
基于词向量与CNN-BIGRU的情感分析研究
2022-08-25 09:56吴贵珍黄树成
软件导刊 2022年8期
吴贵珍,王 芳,黄树成
(江苏科技大学计算机学院,江苏镇江 212100)
0 引言
情感分析是指利用自然语言处理及计算机语言学等技术识别与提取原素材中的主观信息,找出意见发表者在某些话题上的两极观点态度[1]。目前情感分析方法分为3种:基于情感词典的方法、基于机器学习的方法、基于深度学习的方法。其中,基于深度学习的方法能从大量文本中自动学习到深层特征,情感分析效果好且模型适应性强[2]。因此,目前主流的情感分析方法是基于深度学习的方法。在深度学习领域又有多种情感分析模型,主要包括卷积神经网络(CNN)模型和循环神经网络(RNN)模型,但CNN 模型只能进行局部特征提取,RNN 模型存在短期记忆问题。为解决这一问题,长短期记忆模型(LSTM)和门控递归单元(GRU)等众多变体被提出,并广泛应用于情感分析领域[3-4]。然而,LSTM 和GRU 模型只具有前向信息记忆能力,而不能对后向序列进行记忆,故双向RNN 结构随之被提出。对比两个双向RNN 结构,即相比BILSTM 模型,BIGRU 模型的参数更少,网络训练速率也更快,在保持几乎相同准确率的同时更节约网络训练时间,提高了效率[5-6]。
故本文选用CNN 与双层BIGRU 相融合的方式进行情感分析,一方面利用CNN 局部感知的特点提取出语义特征,另一方面利用BIGRU 提取包含上下文信息的全文特征,对局部特征进行补充,以完善CNN 模型情感特征倾向信息。同时,为丰富特征信息并加强模型的特征学习能力、提高文本情感分析的准确性,提出叠加BIGRU 模型的双层BIGRU 模型,即将第一层BIGRU 的输出作为第二层BIGRU 的输入,形成多层结构以增强特征。
1 相关研究
1.1 词向量相关研究
在NLP(自然语言处理)中存在许多基于神经网络的词向量计算技术,如:神经网络语言模型Word2vec 等。其中,Word2vec 是由MikolovT 等[7]在2013 年提出的,在词向量计算中被广泛应用。Word2vec 技术中包含两种不同的词向量计算模型:CBOW 模型与Skip-gram 模型[8-9]。由于CBOW 模型训练时间短且具有较高计算精度,因此本文采用CBOW 模型。
CBOW 模型,中文译为“连续词袋模型”,其核心思想是:给定中心词一定邻域半径内的单词,预测输出单词为该中心词的概率。该模型共分为3 层:输入层、隐藏层(投影层)与输出层。输入层输入中心词一定邻域半径内的单词词向量,隐藏层将输入层的词向量按照规则进行计算,输出层输出获得中心词的概率。在CBOW 模型中,训练目标为最大化对数似然函数L:
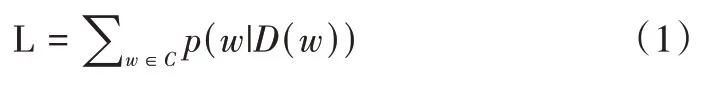
式中,D(w) 表示语句中除词语w外的其他词语,w为词库C 中的任意一个词语。以对数似然函数为导向,计算出词库中词语w在整个句子中出现的概率,实现对中心词出现概率的预测。
1.2 情感分析相关研究
卷积神经网络和递归神经网络是文本情感分析领域两种广泛使用的深度学习模型。Bengio 等[10]最早使用神经网络构建语言模型;Kalchbrenner 等[11]提出动态卷积神经网络模型以处理长度不同的文本,将卷积神经网络应用于NLP;Kim[12]对比了不同词向量构造方法,利用提前训练的词向量作为输入,通过CNN 实现句子级的文本分类,但这种方法也存在弊端,其忽视了待分类句子内部词语之间的联系;Mikolov 等[13]提出的RNN 模型可处理序列数据并学习长期依赖性,但RNN 存在短期记忆问题,无法处理一段很长的序列,且不具有对后向序列的记忆功能。为解决该问题,双向RNN 结构变体被提出。如Graves 等[14]提出的双向长短期记忆网络(BILSTM),该模型在LSTM 上增加了反向层,使得LSTM 能够同时考虑上下文信息,对双向序列信息进行记忆,获得双向无损的文本信息;Chen等[15]利用多通道卷积神经网络模型,从多方面的特征表示学习输入句子的情感信息;Long 等[16]将双向长短时记忆网络与多头注意力机制相结合对社交媒体文本进行情感分析,克服了传统机器学习中的不足;Kai等[17]将卷积神经网络与Bi-LSTM 融合起来,解决了现有情感分析方法特征提取不充分的问题,并分别通过实验表明了该融合模型在实际应用中具有较大价值。同时,Wang 等[18]研究了树形结构的区域CNN-BILSTM 模型,提供了更细粒度的情感分析,在不同语料库上都取得了不错的分类效果。
以上方法使用的都是传统获取词向量模型的方式,并且未使用过CNN 与双层BIGRU 融合进行情感分析,训练准确性不够高。本文通过对词向量进行改进,加入Attention 机制提取重要的输入向量,并融合CNN 与双层BIGRU模型进行改进,以提高文本分析的准确性。
1.3 情感分析相关技术
1.3.1 CNN模型
常见的CNN 模型主要由输入层、卷积层、池化层与全连接层构成。输入层主要是得到一个二维矩阵,矩阵中的每一行对应不同的词,不同的词用不同向量表示。卷积层是卷积神经网络的主要部分,卷积操作其实是卷积核矩阵与对应输入层中一小块矩阵的点积相乘,卷积核通过权重共享的方式,按照步幅上下左右地在输入层滑动提取特征,以此将输入层作特征映射,并作为输出层。池化层一般采用最大池化法,将卷积层每个通道得到的向量进行最大池化,得到一个标量,最后将其拼接起来传到全连接层或直接连接softmax 层进行分类[19]。全连接层连接一个softmax 层,将池化层获得的一维向量输入进去,其通常反映着最终类别上的概率分布,以此进行情感分类。
1.3.2 BIGRU模型
在单向的神经网络结构中,状态总是从前往后输出,只能捕捉当前词前面的相关信息。然而,在文本情感分类中,如果当前时刻的输出能与前一时刻及后一时刻的状态产生联系,则能够学习到该词的上下文信息,有利于文本深层次特征提取,所以在GRU 基础上选择双向循环控制单元(BiGRU)来建立这种联系。BiGRU 是由两个单向、方向相反、输出由两个GRU 状态共同决定的神经网络模型。
2 改进词向量的CNN-双层BIGRU 情感分析模型
情感分析的第一步是将计算机无法处理的文本信息转换成计算机能够识别的0-1 序列词向量,并利用词向量模型捕捉词语之间的关系,得到序列化后的词向量,然后将其送至深度学习模型中进行训练,所以是否能获得准确的词向量对于情感分析非常重要。
在上文已介绍了传统词向量模型——CBOW 模型,该模型能够通过上下文单词预测中心单词,得到序列化后的词向量矩阵。但在实际的情感分析文本中,如大量商品评论或电影评论中,经常会出现商品属性独特的专有名词或电影情节中的专业名词、人名等,加上评论表达过于口语化以及停用词使用存在不当,使得准确提取词向量的难度加大,原有CBOW 模型效果不佳。因此,本文提出一种改进的词向量模型,在原先的CBOW 模型基础上加入Attention 机制对词向量进行改进[20]。Attention 机制能够快速获得需要重点关注的目标区域,并抑制其它无用信息。
具体操作为:在CBOW 输入层与隐藏层之间加入Attention 机制,关注关键词提取并抑制其他干扰词影响。加入Attention 机制后的CBOW 模型如图1所示。

Fig.1 CBOW model after adding the attention mechanism图1 加入Attention机制后的CBOW 模型
CBOW 模型的输入是每个词的one-hot 向量,设其为vj。改进后的CBOW 模型加入Attention 机制后,模型输入为:


其中,第i 个词通过softmax函数进行归一化计算权重得分,得到可用权重。通过式(4)得到:

其中,Zi是Attention 机制中所需的训练参数,Pi、Qi是由不同单词之间的关系和权重所决定的。这一步是将Query与Key进行相似度计算得到权值的过程。
最后经过Attention 机制得到的输入词向量为:

在加入Attention 机制的CBOW 模型中,经Attention 机制得到的输出向量作为CBOW 模型隐藏层输入。在经过隐藏层和输出层计算后,得到模型处理后第n 个单词的词向量如下:

之后,将改进后的词向量模型得到的vnword送入深度学习模型中进行训练。
在之前的情感分析深度模型中,通常将CNN 模型与LSTM 模型、GRU 模型或BILSTM 模型融合以获取深度学习结果,速度与准确率都不太高,本文提出一种将CNN 与双层BIGRU 模型相融合的方式进行情感分析,原因如下:①GRU 模型只有2 个门:重置门和更新门,相比有输入门、遗忘门和输出门3 个门的LSTM 模型,GRU 在达到相同效果的同时,具有更高的时间效率;②双向GRU 模型能学习到该词的上下文信息,有利于文本深层次特征的提取;③最后在BIGRU 模型基础上叠加一层BIGRU,从而丰富了特征信息,并加强了模型的特征学习能力,提高了文本情感分析的准确性,该方式相比之前的深度学习模型,准确率和速率都更高。
其融合过程主要通过以下几个步骤实现:
(1)将上文加入Attention 机制的CBOW 模型得到每个词的词向量vi∈Rn×d作为输入层的输入向量,其中n是词数,d是向量维度,则初始输入矩阵S 可表示为S=(v1,v2,…,vn)。
(2)利用CNN 提取局部信息特征。CNN 卷积层接收输入层传入的词向量,在卷积层中通过设置3 种大小不同的滤波器提取h 个相邻词汇之间的静态局部特征,公式如下:

其中,w 是卷积核,h是卷积核尺寸,vi:i+h-1是i到i+h-1 个词组成的句子向量,b是偏移量。通过卷积层后得到特征矩阵c=[c1,c2,…,cn-h+1],对卷积层得到的句子局部特征矩阵c 进行下采样,得到局部值的最优解Mi。这里采用最大池化技术,公式如下:

由于BiGRU 输入必须是序列化结构,池化将中断序列结构c,因此需要添加全连接层,将池化层后的向量Mi连接成特征矩阵U=[M1,M2,…,Mn]。
(3)将U 作为第一层BIGRU 的输入。BIGRU 由正向GRU、反向GRU、正反向GRU 的输出状态连接层组成,BIGRU 网络模型具体结构如图2所示。
BIGRU 模型由输入层、隐藏层、输出层构成,其中隐藏层由两个方向的G R U 构成。正反向GRU分别得到两个对应隐藏层的输出量其计算公式如下:
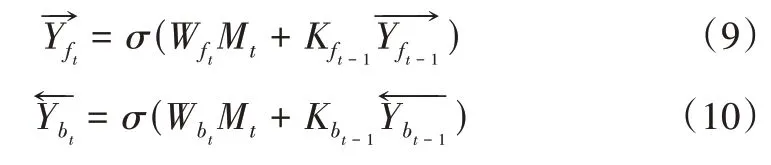

Fig.2 Specific structure of BIGRU model图2 BIGRU模型具体结构
其中,σ表示sigmoid 激活函数,相当于门控信号;Mt表示在t 时刻整个模型的输入值;分别表示t 时刻正向GRU和反向GRU的权重矩阵分别表示上一时刻正向GRU和反向GRU的权重矩阵分别表示t 时刻隐藏层的正向GRU和反向GRU输出分别表示上一时刻正向和反向GRU 隐藏层输出。
(4)将两个输出特征向量合并,得到BIGRU 输出层向量Z′t:

(5)在单层BIGRU 模型上再堆叠一层BiGRU 单元,形成双层结构以增强特征。将上一步得到BIGRU 模型的最终输出Z′t作为第二层BIRGU 的输入,在第二层BIGRU中,Z′t相当于第一层BIGRU的输入Mt。分别计算第二层BIGRU正向和反向GRU在t时刻的输出计算公式如下:

其中,Z′t表示在第二层BIGRU 中t 时刻的输入分别表示t 时刻正向GRU 和反向GRU 的权重矩阵;分别表示第二层BIGRU 中上一时刻正向GRU和反向GRU的权重矩阵分别表示上一时刻正向和反向GRU 的隐藏层输出。

在两层之间需要添加一个大小为0.25 的dropout 层,以减少训练过程的拟合。
(7)最后由情感分类层依靠其中的sigmoid 分类器完成情感分类。经过前面的步骤,已将蕴含实际含义的文本信息转化成用词向量组合而成的序列。本文的情感分析任务是对文本情感进行二分类,即将情感分为两类:正向和负向。sigmoid 分类器在接收到含有语义信息的序列后,因其输出范围是0~1,会将结果转换为概率进行分类。结果大于等于0.5 为正向情感,小于0.5 为负向情感,很适合二分类问题预测,从而最终完成情感极向预测。
3 实验与分析
3.1 实验环境
本次实验基于Windows10 操作系统,处理器为Intel(R)Core(TM)i7-8550U,内存大小为8G,硬盘大小为1T。主要使用底层框架为Tensorflow 的Keras 深度学习API 训练神经网络模型,其版本号为2.3.1,用Python 语言进行实现。
3.2 实验数据集
本文实验数据集是从购物网站中爬取的10 个类别商品的共计6 万条评论,其中正向情感与负向情感的评论各一半,均为3 万条。数据集中每一条评论均被标记好情感类别:正向评价标注为1,负向评价标注为0。按照8:2 的比例划分训练集和测试集,即4.8 万条评论用于训练,1.2万条评论用于测试。
3.3 实验预处理与模型参数设置
首先,将数据集顺序全部打乱,使正向与负向评论不会集中在一起,否则会影响模型分类的准确性;其次,对评论文本进行数据清洗,先去除停用词,再使用jieba 分词对文本进行分词,并用词向量训练工具将单词转化为向量;之后,将分词后的词向量输入到词向量预训练模型,即改进后的CBOW 模型中,设置句子最大长度120。若句子超过120 个词,则超过的部分会被删除;若句子不足120 个词,则对其进行向右补0 操作。设置3 种大小的卷积核,分别为2、3、4,设置词嵌入维度为100,步长为1。模型参数设置会影响分类效果,主要模型参数有:epoch、batchsize、optimizer、learning rate、activation。经过模型的多次迭代,配置最优参数,使得模型的分类效果最佳。详细参数设置如表1所示。
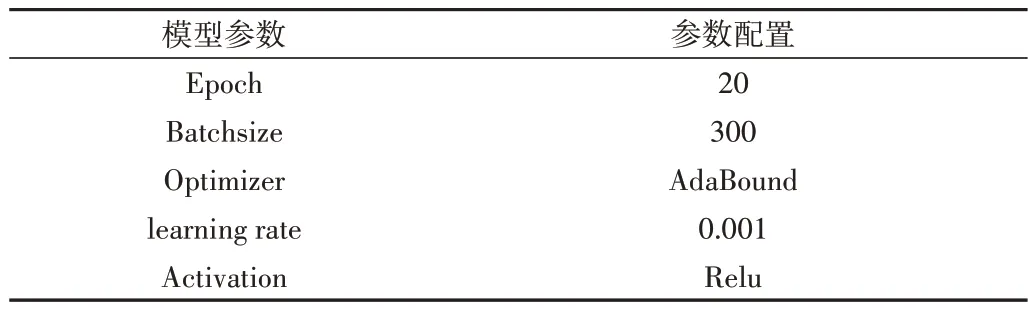
Table 1 Model parameter settings表1 模型参数设置
3.4 实验评价标准
对于深度学习模型,一般有4 个评价指标对模型进行评价:①准确率(Accuracy)。所有预测正确(包括正向和负向)的样本占总样本的比重;②精确率(Precision)。正确预测为正向的样本占全部预测为正向样本的比例;③召回率(Recall)。正确预测为正向的样本占全部实际正向样本的比例;④F1值。精确值与召回率的调和均值。
3.5 实验结果与分析
在10 个商品分类的评价数据集中,首先在词向量不变的前提下,将本文提出的CNN-双层BIGRU 模型与CNN、LSTM、GRU、CNN-LSTM、CNN-GRU、CNN-BILSTM、CNN-BIGRU 模型分别作比较,结果证明CNN-双层BIGRU模型的效果优于其他模型。实验结果如表2、图3所示。

Table 2 Comparison of model results表2 模型结果比较

Fig.3 Experimental results of each model图3 各模型实验结果
其次,经过词向量的改进,即在CBOW 模型中加入Attention 机制后,将本文提出的CNN-双层BIGRU 模型在词向量改进前后的准确率变化进行对比,如图4所示。
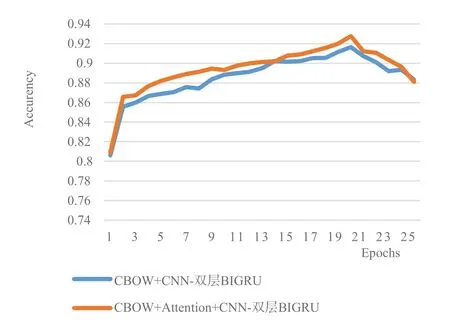
Fig.4 Changes in accuracy before and after word vector improvement图4 词向量改进前后准确率变化
最后,将所有模型的训练时间进行比较,结果如表3所示。

Table 3 Comparison of model training time表3 模型训练时间比较
从实验结果可得出以下结论:
(1)根据图3 和表2 可知,带有双向序列的融合模型CNN-BILSTM、CNN-BIGRU 比不带双向序列的融合模型CNN-LSTM、CNN-GRU 的准确率要高。如CNN-BIGRU 的准确率和精确率相比CNN-GRU 分别提高了0.33%和0.4%,说明双向序列模型考虑了文本的先后关系,能更准确地提取文本上下文的信息特征,提高情感分析的准确率。且根据表3 可知,CNN-BILSTM 和CNN-BIGRU 同样是双向序列的融合模型,但在同样的轮次训练中,CNNBILSTM 的训练时间为67s,准确率为91.19%,而CNN-BIGRU 的训练时间为64s,准确率为91.38%。训练时间减少了3s,准确率提高了0.19%,原因在于GRU 比LSTM 的模型结构更简单。因此,无论从时间还是准确率上,CNN-BIGRU模型都更胜一筹。
(2)多叠加一层BIRGU 的CNN-双层BIGRU 模型与CNN-BIGRU 模型相比,其准确率、精确率、召回率、F1值分别提高了0.27%、0.23%、0.15%和0.24%,说明叠加的一层BIGRU 结构能够捕捉到更丰富的信息,提高了情感分析的准确性。
(3)由表3 和图4 可知,在CNN-双层BIGRU 模型中,采用改进后加入Attention 机制的CBOW 模型获取词向量,相比正常只采用CBOW 模型的CNN-双层BIGRU 模型,整体上的情感分类准确率更高。当迭代次数为20 次时,二者均达到了各自准确率的峰值,且仅相差1.21%,说明能准确、快速提取到文本中的重要词向量对于模型分类的重要性。以上实验证实了本文提出的改进词向量的CNN-双层BIGRU 模型在情感分析中具有较好效果。
4 结语
本文主要通过两方面对传统情感分析方法进行改进:在词向量方面,在对文本进行分析时,发现即使再优秀的模型,若对数据集文本中的每个词不能准确地进行提取与定位,效果也会不佳,故加入Attention 机制进行改进;在模型方面,将能提取局部信息的CNN 与能加强特征信息以获取上下文信息的双层BIGRU 相融合,提高了模型准确率。虽然通过改进提高了模型准确率,但由于模型叠加层数多,导致时间效率不高,且随着数据规模的增长,计算会更加复杂,训练时间也会显著变长,因此下一步将继续寻找可兼顾准确率与时间效率的模型进行情感分析。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
医学食疗与健康(2021年27期)2021-05-13
现代装饰(2019年11期)2019-12-20
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
舰船科学技术(2016年1期)2016-02-27
上海电机学院学报(2015年3期)2015-02-28
电视技术(2014年19期)2014-03-11
电视技术(2014年19期)2014-03-11
