
基于改进YOLO v5的夜间温室番茄果实快速识别
2022-06-21 08:21张亦博龚健林赵昱权吴若丁
农业机械学报 2022年5期
何 斌 张亦博 龚健林 付 国 赵昱权 吴若丁
(1.西北农林科技大学水利与建筑工程学院, 陕西杨凌 712100;2.西北农林科技大学旱区农业水土工程教育部重点实验室, 陕西杨凌 712100)
0 引言
我国既是番茄出口大国又是消费大国,在日光温室内对番茄进行实时监控并利用采摘机器人不仅降低人工成本,同时又能提高效率,节省时间,对于番茄培育具有重要意义[1-2]。但目前夜间环境下光线复杂,果实与叶片重叠在昏暗光线下进一步对采摘机器人与监控设备的识别造成了困难。
日光温室内番茄果实的传统识别方法主要依靠颜色空间的差异与形状对图像进行分割,随着计算机技术与机器视觉技术的发展,深度学习也应用到了番茄果实的识别方法中[3-11]。综上所述,图像分割等处理方法对于番茄识别的精度较低,卷积神经网络(CNN)等方法实时性较差,基于深度学习的识别算法虽提高了实时性与精度,但面对夜间复杂环境下的各种影响因素考虑不全,难以满足实际要求。
随着以卷积神经网络为代表的深度学习不断地发展,目标检测已经广泛地运用到了各个领域。目标检测算法可以分为两类,第一类是基于region proposal(候选区域)的R-CNN[12]系列算法,如:R-CNN、Fast R-CNN[13]、Faster R-CNN[14]等。该类算法通过两个步骤进行计算:选取候选框;对候选框进行分类或者回归。此类方法鲁棒性高,识别错误率低,但运算时间长,占用磁盘空间大,对图像信息进行重复计算,不适合进行实时检测。第二类是如YOLO[15]、SSD[16]等网络模型的one-stage算法[17]。该类算法是采用不同的尺寸对图像进行遍历抽样,然后利用CNN提取特征后直接进行回归[18]。该类方法识别速度快,实时性强,但由于网络模型简单,识别率低于第一类方法。SSD神经网络运行速度略低于YOLO,检测精度略低于Faster R-CNN,但鲁棒性较差,需要人工设置各种参数阈值,且先验框无法通过学习获得,需要手工设置,对于小目标存在低级特征卷积层数少,特征提取不充分的问题。YOLO系列网络以YOLO v5为代表,由于平衡了速度快的特点,丧失了部分精度,因为没有进行区域采样,所以在小范围的信息上表现较差,具有识别物体位置精准性差、召回率低等问题。研究表明[19],由于第二类目标检测方法实时性强,有利于提高采摘机器人及监测设备的工作效率,适用于复杂环境下实时的目标检测。
本文基于改进YOLO v5目标检测算法,根据夜间日光温室下复杂环境情况,采用YOLO v5快速精确的检测结构,融合多尺度信息模型,通过数据增强等方法提高检测精度,构建一种可在移动设备下实现夜间复杂环境的番茄本体特征识别的网络模型。并通过与其他算法的对比,验证本网络模型的实时性与准确性,以期为采摘机器人与实时检测设备系统设计提供参考。
1 番茄图像数据采集
番茄图像数据采集自西北农林科技大学园艺场节能型日光温室,番茄植株采用吊蔓式栽培方法。图像采集设备为佳能EOS-750D型相机,采用CMOS传感器,APS画幅(22.3 mm×14.9 mm),采集番茄果实、叶片、花卉、秆茎4类RGB图像共2 000幅用于数据训练及测试,RGB图像分辨率为4 000像素×6 000像素。由于模拟日光温室内夜间环境下采摘机器人夜间视觉系统,采集过程中在图像采集设备一侧设置对角光源[20],如图1所示。为了避免由于样本数据多样性不足导致的过拟合现象,考虑夜间环境下暗光区域以及阴影区域,图像数据分为正常采样与暗光采样两种情况,如图2所示。图像样本中对红色成熟番茄果实与绿色未成熟果实两种情况进行区分,同时也对不同果实数量、不同枝叶遮挡程度进行区分以增加样本多样性。图3为夜间环境下番茄果实图像。

图1 夜间照明设备图Fig.1 Night lighting diagram

图3 夜间环境下番茄果实Fig.3 Effects of night environment on tomato fruit
为了保证数据参数的准确性,在数据训练前需要人工标注数据,标注时将番茄各器官的最小外接矩形作为真实框,以此减少框内背景上的无用像素。本研究的数据训练基于pytorch框架,使用线性增强技术降低出现样本不均匀的概率,即在不改变原有数据特征的情况下对原有数据进行图像处理,无需增加原始数据量,采用的数据增强手段主要有:①翻转。对图像进行90°翻转、水平翻转以及随机(0°~180°)旋转,模拟检测过程中图像抓取的随机性。②缩放。按照一定比例缩放图像尺寸,模拟检测过程中受距离影响的图像尺寸不同。③颜色抖动。改变图像的饱和度与亮度,模拟夜间环境下不同亮度差异。④添加噪声。对数据图像添加椒盐噪声和高斯噪声,模拟拍摄过程中的噪声,同时降低高频特征防止出现过拟合现象。通过数据增强技术后得到新的数据样本量,共计9 042幅。其中70%用于数据集训练,15%用于数据集验证,15%用于数据集测试。
2 基于YOLO v5的番茄识别网络
2.1 YOLO v5网络模型
YOLO v5是一种单阶段目标检测算法,该算法在YOLO v4的基础上添加了新的改进思路,使其速度与精度都得到极大的提升。YOLO v5网络模型主要分为输入端、Backbone基准网络、Neck网络、Head输出端4部分。输入端:包含一个图像预处理阶段,将输入图像缩放到网络的输入尺寸,并进行归一化等操作,操作方法为Mosaic数据增强操作、自适应锚框计算与自适应图像缩放方法。基准网络:通常是一些性能优异的分类器的网络,该模块用来提取一些通用的特征表示。YOLO v5同时使用了CSPDarknet53结构与Focus结构作为基准网络。Neck网络:使用SPP模块、FPN+PAN模块位于基准网络和头网络的中间位置,利用此两个模块进一步提升特征的多样性及鲁棒性。Head输出端:用来完成目标检测结果的输出,包含一个分类分支和一个回归分支,利用GIOU_Loss来代替Smooth L1 Loss函数,增加了相交尺度的衡量,从而进一步提升算法的检测精度。
2.2 多尺度特征提取
YOLO v5算法中使用Focus与CSPDarknet53特征提取网络获取多尺度图像特征,相比前期版本进一步消除网格敏感性,提高对于遮挡物体特征信息的拾取,优化小目标特征信息差异,提高识别精度。该算法首先以640像素×640像素的图像为输入进行切片操作,先变成320×320×12的特征图,切片过程如图4所示。
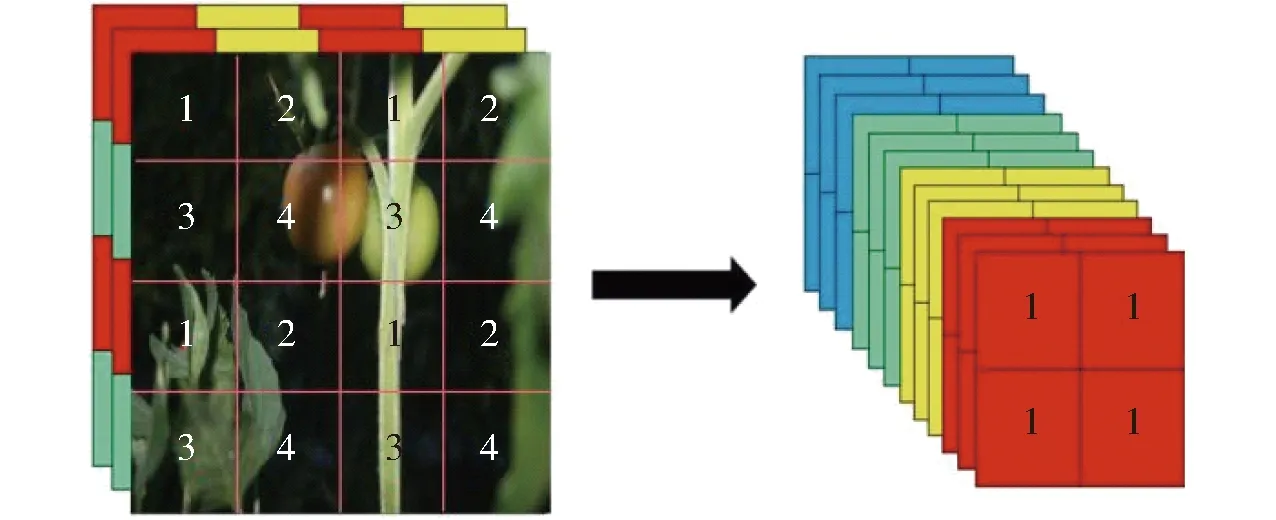
图4 切片操作演示图Fig.4 Slice operation demo
再经过一次卷积操作,最终变成320×320×32的特征图,该操作通过增加计算量来保证图像特征信息不会丢失,将侯选框宽W、侯选框高H的信息集中到通道上,使得特征提取得更加的充分。然后再分别进行32、16、8倍下采样,获得不同层次的特征图,然后通过上采样和张量拼接,将不同层次的特征图融合转化为维度相同的特征图,如图5所示。
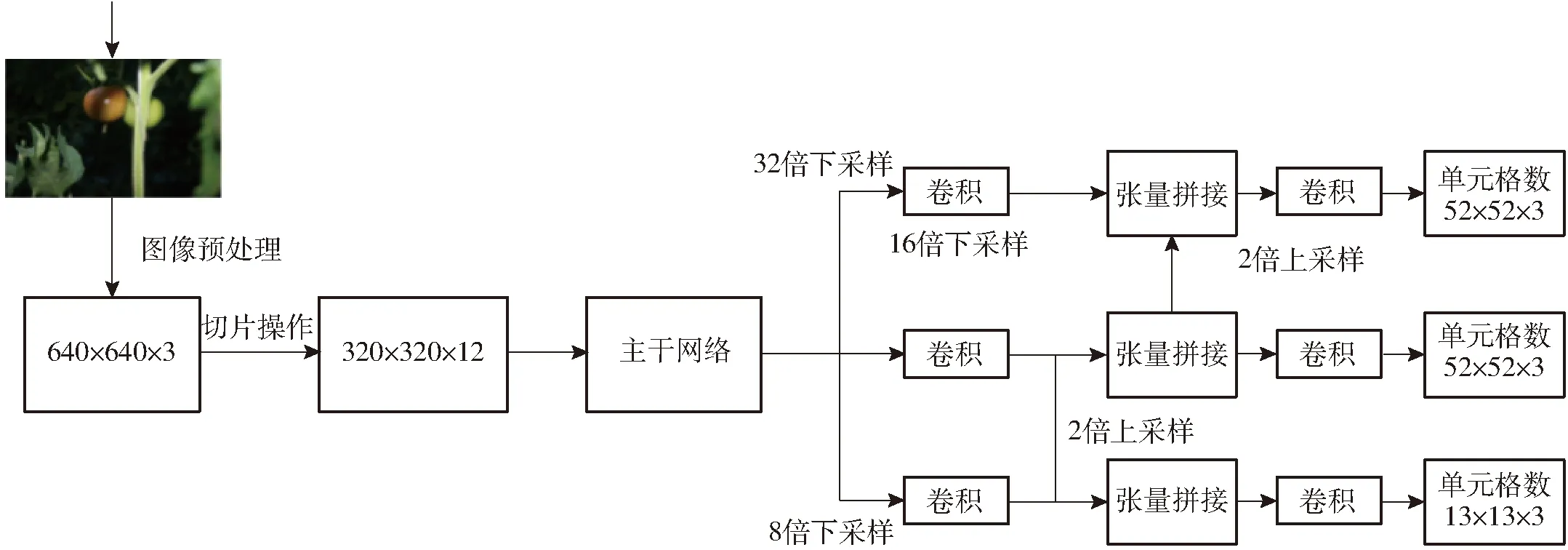
图5 Darknet53特征流程图Fig.5 Darknet53 feature flowchart
其解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和每秒浮点运算次数(FLOPS),既保证了推理速度和准确率,又减小了模型尺寸。鉴于本文检测红、绿两种果实的不同目标,Darknet53特征提取最终分别输出13像素×13像素、26像素×26像素、52像素×52像素3种尺度的特征图,分别作为远近景尺度视场内各目标回归检测的依据。
2.3 自适应锚定框
在YOLO v5中根据目标样本边框标注信息,采用K-means聚类算法预先设置先验框进行回归预测,并根据特征图层次进行分配,但K-means聚类算法可能收敛至局部最小值,无法给出最优解,对预测框造成误差。因此对YOLO v5中锚定框计算方式进行改进。在原始COCO数据集中,针对不同特征大小的检测框尺寸如表1所示。通过对原始检测框的检测效果分析表明,检测框数据不协调,候选检测框长宽比达1∶8,不利于训练效果,影响真实框预测结果[21]。因此通过anchor计算函数进行机器学习,迭代出每个步骤下的最优检测框尺寸,能够有效抓取小目标特征值,减小真实检测框偏离程度,并提高被遮挡物体的识别精度。重新计算检测框尺寸,设置聚类数为9,anchor与bbox比值为8,迭代次数为1 000次,通过YOLO v5自动学习确定锚定框的最优尺寸。

表1 原始数据集检测框尺寸分配Tab.1 Size allocation of original data set detection frame
表2为数据集中缩放至一定水平的最佳锚定框尺寸,并用该尺寸替换原始COCO数据集中锚定框尺寸。

表2 改进后检测框尺寸分配Tab.2 Improved size allocation of detection frame
2.4 损失函数改进
YOLO v5采用GIOU_Loss做Bounding box(目标位置)的损失函数,使用二进制交叉熵和 Logits 损失函数计算类概率和目标得分的损失,计算公式为
(1)
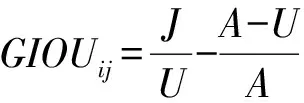
(2)
U=ii+ωihi-J
(3)
式中Losscoord——目标位置损失函数

J——边框交集面积
U——边框并集面积
A——边框最小外接矩形面积
ωi、hi——预测框高与宽
S——真实框与预测框最小外接矩形面积
β——真实框与预测框并集区域面积
当预测框和真实框重合时,GIOU最大取1,反之,随着二者距离的增大GIOU趋近于-1,即预测框与真实框距离越远时损失值越大。但当预测框与真实框出现包含关系或出现宽和高对齐的情况时,差集为0,则损失函数不可导,无法收敛,容易对遮挡情况下物体进行漏检。因此本文采用考虑到预测框中心点欧氏距离和重叠率参数(CIOU)的损失函数作为预测框偏差的偏差指标[22],如图6所示。图中(ωgt,hgt)、(ω,h)分别表示预测框和真实框的高与宽,b、bgt分别表示预测框和真实框的中心点,ρ表示两个中心点间的欧氏距离,c表示最小外接矩形框对角线距离。则有
(4)
式中α——权重函数
ν——真实框与预测框矩形对角线倾斜角的差方
则目标函数改进为
(5)
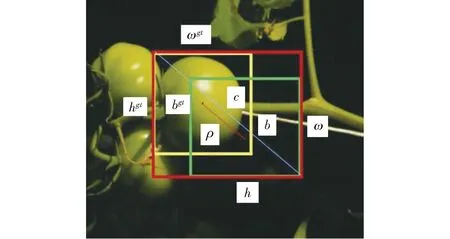
图6 损失函数CIOU边框图Fig.6 Loss function CIOU border chart
该目标函数增加了中心点距离度量,可以直接最小化两个目标框的距离,收敛速度大于GIOU损失函数,且考虑到差异化情形,避免了真实框与预测框包含关系时的不收敛情况,能够有效提高物体在遮挡情况下的识别率,优化了边框之间的相互关系。
3 网络模型训练
3.1 算法运行环境与参数设置
检测网络算法在深度学习框架中运行,硬件环境为Intel i5-9560处理器,16GB DDR4 2 400 MHz运行内存,显卡为GeForce GTX 1050Ti。软件环境为Windows 10操作系统下pytorch 1.8.1深度学习框架和CUDA 11.1并行计算构架。
COCO和VOC数据集上的训练结果初始化YOLO v5的网络参数,参数训练采用SGD优化算法,参数设置如下:图像输入尺寸为640像素×640像素,Batchsize为32;最大迭代次数为700;动量因子为0.9;权重衰减系数为0.000 5。采用余弦退火策略动态调整学习率,余弦退火超参数为0.1,初始学习率为0.001,采用CIOU Loss作为损失函数。
为了验证本试验方法的有效性,将改进YOLO v5、YOLO v5与CNN在数据集上进行试验对比。
3.2 训练过程与结果
采用YOLO v5s检测模块,100次迭代周期中损失函数如图7所示,前20次迭代周期中损失函数值明显减小,后经历80次迭代损失函数值逐渐稳定至0.03处小幅波动,则认为该检测网络模型稳定收敛。经过非极大值抑制(NMS)处理后得到的预测框分类中,将置信度大于阈值0.5的预测框定义为正样本,反之为负样本。
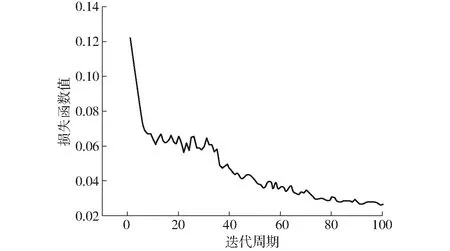
图7 损失函数曲线Fig.7 Loss function curve
选用检测网络性能的指标包括平均精度MAP、绿色果与红色果检测精度APG与APR、准确率P、检测时间t、召回率R及交并比(IOU)。主要衡量指标为平均精度MAP与检测时间t,反映了检测网络的准确性与速度,准确率P为被预测为正的样本中实际为正的样本概率,召回率R为实际为正的样本中被预测为正样本的概率,交并比IOU为预测框与真实框的重合程度。为了对比改进后网络模型的检测效果,将改进YOLO v5、YOLO v5与CNN网络模型进行比较。CNN网络模型选择Faster R-CNN网络模型,对于任意尺寸的图像,首先缩放至固定尺寸M×N,然后将图像送入网络,池化层中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3×3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposal,而ROI Pooling层则利用proposals从feature maps中提取proposals feature送入后续全连接和softmax网络做classification。Faster R-CNN网络模型训练包含5个步骤:①在已经训练好的model上,训练RPN网络。②利用步骤①中训练的RPN网络,收集proposals。③训练Faster R-CNN网络与RPN网络。④再次利用步骤③中训练好的RPN网络,收集proposals。⑤第2次训练Faster R-CNN网络,得到结果。
在训练过程中,对各类图像占比分两组进行统计。其中第1组根据果实遮挡率进行划分,果实遮挡率小于等于50%的图像共6 473幅,占比69%;果实遮挡率大于50%的图像共2 929幅,占比31%。第2组根据单果、多果进行划分,单果图像共4 012幅,占比43%;多果图像共5 390幅,占比57%。训练集、验证集、测试集检测指标结果如表3所示。为还原真实场景中叶片对果实遮挡的情况,根据叶片对果实的遮挡率进行划分,遮挡率计算方式为叶片遮挡果实部分的面积与果实总面积的比值。当遮挡率小于等于50%时,可认为叶片对果实的遮挡无影响,当遮挡率大于50%时认为叶片的遮挡对识别精度造成了影响,需要额外进行说明。
3种检测结果如表4所示。由表4可知,YOLO v5的MAP为93.4%,改进YOLO v5模型MAP为96.7%,提高了3.3个百分点,检测单幅图像时间均为10 ms,可以看出改进YOLO v5模型鲁棒性优于YOLO v5。改进YOLO v5模型绿色果检测精度和红色果检测精度分别较YOLO v5高0.5、1.0个百分点,可以看出改进YOLO v5模型因更换了损失函数,对于遮挡番茄果实预测率提高,因此模型的平均精度有所提高。同时改进YOLO v5模型的交并比IOU比YOLO v5模型提高了1.8个百分点,由此可以看出,使用计算函数anchor重新计算检测框尺寸并替换原有检测框尺寸能够有效提高交并比,提高检测模型的鲁棒性。

表3 训练集、验证集、测试集检测指标Tab.3 Test index results of training set, verification set and test set
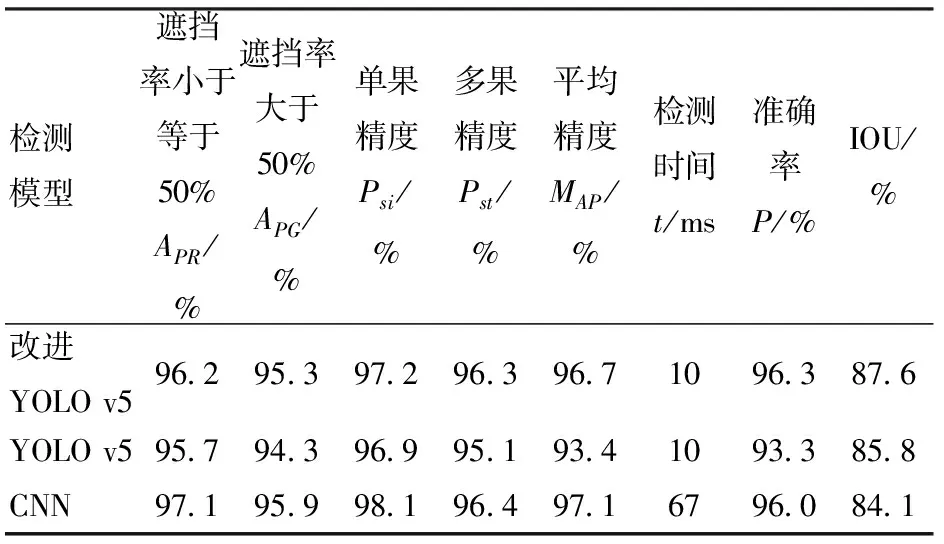
表4 3种模型各项检测指标Tab.4 Results of all test indexes of three models
另外,虽改进YOLO v5模型的平均精度略低于CNN网络模型,但改进YOLO v5的准确率与召回率均略高于CNN模型,果实遮挡率小于等于50%、果实遮挡率大于50%的差值与单果多果检测精度的差值均小于CNN模型,且检测时间为CNN模型的6.7倍,说明在保持准确率的情况下,改进YOLO v5模型的鲁棒性与实时性均高于CNN网络模型。又因为CNN模型的检测框利用滑动检测方式,因此交并比较改进YOLO v5低了3.5个百分点,说明改进YOLO v5对提取不同番茄果实特征信息与区分背景与目标信息的能力更为突出。
4 试验
4.1 材料与方法
为验证模型可靠性,2021年6月1日北京时间20:30于西北农林科技大学北校区园艺场番茄日光温室内进行现场试验,随机挑选250个区域进行数据采集,利用改进YOLO v5模型与YOLO v5模型编译的手机端应用进行番茄检测试验。
试验方法如下:①将两种网络模型的数据文件进行安卓端部署,生成手机检测APP。②在日光温室内随机挑选区域进行数据采集,为满足随机性,图像数据包含远近、遮挡等不同形态。③对采集数据进行人工识别,对不同颜色番茄果实,遮挡与未遮挡等特殊情况进行分类。④利用两种网络模型的手机应用对采集的图像数据进行识别,并与人工识别结果进行比对,分析模型精度。
4.2 YOLO v5安卓端部署
将YOLO v5模型训练后的Best.pt格式权重文件进行半精简转换为onnx格式文件,再将onnx文件使用腾讯NCNN平台编译为bin与param格式文件。利用Netron可视化工具对编译后的文件进行修改,去除原模型文件中的切片操作。最后使用Android Studio工具将修改后的模型文件写入Android系统生成应用软件。试验采用手机型号为Oneplus 8t,系统版本为Android 11.0。
4.3 结果分析

图8 2种模型手机应用的夜间果实检测效果Fig.8 Night fruit detection effects of two mobile phone models
为验证实际检测效果,使用改进YOLO v5与YOLO v5两种模型训练后生成的手机应用进行现场检测,如图8所示。并对检测结果进行统计。以人工识别的番茄果实结果为参考,分别对两种模型的检测结果进行对比与分析评价。2个模型分别对番茄红果、绿果的识别数量、识别总数量与人工识别数量的比值作为两个模型番茄红果、绿果的检测精度。统计结果如表5所示。

表5 2种模型各项检测指标
由表5可知,改进YOLO v5模型的番茄红果与绿果的识别精度较YOLO v5模型分别提高了1.4、1.8个百分点,总识别精度提高了1.6个百分点,对于遮挡情况下或多果重叠情况下改进YOLO v5模型识别率优于YOLO v5模型。为了验证复杂环境下的模型检测效果,对番茄绿果、红果的单果、多果以及遮挡、未遮挡进行统计区分。选取各种情况下样本数量50幅进行验证,成功识别数量与样本总量比值为识别率,结果如表6所示。由表6可以看出,在遮挡率不超过50%的情况下,番茄红果与绿果的单果识别率均可达100%。由于番茄绿果在夜间环境下颜色容易与叶片、秆茎等混淆,多果在重叠情况下边界条件区分较为困难,因此番茄绿果识别率及多果识别率略低于番茄红果。
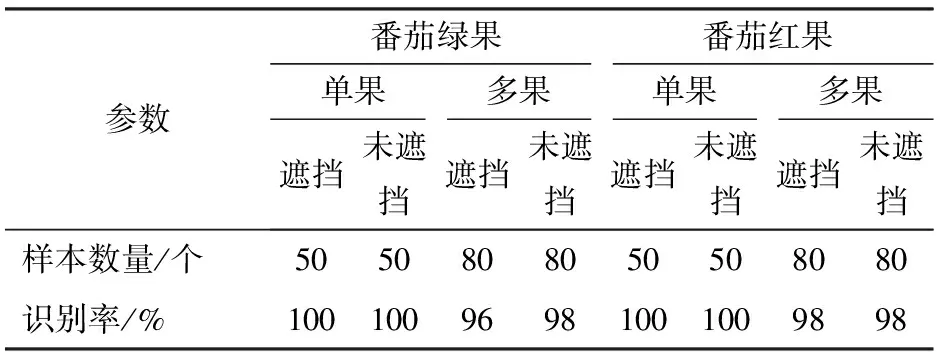
表6 复杂环境下番茄果实检测结果Tab.6 Detection results of tomato fruit in complex environment
5 结论
(1)提出了基于改进YOLO v5的识别网络模型对夜间环境下的番茄果实识别,使用计算函数anchor迭代出最优检测框代替原有方法,并修改原始数据中的目标检测损失函数,建立了夜间环境下番茄果实识别模型。改进YOLO v5的识别网络模型识别精度得到改善,MAP为96.7%,较YOLO v5的MAP(93.4%)提高了3.3个百分点。
(2)为验证模型的实际应用性,利用改进YOLO v5模型训练后的权重文件制作手机端应用软件进行现场检测。试验表明,改进YOLO v5模型检测精度较YOLO v5模型得到改善,针对夜间环境下绿色果实、红色果实及总果实精度分别为96.2%、97.6%和96.8%。
(3)改进YOLO v5模型对于多果重叠、遮挡等复杂情况下的番茄果实识别有显著的提升。在多果的遮挡情况下番茄绿果、红果识别精度分别达96%、98%,相比于YOLO v5网络模型鲁棒性更优。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
作文大王·笑话大王(2018年12期)2018-03-23
CHIP新电脑(2016年3期)2016-03-10
创新作文(5-6年级)(2015年9期)2015-10-21
红蜻蜓(2015年4期)2015-06-01
职业·中旬(2009年12期)2009-06-01
