
基于信息增益的KNN 社交网络异常用户检测
2021-04-23 05:50武海燕李坤明
软件导刊 2021年4期
武海燕,李坤明
(铁道警察学院图像与网络侦查系,河南郑州 450053)
0 引言
随着社交网络平台的迅速发展,国内的微信、微博,国外的Twitter、Facebook 等已经成为人们日常生活中重要的社交工具,越来越多的人们在社交网络平台上获取信息[1-2]。当前社交网络中存在着大量异常用户,这些异常用户通过创建大量的虚假账号和盗用正常用户的账号,发布虚假广告、散布谣言等行为扰乱社会稳定。同时,也存在着发布钓鱼信息,操纵大量用户进行互粉、点赞的恶意行为。因此,社交网络平台上的非法用户检测具有重要意义,不仅让用户在社交网络上获得真实信息、提升上网体验,同时也是公安舆情和社交网络研究领域的一个重要课题。
1 相关工作
近年来,研究者主要采用机器学习算法对社交网络异常用户进行检测,比较常用的方法分为3 种:有监督学习的检测方法、无监督学习的检测方法和图模型的检测方法。其中,图模型检测方法是一种特殊的无监督检测方法。
1.1 无监督学习的检测方法
当样本数据集不含标签或者是仅仅拥有少量用户的标签时,研究者提出利用无监督学习算法解决异常用户检测问题。无监督学习检测方法是基于聚类思想,将正常用户和异常用户聚集为不同簇的方法。Husna[3]等将垃圾邮件的发送者所发送邮件的内容、时间、频率等作为特征,然后使用K 均值聚类算法进行聚类分析;为了提高聚类效果,陈庄等[4]通过引入信息熵,将各属性权重进行排序后计算相似度,提升了检测率;Miller 等[5]通过使用两种聚类算法相结合的方式对Twitter 上的用户进行聚类分析,以识别出正常用户和异常用户;Beutel 等[6]设计出CopyCatch 模型,该方法通过构建出社交网络时间矩阵,最大化TNBC 核心中的异常用户数量,以此进行聚类,检测出Facebook 中的异常用户。使用无监督方法的优点是不需要对数据进行标注,也不用提前训练,可以很方便地构建出社交网络异常用户检测模型。但是,构建出的模型准确率低、算法设计复杂。
1.2 图模型检测方法
基于网络连接的图模型检测方法主要根据异常用户与正常用户所具有的不同拓扑结构,一般采用无监督学习检测方法[7]。常用的两种检测方法是基于谱分解的检测方法和基于随机游走的检测方法[8-10]。图模型的优点是不需要提前训练,只需要图数据,由于对理论假设条件要求高,因而模型准确率较低。
1.3 有监督学习的检测方法
使用机器学习监督算法对社交网络异常用户进行检测是研究者常采用的一种方式。此时的数据集含有标签并利用这些数据集训练出分类模型,然后使用训练好的模型对其他未被标注的数据集进行预测。Chu 等[11]通过提取社交网络用户的内容、行为和属性特征,并结合信息熵使用贝叶斯(Naive Bayesian,NB)算法构建出分类模型,该方法对异常用户检测的准确率较高,但是计算量大,而且该方法假设所有的属性之间互相独立,普适性有所欠缺。孟祥飞等[12]通过将社交网络用户的粉丝数量、评论数、互粉数等作为特征,使用C4.5 决策树(Decision Tree,DT)算法构建分类模型,实现对用户的检测,这两种方法在分类精度上均存在不足;袁丽欣等[13]使用XGboost 方法对特征进行选择,构建集成分类器实现对异常用户的检测;徐华露等[14]使用蜜罐收集数据集,然后使用随机森林算法对社交网络中的僵尸用户进行检测;Bo 等[15]对微博数据集的内容以及用户行为进行抽取并将其作为特征,使用支持向量机(Support Vector Machine,SVM)构建分类模型,该方法可达到较高的分类精度;王越等[16]将微博的数量、转发率等内容特征和用户信息特征,如粉丝数量、人体指数等作为特征,使用模拟退火算法对特征进行处理,然后用BP 神经网络构建分类模型,通过对5 000 个测试集进行测试得到该模型准确率达93%。使用SVM 和神经网络时算法时间复杂度较高。
对此,本文提出一种基于信息增益的KNN 社交网络异常用户检测模型,首先使用信息增益特征选择方法对数据集进行属性约简,选择出重要性较高的特征属性,去除冗余属性,然后使用特征选择后的数据集训练出KNN 分类器模型,该方法有效提高了分类精确率和召回率。
2 相关概念
2.1 信息增益特征选择
在使用机器学习方法对社交网络中的异常用户进行检测时,需要其准确地发现异常行为,但是在文本数据处理过程中会产生很多冗余特征,这就需要使用特征选择方法去除重复多余的特征,挑选出关键特征。当前属性约简算法有主成分分析(PCA)法、奇异值分解(SVD)法和信息增益(IG)等,其中PCA 和SVD 可能会损失部分重要信息。信息增益是一种过滤式特征选择方法。数据样本属性特征之间的信息越多,则这些特征之间的联系也越紧密,同时特征之间的信息增益也就越大。一般情况下,属性特征的信息增益越大,其对分类结果的影响也越大[17]。因此,可以通过信息增益的方法确定数据集中较重要的属性特征,并选择信息增益大的属性特征。此外,信息增益主要通过信息熵实现,信息熵是熵在衡量信息变量中无序度的度量。对于一个给定的数据集D,假设D 中第i类样本所占比例为pi(i=1,2,...,|Y|),假定样本属性均为离散型。对于每个属性A,假定根据其取值将D 分成了V 个子集{D1,D2,D3,...,Dv},每个子集中的样本在A 上取值相同,则属性A 的信息增益为:

对于任何一个离散的数据集,可以通过计算每个属性在该数据集中的信息增益,然后根据需要选择相应的属性。

Fig.1 Flow of feature selection based on information gain图1 基于信息增益的特征选择流程
2.2 KNN 算法
K 近邻算法(K-Nearest Neighbor,KNN)是一种常见的分类算法。其基本思想是:假设给定一个训练数据集,其中的实例类别已定,KNN 算法通过计算待分类样本相似度最大的K 个邻近样本,然后通过这K 个邻居样本的类别采用投票方法确定待分样本所属类别。这K 个实例的多数据属于某个类,就将该实例分为这个类[18-19]。其算法如下:
输入:训练数据集T={(x1,y1),(x2,y2)…(xN,yN)}
其中,xi∈χ⊆Rn为实例的特征向量,xi∈y={c1,c2...ck}为实例类别,i=1,2,…,N;实例特征向量x;
输出:实例x所属的类y。
(1)根据给定的距离度量,在训练集T 中找出与x最近邻的k个点,涵盖这k 个点的x的邻域记作Nk(x);
(2)在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:
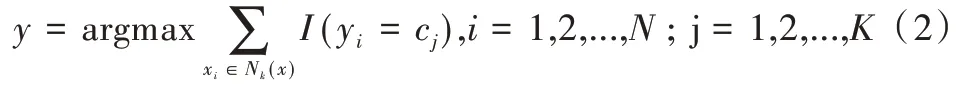
式(2)中,I 为指示函数,即当yi=cj时I 为1,否则为0。
3 检测模型
由于社交网络异常用户的多类特征均与正常用户有所区别,传统的特征提取方法会对用户原始数据进行提取,没有对初始数据集的特征作约简处理,在所保留的特征属性中存在着很多冗余属性。这对高维特征的检测效果非常有限,不仅影响分类器的工作效率,同实也降低了分类器的分类精度。鉴于此,本文通过对社交网络用户初始数据集进行特征选择,删除特征集中的冗余特征。
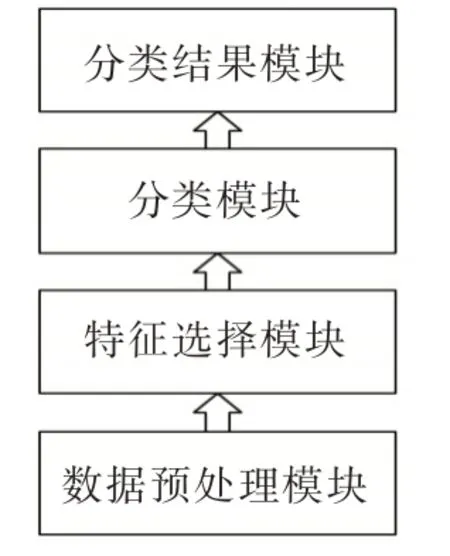
Fig.2 Classification module after feature selection图2 特征选择后的分类模块
分类算法设计是文本分类全部流程中最重要的环节,分类算法的优劣,将直接影响到分类性能的高低。一方面,随着机器学习技术的不断发展,越来越多高精度的分类算法被提出,分类准确性越来越逼近文本的真实类别分布,当然这些复杂算法的时间开销也很可观;另一方面,随着在线应用的普及,互联网对处理算法的时间开销要求越来越苛刻,决策树、朴素贝叶斯等轻量级的文本分类算法,分类效率较高,但在分类准确率上的不足使它们很难适应高性能应用场景。深度学习等人工神经网络方法和支持向量机等高准确率算法的时间复杂度较高,很难给在线应用带来满意的用户体验。KNN 算法作为一种典型的基于实例的分类方法,可以通过非常简单的分类机制达到可媲美复杂算法的分类准确率,是社交网络文本挖掘领域值得深入研究的算法。
信息增益特征选择算法既可以对社交网络用户初始数据集进行特征降维处理,删除数据集中的冗余属性,避免高维特征引发噪声,同时又能保留初始数据中的关键要素。因此,本文提出了一种基于信息增益的KNN 社交网络异常用户检测模型,如图3 所示。
具体步骤如下:
输入:社交网络用户数据集D。
输出:分类结果。
Step1:对原始数据集进行特征抽取。
Step2:计算数据集D 的经验熵H(D):
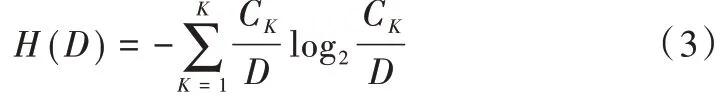
Step3:计算特征A 对数据集D 的经验条件熵H(D|A)。
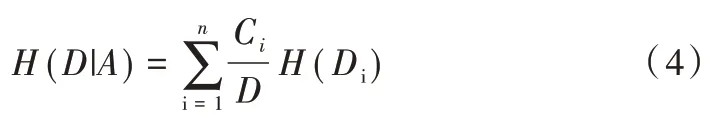
可进一步优化为:
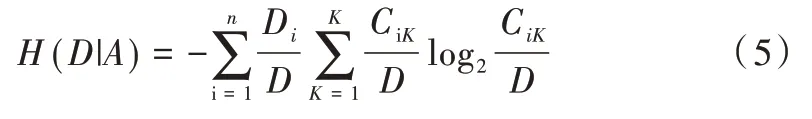
Step4:计算信息增益。
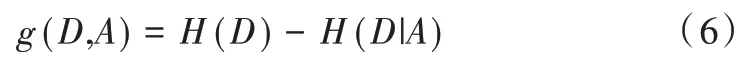
Step5:通过信息增益对数据集进行属性约简,确定优化后最终的特征集。
Step6:使用优化后的数据集构建KNN 分类器模型。
Step7:测试分类模型效果,得到测试结果。
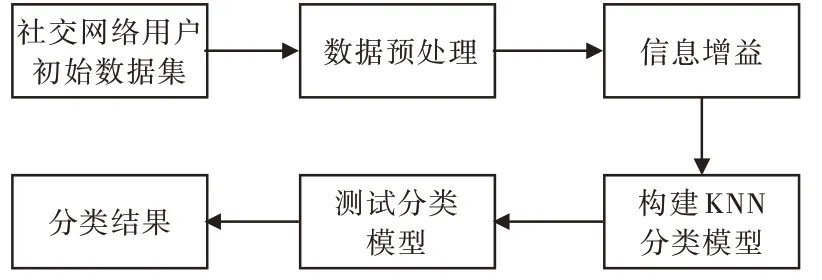
Fig.3 Information gain-based abnormal user detection model in KNN social network图3 基于信息增益的KNN 社交网络异常用户检测模型
4 实验分析
4.1 实验数据集
实验过程中使用的数据集来自Apontador 数据集[20],该数据集包含了正常用户和异常用户,其中异常用户又被分为3 种。表1 展示了本次实验数据集情况,在实验过程中将数据集分为正常用户和异常用户两类,对于Apontador中的广告发布者(LM)、内容污染者(PL)和不良言论发布者(BM)统一定义为异常用户。
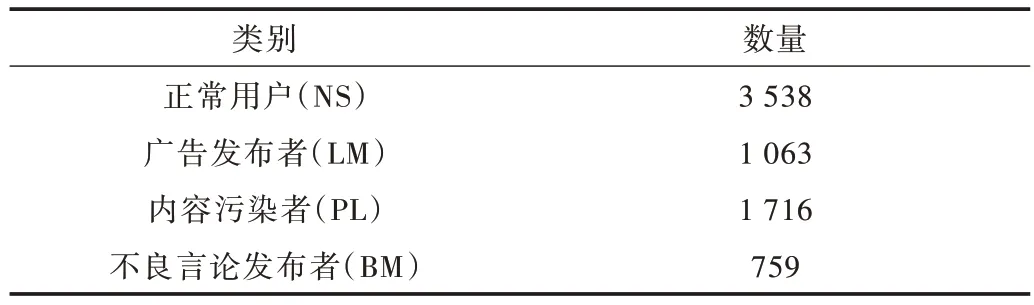
Table 1 User classification of Apontador dataset表1 Apontador 数据集用户分类
4.2 评价指标
在使用机器学习算法构建分类模型进行二分类时,常用评价指标有准确率、召回率、F 值。对于社交网络用户检测而言,在实验过程中更希望检测出更多的异常用户,避免异常用户逃避分类模型检测,因此需要将召回率作为评价指标。同时为了所构建模型的可用性,还需考虑分类结果的准确率。为此,将分类模型的精确率和召回率作为此次实验的评价指标。分类结果混淆矩阵如表2 所示。
其中,准确率表示为:


Table 2 Confusion matrix of classification results表2 分类结果混淆矩阵
4.3 实验结果
实验在开源的机器学习分析工具Weka3.9.2 环境下进行,分类结果比较如表3 所示。

Table 3 Comparison of classification results表3 分类结果比较
可以看出,使用信息增益对数据集进行特征选择后,所构建的分类模型在分类精确度和召回率上均优于传统的KNN 分类模型。其中,精确度由最初的91.3%上升到92.9%,提升了1.6%;召回率提升了2.3%。可以得出,本文提出的方法能够有效提升对社交网络异常用户的效果。
5 结语
本文将信息增益特征选择方法与KNN 算法相结合,提出了一种基于信息增益的KNN 社交网络异常用户检测模型。该模型在对社交网络异常用户的检测效果上优于传统检测方法,在使用机器学习算法对社交网络异常用户进行检测时,需要去除数据集中的冗余属性以达到提升分类效果的目的。
本文所构建的模型仅仅考虑了社交网络中的常规数据集,模型鲁棒性问题未予以考虑,在接下来的研究中可将多种算法相结合以构建分类模型,提升模型鲁棒性,使得模型的可用性更加广泛。
猜你喜欢
英语世界(2023年6期)2023-06-30
意林彩版(2022年2期)2022-05-03
北京航空航天大学学报(2021年6期)2021-07-20
数学小灵通(1-2年级)(2021年4期)2021-06-09
第一财经(2020年4期)2020-04-14
电子制作(2019年19期)2019-11-23
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年19期)2018-11-14
文苑(2018年17期)2018-11-09
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
