
单组率研究稀疏数据的Meta分析方法
2021-01-28 00:54陈文松刘玉秀陆梦洁刘雅琦袁阳丹
中国循证儿科杂志 2020年6期
刘 曼 陈文松 刘玉秀,3 陆梦洁 刘雅琦 袁阳丹
近年来,医学研究中对单组率研究的Meta分析呈增长趋势[1-3],然而当遇到稀疏数据时,不顾方法应用条件盲目选择的情况时有发生,导致合并结果的偏倚,甚至产生误导的结论[4]。有学者指出,单组率研究的Meta分析若出现稀疏数据,尤其是零事件的研究较多时,常用的Meta分析方法统计性能不佳,应谨慎选择[5]。本文针对单组率研究遇到稀疏数据时进行Meta分析的方法,择优选出目前认为具有较好性能的基于Freeman-Tukey转换、反正弦转换的倒方差法和广义线性混合模型(GLMM)方法,通过Monte-Carlo模拟比较其统计性能,为Meta分析的方法选择提供依据、提出建议。
1 方法
Meta分析有3个重要方面,一是分析的框架,二是模型的选择,三是异质性评价方法的选择。
1.1 框架的选择 单组率研究的常用Meta分析方法原理通常是基于正态分布的。对于发生率为p的总体,例数为n的样本中某一事件的发生数e服从二项分布,若n足够大且p不接近0或1,可用二项分布近似正态分布。然而,当n较小或p接近0或1时,由于分布的离散性,则不宜用二项分布近似正态分布。因此,二项数据建模最流行的框架是通过变换使之近似于正态分布,在进行Meta分析的倒方差法中,提出了几种转换方法,包括ln转换(自然对数转换)、logit转换[6]、反正弦转换[7]和Freeman-Tukey双重反正弦转换(FT转换)[8-10]。前2种转换在计算过程中,遇到零事件可能会面临除零问题,尽管可以做连续性校正,但研究证明这些校正仍会产生偏倚,难以保证结果的稳定性,而后2种转换则无需校正且可以保持较好的统计性能,因此不少文献推荐选择后两者[6, 7,11]。
单组率的Meta分析还有另外1种分析框架即GLMM,是Stijnen等[10]提出的确切研究内似然模型(EWLM),包括二项-正态模型(BN)和泊松-正态模型(PN)等[12],可方便地实现稀疏二分类数据的Meta分析,他提出以各研究真实的分布代替其正态分布的假设,在单组率Meta分析中,最常用的是BN[13],该模型包括2个部分,第1部分用二项分布对数据进行建模,假设事件数ei服从参数为pi,样本量为ni的二项分布,即
第2部分是logit转换后使用正态分布来模拟研究之间的异质性,即用正态分布对随机效应进行建模

logit(pi)~Normal(μ,τ2)(2)
其中,μ是总体logit率的均值,τ2是logit尺度下的研究间方差(τ为标准差)。τ为0时则简化为固定效应模型。令 logit(pi)=θi,因此事件数ei的真实分布为[5],

ei~Binomial(ni, exp (θi)1+exp (θi))(3)
1.2 模型的选择[14]在固定效应模型下,分析中的所有研究都具有共同的真实效应,合并效应是对共同效应大小的估计,其原假设是共同效应为0(对于差值)或1(对于比值)。在随机效应模型下,假设研究中的真实效应是从真实效应的分布中抽样的,原假设是这些效应的平均值为0(对于差值)或1(对于比值)。2种模型的选择文献已有详细说明[15],在此不赘述。固定效应模型下,若出现0事件,经模拟证明,FT转换是优选方法,而在随机效应模型下,因研究间变异差异较大,FT转换可能难以保持稳定的统计性能,而在实际应用中,逆方差法应用较多,忽视了GLMM。
1.3 异质性评价方法的选择[14]对于研究间方差τ2,目前常用的参数估计方法有3种。1种由Dersimonian和Laird提出的非迭代法[16],另外2种是极大似然(ML)方法和限制极大似然(REML)方法。在倒方差法中,这些方法都可以应用,对于随机效应模型,由于极大似然估计会导致方差的低估,故首选REML方法。对于二项式模型的GLMM,由于随机效应的高维积分的密集计算,无法使用REML方法,因此大多数软件都使用ML方法估计研究间方差。
2 Monte-Carlo模拟研究
考虑采用3个度量值评估FT转换、反正弦转换和GLMM在Meta分析应用中的统计性能[17],包括点估计的相对偏倚、置信区间覆盖率和平均宽度。所有模拟在SAS 9.4系统环境下实现。将每次Meta分析模拟的研究个数(k)设定为30,取常用的95%CI固定不变。考虑到样本量和数据结构对结果的影响,设置了2个不同的总样本量(6 000和60 000),各样本量下又分平衡和不平衡2种结构。总样本量为6 000时,平衡结构的每个研究的样本量设定为200,不平衡结构的最小样本量为50,其他样本以10为增量依次递增至340。对总样本量为60 000的情形,相应设置扩大10倍即可。模拟研究平均总体率(p)从非常罕见的事件(0.001、0.005、0.01)到相对常见的事件(0.05、0.10、0.30、0.50)变化,研究间标准差(τ)设置为0.005、0.3、1(logit尺度下)。基于以上模拟参数设置,共需模拟2×2×3×3×7=252种场景。基于Meta分析随机效应模型框架,在不同模拟场景下,进行10 000次模拟,模拟分为2步,首先从给定的logit率[logit(p)]和研究间方差(τ2)的正态分布中模拟真实的logit率(ηi),再从二项分布中模拟率为pi=eηi/(1+eηi)、样本量为ni的Meta分析数据集。分别采用不同的变化参数设定进行Meta分析,获得相应的点估计和95%CI估计。该随机模拟过程反复多次进行,直至达到规定的模拟次数,再根据各次的模拟结果计算各性能评价指标。
3 结果
在不同的模拟场景下,通过Monte-Carlo模拟Meta分析获得的不同方法的相对偏倚(图1)、置信区间覆盖率(图2)和置信区间平均宽度(图3)结果。总体来看,在总样本量相同的情况下,平衡和不平衡2种样本量结构下的各种方法的统计性能行为都非常接近;在总样本量不同的情况下,不同方法间的行为表现存在明显差别。
图1显示,总样本量为6 000时,当研究间方差较小(τ<1)时,平均总体率>5%的各种方法的点估计均接近无偏;当研究间方差大时(τ=1),FT转换和反正弦转换只有在率为50%时才接近无偏;而总体率<5%时,只有GLMM继续保持无偏。总样本量为60 000时,当研究间方差较小(τ<1)时,平均总体率>0.5%的各种方法的点估计均接近无偏;当研究间方差大时(τ=1),FT转换和反正弦转换依旧表现较差,而GLMM无论在何种情况都接近无偏。
图2显示,样本量为6 000时,当研究间方差较小(τ<1)时,平均总体率>5%的各种方法的置信区间的覆盖率均接近名义水平;当研究间方差大时(τ=1),FT转换和反正弦转换只有在总体率>30%时才接近名义水平,而GLMM整体上保持在名义水平附近。样本量为60 000时,当研究间方差较小(τ<1)时,平均总体率>0.5%的各种方法的置信区间均接近名义水平;当研究间方差大时(τ=1),FT转换和反正弦转换的覆盖率转换均较差,而GLMM的覆盖率依旧保持在名义水平。图3显示,各方法间的置信区间的宽度无明显差别,而随着平均总体率和研究间方差的增大,各方法的区间宽度均明显增大。
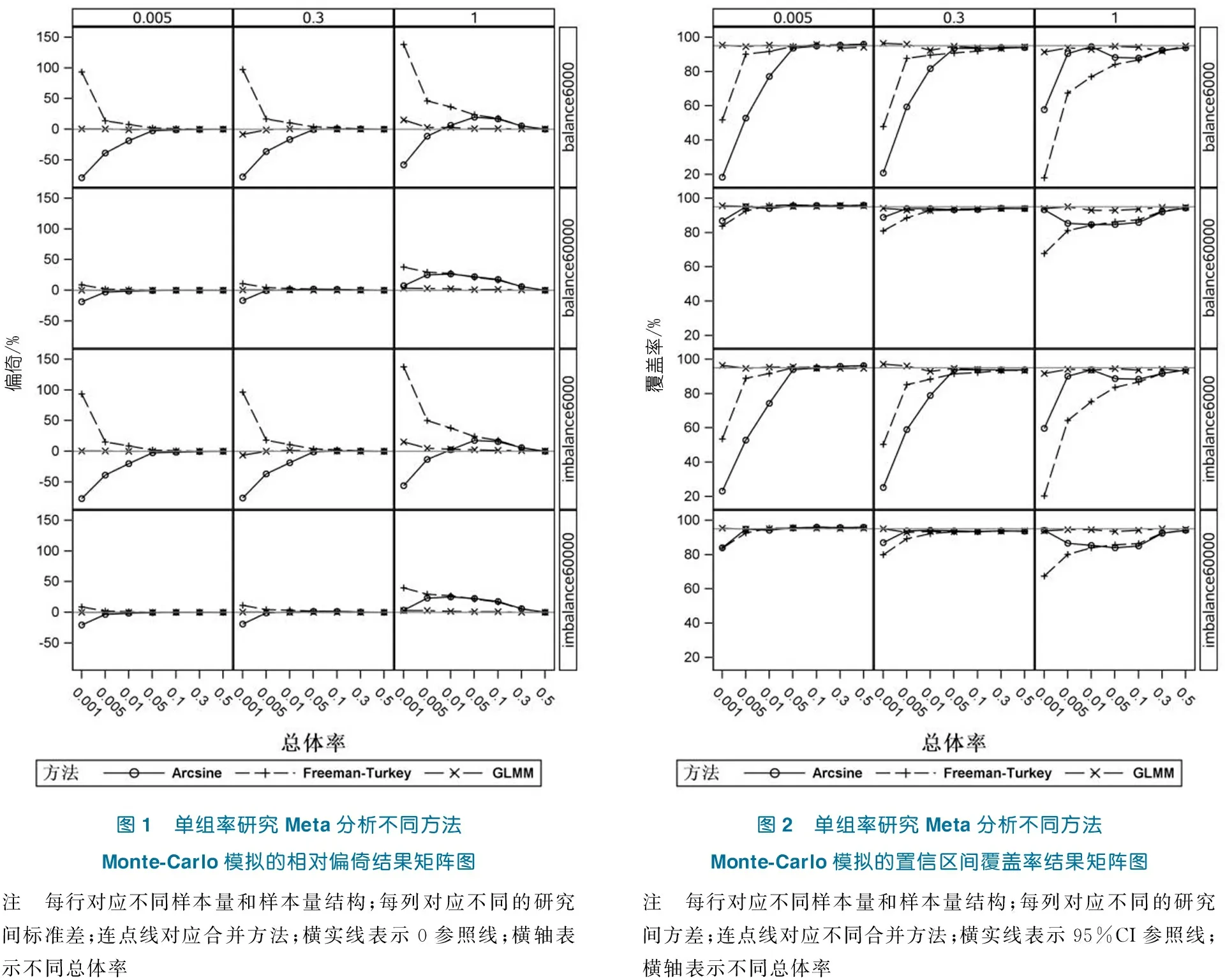
图1 单组率研究Meta分析不同方法Monte-Carlo模拟的相对偏倚结果矩阵图图2 单组率研究Meta分析不同方法Monte-Carlo模拟的置信区间覆盖率结果矩阵图注 每行对应不同样本量和样本量结构;每列对应不同的研究间标准差;连点线对应合并方法;横实线表示0参照线;横轴表示不同总体率注 每行对应不同样本量和样本量结构;每列对应不同的研究间方差;连点线对应不同合并方法;横实线表示95%CI参照线;横轴表示不同总体率

图3 单组率研究Meta分析不同方法Monte-Carlo模拟的置信区间平均宽度结果矩阵图
4 GLMM的软件实现
4.1 SAS实现 SAS中的GLMM是通过PROC NLMIXED实现的[18],NLMIXED过程适合包括固定和随机效应模型的非线性混合模型,考虑到随机效应,可以为数据指定条件分布,包括正态、二项和泊松分布等,通过NLMIXED过程拟合的模型可以看作是通过MIXED过程拟合的随机模型的扩展,在MIXED过程中可以通过ML和REML估计参数,而NLMIXED过程仅能实现ML。另外由于标准Wald方法没有考虑τ估计的不确定性,NLMIXED过程的统计基础是基于t分布的,其自由度df=N-l[19]。
用NLMIXED过程做Meta分析可分别估计固定效应和随机效应模型。固定效应模型中,需指定总体率的初始值及取值范围,并指定事件数的分布类型。在随机效应模型中,除了总体率的初始值,还需指定研究间方差的初始值,并指定随机项。Meta分析的GLMM的NLMIXED详细过程见本文附录。
4.2 R语言实现 R语言的“meta”包中的“metaprop”函数可用来做单组率的Meta分析,通过指定“metaprop”函数中的参数“method=“GLMM”,R语言就会自动调用“rma.glmm”函数拟合GLMM。默认情况下,模型中各个系数的检验统计量以及相应的置信区间是基于标准正态分布的,作为一种替代方法,可以设置“rma.glmm”函数中的参数“test ='t'”,该方法基于t分布获得各个系数和置信区间。对于异质性检验,该函数会自动执行2种设定。①Wald型检验,用于检验与饱和模型中添加的哑变量相对应的系数的显著性。②似然比检验,检验相同的系数集,但是通过计算-2倍固定效应和饱和模型的对数似然差来进行。对于由rma.glmm函数拟合的模型类型,这2个检验并不相同,甚至可能导致相反的结论。
GLMM模型不需要计算单个研究的观察结果,因此,当事件数为零时,不必在事件计数中添加常数,直接令p=0不是问题(所有研究均为零事件的极端情况除外)。原则上,单个研究的权重可以从每个单独研究的似然贡献中得出,然而,该信息目前在R软件中不可用,所以在R中无法获得各研究权重,且只适用于logit转换,对于单组率的其他转换则只能使用倒方差法。
4.3 STATA实现 STATA中的“metan”命令可用来做Meta分析[20],在“metan”中,使用基于渐近方差的正态分布来计算置信区间。对于率,此区间可能包含不允许的值,尤其是当率接近0或1时。当率为0或1时,由于估计的标准误为零,因此无法计算置信区间,“metan”命令会自动从合并计算中排除率等于0或1的研究。
Nyaga等[21]在此基础上开发出了“metaprop”命令,以补充“metan”,允许使用Wilson得分法和Clooper-Pearson确切法计算95%CI并结合了FT转换,该命令还可以使用二项分布对研究内变异进行建模。需要STATA 10或更高的版本,通过键入“ssc install metaprop”命令安装,还可以下载“metaprop”的更新“metaprop_one”,该命令可用来拟合GLMM,更新后的命令需要STATA 13版本。具体语句见附录。
5 案例分析
一项发热婴儿单核细胞增多性李斯特菌和肠球菌检出率的Meta分析[4]就遇到了稀疏数据的问题。该研究为了评估由单核细胞增多性李斯特菌和肠球菌引起严重细菌感染的患病率,纳入了15项研究,共计20 703份血样,分别对李斯特菌和肠球菌引起菌血症的患病率做Meta分析,两者的患病率均不高,因此该Meta分析中出现了大量的零事件,尤其是李斯特菌,除了2项研究各出现1例事件外,其余研究的患病率均为0,用R语言中“meta”包中的“metaprop”函数对李斯特菌菌血症发生率做Meta分析的森林图见图4,其中方法选择GLMM,各研究95%CI方法选择Clopper-Pearson法。用GLMM拟合的结果为0.01%(95%CI:0~0.04%),FT转换的结果为0.02%(95%CI:0~0.07%),反正弦转换的结果为0(95%CI:0~0.01%)。
原文中首先对本组资料的零事件进行校正,得到的结果为0.03%(95%CI:0~0.06%),该结果与GLMM的结果有明显差别。
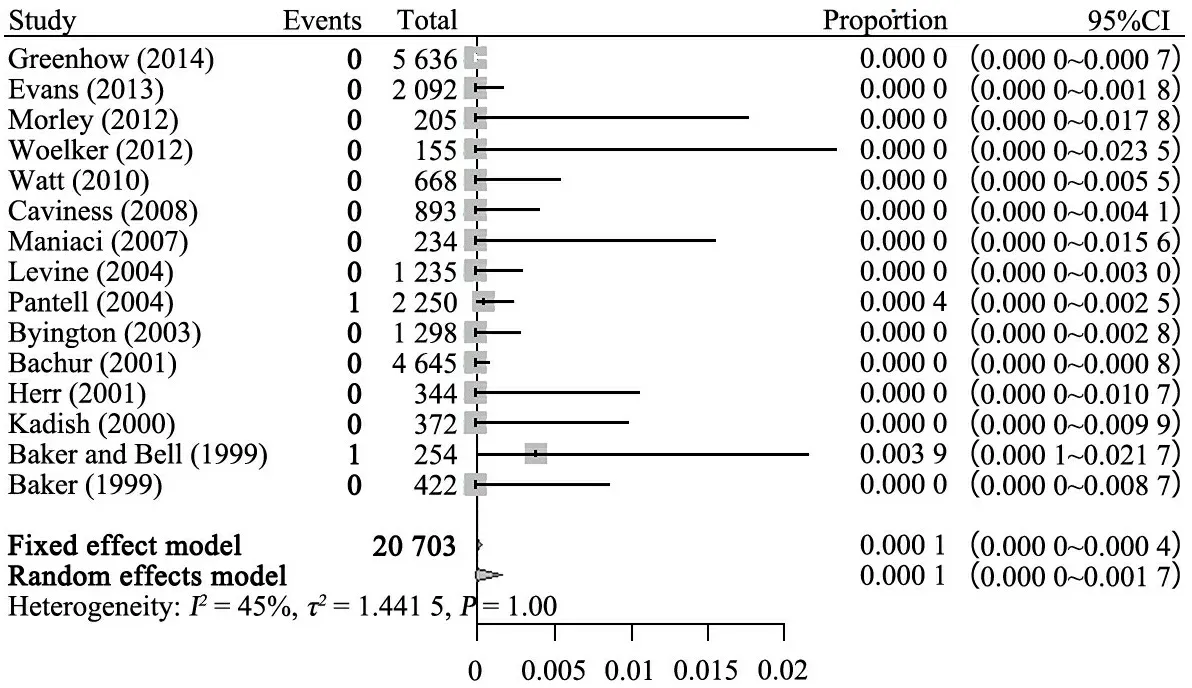
图4 单核细胞增多性李斯特菌引起严重细菌感染的患病率森林图
6 讨论
本文讨论了单组率研究出现稀疏数据时常用的Meta分析方法,包括基于FT转换和反正弦转换的倒方差法和GLMM方法,通过Monte-Carlo模拟,设置多种模拟分析场景,比较了3种方法的统计性能,结果发现GLMM方法具有较好的统计性能且对稀疏数据具有稳健性,应作为单组率研究稀疏数据Meta分析的首选方法。同时介绍了随机效应模型下GLMM方法的原理及其在不同软件中的实现,为医学研究者提供了实用参考。
尽管FT转换可以保留所有研究而无需对零事件做校正,且在固定效应模型下,大多数情况下的FT转换都可以保持优良的统计性能,这在之前的模拟中也得到了验证[11],但当研究数增大且研究中零事件增多时,FT转换的统计性能不佳;在随机效应模型下,随着研究间方差的增大,FT转换的性能难以满足统计学要求,因此应谨慎使用。无疑,GLMM不需要对零事件进行校正,其优异的统计性能成为单组率研究Meta分析随机效应模型下的首选。但该方法也并非完美无缺,对于较小的样本量、极低的事件发生率和较大的研究间方差,各研究会出现较多的零事件,此时GLMM的点估计会出现偏倚,好在这一问题在极低事件率时并不重要。
事实上,GLMM在很多软件系统中都有设置,例如通过SAS中的PROC NLMIXED过程、R语言的“rma.glmm“函数和STATA的metaprop_one命令等,均不难实现。因此,当面临单组率研究稀疏数据的Meta分析时,不应再受限于软件实现的困难,应首选GLMM方法。
附录
1.采用SAS实现固定效应模型Meta分析的方法
proc nlmixed data=Meta_data df=1e6;
parms p=0.5;
bounds 0 model e~binomial(n,p); estimate "logit(p)" log(p/(1-p)); run; 2.采用SAS实现随机效应模型Meta分析的方法 proc nlmixed data=Meta_data DF=1E6 qpoints=100; parms theta=-4.5 to -0.5 by 0.5 sigmasq=0.3; pi=exp(logodds)/(1+exp(logodds)); model e ~ binomial(n,pi); random logodds ~ normal(theta,sigmasq) subject=study; run; 3.采用R软件实现Meta分析的方法 library("meta") 4.采用STATA软件实现Meta分析的方法 ssc install metaprop_one metaprop_one e n, random logit
猜你喜欢
江西师范大学学报(自然科学版)(2022年4期)2022-10-18
心理学报(2022年10期)2022-10-12
福建农林大学学报(自然科学版)(2022年5期)2022-10-08
中国循证心血管医学杂志(2022年1期)2022-03-15
内蒙古统计(2021年4期)2021-12-06
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
内江师范学院学报(2021年2期)2021-03-03
计算机与网络(2020年13期)2020-07-29
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
