
基于改进Rotor模型的客货共线铁路通过能力计算方法
2021-06-18 07:12李和壁田长海张守帅江雨星
中国铁道科学 2021年3期
李和壁,田长海,张守帅,江雨星
(1.中国铁道科学研究院研究生部,北京 100081;2.中国铁道科学研究院集团有限公司铁道科学技术研究发展中心,北京 100081;3.西南交通大学交通运输与物流学院,四川成都 610031;4.兰州交通大学交通运输学院,甘肃兰州 730000)
准确计算客货共线铁路通过能力是编制客货运输计划的重要依据,也是提高运行图利用率的基础。作为传统通过能力计算方法,扣除系数法利用不同类型列车时间占用比例反推区段通过能力,具有简单方便等优势,一直是我国铁路计算通过能力的主要方法。
近年来,扣除系数法的不足开始逐步凸显。随着我国高速铁路的快速发展,连发追踪旅客列车数量在运行图铺画中所占比重越来越大,而扣除系数法会引起连发追踪旅客列车的时间占用因素互相重叠的比例升高,难以得到符合实际的计算结果,无法正确评估会让、越行、停站带来的时间损耗对区段整体通过能力的影响。
除扣除系数法外,现行的客货共线铁路区段通过能力计算方法有图解法、UIC 406 压缩法等,相关学者对此进行了卓有成效的研究,从不同角度予以改进优化。文献[1—5]研究了不同等级列车共线时的扣除系数,并首次量化了扣除系数的计算式;文献[6]提出了不同中速列车数量对扣除系数与通过能力的影响;文献[7—9]从本质上分析了扣除系数法在高速铁路通过能力计算上无法继续适用的原因;文献[10]分析不同速度等级列车的混行比例与停站策略,确定了通过能力可达到最值的列车开行、停站比例;文献[11]利用STA 模态离散事件模型优化调度并计算区段通过能力;文献[12]利用元胞自动机模型,模拟分析了“高中速列车混行”模式下不同因素对通过能力的影响;文献[13]提出了中速列车相对于高速直达列车平均扣除系数的变化趋势;文献[14]对扣除系数法和平均最小列车间隔法进行了结合;文献[15]对越行车站数量与通过能力的关系进行了适用性研究;文献[16]根据现有旅客列车开行方案数据计算了各区段的通过能力及其评估指标;文献[17]分析了混合类型条件对高速铁路列车运行计划及通过能力计算平衡性影响;文献[18]提出在混合交通流条件下列车数、平均速度、稳定性、异质性及其相互关系对通过能力的影响;文献[19—24]采用基于UIC 406压缩运行图法实现通过能力的计算,但由于我国铁路存在大量跨线列车,该方法是否适用于我国铁路尚待论证。
随着我国铁路路网的延展,线上开行列车和中间站数量不断增加,因列车类型不同、列车停站位置不同产生的列车与邻车间组合类型将越来越多,扣除系数法等传统方法难以体现实际通过能力与非标准类型列车通行对数之间的关系,以及不能量化因此产生的时间损耗,因此会导致计算结果误差较大。
本文提出1 种基于改进Rotor 模型的全时迭代方法,可用于计算客货共线铁路通过能力。在确定运行图既有列车分层策略基础上,将运行图通过能力最优解问题转化为基于平行运行图逐层铺画不同种类开行列车,并求解每次铺画对运行图总通过能力影响最小的最值问题;依托京沪铁路徐州北下发场—蚌埠区段实际时刻表数据对算法进行验证,并与其他迭代方法和通过能力计算方法对比,证实其效率。
1 数据分层策略
传统扣除系数法难以体现实际通过能力与非标准类型列车通行对数之间的关系,且不能量化随之而来的时间损耗,导致计算结果误差较大。为了解决这一局限,首先对1昼夜内通过目标区段的列车相关初始数据进行分层,确定不同类型列车及天窗铺画顺序;再根据列车开行优先级,解决通过能力计算过程中不同类型列车互相干扰的问题,实现对各类型列车开行时刻调整的量化,并据此判断其对目标区段整体通过能力的影响。分层铺画的优先级层次如下。
(1)基础编辑列车,包括区段货物列车、直达货物列车等在中间站不停车的列车,为了达到通过能力的极限值,统一取区间运行速度最快的直达货物列车。
(2)不可编辑列车,包括跨线旅客列车、货运五定班列[25]等当前路局无权限调整(不可编辑)的列车,其特点为:开行时刻、停站方案均为定值。
(3)部分编辑列车,由局管内旅客列车构成,其特点为:开行对数、区间运行速度、停站方案是定值,但开行时刻路局可以调整,为可变值。
(4)完全编辑列车,包括摘挂列车等开行时刻、停站方案均可变且级别较低的列车。
(5)天窗起止时刻,考虑天窗时间一定的情况下,其开始、结束的具体时间会对区段通过能力数量产生损耗,故要将其作为迭代因子。
通过考虑不同类型列车等级及其相互之间的复杂组合,对既有列车采取特定分层策略,将计算目标区段客货共线铁路通过能力问题,转换为以平图基础编辑列车列数为起始目标值,逐层铺画并将每次铺画对目标值影响最小作为评价指标,最终使得目标值趋于最值的问题,再去除因为设置天窗导致的能力消耗,即是目标区段的最大通过能力。
2 改进Rotor模型及优点
2.1 简单Rotor模型
由于不同类型列车的会让、越行以及停站组合对整体通过能力的影响较大,而传统迭代模型又有计算效率较低、无法随着约束条件的变化进行动态迭代的劣势,为了计算不同类型列车混合开行下的客货共线铁路通过能力,需要选用1 种能够量化不同约束条件间相关性的模型结构,以实现各类型时刻的无损耗迭代。
简单Rotor 模型是1 种用于数据枚举的迭代算法,主要通过模仿密码锁解锁的方式为定义域是可列集的非连续多元方程寻优。假定1 把密码锁由3个转子构成,每1 个转子的遍历区域为1 到10,则一定可以通过103次迭代找到密码。
同理,若为某多元函数寻优,其目标函数Z为

式中:v为转子函数的数量;fi(xi)为目标函数的第i个转子函数,且1≤i≤v;xi为不同约束条件下的自变量。
假设fi(xi)的定义域基数为card(xi),若所有card(xi)均为正整数,则一定存在正整数φ,使得
2.2 改进Rotor模型
简单Rotor 模型虽然证明了遍历得解的必然性,但在解决某些复杂问题时,存在遍历空间较大导致计算效率过低的缺点。为此通过比照密码锁解锁过程中正确密码附近存在宽容区域,并可通过监听机械轻微响动提前确定上位密码等方法,从转子宽容度、分元枚举、转子约束3 个策略对简单Ro⁃tor模型进行优化。
(1)针对转子宽容度的改进策略。假设某密码锁的某位密码为x0,若该位密码的宽容度为Δx0,则x0-Δx0,x0,x0+Δx0均可作为密码子,即枚举时可以将2Δx0作为迭代参数以减少迭代量。由此,为共同影响目标函数Z的v个转子函数分别施加宽容度Δxi,取其步进的步长分别为2Δxi,则式(1)中的迭代量可由降低为。
(2)针对分元枚举的改进策略。对于式(1)中共同影响目标函数Z的v个转子函数,考虑到转子函数之间并无互相约束关系,因此可针对不同转子函数分别进行枚举,在后续迭代中只需对这v个转子函数分别进行迭代并求解最值,则式(1)中的迭代量可由再次降低为。
(3)针对转子约束的改进策略。对于式(1)中共同影响目标函数Z的v个转子函数,若以γ为转子函数间存在的某种互相约束条件,即存在f1(x1)=γ()f2(x2),将其代入式(1)中,则目标函数Z可表示为

至此,可将改进Rotor 模型的原理总结为:非线性函数的目标函数Z中,有v个转子函数,任一转子函数所对应的定义域的集合均为可列集,若第i个转子函数的定义域集合基数为card(xi),则可通过不大于次迭代,找到符合目标函数的最优解;同时,还可以通过宽容度、分元枚举与约束条件这3 种策略,进一步优化迭代空间。由此形成的改进Rotor模型如图1所示。

图1 改进Rotor模型运算过程示意图
2.3 改进Rotor模型的优点
(1)能够适应客货共线铁路通过能力的复杂计算。根据前文数据分层策略,客货共线铁路通过能力的目标函数为非连续函数,对于基础编辑列车、路局有权限调整的部分编辑列车与完全编辑列车,其开行时刻与合理的天窗时刻均在0~24 时范围内循环,且各类型列车数量可数,只有处于枚举状态的每个变量都达到最优值,才能使目标区段通过能力取到最大值。由改进Rotor 模型的原理可知,模型可解决这一复杂计算过程并为其寻得最优解。此外,利用改进Rotor 模型计算客货共线铁路通过能力,不仅可量化实际通过能力与非标准类型列车通行对数之间的关系,而且还可以考虑到越行、停站等因素对通过能力的影响,继而优化扣除系数法无法准确评估现行不同列车比例导致区段通过能力影响计算不准的问题。
(2)能够大幅减少迭代量。与同属于迭代方法的穷举法相比,改进Rotor 模型既可依据目标函数求出最优解,还可利用宽容度、分元枚举与转子约束这3 种策略大幅减少迭代量,使最终优化结果快速趋于收敛。例如,为求解某三元次方程在2 个约束条件下的最大值,在相同的计算机配置下,利用C#编程环境与GraphPad Prism 平台,采用常规穷举法、简单Rotor模型、改进Rotor模型3种方法得到的迭代曲线分别如图2所示。由图可知,以10 s为计算界限,常规穷举法因效率太低,无法在既定迭代次数既定计算时长内完成收敛;简单Ro⁃tor 模型的迭代次数为10 亿次,可在既定迭代次数内完成计算,但计算耗时较长,为6.43 s;改进Rotor模型的迭代次数为1万次,大大低于简单Ro⁃tor 模型,不仅可在最少迭代次数内完成计算,而且计算耗时较短,为0.54 s。可见改进Rotor 模型不仅优化了性能,还提升了效率。

图2 3种迭代策略的效率曲线与耗时对比
3 基于改进Rotor 模型的通过能力计算方法
由前文数据分层策略可知,需要迭代的参数是基础编辑列车时刻、部分编辑列车时刻、完全编辑列车时刻和天窗起止时刻。因此,算法中首先按照前述分层策略处理既有列车并使其集合化;再利用1 昼夜内通过目标区段的列车数一定为非连续正整数且可数的特点,将列车必须满足的最小追踪间隔时间作为参数,在考虑下层列车铺画对上层列车数量影响的基础上,利用改进Rotor 模型实现无损耗迭代;以直达货物列车平图通过能力作为起始目标值,通过逐层铺画使得目标值逐步优化,最终使得区段通过能力达到有效收敛。基于改进Rotor模型计算客货共线铁路通过能力的迭代流程如图3所示。

图3 基于改进Rotor模型计算客货共线铁路通过能力的迭代流程
3.1 模型参数及变量定义
定义如下模型参数:M为目标客货共线区段(简称目标区段)的区间数量,m为其中第m个区间;Z通为目标函数,即目标区段当前计算阶段的最大通过能力;N基础,N不可,N部分和N完全分别为运行图中当前铺画的基础编辑列车、不可编辑列车、部分编辑列车和完全编辑列车的数量;N天窗为因设置天窗而无法在运行图中铺画或从运行图中抽减的列车数量;T基础,T不可,T部分和T完全分别为当前运行图中铺画的基础编辑列车、不可编辑列车、部分编辑列车和完全编辑列车的占用时间;T天窗为天窗作业的占用时间,即天窗起止时刻内的时间;T交叠为因为越行、会让等因素造成的交叠折损时间;T空闲为运行图总空闲时间;l基础,l不可,l部分,l完全和l天窗分别为区间内实际开行的基础编辑列车、不可编辑列车、部分编辑列车、完全编辑列车和天窗作业导致无法开行或从运行图中抽减的列车;L基础,L不可,L部分,L完全和L天窗分别为基础编辑列车、不可编辑列车、部分编辑列车、完全编辑列车和天窗作业导致无法开行或从运行图中抽减的列车所对应的有序集合;Ts为模型整体迭代步宽。
对目标区段定义如下迭代参数:I追客和I追货分别为旅客列车、货物列车的最小追踪间隔时间;I发发,I发通和I发到分别为自前行列车从车站出发时起,至同方向后行列车从该站发出、后行列车从该站通过、后行列车到达该站时止的最小间隔时间;与之对应,I通发,I通通和I通到分别为自前行列车通过车站时起,至同方向后行列车从该站发出、后行列车从该站通过、后行列车到达该站时止的最小间隔时间;I到发,I到通和I到到分别为自前行列车到达车站时起,至同方向后行列车从该站发出、后行列车从该站通过、后行列车到达该站时止的最小间隔时间。
3.2 目标函数与约束条件
依据数据分层策略中的列车类型分层,提出计算目标区段通过能力的目标函数及其约束条件分别如下。
1)目标函数

2)约束条件
运行图中N基础列基础编辑列车的占用时间T基础为

运行图中N不可列不可编辑列车的占用时间T不可为

运行图中N部分列部分编辑列车的占用时间T部分为

运行图中N完全列完全编辑列车的占用时间T完全为

运行图中因天窗作业导致通过能力折损的时间T天窗为

此外根据运行图可知,算法迭代过程中还需满足式(9)的约束条件。

运行图铺画时,越行、会让等因素会带来列车安全距离上的交叠和空闲,由此产生交叠折损时间T交叠和T空闲。以完全编辑列车越行基础编辑列车为例,2列列车产生的T交叠和T空闲如图4所示。图中:l完全j和l基础p为产生交叠的列车;黄色和灰色阴影部分分别为这2 列列车的前后安全距离,其交叠部分即为T交叠;白色部分为相邻列车及其安全距离无法发生交叠的时间,即T空闲;所有类型列车及前后安全距离所构成的时间总和应满足运行图1昼夜时间等比例折算后的长度与区间数量M之积。

图4 完全编辑列车越行基础编辑列车时产生的交叠时间和空闲时间(局部)
3.3 迭代参数
由问题的复杂程度可知,式(3)中的目标函数难以通过常规方法求解,因此考虑借助改进Ro⁃tor 模型,通过有限迭代寻优的方法,计算得到目标区段的最大通过能力。
为了得到可以满足上述间隔时间的插入时刻,插入非基础编辑列车时需分别遍历得到前行车站第1 个满足参数的出站时刻与后行车站第1 个满足参数的到站时刻,以此为基础,分别向后以1 min 为间隔步进迭代,直至满足如图5所示的5 个参数,则构成可以插入的第1 列非基础编辑列车。图中:l前行基础为前行基础编辑列车;l后行基础后行基础编辑列车;l待插入为待插入运行图中的非基础编辑列车;T1,T2,T3,T4和T5为目标区段行车过程中应满足的时间条件,其中T1,T2分别为l前行基础出站、到站时间与l待插入出站、到站时间的间隔,T3,T4分别为l待插入出站、到站时间与l后行基础出站、到站时间的间隔,T5为l待插入的区间运行时间。

图5 运行图中插入非基础编辑列车需满足的条件(局部)
由图5 可知:为求得能插入货物列车的极限数量,T1,T2和T5须与目标区段I发发,I通通,I到到,I通发,I发通,I通到,I到通,I发到,I到发,I追客和I追货这11种时间间隔适配,即T1,T2和T5刚好等于能满足这些间隔的运行时间;同时,为实现通过能力的极值计算,假设在插入列车后才允许时间出现一定冗余,即T3和T4不仅须与这11 种时间间隔适配,而且还需要大于等于满足这些间隔的运行时间,并在后继的运算过程中将这些时间间隔作为迭代参数。
3.4 计算过程
步骤1:分类与集合化
根据数据分层策略,按时刻表将某区间实际开行的列车类型划分为与转子函数对应的有序集合,有

此时目标函数转换为

其中,
L基础=L不可=L部分=L完全=L天窗=0
步骤2:过滤并铺画平行运行图底图
取速度最快的1 列直达货物列车作为数据准备,对应式(10)中的L基础,从0 时开始,将这一直达货物列车最小追踪间隔I追货铺满全图,作为客货共线铁路通过能力计算的基础,如图6所示。

图6 铺满直达货物列车的平行运行图底图
由图6 可知,此时有L不可=L部分=L完全=L天窗=0,迭代初始时间时分为0,代入式(15),得到现阶段目标区段的最大通过能力Z通为

步骤3:插入不可编辑列车集合L不可
式中:L货平为作为平行运行图底图铺画的货物列车的有序集合。
不可编辑列车集合下的跨线旅客列车或五定班列在本区段无调整权限,对应式(11)中的L不可,故其到发时刻均是固定的,每插入1 列此类列车,均需要满足前节的迭代参数,而这必定会对上层的列车基础编辑列车的数量产生影响,即:会使之前铺画的直达货物列车整体后移并导致现有列车总数降低。插入L不可之后,得到的运行图如图7所示,图中红色线条为新插入的所有不可编辑列车。

图7 插入不可编辑列车集合之后的运行图
由图7 可知:在1 昼夜可容纳列车总数可数的约束下,插入L不可后,L基础的基数减少,则现阶段目标区段的最大通过能力Z通为

其中,
L部分=L完全=L天窗=0式中:L基础'为因插入L不可而发生改变的基础列车集合;角标'代表因插入下层列车而发生的上层列车集合改变,后同。
步骤4:插入部分编辑列车集合L部分
部分编辑列车集合下各元素的开行对数、区间运行速度、停站策略是定值,即其运行线线型不变,但位置可变,对应式(12)中的L部分。要找到对当前通过能力影响最小的插入时刻,可利用改进Rotor 模型迭代,固定基础编辑列车有序集合中的第1 个元素,即固定l基础1在Ti时分,在(Ti+1)时分插入部分编辑列车有序集合中的首个元素l部分1,看是否可以满足迭代参数,如果满足则插入该元素对应的列车;如果不能,则让l部分1以1 min的间隔步进。2 种不同L部分的插入时刻对目标区段整体通过能力的影响如图8所示,图中蓝色线条为新插入的所有部分编辑列车。

图8 2种不同的部分编辑列车插入时刻对目标区段通过能力的影响
由图8 可知:图(a)中l部分1,l部分2没有产生过多的交集,因此带来的T交叠比较大,导致L基础减少6 列;图(b)中n部分1插入位置靠近l部分2,只使得L基础减少3 列。因此第2 种L部分的插入时刻是更优的选择,而第1 种l部分1的插入时刻会在迭代中被遗弃。
继续步进l部分1,最终迭代次数为运行图1 昼夜总分钟数减Ts所在的时刻,即(60×24-1)次,得到Z通并取其中的最大值,这即是插入l部分1可产生的最佳列车总和。取L部分中的第2 个元素l部分2,继续上述循环迭代,直至L部分中所有的元素均被迭代,即每列列车以及每列列车在每个区间的运行时间均满足迭代参数中的11 种间隔时间,且由此产生的时间损耗T交叠最小,所得各类通过列车的数量之和最大,即Z通为

其中,
L完全=L天窗=0式中:min(N交叠)为因为插入下层列车造成越行或停站因素导致通过能力减少的列数。
步骤5:插入完全编辑列车集合L完全
L完全下的各元素主要是摘挂列车等开行时刻、停站策略均是可变值且级别较低的列车,在优化过程中不仅位置、线型均可变,而且没有停站时间的限制,对应式(13)中的L完全。因此,这里的插入策略主要是不改变之前已插入列车位置数量的前提下,在间隙中插入列车,如图9所示,图中黄色线条为新插入的所有完全编辑列车。

图9 插入N完全编辑之后的运行图
由图9 可知,则现阶段目标区段的最大通过能力Z通为

其中,
L天窗=0
步骤6:迭代天窗作业的占用时间T天窗
排除天窗时间对通过能力的影响,这里取客货共线最常用的“V”型天窗模式。选择区段内第1个区间,从0点0分开始,至23点59分止,按T天窗时间为步长,得到每次迭代之后的目标区段整体通过能力,并取其最大值;接着取第2 个区间,继续上述循环,直到找到1组关于T天窗的起止时刻,不仅可满足所有T天窗均以I追货为等差递增排列,且由此产生的时间损耗T交叠最小。如图10所示。图中蓝色斜线区域为迭代得到的天窗作业占用时间。

图10 迭代T天窗之后的运行图
步骤7:确定模型整体迭代步宽Ts
将Ts迭代I追货次,每次迭代时均需得到该次迭代所对应的最优通过能力,并求得每次迭代所得Z通的最大值。至此,可得出既满足不调整跨线列车,又满足可调整的区段旅客列车,兼顾铺满普通货物列车,同时每列车之间的关系满足3.3中的11种列车间隔,也能考虑到最优的天窗起止时刻,从而得到此区段非平行运行图的最大通过能力,即Z通为

同时,各类型列车的总运行时间还需满足

步骤8:填充运算过程中删除的基础编辑列车N补全
为得到通过能力的余量,在已经迭代成功的运行图上,将运算过程中被删除的基础编辑列车进行补全。为了不影响已经迭代成功的能力,只对图9中的黑色虚线进行分段补全,分别取目标区段每个区间满足迭代参数要求的可补全数量并组成集合,该集合最小值即为最终可通过补全逻辑增加的能力N补全。
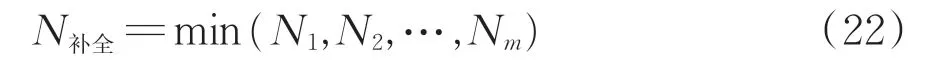
式中:N1为目标区段第1 个区间可以增加的能力;Nm为目标区段第m个区间可以增加的能力,1≤m≤M。
若N1—N补全均满足既不影响固有线型又符合3.3 中的迭代参数,则可通过式(20)和式(22),最终计算得到目标区段的最大通过能力为

4 算例验证
4.1 数据描述
为验证本文方法的有效性,选取京沪铁路徐州北下发场—蚌埠区段时刻表数据进行实例分析,并采用铁路局通用的EXCEL 格式列车时刻表作为数据基础,因铁路使用习惯并不适用作为模型输入结构,故将其做标准化算法处理,得到表1,表中行表示目标区段经由车站;列表示路局提供原始时刻表列车车次;点及其取值表示该点纵向对应的列车车次经由横向对应车站时的到发时刻。

表1 经过标准化处理之后的数据实例(局部)
为对比不同计算方法对目标区段通过能力的计算影响,将标准化处理后的数据作为构建计算模型的输入数据源,结合站场布局,将徐州北下发场—符离集区段定义为数据集1,符离集—蚌埠东区段定义为数据集2,按记录区段内各类开行列车的相关信息示意图如图11所示,图中不同色块代表原始时刻表中不同类型列车的比例。该区段的运营里程为177 km,设站16 座,平行运行图通过能力为188 列。由图11 可知:数据集1 中有旅客列车69列、货物列车51列;数据集2 中有旅客列车74列、货物列车65列。

图11 实验数据分层
4.2 迭代参数
列车间隔种类与间隔时间发生改变会引起算法运行过程中待插入列车的起止时刻的改变。在改进Rotor 模型中,为了将所有时刻进行无损耗迭代,且满足3.3 中迭代参数要求,经查定,统计目标区段行车过程中会产生的列车间隔见表2。

表2 徐州—蚌埠间列车间隔 min
4.3 计算验证
基于上述数据、参数与评价指标,使用配置为CPU I7-7700、内存16G 的计算机,采用C#语言环境,建立客货共线铁路的通过能力计算模型,求解徐州北下发场—符离集区段与符离集—蚌埠东区段客货共线铁路的整体通过能力,并依托2 个数据集,分别进行不同迭代方法间的纵向效率对比与不同计算方法间横向性能对比,对改进Rotor 模型的计算效果进行验证。
1)纵向效率对比
分别计算枚举法、简单Rotor 模型法与改进Rotor 模型法得到的通过能力,3 种算法的耗时以及优化过程如图12所示。由图可知,纵向对比3种迭代算法,简单Rotor 模型法与枚举法无法在既定计算时间内达到有效收敛,而基于改进Rotor 模型的算法能够在既定计算时间内达到有效收敛,证实了算法效率。

图12 不同迭代算法计算耗时及优化过程对比
2)横向性能对比
分别计算扣除系数法、图解法、路局反推法与改进Rotor 模型法得到的通过能力,4 种算法计算结果如图13所示。由图可知,横向对比4种通过能力计算方法,改进Rotor 模型法基于2 个数据集得到的通过能力最大,其结果不仅最接近于路局反推法,而且还能找出其他方法无法得到的能力余量(路局反推法虽无科学依据,但经过多年现场实用,在一定程度上具有指导意义),证实了算法性能。

图13 不同通过能力计算方法结果对比
4.4 性能评价
1)评价指标设置
因要满足3.3 中提到迭代约束,插入不同层次列车必然会对上层列车在图列数产生影响,即每次插入列车会使式(3)中目标函数Z通改变,针对下层列车集合中的每种插入时刻均会产生1个对插入前目标函数的影响值,且不同的插入时刻对通过能力的影响不同,若将可插入时刻集合化,则可利用式(23)作为性能指标,判定新插入列车是否可行。


式中:β为空闲时间占用率,即目标区段运行图总空闲时间占总运行时间的比例。
2)评价结果
通过改进Rotor 模型计算目标区段客货共线铁路通过能力,并利用前文评价指标进行评价,结果见表3,其中优化前的数据来自路局实际运行图。由表3 可知,优化后,区段通过能力平均提升9 列(以作为平行运行图底图的基础编辑列车衡量),区段空闲时间占用率平均降低11.05%,实现了对算例线路的通过能力挖潜。

表3 算法评价结果
4.5 算例性能总结
综合横向效率对比、纵向性能对比以及性能评价可知,改进Rotor 模型法不仅可以充分考虑目标区段各类型列车条件,更可以计算得到空闲时间占用率较低的区段通过能力,兼备效率与性能优点,对铁路运输企业现场分析区段通过能力、提高平图通过能力以及制定行车组织方案有一定参考意义,可用于客货共线铁路运输计划的编制与挖潜。
4 结论
(1)依据密码锁转子解锁原理,提出1 种基于改进Rotor 模型的区段通过能力计算方法,将运行图的通过能力最优解问题转化为基于平行运行图逐层铺画开行列车,并使每次铺画对运行图影响最小的最值求解问题。
(2)充分考虑情况复杂的不同类型列车间运行关系及天窗作业,提出由基础编辑列车、不可编辑列车、部分编辑列车、完全编辑列车以及天窗起止时刻组成的列车分层策略,并基于改进Rotor 模型,解决当前客货共线铁路通过能力计算中,因列车类型不同、列车停站位置不同以及列车与邻车间组合类型太多导致计算结果与实际能力存在误差的问题。
(3)基于京沪铁路徐州北下发场—蚌埠区段时刻表的2 个数据集对本文算法进行验证。纵向对比3 种不同迭代方法的计算效率,与枚举法、简单Rotor 模型法相比,本文算法收敛耗时最短、计算效率最高;横向对比4 种不同通过能力计算方法的性能,与扣除系数法、图解法、路局反推法相比,本文算法平图利用率充分、计算性能最优;对比路局的实际运行图数据,本文算法得到的区段通过能力平均提升9 列(以作为平行运行图底图的基础编辑列车衡量),区段空闲时间占用率平均降低11.05%。本文方法可指导实际,用于铁路运输企业客货共线铁路运输计划的编制与挖潜。
(4)本文提出的模型目前只用于客货共线区段通过能力计算,算法所列皆为双线运行图,若单线情形,则复杂性大大增加,一些步骤无法适用,未来可考虑应用在单线铁路区段上进行改进。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
教学月刊(小学版)(2021年26期)2021-09-30
中等数学(2021年4期)2021-08-14
中学生数理化·高一版(2021年5期)2021-07-21
劳动保护(2019年7期)2019-08-27
模具制造(2019年3期)2019-06-06
铁道通信信号(2018年7期)2018-08-29
汽车维护与修理(2017年17期)2017-02-07
铁道通信信号(2016年10期)2016-06-01
中国铁道科学(2015年4期)2015-06-21
