
基于BP 神经网络的声源定位研究
2021-04-23 05:50佘霖琳赵祎彤李嘉雪宋雲龙
软件导刊 2021年4期
佘霖琳,孙 红,赵祎彤,李嘉雪,宋雲龙
(上海理工大学光电信息与计算机工程学院,上海 200093)
0 引言
21 世纪以来,人工智能的兴起使得基于语音、文字、图像等模式识别的人机交互成为研究热点。要实现机器与机器以及人与机器之间的交流互动,能够精确定位发出声源的人或机器位置是极其重要的[1-2]。目前,声源定位在视频会议、助听器、智能降噪[3]、车载电话、鸣笛抓拍等领域有着广阔的应用前景。
传统声源定位算法大体可分3 类:基于到达时延估计(Time Difference of Arrival,TDOA)的声源定位算法[4]、基于最大输出功率的可控波束形成声源定位算法[5]、基于高分辨率谱估计的声源定位算法[6]。其中,第一类算法根据声源信号到达不同位置麦克风的时间差确定声源位置;第二类算法利用波束形成技术,但需基于背景噪声和声源信号先验知识,因此限制了算法应用;第三类算法来源于高分辨率谱估计技术,其定位性能好,但计算复杂度高,难以达到应用场景要求的实时性。在3 类方法中,TDOA 算法因其计算复杂度与硬件实现成本较低而受到较多关注。其发展主要分为两个阶段:第一阶段为传统的时延估计方法,以相关分析、相位谱、参数估计为基础,以数据收集作为手段进行声源定位,其中应用最广泛的为孙洋等[7]提出的基于相关分析的广义互相关函数法(Generialized Cross-Correlation,GCC)和Haykin[8]提出的基于自适应滤波器的最小均方自适应滤波法(Least Mean Square,LMS)。但GCC 算法需要对信号和噪声谱估计其加权函数,从而增加了算法复杂度。LMS 算法稳定性较差,若迭代步长过大,会出现不收敛的情况;若迭代步长过小,则会导致不平稳信号还未实现寻优便又引入新的误差。第二阶段出现了机器学习声源定位方法,目前应用较多的为焦琛等[9]提出的基于相位加权广义互相关函数的卷积神经网络算法(Convolutional Neural Networks,CNN)。
使用机器学习算法相较于传统算法能避免繁重的计算、具有较高准确度,并且可通过改变少量参数以适应更多不同的复杂应用场景。但对于如何选取其算法模型参数,目前尚无明确的理论研究,大多通过反复实验、参考类似经验得到。本文运用机器学习中的BP 神经网络算法对声源定位进行研究,探讨适合本研究场景的最佳模型参数,以期为声源定位技术的深入发展及应用提供参考[10]。
1 BP 算法基础理论与相关技术
1.1 BP 神经网络简介
BP(Back Propagation)神经网络是一种有监督的神经网络学习算法,其利用误差的反向传播原理,改变传统网络结构,引入新的分层与逻辑。学习过程由正向传播和反向传播两部分组成,在正向传播过程中,输入模式从输入层经过隐含层神经元处理后传向输出层,每一层神经元状态只影响下一层神经元状态。如果在输出层得不到期望的输出,则转入反向传播,此时误差信号从输出层向输入层传播,并沿途调整各层间连接权值和阈值。该过程反复交替进行,直至网络的全局误差趋向给定的极小值。在反复训练过程中,其采用梯度下降法使得权值沿着误差函数的负梯度方向改变,并收敛于最小点。BP 算法主要步骤如下:
(1)正向传播过程。在输入层中,单元i的输出值oi等于其输入值xi的加权和:
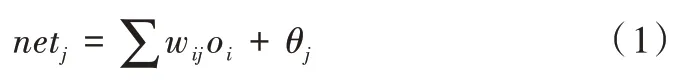
输出值为:

式中,f若为sigmod函数,则:
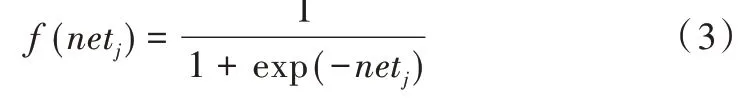
在输出层中,因为输出层单元的作用函数为线性,故输出值为输入值的加权和。对于第k 个输出单元,输出值yk为:

(2)反向传播过程。首先定义误差函数Ep为:
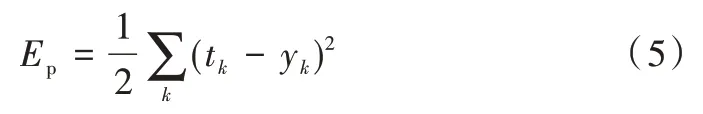
BP 学习算法采用梯度下降法调整权值,每次调整量为:

式中,η 为学习率,0<η<1,由此式可得到权值修正量公式。对于输出层与隐含层之间的权值v:

其中,有:
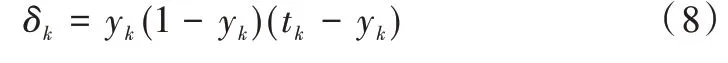
对于隐含层与输入层之间的权值w:
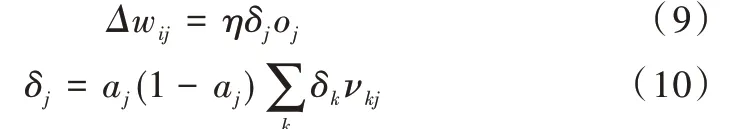
1.2 BP 神经网络神经元个数与隐藏层层数选择
在神经网络中,单层神经网络只用于表示线性分离函数[11],而当数据非线性分离时需要增加隐藏层[12]。对于简单的数据集,通常包含1~2 个隐藏层的神经网络即可得到最优结果。而对于涉及时间序列或计算机视觉等内容的复杂数据集,则需要额外增加隐藏层层数。
当没有隐藏层时,仅能表示线性可分函数或决策;当隐藏层数为1 时,可以拟合任何包含从一个有限空间到另一个有限空间的连续映射函数;当隐藏层数为2 时,搭配适当的激活函数可表示任意精度的任意决策边界,并且可拟合任意精度的任何平滑映射;当隐藏层数>2 时,多出来的隐藏层可学习更为复杂的描述。
层数越深,理论上拟合函数的能力增强,效果越好,但实际上更深的层数可能带来过拟合问题,同时也会增加训练难度,使模型难以收敛。因此,在使用BP 神经网络时,较可取的方法是参照已有的表现优异的模型。而当缺少可参考模型时,从一或两个隐藏层开始尝试不失为探究最佳层数较为合适的方法。
在确定隐藏层的神经元个数方面,若神经元太少将导致欠拟合[13],网络不能有效地学习,需要大量增加训练次数,并且严重影响训练精度;而神经元过多可能导致过拟合,训练集中包含的有限信息量不足以训练隐藏层中的所有神经元。即使训练数据包含的信息量足够,隐藏层中过多的神经元也会增加训练时间,导致难以达到预期效果。显然,选择一个合适的隐藏层神经元数量是至关重要的。
在确定神经元个数方面,首先应该考虑此前提:隐含层节点数必须小于N-1(N 是训练样本数),否则网络模型的系统误差与训练样本的特性无关而趋于0,即建立的网络模型缺乏泛化能力,也无任何使用价值。而除此之外,当前并没有一种科学的确定神经元个数的方法,最佳数量需要通过不断的实验获得。
对于如何确定神经元数量和隐藏层层数,本研究通过不断实验的方法,从1 个神经元、1 层隐藏层开始递增,如果欠拟合则增加层数和神经元,如果过拟合则减小层数和神经元。
1.3 BP 神经网络的不足与反向传播函数选取
在BP 神经网络的标准算法中,其反向传播过程是基于梯度下降法,通过调整权值和阈值使输出期望值与神经网络实际输出值的均方误差梯度趋于最小而实现的。虽然标准训练算法下的BP 网络得到了广泛应用,但其自身也存在一些不足,主要包括以下4 个方面:
(1)由于学习速率是固定的,因此网络收敛速度慢,训练需要较长时间。如果问题复杂,BP 算法需要的训练时间可能会非常长,无法满足应用要求。针对这一点,可采用变化的学习速率或自适应学习速率加以改进,如利用学习速率自适应的BP 算法。
(2)BP 算法可使权值收敛到某个值,但并不保证其为误差平面的全局最小值,这是因为采用梯度下降法可能会产生一个局部最小值。对于该问题可采用附加动量法来解决,如动量因子BP 算法[14]。
(3)对于网络隐含层层数与神经单元个数选择尚无理论上的指导,一般是根据经验或者反复实验确定。因此,网络模型各项参数的可移植性差,并且网络往往存在很大的冗余性,在一定程度上增加了网络的学习负担。
(4)网络学习和记忆具有不稳定性,在增加了学习样本的情况下,训练好的神经网络需要从头开始重新训练,对于以前的权值和阈值并无记忆。
由于BP 标准算法有很多不足,因此在不同的实际应用情况下,需要将其与改进的BP 算法函数相结合。考虑到本研究模型属于中型网络,以下介绍适合中型网络的改进算法及其相应特点:①traingdx:带有动量项的自适应学习算法,训练速度较快;②trainrp:弹性BP 算法,收敛速度快,占用内存小;③traincgf:Fletcher-Reeves 共轭梯度法[15],是对存储量要求最小的共轭梯度法;④trainscg:归一化共轭梯度法,唯一一种不需要线性搜索的共轭梯度法;⑤trainlm:Levenberg-Marquardt 算法,是介于牛顿法与梯度下降法之间的一种非线性优化方法,对于过参数化问题不敏感,能有效处理冗余参数问题,大大减小了代价函数陷入局部极小值的机会[16]。
2 采样原理与仿真模型
在建立神经网络之前,需要先设计出采样模型,获得输入数据与输出数据的形式,再设计神经网络。采样模型如图1 所示(彩图扫OSID 码可见,下同)。
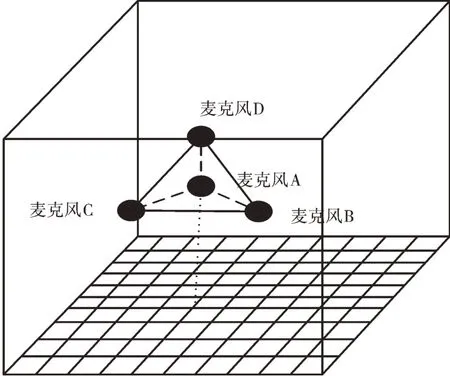
Fig.1 Sampling model图1 采样模型
如图1 所示,把地面划分为n 个小区域后,每一次测试时分别在某一个小区域的中心坐标处用发声装置发声。4个麦克风两两一组,形成AB、BC、CD 3 组,分别记录3 组内两个麦克风收到声音的时间差,具体如下:
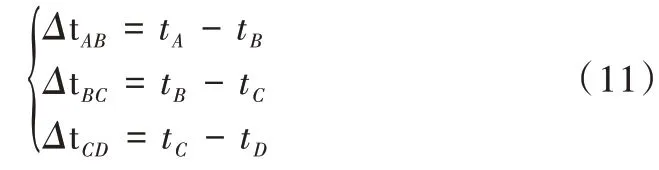
由此可得到n 组对应的数据,分别为3 组时间差以及一对二维坐标值,其中xi为横坐标值,yi为纵坐标值,则第i组数据为:
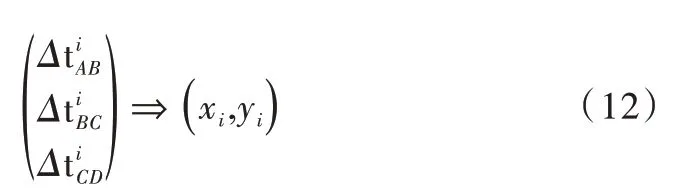
本研究将声源定位场景简化为在一个占地面积为100m2的房间里对声源进行水平面上二维坐标定位的模型。假设房间是一个标准的长方体,房间长为10m,宽为10m,高为5m。在麦克风阵列位置选取方面,选定4 个麦克风的位置分别为A(4.9,4.9,1.0)、B(4.9,5.1,1.0)、C(5.1,5.1,1.0)、D(5.0,5.0,2.0),使其在空间构成一个四面体[17]。
对于神经网络输入、输出数据的获取,本研究根据基于时延的声源定位基本原理,由声源位置坐标计算各组麦克风接收来自同一声源声音的时间差作为测试集的输入数据,将声源实际位置坐标作为输出数据,之后利用BP 神经网络进行训练、验证、测试后,则可得到用于声源定位的模型。
在分析比较神经网络隐藏层神经元个数、隐藏层层数对算法精确性影响的实验中,训练集、验证集都采用400 个数据量,测试集采用50 个数据量。而在比较不同数据量下不同算法精确性的实验中,训练集、验证集采用的数据量从400 开始递增,测试集仍采用50 个数据量。
3 实验与结果分析
为了专注探究算法的精确性,排除环境干扰,在一个100 m2房间里实现对声源的二维空间定位,本研究借助MATLAB 进行仿真实验[18]。运用其中的rand 函数随机生成点坐标数据集用于神经网络的训练、验证与测试。由于数据集是随机生成的,为了保证实验结果的有效性,本研究对同一参数下的神经网络都进行了50 次测试,最后取50次结果的平均值作为对比分析的实验数据。运用构建神经网络的函数,通过设置隐藏层神经元个数、隐藏层层数以及反向传播函数对应的函数参数,构建本研究所需的不同结构的BP 神经网络。
对比、分析3 类因素对声源定位精确性的影响后,将得到适合构建此模型的最佳网络模型,并且得出一定条件下该算法能达到的最佳定位效果。考虑到本研究要解决的是回归预测问题,故选取R 值(Regression)、MSE(Mean Squared Error)作为算法精确性评价标准。
3.1 仿真函数与参数设置
(1)mapminmax[19]。[Y,PS]=mapminmax(X,YMIN,YMAX),将归一化的信息保存到结构体PS 中,自定义MIN、MAX 的范围。
Y=mapminmax(‘apply’,X,PS),用已知的归一化规则PS 归一化其他信息。
X=mapminmax(‘reverse’,Y,PS),用于反归一化。
(2)newff。net=newff(P,T,[S1S2…S(N-l)],{TF1 TF2…TFNl},BTF,BLF,PF,IPF,OPF,DDF),用于创建前向型神经网络。
(3)train。[net,tr,Y,E,Pf,Af]=train(net,P,T,Pi,Ai),用于训练神经网络。
(4)sim[20]。[Y,Pf,Af,E,perf]=sim(net,P,Pi,Ai,T),用于模拟预测,Y 即最终预测的输出。
本研究在使用‘newfff’函数构建神经网络时,设置隐含层输出函数为‘tansig’,输出层输出函数为‘purelin’,设置训练参数依次为:Leaning_rate(学习率)=0.1、初始max_epoch(最大迭代次数)=5 000、初始goal(目标误差)=4e-6、max_fail(最大失败次数)=10 000。其中,最大迭代次数与目标误差需要根据每次具体实验效果加以调整,以确保在神经网络达到相对稳定的状态下记录实验数据。
3.2 神经网络神经元个数对算法精确性的影响
本实验采用LM(LevenBerg-Marquardt)[21]反向传播函数下、隐藏层层数为1 的BP 神经网络[22]对神经网络的神经元个数进行探究。
对于神经元个数选择,本实验从1 开始进行测试。通过实验发现,当神经元个数取1~4 时,所需迭代次数远大于最大迭代次数的初始值(5 000),尝试调整目标误差,使其增大至4e-3,之后得到网络稳定时的最终MSE 与R 值结果;当神经元个数取5~6 时,出现达到最大迭代次数而结果曲线未达到稳定状态的情况,故尝试将最大迭代次数设置为8 000;当神经元个数取7~9 时,在实验初始设置的参数值下,已可获得网络的稳定状态;当神经元个数取10 及以上时,达到原目标误差后曲线未趋于平稳,故将目标误差设置为4e-9。由实验结果可得,当神经元个数增加到10 之后,数据结果的稳定性较差且越来越差,故本实验对神经元个数的研究止于49。实验所得不同神经元个数下的MSE 值与R 值变化情况如图2、图3 所示。
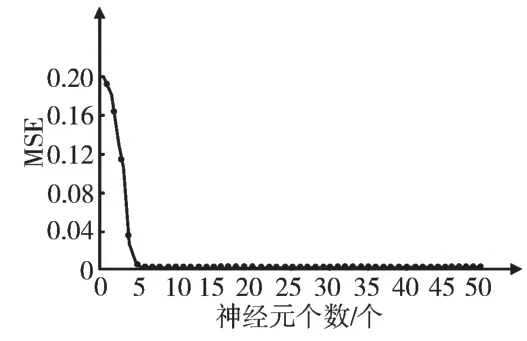
Fig.2 Change of MSE value of the different numbers of neurons图2 不同神经元个数下的MSE值变化情况
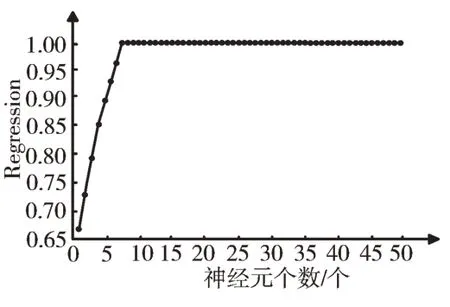
Fig.3 Change of R value of the different numbers of neurons图3 不同神经元个数下的R 值变化情况
分析图2、图3 可知,随着神经元个数的增加,MSE 值整体呈递减趋势,R 值呈递增趋势。为了得到更准确的实验结果,本实验进行局部探测,选取实验结果较佳的神经元个数为5~9 时的BP 神经网络进行研究,如图4、图5 所示。
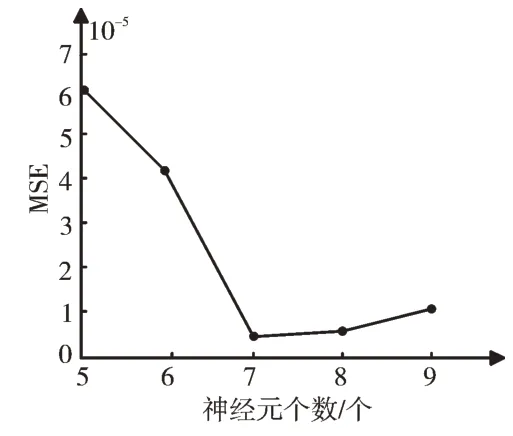
Fig.4 Change of MSE value of the different numbers of neurons from 5 to 9图4 5~9 个神经元个数下的MSE 值变化情况
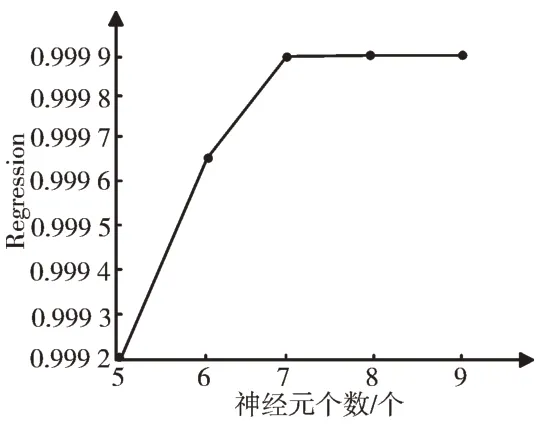
Fig.5 Change of R value of the different numbers of neurons from 5 to 9图5 5~9 个神经元个数下的R 值变化情况
由图可知,神经元个数为7 时的BP 神经网络在整体趋势中表现最好,接下来依次是个数为8、9、6、5 的BP 神经网络。相对于后4 种BP 神经网络,神经元个数为7 的BP 神经网络均方差MSE 值最小,R 值最大,网络收敛速度更快,网络稳定性更强。故得到当隐藏层神经元个数取7 时,BP 神经网络算法的预测结果最佳,该神经网络结构[23]如图6 所示,并且为得到较理想的实验效果,以下实验中神经元个数都取7 进行研究。
3.3 神经网络隐藏层层数对算法精确性的影响
本实验采用LM 反向传播函数下神经元个数为7 的BP神经网络对神经网络的隐藏层层数进行探究。
每层隐藏层都取7 个神经元,从1 开始递增隐藏层层数进行实验。对于1~2 层神经网络,在未达到最大迭代次数时,此神经网络误差即可减小到初始目标误差以下,而后观察MSE 随迭代次数递增的变化曲线可知,MSE 稳定在e-9 数量级。通过增加隐藏层重复上述操作,实验发现,当隐藏层为3~13 层时,达到原目标误差后曲线未趋于稳定,有继续下降趋势,表明精确性有望继续提高,故实验需要减小目标误差,直到得到每一种隐藏层层数下网络模型的最小稳定误差。而当层数取13 以上时,相对应的稳定最小误差已无法达到原先设定的目标误差,且相差甚远,则增大目标误差后继续观察。鉴于当隐藏层为13~16 层时,在相同参数下每次测试的数据变化过大,且平均误差过大,表明其实际应用价值较低,因此不再递增层数继续实验。

Fig.6 Neural network structure图6 神经网络结构
取1~16 层数据进行研究分析,1~16 层隐藏层层数下BP 神经网络误差MSE 值如图7 所示,对应的R 值如图8 所示。观察两图可以看出,13~16 层下神经网络误差较大,1~12 层下误差较小;1~11 层下神经网络拟合度较好,R 值都为1,12~16 层下R 值小于1,且层数达到14 层以上时,R 值急剧下降。由此可得出结论:BP 神经网络隐藏层层数的递增与算法性能的提升并不呈正相关。
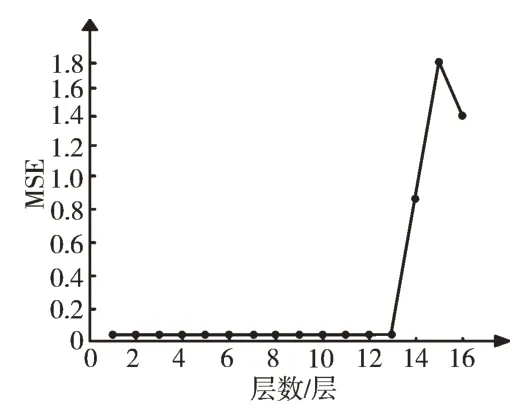
Fig.7 Change of MSE value of the different numbers of hidden layers图7 不同隐藏层层数下的MSE值变化情况
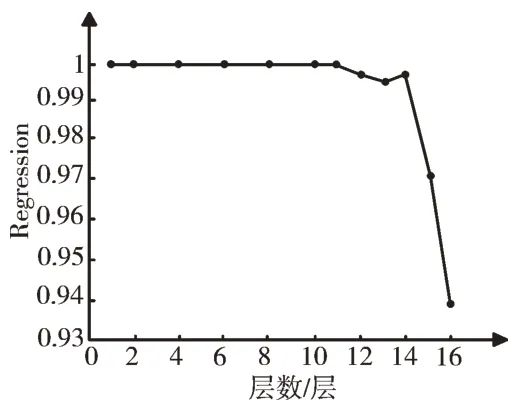
Fig.8 Change of R value of the different numbers of hidden layers图8 不同隐藏层层数下的R 值变化情况
此外,实验发现,层数分别取13~16 层时的神经网络每次测试得到的MSE 值数量级变化范围为e-3~e-8。由此可得,虽然此最小误差与1~12 层时的误差同级,但平均误差过大,此时的网络稳定性差、有过拟合倾向,并且13 层以上的神经网络训练时间过长,应用价值较低。
为了进一步探究1~12 层范围内的最佳层数,本实验对图7 中1~12 层的MSE 值数据单独进行绘制。观察得到1 层下的MSE 值数量级为e-6,远大于2~12 层下的MSE 值数量级。为了更直观、清晰地分析最佳层数,取2~12 层数据,得到如图9 所示的曲线图。由图可以得出,当隐藏层取3、4、8、9 层时,该神经网络达到最佳预测精度。由于8、9 层神经网络训练时间长于3、4 层,可见当隐藏层取3、4 时,该BP 神经网络预测结果达到最佳。为得到较理想的实验效果,以下实验中隐藏层层数都取3 进行研究。
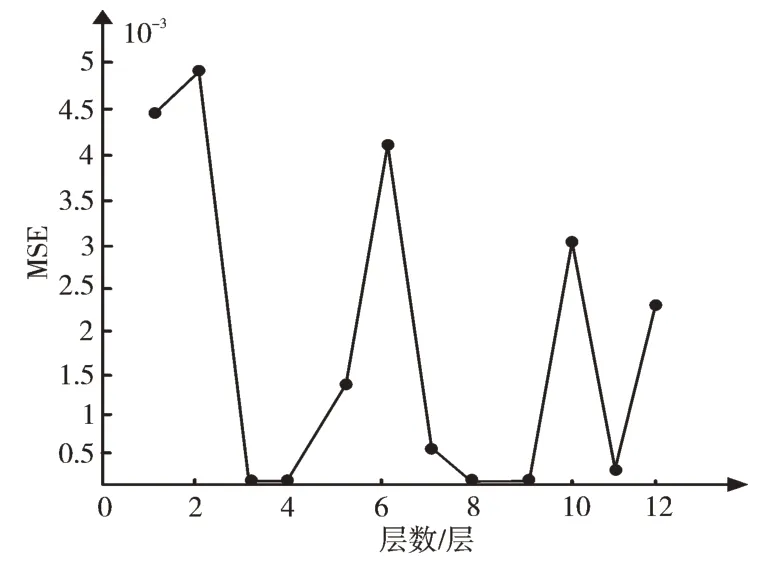
Fig.9 Change of MSE value of the different numbers of hidden layers from 2 to 12图9 2~12 不同隐藏层层数下的MSE 值变化情况
3.4 不同反向传播算法在不同数据量下的精确性对比
本实验采用神经元个数为7、隐藏层层数为3 的BP 神经网络对反向传播算法进行探究。分别针对不同数据量,选择不同的反向传播算法对神经网络进行训练,旨在探究不同算法在不同数据量下的适应性与精确性,并验证基于LM 算法的BP 神经网络适用于本研究采用的中型网络声源定位模型。
对于反向传播函数[24],本实验选用trainlm(LevenBerg-Marquard 算法)、trainbr(贝叶斯正则化算法)、trainrp(弹性BP 算法)、trainscg(归一化共轭梯度法)以及traincgf(Fletcher-Reeves 共轭梯度法)。
通过实验发现,对于trainlm 算法,当数据量取400~2 800 时,在初始最大迭代次数(5 000)、目标误差(4e-6)下,网络未达到稳定状态。调整目标误差为4e-7 时,观察MSE 随迭代次数递增的变化曲线可知,MSE 值稳定在1e-6数量级。通过增加数据量,发现该算法训练达到最大迭代次数后,其MSE 值在1e-4 数量级。调整最大迭代次数为8 000 后,实验发现该网络训练过程缓慢,且出现过拟合现象,则适度增大目标误差、减少迭代次数。考虑到继续增加数据量后算法训练时间过长,且误差并未降低,故本实验对数据量的讨论止于4 000。对于其他4 种算法,采取与上述相同的思路进行实验,得到不同算法在不同数据量下的MSE 值与R 值变化情况如图10、图11 所示。
分析图10、图11 可知,总体来看,在采用的5 种算法中,trainlm 算法的MSE 值最低,R 值最高。其中,trainbr 算法训练结果与trainlm 算法较为接近,但由50 次采用相同参数和数据量的测试结果可得,trainbr 算法的误差波动较大,没有trainlm 算法稳定。而其余3 种算法trainrp、trainscg、traincgf 与前两种算法相比,均方误差均高出两个数量级,且R 值都偏小。
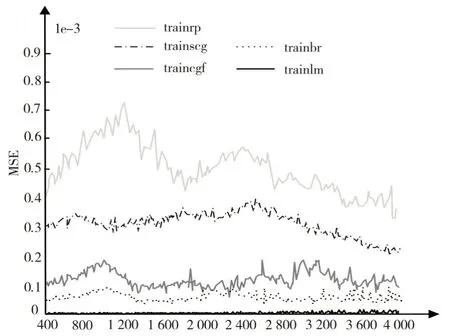
Fig.10 Change of MSE value of different algorithms under different data volumes图10 不同算法在不同数据量下的MSE 值变化情况

Fig.11 Change of R value of different algorithms under different data volumes图11 不同算法在不同数据量下的R 值变化情况
此外,通过实验发现,随着数据量的增加,trainlm 算法和trainbr 算法的MSE 值与R 值在数据量约大于2 800 时有轻微振荡,MSE 值趋于增大,R 值趋于减小。同时,trainrp算法和trainscg 算法的MSE 值趋于减小,R 值趋于增大。由此得出,trainlm 算法和trainbr 算法更适合处理数据量较小的数据集,而其余3 种算法更适合处理数据量较大的数据集。
本仿真实验构建的神经网络输入数据数量为3,输出数据数量为2,神经元数量为7,隐藏层层数为3,该神经网络属于中型网络。由此可得,trainrp、trainscg 算法明显不适用于本实验的神经网络,而较适用于大型网络。traincgf 算法的预测效果相比这两者有所提高,但也未达到较高的精确度。相比之下,trainlm、trainbr 算法更适合于本实验的神经网络,且适合处理数据量较小的数据集。通过进一步比较,trainlm 算法相比trainbr 算法速度更快且精确度更高,对中型网络而言是速度最快的一种训练算法,在训练时间和训练精度上都较适合本研究。
4 结语
在本研究中,使用BP 神经网络进行声源定位的准确度已可达到较高水平,R 值可达到1,MSE 值在e-11 数量级下,位置误差在毫米范围内。含有3 个隐藏层、每层含7 个神经元、反向传播函数取LM 的神经网络是目前适用于此声源定位场景的最佳网络模型。然而,占用内存过大是LM算法的缺点,并且若要进一步提高算法精度、提升鲁棒性,仍有以下几方面值得作进一步改进和深入研究:
(1)本研究是在MATLAB 环境下进行的仿真实验,若在实际情况下进行实验,麦克风所接受到的声音信号除声源信号外,还包括四周墙壁的反射信号、环境的噪音信号等。在这种情况下,对声源位置的预测将受多方因素干扰,如何结合去噪算法[25]提取主要声源特征、建立模型以及维持原声源定位算法的有效性需要作进一步研究。
(2)在当前模型下,LM 为较适合的反向传播函数,而若在更宽阔的场景以及更复杂的大型网络模型情况下,结合降噪算法,可考虑对反向传播函数进行灵活变换,在每一层隐藏层中选取不同的反向传播函数,将有望提高不同模型下算法的精确性与稳定性。
(3)本研究验证了LM 算法对中型网络的适用性与有效性。在大型网络下,LM 算法可考虑通过设置其内部mem-reduc 参数为大于1 的整数,以将Jacobian 矩阵[26]分为多个子矩阵。而为了降低其占用的内存,该方法中的系统开销与Jacobian 各子矩阵的关系有待进一步探究。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
小学生学习指导(低年级)(2021年9期)2021-10-14
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
电子制作(2019年23期)2019-02-23
小学生学习指导(低年级)(2018年9期)2018-09-26
