
高校图书馆典型用户群体电子资源行为数据分析实证研究*
——基于创文图书馆电子资源综合管理与利用系统
2022-08-04 12:39刁羽薛红
新世纪图书馆 2022年7期
0 引言
随着互联网技术的发展以及大数据时代的到来,科研数据应用呈现开放共享的大趋势,电子资源已成为用户获取信息的主要来源。访问电子资源的行为数据能精准地反映出用户在教学、科研等方面的信息需求。一般而言,用户电子资源行为数据(以下简称“行为数据”)受用户信息素养与学术素养共同影响,通过用户浏览、下载、检索等行为,既可以反映用户在线检索技巧的熟悉程度和意识强弱,又可以反映用户对科研学科领域的熟悉程度,以及研究任务的学术深度。但是,行为数据的采集、整理、分析是一项艰巨的任务,目前业界很少有这方面的实证研究。为了践行这一目标,同时降低数据采集的广度及难度,本文通过具体案例,阐明如何通过对典型用户群体行为数据及其学历、职称、科研成果等相关数据的交叉融合分析,预测用户行为,显性化用户资源利用行为的规律与特征,以此实现电子资源与用户个性化需求的精准化、精细化对接,从而为推进图书馆学科服务向纵深化发展提供有益参考与借鉴。
1 基于创文系统的行为数据研究分析介绍
目前,业界对利用大数据进行个性化学科服务的研究和实践方兴未艾,笔者在实践中发现有以下难点:受人力、资源、技术设备等因素的制约,对于大多数高校图书馆来说,既难以广泛搜集全体用户的各方面数据,也难以分析处理大数据;学科馆员个人所具有的学科知识储备尚达不到用户对嵌入式学科服务的需求;学科馆员嵌入服务前没有形成服务预案或服务预案不完备,导致科研工作者对盲目式的嵌入服务有排斥心理。对于上述情况,行为数据正是解决这些难点的利器。该数据具有类型单一、价值密度高等特点。本文从创文图书馆电子资源综合管理系统(以下简称“创文系统”)入手,抽取典型用户群体中的具体案例,通过分析、挖掘其利用电子资源的行为数据,揭示出该群体利用电子资源的偏好、使用规律及研究的学科领域等特征,紧贴用户需求,以期为用户提供有准备、有目标、有内容的服务。这种服务模式有利于增强用户粘性、提高用户满意率,旨在在精准化、精细化、个性化的资源推荐过程中,进一步拓展图书馆学科服务的深度和广度。
1.1 研究群体
本文所指的典型用户群体是使用校外访问系统的频次位于前25%位的教师群体,并同时具备以下条件之一:在学校所属学科领域科研工作中具有较大影响力;副高及以上职称者;博士研究生;年度科研积分在教师群体中位于前25%。选取典型用户群体的优点在于:第一,该群体区别于全体用户,分析结果具有明显的区分度和针对性,能更准确地定位用户的需求,并在对重点群体实行重点跟踪服务的过程中,提高服务效率,提升服务内涵;第二,该群体对电子资源的高利用率能保证有足够的样本数量,同时使分析结果具备统计学意义;第三,高利用率也体现出该群体对文献资源的较高需求,利于与其建立良好的沟通机制;第四,该群体本身具备较强的科研工作能力及较高的学术影响力,能够对本文的研究起到积极的推动作用;第五,行为数据也反映了用户真实的信息需求,通过分析该数据,可以很好地跟踪用户的研究方向,并准确找到嵌入式服务的契合点。
1.2 研究系统
四川轻化工大学图书馆于2016年引入了校外访问系统,即创文系统。该系统可以让广大用户在校外随时随地通过各种前端设备(PC或移动设备)访问校图书馆购买或自建的、远程或本地的所有电子资源,同时该系统详细记录了具体用户利用电子资源时浏览、检索、下载的行为数据
。现阶段,绝大多数数据库都是基于校园网IP地址作身份认证的权限访问,学校网关Web日志中用户访问网络资源行为数据又包含有大量涉及个人隐私的敏感数据,因此难以从以上两个途径获取具有个体信息的访问电子资源行为数据。创文系统数据在一定程度上能体现出用户访问电子资源的总体情况并符合本文对样本数据的需求,因此,本文研究的数据源于从创文系统中提取的行为数据。与此同时,笔者前期已经实现了从创文系统的访问日志文件中提取用户行为数据,也详细介绍了行为数据的数据结构,以及如何对这些数据进行清洗,并最终将其存储在SQL Server数据库中的技术和方法
。
1.3 研究方法
本文以围绕典型用户群体为选取原则,提取主要研究方向为高性能硬质合金及金属陶瓷制备,具有高级职称、作为特殊人才引进的某中青年教师于2019年5月至2021年5月在创文系统上的行为数据为样本数据进行分析和挖掘。限于篇幅,涉及的重点在于该用户多维度的检索词分析过程。主要分析方法有以下几个方面:第一,通过对浏览、下载、访问等用户行为在时间轴上的计数,反映用户的总体访问特征;第二,分析用户的检索词,对检索词的基本构成进行归类,对用户输入的检索词进行分词处理;第三,利用Python统计词频,利用EXCEL计算检索词的检索次数、四分位数、众数等描述性统计量;第四,利用Pythoon和WorldCloud绘制高频检索词的词云图;第五,提取高频检索词,利用Python建立共词矩阵和相关系数矩阵,并用Gephi绘制知识图谱,揭示用户最感兴趣的学科领域;第六,结合中图法的相关类目进行关键词分析,对用户的检索词进行分析并优化,帮助用户更加精准地获取文献信息;第七,通过其他相关关键词分析,帮助用户拓宽研究思路。
4.交代时间、地点、人物或中心事件。《听潮》开头:“一年夏天……”交代事情发生的时间、地点、人物。《故乡》开头:“我冒了严寒……”时间、地点、人物和中心事件均有所交代。记叙类的文章多以这样的方式开头。
2 创文系统用户访问的时间规律和成果产出关系
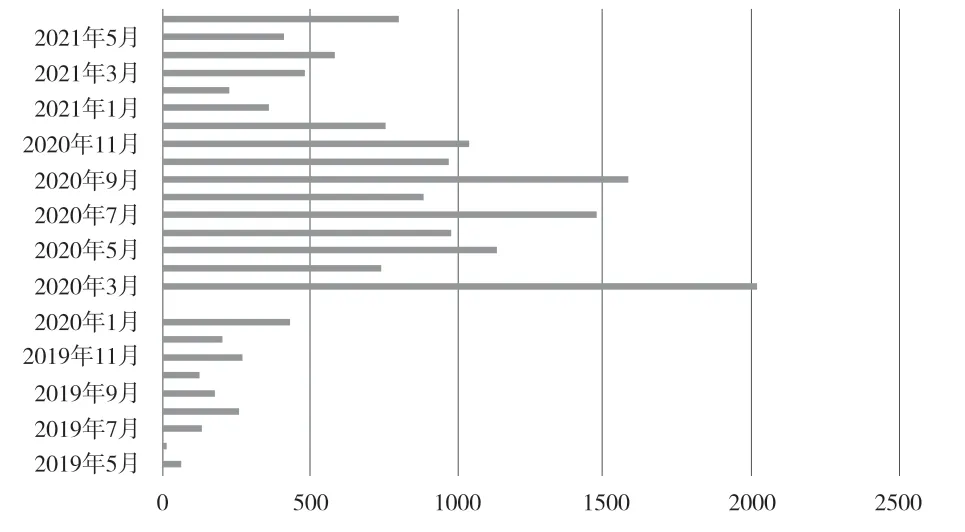
访问量的多少是反映用户利用电子资源意愿的直接指标。本文从时间维度进行统计,全面、直观地揭示出用户在2019—2021年的访问规律。从图1可以看出,该用户在2019各月份的访问次数最少,2020年各月份的访问次数最多,高峰期主要集中在2020年2月、7月、9月,即寒暑假期间,而2021年用户访问次数相对于2020年呈现下降趋势。同时,笔者在CNKI上进行检索,发现该用户在2019至2021年期间共计发文9篇,其中2020年5篇、2021年2篇。据呈现的状态可以推测出该用户的科研成果产出高峰与其年份访问高峰基本趋于吻合。由此可见,校外访问系统中的电子资源在用户科研过程中起到了较大推动作用;电子资源的访问频率能在一定程度上反映用户科研需求状态及科研成果的产出效率。
第二,在制定会计准则时,考虑不到不同利益集团的需要,注重基本原则的指导,同时要相应增加实施的细则,不能只依靠会计人员的经验。
3 创文系统用户访问的资源偏好
电子资源的偏好是体现用户检索特征的重要指标。本文通过对用户选择数据库的偏好、资源语种及浏览、检索、下载行为等进行统计发现如下情况。该用户选择的数据库中,知网占比达到了总访问量的96.12%;该用户访问的资源语种主要是中文,外文数据库的访问量只有0.6%。从该用户检索、浏览、下载的次数可以看出,用户进行1次检索后,平均只有4次查看了检索结果的详细页,有1.6次下载了文献。同时,用户在2年多的时间内下载了近4000篇文献。从浏览和下载的有效性及文献下载量来看,该用户的检索结果大多不尽如人意,可预测出该用户的检索意图多趋于模糊,检索结果难以契合用户本身的科研需求。
由此分析,需加强以下几个方面的工作:其一,对用户个体检索能力及科研需求内涵进行全面评估,在此基础上精细化培训方案,促使用户在有针对性的培训过程中提高检索效率,缩短科研周期;其二,优化电子资源的配置,加大电子资源宣传推广工作,提高电子资源的使用率,使其最大限度地满足用户科研需求;其三,对数据库商提出意见和建议,如进一步完善数据库检索界面、优化及增加平台检索功能,以期提升资源检索效率,促进用户满意度。
4 创文系统用户使用的检索词分析
4.1 检索词的构成分析
从提取的数据可以看出,用户的检索词由以下几种形式构成:第一,纯粹的专业术语,可能是一个或多个,如果是多个,使用空格、“+”“-”等符号组成,如“碳化+WC”;第二,语句式检索词,其包括专业术语和“如何”“浅谈”“发展”等无检索意义的词语,如“超硬材料行业的发展”;第三,单纯的以作者名为检索词或采用“作者+关键词”这种复合检索式,如“张立 硬质合金”;第四,文献篇名;第五,单纯以标准号检索或采用“标准号+关键词”这种复合检索式,如“GB/T 13313-2008 轧辊肖氏、里氏硬度试验方法”。
从检索词的构成分析中可以总结出该用户检索过程存在一些不足:使用类似百度等搜索引擎的检索表达式在CNKI中进行检索,导致查全率和查准率不高;检索作者时常常只使用作者名为检索词,导致检索结果过多且不精确;当有比较明确的检索点时,使用其他关键词反而会影响检索结果,如前文提到的“标准号+关键词”这种复合检索式;从未使用中图分类号作为检索词。
4.2 检索词的分词处理
用户每次检索使用的检索词常常由多个关键词构成,将每个关键词从检索词中分离出来是下一步进行具体关键词分析的必要前提。本文使用Python和Jieba
对用户的检索词进行分词。虽然Jieba是目前较为流行的分词库,但有以下几点需要注意,否则会产生大量分词错误的问题。第一,创建自定义词表。虽然Jieba使用HMM模型和Viterbi算法让自己具有一定的新词识别能力,但其自主学习的功能仍很薄弱,而且用户输入的检索词含有大量其研究领域的专业术语,如抛釉砖、炭相、石墨烯等,使用Jieba自带的语料库不能正确识别它们,因此需要添加自定义词典,并使用Jieba的load_userdict( )函数加载,这样才能确保Jieba正确识别上述词语。第二,处理特殊字符。因用户的专业领域涉及大量的分子式,如WC-Ti(C_N)-Co。这些分子式含有大量的特殊字符,若单纯地将这些分子式添加到自定义词表并不能生效,故要对Jieba根目录下的__init__.py文件和Jieba根目录下posseg文件夹中的__init__.py进行修改
。如此,才能让Jieba正确识别分子式中的特殊字符。第四,建立停用词表。用户检索词中包含大量“浅谈”等无检索意义的词语,分词时需要将这些词语剔除。故需要创建一个停用词词表,将分词结果与停用词表中的词语进行比较,然后从中删除存在于停用词表中的词语。第五,反复迭代。添加自定词典和创建停用词表是一个比较繁琐的工作,需要反复比较、反复迭代才能获得较高的准确性。
4.3 检索词多维度分析
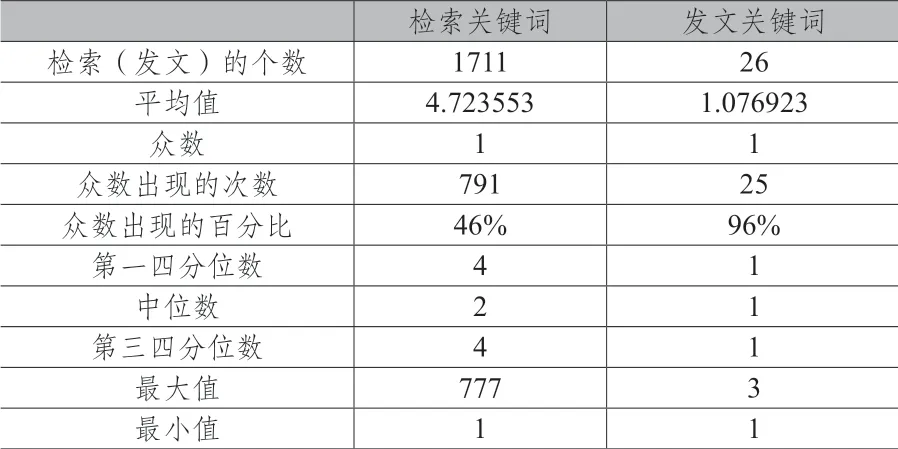
检索、发文关键词的对比分析能揭示出用户的科研方向与其检索文献的吻合度。表1显示:第一,从检索关键词看,其众数和最小值都是1,共有791次,占总检索关键词检索次数的46%,中位数为2,第三、四分位数是4。从发文关键词看,其众数和最小值都是1,共有25次,占总发文关键词出现次数的96%,以上数据推测该用户的研究方向可能趋于模糊;第二,用户的检索和发文出现最多次数的关键词是相同的,同时在用户发文关键词中,通过统计有20个是其检索文献使用的关键词,这些词在检索中最少出现次数是1,最多出现次数是777。通过检索、发文关键词的对比分析能帮助用户梳理、回顾整个研究过程中关键词的变化历程,同时可参考将用户发文关键词在检索时次数的多少作为判断推送文献的优先级的标准,以此实现文献的精准推荐。
后现代主义知识观认为,知识以其自组织性、不确定性、非线性和解释性,能够在教学中不断创生。知识并非像知识本体论认为的具有确定性,也非本体论规定的具有先验性。罗蒂(R Rorty)观点认为:教学任务不是简单的知识传递和道德教化的过程,教学该是即时创作,是师生的共同解读,知识能在动态的即时创作中变得鲜活。即时创作的教学观下,教师对知识的权威,学生作为知识的容器,以及教材是知识载体的看法不再成立。
词频显示了用户对检索词所对应的相关学科领域的关注度。结合Python 和Pandas 模块,可以方便地统计检索词分词后的关键词检索词频。统计词频的基本原理是将分词后的关键词转换为Series,然后调用Pandas 中的value_counts( )函数计算每个关键词出现的频次。在此基础上,为了更形象、直观地展示用户检索词的频次关系,本文使用Python 和WordCloud
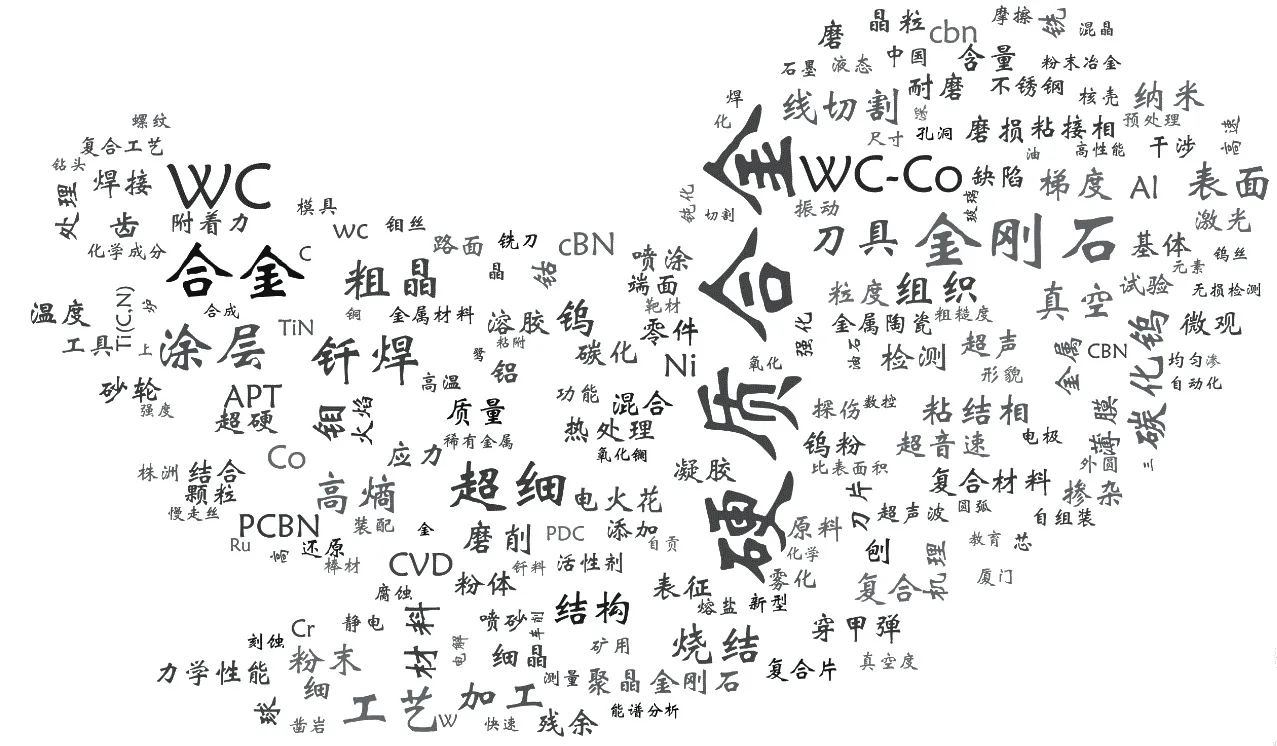
为检索次数≥5 的关键词生成 “高频关键词词云图”。词云图中关键词的字号大小代表了检索频次的多少。从图2 中可以清晰、直观地看出在该用户访问过程中,“硬质合金”“合金”“金刚石”“WC”“WC-Co”等是出现频率较高的关键词。将高频检索关键词结合用户的科研成果,可精准掌握其主要研究方向为“高性能硬质合金及金属陶瓷的制备”。通过高频关键词分析,可精确掌握用户研究方向,并在此基础上提前做好工作预案,使服务做到有的放矢。
本研究采用红茶浸泡除腥的方式,研究红茶脱腥处理对海螺肉感官和品质特性的影响,并对海螺肉中的挥发性成分进行分析。此外,实验以菌落总数为微生物指标,以TBA值、pH为理化指标,研究经红茶脱腥处理的海螺肉在贮藏过程中的品质变化,评价红茶脱腥处理对海螺肉的抑菌保鲜效果。
4.3.1 高频关键词分析,精准掌握研究方向
4.3.3 关键词共现分析,发掘研究方向
共现分析揭示了检索关键词之间的共现关系,它体现了用户感兴趣的不同学科领域之间联系的紧密程度。本文利用Python和Pandas库创建关键词共词矩阵和关键词相关系数矩阵,并选取检索词频≥20的52个关键词创建上述两个矩阵。
创建共词矩阵的主要步骤如下:
步骤一:使用set( )函数为这52个关键词创建集合。
步骤二:将用户每次输入的检索词分词后的结果存储为list列表。
for(i in1∶2 000){x=runif(n,0,1); y=(sum(x)-n×0.5)/sqrt(n/12); A[i]=y}
步骤三:使用pd.DataFrame(0, columns=key_set, index=key_set)语句初始化全0共词矩阵,其中的key_set参数的值为这52个高频关键词集合,目的是将它们指定为Dataframe的行、列索引。
步骤四:遍历用户检索词分词列表,并取其与高频词的交集。当交集的元素个数大于1时,表示高频词间有共词关系。
本文利用Ochiia系数
将共词矩阵转换为相关系数矩阵。Ochiia系数的计算公式如下:
其中,O
为Ochiia系数,N
代表检索词A和B同时出现的频次,N
和N
分别代表A检索词和B检索词出现的总频次。
当第一阈值在波峰1,2之间时,若不进行特征点一致性补偿,则特征点t2将会提前一个周期,在波峰5下降沿的过零点处,此时若要保证特征点一致则到达特征点时间应调整为t1;当第一阈值在波峰3,4之间时,若不进行特征点一致性补偿,则特征点t2将会滞后一个周期,在波峰7下降沿的过零点处,此时若要保证特征点一致则到达特征点时间应调整为t3。综上所述,到达特征点时间T应根据第一阈值所在位置选取为:
步骤五:两次遍历该交集的元素,外循环从第一个元素开始直到最后一个元素,内循环从第二个元素开始直到最后一个元素。
随着2016年我国加入华盛顿成员国,国内高校掀起工程教育国际认证的浪潮。工程教育认证中强调学生的实作技能,鼓励课程设计/毕业设计能出实际作品,鼓励学生以团队合作的形式完成,这是顶石(Capstone)的基本要求。3D打印技术是实现产品从电脑屏幕到实物最为便捷的方式,具有时间和成本优势,从而备受关注和学生喜爱。从专业认证的发展需求看,3D打印技术在高校中的应用将逐步扩大。
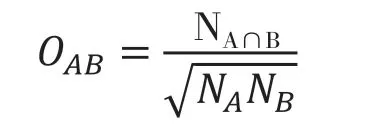
步骤六:遍历时,首先将共词矩阵行、列索引分别与外、内循环的元素名相同的位置元素的数值加1;然后将共词矩阵列、行索引分别与外、内循环的元素名相同的位置元素的数值加1。
4.3.2 检索、发文关键词对比分析,精准文献推荐
使用该公式,就是在共词矩阵的基础上创建相关系数矩阵。基本方法与创建共词矩阵大同小异,要注意两点:其一,将共词矩阵对角线上代表高频检索词的词频元素的数值由0改写为相应的词频;其二,遍历元素是要利用Ochiia系数公式计算相应的值。
利用式(4)通过节点域的上下边界和期望值,得到每个指标变量的最优值如表4。综合权重为0.520,0.292,0.188。
最后,在相关系统矩阵的基础上,利用Gephi软件
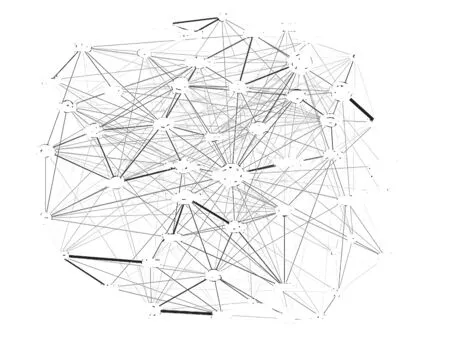
绘制用户检索关系词的共现关系图(如图3)。图中的每个节点代表一个高频关键词,点的大小代表了频次的多少。节点之间的边的粗细代表了节点相关性的大小。在图3中,可以看出硬质合金、工艺、金刚石等是用户检索次数最多的关键词,而金刚石与薄膜、金刚石与涂层、凝胶与溶胶等是相关性很高的关键词。通过关键词共现分析结果向用户推荐相关性较高的关键词进行组合检索,可在进一步提高文献推送准确性的同时,帮助用户发掘新的研究方向及交叉学科增长点。
4.3.4 结合中图法分析检索关键词,提升用户研究成效
中图分类号能够有效地将检索结果限定在需要的学科范围,是用户提高检索效率的重要工具。将该用户检索过程中使用的高频关键词与中图法中的学科分级类目进行比对,发现如TG135.5硬质合金、TG146.4稀有金属及其合金、TG146.411钨、TG146.412钼等能对应或包含用户使用的高频关键词。再如,“焊接”是用户使用较为频繁的检索关键词,比照中图法类目,发现“TG4焊接、金属切割及金属粘接”与之相符,其下位类还包括焊接材料、焊接工艺、焊接设备等类目。
综上,结合中图分类号和检索关键词,通过中图分类号将文献的学科类别限制在用户研究领域内,既能帮助用户提高文献检索的查准率,又能充分拓展其研究方向,从而达到综合提升用户研究成效的目的。
4.3.5 其他相关关键词分析,拓宽用户思路
该用户在检索中还涉及到其他不直接反映学科领域的相关关键词,即标准号和作者。通过这些关键词分析,既可以间接围绕用户研究学科领域进行分析,也能够对该用户整个检索词分析体系进行完善和补充。第一,标准号。如以BS ISO 513-2012和DIN ISO 513-199为检索点进行检索,从检索出来的标准名称、中国标准分类号及国际标准分类号的类目名称中提取对应的关键词。发现有些关键词如硬质合金等是用户高频关键词之一,而有些关键词如排屑等却从未出现在用户的检索词中。第二,作者。如搜索次数大于等于3次的有颜娟、廖军、张立等,将重点关注的作者名与高频关键词相关联进行组合检索,发现这些作者均是从事硬质合金材料和技术研究的专家及本地企业工作者。
三是明确管护责任。针对不同工程的性质和特点,采取专业化管理、社会化管理和自主管理等多种方式,将工程管护责任落实到产权的所有者和使用者,同时健全管理制度约束管理主体,确保工程能够正常地发挥效益,确保用水户的利益不受损害。
为此,在为用户提供检索建议或文献推送服务时,可将标准名称、标准分类号类目名称中从未出现的关键词作为检索点,帮助用户扩大检索结果,拓宽研究思路。同时,可进一步搜集用户重点关注对象的科研背景信息及从事相关专业领域的的企业信息,为用户衡量与对口企业合作的可行性提供决策性参考依据,并从中开拓出创造校企合作的价值空间。
“美丽中国”是党的十九大提出作为建设社会主义现代化强国的重要目标,强调要推进绿色发展,构建清洁低碳、安全高效的能源体系。南方电网云南电网公司作为扎根云南、从事基础产业和公共事业的中央企业,积极响应国家号召、主动承担社会责任,全心全意为云南经济社会发展服务,不断加大充电基础设施和车联网平台建设,全力助推云南省新能源汽车产业发展。
5 创文系统隐私保护探讨
行为数据是研究用户检索行为和科研方向的重要信息源,也是图书馆做好学科服务的根本前提。近年来,国内外对安全、规范使用个人信息日益关注,“数据正义”(Data justice)这一理论也应运而生。目前“数据正义”作为一个发展中的理念,含义尚未定型,其中安全、规范使用个人信息是其核心思想。国家对个人信息的收集、存储、处理做了明确规定,要求必须遵循“合法、正当、必要的原则”,特别是对利用用户画像等手段为用户提供服务作了详细、具体的信息安全规范
。另外,“数据正义”在数据可见性、用户参与性和数据歧视三方面有着规范和约束,用户对个人数据的采集、存储及应用范围须具有知情权
。《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》强调,要统筹数据开发利用、隐私保护和公共安全,加快建立数据资源产权、交易流通、安全保护等基础制度和标准规范
。以此为导向,本文在提取用户个人数据的过程中特别注意保护用户隐私,保证采集的手段、内容和用途对用户保持透明,让用户自主选择哪些行为数据、哪些时段、哪些网站的数据允许被采集,这些数据可以在哪些范围内使用,同时用户可以自主保存、删除自己的数据,切实消除用户顾虑。
6 结语
本文通过对典型用户群体访问创文系统行为数据多角度、多层次的分析,揭示出用户资源利用的行为规律与特征,以期促进图书馆学科服务更具备可操作性和实践性。本研究从反映具体用户真实检索意图的检索行为入手,如访问时间、资源偏好、选用的检索词等探寻其文献需求和检索规律,在一定程度上可为图书馆电子资源行为数据的深入研究提供参考,对推动有效发掘用户个性化需求及图书馆深层次服务建设具有积极意义,但还存在以下几方面的改进之处。
第一,典型用户群体具有一定数量,在进行检索词分析的时候需要反复迭代才能取得较好的分词效果,同时需建立具有学校专业特色的分词词典库,进一步提高分词效率和准确性;第二,分析过程的思路方法与应用角度还需进一步拓展,如将本馆集成管理系统数据、门禁数据及学校教务系统数据和人事系统数据,与创文系统数据进行融合,将用户的信息行为数据与其从事的科学研究及相关专业学习相结合,进一步提升数据的维度及分析的准确性;第三,通过在线交流、面对面沟通、电话沟通和问卷调查等多种方式,对典型用户群体进行调研,印证分析结果,并在此基础上深入研究,构建典型用户群体文献信息推荐模型并建立服务工作流程,撰写用户检索分析报告及资源推荐报告以此优化用户检索策略、提供精准文献服务。
上述探索点将是笔者后续努力的方向,旨在更好、更全面地研究用户数据,突出重点学科的科研价值和应用价值,为图书馆用户提供更优质的学科服务。
[1]创文科技[EB/OL]. [2020-08-13].http://www.cwkeji.cn/html/product.html#4_3.
[2]刁羽,贺意林.用户访问电子资源行为数据的获取研究:基于创文图书馆电子资源综合管理与利用系统[J].图书馆学研究,2020(3):40-47.
[3]Jieba[EB/OL].[2020-08-04]. https://github.com/fxsjy/jieba.
[4]Jieba分词加入特殊字符和空格[EB/OL].[2020-08-10].https://www.cnblogs.com/callyblog/p/10097 847.html.
[5]WordCloud for Python documentation[EB/OL].[2020-08-13]. http://amueller.github.io/word_cloud/.
[6]使用Ochiia系数将共词矩阵转换为相关矩阵(基于EXCEL+VBA的实现)[EB/OL].[2020-09-20]. https://blog.csdn.net/u010785550/article/details/107406230.
[7]The Open Graph Viz Platform[EB/OL].[2020-09-23]. https://gephi.org/.
[8]国家市场监督管理总局.信息安全技术个人信息安全规:GB/T35273—2020[S].北京:中国标准出版社,2020:2.
[9]LINET T . What is data justice? The case for connecting digital rights and freedoms globally[EB/OL].(2017-11-07)[2021-02-23]. https://journals.sagepub.com/doi/full/10.1177/2053951717736335.
[10]中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要[EB/OL].[2021-3-13].http://www.gov.cn/xinwen/2021-03/13/content_5592681.htm.
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
出版人(2022年3期)2022-03-23
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
东方少年·布老虎画刊(2020年4期)2020-06-08
科学与财富(2019年27期)2019-10-25
福建基础教育研究(2019年3期)2019-05-28
小天使·一年级语数英综合(2018年11期)2018-11-23
科学与财富(2017年28期)2017-10-14
瞭望东方周刊(2017年35期)2017-09-22
