
基于GM(1,1)模型和ARIMA模型的大名县油料产量分析*
2021-11-04 08:27杨颖颖陶佩君崔永福
粮油与饲料科技 2021年5期
杨颖颖,陶佩君,崔永福
(河北农业大学,保定071000)
1 引言
油料是食用植物油的重要来源,是人们日常生活的必需品,同时也在国民经济和社会发展中占有重要地位[1]。河北省是我国油料作物主产省之一,常年播种面积在60万hm2左右[2]。油料作为河北省重要的支柱产业,具有广阔的发展前景,与全省人民的生活息息相关,也对农民增收,农业增效发挥着重要作用。大力发展油料产业不仅可以促进河北经济发展,对保障国家油料安全也具有重要意义。近20年,大名县在河北省县域单位中油料总产量一直位居首位,但由于多方面综合因素影响导致近些年大名县油料产量和面积均呈现下降的趋势,产业发展受到一定程度限制。
文章以大名县为研究区域,利用1994~2019年大名县每年的油料产量数据,运用SPSS26软件和Eviews10.0软件分别拟合了GM(1,1)模型和ARIMA模型,综合比较两种模型,从中选出最优模型,以保证预测模型的结果准确性更高、误差更小。并对未来三年大名县的油料产量进行预测,以期为有关部门制定合理的经济政策提供依据。
2 数据来源与研究方法
2.1 数据来源
研究中的大名县油料产量资料(见表1)来源于《河北农村统计年鉴(1995~2020)》和《邯郸市统计年鉴(1995~2020)》。
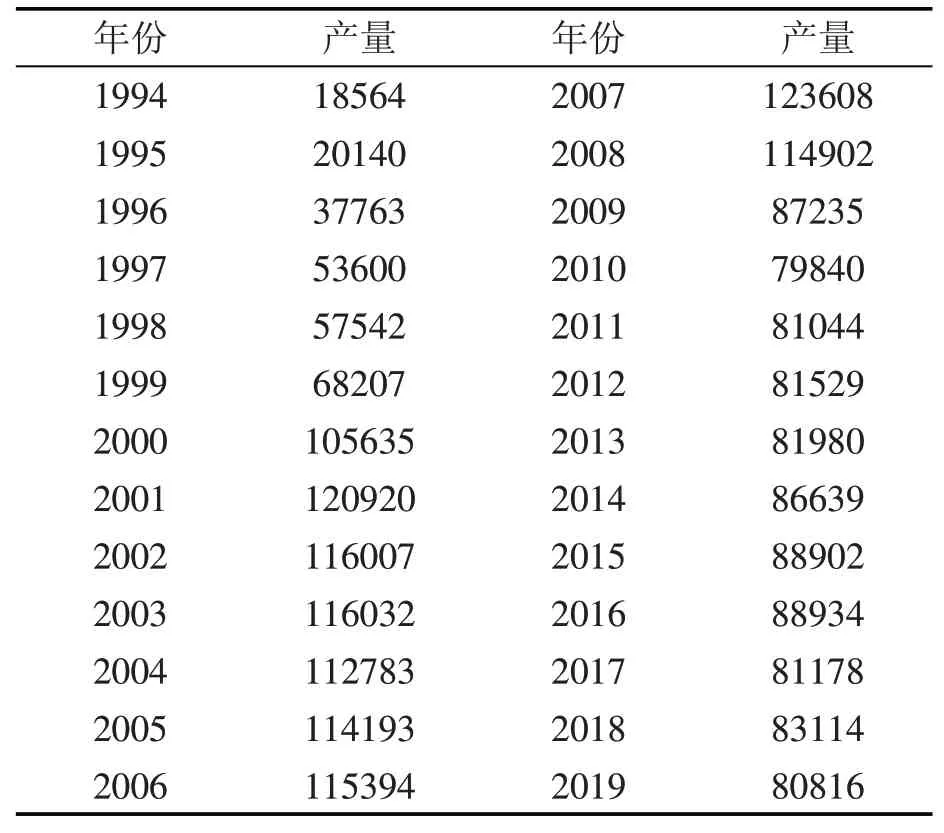
表1 1994~2019大名县油料产量 单位:t
2.2 GM(1,1)模型
GM(1,1)模型是一种常见的灰色模型,它是基于随机的原始时间序列,经按时间累加后所形成的新的时间序列,使新的序列呈现出一定的规律,通过建立一阶线性微分方程模型求得拟合曲线,进而对原始序列进行预测。该模型是在灰色系统理论中应用最为广泛的动态预测模型。
建模过程如下:
①假设产量原始序列:X(0)={X(0)(i),i=1,2,…,n}
②首先对X(0)进行一次累加
生成一次累加序列。
X(1)={X(1)(k),k=1,2,…,n}
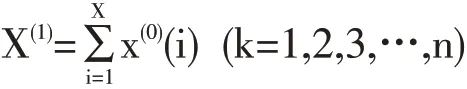
③则GM(1,1)模型相应的微分方程为

式中,a为系统发展系数,u为内生控制变量。
④求解微分方程,得预测模型公式为
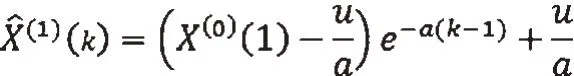
通过SPSS26软件采用编程方法进行GM(1,1)运算,带入原始序列X(0),没有通过级比检验,加入平移转换值494432,转换后的数据在标准范围区间[0.929,1.077]内,意味着本数据适合进行GM(1,1)模型构建。
⑤根据模型原理求得模型参数。
发展系数a=-0.0014,灰色作用量u=571230.5795,后验差比C值=0.7424>0.65,意味模型精度等级不合格;同时由表2 GM(1,1)模型预测情况可知,从1995年到2008年模型相对误差值超出0.2,模型拟合效果不佳,因此不做预测。
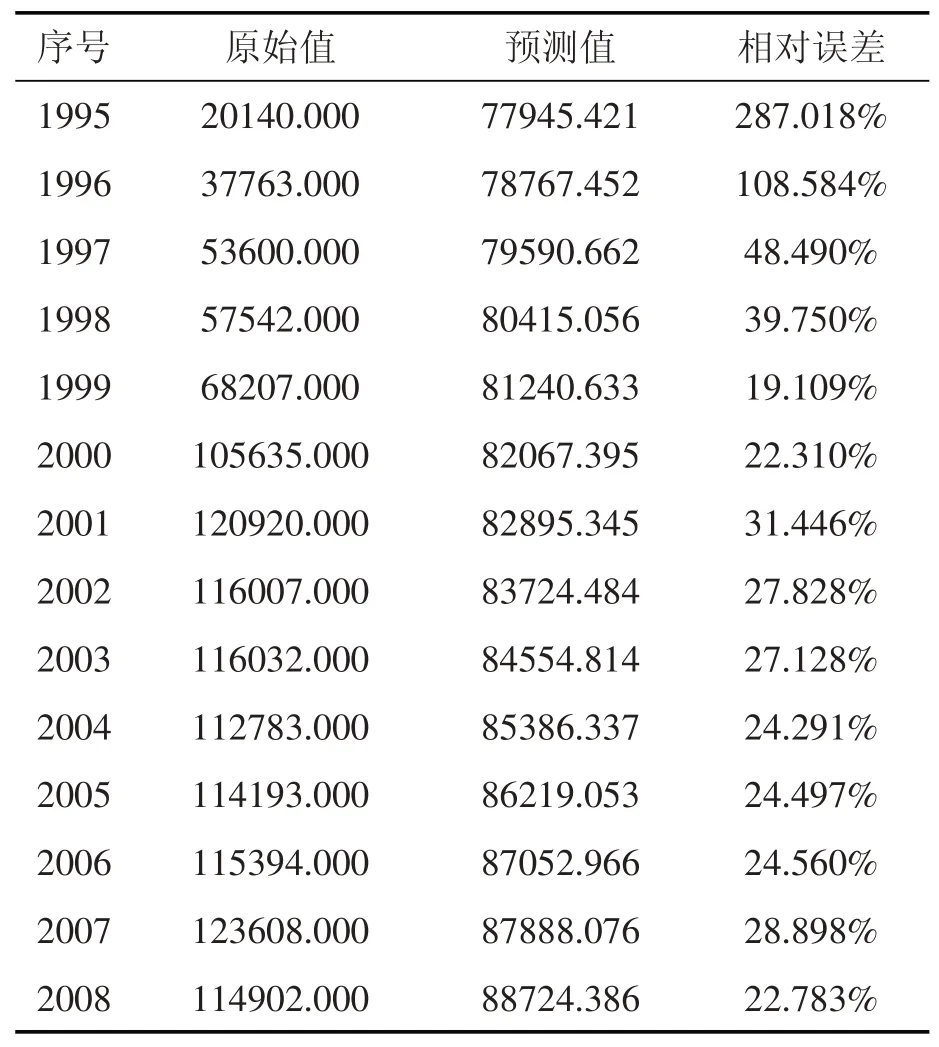
表2 GM(1,1)模型预测情况
2.3 ARIMA模型
ARIMA模型就是ARMA模型与差分运算的组合,差分运算具有强大的确定性信息提取能力,许多非平稳序列经过差分运算后会显示出平稳序列的特征[3],此时的序列即为差分自回归滑动平均模型ARIMA(p,d,q),其中AR代表“自回归”,p代表自回归项数;MA为“滑动平均”,q为滑动平均项数,d为所做的差分次数(阶数)。ARI⁃MA(p,d,q)模型是ARMA(p,q)模型的扩展。ARIMA(p,d,q)模型公式可以表示为:

2.3.1 ARIMA模型预测
ARIMA模型建模步骤流程见图1。
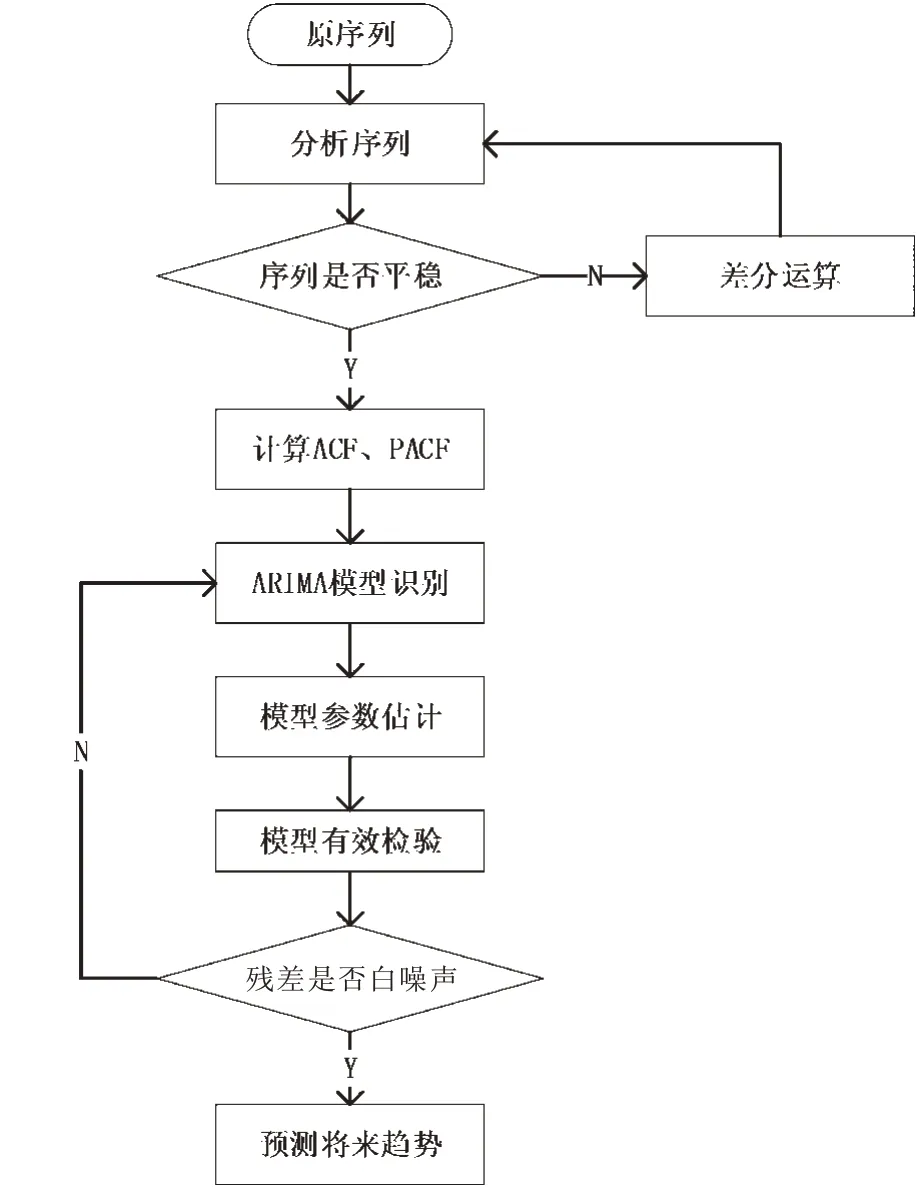
图1 ARIMA模型预测程序
2.3.2 平稳性检验与处理
ARIMA模型建立前需要检验序列的平稳性,只有平稳序列才能建立时间序列模型。1994-2019年大名县油料产量时序见图2。对该序列进行ADF检验显示该序列为不平稳序列,见图3。
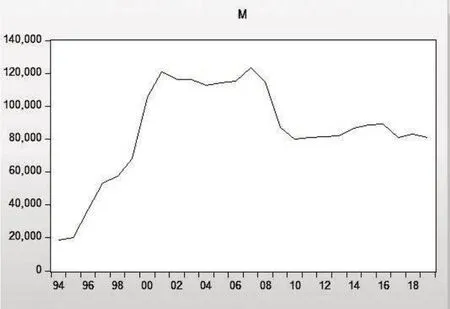
图2 大名县油料产量时间序列图

图3 大名县油料产量时间序列单位根检验
当对序列进行一阶差分时,t值小于各显著性水平(1%、5%和10%)的临界值,故拒绝原假设,接受不存在单位根的结论,认为序列平稳,可以用ARIMA模型预测,见图4、图5。
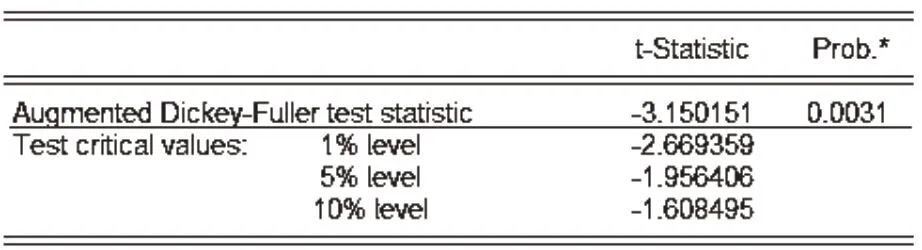
图4 一阶差分序列ADF检验
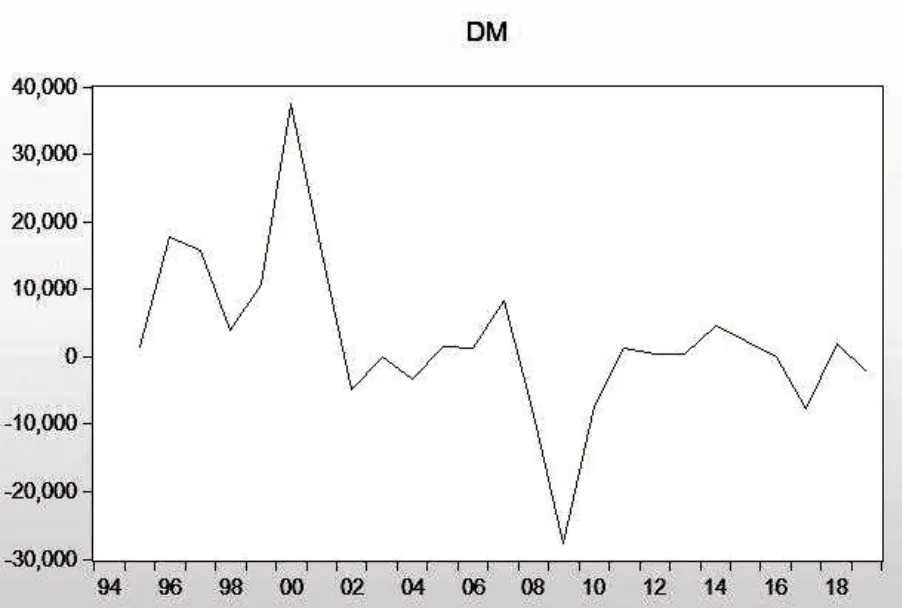
图5 大名县油料产量一阶差分时序
2.3.3 ARIMA模型的建立与优化
ARMA(p,q)模型的识别与定阶可以通过样本的自相关与偏自相关函数的观察获得。大名县油料产量的一阶差分序列DM的自相关-偏相关情况见图6。

图6 大名县油料产量的一阶差分序列DM的自相关-偏自相关情况
根据最大滞后阶数的法则确定p最大值为3,q的最大值为1。可建立的模型有以下三种组合ARMA(1,1)、ARMA(2,1)、ARMA(3,1)。通过观察参数计算结果,发现AR(2),AR(3)项的系数没有显著性,并通过AIC和SC准则,进行项数筛选。最终得到AR(1),MA(1)的系数具有显著性,见图7。
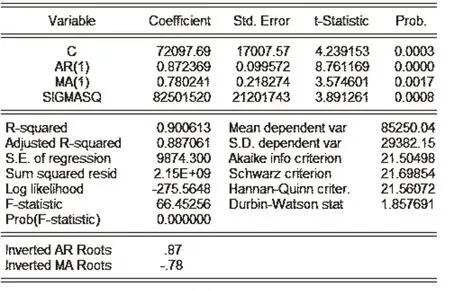
图7 ARIMA(1,1,1)模型参数估计结果
模型最终表达式如下:

所得模型的实际值(Actual)和拟合值(Fit⁃ted)以及残差值(Residual)的比较见图8,可以看出拟合值与实际值拟合效果良好。

图8 实际值、拟合值、残差值比较图
2.3.4 模型检验与预测
检验模型残差是否为白噪声序列,见图9。结果显示,检验统计量Q值均小于对应自由度卡方分布的检验值,且Prob列读出拒绝原假设的概率较大,均大于0.05,所以残差序列为白噪声序列,说明此模型拟合成功,可以用于拟合2020~2022大名县油料产量。
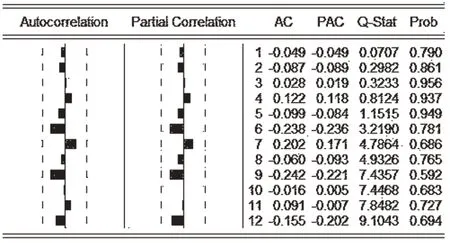
图9 ARIMA(1,1,1)残差序列自相关
2.4 GM模型与ARIMA模型评价
本文基于GM模型与ARIMA模型分别进行了大名县油料产量的预测,其两种预测结果见表3。
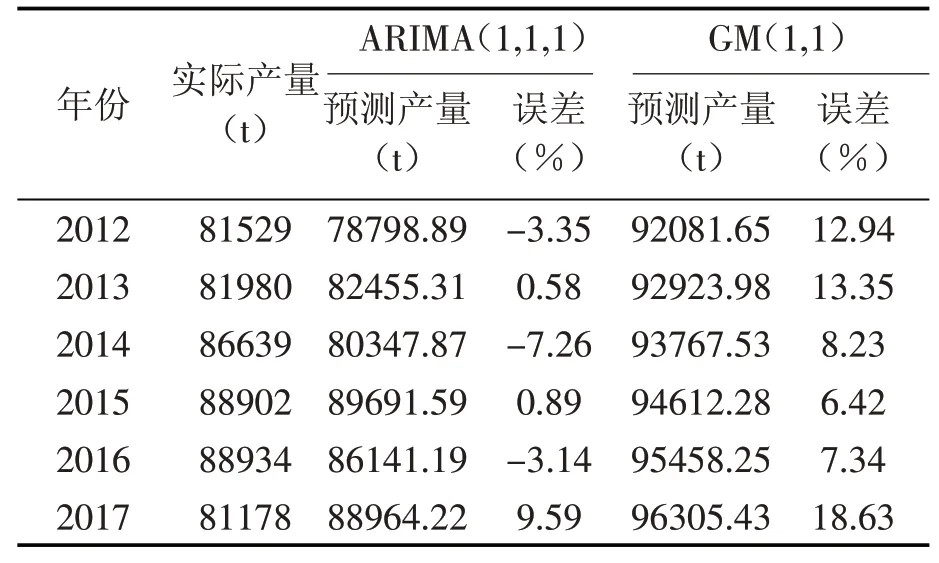
表3 两种模型预测2012~2017年大名县油料产量
采用误差率来比较模型预测效果,评价效果见表3。可见在大名县油料产量预测的过程中,ARIMA(1,1,1)模型的误差率明显低于GM(1,1)模型,表明其预测精度更高、拟合效果更好。
因此采用ARIMA(1,1,1)模型进行大名县2020至2022年油料产量的预测,结果见表4。
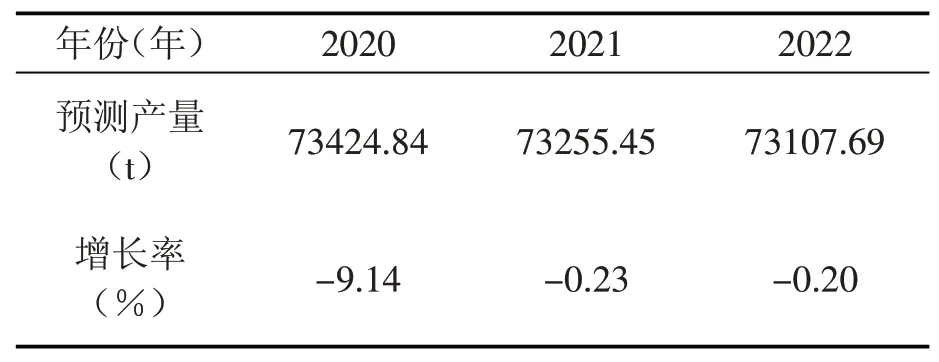
表4 大名县2020至2022年油料产量的预测结果
大名县油料产量未来三年模型预测结果为:2020年油料产量为73424.84 t,增长率为-9.14%;2021年产量为73255.45 t,增长率为-0.23%;2022年产量为73107.69 t,增长率为-0.20%。可以看出在未来几年大名县油料产量仍然呈现下降趋势,但趋于平缓。
3 结论
GM模型和ARIMA模型都是时间序列预测方法中的经典模型,在农业科学、医疗卫生、水利水电、经济管理等多个领域均被广泛应用[4-9]。文章针对大名县1994~2019年油料产量的序列特点,分别建立了GM(1,1)模型和ARIMA模型,通过相对误差、预测精度综合比较两种模型,结果表明ARIMA(1,1,1)模型比GM(1,1)模型精度更高,预测精度更为准确,可以得到较为理想的预测结果。
大名县油料产量预测数据显示未来几年仍然呈下降趋势,针对这一现象文章基于调研和对文献的梳理,发现以下原因可能影响大名县油料产量变化。
首先,我国油料对外依存度过高。在全球经济一体化的推动下,我国油料产业同国际竞争日益激烈,对国外廉价油料的大量进口,严重制约了国内市场,国内油料的供需产生了变化,对我国油料生产造成严重冲击,这也直接导致国内油料产量的下滑。
其次,农民种植油料作物的积极性不高。一方面油料作物的种植规模小,机械化水平低,致使劳动力成本高,另一方面农药化肥等生产资料价格的上涨,除此还有国家的粮油政策对小麦、玉米等粮食作物补贴力度的偏向,多方面综合原因造成油料作物经济效益比粮食作物效益低,进一步影响了农民种植油料作物的积极性。
最后,是由于油料加工技术和设备较为落后。油料作物加工企业多以初加工为主,压榨技术多采用手工压榨技术,同时加工企业规模小,包装水平低,产品单一且附加值低,各经营主体没有形成紧密的合作关系,没有形成科学的油料产业链,严重制约了当地油料产业的健康发展。
作为河北省县域油料产量的第一名,大名县油料产业发展面临较大的压力,建议大名县政府结合国家政策加快油料生产基地的建设,提高基础设施条件,全面提升大名县油料综合生产能力;结合当地社会资源环境和区位条件,合理配置资源,加快推动产供销一体化,积极引导油料产业化经营,推进农民经济组织建设,努力提高油料生产组织化程度;通过引入新品种新技术,加深农业科技入户,提高油料生产机械化水平,改善油料生产劳动强度大、费工费时等问题。
猜你喜欢
数学杂志(2022年5期)2022-12-02
湘潭大学自然科学学报(2022年2期)2022-07-28
中原商报·科教研究(2022年1期)2022-05-13
魅力中国(2021年24期)2021-11-26
军事运筹与系统工程(2020年2期)2020-11-16
指挥控制与仿真(2019年1期)2019-03-01
计算机应用(2016年10期)2017-05-12
农家顾问(2016年12期)2017-01-06
山东工业技术(2016年15期)2016-12-01
试题与研究·中考化学(2016年1期)2016-09-30
