
卷积神经网络在装备磨损颗粒识别中的研究综述
2022-07-08 09:34关浩坚贺石中李秋秋杨智宏覃楚东何伟楚
摩擦学学报 2022年2期
关浩坚, 贺石中*, 李秋秋, 杨智宏, 覃楚东, 何伟楚
(1. 广州机械科学研究院有限公司 设备润滑与检测研究所, 广东 广州 510530;2. 工业摩擦润滑技术国家地方联合工程研究中心, 广东 广州 510530)
随着科技的进步,现代工业逐渐从传统的依靠大量劳动力来运作设备的非自动化和非智能化工业转变为自动化和智能化型工业,机器稳定运行成为了高效率工作的要求. 为保证机器保持长久稳定性,对设备故障分析的技术要求日益增高[1].
磨损颗粒是摩擦副运行过程中的直接产物,它能够很好地反映机器的磨损情况[2-3]. 据统计,机器的磨损故障中,有超过80%的故障都是来源于磨损碎片[4],所以为了减少设备失效造成的生命财产损失,一般通过对设备的在用润滑油中的磨损碎片进行检测,能够及时察觉设备存在的问题,从而提前做好维护.
铁谱技术是油液分析技术的1种,在20世纪70年代传入我国[5]. 其根据设备在用油中磨损颗粒包括数量、形态和尺寸在内的各种信息分析设备的磨损情况,从而对设备的运行状态进行判断,对使用寿命进行预测[6]. 简而言之,铁谱技术就是1种能够提供设备准确的磨损颗粒图像的方法,通过分析磨损颗粒可以确定设备的磨损位置和磨损机理[7]. 目前在机械制造、能源化工和钢铁冶金等行业已经得到广泛应用.
铁谱分析是设备故障诊断中重要的一环,而磨损颗粒的识别则是铁谱分析的核心,但颗粒图像的分析需要大量的人工进行分析,而且非常容易受到主观性的影响,受经验的影响也非常大,尤其面对各种重叠颗粒以及各种设备工况造成的大量不明颗粒,即使是具有多年经验的技术人员也未必能够给出肯定的分析,即依靠人工进行磨粒识别的准确度有限而且成本高. 因此该部分工作极需要智能化,从而提高分析的统一性、准确性和分析效率[8].
1 卷积神经网络与磨粒智能识别
1.1 卷积神经网络
卷积神经网络(CNN)是人工神经网络的1种,属于深度学习算法[9]. 它由卷积层、池化层和全连接层等组成,如图1所示. 它的主要目的是根据训练数据集将输入图像分类为几个类,目前已经成为图像识别领域的研究热点.
1962年 Hubel和Wiesel[10]提出了猫的视觉皮层是逐层提取信息的观点,1980年Fukushima等[11]基于此概念提出了神经认知机,其中的一些卷积和池化的概念(当时未被称为此名字)为后来的卷积神经网络打下了基础. 1989年,LeCun等[12]提出了第一个真正意义的卷积神经网络,这是参考了Fukushima的神经认知机的精华并结合Rumelhart等[13]在1986年提出的反向传播算法提出的. 1998年,LeCun等[14]正式提出了LeNet-5,这是第一个广为人知的经典卷积神经网络模型,也是首个成功进行多层训练的卷积神经网络,为后来深度学习的爆发打下了基础. 2006年,Hinton等[15]首先提出了深度学习的概念,而卷积神经网络则是深度学习中最著名的算法之一. 2012年,卷积神经网络在图像识别领域开始备受高度关注,在此之前一般是通过人工设计特征进行图像识别,其识别效果一直不佳,而当年,Krizhevsky等[16]提出了AlexNet卷积神经网络,通过卷积神经网络自动提取样本的特征进行学习,在ImageNet竞赛中将识别错误率从26%降到了15%,远超同年代识别水平. 从此,深度卷积神经网络成为所有计算机视觉任务的首选算法. 后来逐渐发展出ZFNet[17]、VGGNet[18]、GoogLeNet[19]、ResNet[20]、各种轻量型卷积神经网络[21]、SeNet[22]和DenseNet[23]等,不仅能识别单个物体,还能识别多个物体,甚至能直接分割出所识别的物体,而且识别速度也得到了质的飞跃. 卷积神经网络正在向更深、更宽、更多支路、更轻量以及更有效等多个方向发展,很多前沿问题的解决方法得到了进步,例如通过单预测或多预测方法已经在尝试解决遮挡识别问题. 近几年甚至有研究者提出了NASNet[24],这是1个通过人工智能寻找的非常优秀的神经网络架构,通过计算机寻找网络架构的研究于2019年开始火热.还有被誉为2021年最强骨干网络的Swin Transformer[25],其性能超越了前述多个网络模型. 卷积神经网络的发展大大提高了计算机图像识别的能力,也为磨粒智能识别打下了基础. 图2为卷积神经网络的发展历程简图.
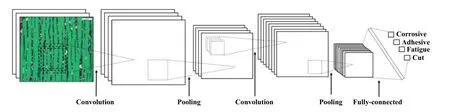
Fig. 1 The structure of convolutional neural network图1 卷积神经网络结构示意图
1.2 磨粒智能识别
自铁谱分析的方法问世以后,将铁谱分析技术与计算机技术相结合的研究就开展起来. 1976年,Odiowei等[26]开发了1种计算机分析系统,提供了关于磨粒的数量、大小和分布的信息. 20世纪70年代末,Reda等[27]首先编制了磨粒图谱第一卷,美国海空工程中心进行了完善,为磨粒识别打下了基础.
1982年,Roylance等[28]提出了1种使用图像处理技术区分不同类型的磨损磨粒的技术. 1994年,Roylance等[29]将来自不同来源的大量磨损颗粒用图像处理和分析方法对其形状特征进行了分析. 还有各种基于人机交互的磨粒分析系统也在当时被开发出来,如CAVE[30]、CASPA[31]、SYCLOPS[32]以及各种基于3D磨粒分析的专家系统[33]. 在2005年之前,这些系统很大程度上都是基于人工定义的磨粒几何和纹理等特性进行特征提取,然后通过早期机器学习方法进行磨粒识别. 但是这些系统只能提取少数基本的特征,面对复杂的图像准确率不高,总体来说实用性不强,即使采用了“先验知识库”,即提前将要识别的东西给机器进行匹配,也只能满足某些光学字符识别和工件识别等的要求,而对于铁谱诊断的磨粒分析而言仍然存在很大的不足,例如针对磨粒的颜色和3D特征等重要的信息不能提取出有效的特征参数.
随着科技的进步,学者们提出了更多的磨粒特征和更多的算法来提高磨粒识别的准确率. 2005年,Chen等[34]对铁谱图像的颜色特征进行了研究. 2006年,Guo等[35]将磨粒的力、温度、超声波或AE信号等与神经网络结合提高了磨粒智能识别的准确率. 2014年,Guo等[36]结合磨粒图像的分形特征和自组织特征映射神经网络,提出基于分形特征的磨粒图像分割方法.除了对特征进行改进外,学者们还对磨粒识别的算法进行了研究. 例如2011年,Wang等[37]利用模糊系统和神经网络的优点建立了1种改进的模糊神经网络模型和算法,通过定义特征和改进算法等来提高识别率.2014年,Nunthavarawong等[38]比较了不同机器学习方法对磨损颗粒颜色分类的效果. 这段时间仍然是通过人工定义特征以及利用传统的机器学习方法来进行计算机识别,但由于图像处理硬件的极大提升,很多以前不成立的算法开始逐渐变得可用,包括统计方法和局部特征描述符的引入,解决了一些问题,例如“先验知识库”中记录的物体若发生诸如形状、纹理和颜色等特征变化,或者受到外界影响如观察角度、光线明暗或受到遮挡等就会严重影响机器识别率. 但由于该阶段的图像识别本质上属于人工定义特征,很多特征得到了尝试但没有特别高的准确率,并且较多的特征耗费了大量计算机算力,其发展一直受到硬件性能的制约,尽管这方面的制约在2012年已经通过深度学习自动提取样本特征的技术出现得到大大缓解,但在磨粒识别领域一直到2018年才开始出现计算机自动发掘特征进行识别的相关文献记载. 有关人工特征和自动特征的工作原理如图3和图4所示,人工对磨粒的特征进行定义,然后根据该人工定义的特征对新磨粒进行识别和分类,该方法存在较强主观性,因为对于整个磨粒来说,其特征信息是人工难以定义的. 而自动特征则利用到计算机的强大计算力和卷积神经网络的强大算法来对磨粒的特征进行自动分析定义,如此经过大量训练后再对新磨粒进行识别,效果自然更好.
表1整理了一些关于磨粒识别人机交互时期和人工定义特征时期的文献,只列出了部分,实际上这两段时期所发表文献数不胜数[39-40].
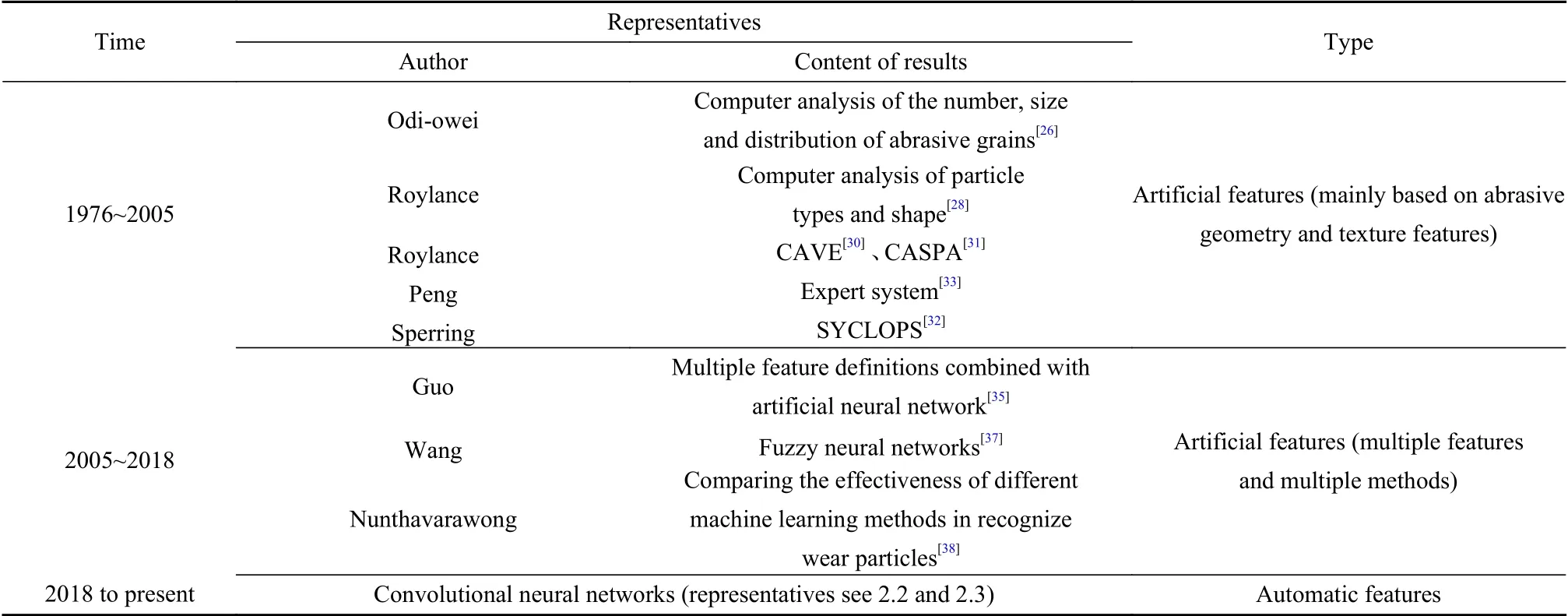
表1 磨粒智能识别的3个阶段Table 1 Three stages of intelligent recognition of wear particles
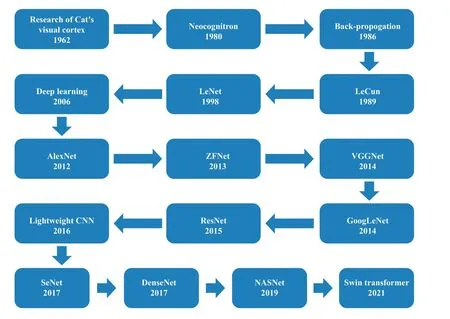
Fig. 2 Development of convolutional neural networks图2 卷积神经网络发展历程
2 磨粒智能识别的现状
2.1 磨粒图像数据的处理技术
2.1.1 数据集的标注

Fig. 3 Principle of artificial feature recognition图3 人工特征识别原理
卷积神经网络模型的训练需要大量的训练数据支持,对于参数众多的模型来说,哪怕是几万乃至几十万的样本数量都是不能达到最佳效果的. 而这些训练数据要预先通过人工标注出颗粒位置及其类型才能作为训练集由计算机进行学习. 这一步的工作需要耗费大量的人力物力,并且根据标记人员经验的不同,所标注的磨粒类型也会有所不同. 对于标注所用工具一般要区分领域,如文本类数据可用doccano软件进行标注;而对磨粒这种二维图像数据而言,则可以采用labelme软件. An等[41]在其Mask R-CNN磨粒识别研究中就采用了labelme进行数据集的标注,图5为用labelme标注好的磨粒图谱.
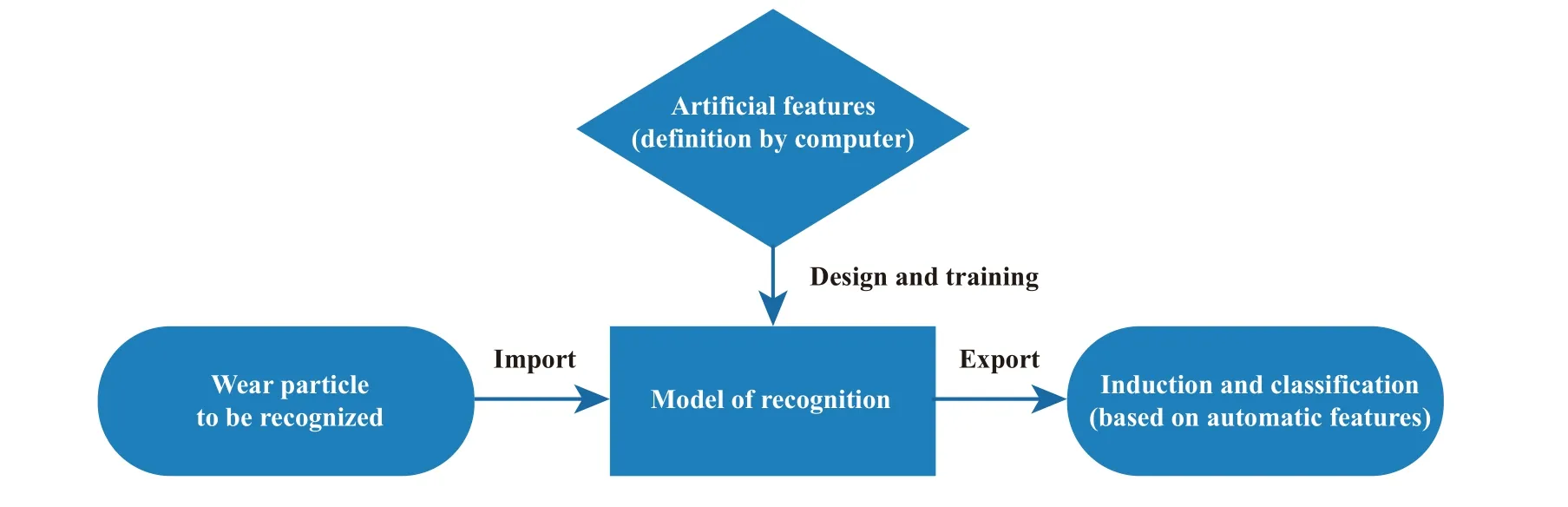
Fig. 4 Principle of automatic features recognition图4 自动特征识别原理
2.1.2 迁移学习
迁移学习(Transfer learning)的主要定义是将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中. 迁移学习主要解决三方面的问题,首先是源任务与目标任务的特征不一样的问题;然后是数据的分布不一样的问题;最后是标注标签的代价很大或很难被标注的问题[42]. 其提出的背景在于随着深度学习的逐渐发展,现有的性能表现比较好的模型需要越来越多的训练数据进行训练,这些巨量的训练数据需要耗费非常多的人力物力,所以迁移学习逐渐受到越来越多的关注,这在磨粒识别领域尤为重要[43].
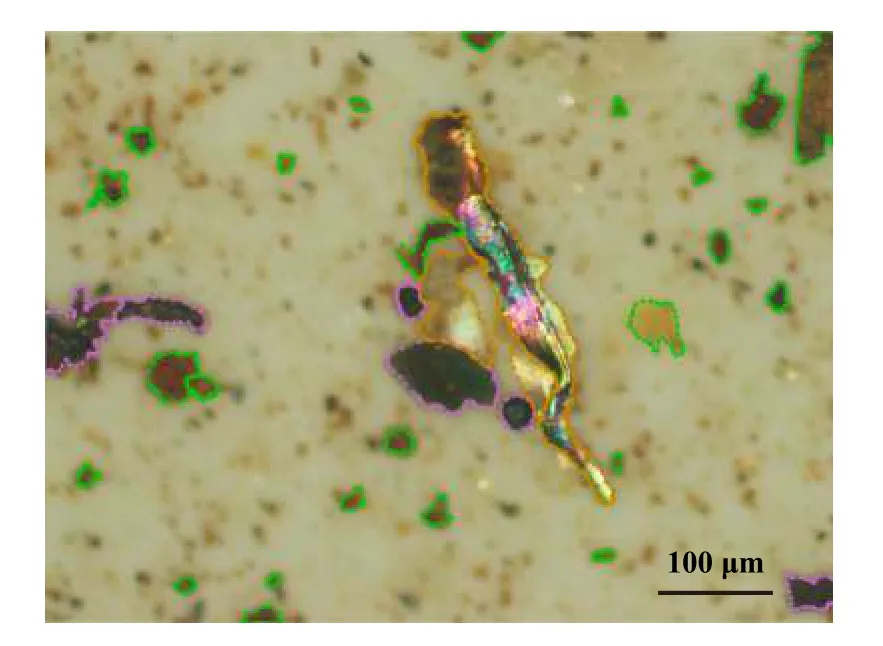
Fig. 5 Marked Ferrography[41]图5 已标注的磨粒图谱[41]
Peng等[44]通过两个试验对迁移学习在磨粒识别中的作用做出了论证. 试验1中将切削、球状、疲劳和严重滑动类型的磨粒分别用RGB (Red-Green-Blue)、HOG(Histogram of Oriented Gradient)、LBP(Local Binary Pattern)、CNN(Convolutional Neural Networks)和经过迁移学习预训练的CNN进行特征提取,结果显示RGB、HOG和LBP无法区分该4种类型磨粒,CNN只能区分切削和球状磨粒,无法区分疲劳和严重滑动,而经过迁移学习预训练的CNN模型则能很好地区分以上4种类型磨粒,精度较高. 试验2中比较了CNN、CNN-SVM(Support Vector Machines)、CNN-TL(Transfer Learning)
和CNN-TL-SVM模型识别同一批样本的精度. 从识别精度上来看,经过了迁移学习预训练后CNN模型精度远胜于CNN和CNN-SVM两者. 由此可见,迁移学习在提高识别精度方面起到了极大的作用.
2.1.3 数据增广
数据增广技术是1种能够把有限的数据集通过平移、旋转和缩放等变换操作然后加入到训练集中,一方面这可以扩充训练集,另一方面也提高了算法的鲁棒性,减少了过拟合的风险[45]. 深度学习早期或更早之前常用的数据增强方法大概有图像裁剪缩放、图像线性变换、图像镜像和颜色空间变换等[46]. 后来陆续有一些新方法出现,如随机擦除算法[47]通过用随机值替换图像中某块区域中的像素值用以生成不同的模拟图片. 还有混类增强算法,如2017年Zhang等[48]提出的mixup方法,通过对图像进行混类叠加来达到数据增强的效果,后续还有研究者提出了mixout方法[49]和cutmix方法[50]等;目前最新提出的FMix方法[51]将图像按照高低频进行区域区分,再进行分像素加权,从而对数据增强,是目前最先进的混类增强算法.
在磨粒识别领域中,由于铁谱图像稀少,导致训练样本稀少,所以如何增加铁谱图像的数量一直是各个研究者需要考虑的问题. 多数研究者采用图像裁剪缩放和水平翻转的方法进行铁谱图像增广[41,52-53];还有少数如Wang等[54]根据粒子的产生机制和独特的粒子特征,利用条件生成的对抗网络合成虚拟故障粒子图像;Peng等[55]提出了1种基于图像斑块置换的数据增广算法,将1张铁谱图像分为4份,以排列组合的方式增广至24张图像. 可见数据增广技术已经在磨粒识别领域得到广泛应用,并成为研究亮点之一.
2.1.4 Dropout技术
当对卷积神经网络的层数加深的时候,经常会因为模型参数过多,训练集数量过少,而出现过拟合问题[56],即模型在训练集上识别准确率高,但在测试集上准确率却很低的问题,这是特征检测器的共同作用使得检测器之间相互依赖造成的,这往往需要消耗大量时间对多个模型进行组合训练. 2014年,Srivastava等[57]提出了Dropout,前向传播的过程中特征检测器有随机的概率会被随机丢弃,这相当于同时对多个模型组合训练的简化,故而能防止过拟合又不会消耗过多时间. 还有观点认为Dropout实际上是1种数据增强的技术,2016年,Bouthillier等[58]将利用原始数据从模型中得到的Dropout噪音投影回模型中,生成了原始训练数据的增强数据,并用增强数据训练出和原始数据类似的结果. Dropout技术的出现使得深层卷积神经网络得到进一步发展.
目前Dropout技术在磨粒识别中已经得到了广泛应用,其中Peng等[59]在2019年提出的FECNN磨粒识别模型论文中对Dropout技术做了具体阐述,文中提到Dropout技术通常用于全连接层,以避免模型的过拟合,而FECNN模型则创造性地将其用于卷积层中使模型能够学习到磨粒的不完整特征. 由此可见,Dropout技术在磨粒识别模型中的准确运用将能很好地提高模型的识别效率.
2.1.5 归一化
由于深度学习中的神经网络层数众多,每层数据的更新都会导致上一层数据的分布发生很大的变化,所以需要使用归一化的方法将所有数据分布映射到1个区间. 归一化指的就是将数据统一映射到[0,1]的区间上,从而提高模型的收敛速度和计算精度. 另外也能避免由于输入变量的数量级过大而导致数值发生问题,但数据需要量纲化和统一评价标准. 其在卷积神经网络模型中最主要的作用是防止梯度爆炸和防止梯度消失. 在神经网络中,常用的归一化方法有Batch Normalization (BN)[60]、Weight Normalization (WN)[61]、Layer Normalization (LN)[62]、Instance Normalization(IN)[63]、Group Normalization (GN)[64]和Switchable Normalization (SN)[65]. BN适用于较大的Batch size(单次训练数据样本抓取量). 2016年,He等[20]就是通过BN的方法解决了深层卷积神经网络难以训练的问题,设计出了ResNet残差网络模型. 但当批量很小的时候,BN操作的效果将大大降低. 而WN则相反,适用于较小的批量;LN则对循环神经网络特别有效;IN对单个样本单个通道的所有元素进行归一化,主要作用是图像风格迁移;GN将通道分组后进行归一化,摆脱了批量的约束;SN的归一化策略则是将BN、LN和IN相结合,赋予它们不同的权重,然后通过神经网络自行学习以使得BN、LN和IN三者达到最适合的权重配比.
目前在磨粒识别领域中,一般采用BN进行归一化,例如Wang等[54]的三维磨粒识别网络、Peng等[53]的WP-DRnet网络以及Zhang等[52]的CDCNN网络中均采用了BN归一化方法. 2020年,Peng等[66]提出的OWSNet粒子分割网络研究中,对BN和IN及两者结合在OWSNet粒子分割网络中的表现进行了试验,验证了BN和IN对OWSNet 具有提升效果,以及在磨粒分割任务中批量较小时IN的效果比BN好,并指出IN和BN的结合可以使模型解决不同领域的图像分割问题.
2.2 基于现有网络结构的磨粒自动识别模型
2.2.1 基于LeNet-5的磨粒自动识别系统
LeNet-5是LeCun在1988年提出的卷积神经网络模型,也是最早的真正意义的卷积神经网络,其特点在于参数较少,这是由其局部连接和权值共享的特性所决定的. 但由于其对具有复杂纹理特征的数据集的分类精度不够高[67],所以若要将其应用于磨粒智能识别中,必须首先对其进行改进.
2018年12 月,Wang等[68]参考了图像识别领域的技术,创新性地将基于卷积神经网络的图像识别模型与磨粒分析联系起来,提出了1个两级磨粒识别模型,其中第一级采用反向传播神经网络对4组近似度不高的颗粒进行识别,第二级则采用LeNet-5改进的卷积神经网络模型对两组近似度较高的磨粒进行分析. 该模型使得磨粒识别的准确率从过去的40%多提高到80%多,其结构如图6所示.
从结构上看,该模型主要的优点在于:
1、在第二级识别模块中首次采用了卷积神经网络进行磨粒智能分析,可以有效地从大量样本中学习相应的特征,避免人工干预,且其局部感知和权值共享的特点大大提高了计算效率和准确度.
2、对所采用的LeNet-5网络进行了有效的改进,主要包括:(1)用ReLu激活函数替代了原来的Tanh和Sigmoid函数,减缓了梯度消失的问题,使模型能学习样本中更深层的特征,大大提高了识别准确率;(2)在全连接层中加入了Dropout运算,加强模型的泛化识别能力,减少了过拟合问题;(3)删除了F6层精简了网络,同时增大卷积层的卷积核大小和神经元数量,使其更适合于磨粒识别;(4)限制了同时训练图像的数量以防止局部最优和内存溢出.
主要的缺点在于:
1、第一级识别模块中采用反向传播神经网络对磨粒进行识别,需要大量训练样本才能达到较高的准确度,在训练样本不足的时候可能会影响到总体的识别准确率.
2、Zhang等[52]在介绍中指出该类通过卷积神经网络提取特征然后通过全连接层进行分类的模型以及通过支持向量机分类的模型等无法识别训练中没有出现过的新类别磨粒,当有新类别磨粒需要识别,必须再次更改模型结构并重新训练.
3、Peng等[53]在介绍中指出该类通过卷积神经网络提取特征然后通过全连接层进行分类的模型以及通过支持向量机分类的模型等无法进行目标检测,所以需要事先对磨粒进行分割,且无法解决识别磨粒链和重叠磨粒困难的问题.
4、第二级识别模块中删除LeNet-5的F6层的做法虽然精简了网络,但可能会导致该模型处理非线性问题的能力很差.
2.2.2 基于inception-v3的磨粒自动识别系统
Inception-v3是由谷歌开发的一款深层卷积神经网络模型,深层神经网络能够提取更多高级特征从而提高识别能力,并且最大的特点是采用正则化方法提高了模型的学习效果,故而备受推崇.
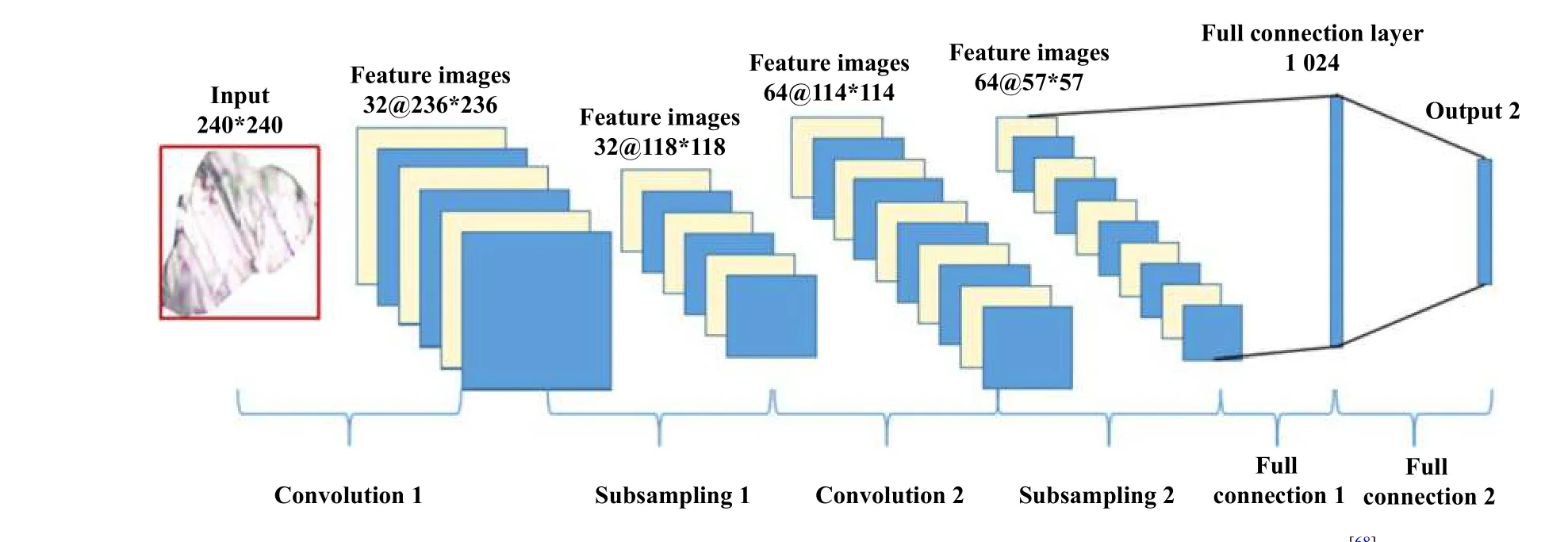
Fig. 6 Schematic diagram of an particle automatic recognition system based on LeNet-5[68]图6 基于LeNet-5的磨粒自动识别系统结构示意图[68]
2019年1月,Peng等[69]设计了1个改进的inceptionv3卷积神经网络磨粒识别模型,其主要结构为保留卷积层和池化层用于磨粒特征提取,将最后两层全连接层替换为自设计的人工神经网络用于磨粒分类. 其新设计的人工神经网络将CNN层提取的特征进行分类,采用Sigmoid激活函数输出结果,当结果超出设定阈值时可输出多个结果,从而达到对重叠粒子的识别.在对模型的训练方面则应用随机梯度下降算法优化交叉熵损失函数,更新人工神经网络模型的权重和偏差. 其结构如图7所示.
从结构上来看,该模型主要的优点在于:
1、第一级模块采用了卷积神经网络,能对复杂图像进行高效的非人工干预的特征提取.
2、用自设计的人工神经网络替换Inception-v3中的全连接层,大大降低了计算机的运算量.
3、在人工神经网络中采用了Sigmoid激活函数,避免了输出结果的归一化,从而实现了重叠粒子的识别.
4、采用Inception-v3提取特征,其池化层采用最大池化策略,能够更好地提取磨粒表面纹理.
主要的缺点在于:
Peng等[53]在介绍中指出该类通过卷积神经网络提取特征然后通过全连接层进行分类的模型以及通过支持向量机分类的模型等不具备目标检测能力,本质上只是1种“图像分类器”,面对多磨粒图像,需事先进行磨粒分割,即使能够识别重叠粒子,但若在1张图中有多个重叠磨粒的时候仍然需要对这些重叠磨粒进行划分.
2.2.3 基于AlexNet的磨粒自动识别系统
2019年5 月,Peng等[44]首次将迁移学习运用到卷积神经网络磨粒识别系统中,减小了卷积神经网络模型对磨粒训练样本的依赖,在较少训练样本的情况下达到了较高的准确率,另外将SVM集成到卷积神经网络模型中,提高了疲劳和滑动磨损碎片之间的识别精度[70],成功建立了1种新的模型来识别类型的磨损颗粒. 该模型的核心在于以下三点:(1)以AlexNet网络为基础,作出了将Softmax分类器更换为SVM分类器的改进,在利用CNN强大的特征提取能力的同时吸取SVM更强的泛化能力;(2)采用了包含120万个样本的Image Net数据集通过迁移学习技术来初始化模型权重;(3)采用了“一对一”方法的SVM分类器,即每两个类别之间建立1个SVM分类器,将该两类标记好的数据放入该分类器训练直到能完全区分开. 其结构如图8所示.
从结构上来看,该模型主要的优点在于:
1、采用最大池化,避免了平均池化的模糊化效果,从而保留最显著的特征,并且其步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提高了特征丰富性,减少了信息丢失.
2、采用ReLu作为激活函数,成功解决了Sigmoid在深层网络时梯度弥散的问题.
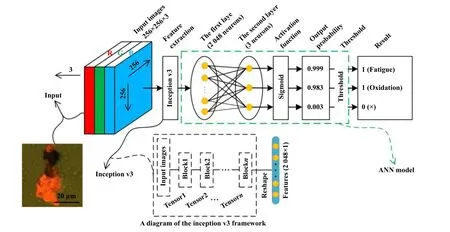
Fig. 7 Schematic diagram of an particle automatic recognition system based on Inception-v3[69]图7 基于Inception-v3的磨粒自动识别系统结构示意图[69]
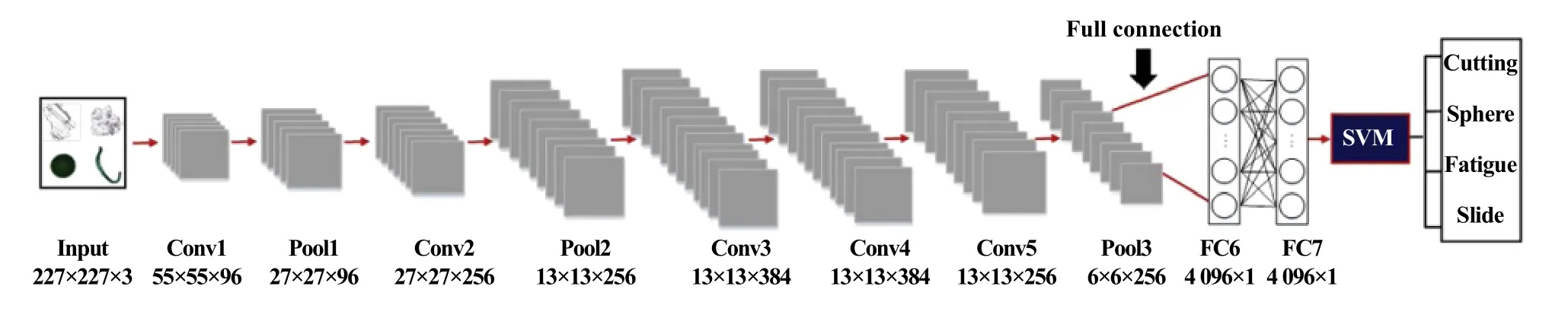
Fig. 8 Schematic diagram of an particle automatic recognition system based on AlexNet[43]图8 基于AlexNet的磨粒自动识别系统结构示意图[43]
3、添加了归一化LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力.
4、采用Dropout方法随机忽略部分神经元,避免模型过拟合,增强模型的泛化能力.
5、采用了迁移学习的技术,大大减少了训练所需样本量.
6、采用SVM分类器,使模型具有更强大的泛化能力,解决了局部最优解的问题,同时减少了训练所需样本量. 并且所采用的“一对一”方法的SVM分类器能够解决非线性问题.
主要的缺点在于:
1、“一对一”方法虽然能够使SVM解决多分类问题,但缺点是类别较多时非常耗费计算资源[71],而且可能会造成分类重叠现象,即每个分类器都认为识别物体属于它所设定的正样本.
2、Peng等[53]在介绍中指出该类通过卷积神经网络提取特征然后通过全连接层进行分类的模型以及通过支持向量机分类的模型等不具备目标检测能力,本质上只是1种“图像分类器”,面对多磨粒图像,需事先进行磨粒分割,且无法解决识别磨粒链和重叠磨粒困难的问题.
3、Zhang等[52]在介绍中指出该类通过卷积神经网络提取特征然后通过全连接层进行分类的模型以及通过支持向量机分类的模型等无法识别训练中没有出现过的新类别磨粒,当有新类别磨粒需要识别,必须再次更改模型结构并重新训练.
2.2.4 基于Mask R-CNN的磨粒自动识别系统
2020年,An等[41]和Yang等[72]等先后独立采用Mask R-CNN模型训练出磨粒自动识别系统. An等所采用的Mask R-CNN神经网络结构包括特征提取层、特征金字塔网络、ROIAlign层和全连接层,特征提取层采用ResNet101残差网络,优化器采用随机梯度下降法来更新模型参数. 另外An等还采用COCO训练集[73]对模型进行迁移学习,也采用数据增广方法来增强数据的丰富度. 而Yang等同样直接采用Mask R-CNN模型训练出磨粒自动识别系统,其随机梯度下降优化器带有动量,可以缓解局部最小值的问题,该方法能够加快模型的训练速度同时保证稳定性,是目前随机梯度下降法中最常用的优化方法之一[74-75]. Mask R-CNN的结构如图9所示.
从结构上来看,该模型主要的优点在于:
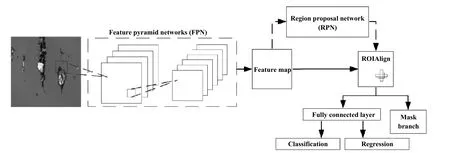
Fig. 9 Schematic diagram of an particle automatic recognition system based on Mask-RCNN[41]图9 基于Mask-RCNN的磨粒自动识别系统结构示意图[41]
1、加入了Mask网络,使模型不仅能处理目标检测问题,还能处理语义分割问题.
2、采用了ROIAlign,将特征金字塔网络中提取到的候选区域转化为固定维度的特征向量,大大提高了小目标的分割准确性.
3、采用了FPN特征金字塔网络,其作为1种多层结构有利于多尺度物体及小物体的检测.
4、特征提取层采用了ResNet101残差网络,可以解决网络层数过深时梯度消失和梯度爆炸的问题.
主要的缺点在于:
1、对于每个ROIAlign层之后的proposal层只进行上采样到28*28的分辨率再输出mask,这个精度对于绝大多数物体并不足够,对磨粒识别也是不够的.
2、Mask-RCNN属于two stage类型网络,训练和识别速度比不上one stage类型的网络,无法满足实时颗粒识别的要求.
2.3 自设计卷积神经网络的磨粒自动识别系统
2.3.1 FECNN磨粒自动识别系统
2019年7月,Peng等[59]提出了1种称为FECNN的卷积神经网络模型,用于识别复杂铁谱图像中的磨损颗粒. 它通过一维卷积运算减少了模型的数量参数和Dropout技术使模型能够学习磨损碎片的不完整特征.该模型能够得到比以往更准确的分类结果,并能减轻样本收集的工作量. 该模型具有较强的特征提取和磨损粒子分类能力,是1种很有前途的磨损粒子识别系统. 其结构如图10所示.
从结构上来看,该模型主要的优点在于:
1、采用ELU激活函数替代ReLu函数,解决了ReLu函数的输出不是零中心的问题,以及学习率过大时神经元无法激活的问题,且在图像过多噪音的情况下比ReLu更具鲁棒性.
2、采用了一维卷积运算来减少模型的参数,减少过拟合现象,同时可以在不改变图片尺寸的情况下改变通道数.
3、在模型中加入了dropout运算,通过随机将输入的张量中的某些元素设置为0,破坏了磨损粒子的某些特征,从而使模型能够学习到不完全的磨粒特征,从而增强磨粒识别的泛化能力.
4、在Tensor9层中采用了全局最大池化,降低卷积层输出的特征图维数,以取代分类器中的Flattening或Dense层,最大限度保留了磨粒的表面纹理. 其后的全连接层有1个sigmoid激活函数用于表示每种磨损颗粒的概率,从而达到重叠粒子的识别.
主要的缺点在于:
1、采用的ELU激活函数计算量比ReLu大,其表现并不一定比ReLu好[76].
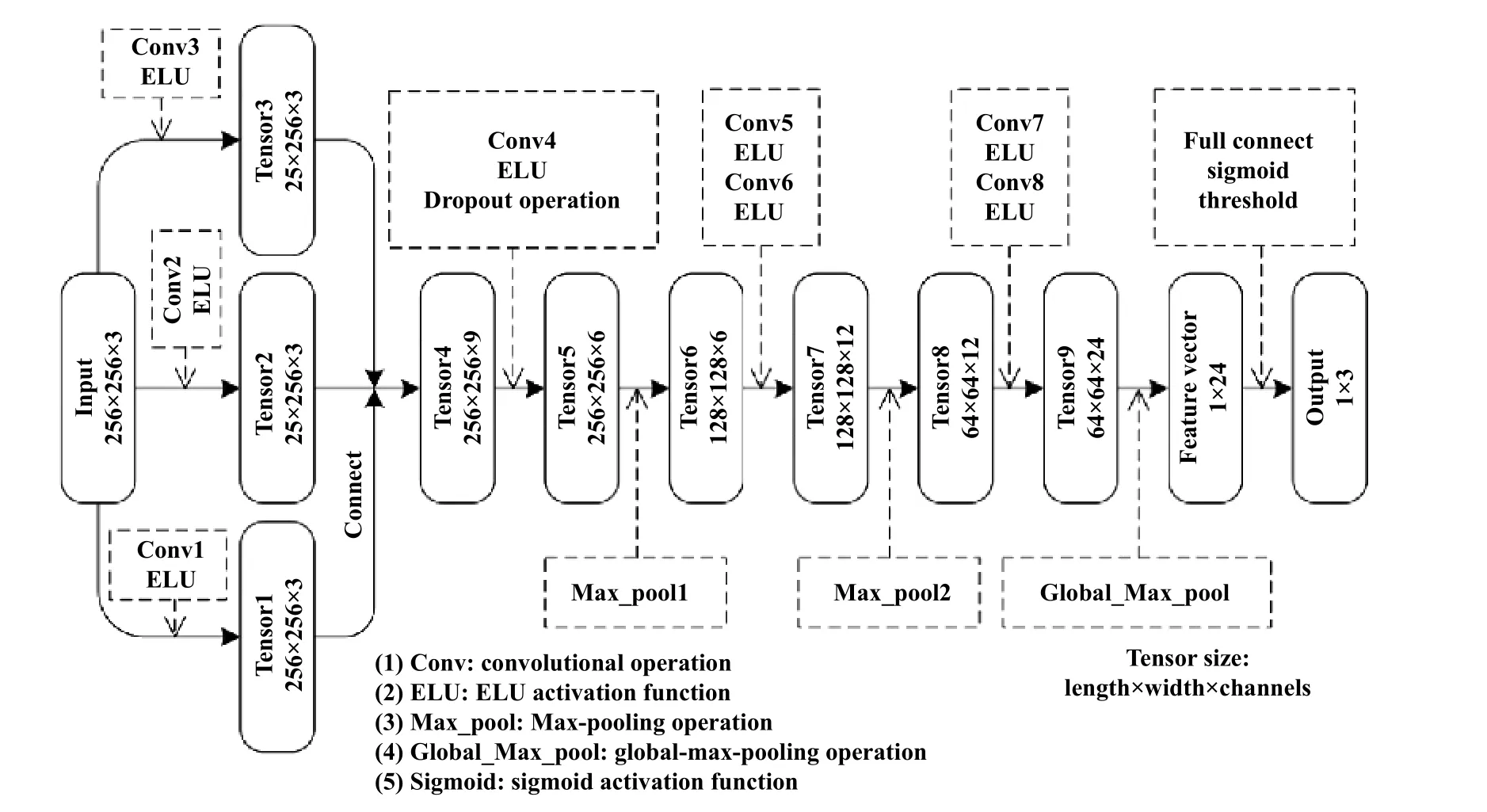
Fig. 10 Schematic diagram of FECNN particle automatic recognition system[59]图10 FECNN磨粒自动识别系统结构示意图[59]
2、Peng等[53]在介绍中指出该类通过卷积神经网络提取特征然后通过全连接层进行分类的模型以及通过支持向量机分类的模型等不具备目标检测能力,本质上只是1种“图像分类器”,面对多磨粒图像,需事先进行磨粒分割,即使能够识别重叠粒子,但若在1张图中有多个重叠磨粒的时候仍然需要对这些重叠磨粒进行划分.
3、Zhang等[52]在介绍中指出该类通过卷积神经网络提取特征然后通过全连接层进行分类的模型以及通过支持向量机分类的模型等无法识别训练中没有出现过的新类别磨粒,当有新类别磨粒需要识别,必须再次更改模型结构并重新训练.
2.3.2 小规模卷积神经网络磨粒自动识别系统
2020年2月,Wang等[77]提出了在其研究中构建了1种小规模卷积神经网络,该网络包含1个输入层,4个卷积单元,2个全连接层和1个输出层,其中每个卷积层后面都带有1个ReLu激活函数用于提高模型的非线性拟合能力. 第一、第二和第四个卷积单元由卷积层和最大池层组成,第三个卷积单元只有1个卷积层. 经过第四个卷积单元后得到的所有输出数据被输入到之后的2层全连接层,最后使用softmax函数进行分类以处理非线性问题. 其结构如图11所示.
从结构上来看,该模型主要的优点在于:
1、采用了多层小核卷积,可以在保持与大卷积核相同的感受野(Receptive Field)的同时,保持较少的参数量和计算量,提高图像处理效果. 同时减少卷积核输入和输出通道的数量,以进一步减小模型大小.
2、采用了恰当的神经网络深度以最大限度减少计算量并缩小模型的同时保证识别精度.
3、将模型小规模化的同时基本没有影响到精度,有利于磨粒识别系统在便携设备或CPU等端部运行,符合未来的发展方向.
主要的缺点在于:
1、该模型不具备目标检测能力,遇到具有多类型磨粒的图像需要分割后再进一步识别.
2、该模型采用的Softmax分类器的多标签识别能力较差,即无法应付重叠粒子的问题.
2.3.3 CDCNN磨粒自动识别系统
2020年6月,Zhang等[52]提出了1种基于类中心向量和距离比较的卷积神经网络模型,称为CDCNN. 其最大的特点在于,磨粒自动识别领域中,该模型首次做到了在测试集中加入新类,并保持很高的识别准确率. 该模型由3个模块组成,分别是特征提取模块、类中心向量提取模块和预测模块. 通过这3个模块组成的模型,可以实现新类磨损颗粒的分类.
首先是特征提取模块,该模块基于ShussleNet[78]模型结构,将输入图像转换为特征向量. 该模块利用采样单元通过“通道重组(channel shuffle)”操作将输入特征映射的信道数均匀地划分,输出2个信道数相等的特征映射,并将普通卷积运算分解为深度卷积和点卷积运算,减少了模型参数的数量,提高了模型训练的速度,并提供了效率和精度的平衡.
然后是类中心向量提取模块,类中心向量指的是某一类别的代表,该模块设定每个类中生成3个类中心向量以应对同一类样本可能存在的差异. 在后续可以通过加入训练新类来使其可以对新类进行识别而不改变现有的模型.
预测模块通过计算“比较集”的特征向量与“代表性集”的类中心向量之间的距离,并根据计算的距离获得后验概率,并通过CDCNN模型输出预测的类结果. 利用了2个损失函数之和来训练模型,分别是距离损失和交叉熵损失. 其结构如图12所示.
从结构上来看,该模型主要的优点在于:
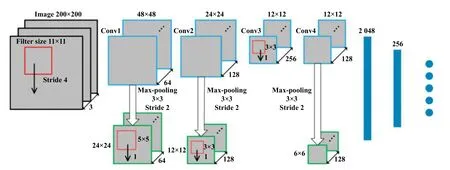
Fig. 11 Schematic diagram of small-scale convolutional neural networks particle automatic recognition system[77]图11 小规模卷积神经网络磨粒自动识别系统结构示意图[77]
1、采用了逐点组卷积(PWConv)和通道重组(channel shuffle)这两种操作,改善了分组卷积时各组间“信息流通不畅”的问题,并在保证准确度的同时能够大幅度地减少运算代价.
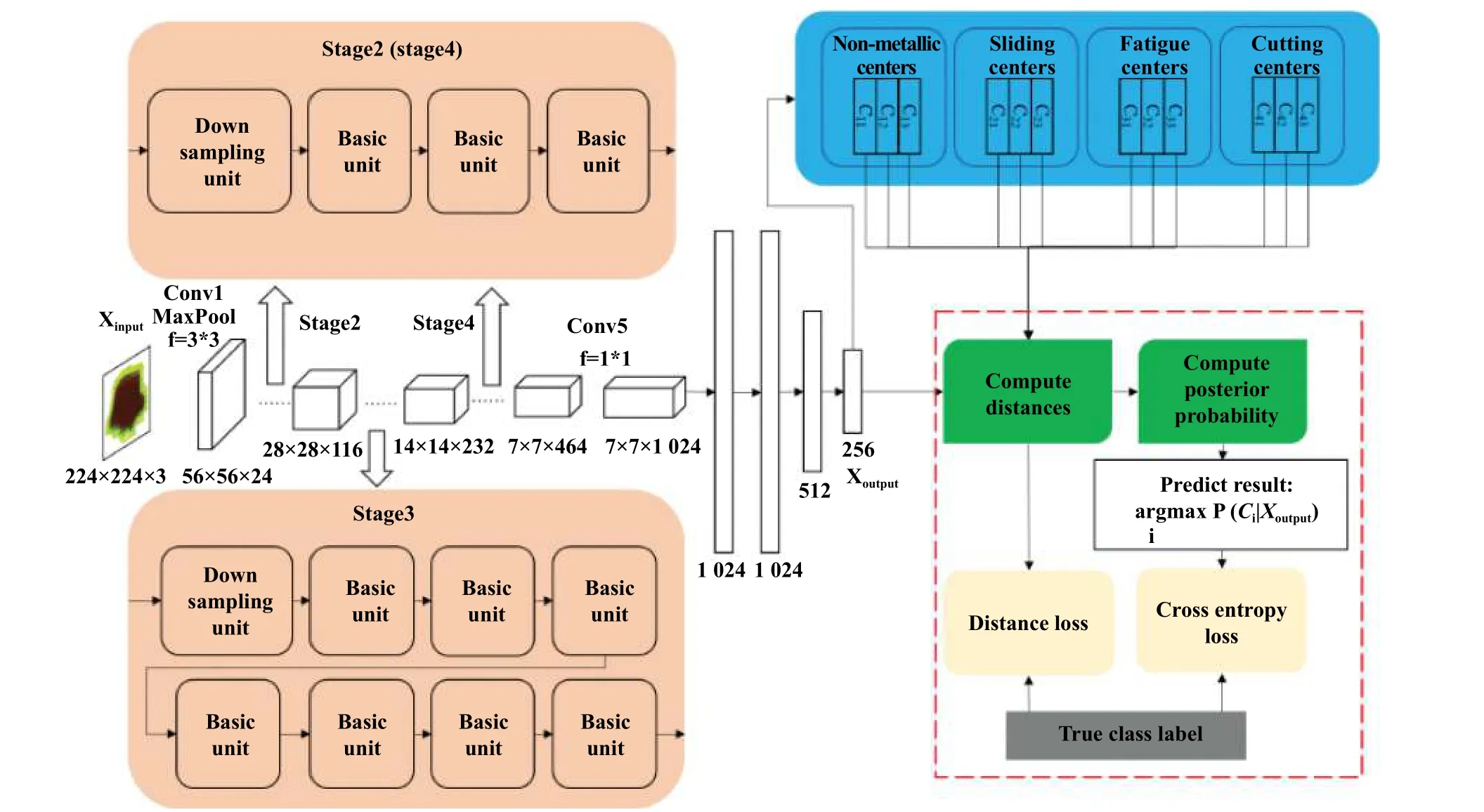
Fig. 12 Schematic diagram of CDCNN particle automatic recognition system[52]图12 CDCNN磨粒自动识别系统结构示意图[52]
2、结构精简,作为轻量级网络非常适合于便携设备中运行,并能保证非常高的精度.
3、当出现新类时,不需要重新对网络进行训练,只需要添加类中心向量即可.
主要的缺点在于:
1、shuffle channel在工程实现时会占用大量内存和指针跳转,这部分非常耗时,实际运行速度可能不会太理想.
2、shuffle channel的规则是人工设计的,分组之间信息交流存在随意性,没有理论指导,不符合自动学习特征的基本原则.
2.3.4 WP-DRNet磨粒自动识别系统
2020年4月,Peng等[53]利用两个基于卷积神经网络的模块和支持向量机(SVM)分类器的级联,开发了1种自动磨损粒子检测和分类模型. 两个模块用于粒子的检测和识别,而支持向量机则用于粒子分类. 其中第一个模块称为粒子检测网络,可以检测并获取磨粒原始图像中粒子的存在及位置;第二个模块被称为粒子识别网络,可以识别疲劳、严重滑动、切削和球形等磨损.
该模型的粒子检测网络是基于YOLOv3中的darknet53网络设计而成的,而粒子识别网络则是2.2.3节中提及的基于AlexNet模型改进的网络,该模型称为WP-DRNet. 通过该设计,将粒子检测和识别时间缩短至23.4 ms,完全满足实时粒子分类的要求,是1种具有在线监测前景的磨粒自动识别系统,其结构如图13所示.
从结构上来看,该模型主要的优点在于:
1、采用了Darknet-53网络用于粒子检测模块中,实现了目标检测功能,对于多类别磨粒图像不需事先分割便可实现识别.
2、采用了Batch Normalization的数据归一化方法,加快了模型在训练时的收敛速度,避免了梯度爆炸或梯度消失. 此外该方法还能支持更多激活函数,增加泛化能力,替代已经过时的Dropout方法[60].
3、采用了Leaky ReLu激活函数,它是ReLu函数的1种改进函数,在反向传播过程中,对于Leaky ReLu激活函数输入小于零的部分,也可以计算得到梯度(而不是像ReLU一样值为0).
主要的缺点在于:
1、预测的bbox较少,导致召回率较低,定位精度较差,对于靠近或者遮挡的群体和小物体的检测能力相对较弱.
2、该模型作为本文2.2.3节模型的改进版,添加了目标检测模块使模型得到质的改进,但在粒子识别模块方面并无过多修改,更多的优缺点可参见本文2.2.3节.
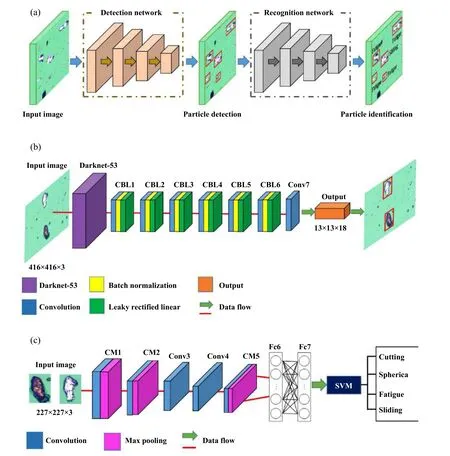
Fig. 13 Schematic diagram of WP-DRNet particle automatic recognition system[53] (A: WP-DRNet system;B: Detection network; C: Recognition network)图13 WP-DRNet磨粒自动识别系统结构示意图[53](A:WP-DRNet系统;B:检测网络;C:识别网络)
2.3.5 三维非参数磨粒自动识别系统
2020年9月,Wang等[54]设计了1个三维非参数的磨粒识别模型,选择深度图作为磨损颗粒形貌的映射方法,将三维磨粒信息转变为二维非参数信息,既保留了磨粒的三维表面信息,又减少了模型的计算量. 另外还详细说明了如何通过条件生成对抗网络来增加磨粒训练样本的数量,将生成粒子与实际粒子相比,评价其分布及表面特征的合理性. 此外,利用网络结构优化和训练方法建立了非参数粒子识别模型,并介绍了利用粒子图像标准化和网络可视化对网络进行进一步优化的方法. 本研究中为提高相似粒子分类效率提供了1种新方法,将有助于加强对机器磨损状态的分析,其结构如图14所示.
从结构上来看,该模型主要的优点如下:
1、采用了Leaky-ReLu激活函数,使得在反向传播过程中,对于LeakyReLU激活函数输入小于零的部分,也可以计算得到梯度(而不是像ReLU一样值为0).
2、采用了条件生成对抗网络生成及鉴定样本,以增加稀少样本的数量.
3、利用粒子图像标准化和网络可视化对识别网络进行了进一步优化,使其能准确识别所有测试的疲劳和严重滑动颗粒及其典型特性.
主要的缺点在于:
在粒子识别模块中,该神经网络同时使用Dropout和BN可能会得到更差的效果. Xiang等[79]指出,Dropout和BN之间冲突的关键是网络状态切换过程中存在神经方差(Neural variance)不一致行为,这种现象称为方差偏移.
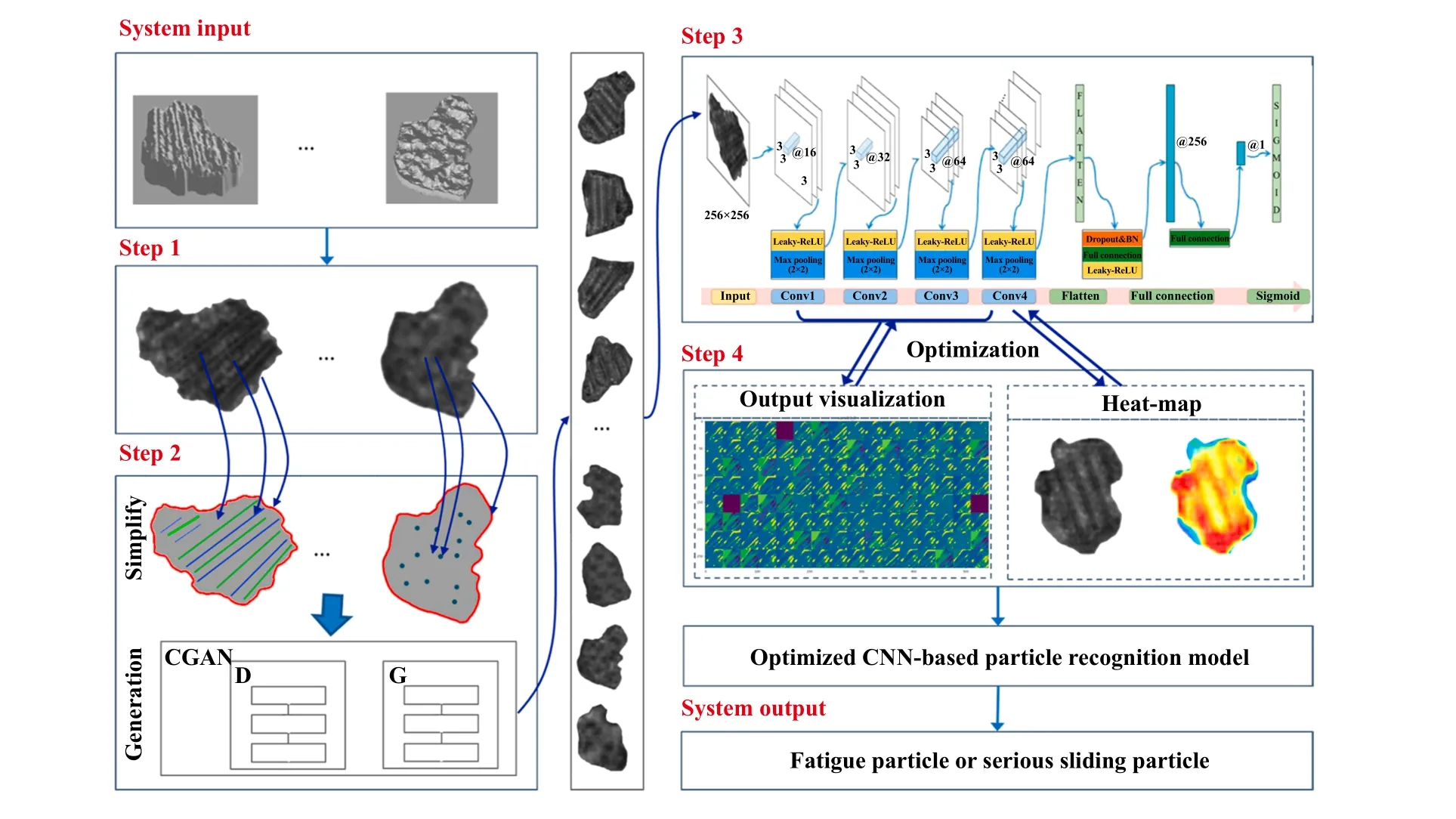
Fig. 14 Schematic diagram of non-parametric particle automatic recognition system[54]图14 三维非参数磨粒自动识别系统结构示意图[54]
2.4 磨粒图像的来源
当前磨粒图像数据较为缺乏,大多数磨粒智能识别研究所采用的图片数量在1 000张以内,且来源的系统种类也不多,对现实的参考意义稍低. 在以上的研究之中,磨粒图片最常见的来源是磨损试验机,一般会严格设计好磨损参数以达到仿真效果. 另外也有一些研究者采用来源于真实设备的铁谱图像数据,其中最引人注目的是采用真实设备的在线监测铁谱图作为数据源,这样的数据最具价值. 表2所示为第2节中有关基于卷积神经网络的磨粒识别模型的数据集情况简述.
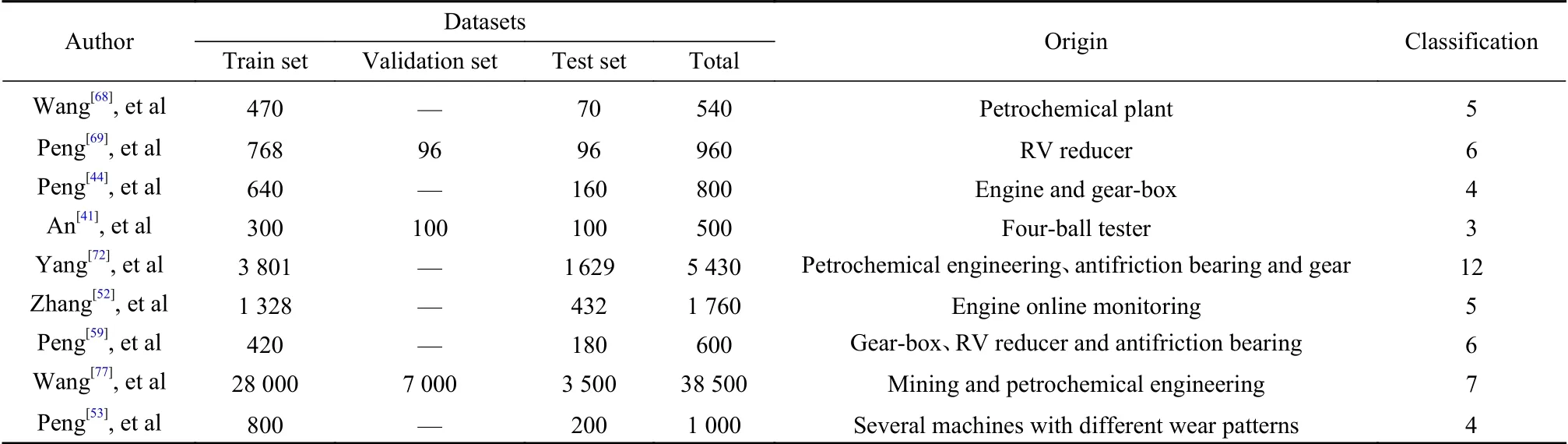
表2 数据集情况简述Table 2 Overview of datasets
3 磨粒智能识别的研究方向展望
很多年来,油液监测一直以离线监测为主,远远不能满足当今设备长时间连续运作的需要,因此在线监测成为了未来发展方向的热点之一,自然地磨粒智能识别就成为了在线监测的重要环节. 在线监测磨粒识别的工作其实早在2015年已经有学者在研究[80]. 随着卷积神经网络的兴起,很多有利于磨粒在线智能识别的技术也随之兴起,甚至不再局限于磨粒的识别.
3.1 设备磨损识别
由于磨粒碎片分析有其局限性,包括磨损碎片受冲击而变形,历史碎片积累以及外来污染物等的影响[81],所以近年来有研究者甚至已经不满足于使用卷积神经网络技术对磨损磨粒进行智能离线分析,而是直接就设备磨损表面进行特征分析. 例如,2020年,Chang等[82]提出了1种结合磨损表面复制成像和卷积神经网络自动评估磨损严重程度的新方法,用于齿轮磨损机制(一级推理)和严重程度(二级推理)的自动评估. 同年,Suh等[83]提出了1种用于轴承磨损的卷积神经网络,无阈值少量样本预测旋转机器健康状态,比其他有阈值方法预测得更早且更为有效. 磨损碎片识别和磨损表面识别并不是相互孤立的,在未来很有可能以1种相互辅助进行故障诊断的形式存在.
3.2 多源数据融合
获取磨粒信息不完全也是在线监测磨粒识别的难点之一. 从2017年开始就陆续有研究者提出利用卷积神经网络来实现多焦点图像融合,这样做的目的是可以提高照片的分辨率和协同多种传感器的优势获取更多磨粒图像信息. 如2017年,Tang等[84]提出了1种像素级卷积神经网络,它可以从源图像的邻域信息中识别出聚焦和离焦像素,用于多聚焦图像融合.2019年,Ma等[85]提出了1种基于深层神经网络的边界感知多焦点融合方法. 该方法利用残差网络,采用两通道模型直接从源图像中提取更多有用的信息,克服了很难直接捕获三维场景全聚焦图像的困难. 2020年,Wang等[86]总结了前人的方法,创新性地提出了1种新的基于卷积神经网络的多焦点图像融合方法以识别聚焦和离焦像素,在融合图像的视觉质量和客观评价方面取得最先进的结果. 此外,多传感器技术为在线监测提供了多方面的数据,但目前大多数基于卷积神经网络的智能监测系统却不能很好地将多方面信息利用起来,即不考虑特征融合. 近年来已经有学者在研究相关的问题,2020年,Xu等[87]提出了1种基于深度学习和多传感器特征融合的新型集成模型,在集成模型中开发的并行卷积神经网络(PCNN)可以实现多感官特征融合.
多源数据融合的发展为在线监测中磨粒图像的去模糊化和获取磨粒三维信息提供了参考,为未来在线监测磨粒智能识别打下了基础.
3.3 离焦图像复原
磨粒是1种三维实体,故而在图像拍摄过程中往往会出现离焦的情况. 若要对离焦的图像直接进行复原,在图像超分辨率领域早已有很多研究[88],但在磨粒识别领域上,离焦图象复原的研究则很少. 2019年,Peng等[89]提出用高斯模型得到背景,再用图像差分法将磨粒与背景分离,最后全方面提取了运动中粒子的二维和三维特征,但图像经过提取后经常出现不够清晰的情况,导致信息丢失. 2019年,Wu等[90]提出了1种基于卷积神经网络的恢复失焦磨损碎片图像的方法,能够恢复更多关于磨损碎片的特征,尤其是表面的细节. Du等[91]利用卷积神经网络,采用两种解决方案来增强图形细节和抑制噪声. 离焦图像复原的发展将推动多源数据融合的发展,从而推动整个磨粒智能识别的发展.
3.4 半监督学习
机器学习技术有三种,1种是有监督学习,另1种是无监督学习,还有1种是半监督学习. 有监督学习只用标注过的数据进行训练,无监督学习则只用未标注的数据,而半监督学习则用大量未标注的数据,少量标注的数据来进行训练. 正如前文所述,目前磨粒智能识别的模型训练需要大量已标注的训练集,而训练集的标注会耗费大量人力物力,同时由于每个人的经验不同,标注的训练集将带有一定的主观性,所以最好可以通过计算机半监督学习来将磨粒进行聚类[92].但目前有关磨损碎片识别领域的成果,主要都集中于有监督学习方面. 而半监督学习方面,2019年Li等[93]提出的基于深度学习的半监督齿轮故障诊断可以为磨损碎片识别提供借鉴. 事实上,半监督学习在其自身的领域有不少的成果,总体来说目前仍然处于初步发展阶段,而在磨粒识别领域则几乎没有任何进展,其发展对于磨损碎片识别领域极为重要,应关注其进展[94-95].
3.5 小结

Fig. 15 Research direction of wear particle intelligent recognition图15 磨粒智能识别研究方向
磨粒识别是设备在线监测的其中一环,也是重要的一环,磨粒识别朝着智能识别的方向发展,必然使得设备在线监测智能化. 磨粒智能识别未来的发展方向,不仅需要紧跟深度学习的发展方向,还要紧贴在线监测的发展方向[96]. 图15为磨粒智能识别未来的研究方向简图.
4 结论
磨粒智能识别为工业上的设备铁谱图像诊断提供了1个快速而又准确的方法,能够解放铁谱技术人员的生产力,并使铁谱图像的诊断客观化. 磨粒智能识别目前已经取得了显著的成果,总结近年来主要的磨粒智能识别相关成果得出以下结论:
a. 以卷积神经网络技术为基础的深度学习方法为主流的磨粒智能识别方案.
磨粒识别本质上是1种图像识别,自2012年以来,基于深度学习方法的图像识别技术大行其道,从而也引发了后面摩擦学研究者将深度学习的方法引入到磨粒识别中. 自2018年12月,Wang等率先发表了基于卷积神经网络的磨粒识别系统后,以卷积神经网络技术为基础的深度学习方法成为了磨粒智能识别的主流方案,并多次被摩擦学方面的国外高水平期刊如Wear和Tribology International等收录.
b. 人工标注图谱是制作磨粒训练集的主要方法,但耗费大量人力物力,且磨损颗粒的多样性不够. 目前制作磨粒训练集的主要方法是人工制作铁谱,然后拍摄铁谱图像,再采用人工的方法对铁谱图像中的磨粒进行标注. 这样一系列的工作过程均非常繁琐,其中以磨粒标注工作尤为耗费人力物力. 以某公司的磨粒标注工作为例,8名技术人员每天标注约2 h,1个月的时间大概能标注磨粒图谱1 000张,而1 000张磨粒图谱对训练识别模型来说是杯水车薪,而且相当一部分铁谱图像的磨损颗粒多样性不足,影响机器对某部分磨粒的识别效果.
c. 通过人工标注训练集磨粒的磨损类型,由计算机自行提取特征,尽管区别于以往的人工定义特征,但技术人员在标记样本时仍然存在主观因素. 在磨粒训练集制作的过程中,人工标注磨粒的环节具体的做法是需要技术人员手动标注出磨粒,并根据经验给出磨损种类,有经验的技术人员和无经验的技术人员对磨粒种类认识有一点的偏差,即使同样是有经验的技术人员,对于同一磨粒图像也会有不同的见解,而且铁谱图像具有磨粒链多、小颗粒多和重叠颗粒多的特点,再加上磨粒失焦问题,所以人工标注训练集存在很大的主观因素,违背了磨粒智能识别的客观性原则.
d. 磨粒智能识别在在线监测方向将是未来磨粒智能识别的应用方向之一. 摩擦学系统油液监测多年来采用离线监测为主,已经不能满足现代设备长周期连续监测需求,所以设备在线油液检测技术成为了当前设备润滑磨损失效诊断技术重要发展热点和趋势之一. 磨粒智能识别也应该以在线铁谱识别为主要的发展趋势以满足现代设备监测的要求. 但目前的研究大多数都是基于离线铁谱识别进行的,所采用的铁谱图像也大多数来源于离线铁谱,磨粒智能识别在在线监测方向的研究略显不足.
e. 必须紧跟深度学习图像识别的发展情况,才能保证磨粒智能识别水平领先. 磨粒智能识别本质上是1种图像识别,其发展依托于图像识别技术的发展. 磨粒智能识别领域的技术很长一段时间远远落后于图像识别领域,例如,图像识别在2012年已经得到突破性进展,研究者很快就发现卷积神经网络是目前图像识别的最佳选择,但直到2018年才有基于卷积神经网络的磨粒识别成果发表,中间的间隔依旧有不少采用传统的图像识别技术. 对磨粒的检测定位方面的目标检测技术也相对滞后.
作为摩擦学技术人员,很难像深度学习技术人员一样钻研图像识别的深层次技术,但应该时刻紧跟图像识别领域相关的进展,才能保证磨粒智能识别的水平领先.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
科技视界(2022年10期)2022-05-20
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
文萃报·周五版(2021年35期)2021-09-13
装备维修技术(2020年32期)2020-08-11
上海师范大学学报·自然科学版(2019年5期)2019-12-13
智富时代(2018年7期)2018-09-03
