
基于不平衡文本分类的改进Stacking模型*
2021-09-15 08:35赵礼峰
计算机与数字工程 2021年8期
蒋 瑶 赵礼峰
(南京邮电大学理学院 南京 210023)
1 引言
如今,我们生活在一个信息驱动的时代,人们不仅从社会、生活的环境中获得信息,更多的信息来自于网络这片海洋里[1]。随着互联网的飞速发展,人们慢慢倾向于在网络上阐述观点和表达情感,从网络上的言论中获取信息。以脸书(Facebook)、微博、微信等为代表的社交平台和以亚马逊、淘宝为代表的电子商务平台上的评论迅速增多,所蕴含的信息量也非常多。从大量评论中挖掘出其蕴含的态度或情绪信息是迫切需要的,因为从一个商品的评价中,卖家和买家可以做出决策;在各大网站上的评论有助于政府的舆情监控。
文本分类就是从文本中获取信息,进而对信息进行分析处理,挖掘出更为重要的知识。文本分类分为两个部分:特征工程和分类器,特征工程是将数据变为信息的过程,是最为耗时耗力的,却又相当重要的过程[2]。DF(词频)、CHI(卡方检验)、IG(信息增益)、ECE(期望交叉熵)等常常被用来作为特征选择的依据[3]。Bao Guo等[4]运用TF-IDF将文本分词后向量化作为文本的特征进行分类。牛玉霞[5]对特征选择算法IG进行改进,并与DF进行了结合,提取了更为重要的特征用以文本分类,提高了文本分类的精度。文本分类的另一部分分类器是将信息变为知识,即我们所想得到的结果,前人对文本分类采用的分类器算法不断更新,使得文本分类的预测效果越来越好。Peixin Liu等[6]将朴素贝叶斯(Naïve Bayesian)作为分类器对短文本进行分类取得了很好的效果。卢兴[7]使用支持向量机对中文短文进行分类,并证明了其有效性。
本文根据网购评论数据预测购物体验的积极与消极倾向,由于积极评论的数量远远多于消极评论,而消极评论对商家的决策过程更为重要,所以识别少样本(消极倾向)的工作更为重要。为适应此数据高维不平衡特征,采用TF-IDF特征提取方法,在算法上提出融合随机森林和逻辑回归的Stacking算法,通过对比,文本分类的效果有所提高。
2 相关技术
2.1 TF-IDF(词频-逆文档频率)
TF-IDF是一种统计方法,它的计算公式为TF(词频)×IDF(逆文档频率),它的含义是如果一个词在某段文本中出现的频率越多,而在所有的文本中出现的频率越少,则这个词的tfidf权值越大,就越能代表这个文本[8]。

1)TF(词频)是指某个词在所有的文本中出现的频率:2)IDF(逆文档频率)即文档频率的倒数,表示在每个文本中经常出现的词对所有文本的影响反而会小[9]:

2.2 随机森林(Random Forests)
随机森林是Bagging集成算法的一个扩展,它是以决策树为基分类器来构建Bagging集成的,并且在集成的过程中引入了随机属性选择,即每个属性都有被选择加入训练过程中,保证了基学习器的多样性,提高了模型最终的泛化性能[10]。
随机森林最终的决策结果由所有基分类器决策树的分类结果的组合得出,如图1所示。对于分类问题,选用投票法来决定,对每个决策树的分类结果进行统计投票,少数服从多数;对于回归问题,则取决策树分类结果的平均值作为随机森林的结果[11]。
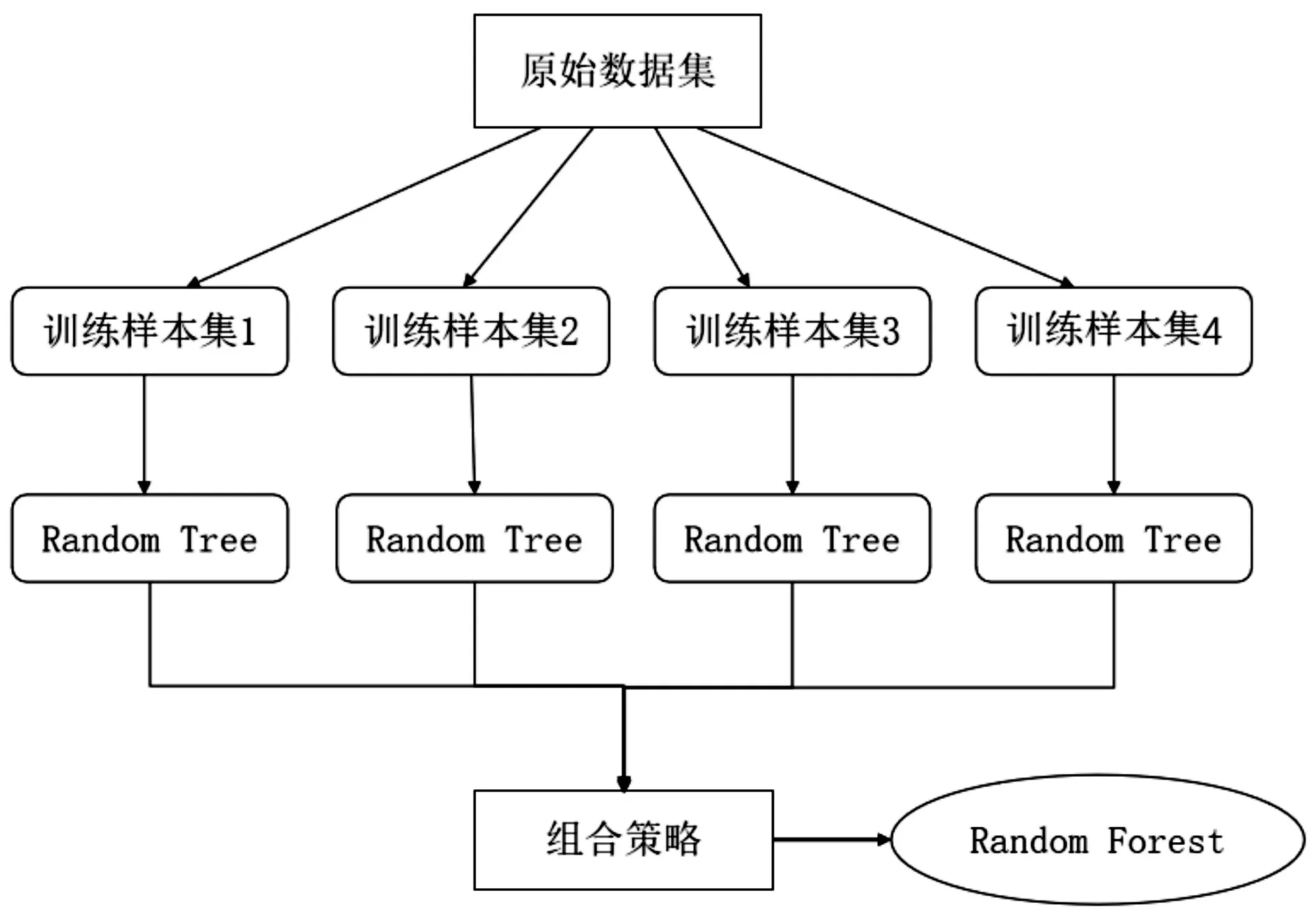
图1 随机森林示意图
随机森林的优点如下。
1)它能够处理高维度数据,并且不用进行特征选择这项耗时耗力的工程;
2)它容易做并行化处理,且速度比较快;
3)最重要的一点,随机森林在处理不平衡数据集的问题上,可以平衡由数据集带来的误差[12]。
2.3 Stacking集成算法
Stacking是将多个不同的机器学习器结合在一起的一种集成算法,与投票法集成不同的是,Stacking将基学习器叫做初级学习器,用于结合的学习器叫做次级学习器[13]。实现Stacking的过程如下。
1)划分数据集D来训练初级学习器h1,h2,h3…;
2)用训练出来的若干个初级学习器对D上的测试集分别进行预测,将所有预测结果结合在一起,作为次级训练集,训练次级学习器[14];
3)对最初划分的需要预测的数据集用每个初级学习器进行预测,然后将预测的所有结果取平均,再用次级训练器对处理后的预测结果再预测,得到最后的结果[15]。
3 基于不平衡数据的改进Stacking模型
3.1 不平衡数据处理方法
在二分类试验中,一般把所关注的一类样本,即少数类样本视为正类,另一类则认为是负类。当正类的样本数量远小于负类的样本数量时,这种情况下的数据称为不平衡数据。
不平衡数据通常通过采样方法来改变数据分布,以减少数据的不平衡度。采样方法有过采样和欠采样,即提升少类样本数或减少多类样本数,从而增大正类特征对分类器的影响,但若只是复制样本的过采样,易导致模型过拟合;只是对负类样本进行欠采样,模型的泛化能力会降低[16]。
故本文不局限于数据采样方法,而是结合采样方法,并在算法层面上做出改进。
3.2 融合随机森林和逻辑回归的改进Stacking模型
每次从负类样本中不放回抽取一定比例的样本,保留所有正类样本,合并成一个训练集,依次训练随机森林模型。具体步骤:分别从负类中随机抽取与正类一样多、数量为正类5倍、10倍、16倍和25倍的数据,与所有正类样本构成一个训练集,依次迭代训练五个随机森林。
抽样倍数不同可以得到不同参数的分类器,保证了分类器的多样性,将得到的五个随机森林作为初级分类器。考虑TFIDF的高维稀疏性,选择逻辑回归分类器作为次级分类器。图2展示了改进Stacking模型的一部分。
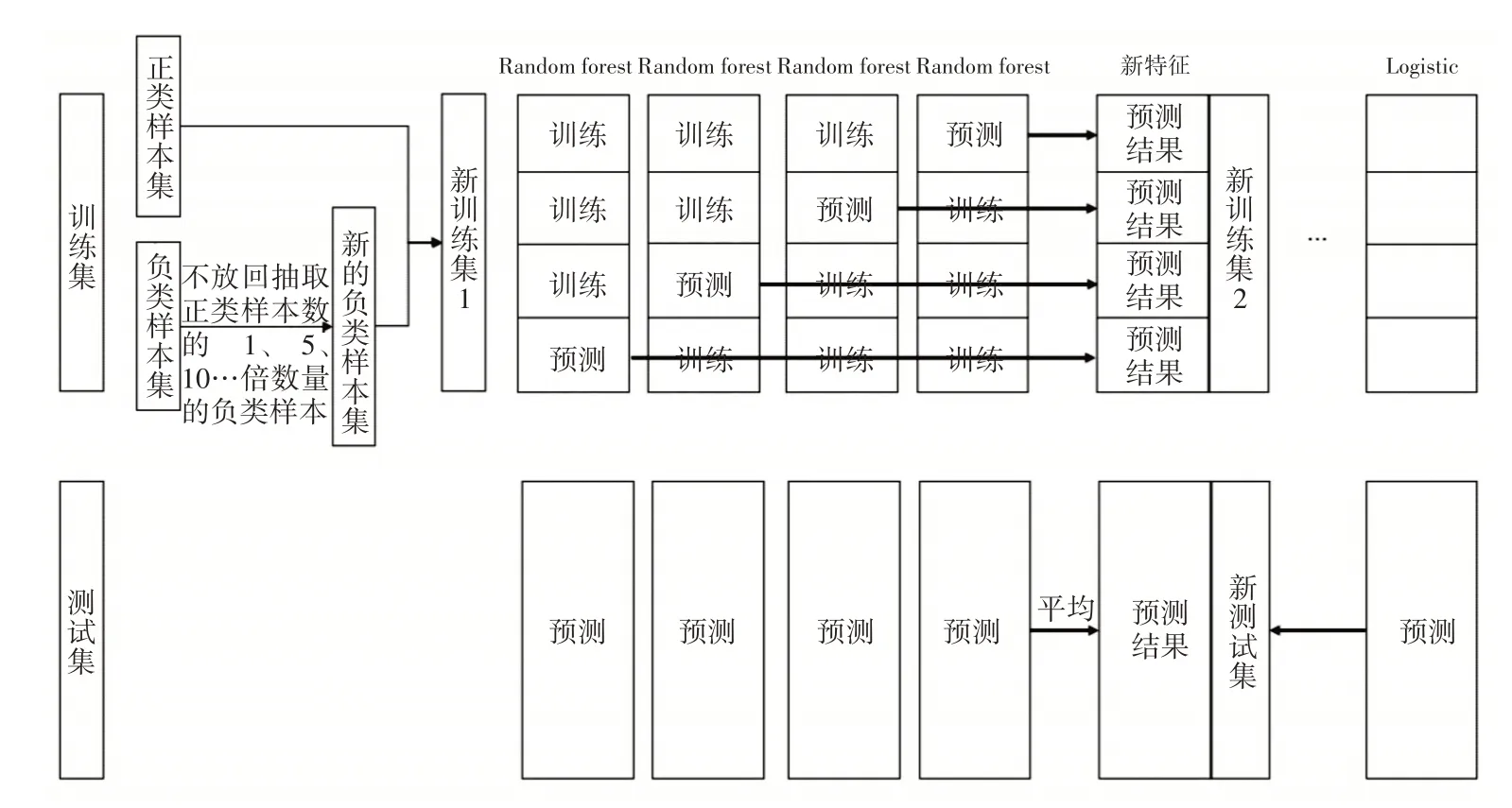
图2 改进Stacking模型
4 实验设计与结果分析
本 文 数 据 集 来 自Kaggle(http://www.kaggle.com)上提供的Amazon电子商务平台的购物评论。该数据集包括67992条评论和评分(1级~5级),笔者将1、2等级视为消极评论,其他视为非消极评论。数据集信息如表1所示。
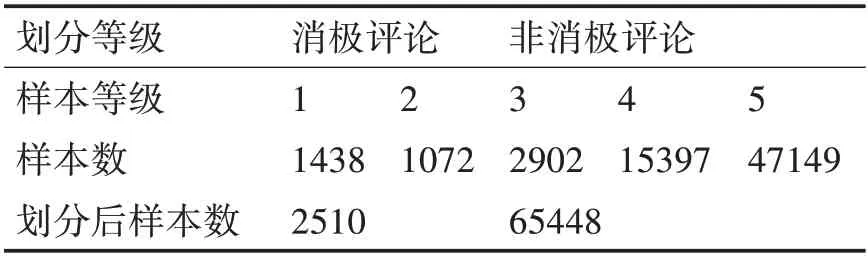
表1 数据集信息
由表1可知,数据存在高度不平衡,将1、2等级的消极评论视为正类,其他等级的视为负类,正类与负类的比值达到1∶26以上。
4.1 数据清洗
本文数据集中的评论为英文评论,对于英文文本的处理包括HTML字符转换、解码数据、移除Stop word、移除标点符号、移除表情符、拆分黏在一起的词、去除URL等[17]。
4.2 特征提取
文本数据属于非结构化数据,机器往往是不能对这种数据进行运算分析的,一般要转换成机器能分析的结构化数据,故将文本数据特征进行向量化[18]。在文本分类中,词向量是一种常用的文本表示方法[19]。词条权重的计算往往需要考虑:
1)如果一个词在一篇文档中出现的频率越多,则对文本识别的贡献越大;
2)如果一个词在所有文档中出现的次数越少,则它对于不同文档的区分能力越强[20]。
TFIDF综合考虑到了这两点。本文将评论中所有的词放入tfidf的词库中,然后计算tfidf值作为词条权重,将文本数据转换为词向量,从而进行分类器的训练[21]。
4.3 评价指标
在大多数研究中,通常用混淆矩阵来评价一个模型分类的好坏,笔者根据本文数据集高维不平衡的特征,选择召回率(Recall)、精确率(Precision)、F1测度值(F1-Measure)和G-mean作为最终结果的评价标准[22],因为这种数据特征的分类准确率一般会很高,而其他指标却不佳,所以不能选择准确率作为评价本文数据集的指标。下面基于表2计算召回率、精确率、F1值和G-mean[23]。

表2 混淆矩阵
4)G-mean在不平衡数据分类的评价中使用较广,它同时考虑了召回率和特异率,综合评估了算法性能,计算公式如下:
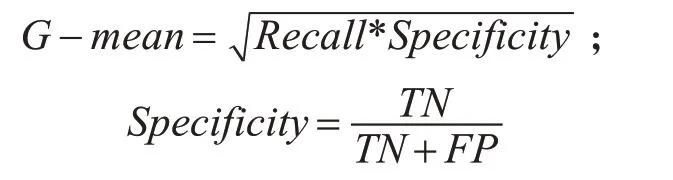
4.4 实验结果
本文的抽样比例为8∶2。由于本文主要目标是提高正类样本的分类效果,且结果表明在正类样本预测效果提高的同时,负类样本分类效果依旧表现优异。负类样本的分类效果对本文研究不具有参考价值,所以表3只给出了单个随机森林和Stacking模型的对正类预测的评价指标的汇总。
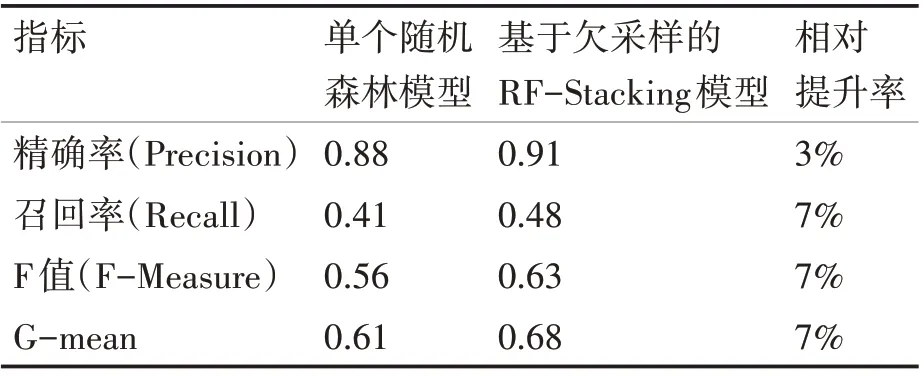
表3 单个随机森林和Stacking模型结果比较
由表3可以看出,Stacking模型的各项指标都要优于单个随机森林模型。一般情况下,召回率提高的同时必然会损失一部分精确率,但本文所选择的模型在召回率提高的同时保证了精确率,说明此模型对高维不平衡数据预测是有效的。
并且笔者将此模型的预测效果与当前文本分类主流算法RNN(循环神经网络)的预测效果进行了比较,发现其准确率达到了97.88%,而RNN的准确率为97.58%,且此模型比RNN的运行用时更短,这进一步说明了本文提出的改进Stacking模型能够有效提高不平衡文本分类的分类效率。
5 结语
为提高消极评论的分类效果,本文提出了一种基于欠采样的随机森林Stacking模型,该模型充分适应本文数据集高维不平衡特征,构造不同倍数的欠采样得到多个不同的基分类器,根据Stacking集成随机森林和逻辑回归,对测试集进行预测,对单个随机森林和改进Stacking模型预测分类结果进行了对比,并与深度学习RNN算法的分类结果和分类速度进行了比较。实验结果表明,本文提出的改进Stacking模型能够提高高维不平衡评论数据的分类效果,充分验证了本模型的有效性。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
领导决策信息(2018年16期)2018-09-27
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
软件导刊(2017年4期)2017-06-20
数学学习与研究(2017年3期)2017-03-09
少儿科学周刊·少年版(2015年3期)2015-07-07
