
融合多环境参数的鸡粪氨气排放预测模型研究
2022-06-21 08:22丁露雨李奇峰王朝元余礼根宗伟勋
农业机械学报 2022年5期
丁露雨 吕 阳 李奇峰, 王朝元 余礼根 宗伟勋
(1.清远市智慧农业农村研究院, 清远 511500; 2.国家农业信息化工程技术研究中心, 北京 100097;3.中国农业大学水利与土木工程学院, 北京 100083; 4.清远市农业科学研究所, 清远 511500)
0 引言
氨气(NH3)是密闭鸡舍主要的有害气体,生产中由于通风不足或通风不及时,常出现有害气体浓度累积、空气质量差的问题,严重制约了畜禽健康生产[1-4]。随着我国畜牧业的不断发展,数字化、福利化养殖成为了畜牧业升级转型的发展方向[5],有效预测舍内NH3浓度可辅助通风量需求计算、评估舍内空气质量,及时、合理地调控舍内NH3水平,对畜禽健康生产具有重要意义。
目前,畜禽舍NH3预测模型的研究大致包括两类,第一类是直接预测舍内NH3浓度的模型。例如,文献[6]结合长短时记忆神经网络(LSTM),使用随机森林(RF)对影响NH3浓度的环境变量进行重要性排序,然后构建鸡舍NH3浓度预测模型。文献[7]提出基于粒子群算法-优化深度神经网络算法(PSO-DNN)预测冬季平养鸡舍NH3浓度,并证明该模型的预测精度高于现有的随机森林模型。舍内NH3浓度受其排放量和舍内通风量的影响,现有研究中建立的NH3浓度预测模型大都没有考虑环境调控设备运行状态和气体排放量水平,且数据量有限,所建立的模型泛化能力和鲁棒性较差,无法直接对设备运行状态予以调控指导和决策指令。第二类是预测NH3产生量或排放量的模型[8-11]。这类模型通过排放机理或统计分析预测NH3排放水平,结合动物环境需求可以获得环境调控参数(如通风量),指导设备进行环境调控。然而,现有模型存在参数数量多或没有考虑动物个体及环境因素不确定性对NH3排放影响的问题,不同生产条件下的预测误差大。
NH3排放过程中常伴随着其他气体的释放,相同条件下,畜禽生产中各类气体的排放具有相关性,可以考虑结合气体产生与释放的机理过程,引入其他易测气体的排放量,用于预测NH3排放[12-14],这有利于代替部分不确定因素的影响,使得预测结果更具有可靠性。本文选取相对易于测量且能代表动物及环境变化不确定性影响的变量参数(温度、相对湿度、H2O排放量、CO2排放量)作为输入特征,利用机器学习方法建立肉鸡粪NH3排放预测模型,对比不同模型类别对NH3排放的预测效果,以期为日常畜禽舍环境管理提供模型参考。
1 材料与方法
地面垫料平养是国内常见的一种肉鸡饲养方式,该模式投资少、成本低、易于管理,但粪便在舍内堆积时间长,舍内NH3浓度较高,尤其是冬季通风量较小时,易诱发呼吸道疾病。本文在实验室条件下模拟平养肉鸡舍冬季NH3排放过程,测试粪便发酵过程中NH3、CO2、H2O浓度及排放量,用于建立NH3排放估计模型的数据集,利用不同的输入参数和模型开展对比研究,构建NH3排放量估计模型,试验流程如图1所示。

图1 试验流程图Fig.1 Flow chart of experiment
1.1 气体排放测试与数据采集
1.1.1试验装置
肉鸡舍气体排放试验装置如图2所示。该试验装置尺寸(长×宽×高)为0.86 m×0.45 m×0.65 m,参照动态箱原理设计,由亚克力材料制成,内部设置有直径0.34 m、高0.2 m圆柱型鸡粪容器以及鸡粪搅动耙、手工操作窗口等设施,便于模拟肉鸡对鸡粪的踩踏及鸡粪与垫料的混合。箱体两侧各设9个进出气孔,一侧为进气面,对侧作为出气面连接气泵模拟机械通风,通气量为0.618 m3/h,出气口管路中接流量计监测箱内通气量。为防止出气孔气体影响模拟环境各项参数数值,气泵出气口设置延长管将废气排至室外。

图2 试验装置实物图Fig.2 Demonstration of experimental setup
1.1.2数据采集与计算
肉鸡舍气体排放模拟试验地点位于中国农业大学上庄试验站内,试验共计12 d。试验初始时,装置内铺加垫料并放置3 000 g鸡粪,之后每日向试验箱内添加鸡粪150 g,每日采集进、出气口NH3、CO2、H2O等气体浓度(质量比)。箱内设置温湿度自动记录仪(艾普瑞(上海)精密光电有限公司)记录箱内温度T及相对湿度,采集频率2次/min。试验装置进、出气口设有气体采样点,通过INNOVA 1403型多路器(LumaSense Technologies公司,美国)及INNOVA 1512i型光声谱多气检测仪(LumaSense Technologies公司,美国)进行气体连续、循环采样及浓度检测。每次测量约1 min,前20 s为管道冲洗,后40 s为气体浓度分析,每个点测3次,进、出口采样点交替采集,去掉第1次测量结果,取后2次平均值为该采样点当前气体浓度。
每日开盖添加鸡粪对排放系统有一定影响,取到达稳态时的相同时间阶段(每日15:30至次日09:25)进行数据分析,共444组数据计算气体排放量。排放量计算公式[15]为
(1)
式中E——目标气体排放量,mg/(kg·h)
Co——试验装置出气口采样点气体浓度,mg/m3
Ci——试验装置进气口采样点气体浓度,mg/m3
V——通气量,m3/h
M——每日鸡粪量,kg
1.2 NH3排放预测模型
1.2.1参数选择
(1)CO2和H2O
从NH3产生机理考虑,鸡粪的尿酸分解是鸡舍内NH3产生的主要途径,因为家禽的肝脏中没有精氨酸酶和氨甲酰磷酸合成酶,不能通过尿素循环把体内代谢产生的氨合成尿素,只能在肝脏和肾脏中合成嘌呤,并在黄嘌呤氧化酶的作用下生成尿酸[16]。尿酸在多种微生物酶的作用下水解成尿素和乙醛酸,最后尿素在脲酶的作用下产生NH3和CO2,尿酸生成NH3的反应式如图3所示[17-18]。

图3 尿酸分解变成氨气的过程Fig.3 Decomposition of uric acid into ammonia
分析鸡粪产生NH3的机理及其产生后排放的机理可以看出,NH3的产生伴随着CO2的生成,而NH3挥发与H2O挥发密不可分。相比于NH3浓度,CO2浓度和相对湿度更容易实现低成本和高精度的测量,且传感器寿命相对于传统的NH3浓度电化学传感器长,维护成本更低。因此,选取H2O排放量(EH2O)及CO2排放量(ECO2)作为环境参数参与模型构建。
(2)温度T和相对湿度H
温度、相对湿度是影响畜禽粪便NH3产生与挥发的关键环境参数。大量研究冬季畜禽舍内温湿度与有害气体分布规律的结果表明,NH3浓度与温、湿度具有显著相关性[20-21]。当处于冬季低温条件时,鸡舍的保温需求会与通风形成较为明显的矛盾,通风不足时舍内的NH3浓度和相对湿度会产生相互影响。文献[21]研究冬季温、湿度对平养鸡舍NH3浓度影响时发现:NH3浓度与T有较强的正线性关系,当舍内环境温度上升时,大部分情况下NH3浓度也会上升;当处于不通风阶段时,舍内NH3浓度会与相对湿度形成负线性相关,随相对湿度的下降而升高,这可能是由于NH3易溶于水[22],湿度较大时,会有部分NH3随之溶解。
1.2.2模型选择
机器学习以数据为研究对象,监督学习作为机器学习的重要组成部分,可以从标签数据中学习模型。标签数据表示输入、输出的对应关系,预测模型对给定的输入产生相应的输出,监督学习的本质是学习输入到输出的映射规律统计[23]。
以与鸡粪NH3排放相关的环境参数为特征数据,以 NH3作为标签数据,目的是从T、H、EH2O、ECO2等特征数据中学习对应关系,使其能够预测标签数据,该种模型是典型的监督学习模型。其中,输入变量(T、H、EH2O、ECO2)和输出变量(氨气排放量ENH3)均为连续变量,这类预测问题成为回归问题,对应模型为非概率模型。因此,采用监督学习的方法建模,考虑到数据量只有444条,不适用于大规模的参数训练,所以使用统计学习——即统计机器学习的方法进行模型构建。
鸡粪NH3排放预测模型由数据直接学习决策函数,所以属于监督学习中的判别模型。依据模型特点,选择较为常用的判别模型对鸡粪NH3排放进行预测,包括广义线性回归模型、内核岭回归、决策树及集成方法(随机森林、极限随机树、AdaBoost回归、梯度提升回归)8个模型,对比各个模型在鸡粪NH3排放预测中的决定系数R2。
1.2.3模型训练
采用Python语言sklearn库进行模型训练,训练过程中的数据集划分方式、超参数选择对模型训练结果至关重要。
(1)数据集划分
模型训练采取10折随机排列交叉验证的方法进行数据集划分,即对数据集随机抽样选出训练集和测试集,进行10次的评估和测试,最终对10次的结果取均值,得到最终的模型评价结果。该方法可以增强模型结果的可信度、减少数据集划分对模型训练的影响[24]。
(2)超参数
训练模型中,决策树及集成模型的训练涉及超参数选择问题。超参数的选择关系到预测结果的优劣,好的模型参数会提升模型的效果,所以模型参数的选择至关重要。超参数不能在模型中自动学习,需要在训练过程中结合多种评价指标进行选择。使用网格追踪法寻找超参数的最优值,并结合所采用的学习机方法进行微调,选择一组最优超参数。本文涉及到的主要超参数如表1所示。

表1 本文模型中涉及的主要超参数Tab.1 Hyperparameters involved in different models
1.3 模型评价指标
使用预测模型的决定系数R2、均方根误差(RMSE)、平均绝对百分比误差(MAPE)作为评价指标[10],测试不同模型对鸡粪NH3排放量的预测效果。
2 结果与讨论
2.1 气体排放测试数据

图4 鸡粪气体排放测试数据Fig.4 Chicken manure gas emission test data
气体排放测试期间,动态箱内平均温度、相对湿度分别为(6.1±1.1)℃、(69.9±5.4)%,期间的平均NH3、CO2及H2O排放量分别为(3.2±0.9)mg/(kg·h)、(147.5±61.6)mg/(kg·h)、(184.1±43.9)mg/(kg·h)。测试期间,T、相对湿度、ENH3、ECO2和EH2O的变化趋势如图4所示。试验开始时,鸡粪进行发酵反应,前4 d时NH3排放量随时间上升并达到最高点,然后大幅下降,之后每日随鸡粪不断添加,重复以上趋势。同时,通过与其它环境参数曲线进行对比观察发现,NH3排放量的数量级远小于CO2和H2O,但3种气体排放量的变化趋势几乎一致,这说明EH2O、ECO2比ENH3相对更容易实现准确检测,研究中选择的T、H、EH2O、ECO2这4个自变量对ENH3预测有较好的可解释性和代表性。
2.2 不同预测模型对比
结合已有超参数的选择方法、各模型超参数的数量及范围,在确保准确度的前提下,使用网格追踪法寻找左右超参数并进行微调。不同模型最佳超参数选择后的结果如表2所示。

表2 不同树模型选用的超参数值Tab.2 Hyperparameter values selected by different tree models
在最佳超参数选择的基础上,分析各模型以T、H、EH2O、ECO2为自变量预测ENH3的评价指标(表3)发现,岭回归、弹性网络、内核岭回归预测氨气排放量的效果很差,决定系数均不足0.2,预测误差大,而树模型和同质集成的树模型的结果较好,其中极限随机树模型表现最优。

表3 不同模型评价指标Tab.3 Evaluation indexes of different models
极限随机树也是一种集成方法,使用多个树来预测样本,图5为集成模型中的一颗子树。该子树是一颗关于所选参数的决策树,该树只显示了前4层,记录着分割的特征和对应的分割点。计算分割点的方法中,进一步增强了分割点的随机性,利用的特征是候选特征的随机集合。根据所有候选特征任意生成分割点,在生成的分割值中选择最佳的点进行分割。这种方法通常可以减小模型的离散度,所以极限随机树在多个模型中表现最好。
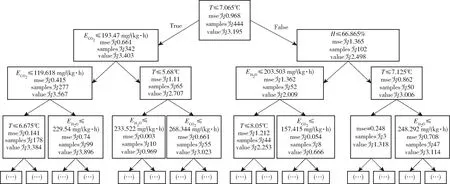
图5 树模型结构图Fig.5 Structure diagram of tree model
选择表3中性能较好的树模型作为预测模型对测试集数据进行验证分析,预测结果与实测结果对比如图6所示。使用T、H、EH2O、ECO2作为影响因子参与建模时,决策树、随机森林、极限随机树、AdaBoost回归、梯度提升回归的平均残差百分比分别为(3±4.6)%、(4±3.7)%、(3±3.5)%、(6±4.8)%、(5±4.5)%。可见,各模型预测NH3排放量时多表现为高估,其中决策树和极限随机树平均残差百分比最低,但决策树模型的残差百分比标准差更高,故而模型的稳定性不如极限随机树,极限随机树模型的预测效果最佳。

图6 各类树模型预测结果对比Fig.6 Comparison of prediction results of various tree models
2.3 参数
2.3.1参数重要性
特征重要性和排列重要性分析可以判别各参数对模型的重要程度。特征重要性是指特征(即输入参数)对预测结果的影响,是模型对每个特征重要程度的描述。排列重要性是随机打乱某个特征之后,衡量该特征对模型的影响,从而得出特征的重要性。
选取表现最好的极限随机树作为分析对象,利用排列重要性和特征重要性分析T、H、EH2O、ECO2在建模过程中的重要程度,探究NH3排放量预测的机理知识与模型重要性的联系。

图7 特征重要性和排列重要性图Fig.7 Feature importance and permutation importance charts
从图7可以看出,EH2O在NH3排放预测中起着重要作用,这可能是因为NH3易溶于水,在今后的研究中可以重点关注EH2O与ENH3之间的相互作用关系。T和ECO2在特征重要性和排列重要性两方面评价中,影响程度并不对应相同,虽然排名有所变化,但不能一定说明ECO2比T的影响程度大。因为测试时环境温度相对比较稳定,变化幅度较小(变异系数18.0%),而ECO2的变化相对更大(变异系数41.8%),因此,随机打乱T和ECO2两个特征后预测的结果变化幅度不同。此外,粪便发酵过程中CO2的产生具有温度依赖性,T变化后,EH2O也会随之变化。
综上所述,如果同一个特征在不同的评价方法中都重要,那么该特征就应该重点关注。在本次试验中,两种评价方法中EH2O的得分都很高,因此,不同参数组合时,模型中都需要考虑EH2O。
2.3.2模型对特征变量的依赖性
通过个体条件期望图(Individual conditional expectation,ICE)和部分依赖图进行依赖性分析,即某一特征变量的值变化对NH3排放量预测值的影响。
个体条件期望图是用来可视化分析目标响应和一组输入特征变量之间的交互作用,可以分析目标函数与输入的特征变量之间的依赖性。设xs为输入特征集合(即特征参数),xc为其补集。响应f在xs处的部分依赖性定义为
(2)

图8所示分别为T、H、EH2O、ECO2为研究对象的条件期望图,即变化其中一个环境参数的取值,保留其他参数取值不变,运用训练完成的极限随机树模型预测ENH3的结果。图中,测试数据集样本为50个样本,细线代表每条数据,粗线代表所有细线的均值。曲线越陡峭,说明该参数对于模型越重要,反之,对模型重要性越低。

图8 个体条件期望图(ICE)Fig.8 Individual conditional expectation graph
从图8中可以看出,当T<6.5℃时,T的ICE曲线变化平缓,说明T变化,其余值不变的情况下,ENH3的预测值几乎不变,即T的变化对ENH3的预测结果影响不大;当T>6.5℃时,T与ENH3大致呈线性的负相关关系。EH2O的变化最陡峭,说明EH2O在预测ENH3的过程中贡献度最大。
部分依赖图与个体条件期望图相似,区别在于研究对象的抽取方式不同,个体条件期望图抽取数据的方式符合数据分布特征,部分依赖图是按照等间隔方式抽取数据并计算。这能够展现出两个特征变量对模型预测影响的函数关系:近似线性关系、单调关系或者更复杂的关系。为了更加形象地观察特征组合与模型之间的交互作用,在三维空间内用两个特征的相互作用绘制部分依赖图。
由图9可以看出,相比于单个变量,同时考虑两个变量的影响时,变量与模型之间的交互变得更为复杂。以EH2O和ECO2为例,在EH2O小于200 mg/(kg·h)时,ECO2对ENH3的作用与单变量时的趋势大致相同,但是当EH2O大于200 mg/(kg·h)时,EH2O的影响占据主导地位,ECO2在该段的影响几乎可以忽略。这也体现出变量影响之间的一个原则:模型中表现强的变量会掩盖掉表现弱的变量。

图9 三维空间内的部分依赖图Fig.9 Partial dependence diagram in three dimensional space
2.4 环境参数融合对模型的影响
2.4.1水汽压差
T和H度二者间存在互作关系,当空气中H不变时,T升高会使得H降低。NH3排放研究中,常使用水汽压差(VPD)来表征T和H二者对NH3排放的共同影响[25]。因此,将模型参数进一步简化,利用VPD代替T和H,探索模型的预测效果。
VPD是空气中水汽分压力与饱和水汽压之间的差值,可通过T和H计算获得[26],公式为
(3)
式中V——水汽压差,kPa
计算后,气体排放测试时的VPD变化曲线如 图10所示。
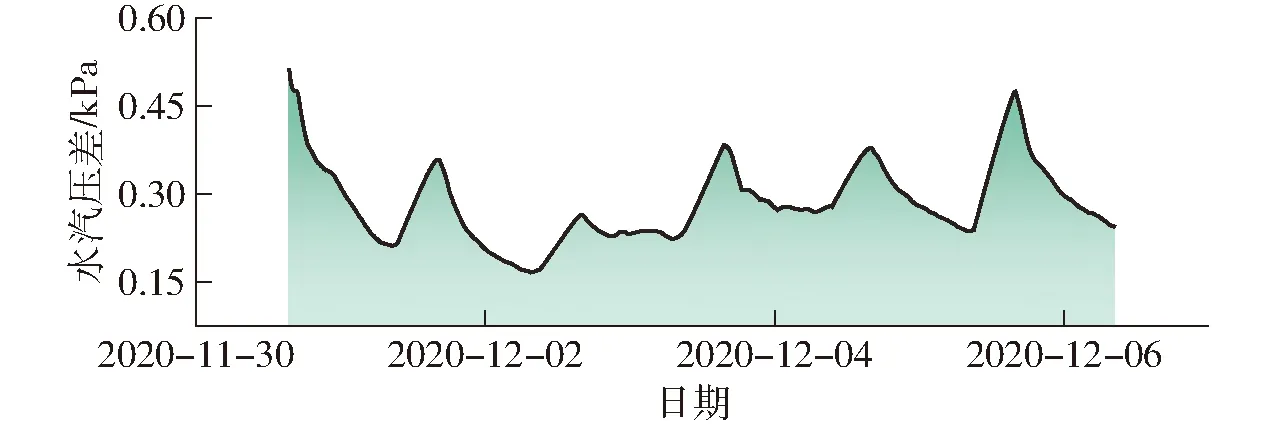
图10 鸡粪气体排放测试期间的VPD变化曲线Fig.10 VPD during experiment of gaseous emissions from chicken manure
2.4.2水汽压差对模型的影响
为了探索衍生参数对模型准确率的影响,选用VPD、EH2O、ECO2等3个自变量的不同组合进行建模尝试,具体组合方式为:VPD、EH2O、ECO2;VPD、EH2O;VPD、ECO2。
对比包含VPD的参数组合与T、H、EH2O、ECO2的参数组合,不同特征变量利用极限随机树模型预测ENH3的决定系数R2如图11所示。

图11 不同参数组合特征输入时模型的决定系数Fig.11 R2 of model when different parameter combination features were input
从参数数量上看,相同模型随着参数数量的变少,模型的R2呈降低的趋势。各模型的预测效果并没有随着引入VPD而有所提升,甚至有所降低。这可能是因为本研究中所选用的模型参数较少,树模型可选的参数较为单一,最后构建出的树模型差异性不大,影响了树的多样性,进而导致了参数数量与评价指标得分之间成正比的结果。从最优模型的选择角度来看,不同参数组合时,仍然是各类树模型的拟合效果更好,最佳模型仍然是极限随机树模型,也体现了极限随机树模型的预测准确性。
综合不同模型种类和参数组合的建模效果可知,采用极限随机树模型且以T、H、EH2O、ECO2为模型特征变量输入时,ENH3的预测效果最好。
2.5 模型应用
(1)模型应用条件
应用中,上述模型的特征参数EH2O、ECO2为粪便挥发所产生[27-28],因此,该模型不同条件的应用方式不同。当模型应用场景的气体排放源仅为粪便时可直接使用模型估计NH3排放量,如粪便贮存、堆肥过程中NH3排放量估计、缺失值填充等。当模型应用场景的气体排放源包含粪便和动物时,需对测得的EH2O、ECO2进行校正,扣除肉鸡自身产生的CO2和水汽后再输入模型进行测算,如肉鸡舍氨气排放量预测、以改善空气质量为目标的通风量测算等。根据国际农业工程学会国际农业工程委员会(CIGR),肉鸡生产中排放的CO2和水汽量可通过肉鸡产生的显热、潜热和总热量,利用已有模型进行计算[29-30]。
(2)模型应用优化
本文中参与模型构建的数据量及各参数变化范围有限,模型应用中可能会存在一些局限。由2.3.1节可知,当EH2O大于200 mg/(kg·h)时,ENH3预测值与EH2O之间有很强的依赖性。本研究中EH2O的范围在110~270 mg/(kg·h)之间,当EH2O大于270 mg/(kg·h)时模型的准确度可能会有所变化。T是影响CO2、NH3、H2O排放的重要环境参数,本研究中T的变化范围相对较小(4~8℃),进而出现了模型对T依赖性最弱的结果。从机理上看,T是影响气体排放最主要的环境因素之一,作用程度远大于相对湿度;当T从10℃以内上升到20℃以上后养殖场的气体排放会增加数十倍[31-32]。当T大于10℃,如果直接使用前述模型可能会出现较大的误差。
本研究构建的模型具有一定的自适应能力,鉴于上述局限的存在,应用中可通过增加数据量进行优化训练,提高模型普适性。数据量的增加包括两方面:一是扩大数据分布的范围,二是增加各范围数据的数量。文献[33]在分类模型泛化能力的研究中发现,样本数量的增加和样本分布范围的扩大,可以有效提升模型普适性,而且数据分布范围的影响大于数据增量的影响[34]。因此,未来应用中优先考虑扩大数据分布范围。例如,可以增加T大于10℃以上的环境数据和气体排放数据,与原始数据混合训练极限随机树模型,提高模型的普适性。
3 结论
(1)考虑到畜禽生产及粪便发酵过程中,NH3浓度及排放量存在数值小、传感器腐蚀性高、不易采集的情况,本文结合NH3产生的机理和机器学习建模技术,利用相对较易采集的环境参数作为影响因子,对比了8种不同模型的预测效果,建立了垫料饲养条件下肉鸡粪NH3排放量预测模型,为垫料饲养肉鸡舍通风调控奠定模型基础,也为粪便管理中肉鸡粪NH3排放量预测提供模型支撑。
(2)通过预测模型结果对比发现,使用T、H、EH2O、ECO2作为特征输入,以极限随机树为预测模型时,肉鸡粪NH3排放量的预测效果最优,R2为0.916 7,ENH3预测的平均残差百分比为(3±3.5)%。各特征参数中,EH2O对模型的影响最为重要。引入VPD代替T和H并不能得到更好的模型效果,甚至会降低模型预测的准确度。应用中,当排放源同时包括粪便和动物时,应当扣除肉鸡自身产生的CO2和H2O,对EH2O、ECO2校正后再输入模型中进行预测。
猜你喜欢
文萃报·周五版(2020年37期)2020-10-12
看世界·学术上半月(2020年9期)2020-09-10
河北工业大学学报(2019年4期)2019-09-10
农民致富之友(2019年12期)2019-05-22
科学种养(2018年4期)2018-04-25
农村农业农民·B版(2018年1期)2018-01-31
中学课程辅导·教学研究(2017年11期)2017-09-23
少儿科学周刊·少年版(2015年1期)2015-07-07
少儿科学周刊·儿童版(2015年1期)2015-07-07
农村百事通(2009年4期)2009-03-02
