
学术资源挖掘方法研究综述
2021-12-21 11:01王颖
现代情报 2021年12期
王颖

DOI.10.3969/j.issn.1008-0821.2021.12.016
[中图分类号]G250.76 [文献标识码]A [文章编号]1008-0821(2021)12-0164-14
科学技术突飞猛进促进了学术交流与合作,也产生了海量的学术资源,如期刊论文、学位论文、会议论文、科技报告、图书专著、专利、标准等正式出版物,以及学术网站、学术社交媒体、科教文化信息、科学数据等网络资源。面向海量学术资源,科研人员一直致力于对不同的学术资源进行挖掘、集成和利用,结合数据挖掘、文本挖掘、机器学习等技术提出了众多挖掘方法与算法模型,并开发了一系列实用工具,不断优化学术资源利用环境,满足用户日益增长的知识服务需求。在此背景下,本文拟对国内外学术资源挖掘方法研究现状进行总结和分析,以期为学术资源挖掘方法的进一步优化提供相应的支撑和参考。
本文的研究对象主体为学术资源,往往容易与科技文献、学术论文等概念混淆。国家标准GB7713-87中定义学术论文是某一学术课题在实验性、理论性或观测性上具有新的科学研究成果或创新见解和知识的科学记录:或是某种已知原理应用于实际中取得新进展的科学总结。邱均平教授认为,“凡是将人类的知识用文字、图形、符号、声频、视频的手段记录于一定载体之上所形成的东西统称为文献,科技文献是一类含有科学技术知识内容的文献,按出版形式分为图书、期刊、会议录、科技报告、学位论文、专利文献、技术标准、产品样本等”。苏新宁教授认为,“学术资源是指能够帮助支持开展学术研究活动的所有资料,除正式出版物,还应包括对科学研究有帮助的政府信息、社会信息、科教文化信息、科学数据等”。从覆盖范围对比,科技文献包括学术论文,而学术资源包括科技文献。从作用上对比,学术论文既是一种探讨学术问题的手段,又是一种学术交流工具,科学文献主要用来记录、积累、传播和继承知识,而学术资源的来源更加广泛、信息量更强、传播范围也更广,是学术研究长期开发、共享和利用的基础资源。从形式上对比,学术论文和科技文献多为正式出版物,而学术资源涉及非正式出版的内部出版物、实验报告、教案、学术动态以及学术网站、学科专业论坛、学者博客等网络信息资源。
学术资源挖掘涉及图书情报学、计算机科学、生物医学等不同领域的研究,如文献挖掘、文献计量、非相关文献知识发现(LBD)、数据挖掘、文本挖掘、机器学习等,这些研究之间存在交叉和融合,并且相互促进共同发展。文献挖掘、文献计量、LBD都是以科学文献为数据集的研究。文献挖掘旨在从科技文献中挖掘有价值的知识:文献计量利用数学和统计学的方法对文献进行定量分析:LBD从非相关文献中识别出潜在关联促进新知识的产生。而学术资源挖掘以科技文献和其他非正式学术资源为研究对象,研究范围更广。数据挖掘、文本挖掘、机器学习是计算机科学领域的重要分支,数据挖掘的研究对象可以是各种类型的数据源,文本挖掘的主要对象是文本数据,也包括学术资源的文本。学术资源挖掘通常采用数据挖掘技术进行关键词统计、主题分析、引用分析、关联挖掘等,利用文本挖掘技术对学术文本进行知识抽取、文本聚类和分类,并借助机器学习技术优化研究方法提升性能。
1学术资源挖掘研究主题分析
由于学术资源涉及类型较多、研究方法较广,分别以“学术资源”“文献”“论文”“图书”“专利”“报告”“工具书”“标准”“学术社交媒体”“教育资源”等为研究对象主题,“挖掘”“抽取”“识别”“分类”“聚类”等为研究方法主体构建检索式,从中国知网、万方、ScienceDirect、ACMDigital Library、IEEE Xplorer Digital IJibrary、Springer Link等数据库中检索相关中英文论文,通过泛读,从中筛选获得与本研究主题相关的论文,并在此基础上对相关引文、相关主题进行扩展检索,最终获得研究问题相关论文集合,以此为基础对学术资源挖掘方法进行总结和归纳。
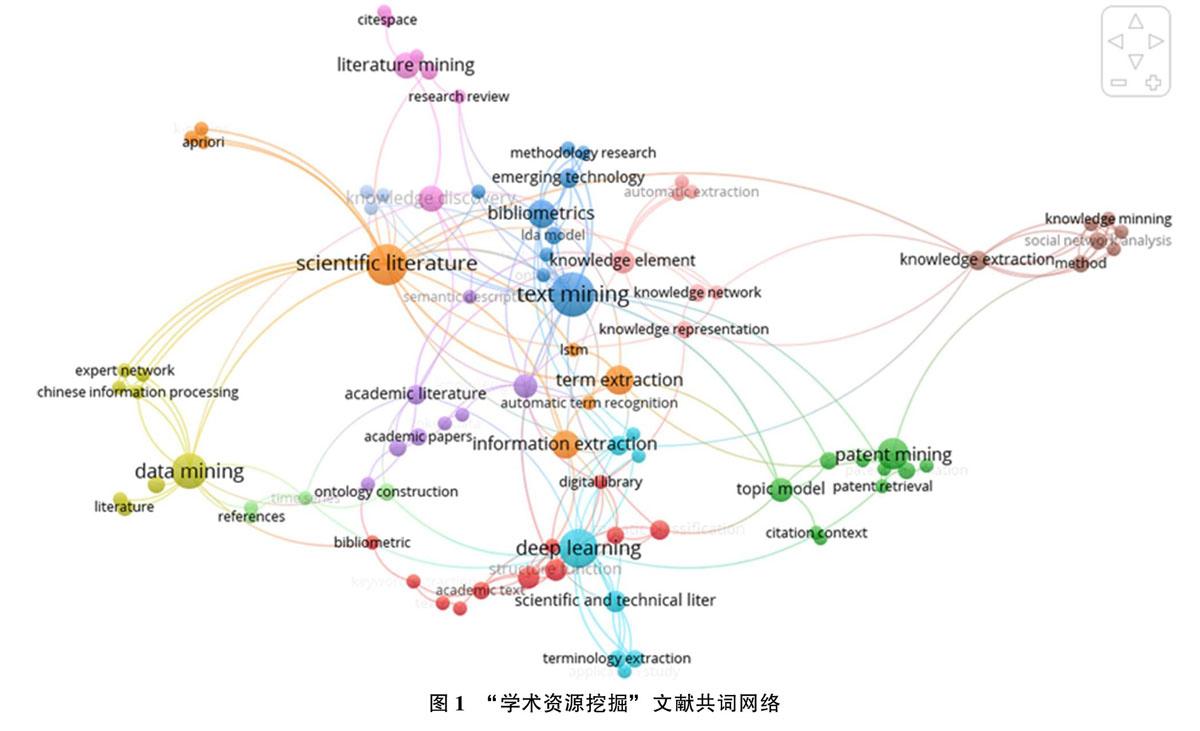
通过去重和去除不相关论文,共获得137篇英文论文和256篇中文论文。对没有关键词的英文或中文论文,利用TextRank算法从标题和摘要中抽取关键词,并采用百度翻译工具对没有对照英文关键词的中文论文进行翻译,最后借助VOSviewer工具对论文关键词进行分析,构建了如图1所示的文献共词网络。从图中可知,学术资源挖掘涉及科技文献(scientific literature)、文本挖掘(text mining)、信息抽取(inforrnalion extraction)、术语抽取(term extraetion)、深度学习(deep leaming)、专利挖掘(patent mining)、数据挖掘(data mining)、知识抽取(knowledge extmction)等热点研究主题。
2学术资源挖掘方法分类分析
在对学术资源挖掘研究主题分析的基础上,本文从研究对象、研究维度、采用技术等角度进一步分类分析。
2.1按研究对象分析
学术资源包括学术论文、图书、报刊、专利文献、科技报告、标准、工具书等正式出版物,也涉及学术网站、学术社交媒体、开放学术知识库、教学课件等非正式出版物或网络资源,针对不同研究对象的挖掘方法有所不同。
2.1.1学术论文挖掘
學术论文挖掘研究工作开展已久,特别是在生物医学领域,一些挖掘方法和实用工具已用于挖掘学术论文的内在知识,如PubTator工具识别PubMed文献中生物医学实体,如基因、化学物质、疾病、变异、物种等。SemRep工具使用UMLS语义网络判断论文中两个生物医学概念之间的关系。CoPub5.0系统从文献中挖掘研究疾病背后的机理、连接基因和Pathway,发现现有药物的新型应用等。此外,还有一些研究利用文本挖掘技术从学术论文中识别生物分子事件、药物之间的相互作用(DDI)、蛋白质的相互作用(PPI)、Protein-residue关联、基因关系、基因功能或GeneRIFs、基因事件提取等。通过从生物医学文献和临床记录中挖掘信息来辅助数据库管理、构建本体、促进语义Web搜索和帮助开发交互式系统(例如计算机辅助管理工具)。
2.1.2专利文献挖掘
专利文献是一种非常重要的学术资源,是技术信息最有效的载体。專利挖掘通过分析专利文献,寻找技术创新的特征,识别核心技术并对现有技术进行改进,研究方法涉及专利术语抽取、专利聚类、专利分类、专利统计分析、技术预测等。如Fenn J等对专利信息进行多维度挖掘,搭建专利知识空间。孙宁宁使用LDA主题模型对专利非结构化的文本信息进行分析,发现潜藏的技术主题。洪勇等基于专利引用关系研究不同企业之间的技术相关性。刘小玲等基于引文分析方法和文本挖掘,创建用于聚类分析的C-T专利网络,研究技术演化过程。谢凯基于IPC分类号形成技术关联网络,分析不同技术之间的关联范围和关联程度。林弘杰设计了一种基于深度学习的专利价值评估模型DLPQV,充分利用专利信息来预测评估专利的价值。此外,一些学者提出基于SAO(Subiect-Action-Object)结构的专利挖掘方法用于技术路线分析、R&D合作伙伴识别、技术机会分析、技术形态识别、技术演化等。
2.1.3工具书挖掘
工具书包括辞书、类书、政书、百科全书、年鉴、手册、书目、索引、文摘、表谱、图录、地图、名录等,由数位领域专家经过多年集体创造,具有权威性、完整性、规范性和一致性。一些学者通过挖掘工具书构建知识库,提高工具书内部知识的可用性,如二十四史语义知识库、国史知识库,通过应用自然语言处理、语义推理技术,发掘工具书中的潜在知识,构建语义分析平台,为用户提供了具有语义的知识服务。除传统工具书外,在线开放百科也成为重要的知识资源,如林泽斐等从百度百科中抽取人物社会关系网络。开放关联数据云(LOD)的核心DBpedia即是从维基百科中抽取的实体、属性和关系,Google推出的Knowdedge Graph也从维基百科中抽取数据并进行人工协同编辑,此外还有YAGO、百度知识图谱、搜狗知立方、CN-DBpedia等以通用百科为基础利用知识提取技术构建的大规模知识库,已被广泛应用于智能搜索、智能问答、个性化推荐、内容分发等领域。
2.1.4学术社交媒体挖掘
学术社交媒体如学术博客、学术论坛等也作为学术资源的一部分受到学者的关注,例如张洋等在检索传统网络数据库的基础上,采集新浪图林和CNKI学术论文等学术社交媒体,绘制图书情报领域多源学术信息聚合的科学知识图谱。王磊对学术型社交媒体中关于期刊评价的非结构化文本信息进行挖掘,通过统计与计量学分析进行期刊影响力评价模型的研究。谭曼等以网络分析为定量方法,以科学网博客作为实证样本,探索共推荐关系在学术博客中具有的实证特性。汤刚强以网络学术社区“科学网”为研究对象,利用社会网络分析工具从整体网络、内部子结构和个体中心度3个角度分析科学网博客频道的规律。黄丽丽从虚拟健康社区的自由文本数据中抽取医学术语和健康词汇,进行药物不良反应事件探测。
2.1.5教育资源挖掘
近年来,一些研究人员开始对教学课件、教学文件等教育文本进行挖掘,发现教学知识点,构建知识体系,辅助学习与教育。例如,清华大学与学堂在线研发的“小木”机器人从课程体系结构里面抽取知识概念及相互关系,构建了庞大的知识图谱体系,提供答疑、导航、推荐、提问、社交等服务。Lee H等使用狄利克雷多项式回归主题模型,分析多个高校机器学习相关课程的教学材料,用以发现其主要教学主题的变化趋势,总结教学内容的热点和重点。Langan G等通过N-Gram关键词抽取的方式分析了多所大学的计算机科学学位课程大纲,为学习者的课程选择以及教育部门对课程学分的认证提供了参考。盛嘉祺以书本教材抽取实体为主干,慕课和博客数据为补充,构建课程知识图谱,在课程设置优化、教育资源智能搜索和个性化推荐等方面进行应用。
2.1.6综合挖掘
目前,学术资源在广度和深度上都呈现快速增长趋势,对海量多源异构学术资源进行综合挖掘有着重要的学术价值。王效岳等从高校网站、学科门户、OA仓储中抓取公开发布的网络学术文献,利用本体集成发现进行异构数据处理,并实现了基于语义驱动的自动分类,解决海量网络信息资源语义分类、语义导航与语义检索等问题。谢前前以论文、专利、新闻、社交媒体数据为来源,构建知识一技术一环境的三维分析模型,研究新兴技术的演化轨迹及趋势预测。Shi Y等以计算机期刊和会议书目数据库DBLP、职业社交网络Linke-dIn为实验数据,联合维基百科发现富文本异构信息网络中上下位关系。曹树金等以图书情报领域开放获取期刊论文、在线百科、博客等网络信息资源为数据源,构建描述聚合单元访问信息、物理信息和语义信息的元数据框架,支持多类型网络信息资源、各层级细粒度聚合单元的检索。
从面向不同研究对象的学术资源挖掘研究可以发现,针对学术论文和专利文献的挖掘技术和方法相对成熟,其他类型的研究相对较少,而开展综合挖掘的研究也多以学术资源的关联和聚合为主。此外,由于各类学术资源作为知识载体的作用不同,开展挖掘的目的也有所不同,如学术论文挖掘主要识别科学知识,专利文献挖掘主要探测技术创新,工具书挖掘偏重于专业知识或常识知识的结构化,学术社交媒体挖掘往往用于社会网络评价,而教育资源挖掘主要用于资源推荐。
2.2按研究维度分析
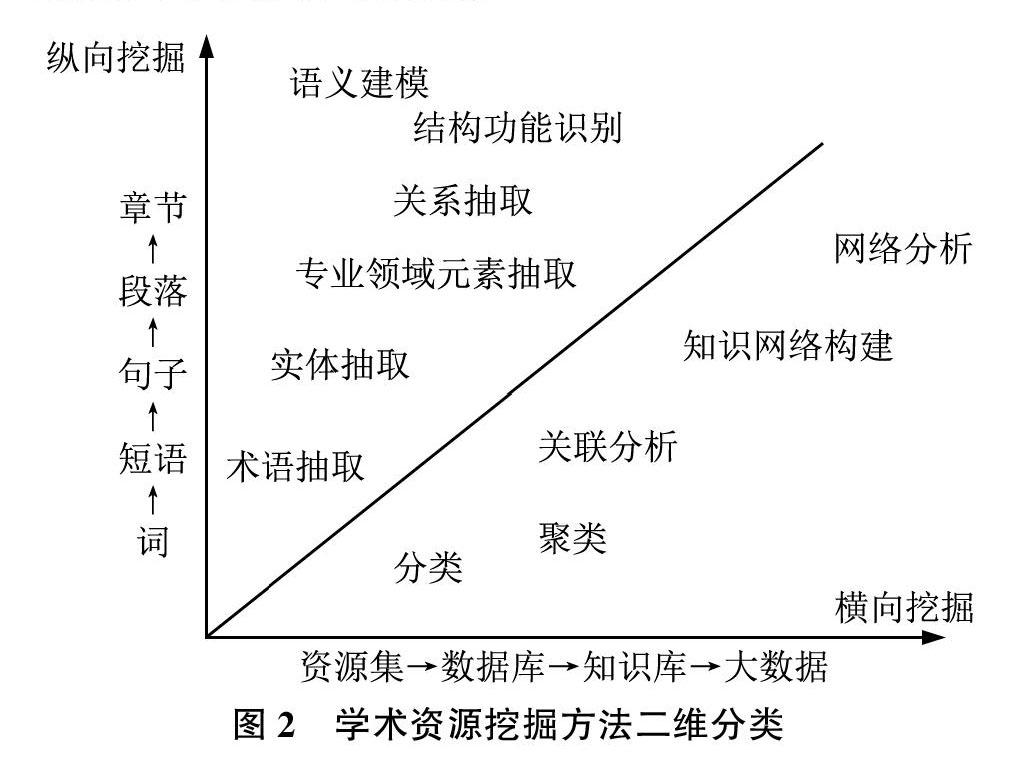
在系统调研学术资源挖掘方法的基础上,本文将这些研究方法划分为纵向挖掘和横向挖掘两个维度,如图2所示。纵向挖掘指对单个学术资源进行纵深方向的挖掘,将学术资源内部各粒度(例如词、短语、句子、段落、章节)的元素进行揭示和语义丰富化,涉及术语/实体抽取、专业领域元素抽取、关系抽取、结构功能识别、语义建模等研究:而横向挖掘是指对学术资源集(例如资源集合、数据库、知识库、学术大数据等)进行横向挖掘与分析,涉及分类、聚类、关联分析、知识网络构建、网络分析等研究。
纵向挖掘
2.2.1纵向挖掘
纵向挖掘针对单个学术资源全文数据,利用自然语言处理、文本挖掘、语义网等技术,从词、短语、句子、段落、章節不同粒度进行知识抽取和语义表示,使得隐藏在学术资源文本内部的知识被清晰地表示,将其转换为结构化知识,供人类理解和机器处理。
1)术语/实体抽取
术语抽取和实体抽取是学术资源挖掘的基础任务,常用的抽取方法包括基于规则的方法、基于统计的方法、基于传统机器学习的方法以及基于深度学习的方法等。如温雯等基于启发式规则与标签传播算法提出了一种面向专业文献知识实体的类型抽取和标注方法,相比传统基于特征的CRF方法效果要好。沈思等利用标签主题模型labeled-LDA对文献中隐含的时间信息进行分析和挖掘。方俊伟等提出一种基于先验知识TextRank的学术文本关键词抽取方法。赵东玥等采用了双向长短时记忆神经网络模型(BLSTM)进行术语抽取。Kaewphan S等构建CNN-BiLSTM-CRF模型从文献中识别分子、细胞和组织等生物医学实体。Zhao Z H等提出了一种多标签卷积神经网络模型用于文献的疾病实体识别,在NCBI和CDR数据集上都取得了很好的效果。
2)专业领域元素识别
随着纵向挖掘的不断深入,从学术文本中抽取常用的领域术语或通用实体已经不能满足专业用户信息获取的需求,一些学者利用机器学习技术开始识别具体专业领域的特定元素。例如赵丹宁等从内容、语法、语义分析等方面,利用规则从药物代谢动力学文献摘要中抽取实验数据如实验、药物、给药方式、药物代谢力学参数等。Pang N等提出一种基于BERT-CRF模型的化学实体和关系抽取方法,从科技文献中抽取化合物、溶液、方法、反应、化学键、PKA、PKA-VALUE 7种类型实体以及化学键能数据链。马建霞等基于Bi-LSTM+CRF神经网络模型抽取中文文献中时间、地名和生态治理技术。Gupta S等构建信息抽取规则识别论文中的方法或工具,化柏林研究了学术论文中方法知识元的类型和描述规则,钱力等基于多规则模式混合机器学习方法抽取学术论文的研究方法、工具等。余丽等基于LSTM-CRF模型从计算机领域会议论文摘要中抽取研究范畴、研究方法、实验数据、评价指标及取值等知识元。
3)关系抽取
面向学术资源的关系抽取随着信息抽取技术的发展不断进步,从早期基于规则、词典、本体的抽取方法,到基于传统机器学习、基于深度学习的方法以及面向开放领域的关系抽取方法,从学术文本中挖掘用户所需的语义关系信息,并构建知识图谱或知识库以及潜在关联发现。例如,李智恒等提出了一个化学物质致病关系抽取系统,利用半监督的Co-Training算法将特征核和图结构特征集合进行句子分类器续联,并利用文档级别分类器抽取化学物质致病关系。蒋婷等利用基于互信息的概念对抽取、基于C-value的关系动词抽取和关系确定3个阶段从学术文献中抽取概念之间的非等级关系。李鲲等将文献资源抽象为一系列独立成果而又互相关联的科研事件,并提出基于触发词的事件抽取方法。Peng Y等提出了将句子向量、位置向量、词干特征、句子的依存特征作为支持向量机(SVM)、卷积神经网络(CNN)以及循环神经网络(RNN)模型的输入,将3种模型结果进行投票,获得生物医学文献中化学品和蛋白质之间关系的最终预测。
4)结构功能识别
结构功能识别是指识别学术文本中一个从句、句子、段落、片段的功能性作用如“背景”“方法”“结果”等,也有学者从语言学角度将其称为科技文献的语步结构(Move Structure或Argumentative Zone)或者语篇元素。学术文本结构功能识别的研究主要从句子、段落和章节3个层次展开。早期的句子级功能识别模型有AZ/AZ-Ⅱ模型、CoreSC模型、Dr.Inventor框架等,主要采用朴素贝叶斯分类器、支持向量机、随机向量场、线性核分类器等进行自动标注。近期研究人员开始利用BERT模型训练分类模型。在段落级功能识别上,Ribaupierre H等提出了SciAnnoDoc标注模型,通过人工制定正则表达特征的方法对人文性别研究领域文献进行自动分类识别。Varga A等基于论证区域的思想提出了zoneLDA模型用于篇章结构识别。王倩等引入神经网络模型进行段落功能识别。在章节功能识别上,陆伟等、黄永等分别从章节标题、基于章节内容、基于段落3个不同层次开展学术文本的结构功能识别。在后续研究中引入深度学习技术,并采用投票方法进行多层次融合。
5)语义建模
为使人和机器都可以访问学术资源内部知识,研究人员应用本体和关联数据对学术资源进行语义表示和描述。例如,很多图书馆和研究机构以关联数据形式发布书目数据和规范数据,如瑞典联合目录(LIBRIS)、OCLC发布的VIAF(虚拟国际规范文档)、WorldCat书目数据、英国国家书目4等,即将数据开放,便于共享和重用,又可以揭示数据之间的关联,通过资源的关联整合促进语义检索和智能检索的实现。新兴的语义出版旨在发掘并丰富文章知识内涵,使其更容易被自动发现并与之关联。众多知名出版机构如PLos One、ACS、Nature、Elsevier等纷纷提出语义出版功能模块。概念网络联盟提出纳米出版(Nanopublication)作为科学文献语义出版的新模式,从文献中抽取科学结论、科学事实,建立语义表示模式,帮助人们进行科学情报和知识的发现、理解、交流、集成及共享。W3C发布了ORB科学篇章修辞块本体,用于捕捉科学出版物的粗粒度修辞结构。SPAR语义出版和引用本体[跎]提出了一套OWL DL本体模块用于创建语义出版和引用各方面机器可读的RDF元数据。
从纵向挖掘角度可以发现挖掘的粒度逐渐细化,一个学术资源可被分解为粗细粒度不同的功能结构并进行语义化转换,这为进一步的知识计算和分析奠定了基础。此外,随着深度学习技术的不断突破,知识抽取的对象也从通用实体、生物医学领域扩展到其他复杂的专业领域元素,有效地推动了学术资源的开发与利用。
2.2.2横向挖掘
横向挖掘从宏观层面对学术资源集合进行整体分析和计算,包括学术资源分类、聚类、关联挖掘、统计分析、知识网络构建、网络分析等研究。
1)分类
学术资源的分类标引对于资源的检索、过滤、推荐等都具有重要的意义,也是数字图书馆建设中的关键问题之一,通常根据学术资源的文本主题、内容或属性进行预处理、特征表示、特征选择并利用机器学习算法构建分类器进行自动分类。例如史盛楠提出了相关主题模型(CTM)与KNN分类算法结合的C-KNN分类方法,实现多学科文献分类。郭利敏构建了基于题名、关键词的多层次卷积神经网络模型,自动给出文献的中图分类号,用以解决编目人员紧缺、加工质量和效率下降等问题。宫小翠等提出了基于Labeled LDA主题模型的医学文献自动分类法。谢剑芳等提出了基于FastText的专利文本自动分类方法,温超东等提出了结合ALBERT和双向门控循环单元的专利文本分类,李湘东等将已知类别的期刊论文题录信息和新闻网页混合起来构建共通语义空间,通过共现关系绘制双向图并实施谱聚类进行跨文献类型文本自动分类。
2)聚类
聚类分析是对学术资源集合进行整体分析的主要手段之一,将学术资源集合分为相对同质的簇进行统计分析,聚类方法常使用内容分析方法,如利用词频、共现、共词、共引、同被引等关系进行发现相似关系,并利用聚类算法和工具进行聚类。例如Sun Y等、刘勘等分别提出基于排名的聚类算法RankClus、改进TF IDF特征词加权算法用以实现科技文献聚类,从中发现热点研究领域,识别学科融合方向。赵楠等针对学术会议信息资源,提出了一种基于密度的聚类算法,利用资源关键字实现了资源热点的自动发现。Yun J等利用共引和同被引关系构建文献二分网络,依赖网络结构信息进行文献聚类。马力等对失效专利、失效/有效专利、有效专利进行聚类分析,根据专利流走向来判断技术主题的新生、消亡及发展状况。赵夷平等采用潜在语义分析方法计算如科学网、统计之都、小木虫等学术资源网发布文献的总体相似度,通过层级聚类方法生成文档关系矩阵,以此发现相似文献。
3)关联分析
关联分析是一种简单实用的分析技术,主要从数据集中发现不同项之间潜在的关联性或相关性。学术资源之间的关联分析通常采取数据挖掘或文本挖掘技术发现资源内部知识或资源之间的关联或模式。例如,资源内部实体关联分析的研究有:范馨月等利用文本挖掘方法从PubMed文献集构建药物一副作用共现矩阵,采用重复二分法进行聚类分析,发现潜在的药物副作用关系。魏星等提出一种基于数据立方的方法,挖掘疾病—基因—药物之间的关联,使用关联规则量化实体关联程度。贾丽燕等利用关联规则分析中文医学文献,发现药治疗糖尿病视网膜病变常用药物的用药特点和组方规律。李娇以图书为研究对象,通过共现分析提取人名节点,并利用Apriori算法发现人物之间的关联规则。资源之间的关联分析研究如:李海林等199]运用关联规则方法,从参考文献作者相关性分析、主题分析和来源期刊相关性分析3个方面,总结和提炼规则及知识反映的决策和建议。宁子晨等从专利主体—关键词耦合、IPC耦合以及IPC-关键词共现3个角度,提出关联方法探究数据挖掘领域内专利文献与学术论文的主体、主题关联关系。
4)知识网络构建
针对海量学术资源,一些大型出版商和研究机构已开始构建用于支持语义搜索、智能问答、数据挖掘、推荐系统等应用的大规模知识网络或知识图谱,如Springer Nature的SciGraph不断地从期刊/文章、书籍/章节、组织、机构、资助者、研究资助、专利、临床试验、会议系列、事件、引用网络、Altmetrics、研究数据集等方面扩展数据,其目标是创建学术领域最先进的关联数据聚合平台,为整个企业和研究领域提供可重用的知识。Elsevier基于其丰富的数据和内容资源如论文、圖书、引文、作者、机构、基金、化学物质、药物、EHRs等构建了面向研究、生命科学和医疗健康的知识图谱。Taylor & Francis开发了知识图谱工具Wizdom.ai,其知识图谱涵盖出版物、专利、作者、机构、概念、事实等。国内方面,清华大学AMiner学术知识图谱、上海交通大学Acemap知识图谱,利用信息抽取方法从海量文献及互联网中获取研究信息,提供搜索、学术评估、合作者推荐、审稿人推荐、话题趋势分析等多样化服务。
5)网络分析
学术资源之间可根据实体之间的关联如关键词共现、主题关联、引文关联、机构关联、作者关联等构建网络,并基于网络进行学术资源整体分析。引文分析是学术资源网络分析的典型分析方法之一,例如王灿友等对文献引文网络采用主路径分析方法揭示3D打印技术的演化路径。Choi J等采用关键词共现网络分析其演化轨迹,揭示韩国教育技术的未来发展趋势及模式。此外,有学者利用知识图谱进行专利情报分析,如张兆锋构建专利知识图谱,利用知识图谱扩展了技术功效图矩阵结构生成的模式类型,提升了专利情报分析效率。也有从学术资源纵向挖掘角度建立网络并进一步发现核心知识点或隐含知识的研究,例如王凯等将学术文献正文表示成一个以句子为节点、句子间关联为边的文本关系网络,利用社会网络分析方法挖掘文本中核心句子。曲佳彬等利用文本挖掘技术从论文元数据和摘要揭示作者机构地理位置、论文研究地域、作者研究主题和学科研究主题等,并构建关联数据,从多维度对学术论文关联数据中隐含的宏观和微观知识进行可视化展示。
从横向挖掘角度可以发现,对于学术资源集合的挖掘分析从分类、聚类、关联分析逐渐聚焦到网络的构建与分析上,利用网络结构进行整体或局部的挖掘与计算,而挖掘方法从传统的统计分析逐步引入图计算、社会网络分析、知识图谱、深度学习等热门技术。从数据处理规模上看,横向挖掘研究逐渐从较小规模数据向大数据方向演化,这也成为目前重要的研究方向之一。
2.3按采用技术分析
针对不用应用需求和研究对象,学术资源挖掘采用的技术也有所不同,本文将其总结归纳为五大类:基于规则/外部知识的方法、基于文本表示/词嵌入的方法、基于传统机器学习的方法、基于深度学习的方法以及基于网络结构的方法,具体如表1所示。
基于规则/外部知识的方法是早期学术资源挖掘任务的普遍方法。基于规则的方法一般通过人工构造规则或模式,将待处理数据与规则进行匹配判断,符合即完成实体或关系抽取任务,如文献等。基于词典的方法利用字符串匹配识别术语或实体,基于本体的方法通过本体层级结构或描述概念之间语义关系来辅助术语/实体抽取、关系抽取、关联分析和网络分析,而语义建模和知识网络构建通常采用本体描述和定义Schema。基于规则/外部知识的方法简单易用、可行性强,但往往耗费人力,并且受限于知识的描述范围。
文本是学术资源基本的表现形式,利用基于文本表示/词嵌入的方法对学术文本进行数学建模和向量表示,进而执行挖掘任务,是一种常用的研究方法。例如TF-IDF、N-gram模型、LDA等文本表示和计算模型可用于关键词抽取、主题识别和分析。而词嵌入模型将每个词映射为低维空间向量,传统模型如布尔模型、向量空间模型(VSM)往往欠缺语义表征能力,因而研究人员提出了Word2Vec、Glove等分布式表示技术,特别是Google发布的BERT预训练语言表示模型取得了突破性进展,在实体抽取、关系抽取、结构功能识别、分类、聚类等任务中均得以应用。
基于传统机器学习的方法以机器学习模型为基础,采用相对简单的方法就可以获得较好的研究效果,在各项挖掘任务中均有所应用。其中,支持向量机(SVM)是一种常用的监督学习算法,因其良好的分类性能得到了广泛使用。K近邻算法(KNN)简单有效,常用于学术资源分类任务。贝叶斯网络是目前不确定知识表达和推理领域最有效的理论模型之一,适用于表达和分析不确定性和概率性的事件,在结构功能识别、分类、聚类等任务中均有应用。条件随机场(CRF)结合了最大熵模型和隐马尔可夫模型的特点,在分词、词性标注、命名实体识别等序列标注任务中取得了很好的效果。
基于深度学习的方法相比传统机器学习方法通过训练大量数据自动获得模型,不需要人工提取特征,近年来在各项任务上均有所突破,受到了研究人员的广泛关注。例如卷积神经网络(CNN)利用多样性卷积核识别目标的结构特征,常用于提取词和句子层次特征,而循环神经网络(RNN)适用于序列数据的处理,能充分考虑长距离词之间的依赖性,可用于句法解析获得句法结构。长短期记忆网络(LSTM)处理时间序列中当间隔和延迟较长时比RNN效果更好,双向长短期记忆网络(BiLSTM)可以同时获取上下文信息并存储记忆,这两种模型可用于优化术语/实体抽取、关系抽取、结构功能识别、分类、聚类等多项任务。
基于图/网络结构的方法利用图的拓扑结构或者聚合来自邻居节点的信息,表征学术资源节点或学术文本知识之间的相关关系或关联,再利用基于图/网络的分析和计算方法进行图内部特征的深入挖掘。社会网络分析是一套规范的,对社会关系与结构进行分析的方法,用于解决人际传播网络、学术网络分析、关联分析、引文分析、知识管理等问题,涉及网络密度、中心性、凝聚子群等量化分析方法。主路径分析是一种数学工具,最早由Hummon和Doreian在1989年提出,用于识别引文网络中的主要路径,该方法通常用于通过书目引文或专利引文来跟踪科学或技术领域的知识流动路径或发展轨迹,如文献等。
从采用技术角度可以发现,数据挖掘、文本挖掘、机器学习、网络科学等为学术资源挖掘研究提供了技术与方法基础,其中词嵌入、深度学习等新技术有效提升了学术资源挖掘的性能,并且大大降低了人力成本,也为相关研究提供了进一步优化和完善的方向,而联合应用多种模型或算法也成为一个可待深入探索的研究思路。
3学术资源挖掘方法应用分析
对学术资源进行深层次的揭示、聚合和挖掘,有效推动学术资源的快速获取和知识共享,学术资源挖掘方法或结果已经为学术检索系统、學术推荐、技术预测和趋势分析等方面提供了有力支撑。
3.1学术检索系统
从海量学术资源中全面、准确地找到需要的信息一直是图书情报领域的重点研究任务。近年来,智能检索和语义检索技术大大提升了学术信息检索的效果,而对学术资源的挖掘使得学术资源更容易被发现,有效推动了学术检索系统的性能提升,一些学术引擎系统已经被广泛使用。如Semantic Scholar致力于理解学术文献的内容,利用AI技术帮助用户从海量的学术文献中筛选有用信息,解决信息超载的问题。AMiner系统构建了大型学术知识图谱,利用一个生成概率模型,在提供主题级专业知识搜索的同时对不同的实体进行建模。此外,刘梦兰等以Word2vec为词向量训练工具,结合专利文献自身的特点,提出了一种基于词向量的查询扩展方法,有效提升专利文献的检索效果。陈国华等基于Glove训练词向量,利用随机映射的方法,在大规模的向量空间中快速定位向量,并提出了一种学术文档向量化的方案,在学者网学术检索中取得良好的检索效果。
3.2学术推荐系统
对学术资源进行深度挖掘有助于向用户推荐相关的学术资源、投稿期刊、合作者、专家等,提高科研用户的工作效率,促进学术交流与合作。例如Guan P等借助标题、关键词、摘要和引文对文献进行语义丰富化,并利用TF-IDF算法构建主题词权重向量,构建用户兴趣模型进行文献推荐。熊峰通过资源—标签矩阵对出版资源标签进行关联分析,提供较优的标签属性供用户选择,使资源备选集的划分得到优化。刘康在论文语料库的“文档一主题”矩阵上加入概率模型形成不确定知识图谱,以此针对用户背景知识和目标知识之间存在的差异进行学术论文的个性化推荐。Ayala-G6mez F等提出了一种使用知识图谱来建立全球引文推荐的方法,通过使用知识图谱扩展来挖掘给定摘要中的语义特征,并将它们与其他特征组合以适应学习排名模型,最后通过这一模型来生成引文推荐。段旭磊等采用数据挖掘、中文信息处理等技术,对科技文献库中专家数据挖掘、分析、建模,用于发现和推荐领域专家群、专家。
3.3科技前沿识别与预测
准确把握科学研究和技术前沿,识别新兴科技并尽早捕获未来的发展契机和变化趋势,对于科技决策机构、科研机构、科技企业、科研人员等都具有重要的作用。学术资源的挖掘同样有效支撑了研究科技前沿的识别与预测。通常情报研究人员以学术资源如论文、专利等为核心,运用情报学、计量学、数据挖掘等方法探测研究前沿。例如冯佳提出了基于LDA的研究前沿识别方法,通过科技文献主题强度和主题新颖度识别研究前沿。黄鲁成等利用技术属性挖掘专利文本信息,并运用物种入侵算法和集对分析方法对颠覆性强度值进行测度。张金柱等利用专利科学论文的关键词和学科分类表示被引科学知识,以不同时间段被引科学知识的差异程度表示技术创新的突变程度,进而识别出突破性创新。白光祖等提出了基于文献知识关联的颠覆性技术预见方法,利用文献知识中的突变、交叉特征识别具有颠覆性潜力的领域內外部技术主题。石慧等提出一种基于文献挖掘的颠覆性技术早期识别方法,从文献中抽取主题词,分析主题词的频数变化以及论文主题词和专利手工代码的突变情况。
4结论与展望
本文系统地梳理了近年来国内外学术资源挖掘方法的发展现状,详细分析和对比了挖掘方法的研究对象、挖掘维度、使用技术等,为相关研究方法的提出和优化提供了参考。纵观学术资源挖掘的研究,可以发现经过不断地研究与探索,学术资源挖掘已取得了长足进步,特别是在文献挖掘、专利挖掘等领域已经形成了一些成熟的技术和应用产品,但仍存在可进一步探索和提升的方向。
1)本体、关联数据、知识图谱等技术推动了学术资源的语义化发展,将学术资源内部知识进行语义建模并通过实体/概念语义化地组织和关联起来并显式地表示,能够促进内容重用和知识集成,但如何对海量学术资源进行语义表示和知识组织体系构建仍有待于进一步研究和探索。
2)深度学习技术在学术资源挖掘的研究正逐步深入,尽管在智能信息抽取、文本分类、文本聚类等方面取得了一定的进展,但是整体来说,深度学习在学术资源挖掘的应用研究还处于初级阶段,在未来必定会有更多的尝试和突破。
3)目前学术资源挖掘的主要研究对象仍为学术论文和专利,尽管其他类型的学术资源逐渐受到重视,但当前研究主要聚焦在学术资源建设和整合方面,如何将学术资源有效地组织、整合起来,为科研用户提供一站式服务,满足其个性化需求,对不同类型学术资源进行联合挖掘的相关研究仍有待于推进。
4)目前,学术资源纵向挖掘研究大多面向领域或指定知识类型,并且往往使用特定的语料库或训练集,很难实现到其他领域的自动迁移。因此,如何实现其他领域或跨领域的深层知识挖掘,如何不断提高方法或工具的准确率、可移植性以及可扩展性,激励着研究人员投入更多的精力和时间。
5)随着学术资源爆炸式增长,基于大数据和人工智能技术扩展及优化现有挖掘方法,实现海量学术资源的高效计算,仍然是亟待解决的难题。
(责任编辑:陈媛)
猜你喜欢
水运工程(2022年7期)2022-07-29
新世纪智能(数学备考)(2021年9期)2021-11-24
开放教育研究(2020年2期)2020-03-31
当代陕西(2019年15期)2019-09-02
传感器世界(2019年4期)2019-06-26
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
化学分析计量(2013年1期)2013-03-11
