
基于深度学习的食品安全领域实体关系抽取研究
2021-08-05 02:37孙劭芃汪颢懿张青川
中国酿造 2021年7期
孙劭芃,汪颢懿*,左 敏,张青川
(北京工商大学 电商与物流学院 农产品质量安全追溯技术及应用国家工程实验室,北京 100048)
作为最基本的民生问题,食品安全牵动着亿万民众的神经,一经曝光,就能迅速引起社会各阶层的普遍关注,激发负面联想,甚至诱发非理性的线下集合行为,危及社会稳定。随着越来越多的食品安全报道在网络上传播,快速且准确的对突发报道中的关键信息进行抽取对于政府对食品安全领域的监管和预测都有着尤为重要的意义和价值。
随着信息时代的到来,互联网技术高速发展。作为自然语言处理[1]的重点课题之一,实体关系抽取[2]作为实现语义关系自动抽取和查询匹配的一种新兴技术,近年来一跃成为热门研究领域,受到越来越多科研人员的重视。在诸多的实体关系抽取方法中[3-6],有监督的实体关系抽取方法[3]依然是目前最基本最常见的方法,其主要过程是在已标注过的训练数据集上训练出关系分类模型,从而在测试集上进行对应的实体关系抽取。本文也采用了有监督的深度学习网络模型对实体关系抽取进行研究。
实体关系抽取一直是经典而又富有挑战性的任务,在过去二十多年的研究发展下取得了很多阶段性的突破,同时也广泛应用在知识图谱[7]的构建、自动问答[8]、文本摘要[9-10]等诸多重要领域。随着以深度学习为基础的人工智能潮流席卷全球,深度学习下的实体关系抽取也同样得到了快速发展,它有效改善了传统标注工具的自身缺陷,取得了良好的效果。文献[11-15]对基于深度学习的实体关系抽取方法进行了总结归纳。文献[12]介绍了基于深度学习的实体关系抽取方法,并进行比对;文献[13]对基于深度学习的实体关系抽取的基本框架和流程进行了介绍。自2018年以来,BERT(bidirectional encoder representations from transformers)网络被应用到自然语言处理(natural language processing,NLP)的各个领域,并都取得了突破性的效果[16-20],其独有的Transformer Encoder编码模型,能够解决句子中的依赖关系,对句子的内部结构进行有效地学习,保证了句子字向量训练的质量,从数据基础的角度为后续的预测模型提供了保障,提高了后续模型的预测准确性[21-22]。值得注意的是,最近注意力机制在NLP上取得了广泛的应用和成功。本研究也基于领域词的位置感知注意力机制,对双向长短期记忆网络进行了改进,取得了较好的效果[23-24]。
本文主要研究针对食品安全领域语料的实体关系抽取方法,在分析现有的实体关系抽取方法优劣的基础上,采用了BERT-双向长短期记忆网络(bi-directional long shortterm memory,BiLSTM)双维度双网络模型结构,不仅很好的处理了不同实体关系的区分度,而且有效学习了文本远程语义的信息和结构。同时,在注意力机制的层面上,为了使BiLSTM网络更好的对词汇特征的语义和文本内部位置信息的学习,采用了领域词识别和词语位置分布信息结合计算的处理方法。整个双网络模型在独立构建的食品安全领域数据集上进行实验和测试,展示出较好的性能效果。
1 数据来源与处理
1.1 数据来源
在进行研究之前,需要充足的语料资源作为数据基础,因此首先构建了食品安全领域语料库,并对库中所有语料做预处理工作,最终将处理好的语料作为本次研究的数据集。
食品安全领域语料库中的语料主要来自于百度新闻、食安通平台、食品伙伴网、新浪微博等平台近年来发布的食品安全领域相关文章,包括检验检疫、生产销售、制度发布、公众投诉、安全事件等相关类型,共计5 000余篇。语料库部分截图见图1。

图1 食品安全领域语料库(部分)Fig.1 Corpus of food safety (part)
1.2 数据处理
本文实体和关系的抽取分别是句子级别的关系识别和标签级别的实体识别任务,目的是抽取食品安全领域语料中的二元关系和实体。将食品安全语料中实体关系定义为R,两个实体的关系用三元组(Ei,R,Ej)表示,其中Ei为实体关系中的主体,Ej为客体,R为映射关系,根据食品安全领域语料的行文特点,定义映射关系和识别的三元组见表1。

表1 食品安全领域语料实体关系抽取类型明细(部分)Table 1 Detailed list of entity relation extraction types of corpus in food safety field (part)
在识别模型训练过程中,把食品安全领域语料划分成多个待识别关系和实体的句子并为每个句子进行标注,贴上正确的标签。标注结果部分截图见图2。

图2 实体关系标注结果(部分)Fig.2 Results of entity relation annotation (part)
根据设计的三元组形式,在模型训练中,分别输入语料句子和相应已标注的三元组信息(实体1,实体2和实体关系)。训练完成后,在模型测试时,输入一个新的语料句子,也按训练集标注格式输出识别的关系与实体对。
1.3 评价指标的计算
采用准确率(precision,P)、召回率(recall,R)与F1值作为实验的评价指标。准确率(P)计算公式如下:

式中:P代表准确率;TP代表模型将一个关系的正类预测为正类的数量,个;FP代表模型将一个关系的负类预测为正类的数量,个。
召回率(R)计算公式如下:

式中:R为召回率;TP代表模型将一个关系的正类预测为正类的数量,个;FN代表模型将一个关系的正类预测为负类的数量,个。
F1值是机器学习评价体系中的一个通用评价指标,其公式计算如下:

在以上各个评价指标中,准确率P、召回率R它们两者之间有明显的负相关关系,当实验的结果准确率高时,其对应召回率普遍较低,反之同理。所以使用F1值作为来衡量分类器综合性能的评价指标,防止上述问题的出现。
2 词语Word2Vec模型增量训练
增量训练是指在对语料进行Word2Vec词向量训练时,对现有的训练模型进行语料补充和修正的二次训练。一般所用Word2Vec的训练模型是基于通用语料训练而来,对于垂直领域的词汇用法和关联程度有所不同,当用专业领域的语料经过增量训练后,可以在垂直领域对现有模型进行专业化的补充。
食品安全领域相关语料具有一定的专业特殊性,尤其在专业的领域词、检测因子、专业语义上与公共领域的语料存在较大的差异,用现有词向量训练工具进行分词、词语向量化较难有很好的训练效果,因此需要对Word2Vec模型进行增量训练。
本文首先在一个公共开放的预训练模型的基础上进行语料扩充,加入实验构建的食品安全领域语料库以及领域词汇百科、领域检测因子等语料,进行词向量模型的训练。增量训练模型参数见表2。

表2 食品安全领域词语Embedding模型增量训练参数Table 2 Incremental training parameters of embedding model in food safety field
随着时间的推移,未来可能出现新的领域词汇,而且业务情景可能发生变更。此后每隔一段时间,当积累了一定的核技术利用单位的检察建议语料时,对词向量模型再进行增量训练。持续的增量训练可以使得词向量模型能学习到新词汇的向量表示并适应最新语料的语义关系,更好地将文本向量化,以提升后续算法准确性。
3 食品安全领域实体关系抽取模型建立
3.1 BERT-BiLSTM双维度模型描述
整个双网络模型结构见图3。由图3可知,右半部分的网络结构图展示了基于领域词的位置感知注意力机制的双向长短期记忆网络模型(BiLSTM)提取出语料中的关系,左半部分的网络结构图展示了基于BERT网络提取出语料中存在的实体对。
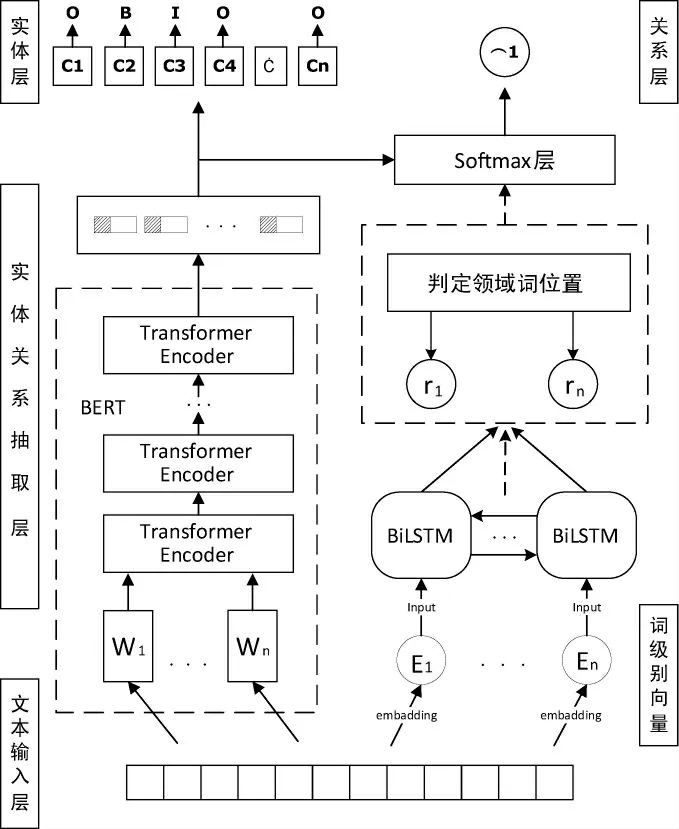
图3 网络模型结构图Fig.3 Network model structure
在模型的右半部分,使用提前训练好的词嵌入模型将食品安全领域的语料进行文本向量化处理。之后将得出的词级别向量作为BiLSTM网络层的输入,由BiLSTM生成隐层向量。首先,将提前构建好的领域词词库与当前的每个词语进行逐一匹配,引入基于领域词的位置感知注意力机制,通过进行计算之后,则可计算出相应的影响向量,同时模型将影响向量与隐层向量进行结合,影响BiLSTM模型输出结果;在模型的左半部分,将标注好的文本句子输入BERT模型进行训练,并将训练所得字向量加入偏旁部首的修正向量,进一步修正训练结果,最终提取出句子中包含的实体对并提取其隐层向量,最后模型将会在两个网络输出向量的结合层累积影响向量,进一步得出实体及其关系抽取结果。
在实体关系抽取模型的输出层中,利用SoftMax层,对每个输出节点的输出向量进行概率转化,并找到概率最高的输出节点所对应的词作为该句子的关系词。关系词的概率转化计算公式如下:

式中:P(q|S)为关系词的概率值,%;S为输入的句子;q为预测的关系词;wν为权重;V为输出向量;bν为偏置向量。
对于关系标注部分,输入句子的每一个词会被指派一个关系标签,本文中采用0~1标签为关系做标注,其中识别出的关系词被标记为1,非关系词标记为0。因此,关系标注问题可以转变为:对于给定的长度为n的句子S=(s1,…st,…sn),假设标注输出结果为Q=(q1,…qt,…qn),在已知序列S下,找出使得Q=(q1,…qt,…qn)的概率P=(q1,…qt,…qn)最大的序列(q1,…qt,…qn)。概率P计算公式如下:
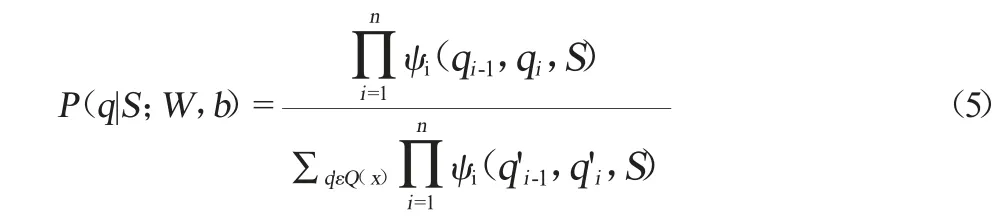
式中:P(q|S;W,b)表示输出序列Q为最优序列的概率;W为权重;b为偏置向量;ψ(q',q,S)=exp(WTq',qz+b,q)是一个隐含函数(其中,WT表示权重向量的转置,b表示偏置向量,z表示词向量的权重向量)。
最后,使用维特比算法对式(5)所得P(q|S;W,b)进行有效的解码运算,得到每个词最终的标注向量。
3.2 基于领域词的位置感知注意力机制
为了将食品安全领域的语言特点融入模型网络中,使得实体关系抽取效果更加优异,在模型中引入了基于领域词的位置感知注意力机制。
依据食品安全领域的专业词汇,构建食品安全领域词库,依据词语是否匹配到领域词库的原则,筛选词语,确定领域词汇。具体执行过程见图4。
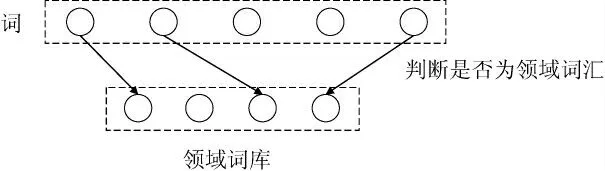
图4 领域词汇匹配示例Fig.4 Examples of domain vocabulary matching
本模型对输入词向量中的领域词进行识别,经过基于领域词的位置感知注意力机制的计算,将影响向量传播到BiLSTM隐层向量中结合计算,从而影响BiLSTM的输出结果。最后模型将会在两个网络输出向量的结合层累积影响向量,进一步得出实体及其关系抽取结果。
注意力机制所生成的影响向量具体计算过程为:假设领域词在隐层向量各维度上的影响是基于高斯分布的,同时设K为影响的基础矩阵,则其影响的表达式如下:

式中:K(i,m)表示距离向量第i维度距离为m的领域词对其产生的影响;N(Kernel(m),σ2)表示期望值为Kernel(m)、标准差为σ的正态分布。Kernel(m)表示高斯核函数,可以对位置感知的影响传播进行模拟,其表达式如下:

式中:m表示领域词到其影响维度的距离;σ表示高斯滤波器宽度。
根据领域词的位置关系,可以计算每个领域词的影响矩阵,通过计算的积累,最后获得每个特定位置下领域词的影响向量:

式中:cfj代表领域词在位置j处的累计影响向量;Sj表示一个距离的计数向量,用来测量属于领域词的数量,K为设定的基础影响矩阵。
4 结果与分析
4.1 实验构建
本次实验以Python3.7语言为依托,利用Tensorflow和Pytorch框架构建深度学习模型,同时选用MySQL数据库进行数据的调用与存储。实验设备方面,工作站内存为16 GB,搭载Windows 10(X64)和Linux CentOS7操作系统,Intel酷睿i7 7700HQ处理器。
本次实验数据集按4∶1的比例拆分,其中训练集有效语句近6 000条,主要用作对BERT模型和双向长短期记忆网络(BiLSTM)模型进行训练,并使各项参数达到最优值;测试集有效语句约为1 500条,用于对模型的实体关系抽取效果进行评估。
实验参数的设置与选择上,设置词嵌入层使用100维的Glove词向量,BiLSTM网络输出向量的维度是128维,注意力机制中设置μ为8。BERT模型的参数设置见表3。

表3 BERT模型参数设置Table 3 Parameters setting of BERT model
4.2 实验结果对比与分析
为了展示双网络及其注意力模型的效果,利用传统的神经网络模型与本文模型针对同一数据集展开了一系列对比实验。对比模型整体分为卷积神经网络(convolutional neural network,CNN)模型、BiLSTM模型和BERT模型,并通过是否引用注意力机制来提升对比效果。具体的实验结果见表4。
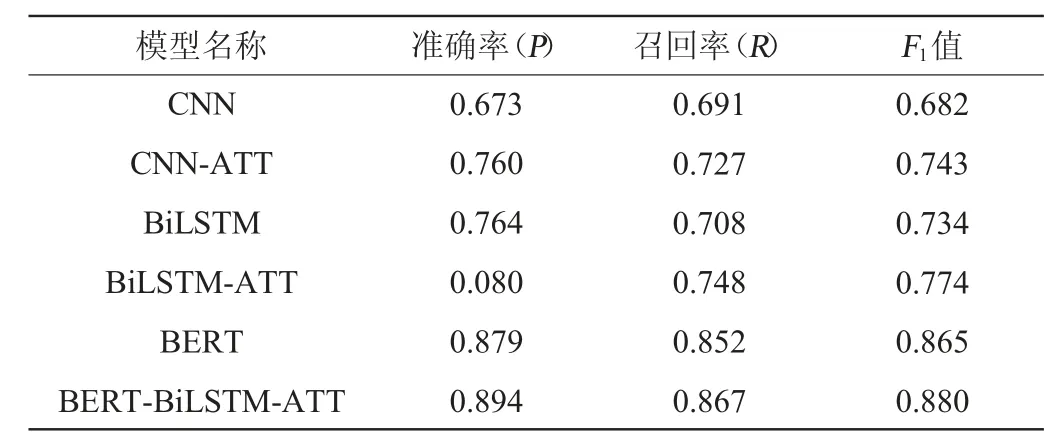
表4 不同模型在实验数据集上的性能对比Table 4 Performance comparison of different models on experimental data set
由表4可知,BiLSTM-ATT模型在实验数据集上准确率、召回率、F1值分别达到了0.801、0.748和0.774,整体上要比CNN及CNN-ATT模型具有更好的性能表现,但带有注意力的CNN仍有着不俗的表现,F1值达到了0.743。而BERT模型凭借着自身强大的训练机制,不出意外的将整体实体关系抽取效果提升了一个档次,三项评价指标均达到了0.850以上,较传统的深度学习模型有很大的提升。值得注意的是,本文提出的BERT-BiLSTM-Attention双网络模型在准确率和召回率层面上均体现出了更好的性能,分别达到了0.894和0.867,F1值高达0.880,较单网络的BERT模型提高了1.5个百分点。在本文模型中,BERT模型自身就有着优秀的字向量训练机制,并根据偏旁部首的加强训练,结合BiLSTM在领域词上的注意力机制,进一步优化了网络整体的注意力权值计算。对于关系抽取而言,本文所使用的双网络模型针对句子结构上有着较好的反馈,同时又不抛弃垂直领域词汇带来的更多有用的信息。
5 结论
本研究完成的主要工作是基于BERT-BiLSTM-Attention构建了一个关系抽取模型,应用到食品安全领域的关系和实体识别中,进行关系抽取,通过BERT模型对语料中的关系进行提取,并将隐层向量与BiLSTM-Attention模型隐层向量相结合,更优的提取出食品安全语料中的对应实体,这两个模型共同组合成食品安全事件实体关系抽取模型,其在测试集上取得了很好的实体关系抽取效果,准确率、召回率、F1值分别达到了0.894、0.867和0.880。
本文的研究为食品安全领域的文本抽取以及知识图谱构建提供了新的方法及思路,为实现相关食品安全监管可视化平台、智能问答等应用奠定了基础。此外如何对抽取后出现的噪音数据进行识别、校正以及对食品领域词、知识的补全将会是下一步工作的重点。未来可通过人工智能进一步打造食品安全监管智能化系统,实现资源共享,提高监管力度,为人民群众提供更优质的服务。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
传媒评论(2017年3期)2017-06-13
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
海外华文教育(2016年1期)2017-01-20
第二课堂(课外活动版)(2016年2期)2016-10-21
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
