
基于改进XGBoost 的螺栓状态异常检测与分类
2023-08-19 09:59徐英豪朱习军
电子设计工程 2023年16期
徐英豪,朱习军
(青岛科技大学信息科学技术学院,山东 青岛 266061)
随着机械设备智能化的发展,螺栓安装流程也越来越智能化,在安装流程中的异常监测已经成为重要的研究内容。如何有效地提高异常检测的准确率以及发掘其应用价值非常有意义[1]。
目前,国内外研究中的机械设备诊断方法依赖于模仿专家对物体现有状态和缺陷的分析策略[2],对于微小故障和早期故障检测非常有效[3-4]。针对以上问题,以机器学习和高级的预处理作为主要的技术途径,完善特征提取方法并建立一个具有共享权重矩阵的XGBoost 分类模型。通过对自动螺栓装配过程中形成的各类异常加以分析和对机械故障事件进行智能监测的方式,进一步提高智能化装备的组装精度和降低故障事件的出现,对于推进中国智能制造的发展有着很大意义。
1 数据预处理
数据来自某汽配组装厂,需要进行如下步骤的简单数据预处理,如图1 所示。
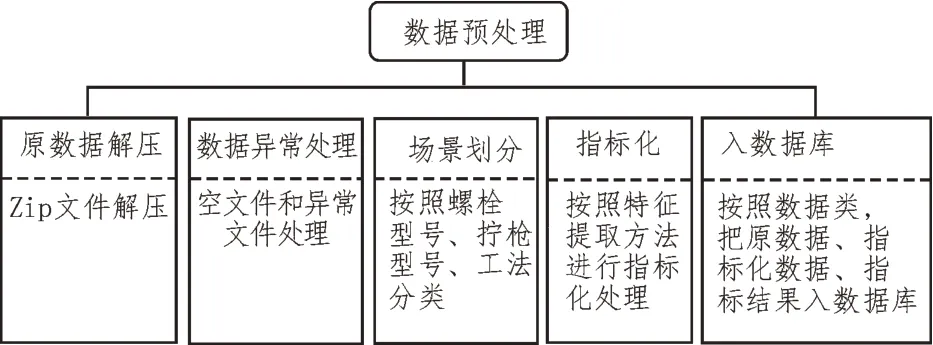
图1 数据预处理流程
文中的目标是对螺栓的异常状态进行分类[5-7],所以数据处理过程的第一步是将正常和异常的数据进行二分类[8],二分类的准确性对以后的异常状态分类尤为关键。正常及异常的分类阈值表示如图2 所示。
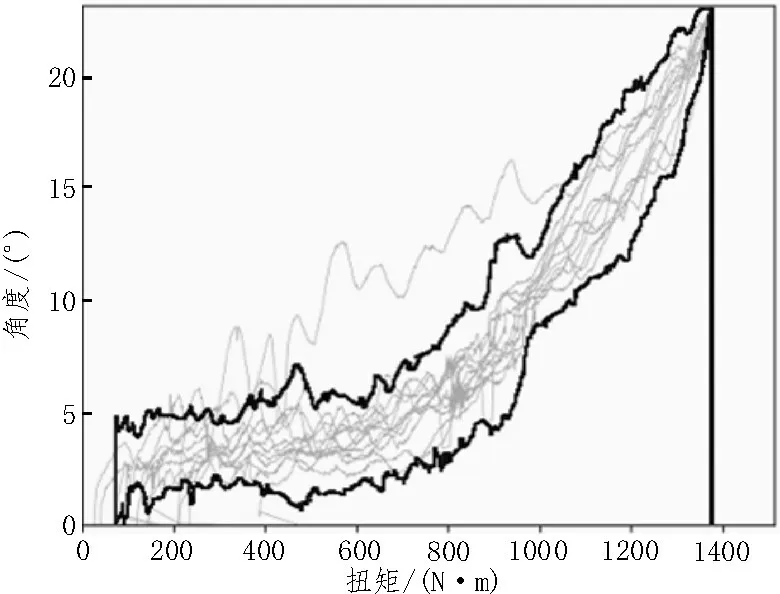
图2 正常及异常的分类阈值
图2 中数据的上下阈值是由灰色数据线上的两条黑色线分别确定的。通过计算样本曲线与阈值下界围成的面积同上下阈值的面积比,来判断异常数据,以此来避免样本中的单个特异值所引起的误判,提高筛选数据的准确性。经过在多种场景下的不同实验,将验证是否为正常值的面积比例阈值设定为标准面积的12%,阈值的上下界分别设定为样本的三倍方差,能得到最精确的结果,精度为95.3%。异常分离准确率如表1 所示。

表1 异常分离准确率
至此,异常样本数据抽取[9-11]完成,后续得以在此基础上进行下一步特征提取、模型建立等其他工作。
2 特征提取优化和设计
2.1 特征提取方法优化
传统的特征提取方式[12-14]主要选择与扭矩相对应的角度值作为特征,这样的特征有碍模型训练,造成分类效果差的问题。因此,文中选取了由扭矩与角度组成的曲线为研究特征,并通过分析基于曲线的相关特征,采用了诸如偏度、峰度和变异系数等12 种相关特征并运用XGBoost 算法在特征提取方法数据集中选择12 个相关特征,显示单个特征对预测结果的影响,并显示影响排名。原始特征贡献率如图3 所示。

图3 原始特征贡献率
2.2 特征分析与降维
为优化特征提取方式,提高模型的运算效率,并减少数据冗余,进行主成分分析,降维后得到了七个特征[15]。其次再次应用XGBoost 方法进行特征提取,从数据集中选出对预测结果最重要的七个特征,并得到影响排名,如图4 所示。事实证明,每个特征对分类结果的贡献在七个维度上基本恒定,可作为模型训练的数据集。
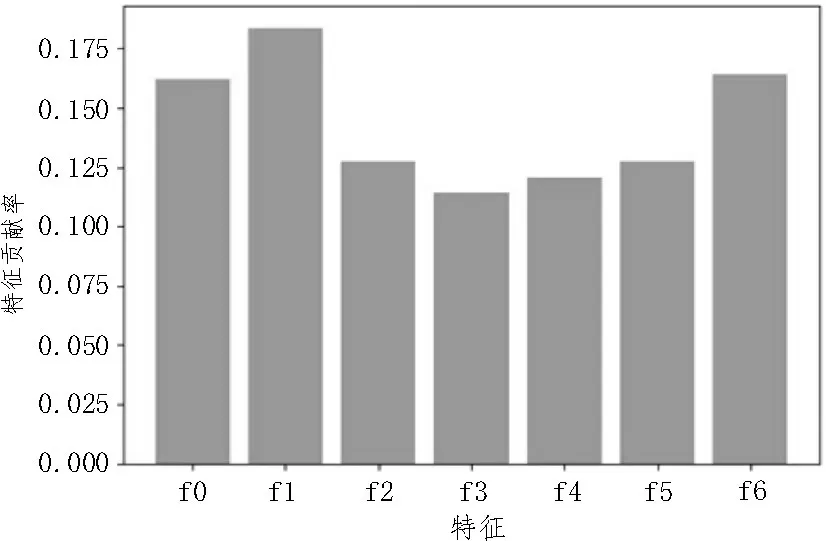
图4 降维后特征贡献率
3 分类算法设计与优化
3.1 XGBoost算法介绍
XGBoost 方法是GB 算法的树状版本,其中GDBT 对应于上一轮拟合损失函数的一阶导数。XGBoost 执行的是二阶泰勒扩展,使之具有更高的精度和更少的迭代次数,以获得更好的训练效果。此外,该策略在处理高纬度特征数据和多分类问题时存在参数过多、不易收敛、训练不够灵活的问题。
3.2 XGBoost算法优化
文中针对多层分类模型[16]之间无法学到相互依赖关系的问题,采用新增共享权重矩阵的方法,使XGBoost 模型在减少参数量的同时可以关注模型间的内在依赖关系。为了解决不易收敛、训练不够灵活的问题,考虑神经网络反向传播中的梯度下降策略,改进损失函数,优化训练。
3.2.1 新增共享权重矩阵
通过新增共享权重矩阵wi,建立多层模型的层间关系,实现多层模型之间权重共享,以捕获各类螺栓异常之间的内在联系,从而解决了原算法在XGBoost 模型的损失函数只计算单个内部模型准确率的问题。此外,使用共享权重矩阵一方面减少了权值数量,提高模型训练效率;另一方面降低了过拟合的风险,提高了整个多层分类模型的分类性能。在训练模型时,通过不断迭代得到最优分类模型和最优参数共享权重矩阵wi。
3.2.2 损失函数优化
设计了一种分类模型反向优化迭代损失函数,使得异常分类结果反馈到分类模型不断进行优化,通过梯度下降反向求导的方式寻求最佳共享权重矩阵wi,解决了原算法在XGBoost 模型的残差计算方法在不同分节点中选择的不一定是最小平方损失的问题。
损失函数设计如下:
其中,xi为各个XGBoost 模型输入向量,yi为模型输出值是输入向量xi和共享矩阵wi的乘积,yj为标签变量,Zji为针对整个模型内部而言的具体损失值,Zji的数学表达如下:
当误差yj-yi小于1 时,采用0.5(yj-yi)2来最小化;当误差yj-yi大于1 时,采用|yj-yi|-0.5 来最小化。原损失函数训练时维持最大梯度不变,这使得当阶梯下降训练即将完成时,错过了最小点。但针对Zji,梯度会由于损失的减少而下降,结果也随着梯度的下降而到达了最小值附近,使结果更为准确。Zji损失函数对数据中的异常点没有那么敏感,具有更好鲁棒性。
根据上述优化方法设计了多层的分类模型。异常分析的尾部结合决策树,根据异常结果对上层的分类模型验证反馈,不断迭代优化。在不同分类模型之间建立树节点关系,保存每个节点的共享权重矩阵wi,并根据分类结果不断反向优化模型,根据预测值跟真实值之间的误差不断优化wi,最终得到最佳wi。文中建立了三层异常分类模型,每层异常建立参数关系,可以通过训练结果前向反馈,异常分类结果反馈到第三层异常模型,第三层异常分类模型将结果反馈到第二层分类模型,以此类推,不断调整参数,得到最佳分类结果,保存训练模型。建立多层分类模型结构如图5 所示。

图5 多层分类模型
4 实验结果与分析
文中使用某汽配螺栓厂人工标注的样本数据,异常情况有滑丝、拧歪、粘连等六种,共20 000 条样本数据进行传统机器学习分类方法与改进特征提取和多层模型优化方法对比,并使用k 折交叉验证的方式验证模型精度。
4.1 模型训练与分类
经过特征提取和主成分分析等数据处理之后,特征值之间仍然存在很大差异,再对数据进行归一化操作,方便算法模型计算,提高运算效率。然后将特征值数据输入创建的多层分类模型,用优化方法建立数学模型,并使用螺栓厂数据对分类模型进行训练。再对训练好的分类器进行评估后,获得了图6所示的六个分类结果。从结果可以明显看出,各个分类差别明显,不同异常所影响的范围不同,但大体上集中在0°~7°范围内,而在角度较大的工作条件下不易出现异常。同样,实验结果表明,在0~400 N·m及2 200~3 300 N·m 的扭矩中,即使在角度较大的工作条件下,各类异常的出现也较为频繁。而与之相对地,在角度大于7°的工作条件时,控制扭矩在400~2 200 N·m 之间,即可有效避免六类异常。

图6 多层分类模型分类结果
4.2 模型评估
为了验证改进的XGBoost 优化算法是否具有更好的分类效果,在相同的实验环境和参数值下进行了实验,实验结果如表2 所示。可以得出,改进XGBoost 优化算法在各指标上都有不同程度的提高,这得益于改进算法添加了共享权重矩阵,使得XGBoost 模型对于不同类型的异常检测具有共用的底层权重,提高了对各类异常进行分类的能力下限。同时应用改进的损失函数,进一步细化多层分类模型的层间权重,通过多次迭代可以进一步实现对权重的微调,达到提高准确率的目的。对比原始XGBoost 分类模型,改进模型的准确率和召回率分别为0.896 和0.841。

表2 不同算法结果比较
文中实验比较了五种算法的接收者操作特征曲线,结果如图7所示。可以看出,改进XGBoost分类模型的结果最优,计算曲线下面积值为0.966,对比其他算法提高了至少8.91%,具有较为突出的分类效果。
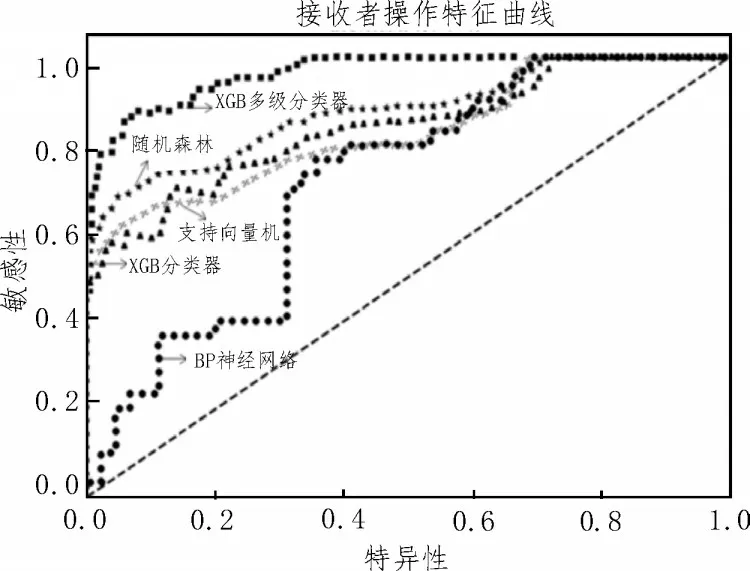
图7 各分类模型ROC曲线
经过实验发现,对数据进行特征提取优化分析以及建立多层分类模型,添加优化参数的XGBoost算法,提高了算法的精度,约为8%,通用性明显增强。这表明提出方法在螺栓装配过程中的曲线异常分类方面具有有效性和可行性。使用提出方法的分析结果对一线工作人员实施辅助检查,对于降低设备故障率、提升设备稳定性等方面都具有重要意义。
5 结论
在工业大数据的背景下,研究螺栓装配过程中的曲线变化规律,分析螺栓在装配过程中角度和扭矩的对应关系,提出基于数据和机器学习的多层异常分类模型,从多个方向分析曲线特征,建立适用于异常分类的数学模型,考虑到数据分布规律和曲线特征提出了独特特征提取方式,通过反向误差的方法优化XGBoost 算法建立的异常分类模型。同时,建立了一套数据处理、特征提取、建立模型、异常判断和分类的异常诊断系统流程。与典型的机器学习分类方法相比,文中提出的方法将计算准确率提高了大约8%,准确率达到89.6%。
猜你喜欢
中国特种设备安全(2022年5期)2022-08-26
数学小灵通(1-2年级)(2021年4期)2021-06-09
四川建筑(2020年1期)2020-07-21
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年19期)2018-11-14
减速顶与调速技术(2018年1期)2018-11-13
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
