
网络信息学及其知识发现前沿与前瞻
2023-06-18 19:44武瑞敏张志强
图书与情报 2023年1期
关键词:大数据
武瑞敏 张志强
摘 要:大数据时代,新兴前沿技术的迅猛发展对网络计量学提出了新的发展要求,文章在学科信息学的学科体系框架下提出了一个全新的概念——“网络信息学”。从网络信息学兴起的背景出发,概述了从网络计量学到网络信息学的发展过程;明确了網络信息学的概念内涵、数据基础以及关键理论方法技术;重点剖析了在网络信息学框架下,重要跨学科领域的知识发现、学术影响力与竞争力评价等四个方面的知识发现前沿与进展。并由此提出,网络信息学利用新兴前沿信息技术挖掘网络大数据以揭示有价值的知识,是网络大数据时代的网络数据挖掘与知识发现学科,也是网络信息研究新范式的支撑学科,但其发展也存在诸如网络大数据质量的控制、专门技术工具的发展等方面的关键问题。随着网络信息学的深入发展,未来网络大数据知识库、网络信息学专门技术工具及其应用领域都将得到蓬勃发展,网络信息学也或将成为学科信息学的领头学科。
关键词:网络信息学;学科信息学;网络计量学;大数据;数据挖掘与知识发现
中图分类号:G201 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2023009
Abstract In the big data era, the rapid development of new frontier technologies has put forward new requirements for the development of webometrics. So,we put forward a new concept here under the framework of the"subject-informatics",which is"cyber-informatics". Starting from the background of the rise of cyber-informatics, this paper introduces the development process from webometrics to cyber-informatics. Secondly, the definition, data basis and key theories and methods of cyber-informatics are clarified. Finally, the research advances of knowledge discovery in interdisciplinary field, academic influence and competitiveness evaluation of cyber-informatics is analyzed.Cyber-informatics is a subject of network data mining and knowledge discovery in the era of network big data, and a supporting subject of the new paradigm of network information research. However, there are still some key problems, such as the quality control of big data and the development of specialized technical tools. With the further development of cyber-informatics, the knowledge base of network big data, the specialized technical tools of cyber-informatics and its application fields will be vigorously developed in the future.In addition cyber-informatics may become the leading subject of subject-informatics.
Key words cyber-informatics; subject-informatics; webometrics; big data; data mining and knowledge discovery
在大数据时代,大数据的“5V”特征[1]加剧了网络信息的复杂性、集合性和交叉性,同时,互联网+、新兴前沿计算机、大数据等技术的迅猛发展,突破了人脑的计算速度与耐力限制,可以弥合大量可用知识与人的能力有限之间的差距。以网络信息为研究对象的网络计量学深受冲击与影响[2],传统的网络计量学利用文献计量学的理论方法对小数据的定量描述与统计分析已经不足以支撑网络大数据之间复杂关联关系、模式结构以及重要隐性知识的揭示。因此,网络计量学必须向前发展,以适应在大数据与人工智能等前沿技术融合的复杂信息环境中开展网络数据信息分析与重要知识发现的研究任务。
此外,在科学研究进入数据密集型研究的第四范式的大背景下,张志强和范少萍提出了一个统一的学科概念——“学科信息学”(Subject informatics),认为其是应用信息科学与计算科学的技术、手段与方法,进行科学数据收集、存储、处理、再分析、可视化和知识发现,从而创造新知识、发现新方法、提供学科战略决策咨询的交叉性学科,重点突出了对学科信息、数据的计量分析与挖掘分析[3]。
在上述双重背景下,基于网络计量学与网络大数据分析的专门学科信息学——“网络信息学”(cyber-informatics)应运而生。一方面,网络信息学是网络计量学的新发展,是网络大数据时代的新型网络计量学,是网络计量学在大数据和前沿技术浪潮的冲击下焕发出的新的生命力;另一方面,网络信息学是网络大数据分析与知识发现的专门学科信息学,是学科信息学在网络信息计量分析、数据挖掘与知识发现领域的具体化表现,是大数据时代基于网络大数据开展知识发现的新型数据分析型学科。文章旨在分析研究网络信息学的兴起、内涵、研究内容、应用实践及其未来发展。首先在概述网络信息学兴起背景的基础上,介绍网络信息学的内涵及其理论方法技术;其次,从重要跨学科领域知识发现、学术影响力与竞争力评价、重要信息的检测与识别和面向决策咨询的网络大数据预测分析等四个方面阐述了网络信息学知识发现的研究进展;最后,对网络信息学的发展进行了总结与展望。随着数据分析与信息技术的快速发展,网络信息学将成为探索网络虚拟世界未知的有力工具。
1 网络信息学发展概述
1.1 从网络计量学到网络信息学
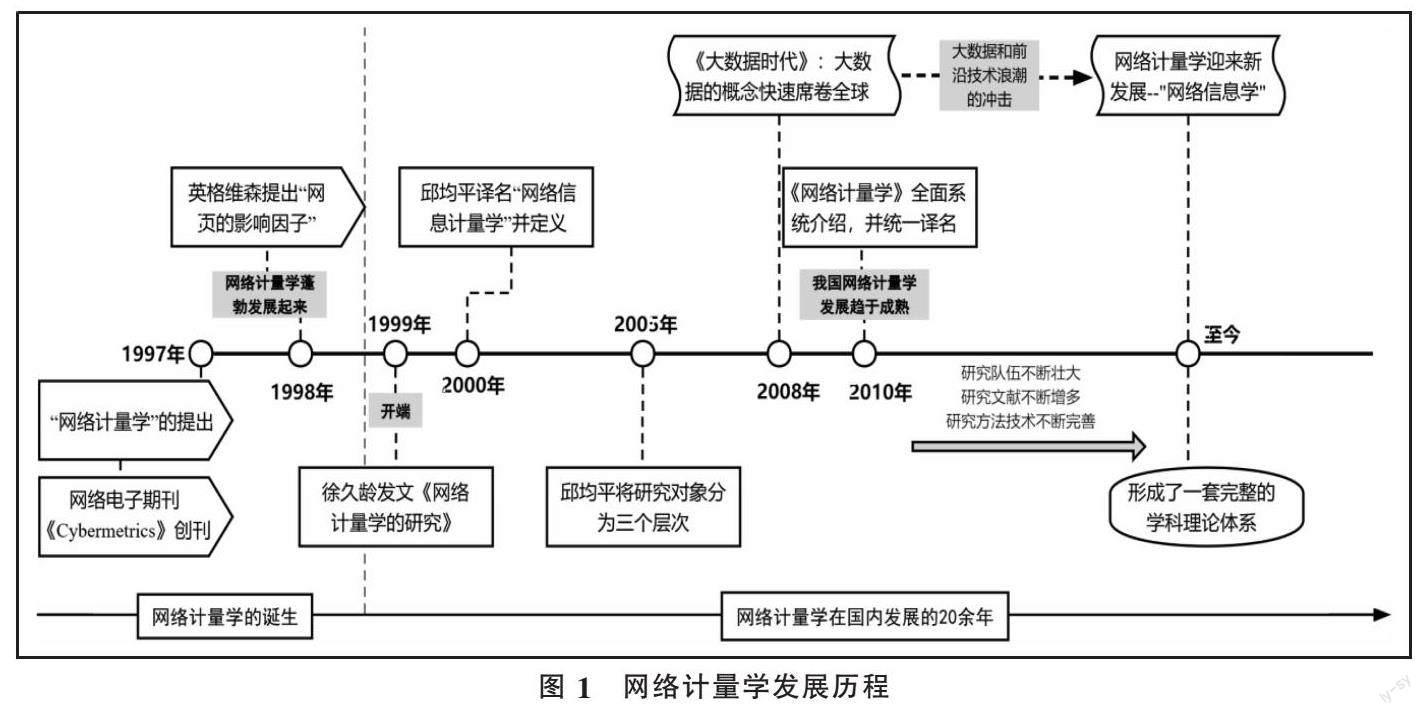
一般认为,网络计量学(webometrics)由阿曼德(Almind)和英格维森(Ingwersen)于1997年提出,即将文献计量方法用于“万维网”上信息的计量研究[4]。1998年,英格维森提出了利用网页的影响因子对一段时间内网页浏览关注情况进行分析,这对网络计量学的发展起到了十分重要的作用[5-6],网络计量学也逐渐从传统的信息计量学脱离出来成为一门独立的新兴学科。
国内网络计量学的研究以1999年徐久龄等的研究[7]为开端(网络计量学在我国的发展历程见图1)。2000年,“webometrics”首次被译为“网络信息计量学[8],并被定义为“采用数学、统计学等各种定量研究方法,对网上信息的组织、存储、分布、传递、相互引证和开发利用等进行定量描述和统计分析,以便揭示其数量特征和内在规律的一门新兴分支学科”[9]。随着理论和实践的发展,2010年,网络计量学理论、方法和应用被系统研究,也统一了将“网络计量学”这一更广泛的概念作为学科命名[10],名称的统一,标志着我国网络计量学的研究趋于成熟。经过20余年的发展,网络计量学研究队伍不断壮大,成果不断丰硕,丰富了我国网络计量学的理论、方法以及应用,形成了一套完整的理论体系。
网络计量学的发展与网络环境的变迁和网络结构的演化息息相关,随着云计算、互联网+、大数据技术的兴起,网络计量学面临许多新的挑战[11]。过去,网络计量学的研究普遍是通过网络小数据以既定的方法和分析模式实现的,小数据的特征是为回答特定问题而量身定制的抽样数据[12]。大数据时代,网络计量学面对的已不仅仅是单方面的数据,还有海量、无序、多样、异构的网络大数据集合单元,传统的网络计量学研究方法面对网络大数据显得力不从心。与此同时,人工智能等前沿技术在大数据挖掘与知识发现中的应用越来越深入,通过复杂计算能够发现无法通过有限检索策略与传统分析方法发现的隐藏在大数据中的各种潜在相关模式。
网络信息学便在大数据和前沿技术浪潮中应运而生。如果说,网络计量学试图利用小数据从狭窄的缝隙中开采“黄金”,那么网络信息学便是试图利用大数据通过最先进的机器通过露天开采、挖掘和筛选大片土地来开采“黄金”。
1.2 网络信息学的内涵
1.2.1 网络信息学内涵界定
科学史告诉我们,任何科学的产生和发展都是由一定的科学背景和特定条件所决定的[13]。结合网络信息学兴起的时代与技术背景,网络信息学的内涵可以概述为:(1)研究对象为网络大数据,具体有网络公共知识库、以网络资源为基础的新一代知识库、搜索引擎、社交媒体以及网络上存在的其它有价值的数据与行为印迹的数据集等;(2)核心是挖掘并研究网络大数据中潜藏的有价值的信息与知识;(3)技术方法支撑是深度学习等新兴计算机技术、通信技术、数学理论与方法等,涉及数据的挖掘、加工、分析等全过程;(4)学科基础为网络计量学、学科信息学、信息科学、知识发现、计算机科学、数据科学、网络科学、复杂性科学等;(5)研究目的主要是:揭示网络大数据间蕴含的重要的隐性知识、识别科学研究中的重要趋势与机制、重要信息的监测与识别、面向决策服务的网络大数据的预测分析等。
基于此,网络信息学可以定义为:是利用数学理论与方法、计量学方法和计算机科学(深度学习、神经网络)等多学科的技术方法,对海量网络信息进行知识挖掘和知识发现研究,揭示网络大数据中潜藏的有价值的信息与知识的一门新型数据分析学科。
此外,网络信息学是一个新概念,目前还没有英文译名,由于网络计量学的英名称为“webometrics”[4]或“cybermetrics”(1997年由西班牙科学信息与文献中心创办的期刊得名),而学科信息学的英文名称为“subject informatics”[3]。因此,基于“X-informatics”学科群的理论,此处将“cyber-informatics”作为网络信息学的英文表达(“webo”是一个没有单独的含义词根,为了保持学科群格式的一致,此处不考虑“weboinformatics”)。
1.2.2 网络信息学相关概念辨析
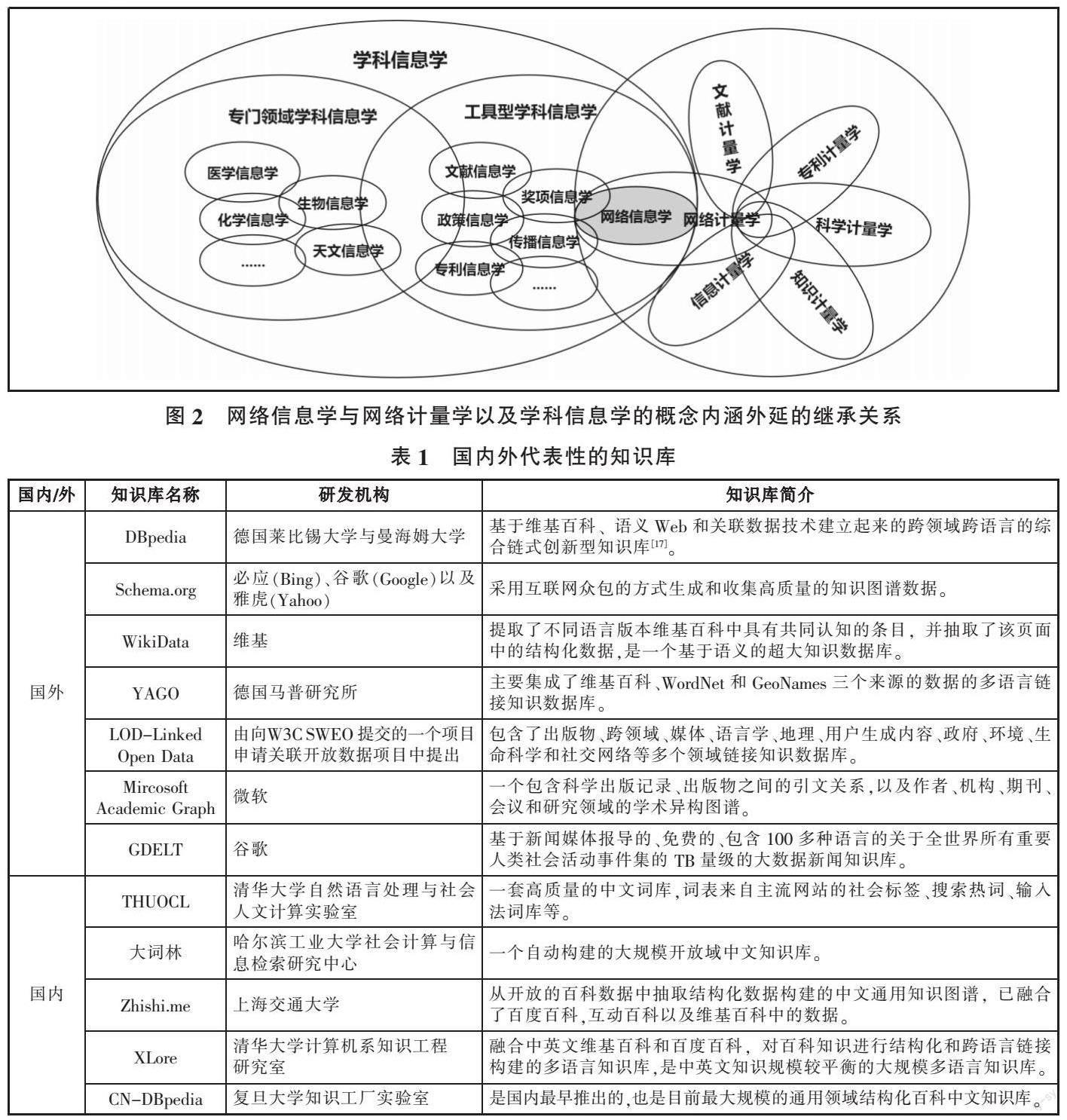
为了厘清网络信息学相关概念的继承关系以及辨析各个概念之间的界限,此处使用维恩图(Venn diagram)来直观展示(见图2)。
首先,网络信息学根植于网络计量学,属于网络计量学内容体系的一部分,是网络大数据时代的新型网络计量学;其次,学科信息学学科群分为专门领域学科信息学(医学信息学、生物信息学等)和工具型学科信息学(政策信息学、专利信息学等)两大类别,网络信息学作为学科信息学在网络信息计量分析、数据挖掘与知识发现领域的具体化表现,是工具型学科信息学体系中的重要一支。
1.3 网络信息学的数据源及方法工具
1.3.1 数据来源
网络信息学的研究基础是各类网络大数据集合单元,如网络公共知识数据库、以互联网资源为基础的新一代知識库、行业/领域垂直知识库、个人自建知识库、搜索引擎、社交媒体以及网络上存在的其它有价值的数据与行为印迹的数据集等。由于搜索引擎和社交媒体是传统的网络计量学以及补充计量学(altmetrics)的研究数据源,在此不做详细介绍。
(1)网络公共知识数据库。数量庞大的可用知识使得人类无法阅读甚至访问全部知识,适当地挖掘公共知识数据库(如维基百科Wikipedia)可以使我们超越这种限制,揭示遥远的学科内容元素之间惊人的关系[14]。这类公共知识库是由人工或专家构建的知识库,如维基百科(Wikipedia)、百度百科、概念网(ConceptNet)、词汇网络(Wordnet)等。
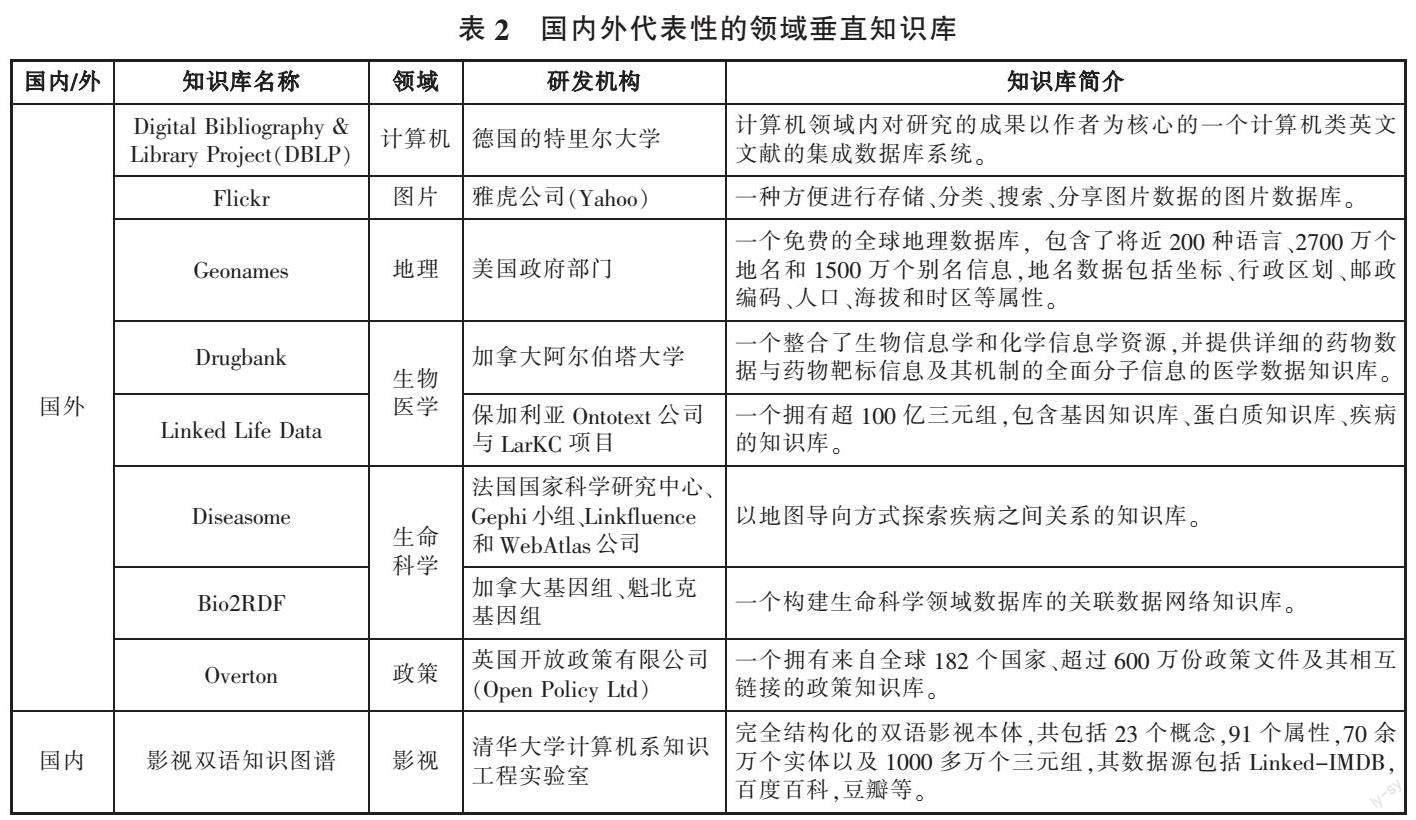
(2)以互联网资源为基础的新一代知识库(知识图谱)。从蒂姆·伯纳斯·李1998年提出语义网至今[15],涌现出大量以互联网资源为基础的新一代知识库,这些知识库以“主语、谓语、宾语”三元组的形式表示并储存了海量对象的结构化信息[16](见表1)。
(3)领域垂直知识库。垂直领域知识库是针对某个学科领域、某个行业或者是某种媒体类型而构建的,根据某个学科领域/行业/媒体类型的数据来构建的知识库,相比于通用知识库,更强调知识的深度,其数据来源相对较窄(国内外代表性的领域垂直知识库见表2)。
除了上述数据源外,网络上还存在大量的个人自建的知识库(如利用Trilium建立个人维基、Baumard等建立的古代文学小说数据库[18]等),这类知识库数据量大、覆盖面广且往往是利用网络爬虫等技术来获取数据,因此也可作为网络信息学数据挖掘与知识发现的数据源。
1.3.2 网络信息学理论方法技术
网络信息学的研究,需要采用恰当的理论支撑与方法技术,除了网络计量学的基本理论以及所常用的连接分析法、统计分析法以及图论分析法等以外,根据当前国内外研究发展来看,方法技术主要有复杂网络、数据挖掘与知识发现、深度机器学习以及常用的网络大数据挖掘与分析工具等。
网络信息学框架下网络大数据分析的理论方法技术框架,主要分为四大类(见图3):一是信息科学(计算机科学、统计学、信息学、信息论等),是网络信息学开展研究的理论基础与保障;二是网络科学(复杂网络),自21世纪以来,随着可计算设备和互聯网的飞速发展,人们开始收集和处理大规模的实际网络数据,涌现出许多基于复杂网络理论的应用研究[19-20],复杂网络为洞见网络大数据之间的复杂关系提供了一种系统的、整体的视野;三是数据挖掘[21]与知识发现[22],基于算法的知识发现技术(在人工智能、信息检索、数据库、统计学、模糊集和粗糙集理论基础上发展起来的)和基于可视化的知识发现技术(在图形学、科学可视化、和信息可视化的理论基础上发展起来的)实现了对海量网络信息的挖掘与信息间的联系的发现。其中,人工智能的核心技术是深度机器学习[23-24],该技术应用于数据挖掘与知识发现,能够很好地解释隐藏在数据中极为错综复杂的结构或模式,并找出表示数据的最佳方式[23];四是网络大数据挖掘与分析工具,在网络信息学框架下,对于从事数据挖掘与分析的人员来说,除了掌握理论方法,还需要学习和了解各种类型的数据分析与挖掘工具,随着技术的愈发成熟、软件的迭代,当前可以选用带有不同算法的工具来进行数据分析与挖掘(常用的数据挖掘与分析工具以及机器学习工具见表3)。需要注意的是,大多数数据挖掘和分析工具或方案以及机器学习工具,都用到了R和Python两种主要编程语言。
2 网络信息学学科框架下的知识发现前沿与进展
当前,已经有很多研究人员基于网络大数据的挖掘分析来进行知识发现研究,网络信息学的提出则为这些实践提供了学科理论基础,并为这些研究找到了学科归属。在网络信息学框架下,这些研究涉及了知识发现、识别、评价、预测等各个方面,本节主要介绍网络信息学学科框架下,重要跨学科领域知识发现、学术影响力与竞争力评价、重要信息(网络舆情、虚假信息、国家安全情报等)的监测与识别以及面向决策咨询的网络大数据预测分析等方面的知识发现研究进展。
2.1 重要跨学科领域知识发现
近几十年来,人们提出了不同的方法来探究不同学科领域的知识联系[25-29],但跨学科研究仍然缺乏在不同学科之间建立定量联系的有效工具。在网络信息学的框架下,适当技术工具地应用可能导致隐藏在大数据网络中的知识自现,不仅可以显示学科间的知识流动,还可以量化连接不同知识领域的元素的个体和集体行为。
Schwartz利用维基百科中的数据对爱因斯坦(Einstein)和毕加索(Picasso)在20世纪初的作品之间的关系,回答了毕加索几乎在爱因斯坦发表相对论的同时发展了立体主义是否是巧合、是否回答了同样的问题、是否受到相同人物/作品的的影响的问题[14]。类似的,Baumard等建立了一个覆盖3800年、77个历史时期以及19个地理区域的古代文学小说数据库来研究了爱情在文化史中的演变,揭示了经济发展水平越高,叙事小说中的爱情元素出现频率就越高的现象[18]。Lai等使用中国银联支付网络的高频精细数据研究了温度冲击对消费的影响,表明温度与消费之间呈倒U型关系[30]。Yin等使用Overton数据集揭示了应对新冠疫情相关的政策文件占比能反映出病例数量的变化,提供了科学研究为政策提供信息的科学证据[31]。此外,清华大学电子系数据科学与智能实验室联合斯坦福大学、哈佛商学院等研究机构基于国内社交电商之一的贝店网站(https://beidian.com/)的千万用户的购买数据的系列研究,系统揭示了以社交电商为代表的社会关系与经济行为耦合新范式[32-38]。
2.2 学术影响力与竞争力评价
学术影响力与竞争力体现了科研人员在所属科研领域中的学术地位及其研究成果所具有的科研学术价值,也体现了在被学术同行、专家群体外的社会大众所认知和了解的程度[11]。长久以来,学术界对于论文质量的评价,往往基于引文提出各类指标,如引用频次、h指数(h-index)和期刊影响因子(journal impact factor,JIF)等,这类指标只能提供不完善、不一致且容易操纵的研究质量度量,并不能代表论文的质量或潜力。当前科研成果发表数量的激增,使得科研人员需要花费大量的时间寻找有价值的研究方向,去进行更有突破性的研究。
在网络信息学框架下,可以借助机器学习利用多源异构更大体量的数据去评价科研成果的价值。经由机器学习,可以综合利用多个网络的指标,为研究者指出最新研究中有潜力的那部分,以辅助科技管理决策,从而提升科研决策的效率。Weis和Jacobson利用千万级别的科技文献数据,基于复杂网络模型构建了一种机器学习框架——DELPHI模型,可以通过分析从科技文献中计算得到的一系列特征之间的高维关系来预测未来可能的“高影响力”研究[39]。Wang等借助科研资助数据构建了评估科学影响力的模型GImpact来评估科学影响力[40]。Wen和Deng基于网络大数据,提出了一种通过局部信息维度识别复杂网络中节点影响力的新方法,实验结果表明了该方法的优越性,该研究为高效识别复杂科研网络中有影响力的节点提供了新的思路[41]。Li等基于Microsoft academic graph中的数据构建科研合作网络,研究了科研合作网络中个体研究人员生产力和影响力的网络效应[42]。
2.3 重要信息的监测与识别
2.3.1 基于深度学习的网络舆情的检测与分析
互联网已经成为人们日常生活中获取信息的重要方式,截至2021年12月,我国网民规模为10.32亿,人均每周上网时长为28.5个小时[43]。作为一个开放的平台,互联网也为公众提供了一个多元开放的舆论环境,促进了公众舆情观点表达以及传播,积累了海量复杂的网络舆情数据。这类数据中汇聚了众多对社会发展有益的观点,也存在着对社会稳定具有潜在威胁的信息,因此有必要对网络舆情大数据进行有效检测与分析。
越来越多的证据表明,人类情感也会在网络社交媒体中传播,然而这种情绪传染的潜在机制在过去由于很少被研究。随着社交媒体用户群体不断扩大,其累计的数据也越来越庞杂,加之人工智能等技术的愈发成熟,对网络用户情绪的分析引起了研究人员的关注。许峰和张柳均尝试设计并构建情感识别模型以用于实际的网络大数据舆情检测与分析[44-45]。Fan等、Hossny等基于社交媒体(微博、推特等)的百万推文研究社交媒体中的弱关系加剧了愤怒情感的蔓延[46-47]。Xie等建模分析了由1亿用户形成的网络结构以及18万多的用户的传播行为数据并辅以大量推特(Twitter)数据。研究发现,社交媒体声音集中程度和正反馈效应都被以往舆情检测大大低估,庞大的社交网络将进一步加剧人们通过社交媒体表达观点的失衡[48]。
新冠肺炎疫情對人们生活生产的方方面面产生了重要影响,并引发世界舆论的广泛关注,研究网络用户对于新冠肺炎疫情的态度及其随着时间的变化,有助于政府及时掌握真实社会舆论情况,科学高效地做好疫情防控宣传和舆情引导工作,对此研究人员进行了大量的相关研究。Kruspe等和chandra等均尝试利用自然语言处理(NLP)和深度学习技术,检测和分析了新冠大流行期间推特亿万的推文所表现出来的情绪[49-50]。Wang等基于100多个国家的6.54亿条带有地理标签的社交媒体帖子开发了一个表达情感指数的全球数据集,以跟踪国家和国家以下级别的日常情感状态,研究表明社交媒体数据与机器学习技术相结合时,可以提供对人们情感状态的实时测量[51]。
2.3.2 网络虚假信息甄别与分析
虚假信息是指向目标个人、群体或国家传递、提供或确认的虚假、不完整或误导信息(RAND,2021)[52],社交媒体和互联网的普及以及人工智能、社交机器人的兴起,使得虚假信息能够以前所未有的速度传递给目标受众。2016年美国大选中,特朗普利用新型社交媒体开展竞选活动并获得胜利使世界开始意识到网络虚假信息的严重欺骗性。
在网络信息学的框架下,基于网络大数据利用人工智能新技术建立自动检测框架以快速检测和识别虚假信息、抵制“信息操纵”、防止虚假信息收割民智已经引起相关研究人员高度关注。Cao等提出了一种基于图的方法Sybil Rank以识别社交机器人进而检测社交网络海量信息中的虚假信息[53]。Wang等、Sharma等都积极探索开发基于深度神经网络的模型来从海量网络新闻中识别网络虚假信息[54-55]。此外,Shu等利用Buzzfeed和Pllotifact两个新闻网站的数据进行分析,发现新闻源以及新闻作者可以成为网络新闻可信度监测的一个有力指标,该方法可以改进传统以内容特征进行虚假新闻检测的方法[56]。
2017年,一位名叫“Deepfakes”的用户在美国Reddit网站上分享了篡改人脸的色情视频,将深度伪造技术带到了大众面前并引起了研究深度伪造技术的热潮,但是深度伪造技术在带来新奇的同时也带来了非常大的隐患,通过制造虚假视频、虚假音频进行诬陷、诽谤、诈骗、勒索等违法行为和事例已屡见不鲜[57]。为此,越来越多的研究者开展了深度伪造的音频、视频识别展开深入研究,基于 CelebA、FaceForensics、UADFV、WildDeepfake等深度伪造数据[58-61],提出识别检测深度伪造信息的方法,如Mo等、Li等、Nguyen等均基于以上数据集尝试通过深度神经网络来检测识别别伪造图像和视频[62-64]。
2020年初,世界卫生组织(WHO)宣布全球正在陷入信息流行病(Infodemic[65])。虚假信息的传播已对公共卫生和新冠肺炎疫情的成功管控构成很大的威胁[66],现在比以往任何时候都更需要找到方法来揭穿、纠正以及分析网上的虚假信息。Wang等[54]设计并收集了一个带不同的注释的新型冠状病毒肺炎推特数据集,其中包含了可用于检测和分析虚假信息的检测模型。Gallotti等、Johnson等和张帅等收集了新冠肺炎疫情流行期间社交媒体上的与新冠肺炎疫情有关的信息,发现社交网络中关于疫情的信息大多是未经验证的、错误的,且虚假信息的传播更为分散[67-69]。这些发现既为有关部门治理疫情相关网络虚假信息提供了有益参考,也为相关平台遏制网络虚假信息的传播提供了有效途径。
2.3.3 基于网络开源信息的国家安全情报监测与分析
开源情报(OSINT)是利用对公开数据和信息的搜集、处理、分析而成的情报[70]。开源情报近年来获得了相当显著的地位[71-73],其对一个国家的战略决策、军事领域、科研活动、社会经济等都有强大的支持价值。
基于开源的网络大数据,利用人工智能等先进的技术手段监测与分析威胁国家和社会安全的情报也成为了网络信息学研究的一个热点。Lindley通过类比凝胶来描述人类社交网络群体建立了网络群体模型以识别极端恐怖组织,这一研究为检测与识别网络信息中存在的威胁国家、社会稳定与安全的情报提供了一个很好的机制[74]。Dionísio等提出了使用深度神经网络对推特(Twitter)进行开源威胁情报监测[75]。崔琳等深入分析了威胁情报挖掘的一百多篇相关文献,提出了一个基于网络海量信息,挖掘网络开源威胁情报的分析框架,集成了多种计算机技术对多源的网络数据进行挖掘与分析,已有绝大部分开源威胁情报挖掘的研究工作都可以纳入到该框架中[76]。
2.4 面向决策咨询的网络大数据预测分析
预测是决策的基础,是进行科学决策的前提条件,预测为决策服务。数据的核心是“预测”,即基于海量数据的数学运算来“预测事物发生的可能性,从而成为新发现、新发明和新服务可能的源泉[3]。网络信息学框架下,科研人员基于海量的各行业数据(如城市时空流量数据、环境数据、气候数据、移动数据、科研数据、经济数据等),利用深度学习等技术方法,提出了大量的预测模型以期为决策提供参考。
随着城市化进程的发展,基于预测的城市规划成为城市科学一个新型研究热点,Gong等和京东智能城市时空AI团队均基于真实的城市交通流量数据构建了能够动态预测城市交通流量、区域客流量的深度神经网络框架,为城市交通规划(如地铁修建)以及智能城市化应用建设提供了一定的决策参考和前期支撑[77-79]。Verbavatz和Barthelemy基于真实城市人口数据,构建了一个能够精准预测城市人口数量变化并解释城市人口分布状况的数学模型,该模型能够动态地预测,在一个较长的时间尺度内,哪些城市可能会衰败,又有哪些城市的人口会增长,对城市规划与城市基础建设具有重要的参考意义[80]。
随着计算科学、网络科学和统计学在气候建模和预测方面的作用变得越来越重要,应用机器学习研究预测气候问题,帮助解决气候危机的相关性已经引起科研人员的注意。Amato等基于空间不规则分布的时间序列数据提出了一种基于深度学习的气候和环境数据时空预测框架[81]。Ludescher等利用历史上观察到的火灾相关时空变量提出了一个机器学习模型来约束预测并揭示森林火灾增加带来的全球社会经济风险[82]。Xu等挖掘了近年来出现的大量人口、土地利用和气候信息数据,搜集了过去几千年人类生活的气候条件资料,对人类气候宜居带进行了分析和预测,研究结果预言了如果按照当今的碳排放轨迹,未来50年间,会有35亿人的生存由于全球变暖而受到严重威胁[83]。
此外,基于网络大数据的预测也体现在科研合作、科研机构影响力预测、商业分析等方面。Bai等利用Microsoft Academic Graph的数据,并基于XGBoost模型构建了一个综合考虑多种因素的新的预测模型来预测科研机构的影响力[84]。Filletti和Grech通过挖掘真实的财务数据以及行业新闻文章报道提出了一个用于预测公司破产的框架[85]。Bonaventura等通过由crunchbase提供的1990-2015年期间全世界的创业公司数据,构建了全球初创企业之间的关系网络——WWS网络。该网络对公司的长期潜力进行无风险的的评估,借此模型投资人和政策制定者能够对创业公司的长期潜力进行更客观地评估并进行相应的干预措施[86]。
3 结语与展望
3.1 网络信息学发展总结
当前,大数据与计算机技术的融合在情报学的应用已经成为了当前情报学实践发展方向与发展趋势。网络信息学提出了利用前沿计算技术挖掘网络大数据的方法来揭示有价值的知识,为人们从海量网络信息中挖掘隐含的知识提供坚实的理论方法支撑,是网络信息研究新范式的支撑学科,支撑科研人员发现重要跨学科知识、检测识别重要信息和模式、识别学科领域研究新兴前沿以及创新科研评价方式等。
同时,网络信息学借助海量的网络信息资源和前沿计算技术,能够比较准确地揭示出客观事物运行中的本质联系,勾画出未来事物发展的基本轮廓,使研究者具有战略眼光,提出各种可以互相替代的发展方案,使决策有了充分的科学依据。
3.2 网络信息学发展展望
3.2.1 网络信息学发展的关键问题
网络信息学的概念才刚提出,正处于学科发展的起步阶段,在其发展过程中必然会产生诸多难以预料的问题。
首先,保障和控制网络大数据的数据质量对于网络信息学发展是關键基础,也是迫切需要有效解决的关键问题,尽管已有各种研究提出各种模型来[87-90]来尝试控制数据质量,但是,大数据的“5V”特征以及数据模式高度复杂化,导致保证数据质量暂时还没有非常行之有效的措施;其次,探索开发面向非程序员的技术门槛低、通用的、开源的大数据分析工具,也是网络信息学发展面临的关键问题。机器学习、深度学习等人工智能技术的应用需要一定的计算机学科专业背景知识,这使得多数不具备相关技能的相关领域的研究人员受困于技术门槛,不利于推动网络信息学的向前发展;再次,专业人才的培养是学科发展的关键要素,随着网络大数据类型愈加多样化和立体化、结构和模式愈加复杂化,对于网络数据的挖掘分析会越来越依赖于大数据挖掘技术、机器学习等人工智能技术,这对网络信息学研究人员的能力提出了更高的要求;最后,与专业领域知识相融合的网络大数据的分析才是知识发现的前提,网络信息学作为一种方法和工具性学科,其必须应用到有关的专门专业领域中的数据分析与知识发现。因此,从学科和领域等专业角度出发,合理且最大化地利用专业知识解释大数据之间的关联关系,是网络大数据充分发挥价值的前提,也是网络信息学发展应用的关键环节。
3.2.2 网络信息学发展前瞻
网络信息学以网络大数据为数据基础,是网络信息研究新范式的支撑学科。随着实践的不断深入,未来,网络信息学的理论框架、方法工具、应用领域、人才队伍都将快速且持续的发展完善。
一是网络信息学或成为信息学的领头学科。网络信息学学科作为一门工具型学科,网络信息理论方法与技术工具可以移植到其它的专门领域学科信息学中为其所用,助力其发展;二是网络大数据知识库将蓬勃发展,大数据的“5V”特征使得有必要对网络信息和知识进行实时动态的大规模的收集和整理,将某类网络大数据通过组织使之成为不断动态更新的网络大数据知识库;三是网络大数据挖掘的相应技术与工具不断开发,未来,在网络大数据分析的强劲需求驱动下,需要开发专门的、技术门槛低的网络信息学专门技术工具以支撑网络信息学的研究人员更好地开展研究;四是网络信息学研究应用领域将快速扩展,海量的网络数据迅速引起了各个领域科学研究的重视,几乎各个领域行业都需要更宽广的视野和长久的策略以全面应对网络大数据时代研究的挑战,即挖掘、计算、分析各领域的海量的网络数据,以发现隐藏在数据中的新的模式,而这些均属于网络信息学的学科范畴;五是网络信息学“高、精、专”人才队伍的培养,要促进网络信息学的发展和应用,未来需要建设一个全面、多维、兼顾理论与技术的网络信息学教育体系,培养既掌握扎实的相关多学科的理论知识,又精通大数据挖掘技术、人工智能技术的网络信息学专业分析人才。
参考文献:
[1] Bechini A,Marcelloni F,Segatori A.A MapReduce solution for associative classification of big data[J].Information Sciences,2016,332:33-55.
[2] 邱均平,邝玉林.人工智能对“五计学”的影响研究——以网络计量学为例[J].图书馆理论与实践,2020(6):17-22.
[3] 张志强,范少萍.论学科信息学的兴起与发展[J].情报学报,2015,34(10):1011-1023.
[4] Almind V C,Ingwersen V P.Informetric analyses on the world wide web:methodological approaches to‘webometrics[J].Journal of Documentation,1997,53(4):404-426.
[5] 夏旭.高屋建瓴 臻于至善——《网络计量学》评介[J].图书情报知识,2012(3):125-129.
[6] 赵蓉英,张心源,张扬,等.我国“五计学”演化过程及其进展研究[J].图书情报工作,2018,62(13):127-138.
[7] 徐久龄,刘春茂,刘亚轩.网络计量学的研究[J].情报学进展,1998.
[8] 邱均平,陈敬全.网络信息计量学及其应用研究[J].情报理论与实践,2001(3):161-163.
[9] 邱均平.网络计量学[M].北京:科学出版社,2010.
[10] 赵蓉英,郭凤娇,谭洁.基于Altmetrics的学术论文影响力评价研究——以汉语言文学学科为例[J].中国图书馆学报,2016,42(1):96-108.
[11] 苏令银.大数据时代的小数据会消亡吗[J].探索与争鸣,2019(7):74-84,158.
[12] 邱均平.“文献计量学”定义的发展[J].情报杂志,1988(4):45-47,31.
[13] Schwartz G A.Complex networks reveal emergent interdisciplinary knowledge in Wikipedia[J].Humanities and Social Sciences Communications,2021,8(1):1-6.
[14] Anastasia Analyti,Nicolas Spyratos,Panos Constantopoulos.On the Semantics of a Semantic Network[J].Fundamenta Informaticae,1998,36(2-3):109-144.
[15] Saxena A,Tripathi A,Talukdar P.Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings[A].Proceedings of the 58th annual meeting of the association for computational linguistics[C].2020:4498-4507.
[16] 王志春,李邦祺,李凱曼,等.全球通信光缆知识图谱构建及应用[J].北京师范大学学报(自然科学版),2021,57(6):883-887.
[17] Baumard N,Huillery E,Hyafil A,et al.The cultural evolution of love in literary history[J].Nature Human Behaviour,2022,6(4):506-522.
[18] Watts D J,Strogatz S H.Collective dynamics of 'small-world' networks[J].Nature,1998,393(6684):440-442.
[19] Barabási A L,Albert R,Jeong H.Mean-field theory for scale-free random networks[J].Physica A,1999,272(1):173-187.
[20] Frawley W J,Piatetsky-Shapiro G.Knowledge Discovery in Databases: An Overview.Cambridge[M].MIT Press,1991.
[21] Usama M.Fayyad,Gregory Piatetsky-Shapiro,Padhraic Smyth.From Data Mining to Knowledge Discovery in Databases[J].AI Magazine,1996,17(3):37
[22] 王大顺,(匈牙利)艾伯特-拉斯洛·巴拉巴西.贾韬,汪小帆,译.给科学家的科学思维[M].天津:天津科学技术出版社,2021.
[23] Arel I,Rose D,C Karnowski,et al.Deep Machine Learning-A New Frontier in Artificial Intelligence Research[J].IEEE computational intelligence magazine,2010,5(4):13-18.
[24] 劉清堂,吴林静,黄焕.网络资源聚合研究综述[J].情报科学,2015,33(10):154-161.
[25] 韩金廷.基于社会网络分析的科研合著研究[D].长沙:国防科学技术大学,2016.
[26] 沈思,李成名,吴鹏.基于时态语义的Web信息检索实践进展与研究综述[J].中国图书馆学报,2018,44(4):109-129.
[27] Xujian Zhao,Peiquan Jin,Lihua Yue.Discovering topic time from web news[J].Information Processing and Management,2015(6):869-890.
[28] Mostafa Keikha,Fabio Crestani.Linguistic aggregation methods in blog retrieval[J].Information Processing and Management,2012,48(3):467-475.
[29] Lai W,Li S,Liu Y,et al.Adaptation mitigates the negative effect of temperature shocks on household consumption[J].Nature Human Behaviour,2022(6):837-846.
[30] Yin Y,Gao J,Jones B F,et al.Coevolution of policy and science during the pandemic[J].Science,2021,371:6525(128-130).
[31] Cao H,Chen Z,Cheng M,et al.You Recommend,I Buy:How and Why People Engage in Instant Messaging Based Social Commerce[C].In Proceedings of the ACM on Human-Computer Interaction 5.CSCW1,2021:1-25.
[32] Cao H,Chen Z,Xu F,et al.When Your Friends Become Sellers:An Empirical Study of Social Commerce Site Beidian[C].In Proceedings of the International AAAI Conference on Web and Social Media,2020(14):83-94.
[33] Cao Q,Sirivianos M,Yang X,et al. Aiding the Detection of Fake Accounts in Large Scale Social Online Services[C].Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation(NSDI'12),2012:15.
[34] Xu F,Han Z,Piao J,et al.“I Think Youll Like It”Modelling the Online Purchase Behavior in Social E-Commerce[C].Proceedings of the ACM on Human-Computer Interaction 3.CSCW,2019:1-23.
[35] Xu F,Lian J,Han Z,et al.Relation-Aware Graph Convo-lutional Networks for Agent-Initiated Social E-Commerce Recommendation[C].Proceedings of the 28th ACM International Conference on Information and Knowledge Management,2019:529-538.
[36] Xu F,Zhang G,Yuan Y,et al. Understanding the Invitation Acceptance in Agent-Initiated Social E-Commerce[C].Proceedings of the International AAAI Conference on Web and Social Media,2021(5):820-829.
[37] Chen Z,Cao H,Lan X,et al.Beyond Virtual Bazaar:How Social Commerce Promotes Inclusivity for the Traditionally Underserved Community in Chinese Developing Regions[C].Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems,2022:1-15.
[38] Weis J W,Jacobson Joseph M.Learning on knowledge graph dynamics provides an early warning of impactful research[J].Nature biotechnology,2021,39(10):1300-1307.
[39] Wang Y,Long Y,Tu L,et al.Delivering Scientific Influence Analysis as a Service on Research Grants Repository[J/OL].[2022-06-19].https://arxiv.org/pdf/1908.08715.pdf.
[40] Wen T,Deng Y. Identification of influencers in complex networks by local information dimension[J/OL].[2022-06-19].https://arxiv.org/pdf/1908.11298.pdf.
[41] Li W,Zhang S,Zheng Z,et al.Untangling the network effects of productivity and prominence among scientists[J].Nat Commun ,2022(13):4907.
[42] 中國互联网络信息中心(CNNIC).第49次中国互联网络发展状况统计报告[EB/OL].[2022-06-20].https://www.cauc.edu.cn/jsjxy/upfiles/202203/20220318171634656.
[43] 许峰.基于深度学习的网络舆情识别研究[D].北京:北京邮电大学,2019.
[44] 张柳.社交网络舆情用户主题图谱构建及舆情引导策略研究[D].长春:吉林大学,2021.
[45] Fan R,Xu K,Zhao J.Weak ties strengthen anger contagion in social media[J].arxiv preprint arxiv:2005.01924,2020.
[46] Hossny,Ahmad Hany,Lewis Mitchell.Event Detection in Twitter:A Keyword Volume Approach[A].2018 IEEE International Conference on Data Mining Workshops(ICDMW)[C].2018:1200-1208.
[47] Xie J,Meng F,Sun J,et al.Detecting and modelling real percolation and phase transitions of information on social media[J].Nature Human Behaviour,2021,5(9):1161-1168.
[48] Kruspe A,Hberle M,Zhu X.Cross-language sentim-ent analysis of European Twitter messages during the COVID-19 pandemic[EB/OL].[2022-06-17].https://aclanthology.org/2020.nl pcovid19-acl.14.pdf.
[49] Sukhwal P C,Kankanhalli A.Determining containment policy impacts on public sentiment during the pandemic using social media data[J].Proceedings of the National Academy of Sciences of the United States of America,2022,119(19):e211
7292119.
[50] Wang J H,Fan Y C,Palacios Juan,et al.Global evidence of expressed sentiment alterations during the COVID-19 pandemic[J].Nature human behaviour,2022,6(3):349-358.
[51] RAND Corporation.Combating Foreign Disinformation on Social Media[EB/OL].[2022-06-23].https://www.rand.org/paf/projects/combating-foreign-disinformation.html.
[52] Cao Q,Sirivianos M,Yang X,et al.Aiding the Detection of Fake Accounts in Large Scale Social Online Services[C].Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation (NSDI'12),2012:197-210.
[53] Wang Y,Ma F,Jin Z,et al.EANN:Event Adversarial Neural Networks for Multi-Modal Fake News Detection[C].KDD18:Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,2018:849-857.
[54] Sharma K,Ferrara E,Liu Y.Identifying Coordinated Accounts in Disinformation Campaigns[J].2020.
[55] Shu,K,Wang S,Lee D,et al.Mining Disinformation and Fake News:Concepts,Methods,and Recent Advancements[J].Disinformation,misinformation,and fake news in social media:Emerging research challenges and opportunities,2020:1-19.
[56] 清華大学人工智能研究院,北京瑞莱智慧科技有限公司,清华大学智媒研究中心.深度合成十大趋势报告[EB/OL].[2022-06-17].http://www.chuangze.cn/third_down.asp?Txtid=4762.
[57] Liu Z W,Luo P,Wang X G,et al.Deep Learning Face Attributes in the Wild[C].Praeedings of the IEEE intermational conference on computer vision,2015:3730-3738.
[58] Rssler A,Cozzolino D,Verdoliva L,et al. FaceForensics:a large -scale video dataset for forgery detection in human faces[J].arxiv preprint arxiv:1803.09179,2018.
[59] Yang X,Li Y,Lyu S.Exposing Deep Fakes Using Inconsistent Head Poses[C].ICASSP 2019-2019 IEEE International Conference on Acoustics,Speech and Signal Processing,2019:8261-8265.
[60] Zi B,Chang M,Chen J.WildDeepfake:A Challenging Real-World Dataset for Deepfake Detection[C].Proceedings of the 28th ACM international conference on multimedia,2020:2382-2390.
[61] Mo H X,Chen B L,Luo W Q.Fake Faces Identification via Convolutional Neural Network[P].Information Hiding and Multimedia Security,2018.
[62] Li L,Bao J,Zhang T,et al.Face X-ray for more general face forgery detection[C].Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2020:5001-5010.
[63] Nguyen H H,Tieu N D T,Nguyen-Son H Q,et al.Modular Convolutional Neural Network for Discriminating between Computer-Gener ated Images and Photographic Images[C].Proceedings of the 13th International Conference on Availability,Reliability and Security,2018:1-10.
[64] Chiolero Arnaud.How infodemic intoxicates public health surveillance:from a big to a slow data culture[J].Journal of epidemiology and community health,2022,76(6):623-625.
[65] van der Linden Sander.Misinformation:susceptibility,spread,and interventions to immunize the public[J].Nature medicine,2022,28(3):460-467.
[66] Gallotti Riccardo,Valle Francesco,Castaldo Nicola,et al.Assessing the risks of‘infodemicsin response to COVID-19 epidemics[J].Nature human behaviour,2020,4(12):1285-1293.
[67] Johnson N F,Velásquez N,Restrepo N J,et al.The online competition between pro-and anti-vaccination views[J].Nature,2020(582):230-233.
[68] 张帅,刘运梅,司湘云.信息疫情下网络虚假信息的传播特征及演化规律[J].情报理论与实践,2021,44(8):112-118.
[69] 刘昊,张志强,武瑞敏.建设适应科技竞争与国家安全的科技情报发展体系[J].图书与情报,2022(1):39-48.
[70] 马海群.专题导语:开源情报的高价值——聚沙成塔、汇流成海[J].现代情报,2022,42(1):4.
[71] 白云,李白杨,王施运.面向新型跨境网络有组织犯罪的开源情报获取与利用方法[J].信息资源管理学报,2022,12(2):65-75.
[72] Rai B K,Verma R,Tiwari S.Using Open Source Intelligence as a Tool for Reliable Web Searching[J].SN Computer Science,2021,2(5):402.
[73] Lindley D.Identifying early signs of online extremist groups[J].Physics,2018,11:76.
[74] Dionísio N,Alves F,Ferreira P M,et al.Cyberthreat Detection from Twitter using Deep Neural Networks[C].2019 International Joint Conference on Neural Networks(IJCNN),2019:1-8.
[75] 崔琳,杨黎斌,何清林,等.基于开源信息平台的威胁情报挖掘综述[J].信息安全学报,2022,7(1):1-26.
[76] Gong Y,Li Z,Zhang J,et al.Potential Passenger Flow Prediction:A Novel Study for Urban Transportation Development[C].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(4):4020-4027.
[77] Zhang X,Huang C,Xu Y,et al.Traffic Flow Forecasting with Spatial-Temporal Graph Diffusion Network[C].Proceedings of the AAAI comference on artificial intelligence,2021,35(17):15008-15015.
[78] Qin H,Ke S,Yang X,et al.Robust Spatio-Temporal Purchase Prediction via Deep Meta Learning[C].Proceedings of the AAAI comference on Artificial intelligence,2021,35(5):4312-4319.
[79] Verbavatz V,Barthelemy M.The growth equation of cities[J].Nature,2020,587(7834):397-401.
[80] Amato F,Guignard F,Robert S. A novel framework for spatio-temporal prediction of environmental data using deep learning[J].Scientific reports,2020,10(1):22243.
[81] Ludescher J,Martin M,Boers N,et al.Network-based forecasting of climate phenomena[J].Proceedings of the National Academy of Sciences,2021,118(47):e1922872118.
[82] Xu C,Kohler T A,Lenton T M,et al.Future of the human climate niche[J].Proceedings of the National Academy of Sciences of the United States of America,2020,117(21):1350-1355.
[83] Filletti M,Grech A.Using News Articles and Financial Data to predict the likelihood of bankruptcy[J].arxiv Preprint.arxiv:2003.13414.2020.
[84] Bonaventura M,Ciotti V,Panzarasa P.Predicting success in the worldwide start-up network[J].Scientific reports,2020,10(1):345.
[85] 汪應洛,黄伟,朱志祥.大数据产业及管理问题的一些初步思考[J].科技促进发展,2014(1):15-19.
[86] Taleb I,Serhani M A,Dssouli R.Big Data Quality:A Survey[C].2018 IEEE International Congress on Big Data(Big Data Congress),2018:166-173.
[87] 刘冰,庞琳.国内外大数据质量研究述评[J].情报学报,2019,38(2):217-226.
[88] Merino J,Caballero I,Rivas B,et al.A data quality in use modelfor big data[J].Future Generation Computer Systems,2016(63):123-130.
作者简介:武瑞敏(1997-),女,中国科学院成都文献情报中心博士研究生,研究方向:情报理论方法与应用、学科信息学与学科知识发现;张志强(1964-),男,中国科学院成都文献情报中心研究员,博士生导师,研究方向:学科信息学与学科知识发现、科技政策与管理、科技战略与规划、情报理论方法与应用、科学计量与科技评价。
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
