层训练每个RBM,最终每一层的RBM的参数集w、o6构成DBN网络中的所有参数集,并用来初始化整个深度信念网络。预训练之后,通过在深度信念网络顶层叠加分类器,例如反向传播算法、支持向量机等,使用带标签的数据来对网络中参数进行微调,调整DBN的判别性能。
2.使用欠采样常常会导致丢失一些有用的多数类样本信息,而使用过采样则会增大过分拟合的可能性,充分考虑算法的复杂性和在整个恶意网站检测系统的应用场景,我们最终选择使用Borderline-Smote过采样方法[49]Borderline-Smote是基于Smote算法(Sybthetyc Minority Over-samplingTechnique),此算法是使用过采样小类样本来生成合成小类实例。不同于己经存在的过采样方法,Borderline-Smote过采样方法只富化边界小类实例(Borderline MinorityExample)。首先我们找到边界小类实例,然后从边界小类中生成合成小类实例,并添加到原始训练集中。基于Borderline-Smote DBN的分析模型,通过混合釆用Borderline-Smote1和Borderline-Smote2两种方法,对数据进行采样生成合成样本时,先后使用这两种方法。也即可以生成2s個合成样本。
3.恶意网站检测的基础也是最重要的一个环节就是特征值的提取,特征值的提取将很大程度上决定了恶意网站检测模型的准确度。网站页面在恶意网站识别中的关键特征包括URL(Uniform Resource Locator,统一资源定位符)特征、页面内容特征以及图像特征,综合考虑特征的重要程度以及提取效率等因素。
4.而特征提取则主要分为URL特征提取、HTML特征提取、以及特征向量的预处理
1).URL特征提取:
URL是网站的唯一定位符,通过在浏览器输入网站URL,用户可以进入访问该网站。其拥有统一的传输协议、数据格式、资源类型以及语法等。互联网上所有访问的图片、视频、文章都称为数据资源,每个资源都有唯一的一个URL地址,用户可以通过对应的URL地址找到需要访问的资源。攻击者通过在对应正规网站域名上进行操作,构造出与正规网站相似的域名或利用漏洞直接在正常网站地址后添加自己的恶意链接,从而诱导网民落入恶意网站。因此我们可以从URL路径级数、URL长度、域名是否为IP形式、域名级数、URL是否使用长词、URL中是否含有敏感词、URL中顶级域名出现在异常位置、URL中是否含有端口、URL中是否有“@”符、域名存活时间等方面来进行URL特征提取。
2)HTML特征提取
通过深入分析网页HTML文档特征、结构特征可以更加精确判断恶意网站。恶意网站为了更逼真仿冒真实网站,常常会加上真实网站的版权信息。而网站的版权所有者和网站是一一对应的,通过比对当前访问网站的版权信息可以判断是否为恶意网站。如:空链接的数目、外部链接数目、内部链接数目、表单数量、注册时间、版权所有者。
(二)实验过程
步骤 1:获取网站的多维属性,利用集合对多
维属性进行表示。
①提取网站首页超文本标记语言 HTML 标题、HTML 正文和层叠样式表 CSS 主题色彩;
②对所述 HTML 标题和 HTML 正文进行分词处理,得到单词向量集合 B={w1,w2…wn},n 为正整数;'
③对每一个向量 B 的单词 wi,统计其在网页HTML 的 标 签 <a>、<h1>-<h6><title>、<em>、<strong> 中出现的次数。按出现的次数加权后排名,得到排名后新单词向量集合 B'={w1,w'2…w'm},其中i=0,1…n,m 为正整数,且 m ≤ n;
④统计所述 CSS 主题色彩中使用最多的 3 种颜色类别,得到色彩向量描述集合 C,C={c1,c2,c3};
⑤获取属性值,建立属性描述集合 S,其中屬性值包括下述中的一项或多项:网站务器类型、Poweredby 信息(驱动信息)、脚本语言类型、返回状态码、跳转次数、网处、外域个数、内域个数和页面大小;
⑥根据集合 B'、C 和 S,建立网站多维属性样本集合 V,V=B'∪ C ∪ S,其中∪表示并集。
步骤 2:针对表示多维属性的集合,进行自编码特征学习。
①构建三层神经网络 N,其输入特征数量等于输出数量,且输入特征数量等于网站多维属性集合V 的特征数量;
②用网站多维属性集合 V 作为三层神经网络 N的输入值 Input,计算当前三层神经网络环境下的输出值 Output;
③比较输入值 Input 与输出值 Output,计算二者之差是否达到目标阈值;如果达到目标阈值,则完成学习,中间隐层节点向量 V '即为自编码学习结果;如果没有达到目阈值,则根据梯度下降法调整三层神经网络 N 的参数,重新计算。
步骤 3:利用自编码学习结果进行网站聚类学习,得到用于进行网站分类的支持向量 SVM 构建支持向量机 SVM,这里使用向量 V '作为输入。1014388653骤 1 和步骤 2,得到与该网站对应的自编码学习结果;然后,将与该网站对应的自编码学习结果输入到步骤 3,得到用于进行网站分类的支持向量机SVM进行网站分类,从而得到网站类别。本方法对于具有恶意特征的恶意网页,能快速侦测;采用多维属性描述方式,增加了系统的便利性与通用性;采用机器学习的方法且采样样本较为广泛,因此系统具有极强的稳定性。
(三)实验结果
最后我们可以通过层次化检测方法保证检测的准确性,以及极大地提升系统的运行效率。成功用深度学习实现了恶意风险网站过滤。
猜你喜欢
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年28期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
