
结合传感器阵列和BP神经网络的挥发性有机物定量检测系统
2021-10-11 02:42金成王久洪张成张泽王海容
西安交通大学学报 2021年10期
金成,王久洪,张成,张泽,王海容
(1.西安交通大学机械制造与系统工程国家重点实验室,710049,西安;2.西安交通大学机械工程学院,710049,西安)
近年来,在医疗、工业、农业、军事等领域对挥发性有机物(VOCs)特别是异戊二烯的检测系统需求越来越多。2012年,杰西卡等人通过气相色谱-质谱仪进行慢性肝病患者呼气研究,得出异戊二烯变化的可能原因是氧化应激、伤肝、新陈代谢等[1]。因此,对异戊二烯的识别与检测成为了慢性肝病检测的研究重点。目前国内外对于异戊二烯的检测研究还比较少,张泉水等人使用气相色谱-质谱联用仪探究精神分裂症患者与异戊二烯的关系,发现两者存在高度相关性[2]。孙美秀等人研究了使用光腔衰荡光谱技术(CRDS)检测非酒精性脂肪肝病人呼出气体中的丙酮与异戊二烯成分[3]。王禹等人使用二次电喷雾电离-离子迁移率谱系统检测样品中的异戊二烯气体[4]。王海容等人研制了用于异戊二烯检测的气体传感器[5],接着提出使用半导体气敏传感器阵列检测人体呼出气体的方案[6]。Han等人研制了花状In2O3半导体传感器检测异戊二烯有望用于呼吸分析[7]。
目前,对于混合物中异戊二烯的检测大部分还是使用基于质谱、色谱、光谱等原理的大型分析仪器,分析时间过长,仪器本身体积大、价格高、操作复杂,而气体传感器检测异戊二烯大部分只针对单一异戊二烯气体。由于异戊二烯在人体呼气中的浓度为痕量级别(体积分数为10-6量级),且浓度范围小,难以检测,因此本文使用金属氧化物半导体传感器阵列与模式识别算法结合的方法检测混合气体中的异戊二烯气体浓度,更加方便快捷,适用于大规模筛查检测的应用场景。
1 测试系统
1.1 传感器阵列
气体传感器选择使用MEMS工艺半导体材料制造的金属氧化物半导体(MOS)气体传感器,其通常使用SnO2、ZnO、TiO2和In2O3等半导体氧化物作为敏感材料[8-12],具有灵敏度高、成本低、稳定性好等特点。肝病的呼吸标志物异戊二烯为内源性气体,为了实现抗干扰能力,配气中选择了与人体疾病有关的内源性气体,即与肾脏疾病相关的氨气和与糖尿病有关的丙酮,以及与饮酒人群相关的乙醇[13-15]。本文针对混合气体的各气体组分,选择了表1所示的4个商用传感器组成传感器阵列。

表1 传感器型号及检测范围与检测气体Table 1 Sensor model, detection range and detection gas used in experiments
1.2 测试系统
图1所示测试系统主要由配气系统、传感器阵列气室、AD转换与数据采集模块、上位机组成。配气系统主要由储气钢瓶和质量流量计(MFC)及管路组成,通过质量流量计配合连通阀进行气体混合,使用纯净空气为载气控制整体气流平稳流动。气室内置传感器阵列,体积小,密封性好。由于测试浓度低、梯度小,因此传感器信号采集电路具有良好的抗噪能力,可避免噪声的干扰。测试电路将传感器电阻值信号转换成电压值信号,通过16位AD76064数据采集模块进行模数转换。通过STM32采集转换数据,使用串口通信将数据传输到上位机保存。
1.3 气体测试
测试实验分成两组进行:实验一选择浓度较高的异戊二烯与氨气的二元混合气体,用模式识别算法预测异戊二烯浓度;实验二的VOCs混合气体包括异戊二烯、丙酮与乙醇。传感器对于同性气体的响应更难分离,且数据差异性变小。两组实验各配置了25组样本。实验二由于有3种气体,理论上应该配置75组,但是这里的乙醇为了模拟可能存在的其他VOCs气体的干扰,因此实验二主要为异戊二烯与丙酮变化的25组样本。各样本混合物的标签及其对应的各组分体积分数如图2所示。实验一测试时异戊二烯体积分数分别为0.5×10-6、0.7×10-6、0.9×10-6、1.1×10-6、1.3×10-6。首先将异戊二烯的体积分数固定,氨气的体积分数逐渐变化为4.5×10-6、4.8×10-6、5×10-6、5.3×10-6、5.5×10-6,测试完毕后,异戊二烯增加,继续重复上述的过程。实验二混合气体各组分配比方法与实验一类似,使用质量流量计设置不同的流量,整体流量控制在200 mL/min,使用空气补足剩下的流量。异戊二烯体积分数分别为0.1×10-6、0.2×10-6、0.3×10-6、0.4×10-6、0.5×10-6,测试时首先将异戊二烯体积分数固定,丙酮的体积分数逐渐变为0.1×10-6、0.2×10-6、0.3×10-6、0.4×10-6、0.5×10-6,乙醇的体积分数变化为1.5×10-6、1.75×10-6、2.0×10-6、2.25×10-6、2.5×10-6,且混合物中乙醇的体积分数为随机的,测试完毕后,增加异戊二烯体积分数,继续重复上述的过程。
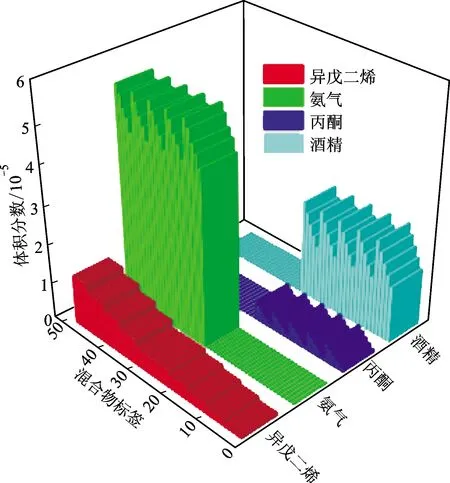
图2 混合物各组分体积分数Fig.2 The volume fraction of each component of the mixture
具体测试过程如下:气路通入纯空气对传感器进行预热与清洗,待基线稳定后,切换通道;实验一向气室通入异戊二烯、氨气与空气的混合气体,实验二向气室通入异戊二烯,丙酮,乙醇的混合气体;单片机进行数据采集并将传感器电压值发送到上位机存储。待反应完成后,通入空气,进行清洗,准备下一次测试。
图3为25组混合气体响应曲线峰值图,其中体积分数配比策略为先异戊二烯体积分数固定,丙酮以0.1~0.5逐渐上升,接着异戊二烯体积分数上升0.1,丙酮继续如上述一样上升,直到异戊二烯体积分数到达0.5,共5×5即25组样本峰值。可以看到传统的单一传感器峰值响应并不适合混合气体的峰值的响应,混合气体的响应不是线性关系而是一种非线性关系。

图3 3种传感器的混合气体响应信号峰值曲线Fig.3 Peak value diagram of mixed gas response curve
2 异戊二烯检测算法
2.1 特征提取
使用数学概念提取响应曲线几何特征,将得到的样本集进行归一化处理,得到模式识别算法中的输入集。采用限幅滤波进行采样,以克服意外干扰。设置前后两次数据可允许的最大偏差,每当有新数据到来时与上一个数据进行比较,若在允许偏差范围内,则本次数据有效,反之则无效,使用上一次数据值代替本次数据。采用去除基线的方法消除温度、气体流速等因素的影响。
特征提取希望将能够将表达样本的信息集中到尽可能少的、理想的独立特征中。考虑到样本采集数据的时域特征,特征提取采用基于原始数据表达的响应曲线法。根据传感器响应数据,将采样数据保存到一个数组中,对数组中的数据进行操作。由于检测的目标气体浓度较小,且梯度间隔小,实验一得到如图4中所示的4个曲线特征,除了将常见的峰值作为特征外,增加曲线下面积特征来增加样本的分离度,同时使用最大上升斜率和到达峰值的时间来表示传感器的特征。实验二得到如图4中所示的7个曲线特征,在实验一的基础上单独分出上升和下降时间和曲线下面积来增加样本的分离度,同时使用最大下降斜率和下降时间进一步细化传感器的特征。使用归一化让每一个特征值处在[0,1]之间,得到测试样本的样本集,使用模式识别算法进行气体识别与浓度预测。
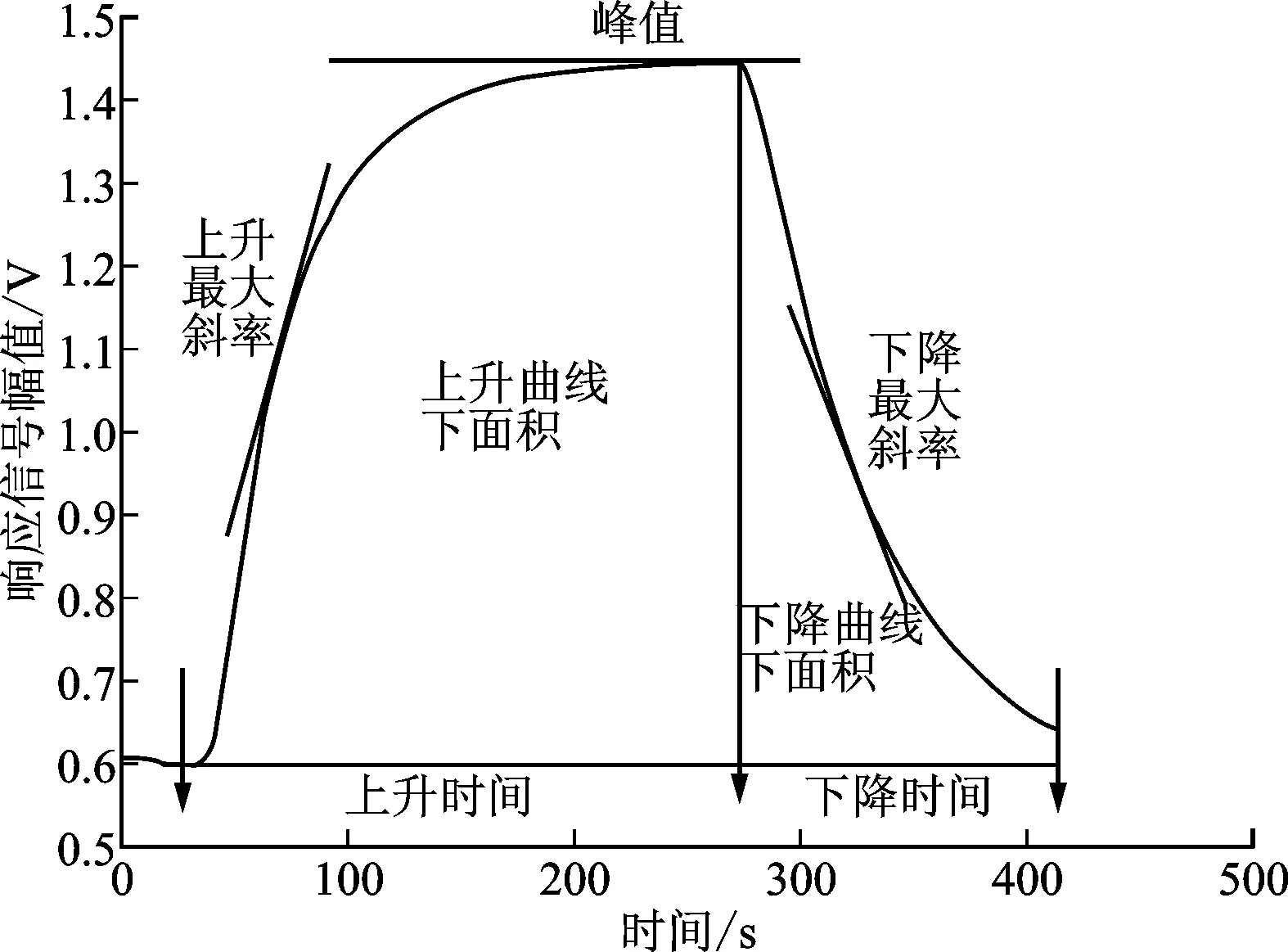
图4 两组实验的特征提取曲线Fig.4 Feature extraction curves of two sets of experiments
图5a为实验一的特征热力图,纵坐标为按照顺序对应的不同浓度的异戊二烯和氨气样本,横坐标为TGS2602和MQ137传感器响应曲线的峰值、曲线下面积、最大上升斜率和到达峰值时间共8个特征。前4个特征即TGS2602的响应曲线的几何特征随着异戊二烯和氨气浓度升高颜色逐渐加深,而后4个特征即MQ137传感器随着氨气的浓度升高颜色逐渐加深。这表明了传感器之间的交叉响应特性,有利于算法对异戊二烯浓度的预测。图5b为实验二的特征热力图,纵坐标依次为异戊二烯和丙酮的不同浓度的样本,横坐标为TGS2602、MMD1013s和TGS2600传感器响应曲线的峰值、上升时间、上升曲线下面积、下降时间、下降曲线下面积、上升最大斜率、下降最大斜率共21个特征。由图5可见,对于TGS2602传感器,峰值随着异戊二烯浓度的升高,颜色逐渐加深;对于MMD1013s传感器,峰值随着丙酮的上升而逐渐上升,颜色趋势呈现以5个样本为一组的依次加深;对于TGS2600传感器,在低浓度时峰值比前两个传感器响应大,但浓度升高,传感器的灵敏度较差,响应相对变差,同时上升下降时间和曲线面积呈正相关,上升和下降斜率更受传感器本身材料的性能有关。
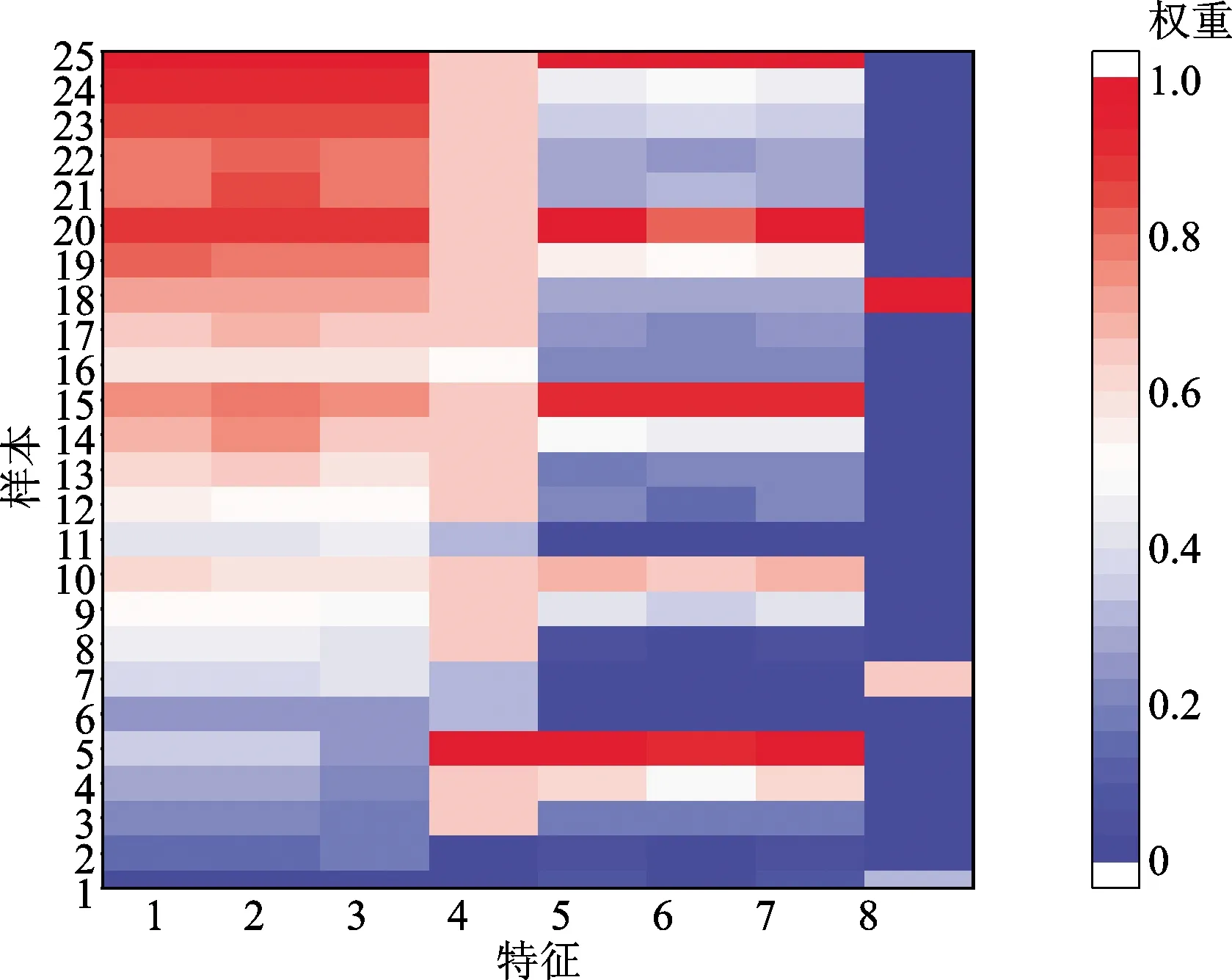
(a)实验一的特征热力图
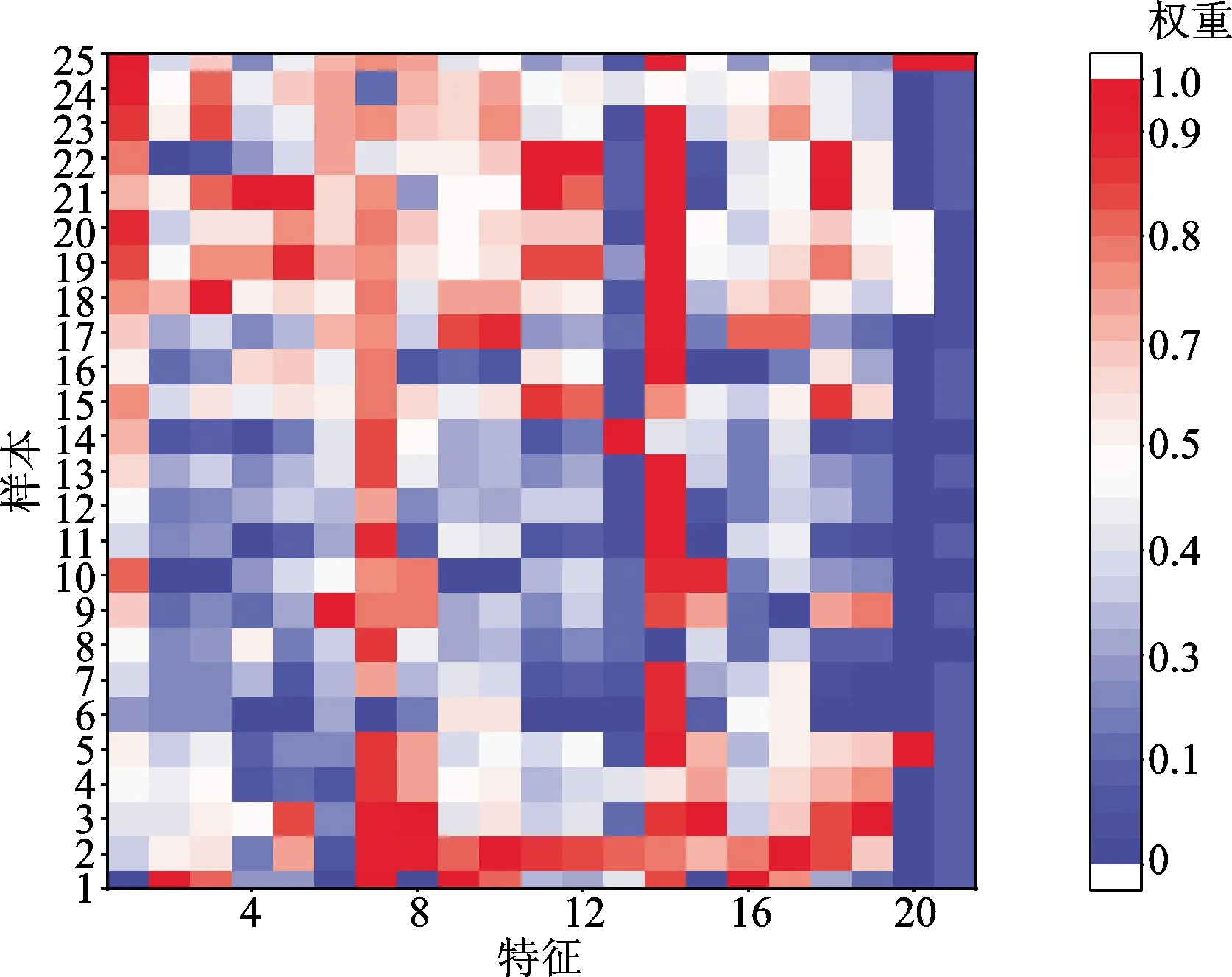
(b)实验二的特征热力图图5 两次实验的特征热力图Fig.5 Heat maps of two experimental features
2.2 特征降维
实验一提取了两个响应传感器的特征值,得到了8个特征;实验二提取了3个响应传感器的特征值,得到了21个特征。为了实现两次实验的预测结果对照实验,使用主成分分析(PCA)得到实验二前10维的数据贡献率。图6a显示实验二的数据取排序好的前8维成分即可代表90%以上的总成分。同时图6b将两次样本数据使用PCA投影到前3个主成分上,观察到主成分1(PC1)、主成分2(PC2)、主成分3(PC3)分别占55.6%、24.3%和16.5%。通过两次实验样本的投影图可以看到两次实验数据有明显的分界面作为区分,但是两个数据之间的距离又很接近且存在混杂的效果,因此存在两组数据融合后进行异戊二烯预测的可能。

(a)第2组实验前10个主成分的贡献率

(b)两组数据在PC1、PC2、PC3上的投影图6 主成分分析贡献率图Fig.6 A contribution rate graph from principal component analysis
2.3 量化算法
BP神经网络由于其简单性和可解释性常用于对非线性回归问题的解决[16-17],本文使用BP神经网络对连续测试的样本进行浓度的预测。
图7显示的BP神经网络拓扑结构设计图中,特征数据集的总维数为n,训练集特征值为输入值xn,预测得到的混合气体各组分浓度从输出层输出。隐含层的神经元结构,左侧代表神经元的输入zi(n),其值为输入层xi(i=1~n)乘以权值wij(n)累加后再加上阈值bij(n)的计算结果,j代表权值所属的层;右侧代表神经元输出ai(n),是将左边输入值带入激励函数后得到的输出结果。输出层与中间层类似,输入的是中间层神经元输出项ai(n),输出的是预测的气体浓度值。BP神经网络隐含层的结构设计经验公式如下:

图7 BP神经网络拓扑结构设计Fig.7 Topology design of BP neural network
(1)
式中:a为输入层个数;b为隐含层个数;c为输出层个数;n为0~10的常数。
隐含层的神经元个数的选择,根据经验公式选择4~13个神经元进行训练。神经元个数过小,会使神经元所代表的信息太少,而神经元个数过大,会使模型过拟合,精度不一定更高。
信息的均方误差(MSE)计算公式为
(2)
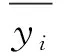
图8为神经网络隐含层节点(神经元)不同个数时的均方误差,由图8可见,当神经元个数为10时,信息的均方误差最小,代表误差结果更小,预测更准确,因此选定神经元个数为10。
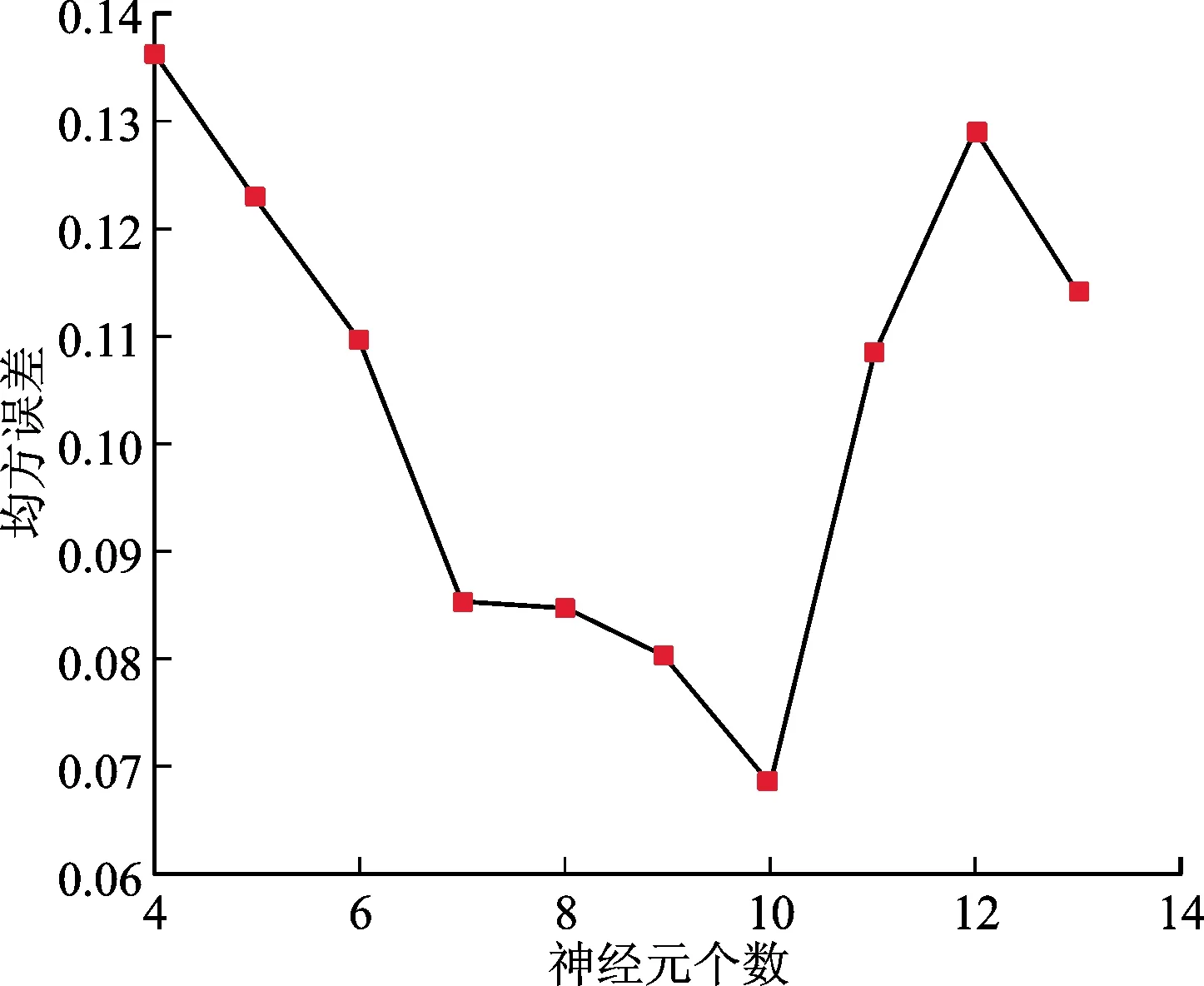
图8 神经网络隐含层节点不同个数的MSEFig.8 MSE with different numbers of nodes in the hidden layer of the neural network
本文使用5折交叉验证,为了防止机器找规律的学习,将样本随机分布后分成5组[18]。交叉验证过程如图9所示,每次取黄色的一组作为测试集,剩下的作为训练集,反复进行5次,最后求平均误差。利用均方误差、均方根误差、交叉验证均方误差及交叉验证均方根误差这4个指标来评估预测效果的好坏。若均方误差高,则表示模型过于简单,存在潜在变量占少数,也就是为一个欠拟合模型,即无法表达特征与目标值之间的实际关系。在这里的应用中,这就表明了不同的传感器对不同的气体的交叉敏感性无法得到很好的补偿。另一方面,一个模型可能会被太多的潜在变量过度拟合,这通过一个小的均方误差与一个大的交叉验证均方误差同时变得明显。因此,一个好的模型是一个尽可能少的潜在变量,一个小的均方误差,以及均方误差和交叉验证均方误差之间的小差异[19]。
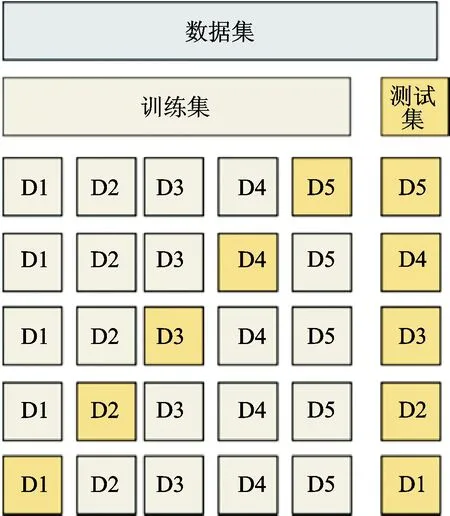
图9 5折交叉验证过程Fig.9 5-fold cross-validation process
2.4 算法的训练
BP神经网络使用梯度下降法进行训练,是一种非线性的逐步逼近式优化方法,可能造成布局最小值,使结果变差。目前常用的优化训练方法有弹性BP算法自适应学习速率法、共轭梯度法、拟牛顿算法、Levenberg-Marquardt(LM)优化算法[20]等,但这些优化算法仍是从局部考虑优化连接权值,会造成局部最小值,因此本文引进了遗传算法(GA)来改进BP神经网络,遗传算法从全局考虑出发,更适合解决全局寻优问题。
表2为有弹性BP算法、自适应学习速率法、共轭梯度法、拟牛顿算法、LM优化算法、CA算法+LM组合优化算法对50组混合样本的训练结果。由表2可以看到:有弹性BP算法与自适应学习速率法计算的均方误差在达到设定的迭代最大值时也达不到设置的精度;共轭梯度法、拟牛顿算法虽然能够达到设定的均方误差,但是迭代次数多,训练时间长;LM优化算法能借由执行时修改参数达到结合高斯-牛顿算法以及梯度下降法的优点,并对两者之不足作改善,训练出的结果经过很少的迭代次数逼近设定的均方误差,有良好的训练效果。同时遗传算法通过优化初始权值阈值后,LM优化训练算法逼近设定的均方误差的迭代次数进一步减少,训练速度更快。
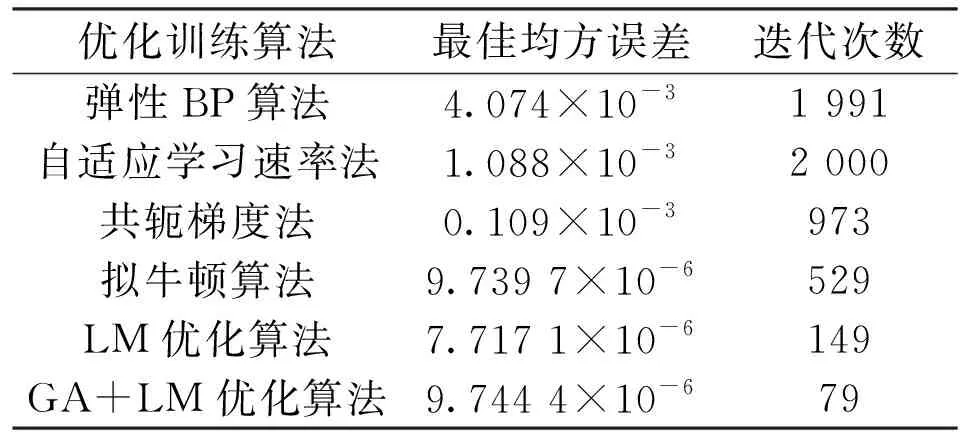
表2 6种训练方法对50组混合样本的迭代次数和均方误差Table 2 The number of iterations and mean square error of 6 training methods for mixed samples
训练选定的样本个数为混合实验测试得到的50个样本,使用5折交叉验证,将样本集随机分为5组,每次使用一组作为测试集,其他9组数据作为训练集训练网络。交叉验证10次,每个子样本验证一次。首先使用BP网络进行训练并预测浓度,将预测的结果保存下来。同时将网络的连接权值和阈值作为遗传算法的个体基因输入进行训练:达到设定的优化指标或者最大代数后,将得到的最终种群的最优个体解码即得到了优化后的网络连接权值。将连接权值重新赋予BP神经网络作为初始权值,重新使用BP神经网络用相同的参数训练网络,达到设定的精度时或者达到最大的迭代次数,则算法结束,得到预测的样本浓度。BP神经网络与遗传算法优化后重新训练的参数保证一致。
3 异戊二烯浓度定量检测分析
3.1 单独测试样本的预测结果
为了对照混合测试样本的预测结果,对实验一和实验二分别采用BP神经网络算法(BPNN)和GA优化的BP神经网络算法(GA+BPNN)进行浓度预测。具体的变化如下:对于实验一,样本集个数为25,维数为8。神经网络拓扑结构如前边介绍,训练方法保持不变,交叉验证选为5折交叉验证。将经过训练与测试得到的预测样本的浓度与实际样本浓度投影下来如图10a所示,可以看出,GA+BPNN组合算法的预测样本比单独的BPNN算法的预测样本更接近中轴线。
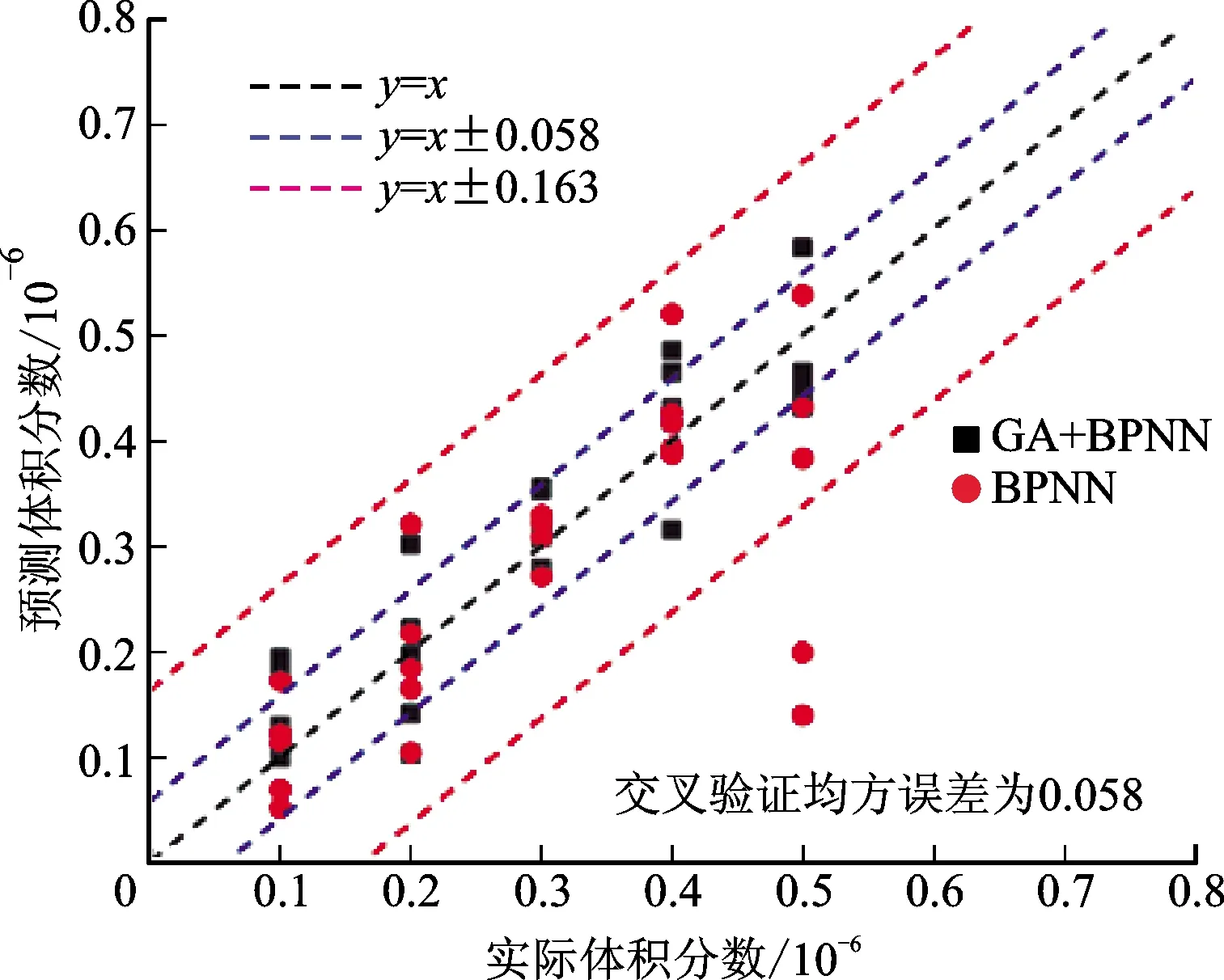
(a)实验一的预测结果

(b)实验二的预测结果图10 两组实验使用GA+BPNN与BPNN的样本预测浓度与实际浓度比较Fig.10 A comparison of the predicted concentration and the actual concentration of samples for two sets of experiments using GA+BPNN and BPNN
对于实验二,样本集选择降维处理后的数据,个数为25,维数为8。神经网络朴拓结构输入层与隐含层不变,输出层改为3种气体的浓度输出,训练方法不变,交叉验证选择5折交叉验证。将经过训练与测试得到的预测样本的浓度与实际样本浓度投影下来如图10b所示,可以看出,GA+BPNN组合算法的预测样本值比单独的BPNN算法的预测样本值更接近真实值。
3.2 混合测试样本的预测结果
将经过训练与测试得到的预测样本的浓度与实际样本浓度投影下来如图11所示。由图11可以看到,GA+BPNN预测样本比BPNN预测样本更接近中轴线。由图10和图11可以看到,GA+BPNN组合算法的预测误差与准确率明显高于BPNN算法,同时由于遗传算法从全局上搜索最优解,大部分的预测数据都均匀分布在两条蓝色虚线附近,而单独的BP神经网络会由于出现局部最小值的问题,部分样本数据与整体预测样本偏离较大。进一步从样本浓度上分析,对于浓度较高的样本预测,预测值更接近真实值,这可能是因为浓度越高,传感器响应越大,对于数据的交叉敏感性越明显,得到的预测结果更准确。对于低浓度气体,传感器响应灵敏度降低,而且更容易受背景气体干扰,从而产生噪声信号,影响预测结果。

图11 混合样本使用GA+BPNN与BPNN的样本预测浓度与实际浓度比较Fig.11 A comparison of the predicted concentration and the actual concentration of the mixed samples using GA+BPNN and BPNN
结合实际体积分数与预测体积分数,使用GA+BPNN组合算法的预测结果以均方根误差说明:实验一的均方误差为0.077,实验二的均方误差为0.058,混合实验的均方误差为0.100。实验一的测试范围为0.5~1.3,实验二的测试范围为0.1~0.5,混合实验的测试范围为0.1~1.3。可以看到,均方误差同样受测试范围影响,测试范围大,均方误差也会增加。增加了特征值数量的实验二得到交叉验证均方误差更小,可以看出增加表达样本特点的特征值,更有利于预测结果的准确性。
4 结 论
本文主要进行了基于传感器阵列与模式识别算法对挥发性有机物检测问题的探究,搭建了一种采样方便、检测迅速的测试系统,同时模式识别算法完成了对混合气体实验挥发性有机物气体异戊二烯的检测与准确率优化,3种实验异戊二烯预测体积分数均方根误差均在0.1以内。该研究工作具有泛化能力,可以通过调整传感器阵列中的传感器进行其他VOCs的检测。
猜你喜欢
广西医科大学学报(2021年9期)2021-11-30
今日农业(2021年17期)2021-11-26
领导决策信息(2018年16期)2018-09-27
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
中学生数理化·高三版(2016年9期)2016-05-14
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
海峡科学(2013年3期)2013-10-21
