
混沌分析和最小二乘支持向量机的毕业生就业率预测模型
2021-03-17 08:12翟晓鹤
微型电脑应用 2021年2期
翟晓鹤
(新疆医科大学 护理学院, 新疆 乌鲁木齐 830054)
0 引言
随着高校的扩展,学生人数不断增加,毕业生的数量随之增多,大学生就业竞争十分激烈,就业压力越来越大[1-2]。人们对毕业生就业问题十分关注,同时毕业生就业率是高校学生培养质量的一个重要指标,因此高校对毕业生就业率高度重视,这样需要对毕业生就业率进行建模与分析,找到影响毕业生就业率的一些主要因素,从而使高校能够相应的调整学生培养模式,给高校毕业生管理者提供有效的建议,同时为毕业生提供有价值的信息[3]。
对于毕业生就业率预测问题,国内外许多学者都进行了各种尝试研究,最初为线性建模技术,如:基于ARIMA的毕业生就业率预测模型、基于灰色系统的毕业生就业率预测模型,基于决策树的毕业生就业率预测模型[4-6]。它们主要针对小规模、变化简单的毕业生就业率进行预测,当毕业生就业率变化比较复杂时,则就业率预测误差急剧上升;随后出现了一些非线性建模技术,如基于机器学习算法的毕业生就业率预测模型,最具有代表性的为人工神经网络,其具有比较好的非线性建模预测性能,能够从毕业生就业率历史数据中挖掘出毕业生就业率变化特点,预测建模效率要优于线性建模技术[7-8]。由于毕业生就业率具有一定的混沌性,而当前机器学习算法进行毕业生就业率预测建模时,忽略了该特点,使得预测结果并未达到最理想的状态,同时预测精度不太稳定。
以获得更优的毕业生就业率预测结果为目标,提出了混沌分析和最小二乘支持向量机的毕业生就业率预测模型(Chao-LSSVM),该模型根据Takers定理对毕业生就业率历史数据进行混沌分析,采用最小二乘支持向量机拟合毕业生就业率变化特点,为了验证该预测模型的有效性,与当前经典模型进行对比实验,验证了Chao-LSSVM的毕业生就业率预测结果的优越性。
1 混沌分析和最小二乘支持向量机的毕业生就业率预测模型
1.1 混沌分析理论
设毕业生就业率样本数据集合为{xi},i=1,2,…,N,N为样本长度,根据Takers定理[9],一个混沌毕业生就业率样本数据可以重构一个具有等价空间的数据,能够更好地把握毕业生就业率变化规律,等价空间的多维毕业生就业率数据,如式(1)。
X(t)=[x(t),x(t+τ),…,x((m-1)t+τ)]
t=1,2,…,M
(1)
式中,m表示嵌入维;τ表示延迟时间;M表示相空间中的点数,如式(2)。
M=N-(m-1)τ
(2)
从式(2)看出,毕业生就业率历史数据的混沌分析主要是确定嵌入维、延迟时间,把毕业生就业率历史数据中把蕴藏的信息充分地挖掘出来,通过相空间重构技术恢复毕业生就业率的混沌特性,本文分别采用饱和关联维数法确定最优的嵌入维,自相关函数法确定最优的延迟时间。
1.2 最小二乘支持向量机
由于人工神经网络经常出现一些预测结果偏差比较大的点,即出现所谓的过拟合缺陷,为了改善毕业生就业率预测结果,本文引入最小二乘支持向量机对相空间重构后的毕业生就业率数据进行建模,这是因为最小二乘支持向量机不仅不存在人工神经网络的过拟合缺陷,建模预测性能十分优异,而且其建模效率更高。对于训练样本集合,在支持向量机的基础上,最小二乘支持向量引入如下的约束条件,如式(3)。
yk[ωTφ(xk)+b]=1-ek
(3)
对如式(3)的问题,最小二乘支持向量机通过下式进行求解,如式(4)、式(5)。
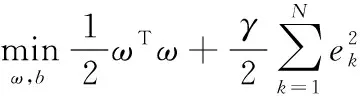
(4)

(5)
式中,γ表示正则化参数[10]。
定义拉格朗日方程,如式(6)。
(6)
式中,αk表示拉格朗日乘子。
根据如下KKT条件,得到αk和b的值,如式(7)—式(10)。

(7)

(8)

(9)
(10)
引入核函数解决非线性回归问题,即:K(x,xi)=φ(x)Tφ(x),最小二乘支持向量机回归的决策形式,如式(11)。

(11)
选择RBF核函数,如式(12)。

(12)
式中,σ2表示核函数参数。
1.3 混沌分析和最小二乘支持向量机的毕业生就业率预测步骤
(1) 收集若干年的毕业生就业率历史样本数据,根据时间先后进行排序,建立一维样本集合,并对样本数据做如下归一化处理,如式(13)。

(13)
(2) 确定一维的毕业生就业率样本集合的嵌入维和时间延迟,根据嵌入维和时间延迟进行相空间重构,这样会产生一个多维的毕业生就业率数据,该数据空间变化轨迹与原始毕业生就业率数据变化轨迹相近。
(3) 初始化最小二乘支持向量机的相关参数,如正则化参数,核函数参数。
(4) 采用最小二乘支持向量机对相空间重构后的多维毕业生就业率数据进行学习,并采用10折交叉验证法确定预测精度最高的最小二乘支持向量机建立毕业生就业率预测模型。
综合上述可知,混沌分析和最小二乘支持向量机的毕业生就业率预测流程,如图1所示。

图1 混沌分析和最小二乘支持向量机的毕业生就业率预测流程
2 仿真测试析
2.1 仿真测试环境设置
为了全面分析混沌分析和最小二乘支持向量机的毕业生就业率预测效果,在相同的仿真测试环境下,选择当前经典的毕业生就业率预测模型进行对比测试,经典模型具体为:(1) 基于ARIMA的毕业生就业率预测模型(ARIMA);(2) 灰色系统的毕业生就业率预测模型(GM);(3) BP神经网络的毕业生就业率预测模型(BPNN);(4) 没有混沌分析的最小二乘支持向量机的毕业生就业率预测模型(LSSVM)。所有模型的测试环境,如表1所示。

表1 所有模型的测试环境设置
2.2 仿真测试的数据
选择10所学校的毕业生就业率作为实验对象,每所学校毕业生就业率历史数据,如表2所示。
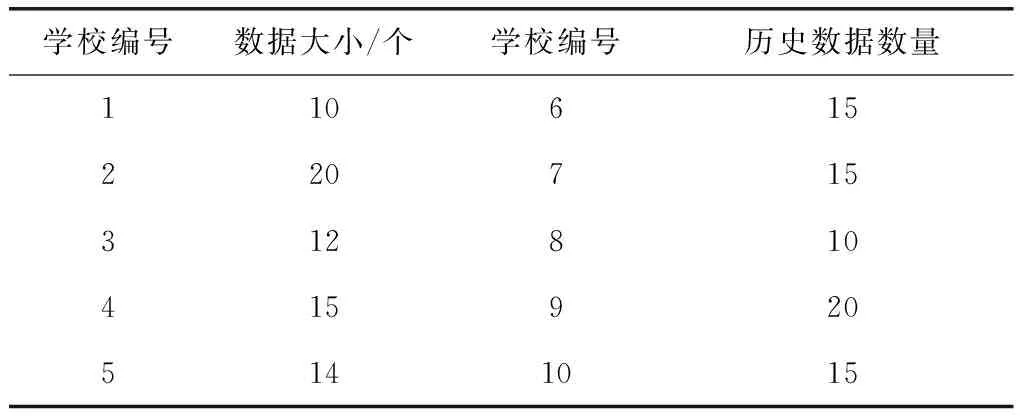
表2 仿真测试的数据
2.3 混沌分析结果
对表2的仿真测试的数据进行混沌分析,确定每一所学校的毕业生就业率数据的嵌入维数和延迟时间,如表3所示。
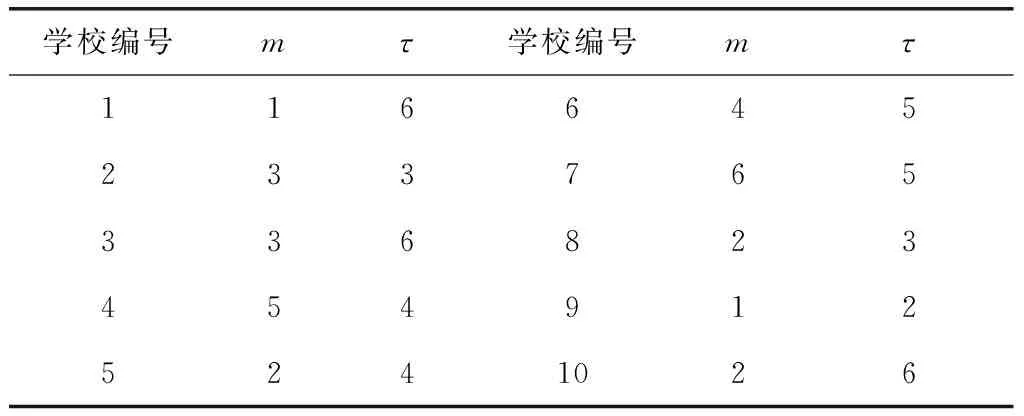
表3 嵌入维和时间延迟的确定
从表3可以看出,不同学校的毕业生就业率数据,它们的混沌特性是不一样的,得到嵌入维数和延迟时间有一定的差别,根据嵌入维数和延迟时间对表2的毕业生就业率数据进行相空间重构,得到毕业生就业率预测学习样本集合。
2.4 毕业生就业率预测精度对比
ARIMA、GM、BPNN、LSSVM的毕业生就业率预测精度的平均值,如图2所示。

图2 毕业生就业率预测精度对比
对图2的实验结果进行对比和分析。
(1) ARIMA、GM的毕业生就业率预测精度低于85%,这是由于ARIMA、GM属于线性建模技术,只能描述毕业生就业率的线性变化规律,而对随机性变化规律无法进行有效描述,使得ARIMA、GM的毕业生就业率预测误差高于15%,超过了毕业生就业率预测的实际应用区间,无法应用于毕业生就业管理中,建模结果没有什么实际意义。
(2) BPNN、LSSVM的毕业生就业率预测精度要高于ARIMA、GM的毕业生就业率预测精度,因为它们属于非线性建模技术,可以描述毕业生就业率的随机性变化规律,但是由于没有考虑到毕业生就业率的混沌特性,使得毕业生就业率预测精度没有超过90%,说明BPNN、LSSVM的毕业生就业率结果不理想。
(3) Chao-LSSVM的毕业生就业率预测精度高于ARIMA、GM、BPNN、LSSVM,预测精度平均值超过93%,大幅度减少了毕业生就业率预测误差,这是因为其结合了混沌分析和最小二乘支持向量机的优点,可以对毕业生就业率变化规律进行精确建模,获得了理想的预测结果。
2.5 毕业生就业率预测模型的执行效率对比
随着高校毕业生人数不断增加,执行效率也成了评价毕业生就业率预测模型的一个重要指标,采用平均建模时间(秒,s)描述毕业生就业率预测模型的执行效率,如图3所示。
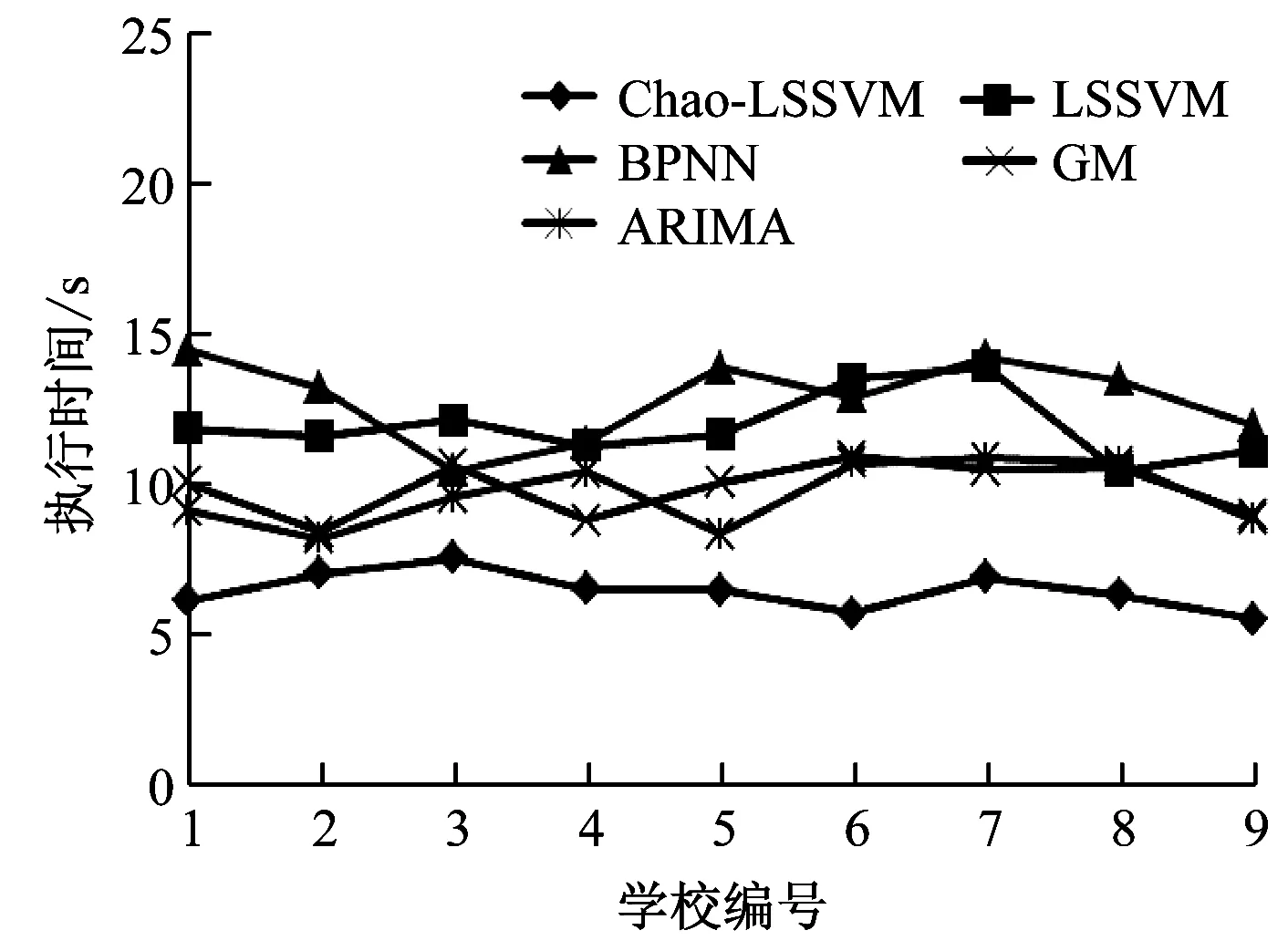
图3 毕业生就业率预模型的建模时间对比
从图3的平均建模时间可以知道,Chao-LSSVM的毕业生就业率预测模型的执行时间要明显少于ARIMA、GM、BPNN、LSSVM的执行时间,这是因为Chao-LSSVM的建模速度更快,提升了毕业生就业率预测建模效率,实际应用价值更高。
3 总结
毕业生就业率预测是当前高校关注的一个重要问题,结合毕业生就业率的变化特点,设计了混沌分析和最小二乘支持向量机的毕业生就业率预测模型,并通过与当前经典毕业生就业率预测模型的对比实验可以得到如下结论。
(1) 通过引入相空间重构将原始毕业生就业率历史数据映射到多维空间,更好的挖掘了毕业生就业率历史数据隐含的变化规律,有助于后续的毕业生就业率预测模型的构建。
(2) 利用最小二乘支持向量机的自适应学习能力,对混沌分析后的毕业生就业率历史数据进行训练,可以更好地拟合毕业生就业率变化特点,获得了较优的毕业生就业率预测结果。
(3) 与经典毕业生就业率预测模型相比,混沌分析和最小二乘支持向量机的毕业生就业率预测精度得到了明显的改善,同时毕业生就业率预测效率也得到了有效的提升,预测结果可以为高校就业管理人员提供有意义的参考信息。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
浙江大学学报(理学版)(2019年6期)2019-12-19
发明与创新·职业教育(2018年6期)2018-05-14
浙江大学学报(理学版)(2016年1期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
新闻前哨(2014年11期)2014-12-25
职业技术教育(2014年9期)2014-07-08
中山大学学报(自然科学版)(中英文)(2014年4期)2014-03-27
