
基于支持向量机的高速铁路地震预警震级连续预测方法
2021-06-18 07:12宋晋东朱景宝李山有
中国铁道科学 2021年3期
宋晋东,朱景宝,李山有
(1.中国地震局工程力学研究所,黑龙江哈尔滨 150080;2.中国地震局地震工程与工程振动重点实验室,黑龙江哈尔滨 150080)
地震是1 种对铁路行车安全危害极大的突发性自然灾害,即使是较小震级的地震,对路基、轨道和桥梁等造成的冲击都可能导致危害旅客生命安全的重大事故[1-4]。高速铁路地震预警系统是减轻地震带来重大损失的有效手段之一。如果能够在地震的破坏性震动到来前,对高速铁路提早哪怕是短短的几十秒甚至几秒实施报警并开展紧急处置,都能够大大降低旅客生命、财产损失的发生概率[5]。随着我国高速铁路的迅猛发展,建设高速铁路地震预警系统并提升地震预警能力迫在眉睫,同时,相关研究也将为穿越多个地震断裂带的川藏铁路设计建设提供支持参考。
震级预测是高速铁路地震预警的重要环节,地震预警信息发布、地震影响范围判断、紧急处置控车范围确定等都依赖震级预测的结果。震级预测通常利用P 波初期特征参数与震级的线性比例关系,并依据这个比例关系建立预测震级的模型。预测模型中,采用的特征参数主要分为2 大类,即周期类参数[6-10]与幅值类参数[11-13],基于这2 类参数的常用震级预测模型分别是τc方法[6]与Pd方法[11]。
在基于网状密集布设地震监测台网的地震预警系统中,震级估计可以采用加权平均或多台信息协同处理等方式。与地震行业不同的是,因铁路具有线性特征,高速铁路地震监测台站只能在铁路沿线呈稀疏线性布设,受台站数量、分布等方面的限制,高铁地震预警只能采用单台震级估计的模式,因此需要建立准确性更高的震级预测模型。
既有高速铁路地震预警通常利用地震P波到达后3.0 s 的固定时间窗进行震级预测,而常用的震级预测模型τc方法与Pd方法,都只用到地震波初期的单一参数特征,导致预测模型的泛化能力低,预测结果的离散性大,小震高估与大震低估现象明显,且建立特征参数与震级的线性比例关系时需要筛选震中距与信噪比。随着大数据分析技术的快速发展,机器学习方法在地震预警领域的应用逐步扩大,一些学者、专家将机器学习方法应用于地震预警震级预测的研究中,例如,马强[7]基于人工神经网络建立了多个参数与震级的关系,Reddy等[14]使用支持向量机的方法建立了小波系数与震级的关系,这些工作为利用多参数输入与人工智能方法进行震级预测提供了可行性参考。
为尽早发出准确的地震预警警报,满足高速铁路地震预警警报随时间变化而不断更新的要求,实现“在3.0 s 以内提高震级预测的准确性、3.0 s 以后提高震级预测的连续性”的目标,本文选取P波到达后的0.5~10.0 s 范围内,以0.5 s 为间隔时间建立预测时间窗,利用日本K-net 强震动数据,基于人工智能机器学习领域经典的支持向量机(Sup⁃port Vector Machine,SVM)方法,以幅值参数、周期参数、能量参数、衍生参数这4 大类共计12 个P 波特征参数作为SVM 的输入参数,构建支持向量机的高速铁路地震预警震级预测模型(SVM-based High-speed Railway Magnitude Pre⁃diction Model,SVM-HRM),将3.0 s 时间窗下的震级预测结果与τc方法与Pd方法分别对比,并依据现行的《高速铁路地震预警监测系统试验方法》的相关条文[15],将统计得到的震级预测实现率与实现率标准进行对比,旨在为中国高速铁路地震预警系统的建设与完善提供借鉴与参考。
1 数据及处理
机器学习算法需建立在大数据统计的基础上。中国现有的高铁地震监测台站记录到的数据较为有限,而日本的K-net 强震观测台网采用了与前者类型相同的强震观测台站,且记录有海量的高质量强震数据,因此本文的研究主要选用日本K-net 强震观测台网[16]数据,并基于以下原则选取强震动数据[17]。
(1) 发震时刻:2007年10月1日至2017年9月1日。
(2) 发震区域:日本岛内及周边海域。
(3) 震源深度:10 km范围以内。
(4) 地震震级:范围在3~8级之间。
(5) 震中距:未做筛选。
对选取的数据进行如下处理。
(1)采取马强等[18]与王子珺等[19]提出的方法,对加速度数据进行P波到时自动捡拾,并做人工核对。
(2)对加速度数据进行一次积分得到速度记录,对速度记录进行一次积分得到位移记录,对积分后的记录进行0.075 Hz 巴特沃斯高通滤波,消除积分带来的低频漂移影响。
(3)考虑到特征参数值巨大变化产生的数值失真,以及模型的训练效率提升等问题,取P波到达后0.5~10.0 s 的时间范围内,以0.5 s 为间隔计算特征参数,对数据依次进行归一化处理,归一化方法可表示为

其中,
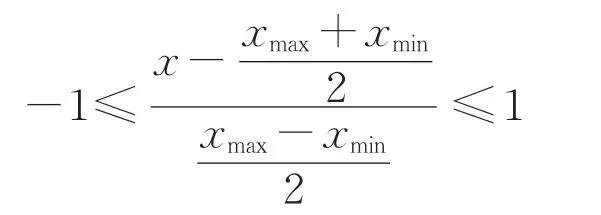
式中:bg为各个特征参数归一化的结果;x为各个特征参数对应的数据;xmax和xmin分别为相应P波特征参数的最大值和最小值。
经过处理,共筛选出地震1 837 次,强震动数据19 263组、57 789条,记录到强震动数据的台站922 个,筛选得到的地震震中与记录台站分布如图1所示。图中,红色空心圆表示地震震中位置,圆的直径与震级大小成正比;绿色三角形表示记录到数据的台站。

图1 选取的日本地震震中及K-net台站分布
将筛选得到的强震动数据随机划分为互不重复的2 组,即训练数据集和测试数据集,其中训练数据集占全部数据的80%,共有数据15 410 组、46 230 条;测试数据集占全部数据的20%,共有数据3 853 组、11 559 条。筛选数据的震级、震中距和记录数量关系如图2所示,图中绿色圆点表示用于建立SVM-HRM 预测模型的训练数据集,红色圆点表示用于测试SVM-HRM 预测模型的测试数据集。

图2 震级与震中距、记录数量的关系
2 模型特征参数
高铁地震预警只能采用单台震级估计的形式,对准确度的要求更高,因此在分析震级估计结果时需要融合多种参数。本文以获得最优预测结果为目标进行参数设置,选取幅值参数、周期参数、能量参数、衍生参数这4 大类共12 个特征参数作为支持向量机的高速铁路地震预警震级预测模型SVMHRM 的输入参数,其中,幅值参数、能量参数、衍生参数均进行震源距修正,统一校正到参考震源距10 km[12,20-21]。各特征参数的定义分别如下。
1)幅值参数
包括峰值位移Pd[11]、峰值速度Pv和峰值加速度Pa,计算式分别为
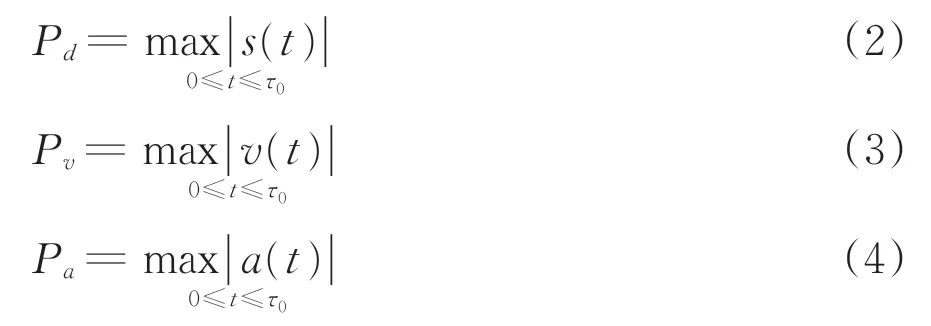
式中:0 为P 波的到达时刻;τ0为P 波到达后的时间窗长度;s(t)为竖向位移时程;v(t)为竖向速度时程;a(t)为竖向加速度时程。
2)周期参数
包括特征周期τc[5]、峰值比Tva[6]和构造参数PP[8],计算式分别为

式中:r为依据帕塞瓦尔定理取的中间变量。

3)能量参数

式中:a3(t)为三分向合成的加速度。
4)衍生参数
包括竖向累积绝对位移cad、竖向累积绝对速度cav和竖向累积绝对加速度caa,计算式分别为

3 预测模型算法
支持向量机是人工智能领域中1 种基于统计学习的机器学习方法,可利用多个参数来进行模式分类以及非线性回归分析[21]。本文利用前述筛选得到的训练数据集,在获得其拟合函数的基础上,建立支持向量机模型算法,算法的关键是确立高斯核参数与训练参数。
3.1 支持向量机算法
定义参数:f(X)为预测震级;W为各特征参数的权重向量;X为特征参数组成的向量;b为截距;n为训练集数据数量,i为其中第i条数据;yi为与特征参数对应的震级;E为容忍误差。利用线性回归函数f(X)=WT∙X+b,对基于前述训练数据集计算得到的4大类共12个参数进行拟合。
假设经过拟合,所有的样本数据都可以在[-E,E]范围内通过线性函数f(X)表示[22],其数学表达式为
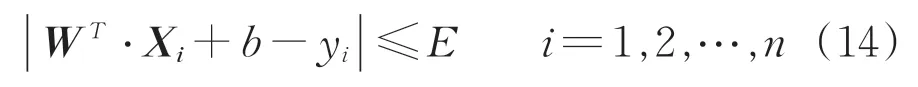
在此基础上,通过如下步骤建立支持向量机模型。
1)问题转化
优化数据点与线性回归函数之间的距离,并将计算距离问题转化为极值问题,则有

式中:‖W‖为权重向量的模。
2)引入惩罚参数
不同于最小二乘拟合法,支持向量机算法允许一定范围内的拟合误差,所以可引入惩罚参数C,表示超出允许误差时对样本的惩罚程度,并将式(16)的目标函数(极值计算式)转化为
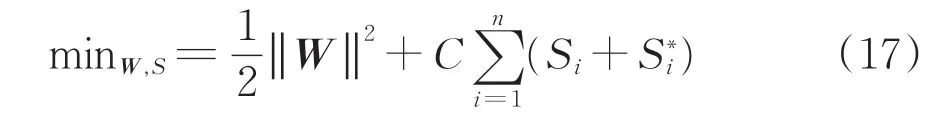
其中,

支持向量机的线性回归函数与损失函数之间的关系如图3所示。图中的实线表示线性回归函数,虚线范围[-E,E]称为容忍误差范围,表示支持向量机的超平面。如果落在虚线范围内的样本点(空心圆)的误差可以忽略不计,那么落在这2 条虚线上的样本点(红色实心圆)则记为支持向量;落在虚线范围外的样本点(空心圆),即表示超过[-E,E]范围,就可记为损失函数S。

图3 支持向量机的线性回归函数与损失函数
3)目标函数转化
为了解决第2 步中的极值问题,将上述的目标函数转化为拉格朗日函数,从而解决有约束下的极值问题,由此,式(17)可转化为

式中:α,β,γ为拉格朗日因子。
4)求拉格朗日函数
对式(18)求导,分别得到
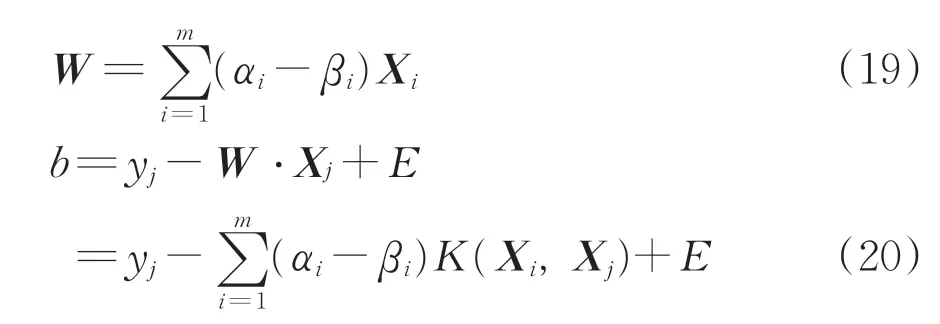
式中:αi,βi不同时为0,且αi>0;K(Xi,X)为支持向量机的核函数。
通过以上4 步即可以得到支持向量机的线性回归函数为

3.2 支持向量机的高斯核参数
支持向量机与线性回归最重要的区别在于,前者通过核函数运算,将样本数据映射到高维空间,即:基于非线性函数的线性组合,其网络结构如图4所示。图中的样本点X基于i个支持向量进行非线性变换K(Xi,X),再基于支持向量机的线性回归函数即式(21),便可求得预测震级。
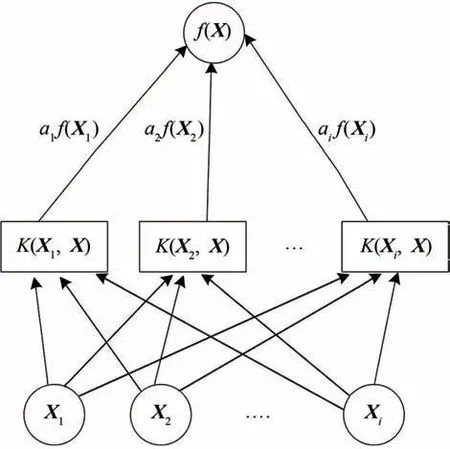
图4 支持向量机网络结构
核函数有多种形式,本文中核函数采用的是高斯核函数,该函数应用范围广、差值能力强,能够更好地提取样本数据的局部特征[27],计算方法为

式中:λ为高斯核参数。
3.3 支持向量机的训练参数
合理的支持向量机模型需要选择合适的训练参数,以使预测结果与真实值的误差尽可能小。在支持向量机中与误差相关的参数有惩罚参数C、容忍误差E、高斯核参数λ,本文计算依据的是Cher⁃kassky和Ma[28-29]给出的经验计算,分别如下


式中:μ为训练集数据输出结果的平均值;γ为训练集数据输出结果的标准差;n为训练集中的数据数量;η为训练得到的预测值与真实值误差的标准差;q为输入特征参数值的范围;m为输入特征参数的数量。
根据式(23)—式(25)给出的训练参数计算方法,经过6 次交叉验证,确定不同时间窗下的惩罚参数C、容忍误差E和高斯核参数λ,进而建立不同预测时间窗下基于支持向量机的高速铁路地震预警震级预测模型SVM-HRM。
4 SVM-HRM 预测模型的震级预测结果对比
基于测试数据集,对SVM-HRM 预测模型的震级预测结果进行如下对比。
(1)在3.0 s的时间窗下,将SVM-HRM 预测模型的震级预测结果与传统的震级预测模型τc方法与Pd方法进行对比。
(2)依据现行《高速铁路地震预警监测系统试验方法》相关条文,计算SVM-HRM 预测模型震级预测的单台实现率,并与《高速铁路地震预警监测系统试验方法》要求的震级预测实现率标准进行对比。
4.1 与传统震级预测模型的对比
定义SVM-HRM 预测模型的预测震级为预测值,定义地震事件的编目震级为真实值,如果取预测值与真实值之差为误差ωi,则ωi的标准差σ为
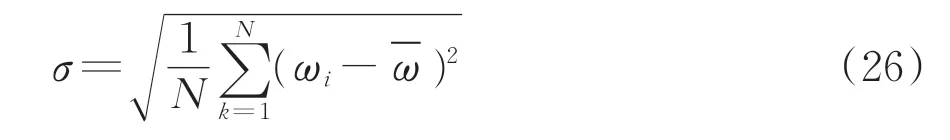
式中:N为测试集中的数据数量,k为其中第k条数据。
在P 波到达后3.0 s 的时间窗下,将SVMHRM 预测模型与传统震级预测模型τc方法与Pd方法的震级预测结果进行对比,并按式(26)计算3种模型的标准差σ值,结果如图5所示。图中的黑色实线表示预测值与真实值的1∶1 线性比例关系,红色虚线表示预测值与真实值误差的1 倍标准差±σ。
由计算并结合图5 可知:τc方法、Pd方法和SVM-HRM 预测模型的震级预测误差标准差分别是1.64,0.43 和0.30 个震级单位,即SVM-HRM预测模型远小于τc方法,也小于Pd方法。

图5 τc方法、Pd方法和SVM-HRM 的震级预测结果对比
需要注意的是,τc方法对5 级以下地震的震级预测结果存在明显高估,即存在“小震高估”现象,这是因为τc方法需要对地震数据进行震中距与信噪比筛选才能构建合适的预测模型。本文构建的SVM-HRM 预测模型没有这一步骤,大幅度提高了模型的普适性。同时,对比Pd方法的震级预测结果能清晰发现,SVM-HRM 预测模型的“小震高估”现象也得到了改善。
显然,对比τc方法与Pd方法,SVM-HRM 预测模型得到的震级预测准确性明显提升。
4.2 与高速铁路震级预测实现率标准的对比
SVM-HRM 预测模型基于训练数据集的震级预测误差标准差,以及基于测试数据集的震级预测误差标准差随预测时间窗的变化如图6所示。图中,横坐标为时间窗,0 s为P波的到达时刻。
由图6 可知:2 条曲线趋于重合、且在相同时间窗所对应误差标准差的最大差值不超过0.02,这表明在P 波到达后,所有预测时间窗所构建的SVM-HRM 预测模型均有极强的泛化能力,即SVM-HRM 预测模型在新鲜数据样本下的适应能力强,对具有同一规律的训练数据集以外的数据,经过训练的网络也能给出合适的输出;随着时间窗的增加,震级预测的误差标准差显著减小,这表明SVM-HRM 预测模型具备震级预测的连续性,且随着P波到达后时间窗的逐步增加,预测震级准确性显著增强。
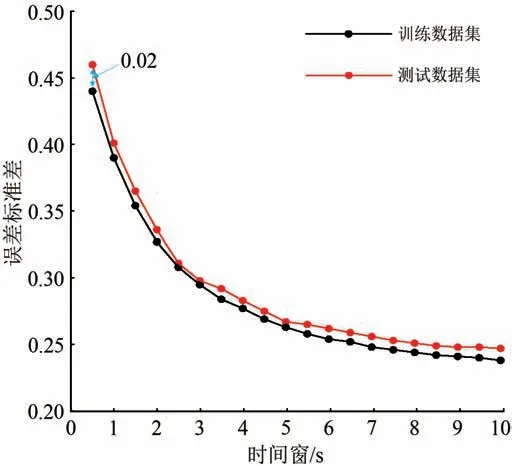
图6 SVM-HRM 震级预测误差标准差随时间窗的变化
《高速铁路地震预警监测系统试验方法》对地震预警首报(第一次发布警报)预测震级实现率做出了规定与要求[15],并以实现率作为衡量高速铁路地震预警系统震级预测准确性的指标参数。实现率根据预测震级误差绝对值小于等于1 的数量所占百分比来定义,计算式为

式中:r为实现率;h为测试数据中预测震级误差ωi≤1的数量;H为测试数据的总数量。
《高速铁路地震预警监测系统试验方法》中所规定的震级预测实现率标准见表1。本文在此研究实现率随预测时间窗的变化规律,旨在分析SVMHRM 预测模型在P 波到达后多久可以给出准确可靠的首报震级。

表1 现行震级预测实现率标准
需要指出的是,在高速铁路地震预警中,多台的震级预测结果需要依据单台震级预测结果加权平均后得到,因此在多台实现率的对比分析中,只要单台分震级范围实现率统计结果优于多台实现率标准,就表明多台实现率结果优于标准,故只需要统计不同震级范围下的单台实现率与《高速铁路地震预警监测系统试验方法》中相应的震级范围实现率标准进行对比即可。
不同时间窗下,SVM-HRM 预测模型开展震级预测的单台实现率计算结果以及与《高速铁路地震预警监测系统试验方法》规定的实现率标准的对比如图7所示。图中的虚线分别为现行《高速铁路地震预警监测系统试验方法》规定的单台(红色虚线)与多台(蓝色虚线)实现率标准[15]。

图7 不同时间窗下SVM-HRM 预测模型的单台实现率与现行实现率标准对比
由图7(a)可知:对于震级范围在3~8 级之间的地震事件,SVM-HRM 预测模型得到单台预测震级实现率在P 波到达后的0.5 s 达到95%,即优于《高速铁路地震预警监测系统试验方法》规定的单台实现率标准;随着预测时间窗的增加,实现率逐渐增大,表明震级预测的准确性持续增加;当时间窗达到2.0 s 时,SVM-HRM 预测模型的预测震级实现率接近100%。
由图7(b)可知:对于震级范围在3~5 级之间的地震事件,SVM-HRM 预测模型在P 波到达后的0.5 s 实现率达到98%,即优于《高速铁路地震预警监测系统试验方法》规定的多台实现率标准;随着预测时间窗的增加,实现率逐渐增大,表明震级预测的准确性持续增加;当时间窗达到1.0 s时,SVM-HRM 预测模型的震级预测实现率接近100%。
由图7(c)可知:对于震级范围在5~7 级之间的地震事件,SVM-HRM 预测模型在P 波到达后的1.5 s 实现率达到92%,即优于《高速铁路地震预警监测系统试验方法》规定的多台实现率标准;随着预测时间窗的增加,实现率逐渐增大,表明震级预测的准确性持续增加;当时间窗达到4.5 s时,SVM-HRM 预测模型的震级预测实现率接近100%。
由图7(d)可知:对于震级范围在7~8 级之间的地震事件,SVM-HRM 预测模型在P 波到达后的0.5 s 实现率为67%,即优于《高速铁路地震预警监测系统试验方法》规定的多台实现率标准;随着预测时间窗的增加,实现率逐渐增大,表明震级预测的准确性继续增加;当时间窗达到2.5 s时,SVM-HRM 预测模型的震级预测实现率达到95%并进入平台阶段;当时间窗达到6.0 s 时,实现率又继续增加,且在时间窗达到7.0 s 时,震级预测实现率达到100%。
通过上述分析可以发现,本文建立的支持向量机震级预测模型SVM-HRM 的震级预测准确性和连续性都得到极大提升,满足《高速铁路地震预警监测系统试验方法》中对震级预测的相关条文要求,可用于高速铁路地震预警系统震级预测。
5 结论
(1)在P 波到达后3.0 s 时间窗下,与传统的地震预警震级预测τc方法与Pd方法相比,SVMHRM 预测模型的震级预测误差明显减小,且小震高估的现象得到明显改善,准确性得到极大提升。
(2)SVM-HRM 预测模型的训练数据集可不做震中距与信噪比筛选,表明该模型具备极强的普适性;模型的训练数据集与测试数据集震级预测结果误差标准差趋于一致,且随着时间窗的增长而显著减小,表明该模型具备极强的泛化性能,震级预测连续性得到极大提升。
(3)将SVM-HRM 预测模型的震级预测结果对比《高速铁路地震预警监测系统试验方法》要求的首报震级预测实现率标准,可发现对于震级范围在3~8 级的地震事件,SVM-HRM 预测模型的单台震级预测实现率在P波到达后的0.5 s达到95%,且优于《高速铁路地震预警监测系统试验方法》要求的首报震级预测实现率标准;对于3~5,5~7,7~8这3 个震级范围下的地震事件,震级预测单台实现率分别在P 波到达后的0.5,1.5,0.5 s 优于多台实现率标准。这表明利用本文构建的SVMHRM 预测模型,最迟在P 波到达后的1.5 s可以发出满足《高速铁路地震预警监测系统试验方法》震级预测实现率标准的地震预警首报,准确性得到极大提升。
猜你喜欢
自然灾害学报(2022年2期)2022-05-10
高速铁路技术(2022年2期)2022-05-05
高速铁路技术(2022年1期)2022-03-17
奥秘(创新大赛)(2021年3期)2021-05-15
山西地震(2020年1期)2020-04-08
今日农业(2019年12期)2019-08-13
现代园艺(2017年22期)2018-01-19
铁道通信信号(2016年2期)2016-06-01
火控雷达技术(2016年3期)2016-02-06
地震科学进展(2015年9期)2015-05-13
