
基于Realized GARCH模型已实现波动率预测研究
——以沪深300指数为例
2022-09-05 09:15钱星曌
河南科技大学学报(社会科学版) 2022年4期
胡 倩,钱星曌
(安徽大学 经济学院,合肥 230031)
中共十一届三中全会以来,社会主义市场经济的广度与深度不断提升,中国经济高速发展,社会对资本的探索不断加大。上交所、深交所的成立标志着证券市场时代已然到来,然而证券市场作为金融市场,会受到来自各方的干扰产生波动。对投资者来说,波动情况与资产价格直接相关,是其进行投资的依据。同时,对于股市的剧烈波动如果不加以防范,必然会使市场不稳定,对社会经济的发展造成危害。鉴于此,金融资产的波动性研究就成为众多学者的研究热点。
一、文献综述
由于金融产品收益率序列具有异方差性和波动聚集效应,Engle提出了自回归条件异方差(ARCH)模型[1]。Bollerslev对ARCH模型作出改进,提出了广义自回归条件异方差(GARCH)模型[2],该模型被广泛应用。徐立霞将GARCH族模型用于中国股市波动性的研究,运用GARCH、TGRCH和EGARCH模型拟合中国股市的波动性,结果表明,股票收益率序列存在尖峰厚尾、波动聚类的特性,GARCH族模型能很好地拟合股市波动性0。但是,上述模型大多使用低频数据,属于低频波动率模型。随着科学技术的发展,获取数据的技术越来越成熟,高频数据的收集呈现爆炸性发展,众多学者开始研究高频波动率模型。
Andersen和Bollerslev最早提出了已实现波动率(Realized Volatility,简记为RV)的概念,并首次明确了高频数据波动率的测度指标[4]。Torben和Andersen将RV和条件协方差矩阵联系起来,并用美元、日元等汇率的高频数据进行拟合,发现拟合效果很好[5]。此后学者们在此基础上提出了各种已实现测度,如Martens和van Dijk根据金融资产价格极值理论提出了已实现极差波动率(RRV)[6];Ole和Barndorff构造RV的核密度估计表达式,提出了已实现核波动(RK)[7];Christensen、Oomen和Podolskij基于分位数提出了新的已实现测度[8]。同时,如何把波动率和已实现测度有效结合且具有良好的预测效果成为学者们探究的重要问题。Hansen、Zhuo和Shek提出了Realized GARCH模型[9],添加已实现测度到GARCH模型中,并通过测量方程将条件方差与已实现测度联系起来。此后,王天一和黄卓扩展了在数据分布形态呈厚尾分布的情况下已实现GARCH模型,并发现t分布下拟合的模型具有更高的预测精度[10]。黄友珀、唐振鹏和周熙雯研究了Realized GARCH模型在偏t分布下的拟合效果[11]。玄海燕等发现Realized EGARCH模型在t分布和偏t分布下的拟合效果显著优于正态分布[12]。Louzis、Xanthopoulos和Refenes将改进的已实现测度引入Realized GARCH类模型中进行分析[13]。于孝建和王秀花提出了针对混频数据的Realized GARCH模型,发现预测效果很好[14]。蒋伟和顾研引入广义已实现测度,数据选取上证综指和沪深300指数,发现广义已实现波动率能够提高Realized GARCH模型对市场风险的预测能力[15]。
在已实现GARCH类模型中,已实现测度的选择十分重要。目前大多数文献使用RV作为已实现测度。受上述文献启发,基于沪深300指数的5分钟高频数据,建立Realized GARCH模型,基于已实现测度RV和改进后的RMV的模型分别在正态分布、t分布、GED分布下展示其拟合效果。结果表明:不论是基于RV还是改进后的RMV,似然函数值都在t分布下最大,模型拟合效果最优,正态分布下效果最差;而且基于RMV拟合的模型相比基于RV在估计精度上有所提高,风险价值VaR的预测效果也表现更好。
二、模型及方法
(一)Realized GARCH模型
本文所使用的Realized GARCH模型是在GARCH模型的基础上进行拓展的,所以下面先给出GARCH模型的一般形式:

式(1)(2)统称为均值方程,式(3)称为方差方程。GARCH模型中过多的对于参数的限制条件使得实际估计起来可能达不到理想效果,而且用GARCH模型来拟合高频数据,可能无法拟合出数据的真实波动情况。
为此,选择Realized GARCH模型,其具体形式如下:

(二)已实现波动率的改进
由Andersen和Bollerslev提出的已实现波动率(RV)[4],将波动率的研究对象从低频数据转向高频数据。本文在已实现测度的形式上结合方差的思想,纳入平均水平,基于RV,得到改进后的已实现波动率(Realized Mean Volatility,简记为RMV),具体计算步骤如下:
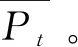
(7)
第二步,计算金融资产第t个交易日的收益率,rt,i表示第t个交易日内金融资产在第i个区间的对数收益率,见式(8)。与已实现波动率RV相比,其区别就在于用日内平均收盘价代替前一间隔区间的收盘价。
(8)
第三步,将第二步中计算得到的t个交易日的收益率进行平方后加总,如式(9)所示:
(9)
(三)样本外预测
为了检验Realized GARCH模型对沪深300指数的波动率预测效果,本文使用滚动时间窗口方法以获得样本外预测值,具体步骤如下:
(1)将沪深300指数的收益率序列按照4∶1的比例划分为估计样本和预测样本。
(2)用估计样本对Realized GARCH模型进行估计,预测次日波动率,滚动周期为一天。
(3)重复(2)中的操作,依次重复滚动预测,得到与预测样本同样数量的波动率预测值,将得到的预测值与真实值进行比较,采用均方误差MSE和平均绝对误差MAE这两个预测评价标准来反映预测效果如何。
MSE和MAE的具体形式分别如式(10)和式(11)所示:
(10)
(11)
(四)Kupiec失败率检验
VaR(Value at Risk)作为衡量金融市场风险的指标,表示在给定的置信水平下,金融资产在某一时期可能遭受的最大损失:
Prob=(ΔP>VαR)=1-α
(12)
其中,ΔP表示金融资产在时间区间△t内的损失额,α为给定的置信水平。
Kupiec提出了一种针对VaR模型的失败率检验方法,其基本思想是:假设VaR序列彼此相互独立,若VaR估计值小于实际损失额,记为失败,反之记为成功[16]。该检验通过检验实际失败次数和预期失败次数的接近程度,来避免过于低估或者高估风险。检验原假设为H0:P=P*,提出检验统计量表达式(13):
(13)
其中,P=N/T,N为失败天数,T为总检验天数,置信水平为1-α,期望失败率P*=α。而且LR值越小,模型估计越准确,效果越好。
三、实证分析
(一)数据来源与描述性分析
本文选取2014年1月3日—2020年12月30日共1 705个交易日的沪深300指数5分钟高频数据。数据来源于JoinQuant聚宽量化交易平台。股市每日交易时间为4小时,即每日Ln1n有48个高频数据,总共81 840个高频数据。收益率采用“收盘价-收盘价”的方式并且通过对数计算,形式如式(14)所示:
rt=lnPt-lnPt-1
(14)
其中,Pt为当前时刻收盘价,Pt-1为前一时刻收盘价。
图1-a5分钟收盘价的时序图显示沪深300指数的价格波动幅度较大,尤其在2014年—2015年这两年的波动程度非常剧烈;图1-b、c、d日收益率序列、RV序列和改进的RMV序列的时序图则显示每个序列都有明显的波动聚集效应。通过图2沪深300指数日收益率序列的频率分布图显示其分布的大致形态,其结果显示,与标准正态分布相比,沪深300指数的日收益率序列分布具有尖峰厚尾特征,说明该序列并不符合传统的正态分布假设。

图1-a

图2 日收益率频率分布图
表1给出了日收益率r、RV、改进后的RMV的基本描述统计量的信息。从均值看,三者的均值都接近0,可以忽略不计;从偏度上看,日收益率r分布左偏但是偏度较小,RV和RMV都呈右偏分布且偏度较大;从峰度上看,三者都呈尖峰分布,与图2尖峰厚尾分布形态也是吻合的;从J-B统计量和P值上看,这三个序列都显著拒绝了正态分布的假设,表明各序列都不服从正态分布。从ADF检验的结果看,日收益率r、RV和改进后的RMV都显著拒绝了原假设,即三者都是平稳序列。而且使用Ljung-Box检验验证收益率序列是否适合用GARCH族模型建模,发现给定5%的显著性水平,在从1到10的滞后阶数下,不存在ARCH效应的原假设都被显著拒绝。因此更加明显地验证了日收益率具有显著的ARCH效应,可以进行下一步的建模。

表1 日收益率r、RV、RMV的基本统计量
(二)模型参数估计
前面已经检验ARCH效应的存在,但由于滞后阶数过多会导致模型不稳定,因此本文选择Realized GARCH(1,1)模型进行实证研究。表3显示了基于RV和改进后的RMV的Realized GARCH(1,1)在三种不同分布下的参数估计结果。

表3 基于RV和RMV的Realized GARCH(1,1)模型参数估计
从结果来看,发现不论是改进前还是改进后,每种情况下三种分布的各参数估计结果都比较接近,这说明建立的Realized GARCH模型具有稳健性;基于RV下的模型估计参数在正态分布、t分布和GED分布下的标准误差几乎都大于基于RMV下的模型参数的估计标准误差,基于RMV的参数估计误差普遍较小,例如,基于RV的模型估计标准误差在各分布下都在0.16左右,而基于RMV的模型估计标准误差在各分布下则在0.05左右,GED分布下甚至只有0.005,标准误差显著降低。通常似然函数值可以体现模型的拟合效果,不论是基于RMV还是RV的似然函数值,都在t分布下取得最大值,表现最好,其次是GED分布,且远胜于正态分布下的拟合效果。这表明收益率序列具有尖峰厚尾特征,确实不符合正态分布的假设,用t分布拟合可以得到更好的拟合效果。
(三)波动率的样本外预测
采用滚动时间窗口方法进行样本外预测,将2014年1月3日至2020年12月30日共1 705个沪深300指数收益率数据按照4∶1的比例划分。估计样本长度为1 364,预测样本长度为341。其中,i表示滚动周期,当i=0时,则使用序列对Realized GARCH模型进行估计,预测次日波动率。本文选择滚动周期为一天,即i=1,依此重复滚动预测,得到341个波动率预测值。将得到的341个波动率预测值与真实值进行比较,采用均方误差MSE和平均绝对误差MAE这两个预测评价标准来反映预测效果如何。从表2的结果来看,基于RV的估计结果中MSE显示正态分布最好,这可能与收益率序列偏度不大有关,MAE则显示GED分布最好;基于RMV的估计结果中不论是MSE还是MAE,都选择了GED分布,其次是t分布,正态分布最差。另外,改进后的RMV在三种分布下的估计残差基本都略小于RV下的模型估计残差。

表2 预测残差
(四)VaR风险度量
模型拟合完成之后,投资者往往会关心模型对风险度量的效果如何。为此选择Kupiec失败率检验法来比较每个模型在不同置信水平下的VaR预测效果。其中,LR值越小,P值越大,模型越精确,可信度越高。
从表4可以看出,在显著性水平α=0.05时,基于RV的Realized GARCH模型在三种不同分布下LR值都较大,且检验的P值均小于0.05,拒绝原假设,说明得到的失败率与给定置信水平下的失败率相差较大,风险度量效果较差;而基于RMV的模型在三种分布下LR值明显减小,且P值都大于0.05,说明风险度量效果较好。在显著性水平α=0.01时,基于RV下的Realized GARCH模型只有在t分布下的P值较大,大于0.01,可以认为t分布下的风险度量效果稍好一些,在正态分布和GED分布下的P值都小于0.01;而基于RMV下的模型在三种分布下的LR值都很小,且P值远大于0.01,风险度量效果较好。

表4 预测样本上Kupiec失败率检验结果
图3(a)-(f)展示了在99%的置信水平下三种不同分布下RV和RMV的VaR拟合效果。可以看出不同分布下基于RV的收益小于VaR的部分都要少于基于RMV下的部分,说明基于RV的模型与基于RMV的模型相比更低估了风险价值,这和Kupiec失败率检验结果也是一致的。

图3-a 正态分布下基于RV的VaR预测
四、结论
已实现波动率是高频波动率模型中体现数据波动的重要测度,本文在RV的基础上做出改进,得到改进后RMV,以沪深300指数为例,利用Realized GARCH模型对其波动率进行预测研究,得到以下结论。沪深300指数的收益率序列具有明显的波动聚集特征,且基于正态分布、t分布和GED分布的参数估计结果具有稳健性;由于收益率序列并不符合正态分布假设,两者都是在t分布下似然函数值最大,模型拟合效果最优,正态分布下效果最差;改进后的已实现波动率相比之前的已实现波动率在残差上要有所降低,估计精度提高,并且在VaR的预测效果上更好。针对股市高频数据的波动率的建模,对投资者掌握市场动向具有重要意义,对已实现波动率进行改进并且取得较好的预测效果意味着对已实现测度的选择仍可以拓展思路,可以通过改进其形式不断提高模型的拟合效果。
猜你喜欢
科技资讯(2020年14期)2020-06-27
小资CHIC!ELEGANCE(2018年24期)2018-08-13
智富时代(2018年1期)2018-03-26
智富时代(2018年1期)2018-03-26
数学教学通讯·高中版(2017年3期)2017-04-17
数学教学通讯·初中版(2014年2期)2014-03-21
中学生数理化·高考版(2008年2期)2008-11-01
