
基于概率语言术语集中考虑专家权重的决策方法研究*
2021-10-25 13:00朱国成
曲阜师范大学学报(自然科学版) 2021年4期
朱国成
(广东创新科技职业学院通识教育学院,523960,广东省东莞市)
0 引 言
生产实践中,由于资源的有限性及人们认知周围环境思维的局限性,在面对众多选择结果时往往犹豫不决,怎样科学合理的选出最优方案是摆在人们面前必须解决的难题.决策理论对于解决此类问题大有裨益,理论分为经典决策理论与不确定信息环境下决策理论.由于传统的精确数值很难完整刻画决策对象的特征信息,人们经常用不确定信息来描述事物性质,例如区间数据[1,2]、三角模糊信息[3]、梯形模糊信息[4]、直觉模糊信息[5]及语言信息[6]等.因为模糊信息数据蕴含更加丰富的信息量,在表征事物性质方面具有明显优势,很快引起了学者关注,模糊信息理论的发展源头则始于1965年Zadeh L A[7]提出的模糊集(Fuzzy Sets,FS)理论.随着FS的大范围应用,其只考虑隶属度这一单一因素的缺点开始显现,为了弥补FS只有单一隶属的不足,Atanassov k等[8,9]定义了直觉模糊集(Intuitionistic Fuzzy Set,IFS)概念,IFS充分考虑了隶属度、非隶属度及犹豫度,相较于FS,IFS拥有更加强大的信息储存能力,在具体应用上能更好服务于生活.例如,梁美社等[10]从相似度的角度出发,给出一种新的直觉模糊相似度计算方法并研究了方法性质,最后将该理论用在模式识别中;石乙英等[11]为了解决IFS中蕴含算子构造方法缺乏理论依据问题,利用重截集与表现定理构造模糊蕴含关系也即直觉模糊蕴含算子,详细讨论了算子性质,算子丰富了IFS理论;连强[12]为了拓宽直觉模糊环境下群决策问题中属性间相互作用的集成算子使用范围,在Hamy平均基础上,将另一种HGA平均算子推广到多属性信息集成中,文中实例验证了方法的可行性.由于IFS中的隶属度为单一量,不能表现决策者犹豫心理,在具体应用中随着解决多属性群决策(Multi-Attribute Group Decision Making,MAGDM )问题水平的更高要求,该理论在使用时渐渐“力不从心”.鉴于此,Torra[13]提出犹豫模糊集(Hesitant Fuzzy Sets,HFS)概念:可以使用多个隶属度来表达决策者的犹豫思想,能够更加全面照顾决策者的判断标准.生产实践中,杨延璞[14]通过引入犹豫模糊语言术语集与粒子群优化算法解决了产品设计评价问题;刘文等[15]在研究犹豫模糊粗糙算子方面向前迈进了一大步,具体做法是利用犹豫模糊拓扑空间与犹豫模糊粗糙近似空间之间关系,完美揭示了犹豫模糊粗糙近似算子的更深层次的本质特征;曲国华等[16]将对偶犹豫模糊(DHFS)结合Heronian平均算子,得到一种新的对偶犹豫模糊几何DHFG-Heronian平均算子和对偶犹豫模糊几何加权DHFGW-Heronian平均算子,通过比较系统分析了2种算子的性质并将DHFGW-Heronian平均算子应用到多属性决策当中,取得了较好决策效果;文献[17]在HFS的基础上定义了一种新模糊集合:区间值q阶犹豫模糊集(IV-q-ROHFS),建立了一类IV-q-ROHFS-Frank集成算子模型并详细分析了其性质,最后将该算子用在解决投资公司的优选问题中.HFS虽完美解决了决策者犹豫隶属关系,但是却忽略了各隶属度发生的可能情况,不能体现决策群体的整体决策偏好,为了解决此类问题,朱斌[18]在其博士论文中将决策群体中对于某个隶属度的认可决策者数量与总体决策者占比作为该隶属度发生的可能性,并将添加可能性后的HFS命名为概率犹豫模糊集(Probabilistic Hesitant Fuzzy Sets,PHFS).概念引起了学者注意后不久,其理论与应用范围既得到了极大丰富与拓展,例如,曹倩等[19]研究了PHFS中概率信息未知情况下的PHFS多属性决策问题;李宝萍等[20]构建一种基于概率犹豫模糊Maclaurin对称平均算子的决策算法,算法可使决策者根据决策风险偏好选择自己信任的参数值进行决策;付超等[21]定义了PHFS基本运算法则并讨论了运算法则的相关性质.类似于HFS,PHFS在应用中也显现出局限性,首先,概率犹豫模糊元(Probabilistic Hesitant Fuzzy Elements,PHFE)中随着隶属度数量的增加其对应的概率在集结时快速衰减的速率尤其明显;其次,PHFE中隶属度对应的概率求解默认各位决策者重要性程度一致,显然现实决策问题中对于评价专家的偏好时有发生,在PHFS环境下的多属性群决策问题中怎样解决以上2种不足显得很有必要,本文从概率语言评价术语(Probabilistic Linguistic Terms Sets,PLTS)的角度出发,对解决以上2个问题进行了有益尝试.
文章按照文献[21]中方法确定语言评价术语(Linguistic Terms Sets,LTS)的相关概率,将决策专家给予属性的LTS信息转换为PLTS信息,属性的PLTS信息中考虑决策专家权重,构造考虑决策专家权重的PLTS模型P(W)LTS,把属性的P(W)LTS信息转化为概率区间值犹豫模糊元(Probabilistic Interval-Valued Hesitant Fuzzy Elements,PIVHFE),将PLTS情境下MAGDM问题映射为概率区间值犹豫模糊集(Probabilistic Interval-Valued Hesitant Fuzzy Sets,PIVHFS )的MAGDM问题.为了防止方案属性进行集结时损失决策信息及避免概率运算衰减问题,利用区间数(Interval Numbers,IN)的积型贴近度公式对各方案属性值两两测度,通过统计各方案属性优胜个数鉴定方案优劣.方法为PLTS环境下的MAGDM问题的解决提供了一种新的思路,文中案例验证了思路的可行性.
1 基础知识
本节描述PHFS定义、PIVHFS定义、PIVHFE定义及其得分函数、IN定义、基本运算法则及IN的积型贴近度公式、LTS、PLTS定义.

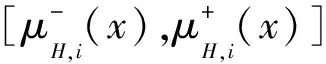
定义3 为了最大化保留有限集PIVHFE信息,其基本得分函数用区间数表示,具体计算定义如下式
(1)



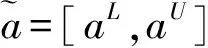

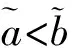


定义6 语言评价术语采用九段制,为了突出较差与较好程度的模糊性,在转换成区间数时加大区分力度,具体对应转换分数如表1.

表1 语言评价术语转换表
定义7[24]在MAGDM问题中,A为决策专家集,X为评价方案集,C为属性集,一个语言术语集S={sα|α=0,1,…,τ},方案x∈X关于属性c∈C的一个PLTS定义为
(2)
其中L(k)(p(k))为方案x∈X关于属性c∈C的语言术语L(k)及对应的概率p(k),#L(P)为L(P)中概率语言术语个数.
定义8 在定义7基础上,考虑决策专家权重的PLTS用P(W)LTS表示,定义为


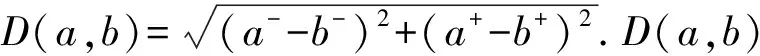
2 属性权重确定路径与方法

定义11 根据定义7,将第n′个方案的第m′个属性评价信息的集合记为PLTS,形式为
(3)

定义12 根据定义8,考虑决策专家权重,将第n′个方案的第m′个属性评价信息的集合PLTS记为P(W)LTS

定义13 根据定义6,将P(W)LTS中的ql′,n′,m′进行置换,置换以后考虑决策专家权重的PIVHFS用P(W)IVHFS表示,
ql′,n′,m′∈L,l′∈{1,2,…,l},0≤Pqn′,m′≤1,0≤ωql′,n′,m′≤1}.
(5)
定义14 考虑决策专家权重的概率区间值犹豫模糊元用P(W)IVHFE表示,定义为
(6)
定义15 根据定义3,第n′个方案的第m′个属性的P(W)IVHFE得分函数计算方法为
(7)
由于公式(7)中表达P(W)IVHFE得分函数符号较复杂,可写为
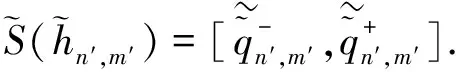
(8)
定义16 根据定义9,各属性的理想属性值确定方法
(9)
按照本文定义确定属性权重步骤如下:
步骤1 将评价专家以LTS形式给出的评分表,按照定义11~定义14将其转换为对应的由P(W)-IVHFN构成的评分表;


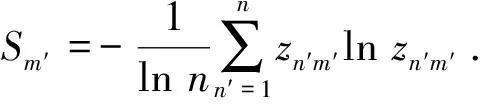

3 多属性群决策步骤建构
在MAGDM问题中,假设方案集A={a1,a2,…,an},属性集C={c1,c2,…,cm},评价专家集R={r1,r2,…,rl},属性权重ωcm′(m′=1,2,…,m)未知,评价专家权重ωrl′(l′=1,2,…,l)已知,第l′位专家给第n′个方案的第m′个属性评价值用语言评价术语ql′,n′,m′表示.决策中的属性皆默认为效益型.
第1步 计算属性权重ωcm′(m′=1,2,…,m);
第2步 利用定义11~定义14将决策问题中语言评价术语ql′,n′,m′置换为P(W)IVHFN并汇总属性P(W)IVHFE;
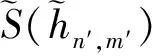


①当T+(an′,an″)>T-(an′,an″)时,说明方案an′优于方案an″.
②当T+(an′,an″) ③当T+(an′,an″)=T-(an′,an″)时,说明方案an′与方案an″等同. 第7步 决策结果比较及说明. 现实生活中“男大未婚,女大不嫁”已经成为困扰很多父母的家庭问题,对于还没“上岸”的大龄男女俨然成为父母及亲戚共同“研究”对象,随着社会经济的发展及择偶条件的理性选择,男女双方更看重对方综合条件.以某父母择婿为例,女儿为某相亲公司会员,根据女儿选择另一半的要求,公司给该家庭提供了3个满足要求男士资料供选择并排序,家庭成员对3位男士从8个方面进行考察:财产、工作、家庭出身、健康、学历、才能、相貌、兴趣等,用符号cm(m=1,2,…,8)表示,家庭4位成员依次为:女儿、母亲、父亲及弟弟,用符号分别刻画为rl(l=1,2,3,4),各位家庭成员参与对3位男士评价,权重为ωr1=0.6,ωr2=0.25,ωr3=0.10,ωr4=0.05,3位男士用符号an(n=1,2,3)代替,讨论结果以语言评价术语形式给出,如表2,利用本文知识对3位男士进行量化分析并排序. 表2 家庭成员讨论评价表 学 历才 能相 貌兴 趣a1{AG|(r1,r2,r3,r4)}{VG|(r2,r3,r4)}{AG|r1}{G|(r2,r3,r4)}{F|r1}{MP|(r1,r4)}{MG|(r2,r3)}a2{MP|(r2,r3,r4)}{F|r1}{F|(r2,r3,r4)}{MG|r1}{VG|(r2,r3,r4)}{G|r1}{F|r3}{MP|(r1,r2,r4)}a3{VG|(r2,r3,r4)}{G|r1}{MG|(r3,r4)}{F|(r1,r2)}{VG|(r1,r2)}{G|(r3,r4)}{F|(r2,r3,r4)}{MG|r1} 本节主要讨论属性权重计算步骤及方法. (1)利用定义11~定义14将家庭成员讨论表(表2)转换为P(W)IVHFN评价表,如表3所示. 表3 P(W)IVHFN评价表 c5c6c7c8a1[0.9,1.0](11,1.0){}[0.8,0.9](34,0.4){}[0.9,1.0](14,0.6){}[0.7,0.8](34,0.4){}[0.45,0.55](14,0.6){}[0.3,0.45](12,0.65){}[0.55,0.7](12,0.35){}a2[0.3,0.45](34,0.4){}[0.45,0.55](14,0.6){}[0.45,0.55](34,0.4){}[0.55,0.7](14,0.6){}[0.8,0.9](34,0.4){}[0.7,0.8](14,0.6){}[0.45,0.55](14,0.1){}[0.3,0.45](34,0.9){}a3[0.8,0.9](34,0.4){}[0.7,0.8](14,0.6){}[0.55,0.7](12,0.15){}[0.45,0.55](12,0.85){}[0.8,0.9](12,0.85){}[0.7,0.8](12,0.15){}[0.45,0.55](34,0.4){}[0.55,0.7](14,0.6){} 在4.1节权重计算基础上,说明决策步骤及方法. 表4 考虑决策者重要性程度的属性值的积型贴近度测度表 本节与4.1节中的权重计算结果、4.2节中的决策结果做系统比较. (1)若不考虑概率对应下的决策者重要性程度,则表2利用定义6将家庭成员讨论表转换为由PIVHFN构成的评价表,如表5所示. 表5 PIVHFN评价表 c5c6c7c8a1[0.9,1.0](11){}[0.8,0.9](34){}[0.9,1.0](14){}[0.7,0.8](34){}[0.45,0.55](14){}[0.3,0.45](12){}[0.55,0.7](12){}a2[0.3,0.45](34){}[0.45,0.55](14){}[0.45,0.55](34){}[0.55,0.7](14){}[0.8,0.9](34){}[0.7,0.8](14){}[0.45,0.55](14){}[0.3,0.45](34){}a3[0.8,0.9](34){}[0.7,0.8](14){}[0.55,0.7](12){}[0.45,0.55](12){}[0.8,0.9](12){}[0.7,0.8](12){}[0.45,0.55](34){}[0.55,0.7](14){} (2) 利用定义3,将表5转换为PIVHFE基本得分函数矩阵S[hn′×m′]n×m,按照4.1节中做法,可得属性权重为:ωc1=0.1455,ωc2=0.1769,ωc3=0.0057,ωc4=0.2431,ωc5=0.0069,ωc6=0.1007,ωc7=0.2430,ωc8=0.0782. (3) 根据4.2节中决策步骤,绘制不考虑决策者重要性程度的属性值的积型贴近度测度表,可得Q1,2=5>4,Q1,3=3<4,Q2,3=1<4, 3位男士排序a3≻a1≻a2. (4) 决策结果说明 在考虑概率对应的评价者重要性程度后,有两方面差异显著,首先在属性重要性认可程度上,考虑女儿及各位家庭成员权重前后,属性c1,c3,c5,c7重要性发生极大变化;其次,在最优男士排序认同上也发生了变化,具体如表6所示. 表6 决策比较表 事实上,PIVHFS中概率反应的是决策整体偏好,只强调“整体性”,而考虑了概率对应决策者重要性程度后,兼顾了决策整体中的个体重要性,所以在决策过程中考虑的因素更加全面.结合例题,虽然是家庭成员集体对所有男士进行评价,但是作为选择另一半的女儿,其观点的重要性“不言而喻”,排序结果也证明了这一点. 文章把决策专家给出的语言评价术语转换为区间数,并将专家对该区间数的认可度换算为概率,构造P(W)IVHFS,与经典PIVHFS多属性群决策相比,兼顾了隶属度发生概率对应下的决策专家总的权重,例子说明了这样做的必要性.为了防止P(W)IVHFE中数据集结损失决策信息,本文利用区间数的积型贴近度公式对不同方案对应的相同属性进行测度,通过统计大于1的测度结果数量来达到鉴定方案优劣目的,做法优点是无需定义集结算子,计算简单,由于采用区间数刻画决策信息,能够最大限度保留决策群体及个人评价信息数据,缺点是对于具有“一票否决”式重要的属性存在,该决策方法不太适合.未来,在P(W)IVHFS的多属性群决策当中基于方案序关系的研究或决策信息当中蕴含的代数结构还需要研究者给予更多关注与探索.4 应用举例


4.1 属性权重计算



4.2 决策过程
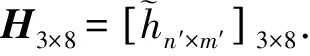
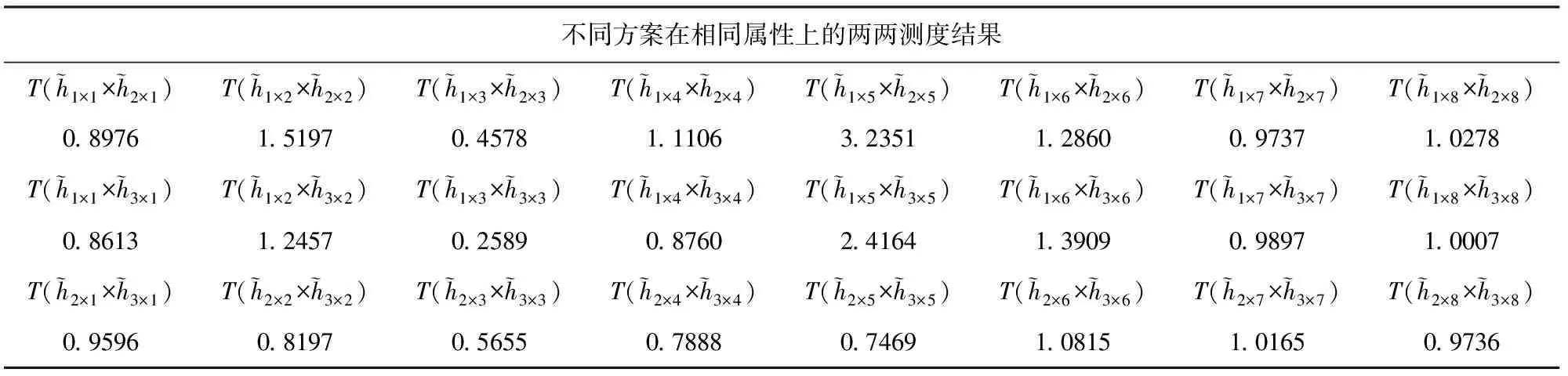

4.3 决策结果比较



5 结 语
猜你喜欢
数学物理学报(2022年5期)2022-10-09
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
校园英语·上旬(2020年1期)2020-05-09
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
卷宗(2017年16期)2017-08-30
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
