
基于残差注意力和金字塔上采样的图像语义分割
2022-01-27 10:26高军礼宋海涛
信阳师范学院学报(自然科学版) 2022年1期
高军礼,周 华,宋海涛,郭 靖,张 慧
(1.广东工业大学 自动化学院, 广东 广州 510006; 2.华南理工大学 工商管理学院, 广东 广州 510640)
0 引言
图像语义分割是对图像中的每个像素进行分类、将不同的实体分类为不同标签的像素级别的分割,已广泛应用于多个领域。例如,在自动驾驶领域,汽车需要具备必要的图像识别与分割能力才能充分理解其行驶过程中的环境变化;在医疗图像诊断领域,可以帮助医生对病人的患病处图像进行分析,从而提高对病患的诊断效率。
随着卷积神经网络(Convolution Neural Network, CNN)的发展,采用CNN的图像语义分割方法在精度和效率方面得到显著改善。基于CNN的方法一般是将提取的特征图作为目标,在特征图中再次提取不同尺度的特征并进行多尺度融合,但是仅仅针对最终输出的特征图不足以提取充分的多尺度特征,而且也缺乏像素级的信息[1]。越深层的CNN对图像特征提取的能力越强,但是当网络达到一定的深度时,模型对图像的预测精度反而会迅速下降,出现梯度消失现象[2],而且网络越深,梯度消失现象越明显。ResNet[3-4]中的残差模块则能有效解决深层网络中出现的梯度消失现象,且能进一步提高网络的特征提取和识别能力。因此多数语义分割算法使用了残差模块,或基于ResNet-101[5-6]作为特征提取的主干网络。编解码器的结构采用逐级下采样方式以增大感受野(Receptive Field),但在感受野增大的过程中会丢失原始图像的空间信息。而上采样能够将分辨率逐步还原到原图大小,不过仍然会丢失部分细节信息。对于将所有像素平等对待的语义分割算法显然和人类的视觉机制不同。
为了加强对图像中感兴趣区域的影响,削弱无关背景,注意力机制在图像语义分割中得到了关注。该机制模仿生物观察行为的过程,着重增加对某部分区域的关注度。通过注意力机制保留图像中关键信息的代表性网络为JADERBERG等[7]所提出的STN(spatial transformer networks)。虽然可以通过增加注意力模块来提取不同尺度的特征,但过多的注意力模块会导致网络层次过深而出现梯度消失现象。对于金字塔池化模块,通过全局平均池化和特征融合引入更多的上下文信息,能有效提升模型的场景识别能力,但对低维度的语义特征利用得不充分。它将后端提取的特征直接接入到金字塔池化模块中,对多层信息尤其是浅层细节信息利用较少。
1 相关研究
2015年,LONG等[8]通过全卷积神经网络(Fully Convolution Neural Network, FCN)进一步促进了语义分割技术的发展。RONNEBERGER等[9]在FCN的基础上提出U-Net,采用编解码器框架,将上采样和下采样进行融合,既能提取低分辨率信息又结合了高层语义信息。2015年,何凯明团队提出残差网络(Residual Neural Network, ResNet),与传统的简单堆叠网络方式不同,其在神经网络的上一层和下一层之间加入了恒等映射,使得上一层神经网络在传递信息时,能够直接传递给下一层,使得信息传递的层次更深,又能减少普通CNN在传递过程中的损失,且网络层数可高达101层。2019年,HU等[10]提出注意力辅助网络(Attention Complementary Network, ACNet),利用图像深度信息对室内场景下的RGBD图像进行语义分割,获得了良好的分割效果。CHEN等[11]认为不同尺度的特征图对预测结果会产生不同的影响,并基于注意力机制设计了一种可学习的权重图,实现对不同尺度的预测结果分别加权处理。HU等[12]提出SE-Net,通过Squeeze和Excitation两个关键的操作,学习特征图通道之间的相关性,筛选出对特征影响更大的通道,精度提升明显,但计算量也相对较大。针对图像目标检测,HE等[13]提出空间金字塔池化(Spatial Pyramid Pooling, SPP)模块,通过使用不同步长的池化层,将输入的特征图转化为多个尺度,实现对输入特征的多尺度学习,但由于其最终融合的特征是单个向量,对于图像语义分割而言不具备物体的空间关系。ZHAO等[14]对其进行改进,提出金字塔场景解析网络(Pyramid Scene Parsing Network, PSPNet),通过金字塔池化模块获取不同区域的语义信息,在进行特征融合后得到全局的场景信息,加强了对象间的上下文关系,能够有效地解决不同场景中误分割的问题。Google团队[15-18]结合深度CNN相继提出DeepLab系列算法,其核心是空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP),并将神经网络特征提取部分作为编码器,上采样过程作为解码器,分割准确率得到较大提升。LIU等[19-20]利用空洞卷积和空洞金字塔池化的方式在不降低特征图大小的同时获得更大的感受野,既保留了图像中的空间信息,又得到了高层语义信息,但由于计算量较大,容易产生网格效应。
在对前述成果进行研判的基础之上,针对深度CNN容易出现的梯度消失问题,本文基于ResNet-101主体网络,引入ResNet[3-4]中的残差模块;基于U-Net网络,提出将注意力模型拼接在残差模块之后而构成残差注意力模型。通过注意力机制训练出权重图,以重点关注特征图中权重较大的部分,使其在提取深度语义特征的同时也能关注图像的细节信息。为了有效恢复图像中的空间信息又不产生过大的计算量,基于金字塔池化机制,提出联合金字塔上采样模块。最后,基于VOC 2012和Cityscape数据集,对本文所设计的图像语义分割网络和相应的算法进行实验验证,并与FCN-8s、SegNet、Deeplab-v2、PSPNet等方法进行对比分析。结果表明,本文所提出的方法在语义分割准确度(如mIoU、mPA)和分割效果(如类别、对象轮廓、边缘细节等)方面有着显著的提升和改善。
2 图像语义分割
在编解码器结构的基础之上,结合残差注意力模型和金字塔上采样机制,本文所设计的图像语义分割网络如图1所示。编码器的输入为RGB彩色图像,结构上包含1个卷积层、1个池化层和由残差模块及注意力模块重复堆叠构成的残差注意力模块。经由每个残差注意力模块输出分辨率呈阶梯状变化的特征图作为解码器的输入,以获得4种不同尺度的特征图。对于原始的ResNet-101网络,只能得到最后的特征图,其后续的操作都基于该特征图进行,虽然可以获得高层的语义特征,但对低层的细节特征提取却不足。因此,本文将ResNet-101分为4个阶段,在每一个阶段后再拼接残差注意力模块,对特征图中的像素进行加权处理,从而得到不同尺度的特征。
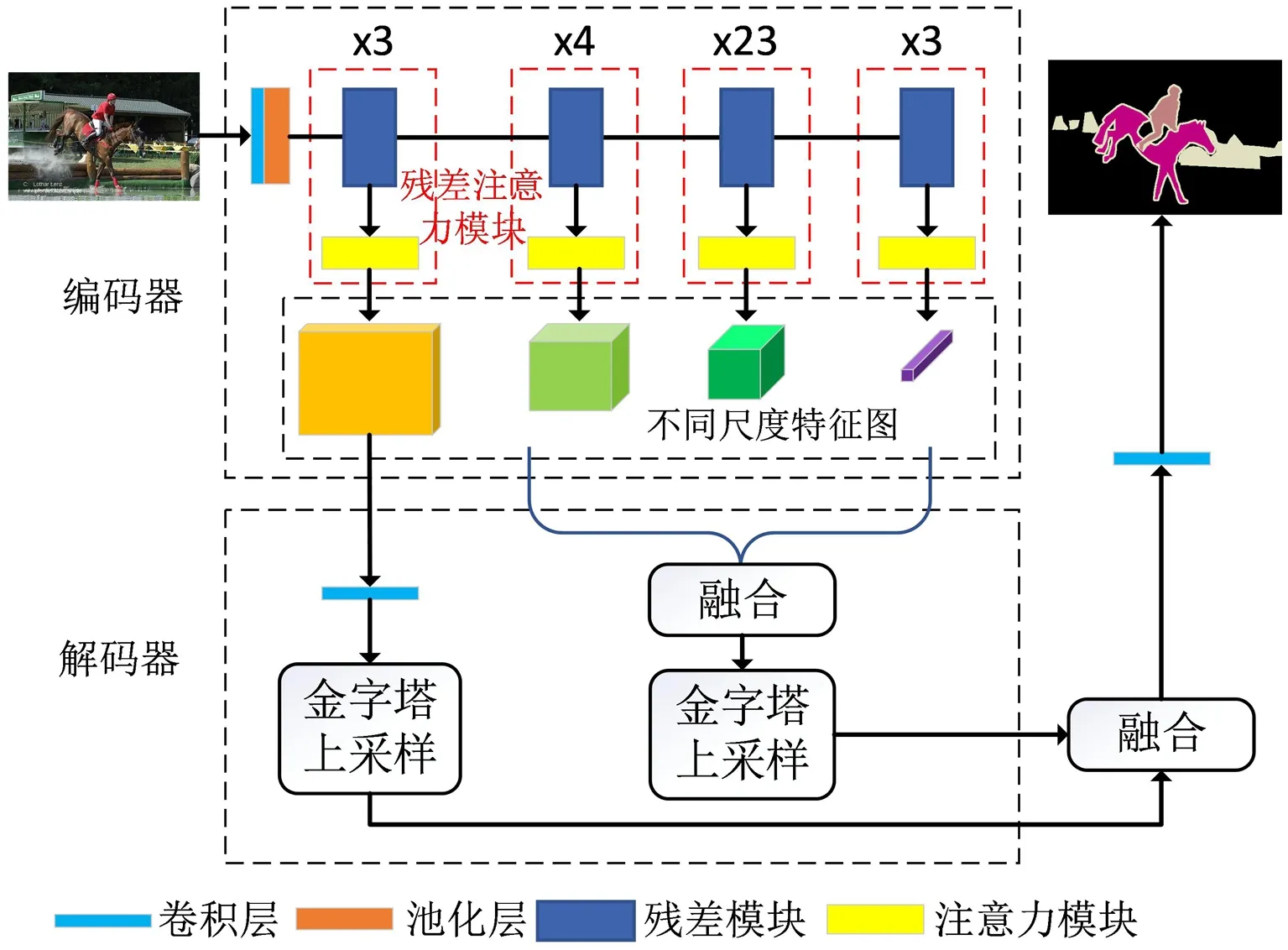
图1 网络整体结构Fig. 1 The overall network structure
解码器参考Deeplab-v3+中的结构,负责将不同尺度的特征图恢复至原图大小。第一条支路的输入为含有丰富细节特征的低层次特征图,对其进行单独上采样,以在解码过程中恢复尽可能多的细节特征;另一条支路的输入是3个层次较高的不同尺度的语义信息特征图,采用双线性插值上采样后再与另一支路的低层次特征进行融合,经过卷积和Softmax函数后,输出与原图分辨率大小相同的像素级别的特征图,进而对图中每个像素进行分类,输出最终的分割结果。
下面对本文所提出的图像语义分割网络的残差注意力模型和联合金字塔上采样两个最为关键的部分进行深入探讨。
2.1 残差注意力模型
通道注意力能够建立起图像通道维度的特征,输出每个特征通道的权重分布图,进而可以根据不同场景学习到不同通道的重要性。本文所采用的注意力机制模块如图2所示,其输入为特征图,先对特征图进行全局平均池化,以降低输入特征图的维度。然后经过1×1卷积层和Relu激活函数组成非线性映射,输出数值范围在1和0之间的权重特征图,表示不同尺度和像素位置的重要性,最后和原始输入的特征图进行加权后输出相应的权重图。
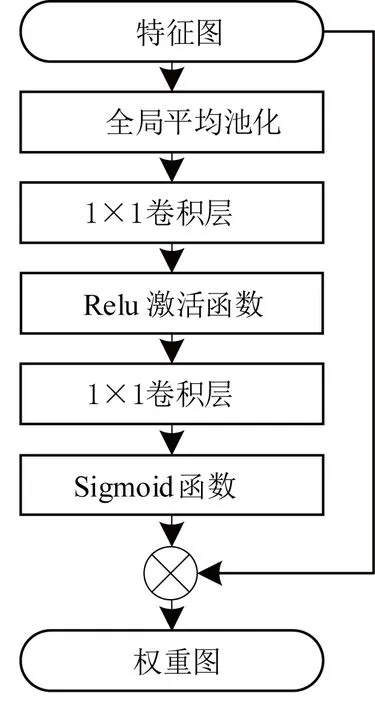
图2 注意力机制模块Fig. 2 Attention mechanism module
若U表示输入特征图(uc为某一通道特征),H和W分别为特征图的高度和宽度,C为维度,则其大小为H×W×C。z∈Rc表示池化后的信息量,c为通道数,则经过全局平均池化后的信息量可表示为:
(1)
基于ResNet的残差模块如图3所示,若残差模块的输出为:
y=F(x,{Wi})+x,
(2)
其中:x为输入向量,Wi为第i层神经网络,y为输出向量,函数F(x,{Wi})表示需要学习的残差映射。
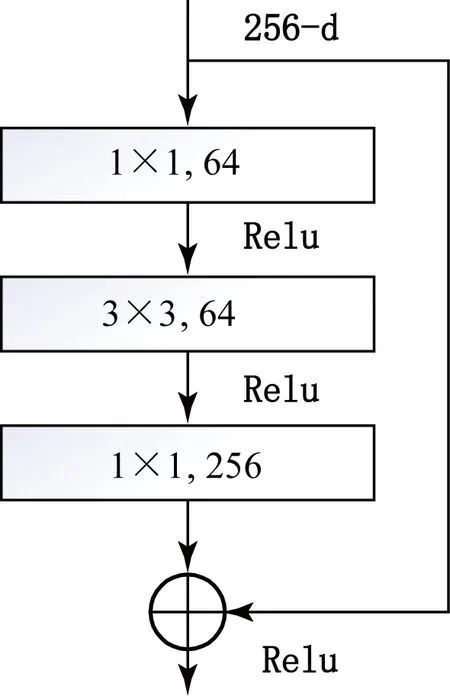
图3 残差模块示意图Fig. 3 Schematic diagram of the residual module
若残差模块中有两层CNN,则函数F可表示为:
F=W2σ(W1x),
(3)
其中:σ表示Relu激活函数,W1和W2分别表示第1层和第2层神经网络。输入向量x和F的维度必须相等,如果改变了输入或输出的维度导致两者不相等,则可以用一个线性映射Ws来表示短连接:
y=F(x,{Wi})+Wsx。
(4)
基于注意力和残差机制,本文将注意力模型拼接在残差模块之后,所构成的残差注意力模型的结构如图4所示。
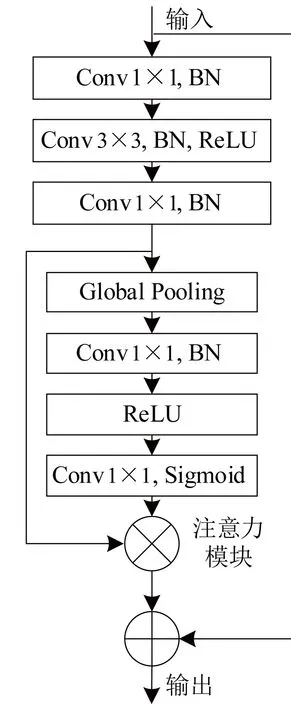
图4 残差注意力模型结构图Fig. 4 Structure diagram of residual attention model
首先,输入的特征图进入残差模块,残差模块中第一个和第三个卷积核大小为1×1,第二个大小为3×3。其次,在卷积层之后,激活函数之前加入批正则化层,对输入数据进行归一化操作,防止输入数据发生偏移。然后,将数据输入到注意力模块,经过全局池化和 1×1卷积后,再通过Sigmoid函数进行像素权重的划分,得到的特征图和原始的输入特征进行加权,并输出至解码器。
2.2 联合金字塔上采样
金字塔模型可用于对同一图像按照金字塔的形状逐步降低分辨率,形成图像金字塔,从不同尺度的特征图中提取多尺度的语义信息,并且结合浅层的细节特征,使模型能获得更好的性能。PSP-Net中所提出的金字塔池化模块如图5所示,包含4层,输入为特征提取阶段产生的特征图,经过不同步长(如1、2、3、6)的池化层,产生4种不同尺度的特征图。为了对特征图进行重新映射,金字塔中每一层使用1×1大小的卷积核进行卷积,将特征图的大小降低到原来的1/N,其中N为金字塔的层数;然后将得到的特征图进行上采样,使用双线性插值将图像还原至原始分辨率;最后与原始输入的特征图进行融合。
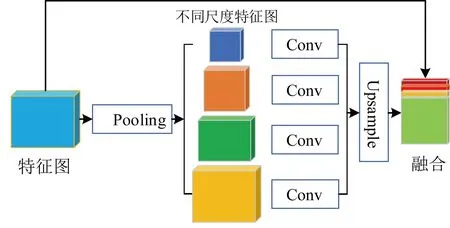
图5 金字塔池化模块示意图Fig. 5 Schematic diagram of pyramid pooling module
为了恢复图像中的空间信息又不至于产生过大的计算量,受金字塔池化的启发,本文所提出的联合金字塔上采样模块如图6所示。首先将不同尺度的特征图作为输入经过上采样后进行融合,以提取多尺度特征,用以提高模型的预测效果;然后采用不同空洞率的深度可分离卷积捕获不同级别的特征,图1中空洞率为1的卷积层用以捕获低层次的语义特征,而空洞率为2、4、8的卷积层则用于学习不同尺度的特征转换;最后将这些金字塔式的特征图进行拼接,以融合目标图像的细节和全局特征。
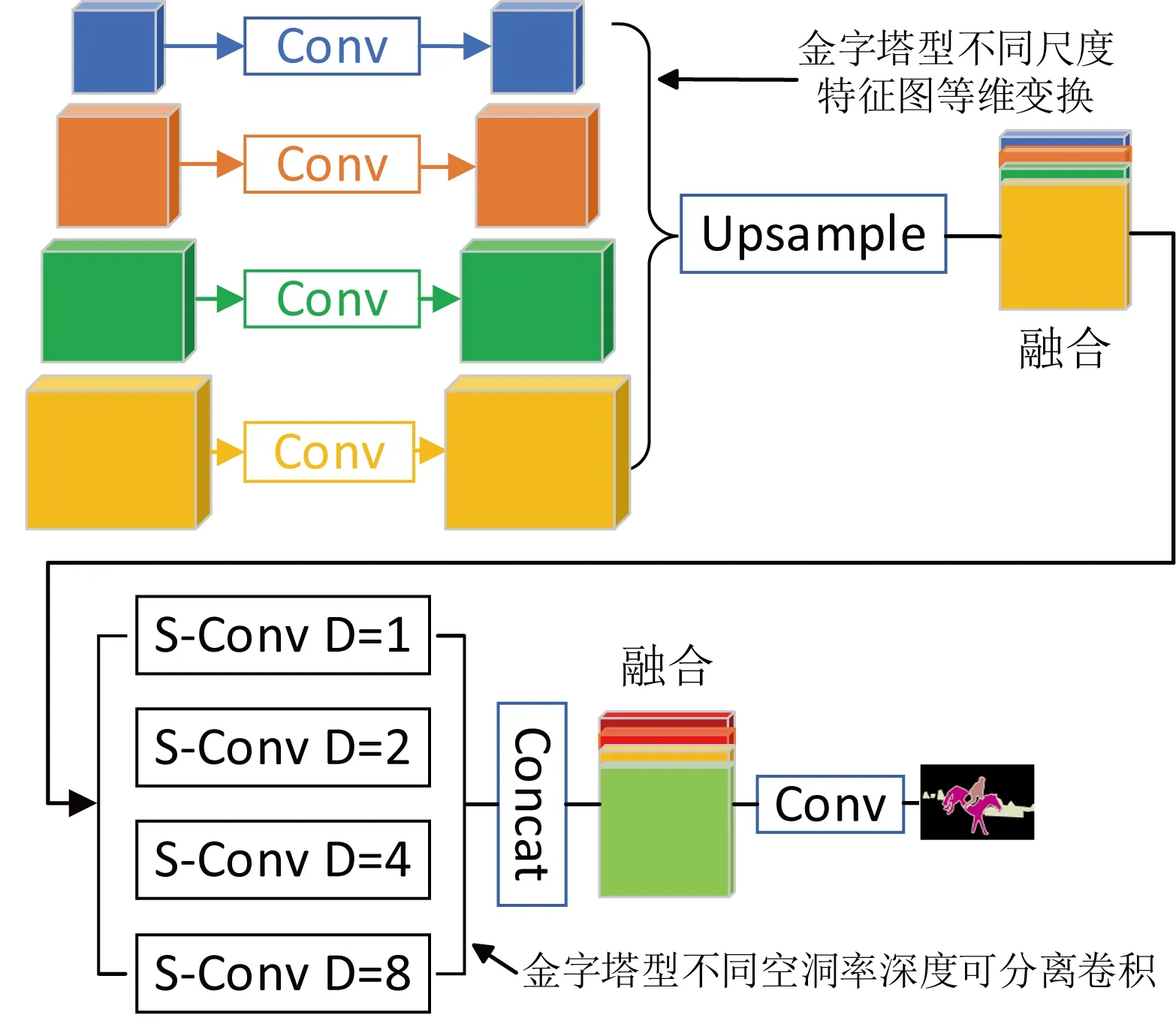
图6 联合金字塔上采样模块Fig. 6 Joint pyramid upsample module
3 实验验证
3.1 实验设定
系统实验环境采用Ubuntu 16.04,计算平台采用显卡GTX1080Ti 8 G,CPU E5-26890 2.6 GHz,内存16 G,Tensorflow 1.13深度学习框架。以平均像素精度与平均交并比作为评价指标,设数据集中可供分割的对象类别为k,则总的类别为k+1,其中1代表背景。设Pij表示属于i类的像素被错误的识别为j类的像素点的个数,Pii表示被正确判断为i类的像素点个数,Pjj表示被正确判断为j类的像素点个数。平均像素精度 (mean Pixel Accuracy, mPA)如式(5)所示,表示每个类别被正确分类的比例的平均值。
(5)
平均交并比(mean Intersection over Union, mIoU)如式(6)所示,其含义为图像中分割结果与真实值的交集和并集之比。
(6)
实验中,首先对Pascal VOC2012[21]和Cityscape[22]数据集进行数据增强,即将图像数据和对应的标注图像进行同步随机垂直镜像和水平翻转,然后再采用最近邻插值算法,进行比例在0.5~2.0之间的随机整体缩放。模型训练过程中的优化器采用Adam[23]。与传统的随机梯度下降算法相比,Adam能够动态调整算法内超参数的学习率,使模型训练过程中的参数变化更加平稳,而且对内存的需求相对较小。批大小的设定和实验的硬件环境有关,如设置过大则会超过图形处理单元(GPU)显存容量,本实验分别设定为12和6。采用多项式Poly衰减学习率策略,学习率会随着训练批次的变化而逐渐减小。设lr为学习率,power为衰减系数,iter为批次大小,则衰减公式如式(7)所示:
(7)
3.2 基于PASCALVOC2012的实验验证
PASCAL VOC2012数据集广泛用于物体识别、目标检测等领域,也是图像语义分割中常用的数据集之一。该数据集包含1464张训练图片和1449张验证图片。实验中随机裁剪图像的大小为256×256,模型的损失 (loss) 与精度(acc)随迭代次数(step) 的变化过程如图7所示。
从图7中可看出,经过约230次的迭代,模型损失与精度达到收敛。为进一步验证本文所提出网络和算法实现的效果,以mIoU与mPA为评价指标,与FCN-8s、SegNet、Deeplab-v2、PSPNet等进行分析比较。在VOC2012数据集上的语义分割性能如表1所示,相比其他4种方法,本文所提出的方法具有最佳的分割准确率(mIoU和mPA指标值均为最高),最高分别提高15.9%、3.57%,达到78.1%、92.67%。
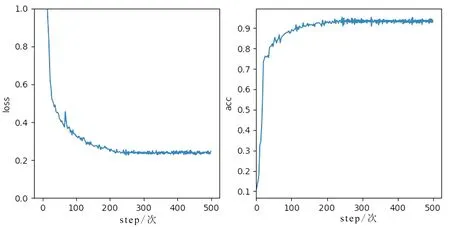
图7 训练过程中模型损失与精度的变化Fig. 7 Model loss and accuracy during training
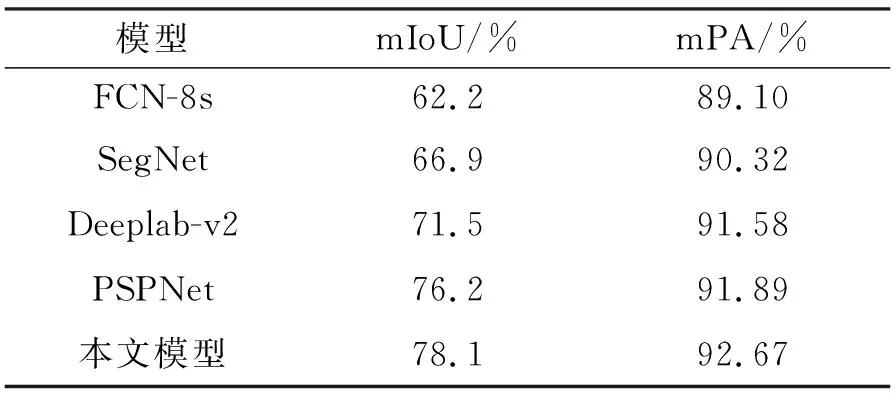
表1 基于VOC2012的mIoU与mPATab. 1 mIoU and mPA based on VOC2012
与FCN-8s、PSPNet、GroundTruth相比,语义分割的效果如图8所示。其中,黑色部分表示背景,不同的颜色区域则对应不同的类别。

图8 在VOC2012中的分割效果Fig. 8 Segmentation effect on VOC2012
FCN-8s在语义分割中存在分割遗漏的问题,如第2组(行)忽略了图像边缘的显示器,第4组(行)对后面汽车的分割明显不完整;PSPNet的分割效果与本文所提出网络的效果较为接近,在第2组(行)PSPNet能够正确识别出其中的显示器,但类别识别错误,而本文所提出的方法则能够正确地识别出对象的类别;第3组(行),FCN-8s无法精细分割人物的手部,PSPNet人物的手部粘连在一起,而本文所提出的方法能够清晰地辨识出人物的手部,即对物体的类别识别和细节边缘上有所提升,也验证了所提出的残差注意力模型的有效性。
3.3 基于Cityscape的实验验证
Cityscape数据集是拥有50多个城市街道场景的大型数据集,并以无人驾驶的视角用视频序列的方式记录街道上的图像,共有5000张图片,包括2975张训练图片、500张验证图片和1525张测试图片。该数据集中图像的分辨率为2048×1024,受计算资源的限制,实验中将其随机裁剪为713×713。不同于VOC2012,Cityscape拥有更多的图像用于学习,同时也存在更加复杂的场景和类别,要求模型对场景的理解能力更高。针对该数据集的实验结果如表2所示。与其他 4种方法相比,本文所提出的方法具有最佳的分割准确率(mIoU和mPA指标值均为最高),最高分别提高17.8%、13.3%,达到66.5%、88.7%。另外,由于Cityscape数据集本身类别较多、场景复杂、每种类别和细小物体也多,所以在该数据集上的mIoU普遍比在VOC2012数据集中的低。
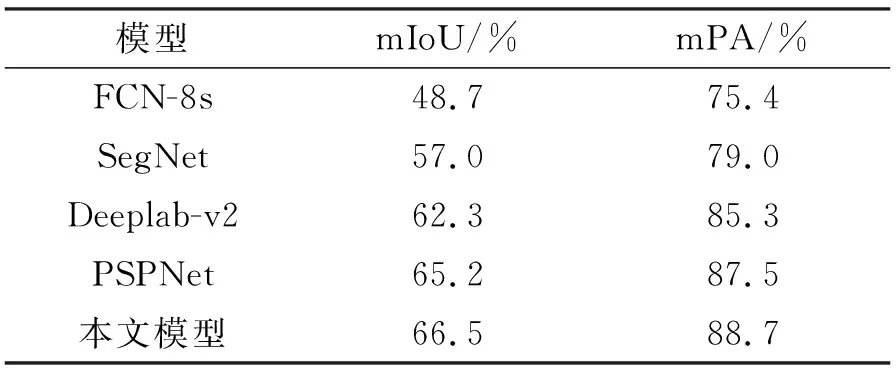
表2 基于Cityscape的mIoU与mPATab. 2 mIoU and mPA based on Cityscape
与SegNet、PSPNet、GroundTruth相比,在Cityscape数据集中的语义分割效果如图9所示。SegNet倾向于识别对象的类别, 但不能很好地处理对象的轮廓,尤其是对车、树林、建筑等物体。如第1组(行)中道路旁边的圆柱,其边缘明显比PSPNet和本文所提出方法的分割效果差,第2组(行)中的红绿灯也是类似;在第2组中,由于婴儿车上的小孩和车处于粘连状态,PSPNet无法正确分辨两者的正确位置,而本文所提出方法的分割效果与真实标签更为接近;在第3组(行)中,由于灯柱部分很细,PSPNet的分割中产生断层现象,而本文所提出的方法则可以很好地分割出这类细小的物体。
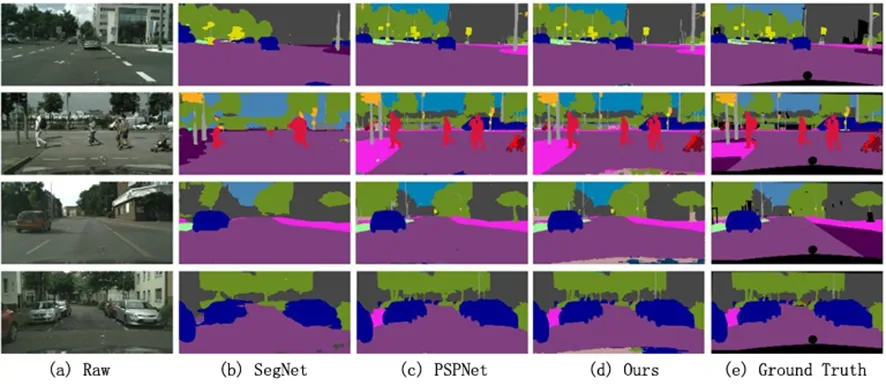
图9 基于Cityscape的语义分割效果Fig. 9 Semantic Segmentation Effect based on Cityscape
4 结论
随着深度学习的崛起,图像语义分割成了近几年的研究热点。在编解码结构的基础上,对语义分割领域中分割类别边缘粗糙、多尺度物体识别能力不强的等问题进行研究,提出基于残差注意力和金字塔上采样的图像语义分割网络。其中,残差注意力模型,可增强对图像细节特征的关注度,加强不同尺度特征图之间的关系,从而得到更加精细和准确的分割效果。通过设计联合金字塔上采样模块,提高了网络对多尺度物体和复杂场景的识别能力。最后基于Pascal VOC 2012和Cityscape数据集,通过实验对不同网络的语义分割效果进行对比验证。结果表明,本文所提出的网络和方法在分割准确度(mIoU、mPA)和分割效果方面有着较好的表现。接下来,我们将聚焦于基于语义分割的语义理解及其在人机交互领域中的应用。
猜你喜欢
计算机应用(2022年9期)2022-09-25
环球时报(2022-09-19)2022-09-19
网络安全与数据管理(2022年3期)2022-05-23
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2020年10期)2020-11-14
考试与评价·七年级版(2020年4期)2020-10-23
自动化学报(2019年6期)2019-07-23
少儿美术(快乐历史地理)(2019年2期)2019-06-12
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
