
基于深度学习的中文文本分类算法*
2022-02-16 08:34薛兴荣靳其兵
计算机与数字工程 2022年1期
薛兴荣 靳其兵
(北京化工大学信息科学与技术学院 北京 100029)
1 引言
文本情感识别也称为情感分析、意图挖掘[3],它是根据文本所表达的含义和情感信息将文本分为积极、消极的两种或多种类型,它是特殊的文本分类问题[4]。通过分析和研究这些数据,挖掘出潜在的信息,以此来分析网民对社会热点话题的关注度和情感倾,从而为相关部门的政策制定提供支持以及正确引导网民的情绪传播[5~11]。
2 方法
本文提出了一种混合深度神经网络文本分类模型TBLC-rAttention,如图1 所示。模型由七个部分组成:1)输入层:获取文本数据;2)预处理层:分词并去除无关数据;3)词嵌入层:把文本数据映射为词向量;4)Bi-LSTM 层:提取文本数据的上下文语义特征;5)Attention 机制层:生成含有注意力概率分布的加权全局语义特征;6)CNN 层:在加权全局语义特征的基础上进行局部语义特征提取;7)输出层:实现文本分类。
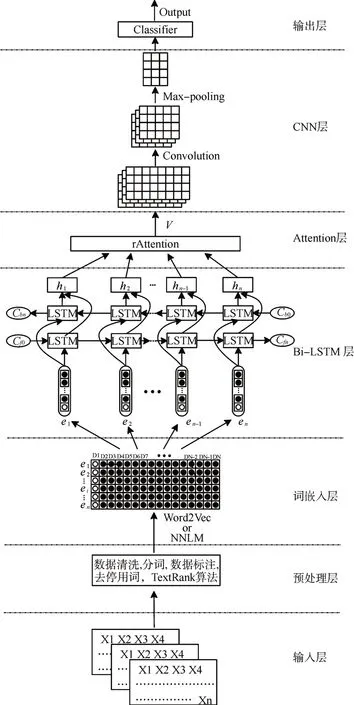
图1 TBLC-rAttention文本分类模型
2.1 预处理层
对文本数据按照以下方式进行预处理操作。
1)数据清,删除原始数据集中的无关数据、重复数据以及处理异常和缺失数据;
2)进行类别标签标注;
3)使用jieba 进行分词和去停用词,在分词的过程中可以使用一些领域专属名词以提高分词的准确度;
4)将预处理完成的文本数据分为训练集、测试集和验证集。
2.2 词嵌入层
词嵌入是把文本数据转化为计算机能够识别和处理的过程[12],如图2所示。
在这样的故事情节之中,小说的创作还体现出如下的特点:首先,小说具有欧·亨利特有的结尾方式。即,故事的结局既在人的预料之中又出乎人的意料。因而,它体现出了故事独有的幽默,体现出了小说主题特有的讽刺。其次,小说语言与众不同。在小说各种语言描写中,作者不仅通过巧妙的修辞增强了文学语言的意蕴性,还且通过对时弊的针砭产生了“含泪的微笑”。
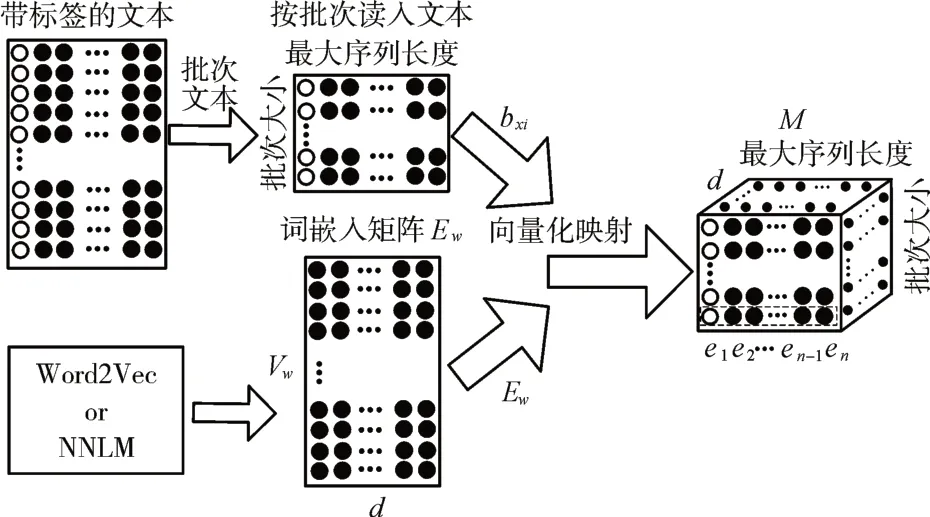
图2 文本数据向量化表示
通过词嵌入矩阵Ew的映射,把按批次读入带有标签的文本数据映射为一个三维词向量矩阵M,Ew可以通过Word2Vec 等方法得到。此时,一个包含n 个字的文本Dj=(x1,x2,…,xn)可以表示如下:
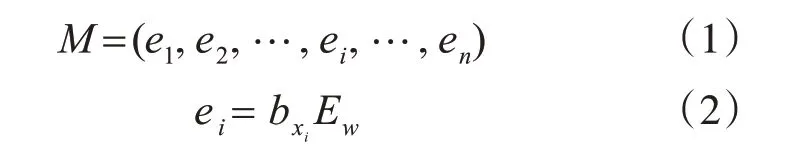
其中,M∈Rbatch×n×d,Ew∈Rvw×d,batch为每一批次读入的文本数据条数,vw为字典大小,d 为词向量维度,每个字在Ew中都有一个唯一的用于检索其对应词向量的索引bxi。
2.3 Bi-LSTM 层

2.4 Attention机制层
在Bi-LSTM 网络之后引入注意力机制[14~16],对重要的信息给予较多的关注,模型如图3所示。

图3 多注意力机制


其中,V∈Rbatch×r*n×2d为加权全局语义特征,a∈Rbatch×r*n×2d为注意力概率分布,r 为每个文本的Attention 方案数,Wa1∈Rd×n是全局注意力权重矩阵,ba为全局注意力偏置矩阵,wa2∈Rr*n×d为每个文本不同的Attention 方案矩阵,m 值越大说明了该时刻的全局语义特征越重要。
得到每一时刻的ai后,将它们分别和该时刻对应的hi相乘,得到第i 时刻的加权全局语义特征Vi。
2.5 CNN层
把V作为CNN的[17~18]输入进行局部特征提取,如图4 所示。每一次卷积都通过一个固定大小的窗口来产生一个新的特征,经过卷积后得到第j个文本包含局部和全局语义特征的Cj,接着采用最大池化方法得到每个文本的最终特征表示C。

图4 CNN模型
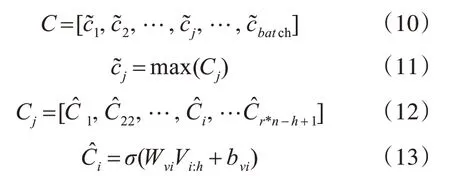
其中,C ∈Rbatch×2d,Cj∈R(r*n-h+1)×2d,Wvi∈R2d×h为卷积核向量,h 和2d 分别为卷积核窗口的高和宽,Vi:h表示第i行到第h 行的加权全局语义特征值,bvi表示偏置。
2.6 输出层
把C 作为分类层的输入,分类层采用dropout方式将最佳特征Cd连接到Softmax 分类器中,并计算输出向量p(y):
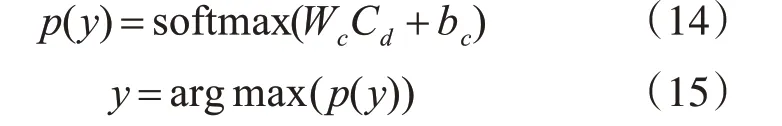
其中,p(y)∈Rbatch×classes,Wc和bc分别表示分类器的权重参数和偏置项,classes表示文本的类别数,Cd为C通过dropout产生的最佳特征。
分类器用于计算出每个文本属于每一类别的概率向量p(y),然后选择最大概率y对应的类型作为文本分类的预测输出,通过分类器层之后,整个模型就实现对文本的分类任务。
3 实验
3.1 实验语料
语料数据是利用爬虫技术爬取某电商平台上一种感冒药销售的评论数据,语料的一些基本信息如表1、图5和图6所示。
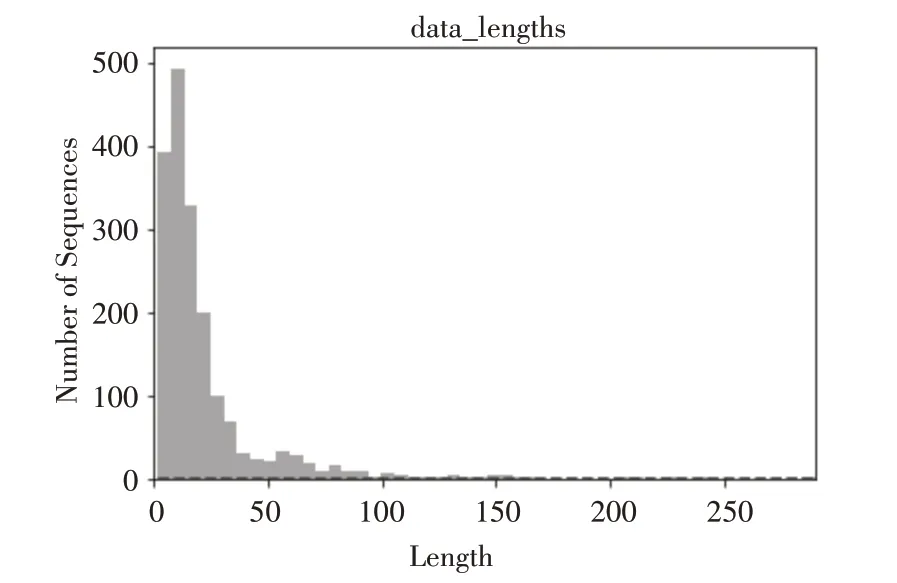
图5 语料句子长度分布

图6 语料词云图

表1 语料数据信息
3.2 实验设置
具体实验设置如表2和表3所示。
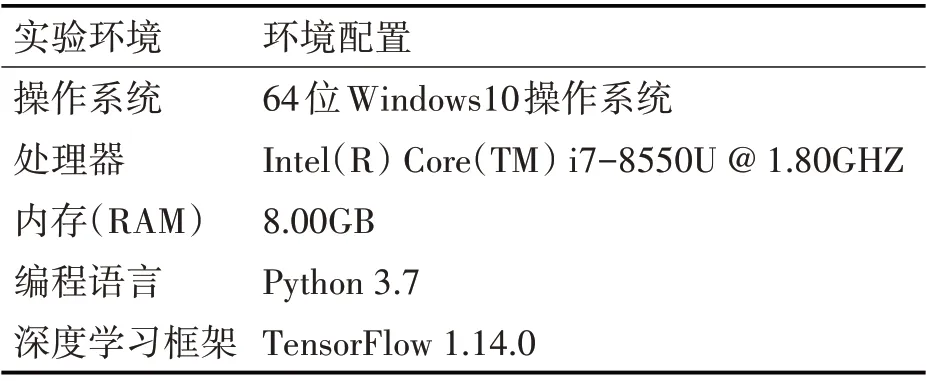
表2 实验环境
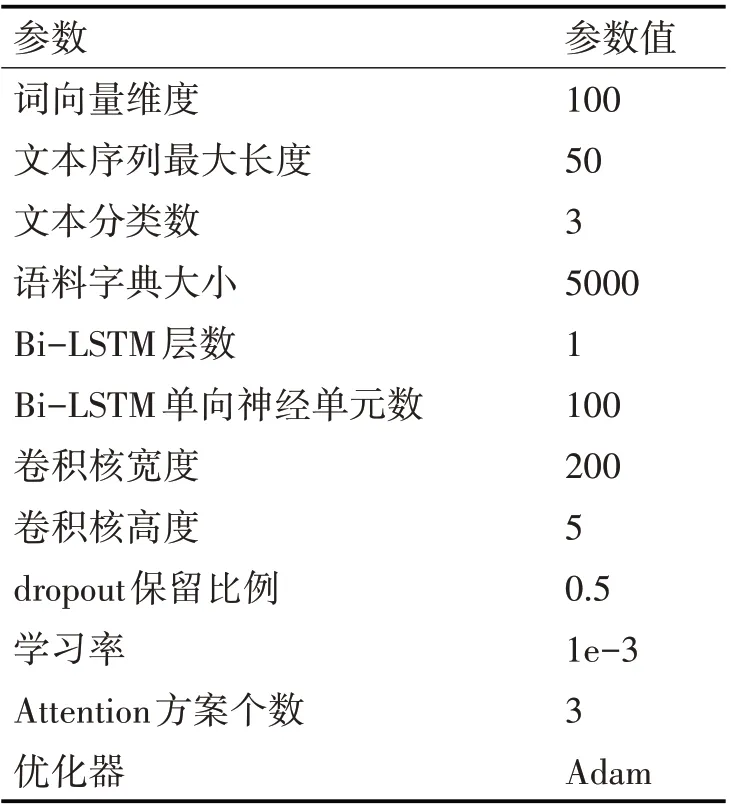
表3 实验参数设置
3.3 模型训练

其中,θ为模型当前参数,α为学习率,N 为训练样本大小,D 是训练样本,L是样本D 对应的真实类别标签,Li∈L,y 为分类器的预测分类结果,p(Lj)表示正确分类结果,λ是L2正则项系数。
3.4 评价指标
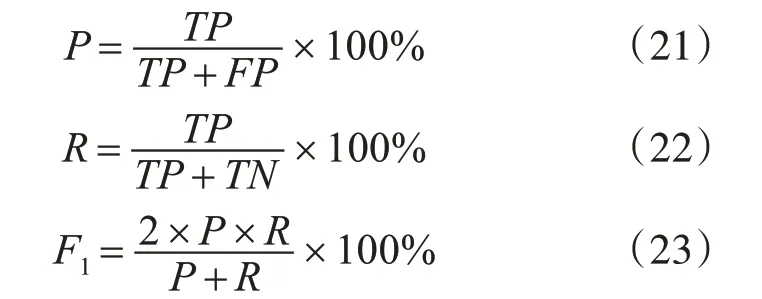
其中,TP 为真正率,TN 为真负率,FP 为假正率,FN为假负率。
4 结果与讨论
模型训练过程的准确度和损失值变化如图7所示,为了比较本文提出的模型性能,选取了CNN、LSTM、Bi-LSTM、BiLSTM+Attention、RCNN 5 种模型作为比较基准,比较结果如表4 所示,所有结果都是在训练的准确度和测试准确度都不再变化再循环1000次后得到的结果。
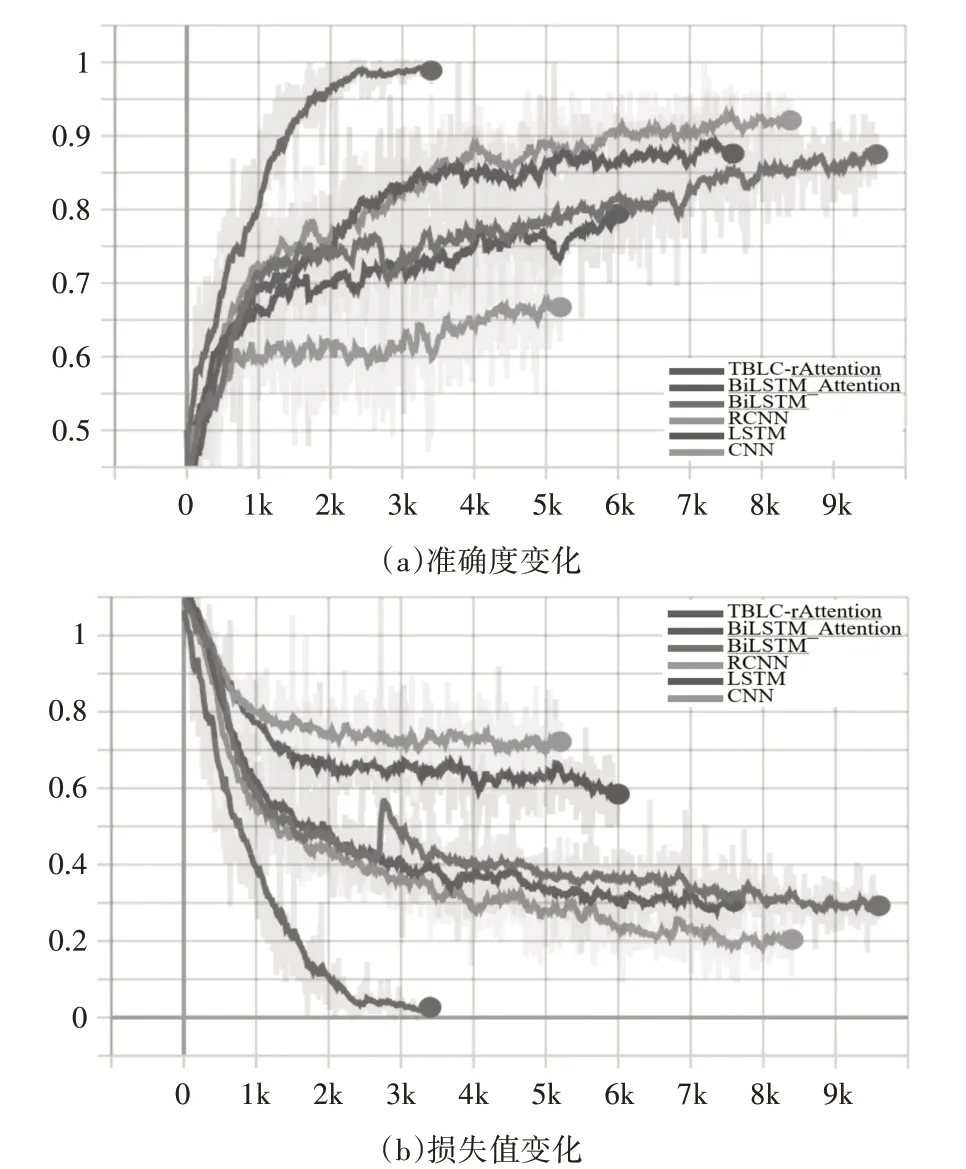
图7 训练过程中个模型的准确度和损失值变化
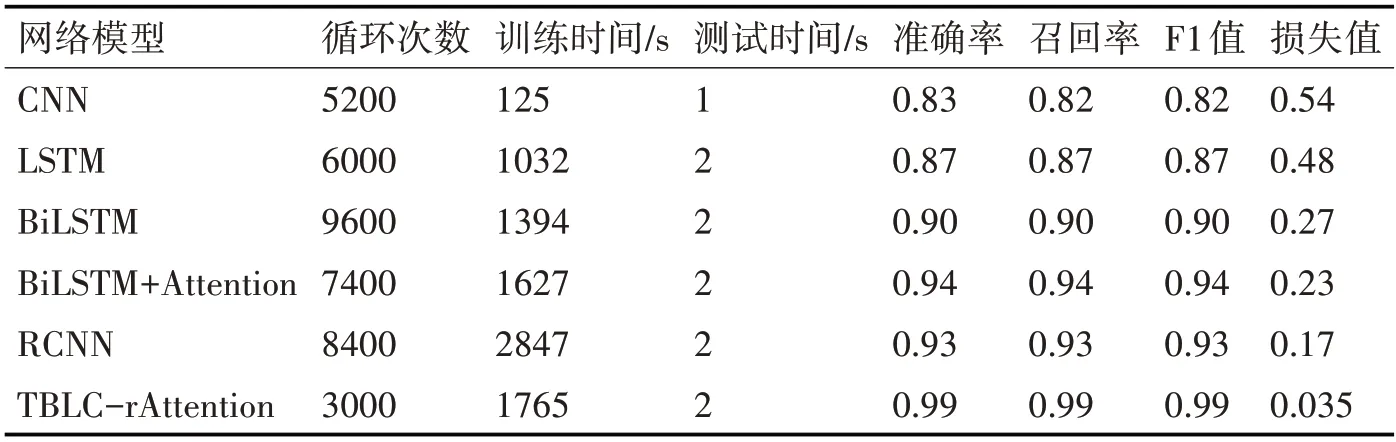
表4 各文本分类模型分类效果对比
在表4 中,通过LSTM 和Bi-LSTM 的实验结果可以发现,虽然Bi-LSTM 花费的时间比LSTM 多,但是准确度提高了约3%,这是由于Bi-LSTM 网络通过正向和反向两层网络结构来扩展单向的LSTM 网络的结果,这样的网络结构可以充分提取文本的上下文信息,但是空间复杂度是LSTM 的2倍,所以花费的时间比LSTM 略长;在Bi-LSTM 模型中引入Attention 机制准确度提高了4%左右,说明Attention 机制的确可以有效识别出对分类影响较大的特征信息;只使用CNN 时,虽然准确率不是最好的但大大的节省了训练时间;RCNN 汲取了RNN 和CNN 各自的优势,分类效果比单独使用RNN、CNN 都好,与BiLSTM+Attention 效果相近;本文提出的模型分类准确率达到了99%,在本次实验的所有模型中分类准确度最高,模型在验证时以100%的准确率实现了数据分类,值得注意的是当消费者没有进行评论,电商系统会默认为好评,但模型将这类数据视为中评。
5 结语
本文提出了一种基于混合深度神经网络的网络舆情识别方法,该方法先提取文本数据的上下文语义特征,再提取局部语义特征得到最终的特征表示,并通过实验验证了本文提出模型的有效性。未来的工作是如何对语料数据进行更好的预处理操作,例如进一步减少噪声数据、更好地进行精准分词等;同时,研究其他算法和模型,并进行有效的融合和改进,进一步提高分类的准确度。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
科海故事博览·下旬刊(2022年4期)2022-05-07
电子产品世界(2022年4期)2022-04-21
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
软件导刊(2017年4期)2017-06-20
科学与财富(2016年30期)2017-03-31
价值工程(2016年32期)2016-12-20
考试周刊(2016年34期)2016-05-28
