
基于卷积神经网络和Transformer的手写体英文文本识别
2022-08-24 06:30张显杰张之明
计算机应用 2022年8期
张显杰,张之明
(1.武警工程大学信息工程学院,西安 710086;2.武警工程大学研究生大队,西安 710086)
0 引言
离线手写体文本识别(Offline Handwritten Text Recognition,OHTR)一直是计算机视觉和模式识别的主要研究内容之一[1]。不同于联机手写体文本识别可以记录书写人的轨迹,OHTR 由于不同的人书写的风格不同以及文本的结构越来越复杂等原因,仍然是一个具有挑战性的难题[2]。早期的OHTR 主要是基于分割的手写体文本识别[3-4],该类方法将图像分割成像素级的小部分,再使用分类的方法给每一个部分归类,由于分割的不确定性,此类方法识别的精度较低;另一种主流的方法是基于隐马尔可夫模型(Hidden Markov Model,HMM)的无分割的手写体文本识别[5-6],该类方法将图像作为整体输入到模型中,能避免出现图像分割产生的问题。
随着深度学习技术的飞速发展,基于循环神经网络(Recurrent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)的无分割手写体识别模型[7-10]不断被提出。Vaswani 等[11]提出了基于全局自注意力的Transformer,该模型放弃了循环连接的长短时记忆(Long Short-Term Memory,LSTM)网络,已经广泛应用于自然语言处理和计算机视觉领域[12-14]。
受此启发,本文提出了基于CNN 和Transformer 的手写体英文文本识别模型。主要工作有以下几点:
1)将CNN 和Transformer 编码器结合,提出了无分割的手写体英文文本识别模型;
2)使用链接时序分类(Connectionist Temporal Classification,CTC)贪心搜索算法解码,解决输入序列和标签的对齐问题。
1 相关工作
1.1 CNN
CNN 已经成为深度学习时代的主干架构,广泛应用于图像分类[15]、目标检测[16-17]、实例分割[18-19]。然而,大多数CNN擅长利用卷积操作捕捉局部信息[20-25],但不擅长捕捉全局信息,比如对于手写体文本识别比较重要的长序列依赖关系。为了使CNN 能够捕捉到全局信息,一种方法是通过卷积层的堆叠,使网络模型变得更深[21-23],而这往往导致模型的参数量急剧增加;另一种方法是增大卷积核的尺寸,扩大卷积操作的感受野,这需要更多具有破坏性的池化操作[26-27]。虽然使用以上两种方法确实提高了CNN 的性能,但直接使用全局依赖关系的机制可能更适用于手写体文本识别任务。
1.2 Transformer
基于全局自注意力机制的Transformer 在许多序列模式识别任务中取得了不错的效果,比如机器翻译[28]、语音识别[29]。Kang 等[30]首次将Transformer 的自注意力机制应用于手写体文本识别,提出了没有循环网络的识别模型,解决了循环网络不能并行的问题,并且在字符级别上预测手写体文本。Mostafa 等[31]构建了自己的数据集,应用Transformer 编码器和解码器,结合页面分割和文本分割技术用于手写体阿拉伯文识别。Ly 等[32]将Transformer 编码器与双向长短时记忆(Bidirectional LSTM,BLSTM)网络结合,提出了注意力增强的卷积循环网络,在手写体日语文本识别中表现优异。虽然Transformer 在计算机视觉领域发展迅速,但在手写体文本识别中还有很大的发展空间。
1.3 CTC
目前,CTC 解码方法是无分割手写体文本识别任务常用的一种解码方法,Graves 等[33-34]最早将CTC 和BLSTM 结合用于端到端手写体文本识别。之后,Chen 等[35]提出将门控卷积网络和可分离的多维长短时记忆(Multi-Dimensional LSTM,MDLSTM)网络结合,同时训练笔迹识别和文本识别,使用CTC 处理文本识别输入和标签序列对齐问题。Zhan等[36]提出将带有残差连接[23]的CNN 和BLSTM 结合,用CTC计算损失和解码。基于CTC 模型,Krishnan 等[37]提出了一种端到端的嵌入方案,联合学习文本和图像的嵌入。
在手写体英文文本识别任务中使用CTC 解码器能够取得一定的效果,但CTC 解码器假设不同时刻的网络输出是条件独立的[33],存在忽略全局信息的不足,而Transformer 基于全局自注意力机制能够有效地捕捉到全局信息。因此,本文利用Transformer 捕捉全局信息的优点弥补CNN 难以捕捉全局信息和CTC 忽略全局信息的不足,探索Transformer 在手写体英文文本识别中的应用前景。
2 CNN-Transformer Network
2.1 总体架构
本文提出的基于CNN 和Transformer 的手写体英文文本识别模型CTN(CNN-Transformer Network)如图1 所示,主要包含三个部分:CNN 特征提取层、Transformer 编码器、CTC 解码器。输入灰度图像I∈RH*W*1,经过CNN 提取到特征图,而后将特征图F输入Transformer 编码器得到特征序列每一帧的预测Y=[y1,y2,…yT],yT∈RL,其中:T是序列长度,L是标签字符种类的个数(含空白字符)。最后经过CTC 解码器获取最终的预测结果。
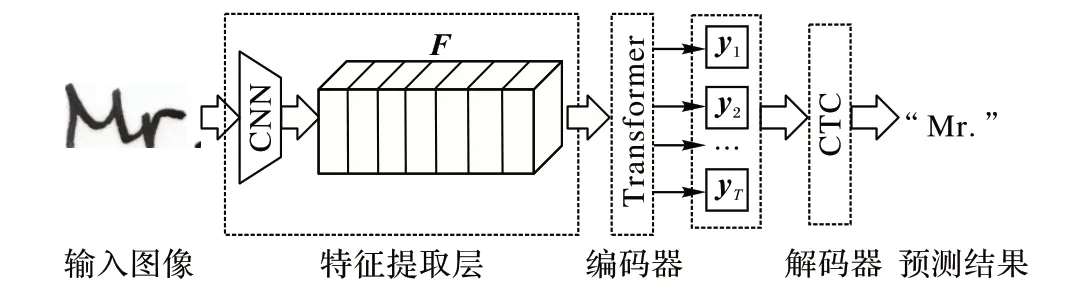
图1 CTN总体架构Fig.1 Overall architecture of CTN
2.2 CNN特征提取层
由于Transformer 缺少CNN 固有的一些归纳偏置[12],即对模型作出的一系列人为限制,同时对训练数据集需求较高,因此本文使用CNN 作以弥补,使模型能够在一般的数据集上具有泛化性。
本文使用带有压缩激励(Squeeze-and-Excitation,SE)块的SE-ResNet-50[27]作为特征提取层,SE 块结构如图2,特征图X经过压缩函数Fsq(·)得到关于通道的统计信息Z,随后经过激励函数Fex(·,We)获取通道的相关性S,最后经过缩放函数Fscale(·,·)得到新的特征图。计算公式如下:

图2 SE块Fig.2 SE block


SE 块让特征图通过一些网络层得出每个通道的“权重”,再和原特征图进行运算,对通道增加了注意力机制。
2.3 Transformer编码器
Transformer 编码器由一个多头注意力(Multi-Head Attention,MHA)和一个多层感知器(Mult-iLayer Perceptron,MLP)两个子层组成[11],每个子层前使用层标准化(Layer Normalization,LN)[38],每个子层后使用残差连接[23],如图3(a)所示。
为了减少运算量,文献[14]提出了线性的空间缩减注意力(Liner Spatial Reduction Attention,LSRA),如图3(b)。和MHA 类似,LSRA 也是接收查询Q、键K、值V作为输入,计算公式如下:
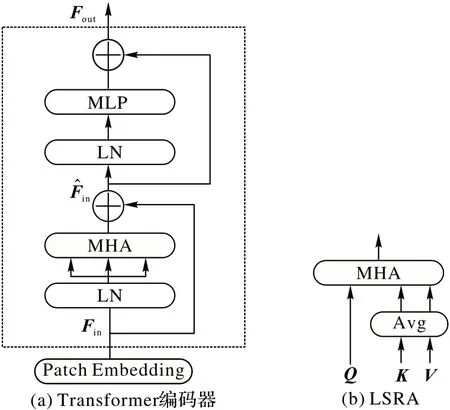
图3 Transformer编码器和LSRAFig.3 Transformer encoder and LSRA
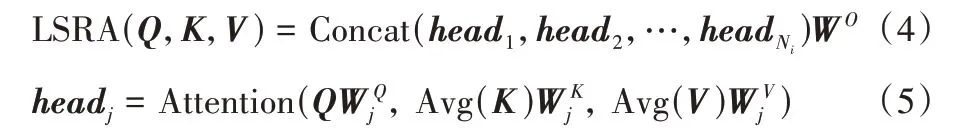
其中:Ni表示的是第i个阶段注意力头的数量;表示第j个头与输入对应的权重矩阵;WO表示线性层的权重矩阵;Avg(·)表示的是平均池化,目的是减少参数运算量。和文献[11]一样,Attention(·)注意力计算如下:
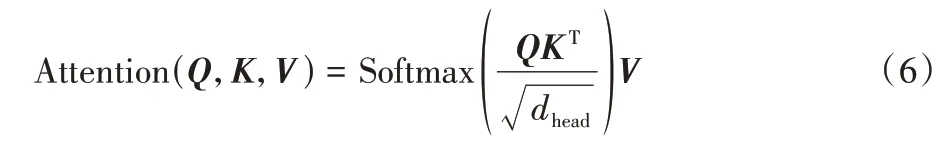
多头注意力经过Ni次计算,将所有头的结果拼接到一起,再经过一个线性层获得LSRA 的输出结果。
对于输入特征Fin,带有LSRA 的Transformer 编码器计算过程如下:
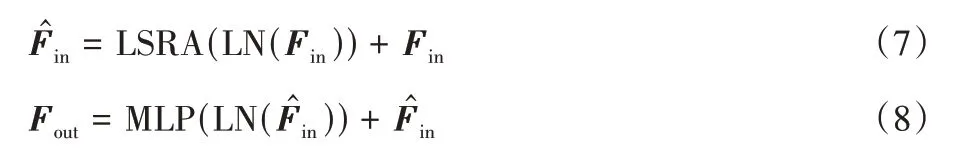
由于Wang 等[13]提出的金字塔视觉Transformer(Pyramid Vision Transformer,PVT)大幅减少了模型的计算量和内存消耗,并且能很好适用于下游任务,本文在Wang 等[14]提出的PVTv2 上作以改良,用于建立图像内部的上下文关系,整体结构如图4 所示。
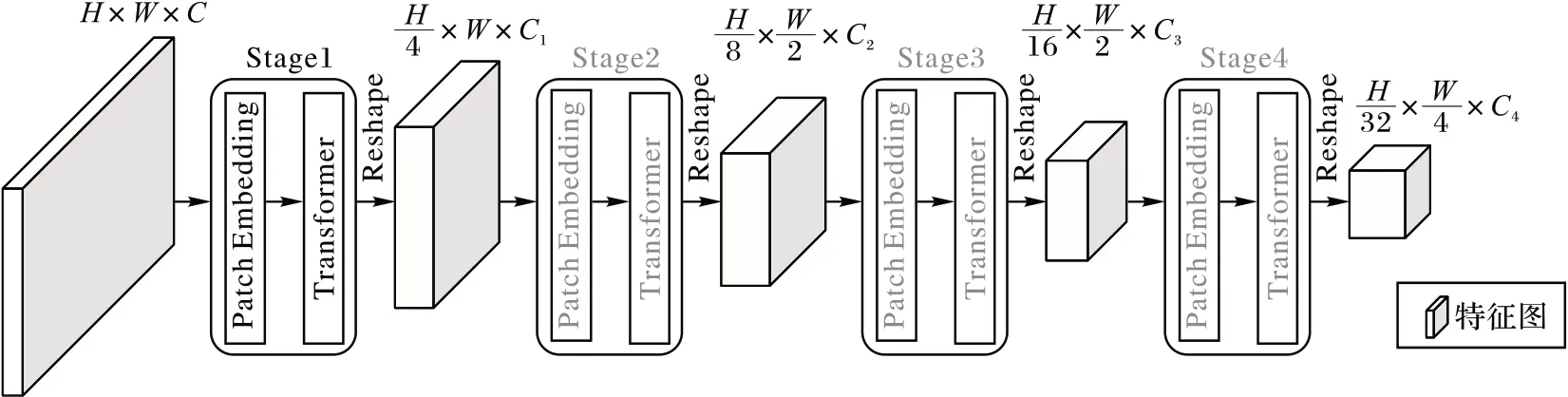
图4 改良的PVTv2整体架构Fig.4 Overall architecture of improved PVTv2
PVTv2 共有4 个相似的阶段,每个阶段都包含一个块嵌入层(Patch Embedding)和多个Transformer 编码器,CNN 获取的特征图经过嵌入层后输入到Transformer 编码器中。PVTv2 在第i个阶段开始都会把特征图平均分成份,分辨率降为原来的,每个阶段输出的结果都会重塑(Reshape)成特征图,再输入到下一个阶段,从而降低图像的分辨率。为了产生宽度较大的特征图,本文对特征图的划分与PVTv2不同,经过Transformer 后,特征图的高H依次降为,宽W依次降为
2.4 CTC解码器
Transformer 编码器输出的特征序列每一帧的预测,输入到CTC 解码器中得到最后的预测结果。实验结果表明,使用CTC 束搜索算法解码和使用贪心搜索算法解码精度相差不到0.1%,但束搜索算法(束大小设置为10)解码时间是贪心搜索算法的3 倍左右,因此,在实验时,本文使用CTC 的贪心搜索算法解码。
3 实验与结果分析
3.1 数据集
实验所用数据集是公开的IAM(Institut für Angewandte Mathematik)手写英文单词数据集[39],包含由675 个作者手写的115 320 个单词以及对应的标签,由字母、数字以及特殊符号组成。由于原始数据部分单词分割错误,本文在实验前对原始数据进行了筛选,去掉了错误分割的图像、纯标点符号的图像以及两张损坏的图像和一张标签错误的图像,得到实验图像数据共84 976 张,按照8∶1∶1 划分为67 919 张训练集图像、8 461 张验证集图像和8 596 张测试集图像。图5 是实验中使用的数据集和标签示例。
图5 实验数据集和标签示例Fig.5 Examples of experimental dataset and labels
3.2 评价标准
为了量化实验的结果,使用标准的字符错误率(Character Error Rate,CER)和单词错误率(Word Error Rate,WER)评估模型。预测的单词转换为标签,需要替换的字符个数记为SC,需要插入的字符个数记为IC,需要删除的字符个数记为DC:

其中:LC表示单词标签中字符的总个数。最后求取所有单词CER 的算术平均数。同理,

其中:SW表示预测的字符串转换为标签需要替换的单词个数;IW表示需要插入的单词个数;DW表示需要删除的单词个数;LW表示字符串标签中单词的总个数。最后求取所有字符串WER 的算术平均数。
3.3 实验细节
3.3.1 实验设置
在CNN 特征提取层,选择3.4.1 节消融研究的最优结果作为基准,Transformer 编码器的参数在遵循文献[14]的B2-Li 的基础上,对特征图的划分份数作以修改,CTC 解码器采用贪心搜索算法。输入图像为灰度图,尺寸统一缩放到128 × 384,预测序列长度为24,标签字符种类个数(含空白符)为72,使用CTC 损失函数,优化器使用均方根传递(Root Mean Square prop,RMSprop),共训练100 个循环次数。实验操作系统为ubuntu18.04,GPU 型号为GTX1080Ti,CUDA(Compute Unified Device Architecture)版本为10.2,采用Pytorch 1.5.0 学习框架。
3.3.2 数据增强
由于数据量有限,为了防止过拟合,本文对输入图像做了增强。在训练阶段,为了增加训练样本的多样性,既采用了随机几何数据增强,如旋转、平移、缩放、错切等,又采用了文献[40]提出的数据增强方法。前者将图像视为一个整体,而后者对图像中每个字符作以变化,更加适用于手写体英文文本的识别。在测试阶段,为了防止数据增强对识别产生影响,只将图像缩放到128 × 384,不做其他任何处理。
3.4 消融实验
为了选择最优的训练模型,本文做了大量的消融实验,主要包括CNN 深度对实验精度的影响和学习率对实验精度的影响。
3.4.1 CNN深度对实验精度的影响
实验中选择了SE-ResNet-50 作为CNN 特征提取层,其模型含有5 个层级。为了选择合适的截取层级作为CNN 特征提取层,对不同截取层级获得的精度和速度进行了比较。所有的实验都在同一个数据集和实验环境下进行,学习率设为0.000 5,选取在验证集上WER 最低的模型进行测试。实验结果如表1 所示。
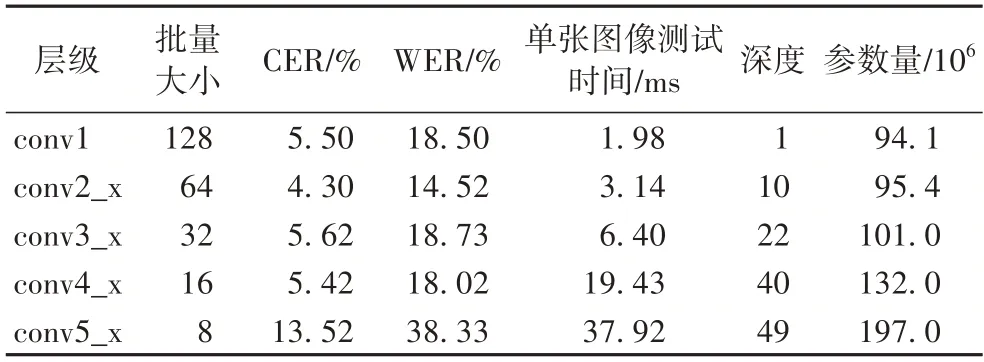
表1 SE-ResNet-50不同截取层级的性能Tab.1 Performance of different interception layers of SE-ResNet-50
从实验结果可发现:随着层级的不断加深,模型的参数量由94.1×106增加到197.0×106,单张图像测试时间由1.98 ms 增加到37.92 ms,但模型的字符错误率和单词错误率在conv2_x 达到最低,分别为4.30%和14.52%,同时参数量相对较低。由此可见,CNN 的归纳偏置能够增加Transformer 的识别精度。因此,本文选择截取层级conv2_x作为CNN 特征提取层。
3.4.2 学习率对实验精度的影响
为了选择最优的训练模型,在3.4.1 节模型的基础上设置不同的学习率进行实验,同样选取在验证集上WER 最低的模型进行测试,结果如图6 所示。

图6 不同学习率的测试精度Fig.6 Test accuracies of different learning rates
从图6 可以看出,学习率不同,测试精度不同,随着学习率的不断增加,CER 和WER 也不断变化,总体呈现先下降后上升的趋势,学习率为0.000 7 时CER 和WER 达到最高,分别为11.98%和29.78%,学习率为0.000 2 时CER 和WER 达到最低,分别为3.60%和12.70%,因此,本文选择0.000 2 作为模型的最终学习率,所得测试精度作为模型的最终测试精度。
3.5 实验对比及分析
3.5.1 与其他模型的比较
表2 是不同模型在IAM 手写英文单词数据集上评估的结果。表2 中分别提供了作者采用的主要模型所获得的识别精度,部分模型同时提供了在不同条件下所得的评估结果,可以看出,在有词典或语言模型的情况下,识别精度都比较高。本文所提出的模型不依赖于词典或语言模型的约束,既能呈现出模型的真实识别能力,也能应对一些不能提供词典的情况,比如姓名识别,实用性较强。表2 中CTC+Attention[2]、RNN+CTC[37]、RNN+CTC[41]、Attention[42]没有使用预处理方法,CER 和WER 基本都高于本文的CER 和WER;RNN+Attention[8]、RNN+CTC[9]、Attention[43]和本文模型一样使用了预处理,其中RNN+Attention[8]在未使用其他方法的情况下,CER 和WER 分别比本文高了5.20 个百分点和11.10个百分点,使用了词典约束后CER 比本文高了2.60 个百分点,RNN+CTC[9]只使用了预训练方法后CER 比本文高了1.28 个百分点,WER 比本文低了0.09 个百分点,Attention[43]只使用了预训练方法后CER 和WER 分别比本文高了2.19个百分点和2.45 个百分点,通过比较验证了本文模型的可行性。
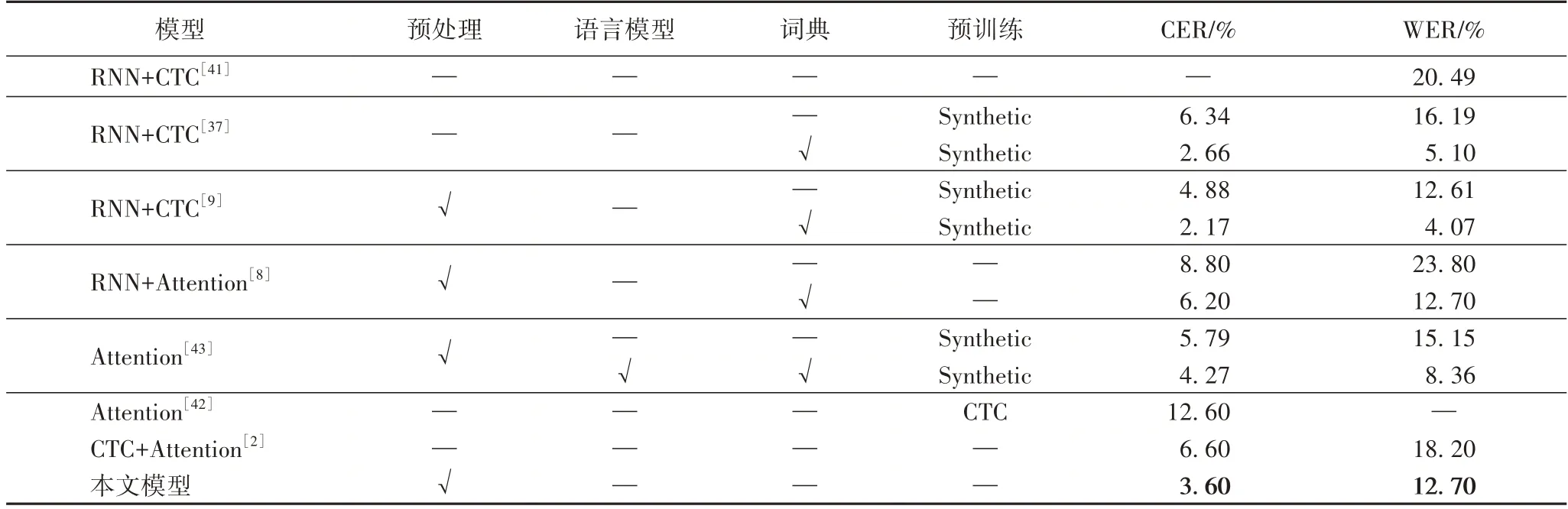
表2 IAM手写英文单词数据集上的评估结果比较Tab.2 Comparison of evaluation results on IAM handwritten English word dataset
3.5.2 错误结果分析
为了进一步了解模型的识别能力,从预测错误图像的结果中随机抽取100 条记录进行分析,表3 给出了预测错误的类型占比。从表3 可以看出,单词预测错误1 个字母所占比例为68%(单词内部错误1 个字母所占比例为41%,开头或结尾错误1 个字母所占比例为27%),单词大小写预测错误所占比例为4%,而整个单词错误所占比例仅为1%,验证了模型能够识别出单词中大部分的字母,识别能力比较强。

表3 预测错误的类型占比Tab.3 Proportion of types of prediction errors
图7 展示了模型预测的图像示例。图7(a)展示的是预测正确的图像示例;图7(b)、(c)展示的是预测错误1 个字母的图像示例;图7(d)展示的是整个单词预测错误的图像示例。

图7 预测的图像示例Fig.7 Examples of predicted images
从图7 可以看出,模型对于书写相对规范的英文文本识别精度高,对于书写随意性较大的英文文本识别精度低。
4 结语
手写体英文文本识别因书写随意、结构复杂和分割困难等问题,一直是计算机视觉和模式识别的难题之一。针对这些问题,本文提出了一种基于卷积神经网络(CNN)和Transformer 相结合的手写体英文文本识别模型。该模型利用CNN 提取特征,而后输入到Transformer 进行编码,最后采用CTC 解码器解决输入序列和标签的对齐问题。通过在公开数据集上进行大量的实验分析,验证了本文模型的可行性。接下来的研究工作:一是将本文模型应用于其他手写体文本识别任务,比如中文或日文手写体文本识别;二是在手写体行级文本识别中提出合适的网络结构,达到较高的识别精度。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
传感器世界(2022年4期)2022-08-05
小学生必读(低年级版)(2021年10期)2022-01-18
一重技术(2021年5期)2022-01-18
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
家庭影院技术(2019年8期)2019-12-04
