
针对心血管疾病预测的改进算法模型
2021-04-23 05:50刘纪敏张楷第文龙日贾全秋谢创森
软件导刊 2021年4期
刘纪敏,张楷第,文龙日,贾全秋,谢创森,王 菲
(1.山东科技大学智能装备学院,山东泰安 271000;2.山东科技大学计算机科学与工程学院,山东青岛 266000;3.泰山科技学院大数据学院,山东泰安 271000)
0 引言
随着高科技的发展以及个人健康管理需求的不断增加,人类进入了长寿时代,但高危疾病导致的突然死亡给很多家庭带来巨大的痛苦。据统计,山东省居民主要死亡原因中排名前三位的疾病分别为心血管疾病、恶性肿瘤和脑血管疾病。从年龄组来看,不同年龄组死因排序有所不同,14 岁以下儿童及青少年组排名前三位的死因分别为伤害、恶性肿瘤和先天异常,占该年龄组死亡人数的74.28%;15-44 岁青壮年组排名前三位的死因分别为伤害、恶性肿瘤和心血管病,占75.97%;45 岁以上中老年人组排名前三位的死因分别为心血管疾病、恶性肿瘤和脑血管疾病,占88.07%。通过分析,心血管疾病(Cardiovascular Disease,CD)导致的死亡率达到20%[1]。因心血管疾病与日常饮食习惯、运动习惯有着密切关联,所以早期发现发病影响因素并进行预防与治疗对降低疾病发病率具有重要意义。虽然现代医学技术发展迅速,但是针对高危疾病发病可能性预测与预防方面的技术仍然比较薄弱,缺乏标准的预测模型以及有效的疾病预测服务。
近年来,通过整合信息通信技术(Information and Communication Technology,ICT)与医学技术预测疾病发病率并提高预测结果的精准度成为疾病预测领域研究的焦点。如Jabbar 等[2]提出结合K-最近邻算法(K-Nearest Neighbor,KNN)与遗传算法的分类算法提高心血管疾病诊断精准性;Mohan 等[3]对近年来心脏病预测相关研究内容进行了汇总;Choudhary 等[4]使用数据挖掘算法、决策树、朴素贝叶斯、神经网络、关联分类和遗传算法从数据集中预测与分析心脏病。研究人员在一个数据集上进行了一项实验,使用神经网络和混合智能技术建立一个模型,结果表明,混合智能技术可提高预测精度。Sharma 等[5]在心脏病数据仓库中使用K-均值聚类算法提取与心脏病相关数据,并应用MAFIA(Maximal Frequency Item Set Algorithm)算法计算对心脏病发作预测有重要意义的频繁模式权重;Fadini等[6]将年龄、血压、血管造影报告等13 个变量输入神经网络模型中以预测心脏病发病率,并证明了该模型的可行性;Yan 等[7]提出利用神经网络和遗传算法预测疾病的模型,并通过实验证明了该模型可提高疾病预测精准度;Guru 等[8]提出在确定疾病影响因素的前提下,利用神经网络、反向传播算法进行疾病预测的模型。
研究发现,虽然这些疾病预测模型在一定前提条件下达到了疾病预测的目的,但数据特征和维度过多等原因影响了预测模型的时效性和精准度。研究人员大多注重提升疾病预测的正确率,而忽略了疾病预测的时效性,但时效性在临床诊断中是极为重要的因素。过多的数据特征和维度在数据处理过程中会增加预测模型的结构复杂度及模型训练时间复杂度,导致训练出的模型在预测疾病时的时效性不强。
因此,在保证预测准确率的前提下,为提高疾病预测时效性,本文首先提出基于国家标准查体报告与心血管疾病影响因素的标准化心血管疾病影响因素提取方法,以提高采集医疗数据的标准性和通用性;其次,提出基于随机森林与Relief 算法的疾病影响因素特征选择方法,以降低疾病预测模型的结构复杂度、提高时效性,并提出基于误差反向传播网络的心血管疾病预测模型,以提高心血管疾病预测精准度;最后,对传统预测模型与改进模型的实验结果进行比较分析,证明了改进模型的优越性。
1 疾病预测相关技术研究
目前国内医疗机构的医疗数据管理系统,如Hospital-InformationSystem(HIS)、Electronic Medical Record(EMR)等并未实现规范化与标准化。为解决这一问题,本文结合国家标准查体数据模型与山东省解放军第九六〇医院查体中心个人查体报告模型建立规范化、标准化的心血管疾病样本数据模型。在心血管疾病发病影响因素特征选择中,利用随机森林和Relief 算法以更准确地选取影响因素。在心血管疾病预测方面,利用神经网络(Artificial Neural Networks,ANN)和误差反向传播(Back Propagation,BP)神经网络模型对心血管疾病的发病可能性进行研究。
1.1 个人查体标准数据模型
本文利用国家标准查体数据模型提出个人查体报告书,并基于该报告书建立心血管疾病发病相关因素标准化数据模型。根据个人查体报告书导出心血管疾病相关特征数据如表1 所示。
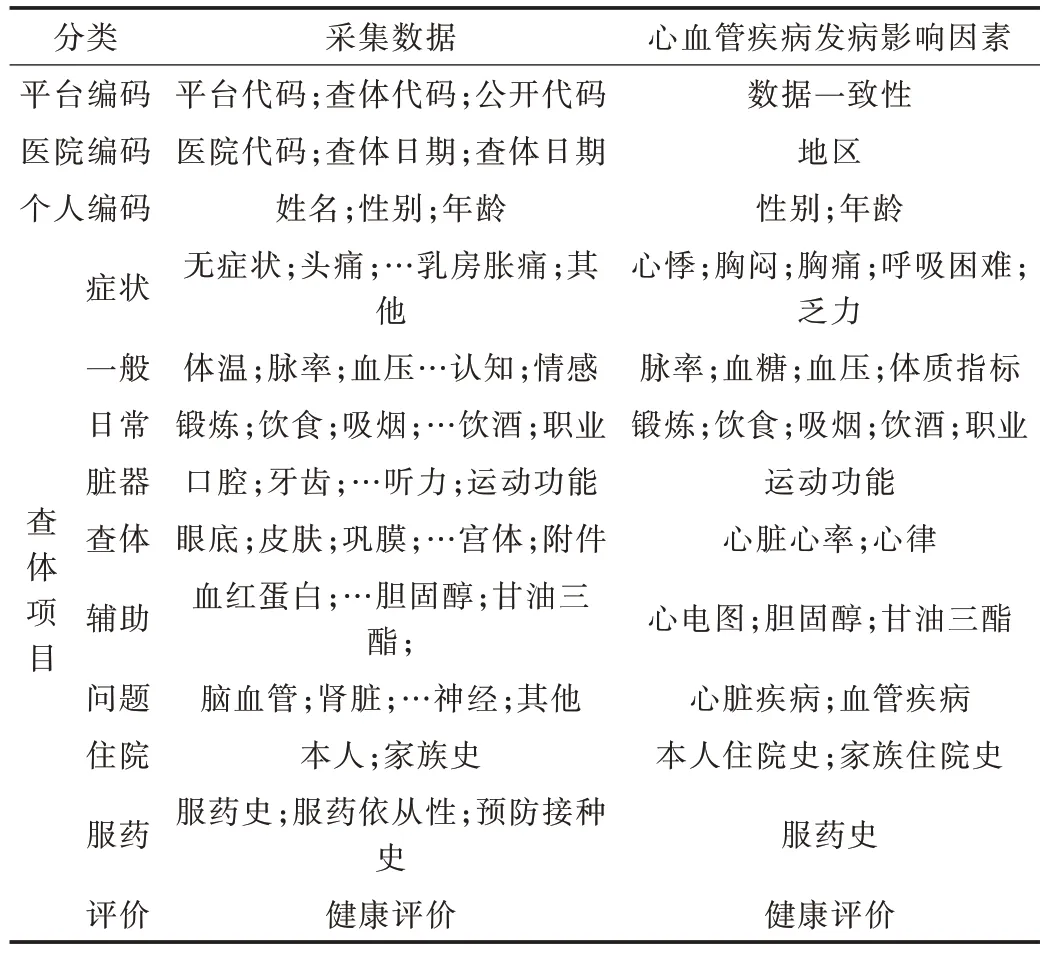
Table 1 The characteristic data related to cardiovascular diseases表1 心血管疾病相关特征数据
1.2 特征选择方法
在心血管疾病发病影响因素较多的前提下,有必要在查体数据预处理特征集合中选择有效特征以决定发病影响因素权重。特征选择是从经过预处理的特征集合中选择有效特征,以降低数据维度、减少计算量。常见的特征选择方法包括方差过滤、相关系数、递归特征消除、模型选择等,本文采用随机森林与Relief 相结合的算法进行发病影响因素特征选择。
随机森林由多个决策树构成,决策树中每一个节点都是关于某个特征的条件,从而将数据集按照不同响应变量一分为二,利用不纯度可以确定节点(最优条件)。当训练决策树时,可计算出每个特征减少了多少树的不纯度。对于一个决策树森林而言,可计算出每个特征平均减少了多少不纯度,并把平均减少的不纯度作为特征选择值。随机森林具有准确率高、易于使用等优点[9-11]。
Relief 算法的基本思路为从训练集D 中随机选择一个样本R,然后从与R 同类的样本中寻找k 点的最近邻样本H,并从与R 不同类的样本中寻找k 最近邻样本M,最后按照公式更新特征权重,通过筛选属性值达到降维的目的。为解决随机森林求权重过程中存在的会将权重大的属性赋予低权重值的问题,引入Relief 算法。Relief 算法可筛掉中、低影响度的属性,而不会影响中、高影响度的属性,从而避免在随机森林中将影响度高的医疗属性筛掉。但Relief 对中、低影响度的属性区分不明显,仅对高影响度的属性区分明显,因此选取随机森林中权重值高的属性加以保留[12-14]。
1.3 疾病预测模型
本文用于预测心血管疾病的医疗数据集是从UCI 的机器存储库中获得的,为部分人的体检数据,共包含2 121 例样本,其中包括13 条医疗属性以及1 条标签属性。13 条医疗属性分别为:年龄、性别、胸部疼痛类型、静息血压、胆固醇、空腹血糖>120mg/dl、静息心电图测量、最高心跳率、运动诱发心绞痛、运动相对于休息引起的ST 抑制、运动ST 段的峰值斜率、主要血管数目、血液疾病。
常用于研究疾病在群体中产生与发展趋势的预测模型有回归预测模型、时间序列预测模型、马尔科夫预测模型、灰色系统预测模型等。由于BP 神经网络具有学习能力,能够优化学习进度,在信号正向传播过程中,输入层将数据传送给隐层,隐层将信息传送给输出层,若输出的信息不正确,则将输出结果转化为输入数据再反馈给隐层并重新输入。在反向传递时,根据整体误差不断修正各个连接权值和阈值,使得最终整体误差最小,或达到预设精度后再进行预测[15-17]。
2 心血管疾病预测模型
2.1 改进的特征选择方法
特征选择是指从经过预处理的特征集合中选择有效特征,在降低数据维度的同时,能够减少计算量。但随机森林的特征选择虽然在特征变量特别多的数据集中表现良好,但在具有较少属性值的医疗数据分析中效果不佳,其会对各种属性赋予不等同于其重要性的权值,因此单纯使用随机森林会导致重要属性被忽略。为此,本文引入Relief 算法,虽然Relief 算法对于中、低影响度的属性区分不明显,但对于高影响度的属性区分明显。两种算法的结合使得随机森林避免了重要属性的缺失,也弥补了Relief算法无法区分中、低影响度属性的缺点,从而在保证重要属性不丢失的情况下,对各种属性按其重要程度赋予权值。
2.2 改进的发病预测模型
2.2.1 属性指标定义
实验中所使用的心血管疾病相关属性信息如表2 所示。

Table 2 Cardiovascular disease related attributes表2 心血管疾病相关属性
属性指标中存在如性别、胸部疼痛类型、空腹血糖、静息心电图测量、运动ST 段峰值斜率等文本型指标需进行文本转换,对于二值类数据,例如在性别特征中,包含男性和女性两种取值,可将女性映射为0,男性映射为1。在空腹血糖指标中,当空腹血糖大于120mg/dl 时,将其映射为0;当空腹血糖小于120mg/dl 时,将其映射为1。同理,在运动性心绞痛属性中,当属性值为真时,将其映射为0,反之映射成1。对于多值型属性,如在胸部疼痛类型的数据特征中,可根据疼痛由重到轻,将典型心绞痛映射为0,非典型心绞痛映射为1,非心绞痛疼痛映射为2,无临床症状映射为3。同理,在静息心电图测量、ST 段坡度值以及地中海贫血严重程度属性中,将其映射成0~3,文本属性数据化后的处理结果如表3 所示。
2.2.2 数据归一化处理
数据集中不同属性值的数量级与物理含义往往不一致,为加快训练速度,在训练样本进入训练模型之前,往往需要对训练数据进行归一化处理,使不同类型的属性值均在同一数量级,以对各属性值进行综合对比评价。由于每个特征属性之间具有不同量纲,针对连续变化的数值型数据,需要对其进行数值归一化处理,以消除不同量纲对各属性综合性能的影响。目前,常见的归一化方法有最大最小值归一化、零均值归一化等,本文采用标准差标准化(Standard Scale)方法,使得处理后的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为。其中,μ为所有样本数据均值,σ为所有样本数据标准差。与最大最小值归一化、零均值归一化不同,标准差标准化方法是针对每一个特征维度进行的,而不是针对样本。处理结果如表4 所示。

Table 3 The results processed after the datamation of text attributes表3 文本属性数据化后处理结果

Table 4 Results after normalization of index data表4 指标数据归一化后结果
2.2.3 特征选取
在大数据时代,海量的结构化与非结构化数据为医疗数据处理增加了一定难度,过多的数据特征和维度在数据处理中会增加BP 数据网络的结构复杂度,也会加大模型训练的时间复杂度,使训练出的模型无法为心血管疾病提供更准确的预测。要通过较少的指标属性达到理想的预测精度,可运用属性降维算法来实现。从众多医疗指标中选择与心血管疾病相关性较强的一些指标,同时过滤掉不相关及冗余指标。分别采用随机森林以及Relief F 求各个医疗属性的权重及其排序,结果如表5 所示。

Table 5 The weights of medical attributes and their order表5 医疗属性权重及其排序
随机森林基于不纯度的排序结果非常鲜明,除得分最高的几个特征外,其余特征得分急剧下降。从表中可以看到,得分第5 的特征权重值比得分第1 的特征权重值小一倍,而其他特征选择算法下降没有这么剧烈。随机森林是一种非常流行的特征选择方法,其易于使用,一般不需要特征工程、调参等繁琐的步骤。但是利用随机森林求权重存在两个缺陷,一是重要特征有可能得分很低,二是这种方法对特征变量类别越多的特征越有利[17]。因此,仅使用随机森林进行特征选择会将重要的医疗属性赋予低权重值,导致重要的医疗属性被筛掉,从而影响对疾病的预测,大大降低了预测精度[18]。为克服随机森林的缺陷,引入Relief F 算法可筛掉中、低影响度的属性,而不会影响中、高影响度的属性。由于在随机森林训练中会将权重大的属性赋予低权重值,而Relief F 对中低影响度的属性区分不明显,对高影响度的属性区分明显,因此保留随机森林中权重值靠前的属性,分别是cp、thalach、thal、oldpeak、age、trestlops,再取在Relief F 算法中权重排名前5 的属性,分别是sex、restecg、thal、exang、ca。由Relief F 算法训练结果可发现,sex 及restecg 属性被赋予了较高权重值,而这两个属性在随机森林训练中则被赋予了较低属性值,因此保留sex与restecg 属性。最终保留的属性为:cp、sex、thalach、restecg、thal、oldpeak、exang、age、ca、restbps。
2.2.4 神经网络层数
由于三层神经网络结构简单、易于实现,因此疾病预测系统选择三层结构进行相关测试,网络中层数都被设定为1。
2.2.5 输入层与输出层节点数确定
本文采用神经网络技术,首先要确定各神经网单元数。神经网络输入节点就是心脏病预测时的相关指标数据,本文所选数据通过特征选择算法之后确定了10 个特征属性。所以,确定输入层节点数为10,输出层节点数为1。
2.2.6 隐层神经单元数
隐层单元数选择是一个十分复杂的问题,也是神经网络研究的热点问题之一。隐层节点数的确定与问题要求、输入输出单元数量及输入输出单元分布都有直接关系。节点数太多会增加训练时间,其中隐层神经单元数可自行设定。一般而言,问题越复杂,需要的隐层单元数越多,隐层单元数越多,则越容易收敛,但隐层单元过多会增加计算量[19]。本文根据如下规则确定隐层神经元数目:隐层神经元数目大于输入层神经元与输出层神经元数目总和的一半,小于输入层神经元与输出层神经元数目总和[20]。对于不同的隐层,网络识别率也不同。因此,统计出不同隐层神经元个数对应的网络识别正确率,如图1 所示。
2.2.7 学习率M
较高的学习率会导致网络误差较大,或呈现不规则离散状态,学习率过低会降低网络训练效率,但能保证收敛于某个极小区间。因此,为使训练过程收敛速度快且较稳定,通常在0.08~0.1 区间取值[21-22]。经反复多次验证后,将识别率高的平均值筛选出来。通过研究得出结论,当起始学习率取0.08 时,网络所用时间越少,收敛速度越快。因此,网络模型将原始识别率设置为0.08,如图2 所示。

Fig.1 Correct rate of BP neural network with different number of hidden layer neurons图1 不同隐层神经元个数对应的BP 神经网络正确率

Fig.2 Training time at different learning rates图2 不同学习率下的训练时间
3 预测模型实验结果分析
在输出部分,BP 神经网络的训练函数trainscg 值域一般区间为[-1,1],由于本文样本数据的特殊性,都是0 和1,所以对于输出的数据,将输出值大于等于0.6 的数据赋值为1,将输出值小于0.6 的数据赋值为0。在正确率计算部分,将训练样本与测试样本的每一位逐一进行比较,若一致即视为正确,若不一致则视为错误。
本文将经过特征选择筛选后的属性带入BP 模型预测结果,并与直接使用BP 神经网络算法进行预测的结果相比较。改进后的模型运行速度得到了有效提升,大大缩短了运行时间,提高了时效性。两个模型运算时间对比如图3所示。
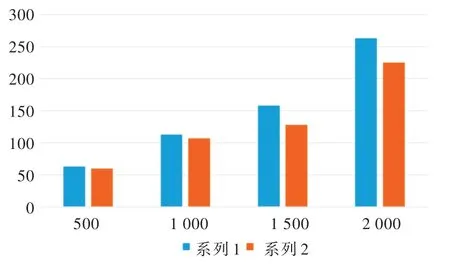
Fig.3 Comparison between operation time of the two models图3 两个模型运算时间对比
在图3 中,分别采用500、1 000、1 500 以及2 000 个例子作比较,系列一为直接使用BP 神经网络进行心血管疾病预测所耗费的时间,系列二为采用与特征选择相结合的BP神经网络进行心血管疾病预测所耗费的时间。通过对比发现,采用与特征选择相结合的BP 神经网络模型可以大大提升预测速率,从而增强了数据从上传到诊断的时效性,加快了诊断速率。
为防止过于追求时效性而忽略准确性的情况发生,图4、图5 分别为采用经过特征选择的BP 神经网络与没有经过特征选择的BP 神经网络预测心血管疾病的混淆矩阵。
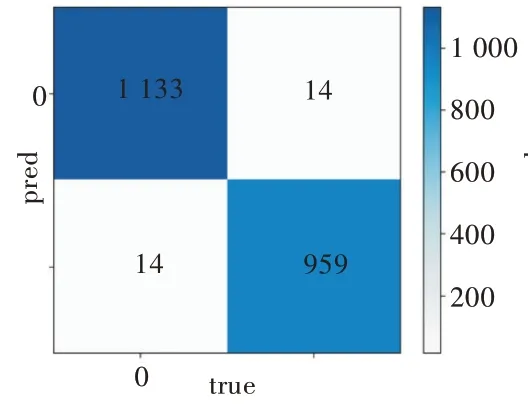
Fig.4 Confusion matrix without feature selection图4 没有经过特征选择的混淆矩阵
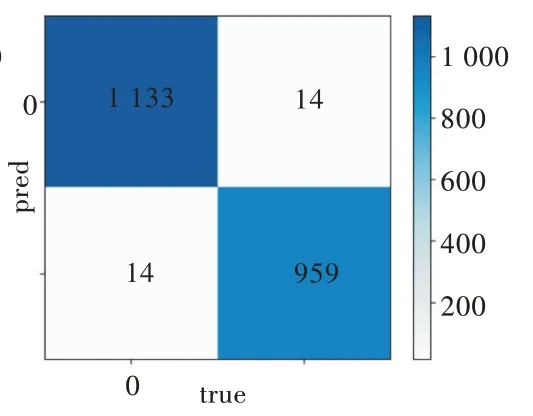
Fig.5 Confusion matrix selected by feature selection图5 经过特征选择的混淆矩阵
在图4 与图5 中,混淆矩阵是对分类结果的矩阵表示。左上方单元格表示当样本实际为真时被分类为真的样本数(即真实阳性),右下方单元格表示当样本实际为假时被分类为假的样本数。其他两个单元(左下方单元格和右上方单元格)表示错误分类的样本数。具体来说,左下方单元格表示样本实际为真(即假阴性)时分类为假的样本数,右上方单元格表示实际为假(即假阳性)时被分类为真的样本数。一旦构建了混淆矩阵,即可轻松计算出分类精度、灵敏度和特异性。分类精度=(TP+TN)/(TP+FP+TN+FN);灵敏度=TP/(TP+FN);特异性=TN/(TN+FP)。其中,TP、TN、FP 和FN 分别表示真阳性、真阴性、假阳性和假阴性。每个模型是根据分类精度、灵敏度以及特异性进行评估的。对于每种算法,发现没有经过特征选择的BP 神经网络分类精度为98.68%,灵敏度为98.78%,特异性为98.56%。经过特征选择的BP 神经网络分类精度为98.68%,灵敏度为98.78%,特异性为98.56%。
通过分析可以得到,经过特征选择后的BP 神经网络可在保持准确率的同时,极大地提高时效性。
4 结语
本文应用基于随机森林与Relief 的特征选择方法对心血管疾病属性进行权重排序,筛选出权重高的医疗属性,应用BP 神经网络算法对心血管疾病数据进行预测并得到最终的患病结果,根据分类精度、灵敏度、特异性进行评估。研究结果表明,经过特征选择后的BP 神经网络能够在不影响预测准确率的同时,得到更好的时效性,能准确、有效地预测心血管疾病。此外,目前的文献提出的模型用于预测心血管事件的风险,但大多数都没有经过临床验证来比较其预测效果,所以该模型目前对临床疾病预测方面的价值尚不可知,更不用说在实践中加以应用。在大数据时代应该关注现有心血管风险模型在临床中是否可以保证预测效果,最后对最有前途的临床预测模型进行量化。
猜你喜欢
心血管病防治知识(2022年23期)2022-11-10
现代临床医学(2022年3期)2022-06-06
人民珠江(2019年4期)2019-04-20
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
医学研究杂志(2015年8期)2015-06-22
医学研究杂志(2015年11期)2015-06-10
计算机工程(2014年9期)2014-06-06
机械工程与自动化(2014年3期)2014-05-07
振动工程学报(2014年4期)2014-03-01
