
基于K-LSTM-ecm模型的城市轨道交通短时客流预测
2022-05-26 13:00王金锋孙连英
制造业自动化 2022年5期
王金锋,孙连英,张 天,涂 帅
(1.北京联合大学 城市轨道交通与物流学院,北京 100101;2.北京联合大学 智慧城市学院,北京 100101)
0 引言
我国正在经历世界历史上规模最大、速度最快的城镇化进程,随之也带来了新的问题,日益加剧的交通拥堵和环境污染困扰着人们。轨道交通作为准时、大运量的出行方式是解决城市交通问题的重要手段[1]。因城市轨道交通系统客流具有明显的时效性,成为人们出行主要手段,也造成高峰时刻客流量过饱和的问题,影响城轨交通运营安全可靠性。如何采取有效的方式对客流量过大造成的隐患进行有预见性的运营规划和安全防护,关键技术在客流预测[2],通过挖掘客流特征实现城市轨道交通客流短时预测,可以为制定更加准确科学的运营方案以及提高运营服务水平提供有效的解决途径。
应用于城市轨道交通客流预测的模型主要包括计量模型以及人工智能模型。常见的计量模型如:卡尔曼滤波(Kalman)模型[3]、自回归滑动平均模型(Autoregressive Moving Average Model,ARMA)[4]。回归模型对于刻画中长期客流的变化趋势有良好的效果,然而对数据中出现的随机变化敏感度不足,难以精准进行随机性较高的短时客流预测。而应用支持向量回归模型(Support Vector Regression,SVR)[5]、神经网络(Back Propagation,BP)[6]等人工智能模型对客流数据拟合程度更高,通过自身学习能力以及自适应能力可以更好捕捉非线性规律从而提升预测精度,但对描述输入与输出之间联系的能力有限,参数的训练过程也相对较慢。其中,中长短期记忆网络(Long Short-Term Memory,LSTM)[7]在处理时序性数据的时间特征时有很好的效果,能够处理长间隔跨度数据有效信息消失的问题。但单一使用LSTM进行短时客流预测仍存在一定的局限性。因此,本文构建了K-means聚类、LSTM以及误差修正模型(ErrorCorrection Model,ecm)结合的K-LSTM-ecm的城市轨道交通短时客流预测模型。
1 K-LSTM-ecm模型构造
1.1 K-LSTM-ecm模型
本文以LSTM模型作为主模型,在此基础上增加K-means聚类以及误差模型构建城市轨道交通短时客流预测模型。LSTM模型首次发表于1997年,其独特的设计结构适用于处理时间序列性数据,对预测时间序列中的长间隔和延迟有很好的处理效果,LSTM模型在预测问题上的表现优于时间递归神经网络(RNN)以及马尔科夫模型(HMM)。作为非线性模型,LSTM模型适用于预测客流数据这种非线性数据[8]。本文提出的K-LSTM-ecm模型通过以下流程实现城市轨道交通短时客流预测。
1)基于客流数据的短时间随机性、长期周期性以及同类型临近站点的空间客流分布,构建前d天q个历史客流数据的数据集合,利用LSTM模型对时序性数据的敏感性,对预测目标站点及其同类型相邻站点的时间、空间关系进行提取。
2)探究预测目标站点及其同区域相邻站点工作日、非工作日(节假日、周末)客流特点,以单个时段客流数据作为样本点,采用K-means算法进行聚类分析生成聚类标签,将最终聚类后的数据作为主模型的输入数据。
3)将第一次LSTM模型输出的y-pre作为ecm模型输入,对y-pre进行协整分析,以发掘第一次预测值与真实值之间的协整关系,并构成误差修正项建立ecm模型。将误差反馈到LSTM模型,最终实现城市轨道交通短时客流预测。K-LSTM-ecm模型框架如图1所示。

图1 K-LSTM-ecm模型框架
1.2 输入数据构造
城市轨道交通在网络化运营条件下,不同区域站点有不同的客流特点,可分为居住密集型、岗位密集型、混合型和枢纽型4类[9],同类型临近站点之间的客流分布相互影响。城市轨道交通网络化运营导致了客流不仅受本站历史时段客流量的影响,还会受相邻站点客流分布的影响,因此构建输入数据时不仅要考虑预测目标站点的历史客流数据时间特征,还要考虑同类型区域相邻站点客流的空间分布特征,以达到更好描述目标站点客流特点的效果,从而提升预测精度。
将目标站点定位为N(1<N,n=1,2,3,…,N),用XNT,t表示目标站点T天第t时刻的客流量,由于同类型临近站点客流特点具有相似性,输入数据按空间位置关系将相关站点表示为XN-nT,t。对于N站点的T天第t时段的客流预测来讲,由于客流具有连续性,输入的客流数据应考虑其前q个时段的客流量以及前d天的连续性客流量,故模型输入数据集如式(1)表示:

1.3 工作日与非工作日聚类分析
城市轨道交通作为市民的出行首选交通方式,其客流分布与市民的出行模式相关,不同车站所处位置在一定程度上能反映其客流规律,如:在居住密集型区域地铁站,受乘客们的出行目的影响,工作日与非工作日(节假日、周末)的客流时段分布差异较大。工作日期间,绝大多数乘客都是通勤乘客。客流潮汐式分布十分明显,表现在高峰时期客流量巨大,早高峰时段进站乘客数量远多于出站乘客数量,晚高峰与之相反。客流在工作日期间分布具有显著的突峰特征,早高峰客流出现峰值。
非工作日期间,乘客出行目的区别于工作日,会出现一定商务客流、出行客流等,因而客流分布与工作日有所区别。节假日和周末客流无工作日的潮汐式分布,全天各时段进站乘客数量较为均衡,无明显低谷,一般呈全峰型分布。同时,节假日和周末的客流分布具有相似性。
为进一步量化工作日和非工作日单日客流量之间的相似性,本文选取Pearson相关系数对于客流数据进行相关性分析,其能够精准地表达数据之间的数量关系,从而达到定量分析和比较。结果如表1所示。

表1 工作日和周末客流相关性分析

图2 工作日进站客流分布
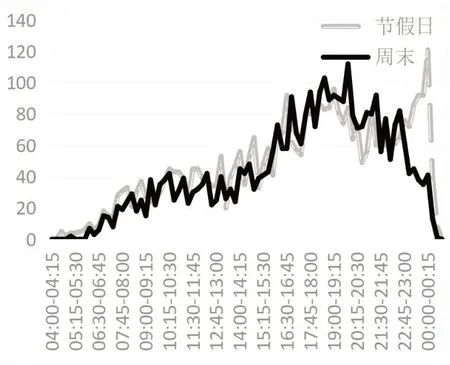
图3 节假日与周末进站客流分布对比

表2 周末和节假日客流相关性分析
由上表,周一至周五单日客流之间均呈强相关性,周六和周日客流数据之间同样呈强相关性,而工作日数据和周末数据呈中相关性,究其原因,周末的客流组成区别于工作日的客流,客流随机性更强,故导致该结果;周末和节假日数据之间呈强相关性,但其系数表现上与其他强相关数据比略低。
通过上述相关性分析结论,工作日期间单日客流量相似性极强,非工作日同工作日一样,为进一步提升短时客流预测精度,本文采用K-means聚类算法对客流数据进行聚类并生成聚类标签。K-means聚类的无监督分类方法可以无监督地探索客流数据的内部结构特征,将具有较强相似性的数据划分为相似的数据集。因此,本文采用K-means聚类算法将采集到的客流数据划分为工作日和节假日聚类集,不同类别间数据相似度越小越好。相似的通过样本之间的距离表示,两个样本之间距离越小,说明样本之间相似度越高,反之,说明相似度越小。对于样本之间距离的计算通常通过欧式距离计算二维空间,高维度空间多采用马氏距离和曼哈顿距离等。欧式距离计算公式如下:

K-means聚类算法基本计算思想:
首先对有n个数据点的数据集从n个数据点中随机选取k个点作为初始聚类中心,再通过欧氏距离计算对靠近各聚类中心的数据进行分类,采用迭代的方式,在上述过程中不断更新聚类中心点,直至整体达到稳定的状态,获得聚类中心C。
K-means聚类算法计算基本步骤:
1)输入一个数据集,确定聚类中心数目k;
2)在数据集中随意生成k个初始聚类中心;
3)计算聚类中心点与其他数据点的距离,取距离最小值;
4)计算同一聚类中所有对象的均值并加以统计,将计算结果更新替换为新的聚类中心;
5)重复上述步骤,直至结果稳定,聚类中心不再变化,输出。
1.4 LSTM模型
LSTM模型在RNN结构基础上,添加了各层的阀门节点。LSTM结构如图4所示,其结构由遗忘阀门(forget gate),输入阀门(input gate)、输出阀门(output gate)以及细胞状态组成。

图4 LSTM神经元结构
这些阀门可以打开或关闭,用于判断模型网络的记忆态(之前网络的状态)在该层输出的结果是否达到阈值,从而加入到当前该层的计算中,阀门节点利用Sigmoid函数将网络的记忆态作为输入计算;如果输出结果达到阈值则将该阀门输出与当前层的的计算结果相乘作为下一层的输入;如果没有达到阈值则将该输出结果遗忘掉。每一层包括阀门节点的权重都会在每一次模型反向传播训练过程中更新。具体计算过程如式(3)~式(8)所示:

其中,W表示输入向量与输入阀门、输出阀门等之间相对性的权向量,b为偏置变量。
1.5 ecm模型
误差修正模型(ecm)是1978年由Davidson等提出的表示变量之间的一种长期均衡关系的模型,这种均衡关系可能会在短期内出现波动或者偏离这种均衡关系[10]。该模型通过对误差的修正,可以使变量重返均衡状态。不仅考虑到了短期波动,还兼顾长期趋势影响,对于城市轨道交通客流预测模型有良好的修正效果,其表达式如式(9)所示。

其中,λ1、λ2为各变量差分项的系数,反映了模型短期的动态变化;φ为修正系数,也称调整速度,通常为负值;ecmt-1为误差修正项;c为模型的常数项。
2 案例分析或实证分析
2.1 实证数据
本文以北京地铁回龙观站为预测目标站点,该站位于北京市大型社区回龙观地区的核心位置,是典型的居住密集型区域地铁站,日常客流潮汐现象明显且客流量巨大,并呈现非线性特征。本文选取北京地铁AFC客流数据作为K-LSTM-ecm模型的输入数据集。选取4:00到第二日00:30作为预测时段,进行数据预处理,除去重复值与异常值。选取15min为一个间隔,每日84个统计时段,以便于指导站点实际运营管理以及紧急情况预警。
3.5 金属蛋白酶结构域10(ADAM10) 去整合素和ADAM10是APP剪切的主要α分泌酶,能阻止Aβ产生[27]。ADAM10过表达能预防淀粉样病变和提高长时程增强作用及学习记忆功能[28]。ADAM10中罕见的编码变体与晚发家族AD相关。没有关于ADAM10与自噬和AD相关的报道,但最近一则报道指出在内皮细胞中ADAM10可以被自噬调节,反过来调节小鼠对内皮ADAM10相关疾病状态的敏感性[29]。因此,有可能ADAM10在神经元和神经胶质细胞也可以被自噬调节。神经元和胶质细胞ADAM10的自噬调节及AD相关的ADAM10变体对自噬的影响需要在将来的研究中得到阐明。
依据地铁站所处区域属性相同,客流分布相似的特点,选取同区域邻近地铁站霍营站和龙泽站。为直观地分析所选三个站点的客流分布规律,随机选取一天三个站点的进站客流进行对比,如图5所示。
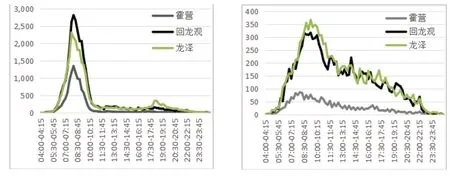
图5 同类型区域站点全天客流对边图(节假日、工作日)
可以看出,所选三个同区域相邻站点工作日出站客流分布曲线整体相似性强,由于回龙观站所处于居住密集型区域,主要客流为通勤客流,进站客流量分布呈现早高峰时段(8∶00-10∶00)客流激增的情况,而晚高峰时段(5∶00-21∶00)并未出现客流激增的特点,客流峰值出现在8∶30-8∶45时段;节假日客流相比工作日客流分布较为均衡,在19∶00-19∶15时段三站出站客流均呈平缓上升趋势。故选取地铁龙泽站、回龙观站以及霍营站的客流数据为模型输入数据集。
2.2 时段选择选择
预测规定站点的客流量受前q个相邻时段客流数据影响,不同q值会影响预测精度,为确认合理q值,本文根据地铁站客流分布规律、客流的周期性以及每日运营时段数设计实验,分别选择q=5、10、15、20,以回龙观站历史客流数据为训练数据集,最大训练迭代次数为10进行试验,以标准差(RMSE)作为判断依据。q值取5、10、15、20时模型标准差如表3所示。
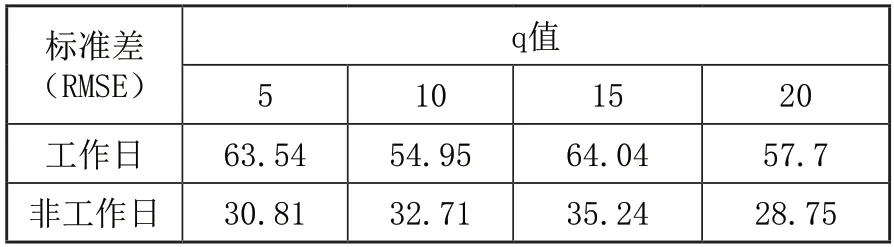
表3 q取不同值的标准差
由实验得出结论,当q值取10时,标准差最小,因此工作日预测结果较为精准。也就说明对预测当前时段客流量,前5个时段客流量与预测时段客流量联系紧密;而非工作日的客流分布波动相对平缓,标准差值相差不大,其中q值取20时标准差最小。在后续实验中设定工作日q值取10,非工作日q值取20进行模型性能实验。
2.3 实验模型训练流程
本节以地铁回龙观站进站客流为例进行预测,构建K-LSTM-ecm城市轨道交通短时客流预测模型进行实验,其实验参数设置为包含一个输出层、两个隐含层和一个输出层,输入层神经元个数为5,隐含层的节点数为(100,100)输出层神经元个数为1。工作日q值取10,非工作日q值取20。
K-LSTM-ecm模型训练流程如下:
1)将三个站点客流数据进行K-means聚类并生成标签;
2)将聚类后的客流数据划分为训练集和测试集;
3)将LSTM神经网络模型网络权重及其参数进行初始化处理;
4)选取ReLU函数为激活函数,并向前传播输出单个神经元输出值;
5)选取平方损失函数为损失函数,并向后传播误差值;
6)计算梯度;
7)采用Adam函数为优化函数,更新参数;
8)输出预测结果到ecm误差补偿模型,计算误差,输出误差到LSTM神经网络;
9)输出预测结果。模型训练流程如图6所示。

图6 K-LSTM-ecm模型训练流程
为了后续实验的公平性及准确性,对照模型K-LSTM模型与LSTM模型的参数取值与K-LSTM-ecm模型一致。
2.4 模型性能分析
本文选取北京地铁龙泽站、回龙观站以及霍营站历史客流数据集验证K-LSTM-ecm模型效果,数据集为2020年9月1日至10月8日全天出站客流数据,数据总量为9577条,其中每条数据包含4个输入数据,主模型输入数据为同一天预测时段前q个时段客流数据、同类型站点同时段客流数据、日期数据以及工作日、节假日聚类标签数据,输出数据为当前时段的预测客流数据。为保证模型稳定性,提升预测精度以及模型训练速度,将输入数据归一化处理。划分2020年9月23日至10月8日为测试集,其余为训练集。使用python语言进行建模。为验证模型选取LSTM模型、K-LSTM模型进行对比。预测结果如图7、图8所示。

图7 工作日预测结果

图8 节假日预测结果
由预测结果显示以及进站客流的结果图可知,客流受时间因素较大,进站客流同真实客流一样呈现集中现象,主要集中在早高峰数段7:00-9:30。对于非工作日真实客流所展现的客流波动性,LSTM模型波动时段与真实客流不符,K-LSTM模型客流波动范围相较K-LSTMecm模型与真实客流有所差异。故客流除LSTM短时客流预测模型效果不理想,K-LSTM模型与K-LSTM-ecm模型都对未来客流进行有效预测。但对客流随机性波动K-LSTM-ecm模型直观上看效果更优,与真实客流量曲线趋势更加贴近。为更精准对比预测结果,本文选取RMSE、MAE、MAPE作为模型评价指标,以验证模型有效性,结果如表4所示。

表4 模型评价指标
由上表数据可知,本文构建的K-LSTM-ecm模型在三个评价指标表现上均优于单一的LSTM模型与未采取误差补偿模型的K-LSTM模型。
3 结语
对于城市轨道交通的客流预测,现有研究对于历史客流数据的时间特征有很多理论成就,而对于空间特征多是考虑整体地铁路网的空间关系,为更加细化空间特征,本文根据地铁站同类型相邻原则构建考虑时空特征的K-LSTM-ecm模型,进一步提升预测精准度。为更精准预测客流,本文设计实验,选取q个临近历史客流量,结果表明:预测当前时段的客流时,工作日前10个时段客流数据影响最大,而节假日则受20个时段客流影响。为进一步证明K-LSTM-ecm模型效果,设计对比实验,将模型与LSTM模型与K-LSTM模型进行直观的折线图结果比较与评价指标比较,研究表明,在进行K-means聚类生成聚类标签,实现了对历史客流数据集客流特征的细化,更加有效的描述了客流特征且提高了预测精度。实验结果显示K-LSTM-ecm模型优于LSTM模型与K-LSTM模型,进而验证了模型的有效性。
猜你喜欢
环球时报(2022-12-12)2022-12-12
现代电子技术(2021年15期)2021-08-06
科学家(2021年24期)2021-04-25
大连交通大学学报(2020年5期)2020-10-17
数学大王·中高年级(2019年5期)2019-06-09
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
湖北函授大学学报(2018年6期)2018-05-23
理论观察(2018年1期)2018-03-24
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
