
又见爬虫
2021-03-16 10:05向治霖
南风窗 2021年4期
向治霖

烂尾的新闻很多,本不值得惊奇。年初的拼多多,热点一个赛似一个,但到最后,仍是草草收场了。
这也难怪,现今的社交媒体,称呼围观的人“吃瓜群众”。瓜吃饱了,仅剩一点瓜皮,自然是要扔掉的。具体到拼多多的事件,剩下的这点瓜皮,应是尚未落定的“爬虫”事件。
但这点瓜皮,尚还有味,弃之可惜。
对事件大致复盘:因拼多多一名员工的疑似猝死,“996”受到声讨。众人正酣时,一名拼多多员工自曝,只因为拍了一张救护车开到公司的照片、随后上传网络并配文,他被公司定位找到,接着被“恶意辞退”。
拼多多负责危机处理的部门,保持了一贯水平。此前回应员工的疑似猝死时,拼多多官方账号反问网民,称:“你看底层的人民,哪一个不是用命换钱。”虽然拼多多很快删除,并试图否认这个发言,但被平台网站知乎一把做实,耳光响亮。
轮到“恶意辞退”事件,拼多多官方发文解释,辞退员工并非因为拍照上传,而是公司发现,该员工在社交平台脉脉发表“极端言论”,违反了员工手册。
坏就坏在,脉脉有着匿名功能,且涉事员工发言时均已匿名。拼多多是怎么获取了信息的?
爬 虫
拼多多的应对,犹如一把多米诺骨牌,先拉上了知乎,后推倒了脉脉。
1月10日,脉脉官方连忙澄清,称信息经过了技术加密,“即便是脉脉内部工作人员,也无法获取任何个人相关信息”,意思是说,在脉脉上的发言信息是安全的,不存在泄露问题。
同时,脉脉强调,在遵守法律的前提下,公司不以任何形式向任何第三方提供发帖用户信息。言下之意,否认与拼多多“勾兑”。
但疑问没有解决,拼多多拿到的信息,“白纸黑字”地写在通报上,它是如何实现的?
涉事员工“王太虚”在知乎上的更新,目前截止于1月10日。他发文推测:“公司没有查我手机,而是直接找到了我。初步判断是,(我)被公司对脉脉的爬虫定位到了本人。”
这话有些绕。“王太虚”的推测是,拼多多对脉脉定制了爬虫,爬取了脉脉的数据库信息,再从这些信息中定位到他。
至此,拼多多的一系列风波,终于接近了尾声。渐渐地,没有人再讨论。
爬虫这块“瓜皮”, 吃瓜群众难以下咽,可能的原因是,这瓜有一定的技术门槛。
但理解爬虫并不难。
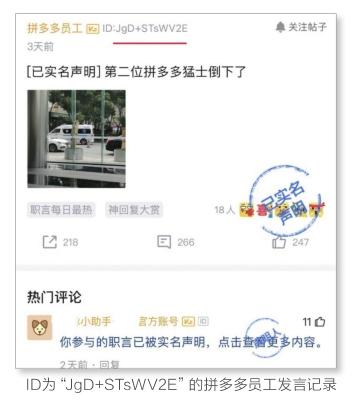
先看拼多多的官方回应,在1月11日的通报中,拼多多列出了涉事员工的“极端言论”。据拼多多罗列,第一条信息是“王太虚”提到的救护车事件,但发言用户为匿名。
拼多多特意用红线,标注出附在用户名后的ID,“ID:JgD+STsWV2E”。
争议也是因此来的,救护车事件的信息,发表于2021年1月7日。但拼多多接着罗列,将该ID的发言继续挖掘,如一条2020年10月22日的言论,提到“希望阿里的物流封杀狠一点,把拼多多的那个XX骨灰都扬了”。
这仍是一条匿名发言,但用户名后的ID,同为“ID:JgD+STsWV2E”,拼多多也用红线标注了出来。
拼多多的追溯不止于此,在通报中,还列出一个表格,其中有四条涉事员工的“极端言论”。发表时间分布于2020年的10月、11月、12月。
如“王太虚”的推测,在技术人员看来非常合理。在通报中,拼多多罗列数据的规律,极符合爬虫的工作原理。这是因为,匿名发表的信息,并不在实名账户的列表中。比如说,同一个账户,发一条实名动态,再发一条匿名动态,则该账户下的动态列表中,只显示实名的那条,否则匿名无意义。
爬虫这块“瓜皮”, 吃瓜群众难以下咽,可能的原因是,这瓜有一定的技术门槛。
这意味着,拼多多得到的信息,本藏身于脈脉庞大数据的角落里。
另一方面,由于唯一的标志物是一串字符,字符藏在字符里,本不容易被发觉(对一般互联网用户)。
那么,爬虫便是一种合理的解释。
环 境
爬虫有两个名字,Google公司的爬虫叫“bot”(机器人),百度公司的爬虫叫“spider”(蜘蛛)。两个名字都很形象,结合起来,爬虫即是指,一种在网络上游走的、自动化操作的程序。
它的用武之地在数据。而在互联网上,数据都有属性和标签,否则数据就是杂乱无章的。前文提到的ID,就是数据的一个属性,且是标识性极强的属性。
如是,理解爬虫的原理就简单了。设计者需要做的,是为爬虫制定规则,爬取特定的属性/标签下的数据。
Python是近年流行的编程语言,以它为例,可以了解爬虫的工作原理:
假设,张三在知乎注册账户,用户名叫“张三”。现在,我们要爬取他的所有动态信息。第一步,我们需要找到的,是张三评论所在的网址(url)。
得到了对应网址,下一步调用模块request.get(),字面意义是:向服务器发起请求、获取该网址的数据。那么,张三评论的所有数据,就都在其中了。
此时,我们想要的评论,依然藏在一堆庞杂的字符中。所以,在接下来,我们需要确定数据的性质,如用户名是张三(name =‘ zhangsan),将这一属性的数据筛选出来。
所谓爬虫的规则,即是经过层层筛选,最终得到目标信息。这还没完。
上述的步骤,只是自动化地获取、筛选了数据,但没有罗列出来。当数据量极大时,一条一条罗列数据,显然并不现实。因此,爬虫的设计者,还要制定一定的规则,将数据按规则打印。如,列出张三的评论内容、评论时间、评论网址……
如此操作完,会自动生成一个数据表格(格式可能不同),爬虫的工作就结束了。在这张表格中,张三评论的所有信息,一望可知。
正因如此,拼多多1月11日的回复中,那张表格尤其可疑。表格中罗列了四条“极端言论”,且信息的属性完整,分别是用户名、ID、内容、时间、网址。更增加了嫌疑的是,“属性”用英文写成:username\ID\comment\time\url,这是符合编程规范的。
对此,拼多多官方没有回应质疑。
但在1月11日,据媒体报道,拼多多相关人员回复,否认信息是通过爬虫获取,并解释道,“是公司多人通过公开的网页浏览,搜索、比对发帖账户ID发现的”。
这一解释并非不可能。但如前文所述,仅凭一串标识字符(ID),人工地浏览海量数据,并且追溯了三个月内的信息,再一个一个列表出来,工作量是庞大的。
当然,不能排除拼多多日以继夜地“996”式搜查,且“公司多人”指的是很多很多很多人。
无论如何,质疑与辩解的双方,都没有拿出证据来。究竟是何种获取方式,现今只能各凭各据。
协 议
鸡毛撒了一地后,有不少网友揶揄,最大的“受害者”是脉脉。这一次事件,暴露了匿名社区的不可靠。如前文所说,无论是爬虫技术,或者是人海战术,都可以破解脉脉的匿名机制。
罪魁祸首在于,ID这一标识性极强的属性,在脉脉的网页中居然“明文显示”—对匿名社区来说,这是不可思议的。
此处的“明文”,对普通用户不成立。这是因为,即使外显了ID,普通用户也无法据此搜索。但对有一定网页设计知识的人来说,只需打开“查看网页源代码”,所有数据都在眼前,而ID就成为可追查的“锚”。
是的,在大多数网站上,用户的行为全被记录下来。对具备一定技术的人来说,用户们都是“透明人”。
是的,在大多数网站上,用户的行为全被记录下来。对具备一定技术的人来说,用户们都是“透明人”。
通俗的解释是,普通用户每一次的点击链接,是一次对服务器的请求(request),而每一次网页的呈现,是服务器对请求作出的回应(response)。这一切对技术人员来说,全部有迹可循。如果有心,通过对请求的分析,就可以获知请求者的身份、设备、IP地址等信息。
不过,人工查找费时费力,在有了爬虫代劳后,性质也就不同了。数据可以批量地、有规则地获取,且过程自动化,所占的不过是存儲而已。
恶意爬虫的存在,显然是对信息/数据安全的威胁。包括脉脉在内,大多数网站上,都设计有“机器人协议”,其中规定了,哪些信息不允许爬取(disallow),哪些信息允许爬取(allow)。
打开脉脉的“机器人协议”,规定不许爬取的内容共18项,其后的允许项目,分别是对“360”和“haosou”公司的爬虫开放。—搜索引擎本身是爬虫,将爬取到的数据存入服务器,以供用户的搜索之用。因此,对搜索引擎开放爬虫协议,是为了获取关注度,这无可非议。
那就是说,在原则上,除了360和haosou,其它爬虫无权爬取脉脉数据。但在现实生活中,这个原则几乎等于不存在。
原因有两方面。一是技术层面,网址虽然拒绝爬虫,但爬虫的设计者可以伪装,将爬虫行为模拟为人类的行为,比如伪造“请求头”(request header),设计访问次数、时间间隔等。
二是法律方面,事实上,“机器人协议”没有强制力。司法实践中,截至目前,没有因违反“机器人协议”而入罪的案例。主流的观点认为,它是一种技术协议,而非法律认可的规范。
也因此,机器人协议被戏称“君子协议”。但很显然,一个行业如果靠道德自律,“君子”是远远不够用的。
猜你喜欢
华人时刊(2023年15期)2023-09-27
学生天地(2020年6期)2020-08-25
快乐语文(2020年17期)2020-07-16
小小说月刊(2018年9期)2018-09-25
小学生作文选刊(2017年23期)2017-02-14
太湖(2015年2期)2015-11-17
火花(2015年1期)2015-02-27
今日中学生(初二版)(2013年11期)2014-01-23
石油工程建设(2011年3期)2011-01-03
