
基于语句分类模型的《红楼梦》作者探析
2021-04-23 05:50秦贵秋顾长贵
软件导刊 2021年4期
秦贵秋,顾长贵
(上海理工大学管理学院,上海 200093)
0 引言
古往今来存在许多作者存疑的文化巨著,比如:英国著名的戏剧文学《亨利八世》被称为莎士比亚的最后遗作,但它的实际作者却可能不止一位[1];明清代表性小说《红楼梦》,同样存在作者存疑,有人认为前80 章和后40 章不是同一人所写[2]。本文采用文本卷积神经网络(Text Convolutional Neural Networks,TextCNN)+长短期记忆网络(Long Short-term Memory,LSTM)的改进型语句分类模型确定《红楼梦》前后章回的写作风格和文体特征是否存在明显差异。
1 相关研究
以往对《红楼梦》作者问题的研究都是基于统计学理论方法研究的。例如,2015 年,肖天久等[3]在《〈红楼梦〉词和N 元文法分析》一文中,利用虚词、词及词类构建的N 元文法模型、实词以及词长进行聚类,并计算相似度,结果发现《红楼梦》前80 回与后40 回不为同一人所写;2018 年,马创新等[4]在《从高频词等级相关角度探析〈红楼梦〉作者》中,将语料中的词型均按照出现频次递减排列并确定等级,然后计算出各语料之间等级的相关度,以推断各语料的语言风格相似度,发现《红楼梦》的作者不是同一个人;2019 年,陈城钰等[5]利用《红楼梦》文本中虚词的频率构建一元线性回归模型,通过判断前80 回与后40 回虚词频率之间的差异,判断《红楼梦》的作者不为同一人;同年,王晔等[6]在《红楼梦》中选取10 个特征汉字分别统计在前80 回与后40 回出现的频次构建特征向量,利用层次聚类模型和支持向量机方法,最终证明前80 回与后40 回作者不同;2011 年,施建军[7]利用机器学习中的支持向量机技术,在《红楼梦》中选取了44 个虚词并将虚词的频率作为特征向量,训练支持向量机,最终对《红楼梦》的120 回作分类,发现前80 回与后40 回存在明显差异,因此认为《红楼梦》为两人撰写;2016 年,叶雷[8]利用字典字项构建矢量特征空间,用无督导的聚类方法方法对《红楼梦》各章回的著作权进行分析,结果表明,后40 回和第67 回与其余的章回有明显不同,因此后40 回和第67 回可能不是原作者所写;2018 年,王阳阳[9]利用朴素贝叶斯和BP 神经网络分类法分析了《红楼梦》的文本特征,发现《红楼梦》前80 回与后40 回文本特征存在显著差异,得出《红楼梦》不为一人所作的结论;同年,周靖[10]在《红楼梦》中选取100 个高频词汇作为文本风格的词特征,分别利用机器学习的Bagging、Adaboost、Rotation Forest 对《红楼梦》作者问题进行分类研究,最终发现《红楼梦》不为同一人所著。
上述对《红楼梦》作者的研究方法均为传统统计学方法,统计学方法需要手动提取出有用的表示(手动特征工程),例如选择虚词频率、句类特征、语言风格“数量化”等。手动特征工程是一种传统的特征工程方法,它主要利用领域知识构建特征,一次只能产生一个特征,是一个繁琐、片面、费时又易出错的过程。而深度学习采用的是自动化特征工程,这也是它发展如此迅速的原因。自动化特征工程可以一次性学习所有特征,而无需自己手动设计。将深度学习方法应用在语句分类上,使得语句分类任务变得更加简单,准确率也不断提升。本文采用Kim[11]提出的TextCNN 语句分类模型与Minar 等[12]在其综述提到的LSTM 相结合的方法对《红楼梦》作者问题进行探讨,有效解决传统方法人为特征提取片面、繁琐等不足,提高验证和测试准确率,使研究结果更可靠。
2 语句分类模型
2.1 Word2vec
基于深度学习的语句分类模型不会接受原始文本作为输入,它只能处理数值张量。文本向量化就是将文本转换为数值张量以便于模型对文本的识别。文本向量化首先将文本分解成单元(单词,字符),单元也称之为标记,其次将数值向量与生成的标记相关联。关联方法有多种,如对标记进行one-hot 编码、标记嵌入(词嵌入)。本文采用Word2vec 词嵌入法[13-14]。Word2vec 是从原始语料中学习字词空间向量的预测模型,它有两种实现模式:CBOW 和Skip-Gram,其中CBOW 是从原始语句中推测出目标词;而Skip-Gram 相反,从目标字词推测出原始语句,两者都是简单的神经网络模型,具有一个隐藏层。实验中所使用的词向量是采用Skip-Gram 模型训而练成,如图1 所示,图中V表示原始语句中有V 个唯一单词,N 表示每个单词用N 个特征表示,Skip-Gram 的输入层是原始语句中唯一单词的one-hot 码,输出层为Softmax 层,通过反向梯度传播更新隐藏层权重,最终得到词向量就是隐藏层的权重。
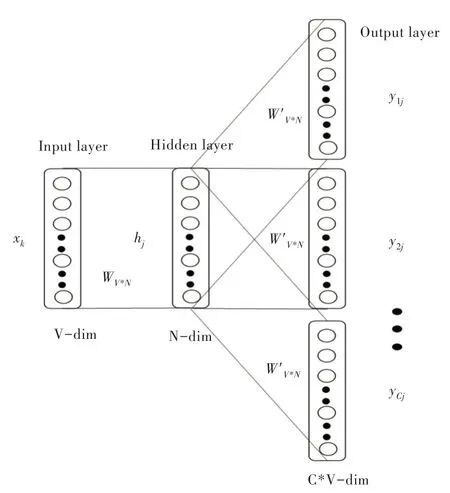
Fig.1 Model of Skip-Gram图1 Skip-Gram 模型
2.2 TextCNN 语句分类模型
Kim 的TextCNN 语句分类模型如图2 所示。令xi∈Rk代表句子中第i个单词所对应的k维词向量,一个长度为n的句子(不足的可以填充)可以表示为如式(1)所示。
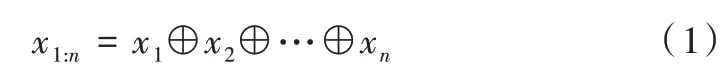
式中,⊕为拼接算子,通常让xi:i+j表示为单词xi,xi+1,…,xi+j的拼接。卷积运算将卷积核w∈Rhk应用到h个单词组成的特征向量窗口产生一个新的特征。例如,特征ci是由h个单词(xi:i+h-1)组成的特征向量窗口,通过式(2)生成,如式(2)所示。
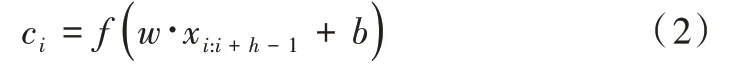
式中,b∈R是一个偏置项,f为非线性函数。将卷积核应用到句子每个可能的单词特征向量窗口中生成一个特征向量图c∈Rn-h+1,如式(3)所示。
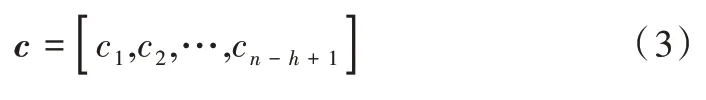
然后对得到的特征图使用最大池化操作,得到该特定卷积核对应的特征最大值cˆ=max{ }c,其思想就是获取特征图中最重要的特征——最大特征值。
上述已经描述了从一个卷积核中提取一个特征的过程。该模型使用多个卷积核(卷积核大小各异)来获取多个特征。这些特征经过最大池化后连接组合形成图2 中倒数第二层,之后这些最大特征组合输入到全连接的Softmax 层,最终输出一组标签的概率分布。
为了正则化,在倒数第二层采用权重向量l2范数约束的Dropout[15]。Dropout 用来防止模型过拟合,通过在前后向传播期间随机删除(即设置为零)p% 的隐藏单元。因此,假设倒数第二层输出为z=(使用了m个过滤器),对于输出单元y而言,不采用Dropout,输出y 如式(4)所示。

采用Dropout,输出y如式(5)所示。

式中,∘是逐元素乘法运算符,且r∈Rm是一个概率p为1 的伯努利随机变量的掩码向量。梯度反向传播时不经过掩码单元。
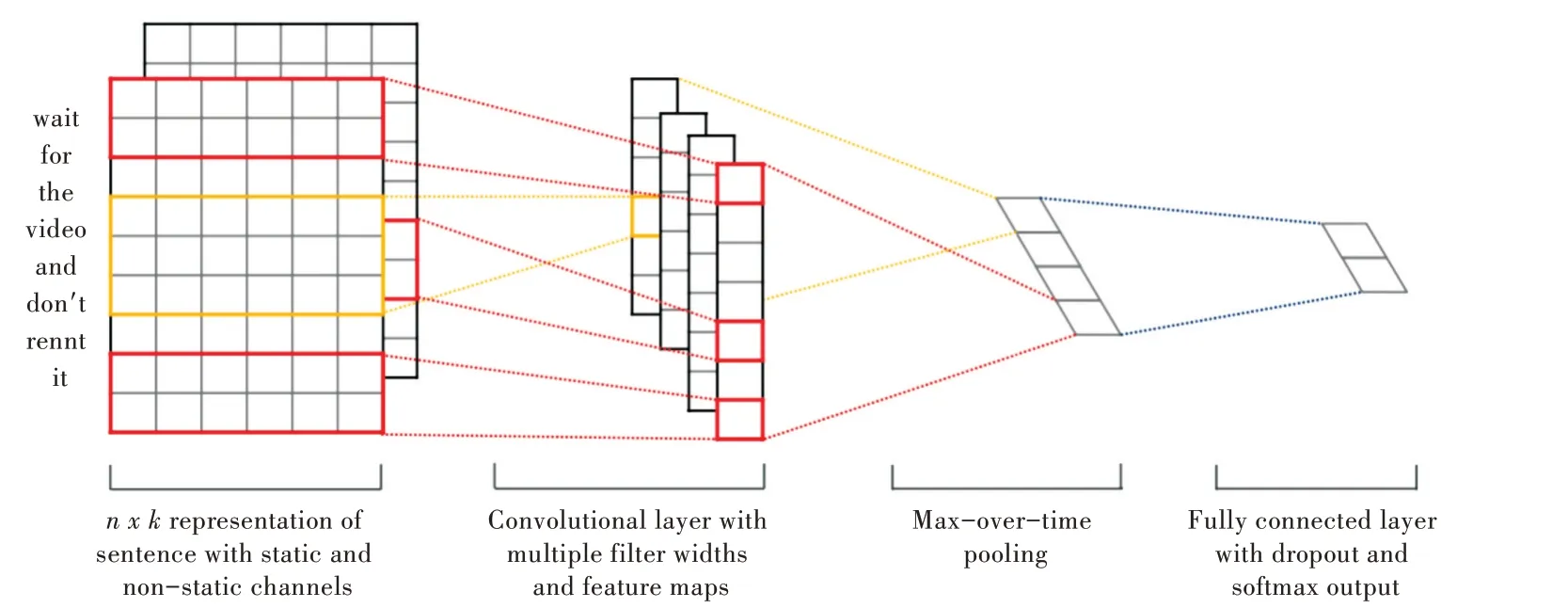
Fig.2 Kim's TextCNN statement classification model图2 Kim 的TextCNN 语句分类模型
2.3 LSTM
循环神经网络(Recurrent Neural Network,RNN)记忆单元无法筛选有用信息,导致无用的信息被存储在记忆单元中,有用的信息却被挤出去。文献[12]中,长短期记忆网络LSTM 是在RNN 基础上优化而来,通过引入记忆单元和门机制,有效解决了信息筛选,以及反向梯度消失或爆炸问题。
如图3 所示,在基本的LSTM 单元中,存在3 个门单元,分别称为输入门、输出门和遗忘门。单元状态更新实现和LSTM 输出计算如式(6)—式(13)所示。
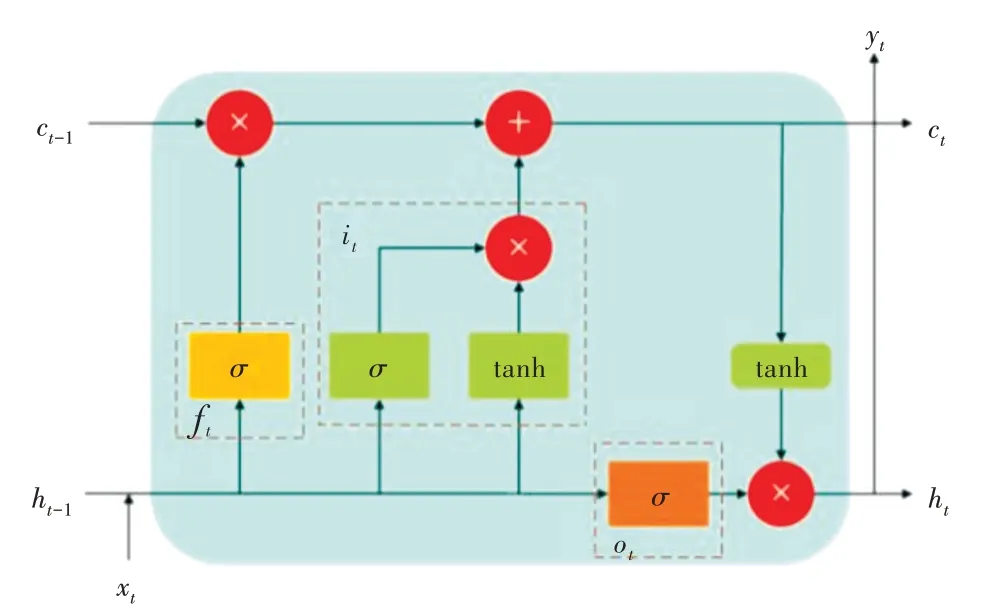
Fig.3 LSTM basic cell model图3 LSTM 基本单元模型
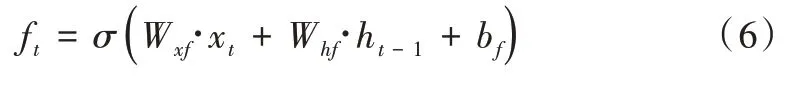
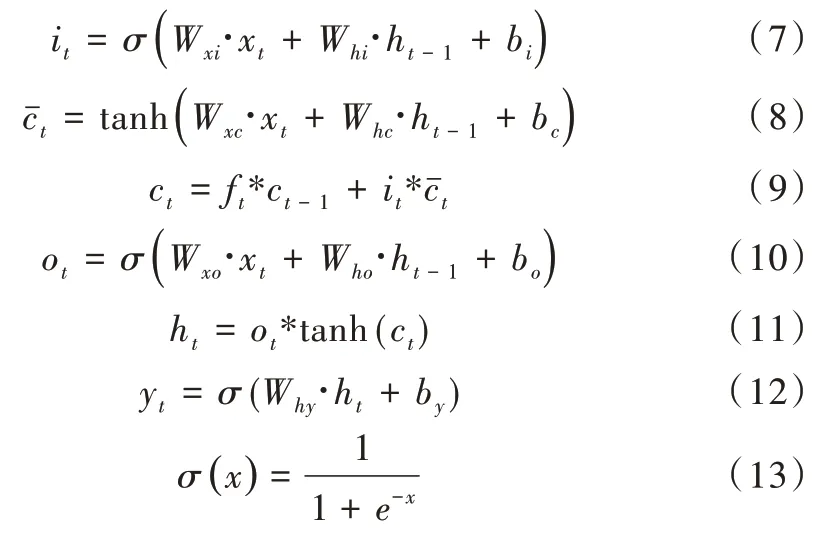
式中,ft代表遗忘门的输出,it代表输入门的输出,ot代表输出门的输出,ht-1为上一个LSTM 单元的输出,ct-1为上个单元的状态信息输入,保留了上个单元的状态信息,σ代指Sigmoid 函数。
2.4 TextCNN+LSTM
本文将LSTM 加入到TextCNN 语句分类模型的倒数第二层后、Dropout 之前,如图4 所示。可以认为多个不同尺寸的卷积核(窗口大小为2、3、4,汉语词语主要由2、3、4字组成)产生的最大特征向量间也存在关联,通过LSTM 捕捉最大特征向量之间的关联性,提高分类准确性,最终通过模型验证和测试准确率判断模型优劣。准确率计算如式(14)所示。

式中,a为准确率,p为模型验证数据集验证正确的样本个数,t为数据集中的样本总数。
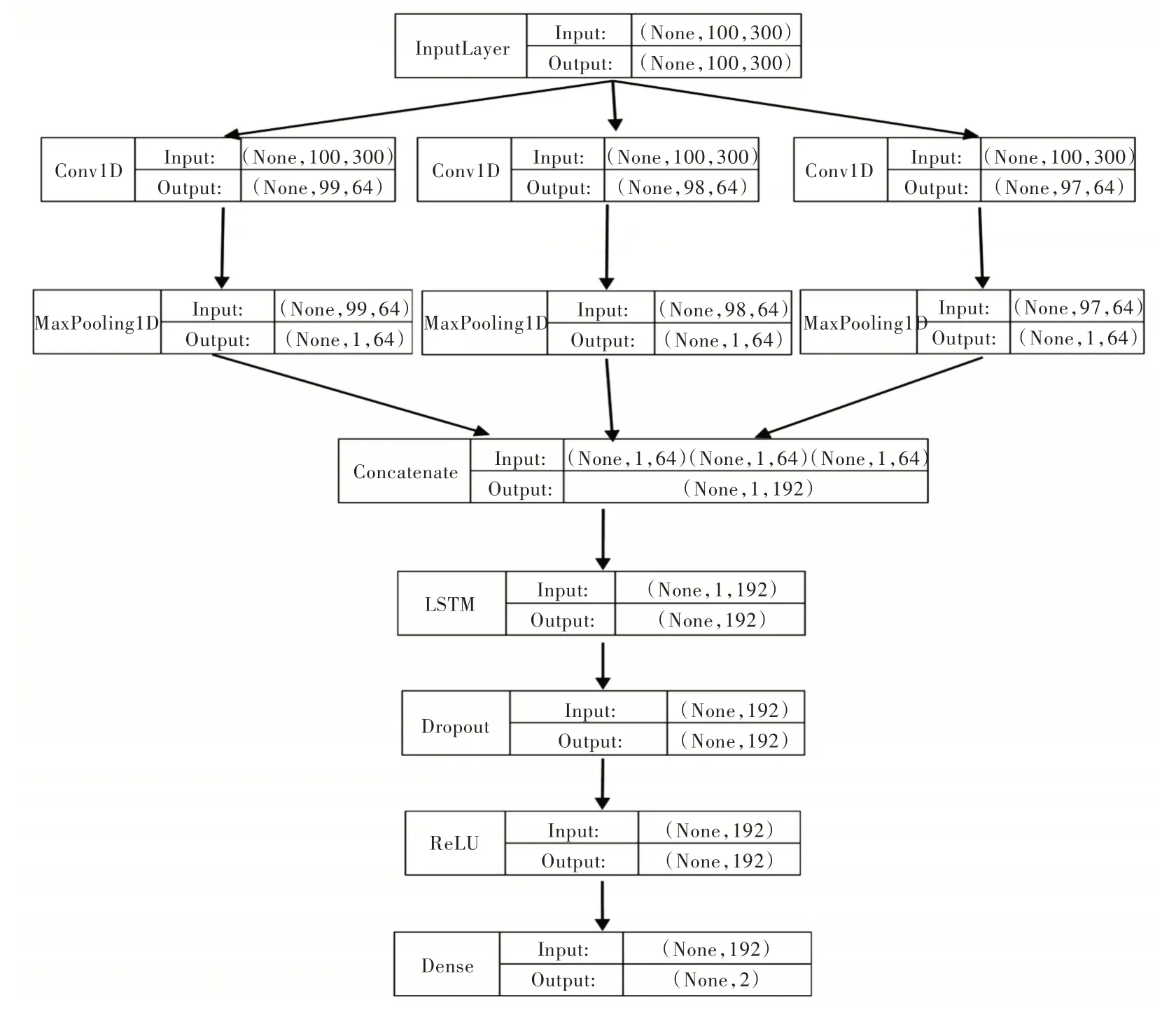
Fig.4 TextCNN+LSTM statement classification model图4 TextCNN+LSTM 语句分类模型
3 实验与结果分析
3.1 文本数据处理
分别对《红楼梦》的每一章回,都以逗号、问号、分号、感叹号为分割点进行语句分割,之后将句子以最小句子数合并成超过100 字符的长句子,例如,句子一长33,句子二长40,句子三长50,句子四长20……,将句子一、二、三合并,这是最少句子数合并。短句子在样本少的情况下,模型并不能有效提取出不同的写作风格和文本特征,因此将短句子合并成长句子。
为了探究《红楼梦》作者在哪一章回出现明显不同,为此,从第25 回开始将《红楼梦》分割成两个部分,前25 为样本负例,后95 为正例。之后每隔5 章回依次将《红楼梦》分割成前后负正例,所有分割点为25、30、35、40、45、50、55、60、65、70、75、80、85、90、95,共计15 个分割点。从分割前后部各自随机抽取约1 200 例样本作为训练集,共计约2 400 个样本。为了让抽取的样本均衡,从前后部每一章回都要均衡随机抽取。例如以80 为分割点的前后部,对于前80 章采样1 200 例,则每章随机抽取1 200/80=15 例,后40 章每章随机抽取1 200/40=30 例。对所有分割点的训练集都是如此采样,除不净取下整。每个分割点的测试集也依次取剩余正负样本各约250 例,共计约500例。这样就产生了15 个不同分割点的训练集和测试集,如图5 所示。
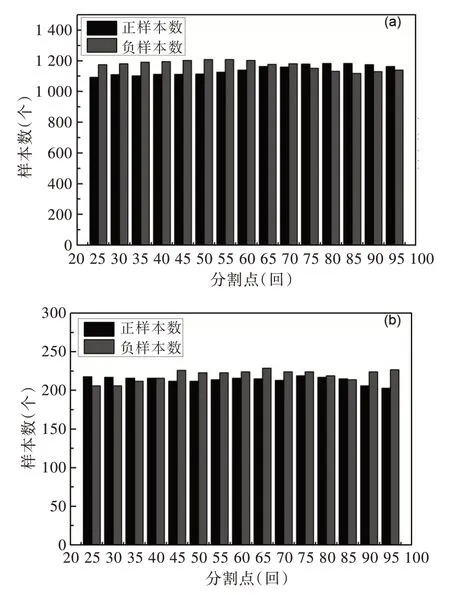
Fig.5 Sample size distribution of training set and test set图5 训练集与测试集样本数分布
由于《红楼梦》作者存在争议,因此不采用《红楼梦》训练词向量,因此文本的词向量采用GitHub 上已处理好了的文学文本的词向量,采用Cun 等[16]提出的Skip-Gram with Negative Sampling 法而生成,单字的向量维度为300,图6为部分词向量的二维可视化图。
Fig.6 Two-dimensional visualization of word embedding图6 词向量二维可视化
将上述15 个训练集输入到TextCNN+LSTM 模型中,每个训练集在模型中迭代20 次并且随机选取10% 的训练样本作为验证集,重复3 次,选取验证准确率最高的作为次分割点的最优模型,训练出15 个语句分类模型。
3.2 实验结果分析
如图7(a)所示,图中横坐标为《红楼梦》章回的15 个分割点的取值范围,纵坐标代指模型在数据集上的准确率,方点折线由15 个模型各自的验证准确率连接,圆点折线由15 个模型各自的测试准确率连接。
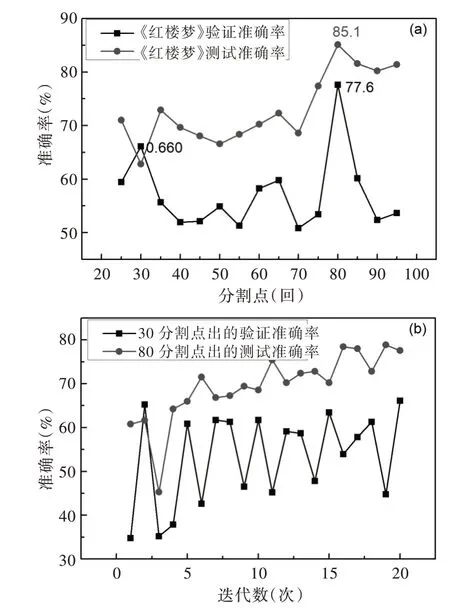
Fig.7 Comparison embedding the verification and test accuracy of A Dream of Red Mansions and the iteration verification accuracy of two segmentation points图7 《红楼梦》验证和测试准确率与两分割点迭代验证准确率对比
从图7(a)可以发现,无论是验证准确度,还是测试准确度,在《红楼梦》章回80 分割点处都取得了最大准确度值,而且明显异于其它分割点。在方点折线中除80 分割点处的最高点外,还有一处次高点的异常值在30 分割点处。如图7(b)所示,此图为30 和80 分割点处的训练集在20 次迭代中验证准确率对比图,图7(b)的横坐标为迭代值的范围,纵坐标为验证准确率,方点折线为30 分割点处的验证准确率连线,圆点折线为80 分割点处的验证准确率连线。从图7(b)中可以发现黑色折线波动异常不稳定,而红色折线稳步波动上升并趋于平稳,也即模型在30 分割点处并没有学到有效的写作风格和文本特征。因此前80 章回与后40 回在写作风格上有着较为显著的变化。
由于在Kim[11]的模型中加入了一层LSTM,为了检验加入LSTM 层对分类模型是否有改进,在不改变其他参数的情况下,将LSTM 层删除,重新训练15 个二分类模型。如图8 所示,其中横坐标为《红楼梦》章回15 个分割点的取值,纵坐标代指模型在数据集上的准确度,正三角和倒三角点折线分别由无LSTM 层的15 个模型各自的验证和测试准确率连接,方点和圆点折线分别由带有LSTM 层的15 个模型各自的验证和测试准确度连接。由图8 可以发现,在80 分割点处两种模型的验证和测试准确率都取得了最大值,且同样明显异于其他分割点。但两模型在80分割点处的测试准确率上,带有LSTM 层模型的测试准确率要高于无LSTM 层模型的测试准确率3.6%。因此带有LSTM 层模型在提取写作风格和文本特征上要略胜一筹,具有更好的泛化能力。
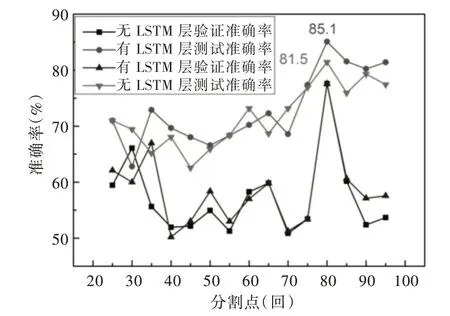
Fig.8 Accuracy comparison of models with or without LSTM layer图8 模型有无LSTM 层准确率对比
为了验证模型是否真的能在一本作品中提取出不同作者写作风格,还选取了一本无作者争异的《西游记》用来测试模型,对《西游记》用上述同样的方法进行数据预处理。西游记只有100 章回,因此其分割点为25、30、35、40、45、50、55、60、65、70、75,共计11 个分割点。
如图9 所示,横坐标为章回分割点的取值范围,纵坐标代指模型在数据集上的准确度范围,圆点折线由《西游记》11 个模型各自的验证准确率连接,方点折线由《红楼梦》15 个模型各自的验证准确率连接。《西游记》各分割点处的验证准确度一直处于波动状态,并不像《红楼梦》那样出现一个非常突出的80 章回分割点,这是由于《西游记》是由一人所写,语句分类模型无法提取《西游记》各处分割点前后的章回中能体现出不同写作风格的特征。因此,语句分类模型确实可以应用在一本作品中以区分作者的写作风格。
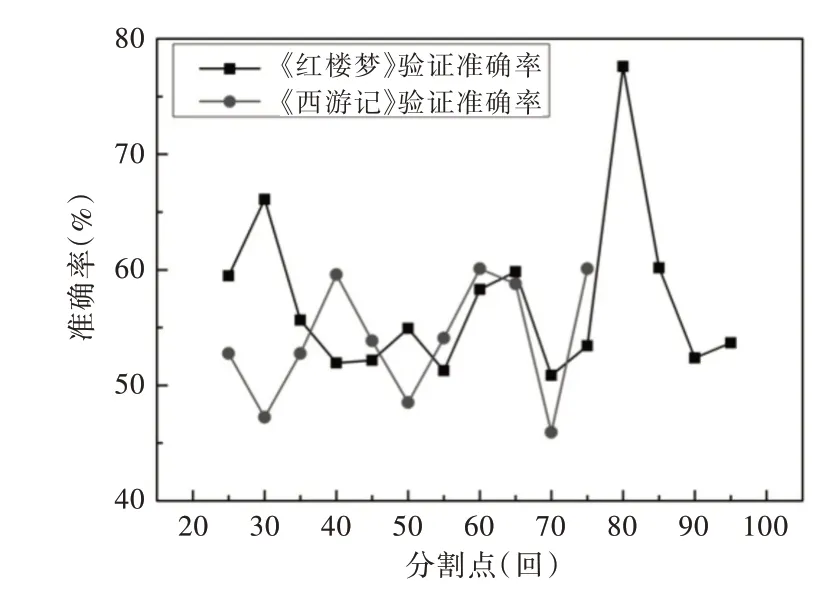
Fig.9 Verification and comparison between A Dream of Red Mansions and Journey to the West图9 《红楼梦》与《西游记》验证对比
4 结语
通过运用改进型语句分类模型,自动地提取文本特征,解决了人为提取文本特征片面、繁琐等不足。在《红楼梦》的15 个章回分割点处分别训练语句分类模型,通过15个模型的验证准确度和测试准确度折线图发现,在《红楼梦》第80 章回分割点处的验证准确度和测试准确度明显高于其余分割点处的准确度,且带有LSTM 层的语句分类模型具有更好的泛化能力,在准确度上提升了3.6%。结果表明,《红楼梦》前80 回与后40 回在写作风格上存在明显差异性。换言之,《红楼梦》的前80 回与后40 回不是同一人所写,与大多数前人的研究结论相符合,也为佐证其它作者存疑作品提供了新的解决思路或判定方法。同时,通过该研究可以发现不同作者间的语言风格不同,该研究仅对单个汉字做了词向量,这样割裂开了词语间的联系,而且分类准确率还有待提高,今后可以引入注意力模型,同时训练新的结合字词的词向量。
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
红楼梦学刊(2020年4期)2020-11-20
海峡姐妹(2020年7期)2020-08-13
新世纪智能(语文备考)(2020年4期)2020-07-25
红楼梦学刊(2020年3期)2020-02-06
中国交通信息化(2018年5期)2018-08-21
海峡姐妹(2018年5期)2018-05-14
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
