
基于预训练语言模型的建筑施工安全事故文本的命名实体识别研究
2021-05-13 13:30宋建炜邓逸川
图学学报 2021年2期
宋建炜,邓逸川,2,3,苏 成,2,3
基于预训练语言模型的建筑施工安全事故文本的命名实体识别研究
宋建炜1,邓逸川1,2,3,苏 成1,2,3
(1. 华南理工大学土木与交通学院,广东 广州 510640; 2.亚热带建筑科学国家重点实验室,广东 广州 510640; 3. 中新国际联合研究院,广东 广州 510555)
建筑施工安全事故分析是施工安全管理的重要环节,但分散在事故报告中的施工安全知识不能得到良好的复用,无法为施工安全管理提供充分的借鉴作用。知识图谱是结构化存储和复用知识的工具,可以用于事故案例快速检索、事故关联路径分析及统计分析等,从而更好地提高施工安全管理水平。命名实体识别(NER)是自动构建知识图谱的关键工作,目前主要研究集中于医疗、金融、军事等领域,而在建筑施工安全领域,尚未见到NER的相关研究。根据建筑施工安全领域知识图谱的应用需求,定义了该领域5类概念,并明确了实体标注规范。采用改进的基于Transformer的双向编码表征器(BERT)预训练语言模型获取动态字向量,并采用双向长短期记忆-条件随机场(BiLSTM-CRF)模型获取实体最优标签序列,提出了适用于建筑施工安全领域的NER模型。为了训练该模型并验证其实体识别效果,收集、整理和标注了1 000篇施工安全事故报告作为实验语料。实验表明,相比于传统模型,该模型在建筑施工安全事故文本中具有更优的识别效果。
知识图谱;命名实体识别;施工安全;预训练语言模型;事故报告
近年来,我国建筑施工安全形势虽然有所好转,但各类安全事故时有发生,施工安全问题仍不容忽视,其管理水平仍需进一步提高[1]。虽然施工安全事故数据及相关报告在不断积累,但在传统的施工安全管理中并不能充分利用这些信息,其原因在于缺乏将这些信息转化为可复用知识的手段。然而知识图谱以结构化的形式描述客观世界中的概念、实体及其关系,以接近人类认知世界的方式存储和利用知识,是一种组织和管理海量知识的工具[2]。施工安全领域知识图谱可用于事故案例快速检索、事故关联路径及统计分析等[3],同时可进行危险源挖掘、事故隐患发现以及事故处理方法检索[4],这些都将有助于提高施工安全管理水平。
目前,建筑行业在知识图谱方面的研究工作尚处于起步阶段。王丹和宫晶晶[5]基于建筑安全领域相关文献构建了该领域的知识图谱,从而通过可视化分析了该领域的热点问题。李骁[6]构建了建筑信息模型(building information modeling,BIM)知识体系的知识图谱,从而更好地指导BIM领域的研究与实践。牛聚粉和汪苏[7]基于结构健康监测领域相关文献绘制了该领域的知识图谱,通过图谱的可视化直观展现了国内外结构健康监测领域的研究状况。上述研究均使用了Citespace软件,根据文献作者、机构及其合作关系等数据构建知识图谱,并未涉及具体的建筑安全信息。王磊[8]和吴松飞[9]采用本体技术构建了建筑施工安全事故知识的本体库。BOUZIDI等[10]采用本体技术对建筑行业法规一致性检查的流程进行了简化。胡培宁和张金月[11]基于BIM和本体技术开展了建筑防火设计自动审查的研究。黄亚春[12]采用自然语言处理(natural language procession,NLP)技术对建筑施工安全事故报告中的风险因素进行研究,采用卷积神经网络(convolutional neural network,CNN)获得了文本分类模型。上述研究虽然考虑了建筑安全问题,但未涉及建筑施工安全领域的命名实体识别(named entity recognition,NER)问题。
实体是知识图谱的最小单元,NER是获取实体的关键。在NLP技术中,NER是指将文本中的实体按事先定义的类别进行分类。NER有3种方法[13]:①基于规则的方法[14],通过人工编写规则进行识别;②基于统计学习的方法[15-16],包括隐马尔可夫模型(hidden Markov model,HMM)、条件随机场(conditional random field,CRF)模型等;③基于深度学习的方法,根据输入的字向量直接抽取实体,实现知识图谱的自动构建,是当前NER方法的研究热点[17]。王莉[3]构建了城市轨道交通安全管理领域的知识图谱。LENG等[18]针对建筑行业的机械电气和管道(mechanical electrical and plumbing,MEP)系统开展了NER及关系抽取的研究,并构建了MEP领域的知识图谱。上述研究的NER部分采用了基于深度学习的方法,但输入的字向量是由Word2Vec[19-20]模型训练得到的静态字向量,不能全面表征字向量在不同上下文中的特征,从而影响命名实体抽取的准确率。
针对静态字向量不能反映字向量所在语境而导致NER准确性降低的问题,本文采用改进的BERT (Bidirectional Encoder Representations from Transformers)预训练语言模型[21]获取动态字向量,并采用双向长短期记忆-条件随机场(bidirectional long short term memory-conditional random field, BiLSTM-CRF)模型获取实体最优标签序列,提出了适用于建筑施工安全领域的NER模型。实验表明,本文模型具有理想的识别效果。
1 概念定义及实体标注规范
1.1 概念的定义
建筑施工安全领域NER旨在将建筑施工安全事故文本中的实体按事先定义的类别进行分类,这个“事先定义的类别”也称作概念。概念是对一类具有相同属性实体的抽象,实体是概念的实例化表示。概念的定义需要满足知识图谱的应用需求,如张宝隆等[4]在构建煤矿案例知识图谱时,根据实际需求定义了煤矿事故、危险源、事故地点、事故后果等概念。本文针对建筑施工安全领域知识图谱应用需求,定义了安全事故、施工项目、事故时间、事故地点和事故损失5类概念,见表1。
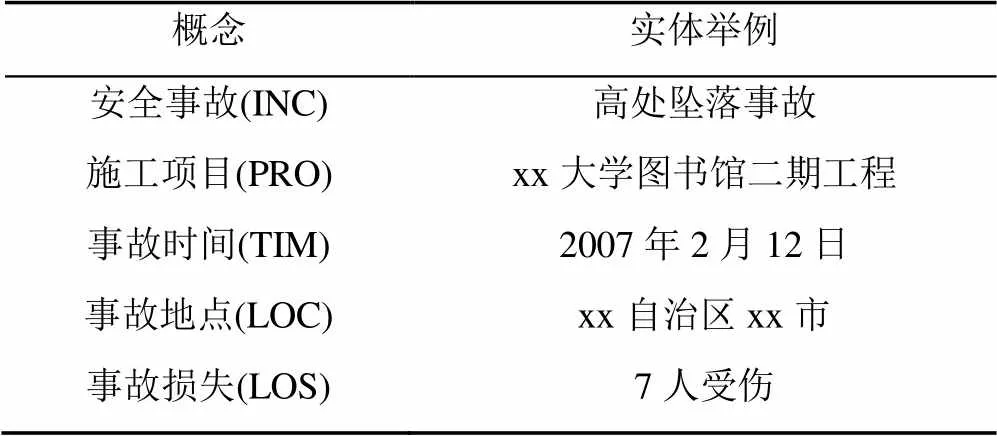
表1 施工安全事故领域概念
1.2 实体的标注规范
实体的标注采用“BIO”规范,其中“B-某概念”为从属于该概念的实体首字的标签;“I-某概念”为从属于该概念的实体其他字的标签;“O”为非实体字及符号的标签。根据以上实体标注规范,对应于表1所列的5类概念,可以得到11类标签,见表2。

表2 标签类别
图1给出了某文本的标签序列,该文本分别包括施工项目类实体“御景项目”和安全事故类实体“坠落事故”2实体。因此,“御景项目”实体中“御”字的标签为“B-PRO”,其他字的标签均为“I-PRO”;“坠落事故”实体中“坠”字的标签为“B-INC”,其他均为“I-INC”。而文本中“发生”一词并非实体,所以这2个字的标签均为“O”。

图1 实体标签示例
本文的主要工作是研究和提出适用于建筑施工安全领域的实体标注模型,实现该领域实体的自动识别。
2 NER模型的建立
2.1 BERT预训练语言模型及改进模型
2.1.1 BERT预训练语言模型
在NLP领域,通过使用大量未标注文本语料训练深层网络结构,从而得到字向量,这种深层网络结构被称为预训练语言模型[22]。早期的Word2Vec模型是静态模型,其得到的字向量未考虑上下文信息,对后续NER的准确率造成较大影响。针对这一问题,ELMO预训练语言模型[23]提出了考虑上下文信息的文本表示方法,但其采用的LSTM编码器在解决长期依赖问题上的表现不如Transform编码器[24]。因此,2018年Google提出了基于Transform编码器的BERT预训练语言模型(简称BERT模型),在基于字向量的NER、机器翻译、情感分类等任务中均取得了当时最好的效果。
BERT模型的网络结构如图2所示。从图中可见,Transform编码器与输入文本中每个字都相连,并通过其自注意力机制反映各个字之间的相关程度,从而使各个输出字向量都充分融合了上下文信息,以解决一词多义问题。王月等[25]采用BERT模型开展警情文本领域的NER工作,取得了91%的准确率。事实上,BERT模型采用遮挡语言模型(masked language model,MLM)和下一句预测(next sentence prediction,NSP)技术逐渐调整模型参数,使得模型输出的文本语义表示可以刻画语言的本质。

图2 BERT模型结构
2.1.2 改进的BERT模型
在传统的BERT模型中,虽然MLM与NSP这2个任务可以学习并输出包含上下文信息的字向量,但仍然存在一定的弊端。MLM任务采用字粒度掩码的方式进行训练,不利于学习完整的词义表示。因此,BERT-WWM(Whole Word Masking)预训练语言模型(简称BERT-WWM模型)改用全词掩码的方式进行训练[26],见表3。从表中可见,全词掩码方式用MASK标签替换一个完整的词而不是字,更符合中文构词方式,有助于提升预训练任务的效果。

表3 全词掩码示例
BERT-WWM-EXT模型是哈工大讯飞联合实验室发布的基于全词掩码的预训练语言模型[22],该模型在BERT-WWM模型的基础上增加了训练步数,同时采用了更大规模(包括了百科、问答、新闻等)的语料进行训练。
RoBERTa模型是Facebook发布的改进BERT模型[27],其在BERT-WWM模型的基础上提出一种动态的掩码机制,可以更深入掌握句子中的语义信息。此外,该模型还同时改进了BERT模型中的NSP任务,可以随机分割句子群,更加有利于学习句子之间的语义信息。
2.2 BiLSTM模型
长短期记忆(long short term memory,LSTM)模型[28]是带有门控单元的循环神经网络(recurrent neural net-work,RNN)模型[29],这些门控单元会对上一个节点的信息进行选择性记忆和传递。因此,相比于普通的RNN模型,LSTM模型在处理长序列文本方面表现更佳。此外,为了同时反映每个字的上、下文信息,GRAVES等[30]提出了BiLSTM模型,如图3所示。从图中可见,由预训练语言模型产生的字向量按照从左向右及从右向左的顺序分别输入正序及逆序LSTM单元,因此BiLSTM模型可以考虑2个方向的信息,综合输出字标签得分向量。

图3 BiLSTM模型结构[17]
2.3 CRF模型
对于图1所示的文本,由BiLSTM模型得到的各个字的标签得分向量如图4所示。从图中可见,“景”的标签得分向量景对应标签“O”的得分最高,故BiLSTM模型对该字的预测标签为“O”,而该字的正确标签为“I-PRO”,模型预测错误。出现错误的主要原因是,BiLSTM模型仅在字向量的层面进行计算,忽略了字标签之间相互约束关系,导致其所输出每个字的标签得分向量不够准确,从而出现上述错误的预测结果。

图4 CRF模型结构
实际上,相邻字标签之间是存在约束关系的,例如标签“B-PRO”后面不可能出现标签“I-INC”,文本开头的字标签不可能是“I-”标签。针对BiLSTM模型的不足,进一步将其输出的字标签得分向量输入CRF模型,如图4所示。CRF模型[31]考虑了各字标签之间的约束关系,利用每个字标签的得分与字标签之间的转移得分计算不同标签序列的出现概率,从中选取出现概率最大的序列作为所考虑文本的标签序列。图4中不同标签序列中最大出现概率为0.9,其对应于“景”的标签为“I-PRO”,预测正确,纠正了BiLSTM模型的误判。
2.4 BERT+-BiLSTM-CRF模型总体结构
本文综合采用改进的BERT模型、BiLSTM模型以及CRF模型(简称BERT+-BiLSTM-CRF模型),开展建筑施工安全领域的NER工作,见表4,其总体框架如图5所示。从图5可见,BERT+-BiLSTM- CRF模型首先采用改进的BERT模型由输入文本输出相应的动态字向量,然后采用BiLSTM模型进一步输出字标签得分向量,最后采用CRF模型输出文本的最优标签序列,实现命名实体的抽取。

表4 BERT+-BiLSTM-CRF模型

图5 BERT+-BiLSTM-CRF模型总体框架
3 NER模型评价指标

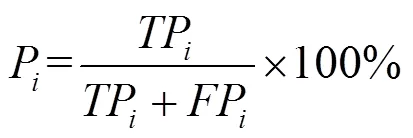
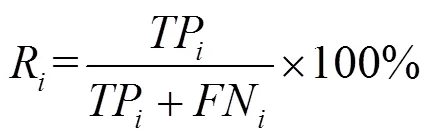

其中,TP为模型识别出的第类正确实体个数;FP为模型识别出的第类错误实体个数;FN为模型未识别出的第类正确实体个数。准确率P用于评估模型抽取第类实体的准确性,召回率R用于评估模型抽取第类实体的全面性。当2个指标不一致时,进一步采用二者的调和平均数F来评估模型对第类实体的识别效果。
除了考虑NER模型对各类别实体的识别效果,还需要考虑模型对所有类别实体的总体识别效果。为了考虑各类别实体数量差异的影响,不宜采用各类别评价指标的算术平均作为总体评价指标,可以采用加权平均的办法得到总体准确率总、总体召回率总和总体调和平均数总,即



其中,TP,FP和FN见式(1)和式(2)。
4 实验分析
4.1 模型搭建和参数设置
采用模型搭建工具Tensorflow[32]搭建NER模型,Tensorflow是由Google人工智能团队开发的适用于各类深度学习算法的框架。在BERT及其改进模块中,使用轻量化版本,将每次读取语料序列长度seq_设为128,处理句子数量_设为24,训练轮数取15。在BiLSTM模块中,采用可加速收敛的优化器Adam[33],训练学习率_设为2×10-5,采用[34]技术防止过拟合,值取为0.5。在CRF模块中,全连接层参数取为字标签类别数,在本文中取为11(表2)。
4.2 实验语料的合理规模
本文收集、整理了近十年1 000余篇建筑施工安全事故报告,获得1 000个长度在60字左右的文本,共计6万字左右的实验语料。除事故损失类实体数目较多外,大部分文本中都有一个类别的实体,总体来说,实验语料中各类实体总数分布较均衡,见表5。
本文采用标注工具YEDDA[35]对实验语料中出现的实体进行人工标注,实验语料中部分标注示例已在图1中有所体现,图6中补充了部分实体类别的标注示例。

表5 实验语料中各类别实体总数

图6 实验语料标注示例
按照8﹕1﹕1的比例将已标注的实验语料划分为训练集、验证集和测试集,其中训练集用于训练模型,验证集用于调整模型超参数,测试集用于评估模型识别效果。为了减少实验语料划分随机性产生的实验偏差,按照8﹕1﹕1的比例重复进行10次不同的训练集、验证集和测试集的划分,并对10次实验结果进行平均处理。
为了考察实验语料规模的合理性,基于3组不同规模的实验语料,采用RoBERTa-BiLSTM-CRF模型开展对比实验。分别考虑800、900和1 000个文本,实验结果见表6。从表中可见,采用900个文本作为实验语料所得到的总体准确率总、总体召回率总和总体调和平均数总,分别比采用800个文本所得到的总,总和总高2.64%,1.21%和1.95%,说明增大实验语料规模可以有效改善模型的识别效果。采用1 000个文本所得到的总和总分别又提升了0.63%和0.25%,而总略微降低了0.11%,说明了文本数量在1 000个左右较为合理,再扩大实验语料规模其识别效果已不明显。

表6 不同实验语料规模下的实验结果
4.3 实验语料的合理划分
为了说明实验语料划分比例的合理性,除了采用8﹕1﹕1比例外,还采用6﹕2﹕2比例将实验语料划分为训练集、验证集和测试集。在1 000个文本情况下,采用RoBERTa-BiLSTM-CRF模型进行对比实验,结果见表7。从表中可见,采用6﹕2﹕2比例所得到的总,总和总明显低于采用8﹕1﹕1比例所得到的结果,说明按照8﹕1﹕1比例划分实验语料是合理的。

表7 不同实验语料划分比例下的实验结果
4.4 模型总体识别效果对比分析
为了比较各种NER模型在建筑施工安全领域的总体识别效果,共开展7组对比实验。考虑前述1 000个文本,并按照8﹕1﹕1比例将实验语料划分为训练集、验证集和测试集,实验结果见表8。
从表8可见,BiLSTM模型的总比LSTM模型的总提高了7.93%,说明BiLSTM模型由于综合考虑文本正逆序双向信息而提升了总体识别效果。BiLSTM-CRF模型的总进一步提高了2.61%,说明CRF模型在考虑字标签之间约束关系后也提升了总体识别效果。采用BERT-BiLSTM-CRF模型后,总再提高了6.70%,说明BERT模型所获取的包含上下文语义信息的动态字向量对总体识别能力有较大的提升作用。结合改进的BERT模型后,BERT+-BiLSTM-CRF模型的总比BERT-BiLSTM- CRF模型的总提高了0.19%~0.91%,其中RoBERTa- BiLSTM-CRF模型的总体识别效果最好,原因是RoBERTa模型在BERT模型的基础上采用了动态掩码机制以及随机分割句子群技术,可以更深入理解文本的语义信息,从而进一步提升了模型的总体识别能力。
从表8还可见,不同模型识别出的实体总数不同,虽然识别出的实体总数不能用来衡量模型性能的好坏,但是模型的3个总体评价指标正是由模型识别出的正确与错误实体个数计算得到,这也恰好说明不同模型的总不同的原因。
4.5 各个类别实体识别效果分析
从表9还可见,事故时间和事故损失这2类实体识别的调和平均数均达到97%以上,主要原因有2个,一是事故时间与事故损失类别的实体都具有比较明显的边界特征,如事故时间多以“日、许、左右”等字结尾,事故时损失多以“死亡、受伤”等字结尾;二是这2类实体的长度适中,多为4~10个字左右。而施工项目、安全事故及事故地点这3类实体识别的调和平均数有所下降,在92%左右,原因分别是,施工项目类别的实体长度过长,多为10~20个字左右,如 “**有限公司**厂房拆除工程”等;安全事故类别的实体较为丰富导致边界特征不明显,如“**坠落”、“**坍塌”、“**触电”、“**中毒”等实体;事故地点类别的实体描述方式过多,同样导致边界特征不明显,如“**交叉路口”、“**市开发区”、“**市境内”等。

表8 各模型总体识别效果对比

表9 各类别实体识别效果对比
4.6 不同领域实体总体识别效果对比分析
为了对比不同领域实体的总体识别效果,表10给出了警情领域、信息化战争领域和本文所研究的建筑施工安全领域的数据规模、问题复杂度及实体识别总体评价指标值。从表10可见,虽然不同领域的文本内容各异,但三者的文本复杂度相近,其数据规模均为万字级,本文采用RoBERTa- BiLSTM-CRF模型所获得的建筑施工安全领域实体总体识别效果最好,从另一侧面也说明了本文模型更适用于不同领域的实体识别研究。

表10 不同领域实体总体识别效果对比
5 结 论
本文根据建筑施工安全领域知识图谱的应用需求,定义了该领域5类概念,并明确了实体标注规范。在此基础上,收集、整理和标注了1 000篇施工安全事故报告作为实验语料,提出了建筑施工安全领域NER的BERT+-BiLSTM-CRF模型,为该领域知识图谱的构建打下基础。所提出的模型综合采用了改进的BERT模块、BiLSTM模块和CRF模块。其中,改进的BERT模块可以获取包含上下文信息的动态字向量,BiLSTM模块可以获取包含文本正逆序双向信息的字标签得分向量,CRF模块可以考虑字标签之间的约束关系,从而获取文本最优标签序列。实验表明,相比于传统模型,BERT+-BiLSTM-CRF模型具有更优的总体识别效果,其中RoBERTa-BiLSTM-CRF模型同时采用了动态掩码机制及随机分割句子群技术,可以更深入理解文本的语义信息,对文本实体的总体识别效果最好。
限于本文所收集的实验语料的覆盖范围,所定义的建筑施工安全领域实体类别仅有5类。有必要进一步扩大该领域的实验语料覆盖范围,定义更完备的实体类别,并开展相应类别的实体抽取工作;考虑到NER的应用价值相对有限,后续会开展施工安全领域的关系抽取工作,从而更好地满足建筑施工安全领域知识图谱的应用需求。此外,考虑到大数据量下的实验语料人工标注难度较大的问题,后续研究会尝试半监督、无监督以及迁移学习的NER方法。
[1] 张扬. 建筑工程施工安全管理[J]. 城市建设理论研究: 电子版, 2017(11): 29. ZHANG Y. Safety management of construction engineering[J]. Theoretical Research on Urban Construction (Electronic Edition), 2017(11): 29 (in Chinese).
[2] 黄恒琪, 于娟, 廖晓, 等. 知识图谱研究综述[J]. 计算机系统应用, 2019, 28(6): 1-12. HUANG H Q, YU J, LIAO X, et al. Review on knowledge graphs[J]. Computer Systems & Applications, 2019, 28(6): 1-12 (in Chinese).
[3] 王莉. 基于知识图谱的城市轨道交通建设安全管理智能知识支持研究[D]. 徐州: 中国矿业大学, 2019. WANG L. Research on intelligent knowledge support for safety management of urban rail transit construction based on knowledge graph[D]. Xuzhou: China University of Mining and Technology, 2019 (in Chinese).
[4] 张宝隆, 王向前, 李慧宗, 等. 煤矿事故案例本体知识库的构建及推理研究[J]. 工矿自动化, 2018, 44(3): 35-41. ZHANG B L, WANG X Q, LI H Z, et al. Research on construction and reasoning of coal mine accident case ontology knowledge base[J]. Industry and Mine Automation, 2018, 44(3): 35-41(in Chinese).
[5] 王丹, 宫晶晶. 基于知识图谱的国内建筑安全领域可视化研究[J]. 工程管理学报, 2016, 30(6): 43-48. WANG D, GONG J J. Visualization research in China building safety analysis based on mapping knowledge domain[J]. Journal of Engineering Management, 2016, 30(6): 43-48 (in Chinese).
[6] 李骁. 基于知识图谱的建筑信息模型知识体系框架研究[D]. 重庆: 重庆大学, 2016. LI X. Research on the framework of knowledge system of building information model based on knowledge graph[D]. Chongqin: Chongqing University, 2016 (in Chinese).
[7] 牛聚粉, 汪苏. 基于知识图谱的建筑健康监测研究态势可视化分析[J]. 安全与环境学报, 2013, 13(5): 225-229. NIU J F, WANG S. Building & construction health monitoring research situation analysis based on knowledge topography[J]. Journal of Safety and Environment, 2013, 13(5): 225-229 (in Chinese).
[8] 王磊. 基于本体技术的建筑安全事故控制措施研究[J]. 现代商贸工业, 2018, 30(23): 195-196. WANG L. Research on control measures of building safety accidents based on ontology technology[J]. Modern Commercial Industry, 2018, 30(23): 195-196 (in Chinese).
[9] 吴松飞. 集成本体与自然语言处理的BIM建筑施工过程安全风险检查研究[D]. 广州: 华南理工大学, 2018. WU S F. Research on safety risk inspection of BIM building construction process integrating ontology and natural language processing[D]. Guangzhou: South China University of Technology, 2018 (in Chinese).
[10] BOUZIDI K R, FIES B, FARON-ZUCKER C, et al. Semantic web approach to ease regulation compliance checking in construction industry[J]. Future Internet, 2012, 4(3): 830-851.
[11] 胡培宁, 张金月. 基于BIM和Ontology的建筑防火设计自动审查的方法研究[J]. 工程管理学报, 2017, 31(2): 49-53. HU P N, ZHANG J Y. Research on automatic fire prevention checking in building design based on BIM and ontology[J]. Journal of Engineering Management, 2017, 31(2): 49-53 (in Chinese).
[12] 黄亚春. 基于自然语言处理的建筑工程安全事故报告风险研究[D]. 武汉: 华中科技大学, 2019. HUANG Y C. Research based on natural language processing for risk of construction accident reports[D]. Wuhan: Huazhong University of Science and Technology, 2019 (in Chinese).
[13] 刘浏, 王东波. 命名实体识别研究综述[J]. 情报学报, 2018(3): 329-340. LIU L, WANG D B. A review on named entity recognition[J]. Journal of the China Society for Scientific and Technical Information, 2018(3): 329-340 (in Chinese).
[14] 向晓雯, 史晓东, 曾华琳. 一个统计与规则相结合的中文命名实体识别系统[J]. 计算机应用, 2005(10): 2404-2406. XIANG X W, SHI X D, ZENG H L. A Chinese named entity recognition system combining statistics and rules[J]. Computer Applications, 2005(10): 2404-2406 (in Chinese).
[15] 韩普, 姜杰. HMM在自然语言处理领域中的应用研究[J]. 计算机技术与发展, 2010, 20(2): 245-248, 252. HAN P, JIANG J. Application and research of hidden Markov model in natural language processing domain[J]. Computer Technology and Development, 2010, 20(2): 245-248, 252 (in Chinese).
[16] 何炎祥, 罗楚威, 胡彬尧. 基于CRF和规则相结合的地理命名实体识别方法[J]. 计算机应用与软件, 2015, 32(1): 179-185, 202. HE Y X, LUO C W, HU B Y. Geographic entity recognition method based on crf model and rules combination[J]. Computer Applications and Software, 2015, 32(1): 179-185, 202 (in Chinese).
[17] 张晓海, 操新文, 高源. 基于深度学习的作战文书命名实体识别[J]. 指挥控制与仿真, 2019, 41(4): 22-26. ZHANG X H, CAO X W, GAO Y. Named entity recognition for combat documents based on deep learning[J]. Command Control & Simulation, 2019, 41(4): 22-26 (in Chinese).
[18] LENG S, HU Z Z, LUO Z, et al. Automatic MEP Knowledge Acquisition Based on Documents and Natural Language Processing[C]//36th CIB W78 2019 Conference: IT in Design, Construction, and Management. Newcastlez: Northumbria University, 2019: 800-809.
[19] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representation in vector space[EB/OL]. [2021-03-12]. https://www.semanticscholar.org/paper/Efficient- Estimation-of-Word-Representations-in-Mikolov-Chen/330da625c15427c6e42ccfa3b747fb29e5835bf0.
[20] LE Q V, MIKOLOV T. Distributed representations of sentences and documents[EB/OL]. [2021-03-12]. https:// arxiv.org/abs/1405.4053.
[21] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2021-03-12]. https://xueshu.baidu. com/usercenter/paper/show?paperid=147v0rh04e5c0a70qy4u0mc03q394989&site=xueshu_se.
[22] 李舟军, 范宇, 吴贤杰. 面向自然语言处理的预训练技术研究综述[J]. 计算机科学, 2020, 47(3): 162-173. LI Z J, FAN Y, WU X J. Survey of natural language processing pre-training techniques[J]. Computer Science, 2020, 47(3): 162-173 (in Chinese).
[23] PETERS M E, NEUMANN M, IYYER M, et al. Human language technologies[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics. New Orleans: NAACL Press, 2018: 2227-2237.
[24] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[EB/OL]. [2021-03-12]. https://www.isi.edu/ research_groups/insy/events/attention_all_you_need.
[25] 王月, 王孟轩, 张胜, 等. 基于BERT的警情文本命名实体识别[J]. 计算机应用, 2020, 40(2): 535-540. WANG Y, WANG M X, ZHANG S, et al. Alarm text named entity recognition based on BERT[J]. Journal of Computer Applications, 2020, 40(2): 535-540 (in Chinese).
[26] CUI Y M, CHE W X, LIU T, et al. Pre-training with whole word masking for Chinese BERT[EB/OL]. [2021-03-12]. https://github.com/ymcui/Chinese-BERT-wwm.
[27] LIU Y H, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2020-03-12]. https://xueshu.baidu.com/usercenter/paper/show?paperid=1m0e08s0bt7k0as0eg4a06d0t5223532&site=xueshu_se.
[28] GERS F A, SCHMIDHUBER E. LSTM recurrent networks learn simple context-free and context-sensitive languages[J]. IEEE Transactions on Neural Networks, 2001, 12(6): 1333-1340.
[29] BULSARI A B, SAXÉN H. A recurrent neural network for time-series modelling[M]//Artificial Neural Nets and Genetic Algorithms. Vienna: Springer Vienna, 1993: 285-291.
[30] GRAVES A, JAITLY N, MOHAMED A R. Hybrid speech recognition with deep bidirectional LSTM[C]//Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. New York: IEEE Press, 2013: 273-278.
[31] WOJEK C, SCHIELE B. A dynamic conditional random field model for joint labeling of object and scene classes[C]//Proceedings of the 10th European Conference on Computer Vision. Heidelberg: Springer, 2008: 733-747.
[32] ABADI M, AGARWAL A, BARHAM P, et al. TensorFlow: large-scale machine learning on heterogeneous distributed systems[EB/OL]. [2021-03-12]. https://xueshu.baidu.com/ usercenter/paper/show?paperid=360778c7d72e9e026f831d208324cc3f&site=xueshu_se.
[33] KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2019-01-10]. https://arxiv.xilesou. top/pdf/1412.6980.pdf.
[34] WAHLBECK K, TUUNAINEN A, AHOKAS A, et al. Dropout rates in randomised antipsychotic drug trials[J]. Psychopharmacology, 2001, 155(3): 230-233.
[35] YANG J, ZHANG Y, LI L W, et al. YEDDA: a lightweight collaborative text span annotation tool[EB/OL]. [2021-03-12]. https://xueshu.baidu.com/usercenter/paper/show?paperid=ac79fddaa9c91415f8f15be732ba89db&site=xueshu_se.
Research on named entity recognition of construction safety accident text based on pre-trained language model
SONG Jian-wei1, DENG Yi-chuan1,2,3, SU Cheng1,2,3
(1. School of Civil Engineering and Transportation, South China University of Technology, Guangzhou Guangdong 510640, China; 2. State Key Laboratory of Subtropical Building Science, Guangzhou Guangdong 510640, China; 3. Sino-Singapore International Joint Research Institute, Guangzhou Guangdong 510555, China)
The construction safety accident analysis plays an important role in construction safety management, but the construction safety knowledge scattered in accident reports cannot be reused, nor can it shed sufficient light on construction safety management. Knowledge graph serves as a tool for structured storage and knowledge reuse, such as retrieval of accident cases, analysis of accident-related paths, and statistical analysis. Named Entity Recognition (NER) is the key task of automatic knowledge graph construction, and currently mainly concentrates on medical, financial, and military fields. In the realm of construction safety, there has been an absence of relevant research on NER. In this paper, five concepts in this field were defined, and the entity labeling specifications were clarified. The improved Bidirectional Encoder Representations from Transformers (BERT) pre-trained language model was employed to obtain dynamic word vectors, and the Bidirectional Long Short-Term Memory-Conditional Random Field (BiLSTM-CRF) model was utilized to gain the optimal entity tag sequence, thus proposing the NER model for the field of construction safety. In order to train and verify the proposed model, 1,000 accident reports on construction safety were collected, sorted, and annotated as an experimental corpus. Experiments show that compared with traditional models, the proposed model can yield a better recognition effect in texts on construction safety accident.
knowledge graph; named entity recognition; construction safety; pre-trained language model; accident report
TP 391
10.11996/JG.j.2095-302X.2021020307
A
2095-302X(2021)02-0307-09
2020-09-04;
4 September,2020;
2020-10-21
21 October,2020
广东省自然科学基金项目(2018A030310363,2017A030313393);广州市科技计划重点项目(20181003SF0059)
Natural Science Foundation of Guangdong Province (2018A030310363, 2017A030313393); Key Project of Guangzhou Science and Technology Plan (20181003SF0059)
宋建炜(1994–),男,湖北襄阳人,硕士研究生。主要研究方向为建筑信息模型、自然语言处理。E-mail:sjwmmt@163.com
SONG Jian-wei (1994–), male, master student. His main research interests cover BIM, NLP. E-mail:sjwmmt@163.com
邓逸川(1989–),男,广东河源人,助理教授,博士。主要研究方向为建筑信息模型、计算机视觉。E-mail:ctycdeng@scut.edu.cn
DENG Yi-chuan (1989–), male, assistant professor, Ph.D. His main research interests cover BIM, computervision.E-mail:ctycdeng@scut.edu.cn
猜你喜欢
军事文摘(2022年24期)2022-12-30
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
厦门大学学报(自然科学版)(2021年4期)2021-06-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少先队活动(2020年12期)2021-01-14
计算机应用与软件(2018年9期)2018-09-26
领导科学论坛(2016年9期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
