
引入外部知识的社交平台立场检测模型
2022-08-25 09:56周珂馨周立欣陆啸尘
软件导刊 2022年8期
刘 臣,周珂馨,周立欣,陆啸尘
(上海理工大学管理学院,上海 200093)
0 引言
立场是在给定话题下用户观点的表达,而立场检测是自动检测用户对于给定话题发表的评论是支持、反对或者中立[1]。随着社交媒体的不断发展,人们更愿意通过微博、Twitter 及Facebook 等在线社交平台来表达自己的观点立场,发表对热门话题的评论,使得从在线评论中自动提取特征信息进行立场检测得到了学术界的广泛关注[2]。
随着立场研究的发展,立场检测任务在国内的NLPCC及国外的Semeval 等多个竞赛中被相继提出。根据这些竞赛提出的立场检测任务,有诸多学者利用该任务提供的数据集构建立场检测模型。如Vijayaraghavan 等[3]首先将给定数据根据立场类别进行划分,然后基于卷积神经网络(CNN)分别从单词级和字符级两个层面构建立场检测模型,最后针对每个类别的数据选择两个检测模型中性能最佳的模型进行预测。实验结果表明,该方法具有一定的鲁棒性,但是采用多个深度学习模型的方法存在计算量过大的问题。为了减少计算量,Siddiqua 等[4]提出基于深度学习方法的单个立场检测模型,该模型利用卷积核过滤输入的评论文本嵌入表征,然后将过滤好的向量分别输入到基于注意力机制的双向长短期记忆网络(Bi-LSTM)[5]和嵌入的长短期记忆网络(LSTM)[6]中得到特征向量,最后将两个特征拼接后进行分类。该模型通过构建基于注意力机制的长短期记忆网络集成模型,从而有效捕获立场信息。
目前已有研究采用的方法大多是基于评论文本特征的模型,而这些模型无法捕获到评论与评论之间的网络结构关系[7]。为获取评论之间的网络结构关系,本文采用门控图神经网络(GGNN)技术捕获评论的立场特征。此外,还有研究在对评论进行数据预处理时,将手动提取的文本特征和预训练模型(如word2vec、bert 等)获取的特征向量相结合,得到评论的表征向量[8]。虽然采用这些方法可有效提高立场检测的准确性,但是对于一些给出文本信息不足的评论并不能有效提取特征信息。Kapanipathi 等[9]的研究表明,通过引入外部知识提供评论文本的背景知识,可有效应对文本上下文信息有限的问题。因此,本文通过知识图谱对评论的关键信息引入外部知识,并基于RGCN模型获取评论的特征表示。
本文训练了一个引入外部知识的门控神经网络模型KRGGNN,在捕获评论与评论之间网络结构关系的同时,解决了评论文本可提取信息不足的问题。首先,利用开源的知识图谱WordNet 针对评论文本关键单词进行外部知识的引入,并将这些知识作为实体构建图模型,然后利用RGCN 获取推文的文本表征,接下来将评论之间的网络结构及相应的表征向量输入到GGNN 中获取立场信息,最后将最终评论的特征向量输入到Softmax 层进行立场分类。
1 相关研究
随着互联网信息技术的发展,立场检测任务在多个竞赛中被相继提出。立场检测研究方法主要分为以下两类:
(1)基于特征工程的机器学习立场检测方法。传统研究主要采用机器学习方法进行文本立场检测,包括支持向量机(SVM)、逻辑回归、朴素贝叶斯以及决策树等。Küçük等[10]针对多目标的立场检测任务,采用SVM 分类器对与体育相关的3 个不同版本的推文进行立场分类,同时在对推文进行特征表示时使用了联合特征;Addawood 等[11]分别采用SVM、朴素贝叶斯及决策树对推文进行立场分类,同时在构建文本特征时结合了情感、推文论证等多个特征。实验结果表明,推文的情感及语气等对立场分类起着重要影响,基于SVM 的模型在测试集中取得了较好效果。但是,这些研究主要通过人工提取特征构建文本特征表示,通过输入分类器进行信息获取,因此人工成本较高。
(2)基于深度学习的立场检测方法。与传统机器学习方法不同,基于深度学习的方法能够对文本特征进行自学习与筛选,不仅能减少人力成本,而且能提升模型的稳定性。Mohtarami 等[12]利用端到端的方式自动进行立场检测,分别利用CNN 和LSTM 对输入的推文信息进行特征提取,引入相似性矩阵计算与推文目标话题或声明的相关性,提取与声明或话题更相关的文本特征信息。虽然该方法可自动学习文本特征,并能获取有利的文本信息,但其只关注评论的文本特征,而忽略了评论相互之间的网络结构信息。Kochkina 等[13]以社交平台推文为对象,基于评论之间的相互关系建立多个分支,并利用LSTM 实现构建的评论分支中前后评论之间信息的相互传递。该方法将文本特征与推文之间的网络结构信息相结合,可有效地捕获推文立场信息。Li 等[14]以新闻文章为研究对象,采用Hierarchical LSTM[15]等多种方法,基于图卷积神经网络(GCN)对以政治人物、用户和新闻文章为对象构建的图模型,获取推文之间的网络信息。实验结果表明,联合文本与网络特征进行立场检测的效果明显优于仅利用其中之一的特征进行立场检测。因此,本文在构建评论文本特征的基础上,根据评论之间的网络结构构建图模型,并利用GGNN 获取评论之间的网络结构信息。
针对立场检测任务,给定评论的文本语言表达情况对最终分类结果起着非常重要的影响。然而,目前大多数研究的关注重点仅限于给定的评论文本,若遇到文本质量不佳或可获取信息不足的情况,则可能导致最终的预测效果不佳。Kapanipathi 等[9]将立场检测转变为文本蕴含任务,利用知识图谱实现文本外部知识的引入,提取句子内外相关实体构建图模型,并利用RGCN 进行分类。Li 等[14]提取句子的有用词,针对这些词引入同义词、上位词、下位词等外部信息,并利用注意力机制对其进行编码,最终进行句子分类。以上研究表明,对给定的目标对象引入外部知识可有效弥补句子内部缺失的信息。本文在进行立场检测前对评论文本进行关键词提取,利用WordNet 知识图谱检索与该关键词有关的其他词汇以构建知识图模型,再利用RGCN 进行推文特征提取以获取推文的初始表征。
针对RumorEval 2019 的立场检测问题,本文不仅将推文的文本特征与网络结构相结合,利用GGNN 进行立场检测,而且在构建文本表征时通过引入文本外部知识,获取基于评论文本的额外背景知识。
2 基于GGNN 并引入外部知识的立场检测模型
本文利用WordNet 知识图谱对数据集的评论信息引入外部知识,补全评论文本可能缺失的信息。本文提取评论文本中的关键单词映射到知识图谱中构建节点,并检索与该节点相关的一阶邻点以获取全局图G。为了提取知识图谱中有价值的信息,通过PPR 过滤方法对该全局图G提取相关子图G′,并利用RGCN 进行图表示学习,进而获取评论的知识表示。同时,利用门控神经网络(GGNN)技术将评论文本特征与评论结构关系相结合进行立场检测。具体模型架构KRGGNN 如图1所示。

Fig.1 Stance detection model KRGGNN based on GGNN and introducing external knowledge图1 基于GGNN并引入外部知识的立场检测模型KRGGNN
2.1 引入外部知识的评论表示学习
2.1.1 基于知识图谱的评论全局图构建
首先,针对目标评论TC进行语义信息提取,利用nltk库对目标评论TC进行了分词。从评论TC中提取关键信息所构建的单词集合W如下:

式中,TC为目标评论,W为TC中提取的关键单词集合,wi为在TC中提取的某个关键单词。
Kapanipathi 等[9]的研究表明,对文本对象引入外部知识可有效捕获缺失信息并构建文本特征表示。为引入与评论相关的外部知识,需要将评论TC提取的单词集合W映射到WordNet 知识图谱,并检索其他与W相关的外部单词。即针对评论TC中的单词wp,在WordNet词典中检索与该单词有关的其他单词,分别为:上位词、下位词、同义词和蕴含词。
针对评论TC中的单词wp,从以上搜索空间中检索外部单词集合Wp′,并将wp作为图G的内部节点ip,Wp′作为图G的外部节点集合op,且该集合为节点ip的一阶邻点。
为构建关于目标评论TC的全局图G,将词集W中所有提取的单词作为图G中的内部节点集I,并将引入的外部词集W′作为图G的外部节点集O。由于目标评论中各个单词通过引入外部知识构建的子图是相互独立的,为充分捕获评论中所有单词的相互关系,对所有子图构建的外部节点集O和内部节点集I中有关系的节点添加连边e(i,j)=(ni∈I,nj∈O)。在构建全局图G之后,由于引入的外部知识过多会使数据集产生很大噪声,Kapanipathi 等[9]证明了通过节点过滤方法(PageRank 算法[16])可有效解决噪声过大的问题。因此,本文需要对全局图G中的所有节点进行过滤,从而提取一个大小合适,且包含的节点与评论TC较为相关的子图。
2.1.2 全局图节点过滤
本文使用PPR 算法对全局图进行节点过滤,获得与内部节点最相关的外部邻居节点。针对图G中的所有节点,首先需要初始化图中每个节点的概率分数p∈P:

式中,I表示图中的内部节点集合,即评论中的关键单词集合。针对图中节点是评论中的单词,初始化节点的概率分数为并且外部节点的概率分数p为0。从初始的概率分数可以看出,内部节点对于图G的重要性较高。接下来需要计算图G中节点的概率分数:
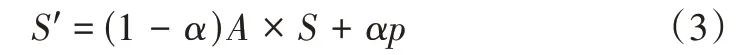
式中,S∈Rn是图中所有节点的PPR 分数,A∈Rn×n是图G的邻接矩阵。α∈(0,1)为衰减因子,通过设置α参数,可将节点的PPR 分数在迭代更新后收敛于某一固定值,最终获取每个节点的RRP 得分Si∈R。本文设置一个阈值θ,利用该参数过滤掉图G中引入的外部节点O中Si∈R分数小于阈值的节点,并删除连接该节点的边。
2.1.3 基于RGCN的子图编码
为获取评论X的向量表示,本节采用RGCN 方法[17]计算子图G′的图表示。该方法是图卷积GCN 方法的扩展,基于该方法可处理不同类型边的图模型:

式中,R代表图G′不同属性边的集合,Nu,r表示节点u连接边属性为r的邻居节点集合是可学习参数。cu,r是常量,在本文中将该常量设为,即邻居节点个数。同时,对于图G′中的每一个节点都额外添加一条自循环边,使得模型在编码过程中保留节点自身属性。本文设置了两种类型的边,分别为自循环边以及图G′中节点之间的连边。
最后,对于图G′中每个节点的隐藏表示hv,需要将其聚合形成基于TC评论的图表示:

其中,V是图G′的节点集合,W为可学习参数。通过将所有节点聚合形成图表示,从而获取评论TC的特征表示。
2.2 模型构建
2.2.1 图模型构建
本文采用端到端的方式对评论进行立场检测。在2.1节中引入外部知识构建评论文本的特征表示后,本节考虑了评论之间的外部结构关系。鉴于给定数据集RumourEval 2019 是以对话线程的形式给出,本节针对数据集给定的对话线程构建图模型,并采用GGNN 技术捕获评论之间的结构关系。首先给出了对话线程的定义:
针对某一特定话题T,S是对该话题发布的一则原始评论。同时,针对该评论S有一系列回复Ri,如图2所示。

Fig.2 Conversation thread and graph model图2 对话线程与图模型
在图2 中,原始评论S被id 分别为6l5b2no、dl5xleh、dl5hnsx 的用户进行了回复,同时用户dl5xleh 又被用户dl6bm8l 进行了回复。通过以上用户之间的互动,将原始评论及用户之间的所有回复评论作为一个对话线程,每一条评论都持有对话题T的立场。因此,对话线程由原始评论和多条回复评论构成,即:C<—{Source,Reply1,Reply2,Reply3,Reply4},并且评论与评论之间存在相互关系。接下来,针对图2(a)的对话线程构建图2 的图模型。其中,每个节点代表一条评论,每一个节点都带有立场标签,不同颜色的边代表不同属性。
2.2.2 基于GGNN的立场检测模型
本文采用GGNN[18]实现对话线程评论的信息传播。利用GRU 单元对目标节点的邻点进行信息传播。在将节点的特征表示X∈Rd传入到GGNN 模型之前,需要针对图模型构建邻接矩阵A。为了使建立的立场检测模型可以处理有向异质图,本文考虑到了出入射边以及边的类型。接下来是对邻接矩阵的定义:
假设图模型的节点集合N∈Rn具有r个类型的边,且深度为m的某一子节点Ni的父节点为Nj。对于邻接矩阵有:


式(8)中,H(1)∈Rn×d为初始化的节点隐藏状态,X∈Rn×d为图模型特征矩阵。在信息传播之前,用节点的初始表征X来初始化图G的隐藏状态H(1)。

其中,W1、W2、b1、b2、Wz、Wr、Uz、Ur、W和U为可学习参数。Iin、Iout分别为入出射边的隐藏表示。通过以上的节点信息传播,在迭代了一定的时间步T之后,得到最终所有节点的隐藏表示,其中d′为节点输出维度。
通过将对话线程的初始特征矩阵X∈Rd与最终隐藏表示H(T)进行拼接,以保留节点自身的特征,然后将y∈Rn×c输入到Softmax 的激活函数中进行立场检测,将预测概率最大的评论作为预测立场:

考虑到本文所解决的问题是一个多分类问题,即支持、否定、评论和中立,本文采用交叉熵损失函数来训练模型。
3 实验与分析
3.1 实验数据集及评价指标
本文采用的数据集是由Semeval 2019大赛发布的谣言立场检测数据,其中持有支持立场的数据有1 184 条,否定的有606 条,质疑的有608 条,评论的有6 176 条。数据中所有评论信息的立场均是针对气候变化、自然灾害等9 个不同主题的突发事件。
首先对数据中的评论文本进行数据清洗。由于评论文本中存在空白或含有无用字符的情况,本文删除了这些无用的评论文本,以防止类似情况给模型训练带来噪声。预处理后的数据集分布如表1所示。

Table 1 Dataset distribution表1 数据集分布
接下来将过滤后的数据集作为训练语料库,用nltk 库对评论文本进行分词。为了引入外部信息,本文检索了WordNet 的corpus 中与评论中提取单词相关的上位词、下位词、同义词等,利用Glove获取评论信息的词向量。
由于本文采用的数据集存在严重的数据分布不均匀的问题,本文使用宏平均(MacroF1)作为立场检测模型的主要评估指标,其余评估指标也具有一定参考性。具体公式如下:

其中,P、R、F1 表示单个立场类别的评估指标,分别为精确率、召回率,以及P和R的调和平均值。TP、FP、FN、TN分别表示预测正样本正确的个数、预测正样本错误的个数、预测负样本错误的个数和预测负样本正确的个数。宏平均的计算公式如下:
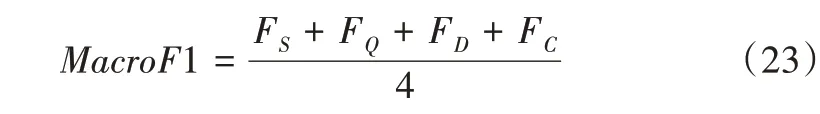
其中,S、Q、D和C表示评论的立场类别分别为:支持、质疑、否定和中立。针对多分类任务而言,对每个评估指标求均值得到宏平均MacroF1。宏平均MacroF1 值越高,模型预测性能越好。
3.2 实验参数设置
通过对比不同参数值的实验结果后,本文设置词向量维度为200d。PPR 的阈值θ也被作为超参数进行调整。本文对θ分别在{0.2,0.4,0.6,0.8}中进行实验取值,实验结果表明,当θ值为0.8时效果最佳。
接下来将局部子图输入RGCN 以获取每条评论的特征表示,并利用GGNN 捕获对话线程中评论与评论之间的外部结构关系。具体实验参数设置如表2所示。

Table 2 Hyperparameters setup表2 超参数设置
其中,hidden_size 表示局部子图输入到RGCN 中的单词隐藏层大小,num_bases 表示RGCN 的基向量个数,num_layers 表示RGCN 的堆叠层数。为了避免数据在训练过程中过拟合,本文设置dropout 值为0.5。n_steps 表示通过对话线程构建图模型时,在GGNN 中进行3 次信息传播。同时,本文通过多次实验比较,发现设置学习率为0.001时,模型性能表现最好。
3.3 对比实验
(1)KGRGCN:是本文提出模型的一个子模型。该模型是基于本文提出的模型KRGGNN 去掉网络结构部分。本实验首先利用WordNet 知识图谱对原始数据引入外部知识,然后利用RGCN 对构建的子模型进行信息传播,最后直接利用Softmax 进行立场分类。
(2)TreeGGNN:是本文提出模型的一种变体。实验在数据预处理阶段利用word2vec 得到的词向量取均值,并与其他特征拼接得到评论的初始向量,然后采用GGNN 捕获立场信息。
(3)CLEARumor[19]:预处理阶段采用ELMo 方法[20],该方法基于双向长短期记忆网络(BLSTM)获取评论文本的上下文信息,并利用卷积神经网络模型进行立场检测。
(4)BranchLSTM:基于LSTM 模型对对话线程构建的分支架构进行评论表征向量信息获取,该模型在充分利用文本表征的同时,也考虑到了评论之间的网络结构关系[13]。
3.4 实验结果分析
本文实验针对社交平台Twitter 和Reddit 的评论信息进行立场检测。表3 通过将KRGGNN 立场检测模型和其他基准模型进行比较来验证本文模型的有效性。其中,采用MacroF1 和Precision 进行模型性能评估。从表3 中可以看出,KRGGNN 模型在所有模型中,宏平均和精准度都最高。相较于其它模型,CLEARumor 模型的整体评估性能最差,因为该模型只利用文本的上下文信息,并没有充分从给定文本中提取立场信息。TreeGGNN 模型在评估指标的性能表现上与KRGGNN 相当,表明在考虑文本特征的同时,GGNN 能有效提取评论之间的网络结构关系。同时,KRGGNN 的性能优于TreeGGNN,说明利用知识图谱引入外部知识可更加充分地捕获评论的文本特征信息,为立场检测模型提供更准确的评论初始表征。
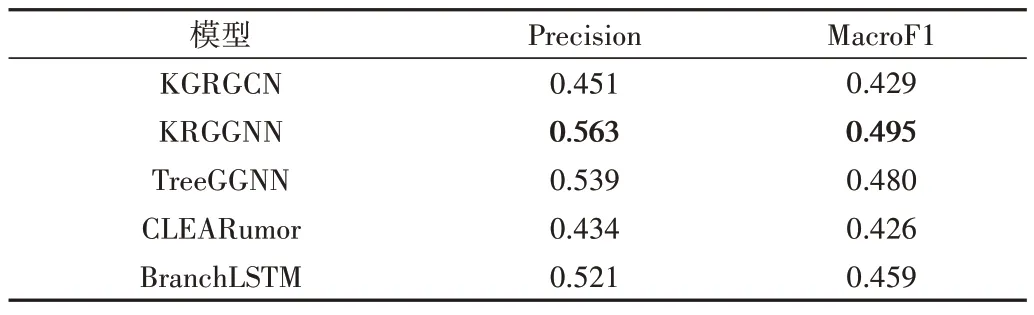
Table 3 Comparison of the evaluation metrics of each model表3 模型各项评估指标比较
表4 为各个模型基于4 个立场类别的F1 分数。由表可知,“否认”的评估分数在所有模型中明显低于其他类别,可能存在两方面原因:①原始数据集分布不均匀,“否认”的数据与其他数据的比例为1:11,这也导致模型对其他类别数据具有一定偏见,并对该类别的数据训练不足;②针对给定的“否认”评论文本,一般表现为含蓄地表达否定的想法,因此文本语气以及表达方式对模型能否精准提取有效信息具有非常重要的作用。同时,相比于其他baseline,虽然本文模型存在某些类别的F1 分数不如其他模型的情况,但其在各个类别中的性能与其他模型相比较为平均。因此,本文模型相比其他模型存在更少的偏见,泛化能力更强。

Table 4 Comparison of F1 scores of each model表4 各个模型的F1分数比较
鉴于数据集是由Reddit 及Twitter 两个平台的数据集构成,本文进一步探讨了平台数据对模型的影响,如图3所示。
实验结果表明,模型对Reddit 平台数据集的评估性能基本优于Twitter,可能的原因为Reddit 平台用户在发表评论时较为正式,而Twitter 平台的评论较为口语化,导致模型相较于Twitter 平台而言,更易于从Reddit 平台评论中提取特征信息。然而,在立场类别“Deny”上,模型的F1 为0。由于给定的Reddit 平台数据中含“Deny”的数量很少,导致模型在训练过程中不能学习到关于“Deny”类别评论的基本特征,因此其预测该类别的能力很差。总体而言,本文研究通过结合知识图谱模型和RGCN 模型,将推文的文本特征与结构信息相结合并引入外部知识,有助于模型的立场检测性能和表现。

Fig.3 Comparison of predictive performance of models based on different platforms图3 基于不同平台预测性能比较
4 结语
本文提出一种基于GGNN 并引入外部知识的KRGGNN 立场检测模型,能够在应对评论文本上下文信息不足问题的同时,考虑评论之间的网络结构关系。首先通过对评论文本基于知识图谱引入外部知识来构建图模型,利用RGCN 获取评论文本的初始表征,然后采用门控图神经网络(GGNN)模型在获取文本特征的同时,结合评论之间的网络结构关系实现评论之间的信息传播。实验结果证明,针对评论引入外部知识获取文本表征,并考虑评论之间的网络结构关系能够有效提升立场检测模型性能。然而,由于数据集的分布不均匀,使得训练之后的立场检测模型存在预测不稳定以及偏见较强的问题。在接下来的工作中将尝试利用缓解偏见的损失函数以及下采样等方法提高模型检测的稳定性。
猜你喜欢
河北画报(2020年10期)2020-11-26
阅读(快乐英语高年级)(2020年8期)2020-01-08
智慧少年·故事叮当(2018年11期)2018-05-14
意林(绘英语)(2017年5期)2017-05-15
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
海外英语(2006年8期)2006-09-28
中国青年(1949年20期)1949-08-17
