
Volterra核优化的SRC人脸识别算法
2022-01-27 09:52焦阳,赵嵩
信阳师范学院学报(自然科学版) 2022年1期
焦 阳,赵 嵩
(1. 河南牧业经济学院 能源与智能工程学院,河南 郑州 450046;2. 郑州航空工业管理学院 智能工程学院,河南 郑州 450046)
0 引言
在生物特征识别领域,分类是识别过程中的关键的步骤。在各种分类方法中,最近邻(Nearest Neighbor,NN)[1]分类法和最近邻子空间(Nearest Subspace,NS)[2]分类法由于简单易用而广为使用。近年来,基于稀疏表示的分类(Sparse Representation based Classification, SRC)[3]因其鲁棒性和良好性能引起了许多模式识别研究者的兴趣[4]。DENG等[5]将SRC应用在每类具有极少训练图像的情况中。SRC使用稀疏信号重建的无参数学习方法表示数据,并依照重建误差进行数据分类。但是SRC会失去在相同方向上的数据分类能力[6]。如果训练样本和测试样本属于两个或多个分类并有相同的向量方向,SRC将不能实现分类。在机器学习中,核函数多用于构造非线性支持向量机[7],不同于径向基函数和多项式核,Volterra核可以有任意(无须是平方)的形式,能够对任意平滑的非线性函数有更好的表示,并产生连续的近似[8]。Volterra核的另一个优势是其平移不变特性,如果原始图像进行固定的量变换,映射图像也同步进行量变换[9]。为了更好地利用Volterra核性能,学者们提出了一些关于Volterra核的改进算法,比如Volterra核的人工蜂群优化算法[10]。在SRC方面也出现了根据遮挡条件进行正则化参数修正优化[11]、多稀疏表示的决策融合[12]等改进算法。但这些方法对属于同一方向不同类别样本的分类准确率还不高,基于此,本文提出Volterra核稀疏表示的分类算法(Volterra-SRC)。该算法在空间域将原始图像分为小块,并使用Volterra核将每个小块映射到高维度特征空间。在训练阶段,通过类间距离最大化和类内距离最小化处理,从而使目标函数导出最优Volterra核。在测试阶段,使用表决程序协调SRC以判定每个分块所属的类。
1 基于分类的稀疏表示方法
WRIGHT等[3]将稀疏表示应用于分类,并拓展了SRC算法。该算法将测试样本表示为训练样本的稀疏组合,其系数通过稀疏分解获得,SRC方法如下:
假设有训练符号集{(xi,yi)|xi∈χ⊆Rm,yi∈{1,2,…,c},i=1,2,…,n},其中c是类别数目,m是输入空间χ的维度,yi对应于xi,给定测试样本x∈χ,目标是从给定的c-分类训练样本中预测出x的标签y。将第j分类训练样本作为矩阵Aj=[xj,1,…,xj,nj]∈Rm×nj(j=1,2,…,c)的列,xj,i表示样本属于第j类。对所有训练样本定义一个样本矩阵A,
A=[A1,A2,…,Ac]∈Rm×n,
(1)
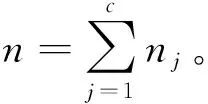
y=Aa,
(2)
其中:a∈Rn是系数向量。如果测试样本x属于第j类,那么所有的a应该是零,即:
a=[0,…,0,aj,1,…,aj,nj,0,…,0]T,
(3)
其中:aj,i∈R是训练样本xj,i的相关系数,且系数向量a是稀疏的。在SRC算法中,把寻找系数向量的问题转化为凸规划问题。
(4)
其中:‖·‖1是l1-范数。式(4)也被称为l1-最小化问题。考虑样本包含噪声的情况,模型可修正为
y=Aa+ξ,
(5)
其中:ξ∈Rm是噪声向量,其带宽能量是‖ξ‖2<ε。‖·‖2是l2-范数,可修正为
(6)
文献[11]使用l1-Magic软件包用于解决上述二次规划l1最小化问题,可以通过测试样本和其近似之间的重建误差进行样本分类。使用与第i个类相关联的系数可获得第i个近似值。
SRC算法的具体步骤为
(1)输入: 训练样本矩阵A∈Rm×n,测试矩阵y∈Rm;
(2)将A的列规范化为l2-norm;
(3)求解式(4)和式(5)中的l2-minimization值;
(4)计算残差rk(y)=‖y-Aδk(a)‖2(k=1,2,…,c);
2 基于Volterra核判别数投影降维方法
SRC算法能够很好实现人脸的正面识别,但是对于线性可分离任务(即不同类的数据具有相同的方向)SRC会失去其分类能力。主要原因是在同一方向上的数据在标准化过程后会互相重叠,以至于难以区别。为了解决这个问题,引入Volterra核的方法计算部分广义特征值问题。
根据费舍尔线性不一致的概念,采用最大化类间距离和最小化类内距离定义一个映射矩阵方程。该距离可以通过散列矩阵计算得出,也就是度量数据的方差。令图像集包括C个类,且每个类Xi有ni个样本,类间散列矩阵(Sb)和类内散射矩阵(Sw)通过式(7)、式(8)计算得出。
(7)
(8)
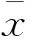
Volterra核由截断的Volterra级数展开形成。由于其具有记忆效应适用于非线性系统建模,已经被成功应用在不同的场景中[14]。本文采用的Volterra级数的离散形式如式(9)所示。
x(m-q1)…x(m-qn)。
(9)
式(9)是无限序列的格式,对于特定应用,只有开始的几项需要给出近似方程。因此,需要Volterra级数的缩短形式,即:
(10)
其中:p表示最大阶数。在截选的Volterra级数中,h(m)是占位符。
方程的数学表达式是
(11)
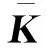
(12)
对称矩阵Sw和Sb可构造为
(13)
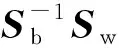
3 实验及分析
在测试中,使用表决程序协调SRC以判定每个分块所属的类。选取的Volterra核大小是3×3,线性情况下使用的非重叠的图像分块大小为8×8。采用标准的人脸数据库ORL和扩展数据库YaleB。在每个数据库中随机选择的一半的图像作为训练样本,剩下的作为测试样本,对于随机选择的10个训练集每个实验重复10次。
3.1 ORL数据库实验
ORL数据库包含40个人的400张面部图像[15],图像尺寸为112×92,像素灰度值为256,在这些图像集中有姿态、光线变化以及面部表情。在实验中,使用的裁剪图像分辨率为32×32,图1显示了一个人的示例图像,表1为在ORL上的平均识别错误率。

图1 ORL数据库中的某一个人的图像样本Fig. 1 A sample image of a person in the ORL database
对于随机选择的10个训练样本,实验时将重复10次。首行为训练集规模,表明使用的训练图像数量,训练样本数为2、4、6、7。从表1可以看到,本文提出的Volterra-SRC比SRC具有更优越的性能。

表1 在ORL数据库中错误识别率对比表Tab. 1 Compares of false recognition rate in the ORL database
为了更进一步比较Volterra-SRC和SRC的特性,图2给出了错误识别率的差值与样本数量的关系。样本数量为2时Volterra-SRC高于SRC算法近4%。随着训练样本数量增加,Volterra-SRC的性能优势不再明显。这意味着本文算法在鲁棒性和小训练样本数量方面有优势。
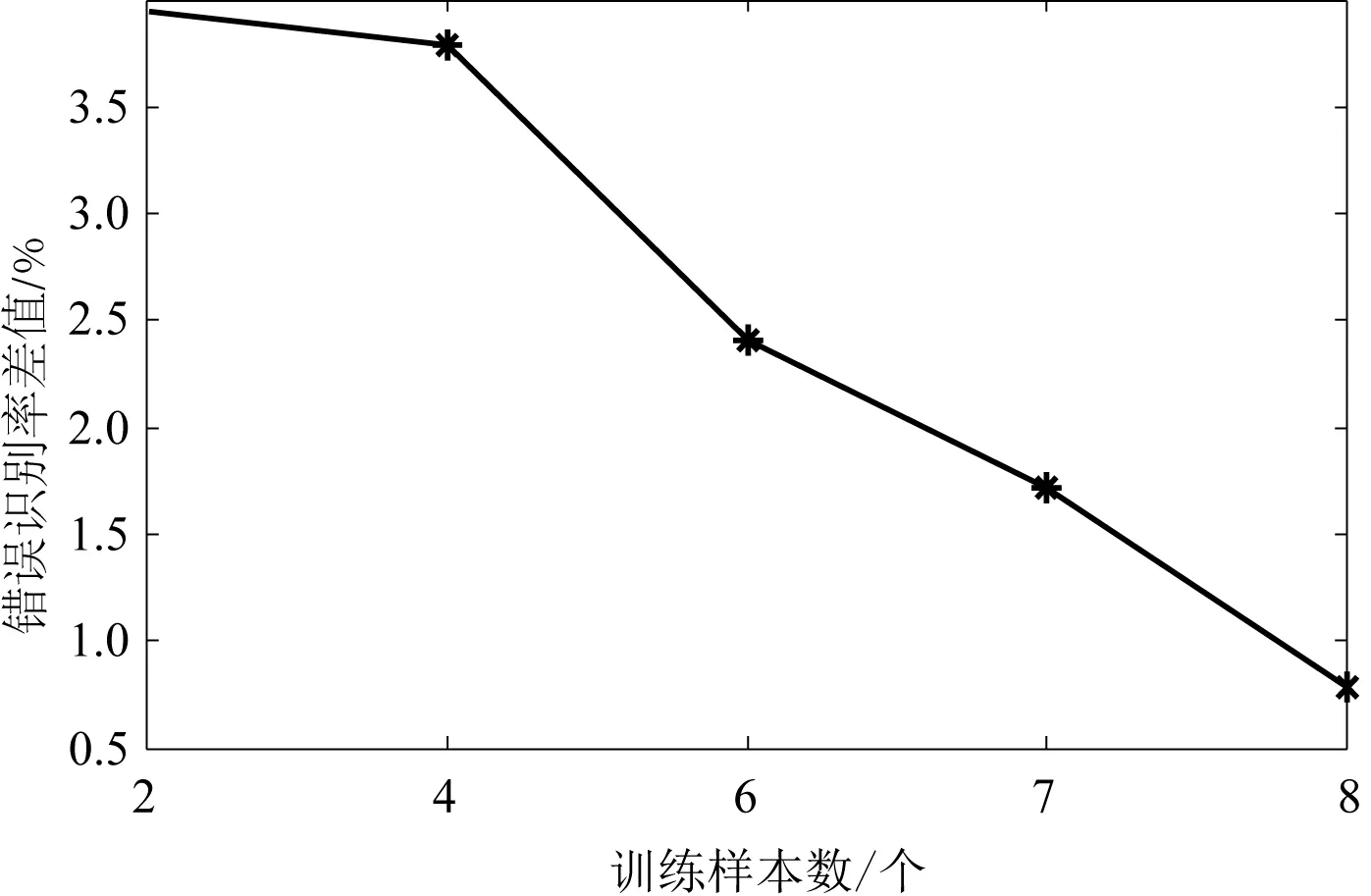
图2 ORL数据库中不同训练样本测试的错误识别率差值Fig. 2 The error recognition rate of different trainingsample tests in ORL database
3.2 YaleB数据库实验
YaleB数据库包含38个人的2414张正面人脸图像[16]。图像是在各种角度可控的实验照明下获取,每个样本拍摄64组图片。在实验中,使用图像分辨率为32×32的剪裁。图3显示了YaleB数据库的示例图片。

图3 YaleB数据库里一个典型的子集样本Fig. 3 A typical subset sample in the YaleB database
表2给出了YaleB的平均识别错误率,训练样本数为4、8、16、32。可以看出,本文提出的Volterra-SRC比SRC具有更优越的性能。
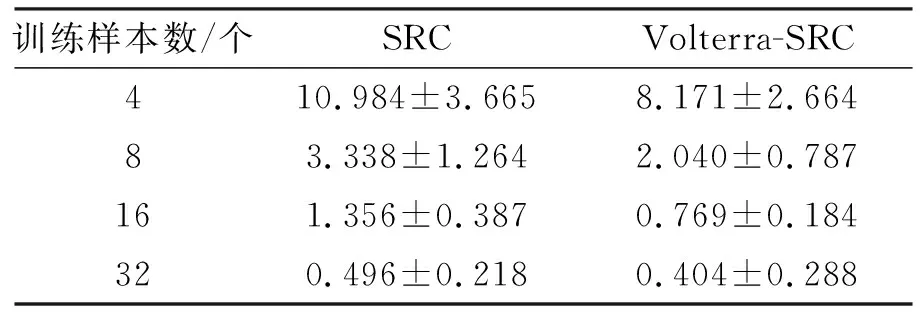
表2 在YaleB数据库里错误识别率对比表Tab. 2 Compares of false recognition rate in the YaleB database
图4表明在小训练样本数量情况下,Volterra-SRC算法的错误识别率高于SRC近3%。本文提出的Volterra核方法改善了SRC的分类性能。
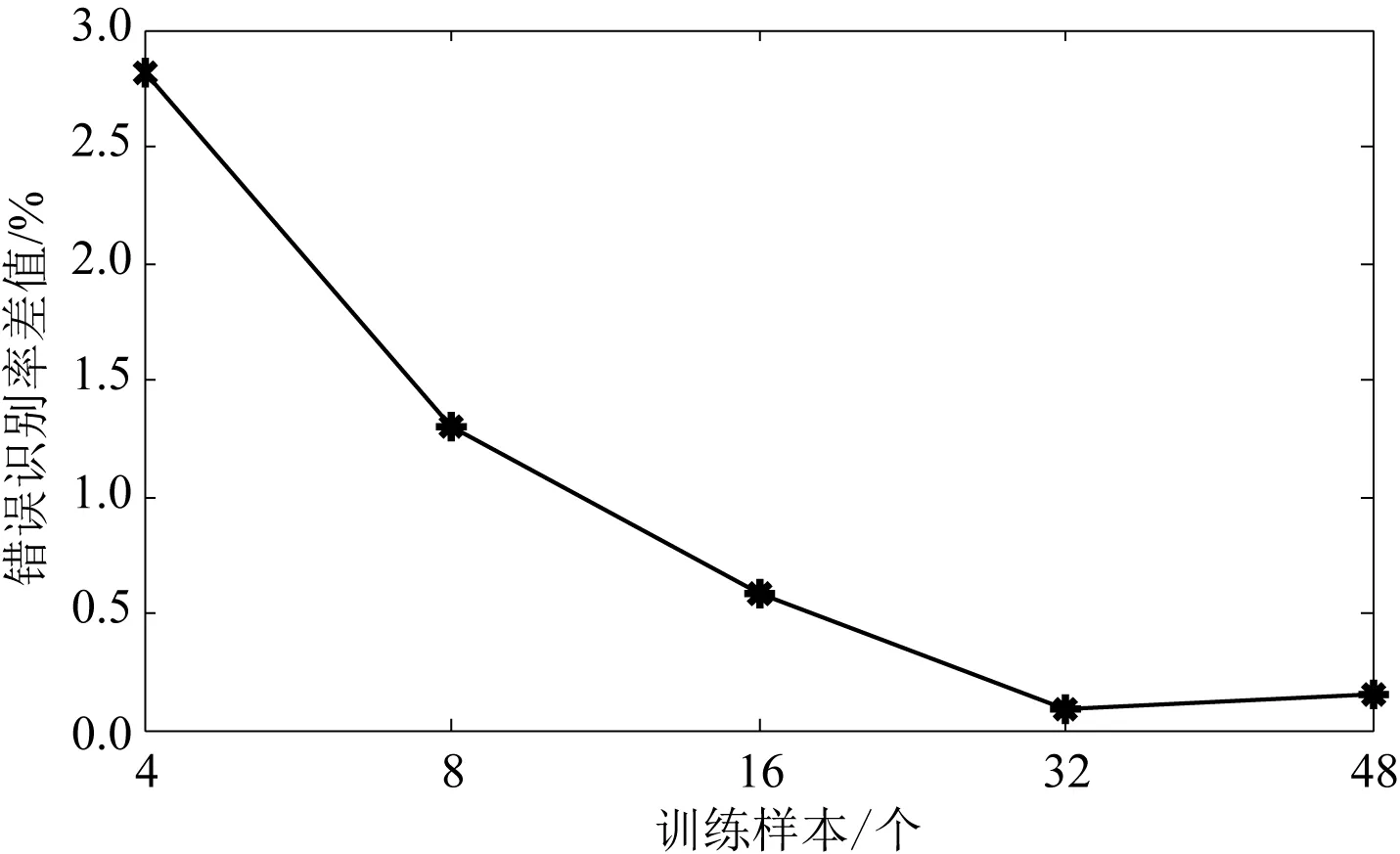
图4 YaleB数据库中不同训练样本测试的错误识别率差值Fig. 4 The error recognition rate of different training sampletests in YaleB database
4 结论
本文提出了Volterra核稀疏表示分类方法,该方法是一种非线性扩展的SRC方法。该方法将原始图像在空间上分块,并映射到一个高维特征空间,利用Volterra核可以产生更好的近似平滑的非线性函数。通过对包含不同的姿势(ORL)和不同照明条件(YaleB)的人脸数据库进行实验,实验结果验证了Volterra核优化的SRC人脸识别算法在小训练样本数量上有一定的优势和鲁棒性,而且Volterra核优化的SRC人脸识别算法比标准SRC算法具有更好的分类性能。
猜你喜欢
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
系统工程与电子技术(2016年7期)2016-08-21
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
中国交通信息化(2016年2期)2016-06-06
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
