
基于卷积神经网络优化回环检测的视觉SLAM 算法
2021-07-25 06:15葛平淑王东兴
西南交通大学学报 2021年4期
郭 烈 ,葛平淑 ,王 肖 ,王东兴
(1.大连理工大学汽车工程学院,辽宁 大连 116024;2.大连民族大学机电工程学院,辽宁 大连 116600;3.大连理工大学控制科学与工程学院,辽宁 大连 116024)
即时定位与建图(simultaneous localization and mapping,SLAM)是智能机器人和无人驾驶汽车实现自主导航与运动控制的关键技术[1].室外环境下,机器人可依靠GPS 和高精地图实现自身定位与导航,但是在室内环境下GPS 信号较弱导致定位偏差较大[2],因此,有必要研究SLAM 技术.早期SLAM技术主要依赖于激光传感器,可获得比较精确的距离信息,但其成本较高导致推广应用困难.计算机视觉的发展促使视觉SLAM 技术得到广泛关注,特别是深度相机的出现,使SLAM 技术得到进一步发展.深度相机可提供像素点的深度信息,解决尺度问题同时,也可减少大量的空间点的深度计算,使得视觉SLAM 的实时性得到较大程度的改善[3].
2007 年,Davison 等[4]提出了MonoSLAM 算法,是第一个可以实时运行的单目视觉SLAM 算法.MonoSLAM 以扩展卡尔曼滤波为后端,追踪前端非常稀疏的特征点,以相机的当前状态和所有路标点为状态量,更新其均值和协方差.同年,Klein 等[5]提出了PTAM (parallel tracking and mapping)算法.PTAM 提出前端和后端的概念,即局部地图建立和对于地图的优化,在之后的SLAM 算法中得到广泛应用.与传统的滤波方法不同,PTAM 还是第一个使用非线性优化的方法,在以前人们一直认为非线性优化方法无法处理数据量庞大的视觉SLAM 问题,但是后来研究发现后端非线性优化具有很大的稀疏性,对于其重投影误差函数的二阶偏导矩阵是可以比较快速求出的.因此,非线性优化方法开始在SLAM算法中占据主导地位.
ORB-SLAM (oriented fast and rotated brief SLAM)是现代SLAM 算法典型代表[6],该算法围绕ORB 算子进行计算,包括视觉里程计与回环检测的ORB 字典,体现ORB 特征是现阶段计算平台的一种优秀的效率与精度之间的折中方式.ORB 比SIFT(scale-invariant feature transform)或SURF (speeded up robust features)省时,可实时计算,相比Harris 等简单角点特征,又具有良好的旋转和缩放不变性,并且ORB提供描述子使大范围运动时能够进行回环检测和重定位[7].
在SLAM 建图的过程中,由于各种噪声的影响将不可避免地导致误差的出现,随着机器人的运动累积误差逐渐增大,建立的地图与真实场景的差距也将逐渐增大.为了减小累积误差的影响,一些SLAM算法引入了回环检测机制,即检测机器人是否运动到之前经过的地方,若有回环出现便对估计的运动轨迹增加约束并进行一次全局的轨迹优化,这样便可以消除累积的运动误差,目前大多数视觉SLAM算法都采用词袋法来进行回环检测.由于利用图像特征点信息来进行回环检测的词袋法的计算量比较大,所以不太适合用于轻量级的计算设备上,而且基于特征信息进行回环检测的准确率也比较低[8].
针对上述问题,本文通过Kinect 深度相机获取环境信息,提出一种利用训练好的卷积神经网络(CNN)提取图像特征并进行回环检测的视觉SLAM算法,使得回环检测的准确率与速度都能得到改善.
1 基本原理与实现方法
算法流程如下,对于Kinect 相机获得的彩色图像进行特征提取并与前一帧进行特征匹配,根据正确匹配的特征信息结合深度图像的距离信息进行PnP(perspective-n-point)求解从而得到两帧图像间的位姿变换.通过设定合理的运动范围来筛选出关键帧,然后将关键帧以及相邻关键帧之间的位姿变换信息进行储存.将当前关键帧与之前所有关键帧进行回环检测,若出现回环则将两个关键帧进行特征提取、特征匹配和PnP 求解,然后将所有的位姿信息利用图优化工具进行全局优化并根据优化后的信息拼接点云地图.
1.1 特征提取
视觉里程计建立的主要问题是如何通过图像来计算相机的位姿变换,因此,希望能在图像中找到一些比较特殊的点.传统的视觉SLAM 算法通常采用SIFT 或SURF 特征,这些特征的不变性都很好,但是其计算都非常耗时,不能满足SLAM 的实时性需求.2011 年Rublee 等[9]提出了ORB 算子,其计算速度比SURF 和SIFT 要快且具有良好的不变性.为此,本文采用ORB 算子实现特征提取.
ORB 算子由关键点和描述子两部分组成:关键点称为“Oriented FAST(features from accelarated segment test)”,是一种改进的FAST 角点;描述子称为BRIEF(binary robust independent elementary features).
FAST 角点是指图像中灰度梯度变化较大的地方,如图1 所示,其中f1为水平方向的阶数.首先,取图像中的一个像素点,然后对比此点的灰度值与以此点为圆心半径为3 的圆上的16 个像素的灰度值,若有连续N个点大于或者小于设定的阈值则认为此点为角点.

图1 FAST 角点示意Fig.1 Diagram of FAST corner
为了解决角点方向性的问题,增加了尺度和旋转特性描述[10].尺度不变性通过构建图像金字塔并对其中每一层的图像进行特征点检测,然后将共同检测到的特征点认定为正确检测结果.旋转特性由灰度质心法来描述,灰度质心法即由灰度值来确定图像的质心[11].在一个图像块M中定义图像矩为
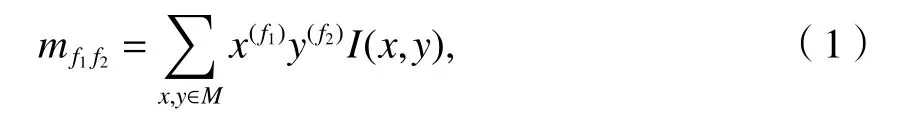
图像块质心C的坐标为,再连接图像块的几何中心O与质心C便可得到方向向量.
BRIEF 是一种二进制描述子,其描述向量由多个0 和1 组成,编码了关键点附近两个像素的大小关系.如果取128 个关键点,则可得到一个由0 和1 组成的128 维向量.结合FAST 角点的旋转特性便得到具有旋转特性的BRIEF 描述子.
1.2 特征匹配与PnP 求解
图像的特征提取结束后,采用快速最邻近搜索算法进行特征点匹配.通过建立随机K-D 树来找到图像中某个特征点在另一张图像中的对应点,然后计算两个特征点BRIEF 描述子的汉明距离.将图像中匹配出距离最小的点的距离记做D,取该距离的4 倍为阈值作为筛选标准,对所有的配对点进行筛选,将小于该距离的点认为正确匹配点.最后对另一幅图像做同样操作,将两者共同匹配到的点作为最终匹配点.
PnP 是求解3D 到2D 点对运动的方法[12],如果两幅图像中一幅图像特征点的空间三维坐标已知,最少仅需3 对点就可以估计相机的运动了.特征点的空间三维坐标可由相机的深度图确定,PnP 问题的求解方法有很多种,例如P3P、直接线性变换、非线性优化等,本文采取非线性优化的方法,将PnP问题转换为一个非线性最小二乘问题.
如图2 所示,由于观测噪声的存在,对于空间中某一个特征点P,p1为重投影点,其观测位置(像素坐标)和该点按照当前相机位姿计算得到的投影位置p2之间是有一定偏差,该偏差即为重投影误差,e为节点间误差.

图2 重投影误差Fig.2 Error because of reprojcetion
假设空间点Pi=(Xi,Yi,Zi),i=1,2,···,n.相机位姿的旋转矩阵为R、位移向量为t,将PnP 问题构建成一个定义于李代数上最小化重投影误差的非线性最小二乘问题,用ξ表示R和t的李代数,Pi在此位姿下重投影点pi的像素坐标为(ui,vi),则

式中:si为第i点的深度;K为转换系数;ξ∧为李代数反对称矩阵.
若有n对匹配特征,根据上面提到的重投影误差可建立最小二乘问题,如式(3).
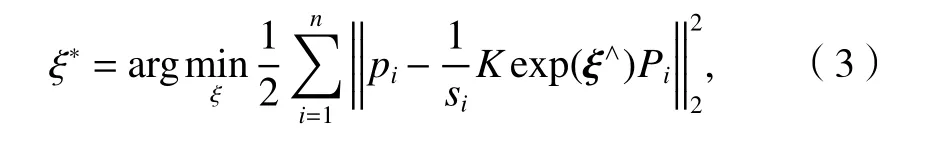
式中:ξ*为李代数重投影.
该最小二乘问题的求解可用Gauss-Newton 法或Levernberg-Marquardt 法进行求解.在SLAM 中,通过调整相机位姿和路标点坐标来使误差达到最小的过程称为BA(bundle adjustment).
1.3 回环检测
如果视觉里程计的建立只考虑相邻帧间的运动,可能会导致误差累积,如果能检测出相机经过相同的位置,那么便可以为估计的相机运动轨迹增添约束,使其更加接近真实轨迹[13].
卷积神经网络是一种前馈神经网络,主要由卷积层和池化层组成[14].相比于传统计算机视觉中人工设计的图像特征,利用CNN 提取的图像特征更能反应图像的真实特性,在图像分类与识别领域使用效果要远强于传统计算机视觉方法.因此,本文采用CNN 代替传统词袋法来进行回环检测.
SqueezeNet 是由UC Berkeley 和Stanford 研究人员一起设计的,其设计的初衷并不是为了达到最佳的CNN 识别精度,而是希望简化网络复杂度,同时达到public 网络的识别精度.SqueezeNet 核心构成 为Fire module,SqueezeNet 包 含fire2~fire9 共8 个Fire module,其中fire2 结构如图3 所示,其中H、W分别为特征图的高度和宽度;ei为通道数.

图3 fire2 结构Fig.3 Structure of fire2
SqueezeNet 通过Fire module 来减少网络的参数量和Flops,每个Fire module 由squeeze 和expand模块构成.squeeze 模块使用e1个1×1 的卷积核对特征图降维,经Relu 激活后特征图为H×W×e1.经expand 的两个分路(卷积核大小分别为1×1,3×3)分别计算后特征图为H×W×e2,然后通过concat 层将两个分路的特征图拼接在一起生成H×W×e3.其中e2=4e1,e3=2e2.由于fire 网络卷积核大小完全相同,只有通道数不同.图4 网络结构图中fire 结构只标注fire 结构输出通道数e3.
当网络输入为224×224×3 的RGB 图像时,网络的计算量仅为837 MFlops,因此,该网络结构比较适合应用于智能移动机器人等轻量级设备上.本文使用的SqueezeNet 的网络结构如图4 所示[15].
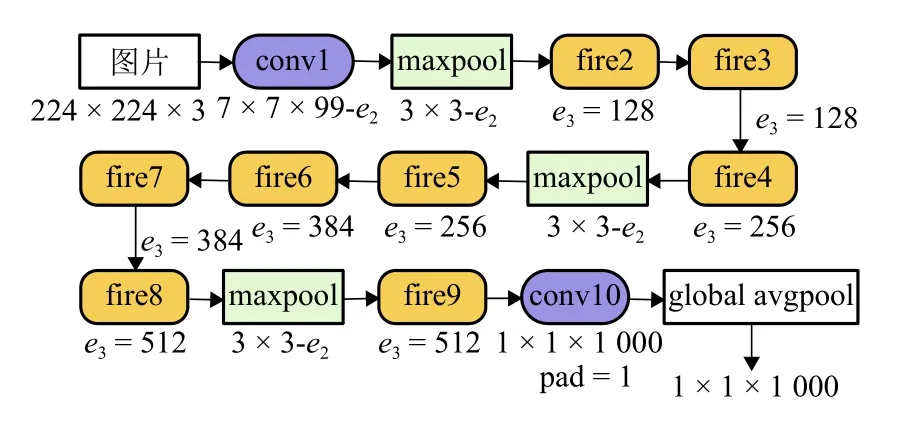
图4 SqueezeNet 网络结构Fig.4 Network structure of SqueezeNet
将图像输入SqueezeNet 网络,输入图像的格式为224 × 224 的三通道RGB 图像,提取网络输出的1 000 维数组A=(a1,a2,a3,···,a1000)作为此图像的特征向量.假设另一幅图像的特征向量为B=(b1,b2,b3,···,b1000).可以通过这两幅图像的特征向量的余弦相似度来判断这两个图像是否相似,如式(4).

若余弦相似度大于设定的阈值则认为出现了回环,否则跳入下一帧图像,再与输入图像的特征向量进行比较,直至出现回环.
1.4 全局优化
在SLAM 过程中,需要考虑后端的全局优化.对于相机的运动可以用位姿图来表示,如图5 所示,其中每个节点代表每一个关键帧对应的相机位姿,节点间的边代表两关键帧之间的相机位姿变换.

图5 位姿图Fig.5 Pose graph
相机的位姿有6 个自由度,分别是3 个轴向位置和绕3 个轴的转矩,用wk表示,即wk=[xk yk zkγkκkϑk],k=1,2,···,j.
两个位姿间的变换关系为

连接的两个节点k和j之间的误差为

将所有的节点间误差相加起来并标量化,可以得到总误差为

式中:F为节点集合;Ωk,j为xk和xj之间的信息矩阵.
求解最小二乘问题便可得到优化后的位姿.本文采用通用图形优化g2o 来得到优化后的位姿[16].定义顶点和边的类型,添加节点和边的信息,选择合适的优化算法的求解器和迭代算法.g2o 提供了3 种不同的线性求解器:CSparse、基于乔里斯基分解Cholmod 和基于预处理共轭梯度算法PCG(preconditioned conjugate gradient),迭代算法包括高斯牛顿法、Levernberg-Marquardt 法和Powell’s dogleg.
2 试验结果与分析
试验在一个安装了Kinect V1 深度相机和Nvidia TX2 开发板的Turtlebot 二代机器人平台上进行.通过Ubuntu14.04 系统运行算法,涉及软件包括ROS机器人操作系统和Caffe、OpenCV、Eigen、PCL、g2o等开源库[17].
试验数据集包括TUM(technical university of munich)数据集、nyuv2 数据集和利用Turtlebot2 自行采集的数据集,如表1.其中,TUM 数据集是由德国慕尼黑工业大学计算机视觉组采集制作的[18],通过在深度相机上加装高精运动传感器使得在获取彩色图像和深度图像的同时可以得到相机的真实运动轨迹.TUM 数据集中还提出了一种轨迹误差的计算方法,可以计算得到SLAM 算法的估计运动轨迹与高精运动传感器获取的标准轨迹之间的误差.

表1 实验采用的数据集Tab.1 Data sets for testing
2.1 与无回环检测的算法进行对比
利用Turtlebot2 在室内采集的数据集,包括968 帧分辨率为640 × 480 像素的彩色图像和对应的深度图像,采集速度为30 帧/s.
有、无回环检测轨迹估计对比结果如图6 所示,当采用无回环检测的算法进行建图时,其轨迹如图6(a)所示,由于误差的累积导致相机运动轨迹出现漂移而无法闭合.而采用本文算法进行建图时,如图6(b)所示,由于成功检测到回环因而在回环处添加了运动约束从而使运动轨迹趋于闭合.

图6 轨迹估计对比Fig.6 Comparison results for trajectory estimation
图7 是采用无回环检测与本文回环检测算法进行建图时获得的点云图.
从图7(b)中可以看出有回环检测时,在出现回环的位置点云地图基本重合,表明估计的轨迹与真实轨迹有较大误差.由此可见:本文算法可成功检测出回环并为全局轨迹优化增添约束,使得估计的运动和建立的地图更接近真实情况.

图7 点云图对比(红圈为出现回环部分)Fig.7 Comparison results for points nephogram(the red circle is the loop)
2.2 与词袋法进行对比
通过算法来判定是否出现回环与事实可能是不同的,大概会出现4 种不同情况,如表2 所示.

表2 回环检测可能出现的结果Tab.2 Possible results for loop detection
采用准确率Ta和召回率Tr来衡量回环检测结果的好坏,如式(8)、(9).

式中:T1、T2、T3分别为回环检测结果是真阳性、假阳性和假阴性的数量.
分别将本文提出的回环检测算法和词袋法在New college 数据集和自己制作的数据集上进行测试,试验得到准确率和召回率对比结果如图8 所示,具体数据见表3 所示.

表3 本文算法与词袋法对比Tab.3 Comparison between algorithm and word bag method in this paper
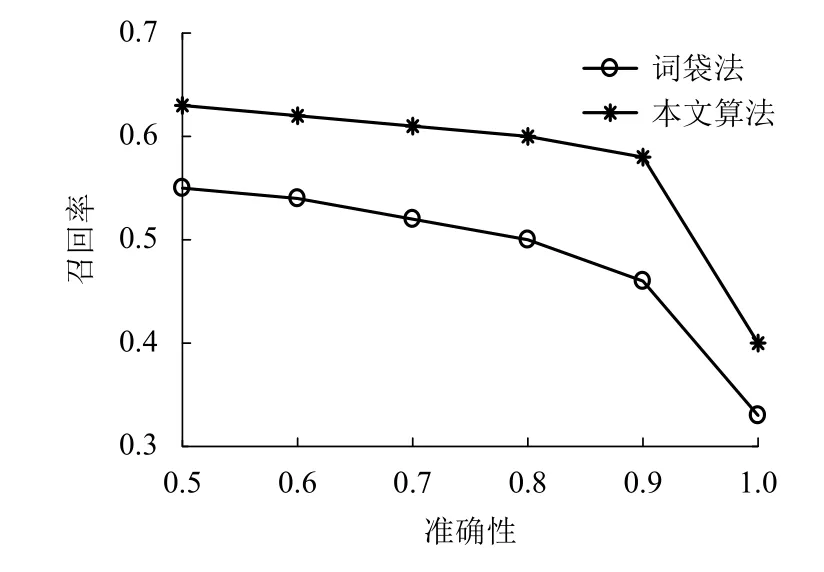
图8 本文算法与词袋法的准确性和召回率曲线对比Fig.8 Comparison of the accuracy and recall curves between the algorithm in this paper and the word bag method
由图8 可以看出,在准确率相同的情况下本文算法的召回率明显高于词袋法的召回率.因为在回环检测算法中准确率的重要性是远高于召回率的,一旦出现假阳性结果会对最终的地图建立有极为不好的影响,因此,一般都要保证准确率为1.当准确率为1 时本文算法的召回率为0.4,而词袋法的召回率为0.33,本文算法相对于词袋法提高了约21%,对两张图片进行相似度计算所花时间减少了74%.
2.3 建图精度
德国慕尼黑工业大学计算机视觉组在TUM 数据集中提供了一种轨迹误差的测量方法——绝对轨迹误差(absolute trajectory error,ATE).ATE 通过计算估计的轨迹和标准轨迹的均方根误差来获得.假设相机的标准轨迹为X={X1,X2,···,Xn},相机的估计轨迹为,则绝对轨迹误差的均方根为

式中:trans(·)为获取位姿平移向量的函数.
图9 为本文算法的估计运动轨迹与通过高精运动传感器获取的标准轨迹.由于TUM 数据集中采用的高精运动传感器的采集频率非常高,所以获取的轨迹信息更加丰富.

图9 标准轨迹、估计轨迹和轨迹误差Fig.9 Standard trajectory,estimated trajectory and trajectory error
表4 对算法的建图精度进行了对比,所使用的TUM fr3_stf 数据集采集时长共31.55 s、标准轨迹总长5.884 m、相机平均移动速度0.193 m/s,计算与本文算法估计轨迹的绝对轨迹误差的均方根值为0.050 0 m.同样使用RGB-D SLAM[19]进行建图得到绝对轨迹误差的均方根值为0.049 0 m.由图9(a)可见TUM fr3_stf 中无回环出现,本文算法与RGB-D S LAM建图误差基本相近.

表4 建图误差对比Tab.4 Comparison of mapping errors
所使用的TUM fr3_xyz 数据集采集时长共30.09 s、标准轨迹总长7.112 m、相机平均移动速度0.244 m/s,计算与本文算法估计轨迹的绝对轨迹误差的均方根值为0.010 4 m.同样使用RGB-D SLAM进行建图得到绝对轨迹误差的均方根值为0.013 5 m.由图9(b)可见TUM fr3_xyz 中有较多回环出现,本文算法与RGB-D SLAM 相比,建图误差降低了29%.
3 结 论
1)提出一种利用CNN 进行回环检测的视觉SLAM 算法.前端采用特征点法建立视觉里程计,追踪ORB 特征并结合深度相机获得的距离信息来估计相机运动,后端利用CNN 进行回环检测并利用g2o 图优化工具进行全局优化.
2)分别对有、无回环检测在轨迹估计误差、点云图、建图精度等方面进行试验.相比与无回环检测算法,本文算法在出现回环情况下可以使估计的运动轨迹趋于闭合从而使建立的地图更加接近真实场景;数据集上测试表明,当有较多回环出现时,本文算法相比较于RGB-D SLAM 算法在建图准确度上有所提高;在回环检测方面,相比于词袋法,本文算法召回率可提高21%且计算耗时减少74%.
3)本文算法在鲁棒性方面并未做具体改进,在面对特征点丢失的情况可能会表现不佳,以后需要展开更加深入的研究.
猜你喜欢
光学精密工程(2022年22期)2022-11-28
交通信息与安全(2022年1期)2022-03-20
现代英语(2022年23期)2022-02-23
汽车工程师(2021年12期)2022-01-17
中学生数理化·八年级物理人教版(2020年6期)2020-10-30
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
电子制作(2019年10期)2019-06-17
电子技术与软件工程(2019年6期)2019-04-26
宝藏(2018年3期)2018-06-29
自动化学报(2017年4期)2017-06-15
