
面向多段落高考阅读理解的答案句抽取方法
2022-08-25 09:56贺文静
软件导刊 2022年8期
贺文静,张 虎
(山西大学计算机与信息技术学院,山西太原 030006)
0 引言
机器阅读理解的主要目标是让机器阅读一段材料后回答问题。研究主要分为基于规则、基于机器学习、基于深度学习3个发展阶段。
20 世纪70 年代,基于规则的阅读理解方法[1]受到普遍关注。Lehnert[2]采用策略模拟和脚本设计一种关于问答系统的框架。Hirschman 等[3]结合问题选择与问题匹配度最高的句子,基于规则的词袋模型设计DEEP READ系统。
在机器学习研究阶段,人们尝试将机器阅读理解转化为有监督学习问题。Narasimhan 等[4]在最大化模型概率的同时,既考虑句子间的关系,又通过设置隐变量捕捉句子间的关联。Sachan 等[5]根据潜在结构支持向量机将问题或预期答案类型进行划分。
随着深度学习发展,Hermann 等[6]提出神经网络模型Attentive Reader,该模型通过注意力机制结合问题与文章内容,以便于抽取答案片段。Seo 等[7]通过双向注意力获得每个时间步的上下文向量表示,动态获取文章和问题间的交互模式。
近年来,Vaswani 等[8]提出的Transformer 结构和Devlin等[9]提出的大规模预训练模型BERT 进一步加速机器阅读理解的发展。其中,Transformer 的自注意力机制相较于LSTM 的记忆/遗忘机制,建模长距离依赖的优势更强;BERT 将Transformer 作为特征抽取器,能够更好地获取上下文信息。
目前,机器阅读理解在实际任务中都达到了较好的效果,但面对篇幅较长、冗余信息较多的阅读理解材料时,现有模型只能从原文中抽取与问题相关的单个连续片段回答问题,作答准确率较低。
为此,本文对高考阅读理解数据集进行分析,发现高考阅读理解数据集的阅读材料一般由多个文本段落组成,答案来源于不同段落的片段。由图1 可见,候选答案句分布于3 个不同段落,需要先从文本中精准定位各个关键片段。

Fig.1 Examples of college entrance examination reading comprehension图1 高考阅读理解样例
此外,通过样例分析发现,材料中答案句子的数量远小于非答案句(见表1),这种数据的非平衡性对基于分类的答案句抽取方法影响较大。
由表1 可知,当训练集句子总数>30 时,候选句条数平为4 条,测试集候选句总数为7 条;当训练集句子总数≤30时,候选句条数平为3条,测试集候选句总数为6条。

Table 1 Analysis of candidate sentences in training set and test set表1 训练集和测试集中候选句条数分析
由表2 可知,候选答案句数(标签为1)和句子总数(标签为0)的比例约为1:7,答案句的数量远小于非答案句数量。

Table 2 Proportion of answer sentences and sentences in the material表2 材料中的答案句和句子占比
针对以上问题,为保证提取候选句的精确率,在最大限度上召回答案句。本文引入段落筛选器解决语文阅读理解中正负样本不均衡的问题,并采用数据增强方法扩充答案句数量以缓解正负样本不均衡对模型性能产生的影响。
综上所述,本文以国内高考语文阅读理解问答题为实验数据,提出面向多段落高考阅读理解的答案句子抽取方法。主要贡献包括:①提出“段落筛选器—答案句抽取”的高考阅读理解答题框架,设计基于词频—逆文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)的段落筛选器;②设计基于文本增强(Easy Data Augmentation,EDA)的答案句扩充方法,解决数据集中答案句与非答案句不平衡的问题;③实现基于RoBERTa 模型的答案句抽取。
1 国内外研究现状
主要从机器阅读理解、候选句抽取和数据增强3 个方面梳理国内外研究现状。
1.1 机器阅读理解
机器阅读理解旨在让机器学习阅读材料包含的语义信息,回答材料提出的问题,现已成为自然语言处理研究的一项重要任务。
目前,面向多文档、多段落阅读理解数据集的研究已受到广泛关注。Wang 等[10]引入单词级别的权重匹配和信息交互提出Match-LSTM 模型,有效预测答案起始和结束位置。Cui 等[11]引入AOA 层叠注意力机制,通过在文档级的注意力机制上增加一层注意力以确定答案。Wang 等[12]引入门机制提出R-Net 模型,根据与问题的相关程度给文本每个词赋于不同权重。谭红叶等[13]针对描述类问题语义概括程度,将问题类型、主题、焦点特征与QU-NNs 模型进行融合,以便于有效提取文章信息。Zhang 等[14]基于BERT 对材料、问题进行编码,并利用余弦相似度和注意力机制获取材料和选项、材料和问题之间的权重信息。Lan等[15]通过精简参数提升训练速度,同时引入自监督损失增强学习句间的连贯性。
以上模型虽取得了较好的成效,但由于高考阅读理解材料普遍较长,现有模型难以对材料进行预筛选,存在非答案区域的冗余段落,造成模型运行效率较低。
1.2 候选句抽取
通过上述研究可知,获取答案句是阅读理解的最终目的。在候选句抽取过程中,首先通过信息检索方法计算两个句子的相似度,然后基于概率主题模型方法将文档高维矩阵进行降维,实现低维空间表示,并基于此计算语义相关度。该方法虽然通过文档与词间的联系进行建模,但忽略了句子间的联系。
随着深度神经网络的快速发展,基于神经网络方法抽取候选句也越来越普遍。郭少茹等[16]分析句子级语义信息以加强材料和选项的相关度,并通过不同维度计算句子的语义相关度,选出最佳答案。Xiong 等[17]动态协同注意力网络(Dynamic Co-Attention Networks,DCN)融合表示问题和文档,然后利用动态解码器不断更新答案范围。Devlin 等[9]将BERT 模型用于抽取答案句,通过双向Transformer 网络获取文本的语义表示。杨陟卓等[18]利用汉语框架网络抽取与问句语义相似的候选句。
通过以上研究表明,目前所提出的模型在大部分问答数据集上均取得了不错的效果。但由于高考阅读题目数据集的答案区间较为分散,若直接将模型应用于该数据集上时,实验效果较差。
为了解决该问题,本文通过RoBERTa 模型对候选句是否为答案句的概率进行预测。
1.3 数据增强
数据增强是一种常用的数据集扩充方式,但在自然语言处理领域,该方法仍处于探索阶段。张一珂等[19]将数据增强模型表述为强化学习问题,利用对抗训练策略语言模型进行数据增强,采用蒙特卡洛搜索算法对生成序列的中间状态进行评估。Wei 等[20]针对自然语言处理中的文本分类任务提出文本增强(Easy Data Augmentation,EDA)方法。
现有模型虽有效融合了问题及阅读材料间的联系,但仍存在部分问题尚待解决。例如,针对高考阅读理解材料篇幅较长,答案由分散在不同段落中的句子概括而成,而现有研究方法未能根据该特性提出改进机制,导致模型性能普遍较低。
为此,探索融入段落筛选器和基于EDA 模型的答案句扩充方法对提高模型预测召回率、准确率存在十分重要的实际意义。
2 模型介绍
基于RoBERTa 所提出的面向多段落阅读理解的答案句抽取模型的整体架构如图2 所示,该架构主要包括段落筛选器、文本增强(EDA)和答案句抽取3个部分。

Fig.2 Overall model architecture图2 模型整体架构
首先,将整个材料按段落划分,根据TF-IDF 计算段落与问题的相关性得分,按照分数对段落进行排序,为每个问题选择最小TF-IDF 余弦距离的前k段落。
然后,通过EDA 模型利用随机(等价)实体替换、随机同义词替换、随机近义字替换、随机字删除、随机置换邻近的字共5 种方式对答案句进行扩充,使材料中的答案句和非答案句比例达到1∶1。
最后,采用RoBERTa 预训练语言模型获取句子的嵌入表示,并将编码后的句子表示输入至全连接层进行打分,以预测句子是否为答案句。
2.1 问题描述
机器阅读理解任务是一个监督学习问题,需要计算机在阅读文本后回答相关问题。因此,可将问题描述为:给定一篇阅读理解材料D={P1,P2,...,Pn},训练一个机器阅读理解模型,该模型输入为一段文本P和相对应的问题Q,输出为答案A:

2.2 段落筛选器
在高考阅读理解材料中,由于答案分布于一个或多个段落,不同段落对答案句具有不同的支撑作用。为了减少无关段落对模型预测的干扰,基于TF-IDF 段落筛选器计算每个段落与问题的相关度,并将相关度较高的段落按段落顺序进行拼接。
问题描述为:基于每篇材料给出问题,根据TF-IDF 计算与问题相似度最高的前n个段落:

其中,wi,j为词语ti在 段落pj中出现的次 数,∑knk,j为段落pj中所有词汇出现的次数总和,|N|为语料库中的段落总数,|{j:ti∈pj}|表示包含词语ti的段落数目。若某个词语未在语料库中出现,则会导致分母为0,因此在一般情况下会使用1+|{j:ti∈pj}|表示包含词语ti的段落数目。
2.3 EDA
基于深度学习和机器学习的研究任务中通常会发生样本不均衡问题。例如,高考阅读理解数据集中答案句和非答案句样本量差距较大。在这种情况下,模型会处于欠拟合状态,预测准确率较低。
为此,本文共使用了随机(等价)实体替换、随机同义词替换、随机近义字替换、随机字删除及随机置换邻近的字共5种样本增强技术解决该问题。具体操作如下:
(1)随机(等价)实体替换。从一段高考阅读理解句子中随机找出句中某个不属于停用词集的词,将该实体与原句中的实体进行替换,并且重复执行n次。
(2)随机同义词替换。从高考阅读材料句中随机选取一个词汇,若它不属于停用词集,则随机选择它的同义词进行替换,并且重复执行n次。
(3)随机近义字替换。从高考阅读理解材料中随机选取一个词,使用近义词预测工具寻找备选词进行替换,并且重复执行n次。
(4)随机字删除。从一段高考阅读理解文本中随机选取一个词汇并删除,并且重复执行n次。
(5)随机置换邻近的字。从一段高考阅读理解文本中随机选取某个字和邻近的n个字进行交换,若遇到特殊字符则停止操作,并且重复执行n次。
其中,参数n表示对当前候选句文本的操作次数。
本文使用EDA 复制原始句子,通过随机插入和随机同义词替换加入噪声防止模型发生过拟合。表3 为使用EDA 模型进行5 种操作后的句子示例,原始答案句文本为“首先牡丹意象作为盛唐文化的表征,在民族记忆强大的恒定力的笼罩下,其内涵被剥夺了拓展的可能和空间。”
2.4 答案句抽取
Word2Vec 或Glove 的嵌入层仅为每个单词提供一个上下文无关的向量表示,而RoBERTa 的嵌入层不仅在句子的开头和结尾分别加入特殊字符,还将单词本身的词向量、句向量和位置进行向量叠加,再将叠加后的嵌入向量作为输入,最后输出整个句子词级别的上下文向量表示。

Table 3 EDA enhancement example表3 EDA增强示例
由于需要对答案句进行抽取,故采用改进RoBERTa 模型将输入序列组成两个句子对,即问句—答案候选句,然后对候选句进行二分类以判断每个候选句是否为答案句。为了便于计算,使用RoBERTa 作为模型编码器获得句子S和问题Q的向量化表示,计算公式如下:

其中,input表示RoBERT的输入序列,v表示句子和问题的向量化表示,本文将[CLS]在v中得到的向量c来表示当前输入的句子和问题,然后输入全连接层Dense得到当前选项是否为支撑句的概率。

式中,S表示句子与问题Q间的关系为答案句的概率,y取值为0 或1,当y=0 时表示该句子不是该问题答案,当y=1 时表示该句子是该问题答案,L(S|P,Q)表示该句子是问题Q正确答案的损失值。
3 实验结果与分析
3.1 实验数据
由于高考问答题在阅读理解中所占比例较小,本文采用的数据集包括各省高考真题、模拟题及对选择题改造的问答题,并基于RoBERTa 模型在高考语文阅读理解问答任务上进行适当微调,微调语料采用各省450 套(不含北京卷)高考真题,约2 万对问题答案句。训练和测试语料采用北京近10 年的高考题(10 套)和各省份高考模拟题(80套),共包括约0.6 万对问题—答案句。经过筛选,最终在各省近12 年高考真题上提取到132 个问句,在各省高考模拟题上提取到511个问句。
依据高考语文问答题只要答中要点即得分的评分规则。按照标准答案,人工找到其在原文中所对应的句子,标记为答案句集合A*,集合A*的大小就是答案句句子数。RA为按照本文方法组成的答案句中正确答案句集合,为按照本文方法形成的答案句集合。实验结果的评价标准如式(10)-式(12)所示。

3.2 基线模型
为验证本文方法的有效性,将本文算法与较为常见的阅读理解基线模型进行比较,具体包括:
(1)BERT 模型。该模型由多个双向Transformer 编码器堆叠而成,相较于其它深度学习模型,能够获取更多文本特征表示。通过结合该模型结构,使用网上公开BERTbase 中文版本预训练模型初始化参数,通过高考数据集对模型进行微调,最终得到测试BERT 模型。
(2)RoBERTa 模型。该模型是BERT 的改进版本,在预处理阶段采用Dynamic Masking 取代Static Masking,在数据生成方式和任务改进过程中去掉了Next Sentence Prediction,并从一个文档中获得数据。此外,RoBERTa 模型参数量更大、训练数据更多,在规模、算力上优势显著。
3.3 参数设置
将Google 官方公开的中文RoBERTa 预训练模型作为初始化模型,先使用高考训练集微调模型,然后使用微调后的模型对侯选句是否为答案句进行预测。在微调过程中,epoch 设置为12,学习率设为2e-5,输入文本序列最大截断长度设为512,batch size 设为10。
3.4 实验结果
本文分别使用BERT、RoBERTa、RoBERTa+EDA+TF 等6 个模型在高考阅读理解数据集上进行实验比较,以答题召回率作为模型的评价指标,具体实验结果见表4。
由表4 可知,RoBERTa 模型的答题效果优于BERT 模型。在引入答案候选句扩充机制后,分别采用COPY 复制(复制n条答案句,使答案句与非答案句数量达到平衡)和EDA 策略进行数据增强。
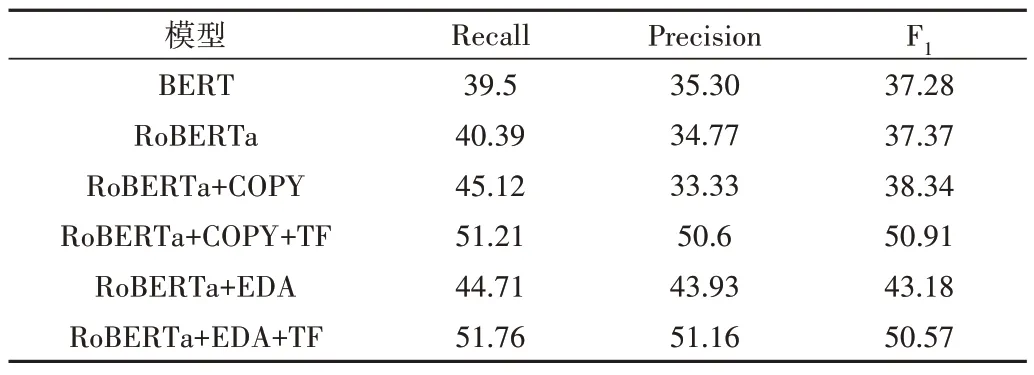
Table 4 Experimental results of each model表4 各模型实验效果 (%)
实验结果显示,两种数据扩充机制对模型召回率的提升相差不大,但准确率和F1值存在显著差别。当在Ro-BERTa 模型同时加上段落筛选和EDA 策略时,结果最优,召回率和准确率分别达到51.76%和51.16%,相较于Ro-BERTa 模型答题准确率约提升10%。
数据分析结果表明,答案候选句数量与阅读材料的长短存在明显关系,为进一步验证模型的有效性,分别在Ro-BERTa、RoBERTa+EDA、RoBERTa+EDA+TF 模型上进行比较实验,尝试依据每篇材料中所包含的答案句条数动态调整k值,具体实验结果见表5-表7。图3 为训练集候中候选句的占比。

Table 5 Effect of RoBERTa recall of the first k sentences表5 RoBERTa召回前k句的效果 (%)
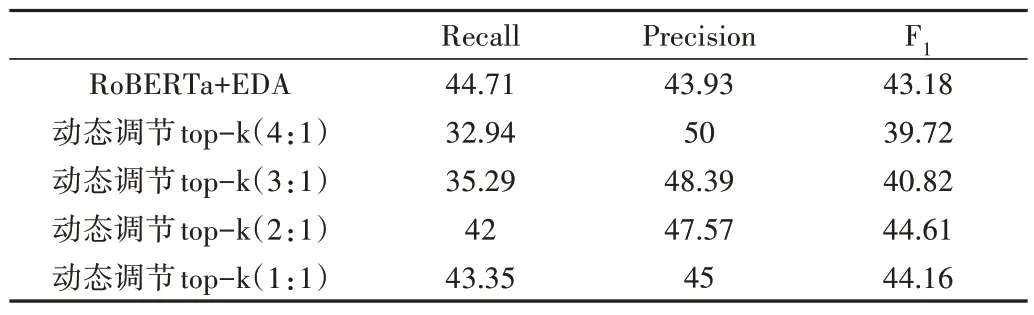
Table 6 Effect of RoBERTa+EDA recall of the first k sentences表6 RoBERTa+EDA召回前k句的效果 (%)

Table 7 Effect of RoBERTa+EDA+TF recall of the first k sentences表7 RoBERTa+EDA+TF召回前k句的效果 (%)
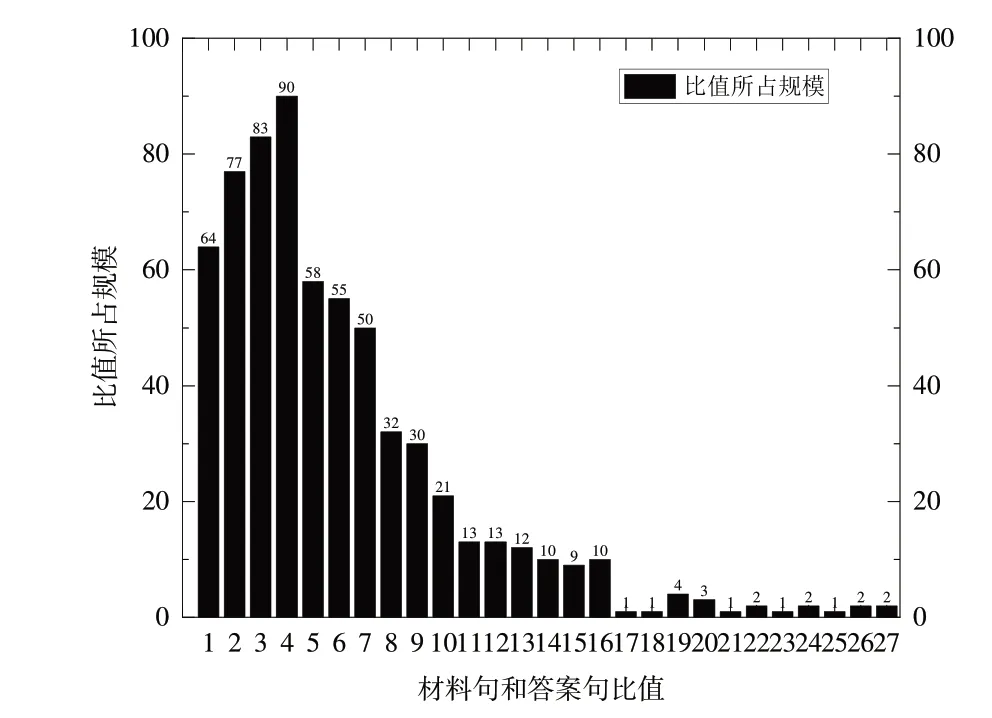
Fig.3 Proportion of candidate sentences in training set图3 训练集候选句占比
实验结果显示,当k与阅读材料句子数的比值越小时,模型召回的句子数量越少,此时3 种模型的召回率下降,但准确率均存在一定程度的提升。同时,相较于其他模型,RoBERTa+EDA+TF 模型表现得更稳定。
4 结语
本文针对高考阅读理解问答任务,提出了面向多段落阅读理解任务的答案句抽取方法。首先,提出了段落筛选器计算不同段落对问题的支撑度,并按照相关性得分对段落进行筛选。然后,提出答案候选句扩充策略解决数据集中存在的非平衡数据问题。最后,使用RoBERTa 阅读理解模型实现答案句标注。实验结果表明,本文方法相较于现有传统方法,准确率更高,适用性更强。
尽管所提出的模型取得了较好的作答效果,但目前未能利用答案句之间的关联关系,仅从问题角度分析段落和问题的相关程度,答案句抽取效果较差。下一步将深入挖掘不同答案句间的关联关系,使用图神经网络准确抽取答案句,并考虑答案句间的复杂语义推理关系。
猜你喜欢
阅读(快乐英语高年级)(2020年9期)2020-01-08
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
汽车实用技术(2017年23期)2017-05-29
课堂内外·创新作文小学版(2016年6期)2016-07-04
读写算(下)(2016年11期)2016-05-04
小学教学参考(2015年20期)2016-01-15
语文知识(2014年1期)2014-02-28
