
基于Faster R-CNN网络的茶叶嫩芽检测
2022-06-21 08:21朱红春杨海滨李振海
农业机械学报 2022年5期
朱红春 李 旭 孟 炀 杨海滨 徐 泽 李振海
(1.山东科技大学测绘与空间信息学院, 青岛 266590; 2.北京市农林科学院信息技术研究中心, 北京 100097;3.重庆市农业科学院茶叶研究所, 重庆 402160)
0 引言
中国的种茶面积和产茶量世界第一[1],是世界级茶叶大国[2]。茶叶采摘是其生产过程中的重要环节,采摘质量很大程度影响茶叶品质。目前人工采摘和机械采摘都是重要的茶叶采摘方式。但随着农业机器人传感技术及图像识别算法的提高,机械采摘对识别的准确率提出了更高的要求[3]。因此,在实现茶叶采摘机械化的过程中,如何有效识别茶叶嫩芽,以提高机械采摘的准确度,通过采摘路线规划以避免伤害茶树,是一个亟需解决的问题。
深度学习技术已经在农业方面得到了大量的研究应用[4-7]。但在茶叶方面研究较少,罗浩伦等[8]基于晴天和阴天自然环境下的茶叶图像数据集,通过Faster R-CNN网络模型和VGG16网络进行训练与测试,平均精度均值为0.76。施莹莹等[9]以自然环境下不同天气情况、不同茶叶品种的茶叶嫩芽图像为试验样本,采用基于深度神经网络的YOLO v3算法构建模型,研究了茶叶嫩芽目标的多尺度检测方法,平均精度为0.64。在研究基于图像处理方法的嫩芽识别方面,吴雪梅等[10]提出了基于图像的G和G-B分量信息,利用最大方差自动提取阈值识别茶叶嫩芽的方法,并研究了距离对识别精度的影响,相机距茶叶10 cm处准确率为92%;杨福增等[11]以G分量作为颜色特征,采用双阈值法分割背景与茶叶嫩芽,根据形状特征检测茶叶边缘,识别准确率达到94%。但由于背景过于复杂,现阶段茶叶嫩芽检测基本是限定在一个镜头较近并且包含少量芽头的小范围内,对于镜头较远包含芽头数量更多及类型多样、背景更复杂的场景下的嫩芽检测,还需开展深入研究。但此类场景下的研究,可为机械采摘中更大范围的路径规划提供指导,在采摘嫩芽的过程中避免损伤茶树。
相比于以往的R-CNN和Fast R-CNN,Faster R-CNN是真正的端到端的二阶段目标检测网络模型,通过分类器和位置回归任务共享卷积特征,解决了目标定位和分类的同步问题,具有更好的检测速度和精度[12-13]。在用于镜头较远、包含芽头数量更多及类型多样、背景更复杂的场景下的嫩芽识别方面从理论上具有应用潜力。因此,本文拟通过Faster R-CNN模型构建该类场景下的茶叶嫩芽检测算法,特别是评估不同芽头类型下的深度学习识别精度,并与传统目标检测算法进行对比,综合评价深度学习算法在茶叶嫩芽检测中的精度,以期为茶叶的嫩芽检测提供准确的数据支撑。
1 试验方案
1.1 试验区及试验设计
试验区位于农业农村部土壤质量数据中心观测监测基地——重庆市永川区茶山竹海(29.38°N,105.89°E,图1)。试验区地处亚热带湿润季风气候,春季回暖早,夏季气温高,雨热同季,空气相对湿润,年均日照时数1 218.7 h,无霜期317 d,年均气温为17.7℃,年均降水量为1 015.0 mm。主栽品种为福鼎大白茶,该品种长势旺盛,抗逆性强,耐旱亦耐寒。试验设计为不同肥力配施试验(图1),具体试验设计参照文献[14]。

图1 研究区示意图Fig.1 Schematic of study area
1.2 数据获取
试验拍摄设备为华为P30手机,所用摄像头配置为后置徕卡三摄6 400万像素,拍摄时间为2020年3月26日14:00—15:00,高度约0.5 m,角度为垂直拍摄,拍摄对象为36个小区,每个小区拍摄2幅图像。本次研究以拍摄的72幅图像(分辨率为3 648像素×2 736像素)为基础数据集,来制作VOC2007格式标准数据集。
2 识别方法
基于颜色特征、阈值以及学习的分割算法是3种主要的植被提取算法[15]。包括茶叶在内的目标检测与识别主要依赖于颜色特征,且大多是基于计算机和图像处理技术[11,16]。本研究通过在复杂背景下,对比传统基于颜色特征和阈值分割算法,来评估基于深度学习算法识别茶叶嫩芽的性能,2种算法的具体思路如图2所示。在深度学习算法中,首先进行了图像裁切、标签制作,以及必要的数据增强[17-18]等处理来制作数据集,然后利用Faster R-CNN模型和VGG16特征提取网络进行模型训练,最后对已训练模型进行精度评价。在基于颜色特征和阈值分割的茶叶嫩芽识别算法中,首先对图像进行过绿处理,得到灰度图像,然后进行p分位二值化、去噪和膨胀,使其可以被OpenCV检测轮廓[19],通过程序完成坐标提取,并进行真值检验以及精度评价。

图2 技术路线图Fig.2 Technological roadmap

图3 Faster R-CNN模型与VGG16网络Fig.3 Faster R-CNN model and VGG16 network
2.1 Faster R-CNN识别算法
使用Faster R-CNN模型与预训练的VGG16网络进行模型训练以及目标检测。
VGG16[20]是牛津大学计算机视觉组和Google DeepMind公司研究员一起研发的特征提取深度网络,它通过反复堆叠带有3×3卷积核的卷积层和2×2的池化层,来构建包含13个卷积层和3个全连接层的深层卷积神经网络,其中13个卷积层分别在第2、4、7、10、13层被池化层分隔,通过池化可将特征图(Feature map)尺寸减少1/2,结构如图3所示。
Faster R-CNN是REN等[21]在Fast R-CNN[22]基础上提出的具有更好检测速度与准确度的深度学习算法,它可以看作是由区域建议网络(Region proposal network,RPN)和Fast R-CNN检测网络结合而成(图3)。Faster R-CNN通过VGG16前13个卷积层用来获得Feature map,并且RPN网络代替了自我搜索(Selestive search,SS)[23],获得前景或背景信息以及检测框坐标偏移量等建议(Proposal);然后通过VGG16的第5个池化层进行感兴趣区池化(RoI pooling),收集Proposal并结合图像尺寸信息(im_info)计算出带有Proposal的Feature map;最后通过VGG16的3个全连接层与Softmax,对Proposal进行分类与检测框坐标修正,获得目标检测类别(cls_prob)与检测框精准坐标(bbox_pred)。相较于Fast R-CNN,Faster R-CNN实现了同一框架下提取候选框与分类回归,从而在GPU的帮助下大大提高检测速度。
茶叶嫩芽识别的学习与实现主要包含4部分:
(1)数据集制作:考虑到计算机的硬件与GPU性能问题,本次研究需要对原图像进行适当裁切,将3 648像素×2 736像素原图4等分,裁切为1 824像素×1 368像素图像,并在Python中进行批量命名得到图像数据集。然后使用开源工具LabelImg用于标注图像,得到标准的VOC2007数据集,并在程序中对数据集进行包括翻转、镜像、中心对称、亮度改变、中心对称且亮度改变、高斯模糊等数据增强,其中亮度用来模拟天气阴晴情况,改变系数为0.9~1.1,高斯模糊系数为0.5,得到包含2016幅图像和73 080个包围框的数据集。
(2)模型训练:深度学习分为直接训练和预训练模型2种方式。本研究选用预训练模型的方式,训练过程主要包含:①使用预训练的VGG16对RPN进行初始化和训练,并端到端进行微调。②使用预训练的VGG16初始化Fast R-CNN,并利用RPN生成的候选框,训练出一个单独的检测网络。③使用该检测网络再次初始化RPN并进行训练,但固定共享的卷积层,只微调RPN特有的层,就使卷积层达成了共享。④再次训练Fast R-CNN,但固定共享的卷积层,只对其进行微调。因此能够实现2个网络共享相同卷积层,构成统一的已训练网络。训练所用软硬件配置见表1,其中训练参数max_iters设置为70 000,batch_size设置为128,其余保持默认值。

表1 计算机软硬件配置Tab.1 Computer software and hardware configuration
(3)模型测试:对已训练模型进行测试时,Faster R-CNN模型会将图像进行多层卷积与池化,然后由RPN网络获取Proposals,判断Positive或Negative以及计算坐标偏移,RoI pooling会综合Feature map和候选框信息,后续进行分类以及获得精准坐标。这些类别和坐标会被保留,用于后续的真值检验,获得评价指标参数,以及与真值建立1∶1图。
(4)交叉验证:将原始数据随机分成5份,将其中的1份作为测试集,剩余4份作为训练验证集,其中训练集和验证集各占其一半,即20%的数据用于测试,80%的数据用于训练验证。为了更全面地评价性能,采用交叉验证的方式对模型进行5次重复训练和测试。
2.2 基于过绿指数和图像二值化的识别算法
本研究进行了基于过绿指数(Excess green, EXG)[16,24]和图像二值化的茶叶嫩芽识别算法对比试验,具体思路为:
(1)过绿指数处理:在该对比试验中,利用EXG来对图像进行灰度化,使嫩芽老叶能在单通道进行区分,其计算式为
EXG=2G-B-R
(1)
式中R、G、B——对应红、绿、蓝通道图像
(2)图像二值化:场景范围较大的图像中,由于包含了非常多的老叶与嫩芽,其在过绿特征上的亮度也有更多的交集,2种类型的特征峰区分并不明显,并且存在一部分背景值,无法利用大津法(OTSU)一类的方法来进行区分。但小芽在EXG上的亮度总体大于背景,所以采用了直方图p分位截取的方法,截取像元累计前100%-p作为背景,后p作为前景,来进行二值化。为了找到最佳的p分位,取后4%~11%像元进行8次试验,分别进行图像二值化。
(3)嫩芽噪声去除:随着截取像元的增加,二值化后的图像所包含的图像信息越来越多,噪声也随之增多。试验对斑块面积进行阈值分割,去除小面积斑块噪声,大面积斑块因为可能是芽头叠加造成,不作为去除对象。在二值化的过程中,嫩芽边缘并不能提取完整,产生微小斑块也会被去除,芽头轮廓会变得锐利,所以采用了3×3的膨胀矩阵对斑块处理,平滑嫩芽边缘,并填充内部空洞。
(4)嫩芽计数:使用OpenCV来对斑块进行轮廓检测,并保留检测包围框的坐标信息,用于后续的真值检验,建立1∶1图,以及后续的结果可视化。
2.3 评价标准
深度学习的评价指标主要有交并比(Intersection over Union,IoU)、准确度(Precision)、召回率(Recall)、平均准确度(Average precision,AP)。
同时,在真值检测的过程中,为了避免出现同一个标注框检测多个预测框的情况,每个预测框和标注框仅考虑一次。如果存在一个标注框和某个检测框IoU大于0.5,那么这个标注框就不再参与预测框的评估。
3 结果分析
3.1 不区分嫩芽类型的茶叶嫩芽深度学习检测结果
首先,进行不区分嫩芽类型的模型训练,交叉验证测试结果如表2策略A所示。后续对每幅图进行检测,并将其IoU大于0.5的预测框数量(TP)与真值数量之间建立1∶1图(图4a),检测结果的RMSE为3.32,表现并不理想。从图5可以看出有较多的漏检以及一部分的错检,分析漏检/错检原因发现主要为尺寸较小的芽头检测效果不佳,来自单芽识别漏检/错检较多,部分采摘时认定为不摘的小芽头被错检,而部分单芽因为在图像视场内的位置较远而漏检,导致总体识别较差。文献[25-26]表明目标尺寸对检测结果存在较大影响,所以有必要对数据集进行尺寸上的筛选与重分类,来探究目标尺寸对于识别模型的影响。

表2 不同策略下交叉验证结果Tab.2 Results of cross validation under different strategies %

图4 不同策略下深度学习茶叶嫩芽数预测真值与真实值散点图Fig.4 Scatter plots of predicted and truth values of tea buds in deep learning under different strategies

图5 不区分嫩芽类型的嫩芽检测结果Fig.5 Bud test results without distinguishing bud types
3.2 区分嫩芽类型的茶叶嫩芽深度学习检测结果
在嫩芽标签制作过程中,根据实际嫩芽类型(单芽和一芽一叶/二叶)统计各类嫩芽的包围框阈值,以此来制作包含单芽和一芽一叶/二叶类别的数据集(图6)。结果表明,以2006为包围框尺寸阈值进行分类时,单芽和一芽一叶/二叶的包围框数量为2 091和8 349,在总包围框中占比约20%和80%。
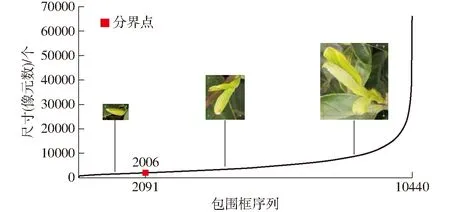
图6 芽头类型分布示意图Fig.6 Distribution diagram of bud head types
当进行了芽头类型区分后(策略B),再次进行模型训练与测试评估时,交叉验证测试结果如表2策略B所示。通过真值检验对每幅图像中的TP数量与真值数量建立1∶1图,结果见图4b,检测结果的RMSE为2.84。结果进一步表明单芽检测精度较低,进而造成总体检测结果偏差。
考虑在实际采摘过程中以一芽一叶/二叶采摘为主,因此分析剔除单芽,仅以一芽一叶/二叶的数据集,重新进行训练以及模型评价,交叉验证测试结果如表2策略C所示。相较于策略A,总体识别效果有较为明显的提升。对每幅图的TP数量与真值数量之间建立1∶1图,结果见图4c,检测结果的RMSE为2.19。结果表明,深度学习算法对以茶叶一芽一叶/二叶为目标的嫩芽识别具有较好的识别精度。
3.3 基于过绿指数和图像二值化的茶叶嫩芽识别算法检测结果
为进一步评价深度学习算法在茶叶嫩芽识别中的精度(以策略C为对比标准),构建基于过绿指数和图像二值化的茶叶嫩芽识别算法检测一芽一叶/二叶来进行对比。考虑芽头颜色有一定的范围,在进行二值化时并不能保留完整轮廓,在进行真值检验时,IoU会普遍较低,所以将IoU设置为0.3,该算法精度结果如图7a所示。随着截取像元p分位的增加,召回率从35%逐步增加到56%,在截取像元9%时达到饱和;但是准确度从53%降低到33%,准确度和召回率呈现负相关关系。因此,综合考虑准确度和召回率,选择截取6%的像元进行图像分割(图8),此时准确度和召回率分别为46%和47%。利用该算法对每幅图进行嫩芽检测,并对其TP数量与真值数量之间建立1∶1图(图7b),检测结果的RMSE为5.47。
3.4 嫩芽检测方法对比与评价
图9为深度学习算法与传统目标检测算法检测茶叶嫩芽的识别结果。表2与图4的结果显示,Faster R-CNN模型在检测不同尺寸的目标时,具有不同的精度表现;在图像分辨率低以及目标的尺寸较小时,Faster R-CNN模型不具备良好的检测性能,单芽头的识别精度不佳;而一芽一叶/二叶的识别精度表现较好,图9a中基本实现该类嫩芽的准确识别;图7和图9b显示了基于颜色特征和阈值分割算法在复杂背景下茶叶嫩芽检测的局限性,准确度和召回率都没有达到一个较高的水平,即使召回率保持在较低范围保证准确度的情况下,也依旧会产生大量的漏检和错检,整体表现较差。在检测时间上,深度学习算法和传统目标检测算法,对单幅图像检测耗时分别为0.20 s和0.72 s(表3),表明深度学习算法在检测速度上也有巨大优势。

图7 图像分割算法一芽一叶/二叶检测结果Fig.7 Detection results of one bud and one leaf/two leaves of image segmentation algorithm

图8 图像分割过程Fig.8 Image segmentation process

图9 茶叶嫩芽识别一芽一叶/二叶检测结果Fig.9 Detection results of one bud and one leaf/two leaves of tea bud recognition
4 讨论
本文构建基于Faster R-CNN网络的茶叶嫩芽检测及精度评价,特别是评价不同芽头类型的识别结果,发现单芽的识别精度不佳,原因主要为Faster R-CNN模型本身在检测小目标时不具有良好的检测性能[26-27]。Faster R-CNN模型是在14×14×512的卷积层(图3)后进行RoI pooling[23],由于经过4次池化,这一层的特征所对应原图的像元尺度非常大,单像元可以对应原图16像素×16像素的尺寸,所以无法对小目标进行有效地特征提取。但在实际采摘的过程中,尺寸很小的单芽并不作为采摘对象,当去除该类数据集后,再进行相同参数的训练,精度有较为显著提升。

表3 算法耗时对比Tab.3 Time-consuming comparison of different algorithms
文献[28-30]研究结果表明,预处理可以使特征信息更加突出,以此来更好地训练模型,提高训练模型的检测性能。本研究也使用了过绿指数来对数据集进行预处理,但在初始训练参数下,单芽和一芽一叶/二叶的平均准确度分别为9%和74%。总体来看并没有达到提高模型性能的目的,推测原因是EXG预处理图像仅仅作为单通道输入的时候,缺少了红蓝通道的信息,即使在绿通道上做到了绿色特征突出,并不能对整体有较大的贡献,导致了训练模型性能没有提升,甚至精度出现了降低。
吴雪梅等[10]的研究表明,随着拍摄距离、范围的增加,以及背景复杂程度的加深,用图像分割算法检测嫩芽,会出现更多的“杂点”和“碎片”噪声,检测效果会越来越差。本文所采用的基于颜色特征和阈值分割的茶叶嫩芽识别算法,尝试了很多的颜色特征(如EXG、EXG-EXR、G-B等)、阈值分割方法(如p分位、OTSU、双峰法),以期获得更高的精度。其中EXG的表现最好,可以较好地表达嫩芽与背景的差异,p分位相较于OTSU和双峰法来说效果也更好。但随着截取像元数的增加,检出的芽头数开始增加,召回率提升;但也产生了更多的噪声,准确度急剧降低。并且该类方法对于拍摄场景和环境有非常高的要求,多云环境下不同亮度、不同拍摄距离和范围的图像,以及不同的生长环境下拍摄的图像,都会有不同的截取分位;茶叶嫩芽之间的叠加以及覆盖问题,也会极大地增加图像分割算法的检测难度。综合已有研究[31]来看,相对于深度学习方法,传统目标检测方法有精度偏低、鲁棒性差、速度慢的劣势。
当数据量较少时,数据增强是提升模型准确度、鲁棒性以及泛化能力的一种较为有效的途径[17-18]。深度学习算法本身需要大量的数据,在数据量不足的情况下,本研究进行了数据增强并模拟了复杂自然场景,来增加数据量以及数据多样性,提升模型性能。但数据增强中不论是翻转、镜像、对称等像素位置的改变,还是亮度、模糊等像素值的改变,其都是在同一个数据集上进行的,增强后的数据集虽然数据更多、更具多样性,但与原始数据仍具有较强的相关性,可能会造成训练模型的性能和表现略差于足量真实数据集训练出的模型。后续补充更具多样性的足量数据,来获得更准确、更鲁棒以及泛化能力更强的模型。
5 结束语
针对范围较大、背景更为复杂的茶叶嫩芽检测问题,本文探究了Faster R-CNN模型和VGG16特征提取网络,对目标尺寸的检测敏感度问题,提出剔除单芽类的方法,较大地提升了模型性能。首先,对原始图像进行了裁切、标签制作、数据增强,然后基于深度学习的Faster R-CNN目标检测算法对茶叶嫩芽进行检测,并探究了该方法对不同尺寸芽头的检测效果,剔除小芽后重新训练与测试,显示出了较好的检测性能,最后对比了基于过绿指数和图像二值化的茶叶嫩芽识别算法检测茶叶嫩芽的结果,表明本文基于深度学习的目标检测算法具有良好的检测效果,可以为复杂背景下检测芽头提供技术保障,以及为智能采摘提供理论指导。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
红蜻蜓(2021年2期)2021-07-20
阅读(中年级)(2019年3期)2019-04-24
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
作文与考试·小学低年级版(2017年13期)2017-07-06
