
基于概率语言赋权交叉熵信度分配的应急决策
2021-01-26 10:48陈业华张亚明
系统工程与电子技术 2021年2期
白 静, 陈业华, 石 蕊, 张亚明
(燕山大学经济管理学院, 河北 秦皇岛 066004)
0 引 言
近年来不断爆发的各类突发事件使应急管理受到了广泛关注,而应急决策就是其中的重要环节。由于突发事件具有不确定性、动态性以及社会群体性等特点,其应急决策是一个利用不完备信息多部门协同合作,进行决策的动态过程。由于应急决策问题具有复杂性和不确定性, 决策者难以及时给出精确的决策偏好信息, 通常以模糊语言的形式表示[1-5]。考虑到犹豫模糊语言不能描述各语言术语的可能概率的限制,为了反映对各评估语言的不同偏好程度,Pang等提出增加犹豫模糊语言术语中每个语言的可能性表示,进而提出了概率语言术语集(probabilistic linguistic term set, PLTS)概念[6]。PLTS由两部分构成:多种评估语言值以及对各评估值的偏好程度(以概率的形式表示),从而完整呈现了事物本身的模糊性、决策者对评估决策的不确定性以及相应的偏好程度。随后,Zhang等学者开始尝试将PLTS应用于群决策中[7-11]。
另外,突发事件的影响范围很大,决策活动往往涉及多部门的协同决策,对于融合来自多部门多指标具有一定冲突的决策信息这一问题,目前的研究主要集中在模糊信息的合成算法上,以对各属性值加权求和从而计算备选方案的综合评估结果为融合方式,其中,杨勇等人为了解决集成直觉模糊数时存在的反直觉现象,提出了基于ε-修正的集成算子[12]。江登英等人将改进的三角模糊数集成算子应用到多属性决策中,优化了权重未知下模糊信息集成的过程[13]。Yu等人则提出了扩展TODIM算子[14]、模糊密集合算子[15-16]等新的合成算子[17]。还有部分学者研究各要素的赋权方法,比如主观赋权法[18]、客观赋权法[19]、组合赋权法[20]等。对于多部门多属性的决策问题,另一种思路是研究部门间的协同决策方式[21-25]。证据推理(evidential reasoning, ER)[26-27]理论融合决策理论、证据组合理论、模糊数学等多学科思想,在信息聚焦上表现优异,改善了信息融合不确定性问题,为融合多部门多指标的决策模糊信息提供了另一种思路,目前已经有学者将证据理论及ER理论应用到多指标不确定性决策中[28-31],但这些研究侧重于ER理论在多指标决策中的应用研究,以及相应的决策信息的证据合成算法研究,缺少专门针对多部门多指标应急决策特点的研究,多部门协同决策与常规的专家群决策均带有偏好性,但偏好来源的主要区别在于:专家间的专业知识结构较为一致,只是存在主观的风险偏好等主观因素,而各部门由于会受到工作经验、工作侧重点以及知识背景的影响,其作出的决策信息存在明显的专业偏好性,但大多数研究在证据合成过程中没有考虑到这一因素造成的证据不确信问题。并且该专业偏好在不同的突发事件下,各部门的偏好权威性可以科学衡量。针对这些问题,本文根据部门单位给出的概率语言评估信息,构建了考虑证据不确信度的信度决策函数及Mass函数,从认知科学角度考虑了不同部门认知差异造成的证据不确信度问题,并通过概率语言赋权交叉熵衡量部门间的专业偏好性,进而确定了指标确信度的计算方法,利用ER理论的递归准则对考虑部门认知差异的多指标不确定性评估证据进行修正与合成,从而实现了对多部门多指标不确定性决策信息的有效综合集成。
1 基本知识
1.1 PLTS及其性质
定义 1设S={si|i=-τ,…,-1,0,1,…,τ}为有序离散语言术语集合,由奇数个元素组成,其中si称为语言元素,2τ+1称为语言术语集S的粒度。则PLTS可以定义为
hS={sφn(pφn) |sφl∈S,pφn≥0,
(1)
式中,sφn(pφn)是概率为pφn的语言术语;NhS是hS中语言术语的个数。
1.2 ER算法及其性质
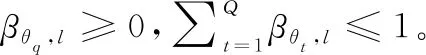
S(el)={(θq,βθq,l),q=1,2,…,Q; (Θ,βΘ,l)}
(2)
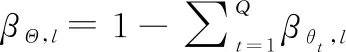

(3)
对于辨识框架中的独立等级元素θq(q=1,2,…,Q)及全局不完全集合Θ,有
mθq,l=wlβθq,l
(4)
mΘ,l=wlβΘ,l
(5)
(6)
(7)

2 决策模型构建与算法设计
2.1 概率语言多属性应急决策问题数学描述

(8)
在多部门多指标决策中,各部门决策者通常会根据自身的专业知识、经验对方案进行评估,具有一定主观性,会受自身知识水平及行事风格的影响对一些评估指标作出相对不可靠的评价,本文的模型构建思路是采用ER理论的证据不确信度衡量评估指标的不可靠性,即将各部门根据决策指标体系给出的评估信息视为ER理论的一组证据信息,通过概率语言交叉熵计算得到的指标不确信度来构建各证据下的不同方案的加权信度指派函数, 然后运用ER合成法则进行信息融合,从而得出决策结果。则部门kt对方案as的第l个评估指标el的信度结构记作:

(9)

(10)

定义 3假设对于评估指标el,根据主观认知或客观分析赋予指标el一个[0,1]内的函数值,该数值表示指标el的可靠度,记为rl。
可靠度rl的特殊取值具有特定的含义:
(1) 对指标el各部门间的决策偏差越大,指标l不确信性越大,进而可靠度越小,rl越接近于0;
(2) 对指标el各部门间的决策越接近,指标el不确信性越小,可靠度越大,rl越接近于1;
(3) 当各部门对指标el在此次评估中的决策完全一致时,rl=1。
则可靠度rl可表示为
(11)

(12)

令S=(St(el(as)))T×L为部门kt通过评估指标el对方案as进行评估的决策矩阵,t=1,2,…,T,l=1,2,…,L。其中,el(as)包含指标el的可靠度rl及权重wel,其决策矩阵可表示为
(13)
2.2 基于概率语言赋权交叉熵的可靠度rl确定方法
在群决策过程中,各部门由于受到部门职权范围、经验和背景等因素的影响,所提供的决策信息往往会有所差异甚至冲突较大,理论上而言, 如果不同部门对某个指标信息的评估差异越小,则说明该指标包含的信息不确信度越低。因此,可以通过部门提供的评估信息之间的冲突度构造出评估指标的不确信度,其中关键问题即是如何合理确定不同部门提供的评估信息之间的冲突度。本文利用概率语言信息熵包含的概率信息与部门间的权重信息结合来衡量指标的评估信息冲突度。

概率语言交叉熵考虑评价语言的模糊程度同时又包含了相互间的偏差程度,因此对于任一评估指标el,部门kt与其他部门所作评价的偏差程度可以用概率语言交叉熵表示,如果作比较的两部门权重值相差悬殊,那么意味着权重低的部门与权重高的部门相比其所作评价对该指标的评估结果并没有起到重要作用,那么两者间的评价偏差对评估指标el的不确信度影响相对较低,相反,如果作比较的两部门权重值接近,那么意味着两部门所作评价对该指标的评估结果起到大体相当的作用,两者间的评估偏差对评估指标el的不确信度影响也相对较高。结合概率语言交叉熵及部门kt相对于评估指标el所占权重,得到概率语言赋权交叉熵。


根据交叉熵定义及部门kt、kj相对于评估指标el所占权重,给出两个PLTS的hSt和hSj之间的赋权交叉熵为
CEW(hSt,hSj)=
(14)


则

(15)

(16)
由Jensen不等式得
(17)
即CEW′(hSt,hSj)≥0。
由0≤|wel,t-wel, j|≤1,得
(18)
综上所述,可得
证毕
同时,不同专家评估时给出的PLTS术语数目可能互不相同,为了方便后续的信息融合,将给出的所有PLTS术语数目统一成其中的最大值,其中补充的术语概率设为0。
那么,对于指标el,其不确信度可以由所有部门所作评价的差异度表示。
定义 5指标el的不确信度为


证明令
(19)
则
对于成熟的、有一定规模的商圈而言,移动应用不可或缺。作为商圈信息展示的网上门户,商业推广和客户服务是移动APP的主要功能。WIFI和4G网络的普及使得相关应用软件的下载更加便捷。依托微信平台的企业公众号开发和小程序应用能提高用户的体验,在系统设计建设过程中可考虑先设计APP,再向其他平台扩展。APP要以轻量级为主,主要体现出商圈的特色服务和货品的分区、分类。

(20)
由式(18)和式(19)得
weijNln 2≤Nln 2
(21)
综上所述,可得
(22)
证毕

这样得到了不同方案在各指标下改进的Mass函数,即
n=1,2,…,Nhs
(23)
(24)
(25)
(26)

2.3 基于ER递归法的证据合成过程
首先合成所有部门kt(t=1,2,…,T)针对某一指标el给出方案as的评估信息S1(el(as)),S2(el(as)),…,ST(el(as))(l=1,2,…,L),求得方案as在指标el下的评估信息,记作S(el(as))=Φ(S1(el(as)),S2(el(as)),…,St(el(as)),…,ST(el(as))),其中Φ表示对St(el(as))(t=1,2,…,T)的合成过程。然后,合成所有指标el(l=1,2,…,L)的信息,即S(as)=Φ′(S(e1(as)),S(e2(as)),…,S(el(as)),…,S(eL(as))),Φ′表示对S(el(as))(l=1,2,…,L)的合成过程。Φ、Φ′合成过程采用ER递归法合成不同证据来源的加权信度指派函数,最后得到各语言术语的信度,具体合成过程如下:
步骤 1合成T个证据得到
(27)
mΘ,l(as)=
(28)
(29)
(30)
(31)
(32)
式中,mθφn,l(as)表示方案as关于指标el被评估为等级θφn的合成加权信度指派函数,通过合成的mθφn,l(as)生成相应置信度pθφn,l(as)。
步骤 2合成所有L个指标el
(33)
(34)
(35)
(36)
mθφn(as)=
(37)
mΘ(as)=
(38)
(39)
(40)
(41)
(42)

综上所述,可以得到基于赋权交叉熵信度分配的概率语言决策方法步骤如下:
步骤 1各部门根据不同评估指标给出各方案的评价信息,得到概率语言决策矩阵Ht;
步骤 2根据对评估指标el部门kt所占权重wel(l=1,2,…,L)以及交叉熵概念计算衡量部门间评估差异的概率语言赋权交叉熵CEW(hSt,hSj);
步骤 3根据概率语言赋权交叉熵CEW(hSt,hSj)计算el证据(指标)的不确信度,进而得到不同方案在各指标下的加权信度指派函数;
步骤 4根据ER递归法合成不同证据来源的加权信度指派函数,最后得到各评价等级的置信度;
步骤 5根据信度函数最大化原则进行决策。
3 实例分析
3.1 问题描述
某县域高速公路部分路段沿线出现突发火情,消防部门(k1)、交管部门(k2)以及电信部门(k3)共同组织协同应急救援。结合受灾程度、区域环境和技术设备限制,专家提出5个应急方案。
方案a1:所有相关路段禁行,采用6架消防设施和2部消防工具实施救援,就地安置区域内民众。
方案a2:所有相关路段禁行,采用3架消防设施和5部消防工具实施救援,组织区域内民众安全撤离。
方案a3:相关路段部分车道限行,采用4架消防设施配合人工方法实施救援,就地安置区域内民众。
方案a4:相关路段部分车道限行,采用2架消防设施和2部消防工具配合人工方法实施救援,就地安置区域内民众。
方案a5:相关路段部分车道限行,采用8部消防工具实施救援,组织区域内民众安全撤离。
3个部门专家分别从可行性(e1)、成本(e2)和效果(e3)3类评估指标对几种方案进行评价,但不同部门根据自身分管工作及专业经验针对某类评估指标的侧重方向存在差异,比如在成本这一指标上消防部门主要从过火面积及灭火操作时长等方面来考虑,交管部门从限行车道数目、封锁路段区位等方面考虑,电信部门从灾情现场信号覆盖率等方面考虑。通过专家打分的方式得到指标本身权重,分别为0.34,0.28和0.38。风险偏好系数δ采用各专家给出的平均值0.9,而指标评估的侧重方向影响了其在该指标上产生的作用程度,即部门kt在3种评估指标上所占权重wel(l=1,2,3),本文采取决策成员自评及互评的打分方式共同决策相应权重,如表1所示。
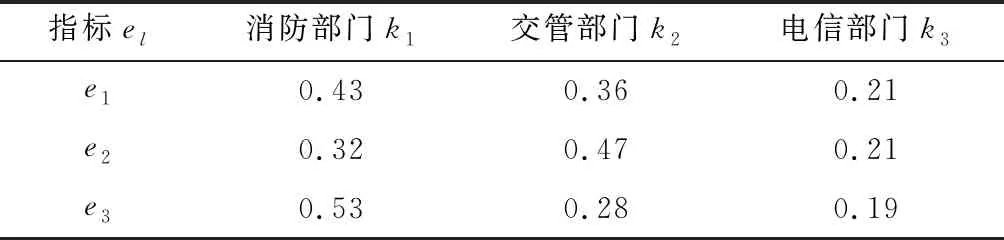
表1 各部门对于决策指标的相对权重
各部门根据自身经验,利用PLTS分别对备选方案进行评价,即给出备选方案的概率语言评价信息及对应语言术语的概率,其中评价信息表示为
S={s-3=极差,s-2=很差,s-1=差,s0=中,
s1=好,s2=很好,s3=极好}
表2~表4为PLTS形式的原始评估信息。规范化后的决策信息如表5~表7所示。

表2 消防部门k1原始评估信息

表3 交管部门k2原始评估信息

表4 电信部门k3原始评估信息

表5 消防部门k1规范化后的决策信息

表6 交管部门k2规范化后的决策信息

表7 电信部门k3规范化后的决策信息
3.2 应急方案决策
步骤 1将各部门针对方案的指标el给出的原始评估PLTS规范成具有相同数量的语言术语,得到规范化的决策信息如表5~表7所示。
步骤 2根据部门kt在3种评估指标上所占权重wel(l=1,2,3),利用式(14)计算部门间关于指标评估的概率语言赋权交叉熵,如表8所示。


表8 部门间指标评估的概率语言赋权交叉熵

进而根据式(23)得到不同方案在各指标下的折扣信度分布函数。
步骤 5根据ER递归法,首先合成针对方案as的同一指标来自不同部门给出的证据来源的基本信度分配函数,如表9所示。

表9 对各方案as部门给出的折扣信度分布函数
步骤 6针对方案as合成来自所有指标的证据来源的基本信度分配函数,得到各评价等级的置信度:
S(a1)={(-3,p(a1)=0.115),(-2,p(a1)=0.115),
(-1,p(a1)=0.121),(0,p(a1)=0.117),(1,p(a1)=
0.032),(2,p2(a1)=0.079),(3,p3(a1)=0.061)}
S(a2)={(-3,p(a2)=0.171),(-2,p(a2)=0.127),
(-1,p(a2)=0.152),(0,p(a2)=0.130),(1,p(a2)=
0.072),(2,p(a2)=0.031),(3,p(a2)=0.036)}
S(a3)={(-2,p(a3)=0.201),(-1,p(a3)=0.116),
(0,p(a3)=0.087),(1,p(a3)=0.025),(2,p(a3)=
0.034),(3,p(a3)=0.124)}
S(a4)={(-2,p(a4)=0.140),(-1,p(a4)=0.146),
(0,p(a4)=0.061),(1,p(a4)=0.067),(2,p(a4)=
0.049),(3,p(a4)=0.120)}
S(a5)={(0,p(a5)=0.142),(1,p(a5)=0.071),
(2,p(a5)=0.124),(3,p(a5)=0.077)}
步骤 7根据信度函数最大化原则计算最优方案,得到方案a4为最优方案,即相关路段部分车道限行,采用两架消防设施和两部消防工具配合人工方法实施救援,就地安置区域内民众。
3.3 敏感性分析
式(11)中的δ取值可能会影响决策结果,本文通过选取不同δ值进行敏感性分析。假设各评价等级的效用采用式(14)中的转化因子g进行转化,仿真结果如图1所示。

图1 不同风险系数下的效用值Fig.1 Utility value under different risk factors
由图1可知,当决策者趋向风险规避型,即δ增大时,备选方案的效用值逐渐减小,当δ<0.25时,δ的变化对备选方案的排序没有影响,保持在a4fa5fa3fa2fa1;当δ增至0.25时,备选方案的排序发生了改变:a4fa5fa3fa1fa2,并且δ>0.25时,δ的变化对备选方案的排序不再产生影响。
3.4 对比分析
为了验证本文模型的有效性和实用性,将本文模型与文献[10]、文献[11]和文献[23]的模型进行对比。其中,文献[10]采用其提出的概率语言交叉熵作为评估指标的不确信度,采用文献[23]模型决策时邀请同一组专家进行补充评价。将上述模型的决策结果与本文的决策结果进行对比,结果如表10所示。

表10 各模型决策结果对比
由表10可知,本文模型与文献[11]和文献[23]的模型对于最优方案的决策结果一致,验证了本文模型的有效性。而文献[10]研究侧重于多属性融合,没有针对多部门协同决策的特点,决策结果与其他模型产生偏差,也进一步验证了本文模型在处理部门专业偏好性的优势。
对于备选方案排序,本文模型(0.25≤δ≤1)与文献[23]的模型完全一致,但本文模型相对于文献[23]的优势在于部门专家在评价方案时,仅需一次评分,评价过程更易于理解,文献[23]方法需要专家根据评分标准多次评分,评分过程费时费力;当本文模型(0≤δ<0.25)时,专家偏向风险接受,即较少考虑部门间的专业偏好,因此备选方案排序结果与文献[10]趋于一致。
4 结 论
突发事件应急决策具有多部门协同决策、多指标评估、评估信息不确定的特点,本文采用PLTS表示决策部门的不确定性评估信息,全面、具体地表达了决策者的多维偏好及偏好程度。将ER法应用到概率语言决策中,利用ER法的大系统分解协调思想对来自多部门、多指标的决策信息进行合成,降低了合成结果的不确定性,其中通过构建概率语言赋权交叉熵对折扣系数进行改进,有效地反映了由部门认知差异产生的指标不确信度。算例分析结果验证了本文模型处理多部门决策信息冲突问题具有较大的优势。本文研究的重点是证据的不确信度问题,而权重的确定也是决策信息合成的重要环节,今后可以从ER法的证据赋权角度入手针对多部门、多指标的应急决策问题进行应用研究。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中国西部(2022年2期)2022-05-23
中学生数理化·中考版(2021年6期)2021-11-22
世界科学技术-中医药现代化(2021年7期)2021-11-04
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
南大法学(2021年6期)2021-04-19
活力(2019年15期)2019-09-25
测控技术(2018年6期)2018-11-25
管理现代化(2016年6期)2016-01-23
