
基于信息熵更新权重的数据自适应聚类研究
2023-08-19 09:59张福华刘丽朱俊东朱再新余大权
电子设计工程 2023年16期
张福华,刘丽,朱俊东,朱再新,余大权
(安徽明生恒卓科技有限公司,安徽 合肥 230000)
近年来,信息技术不断发展,互联网信息技术、工业信息技术、通信信息技术等行业迅速崛起,这些行业产生了大量的数据。在当前阶段,主要是通过自适应聚类对数据进行整合。数据通常以静态的形式存放在数据库中,以便随时提取。但由于信息产生方式、性质以及数据库的存储量是有限的,数据的存放只能是短暂性的,并不能长期存放在数据库中,而在应对大量的数据产生时,数据库无法永久保存所有数据,因此数据的自适应聚类便成为解决该问题的方式。
为了解决上述问题,一些学者进行了数据自适应聚类相关研究。文献[1]提出了基于信息熵加权的空间聚类算法,通过引入信息熵权重约束模式,完成对数据的自适应聚类,但此方式只适用于少量信息的多次自适应聚类,在应对大量数据时仍无法很好地进行聚类,导致聚类准确性变差。文献[2]提出了基于信息流加权的集成分类算法,通过引入集成分类算法赋予数据更高的权重,并根据每个数据类别特征构建分类器,以此完成数据的自适应聚类,但此方式对于大量杂乱的数据无法做到精准聚类,实际应用效果并不好。
针对目前聚类方法的漂移点筛选能力和抗干扰能力较弱的问题,设计了一种基于信息熵更新权重的数据自适应聚类方法,并通过实验对该方法的有效性进行了验证。
1 基于信息熵的数据属性加权
利用信息熵的加权对混乱数据进行自适应聚类,在构建信息熵的加权机制前,设计一种混乱数据相异性度量方式[3-4]。
由于所研究的数据为混乱数据,因此采用K-P算法统计当前数据集中相似数据出现的频率,并设定模糊类中心,以此能够更加直观地度量数据之间的相异性。
根据信息熵权重建立模糊类中心,计算公式如式(1)所示:
其中,xi表示第i个数据集;C表示数据集数据的所属类别。
而数据集中的单一对象也可表示为模糊类中心的形式,该式为模糊类中心一种特殊的表示形式[5-6]。
信息熵具有两种形式,分别为数值型与分类型,针对数值型的数据属性进行加权时,需应用到二阶Renyi 熵,Renyi 熵具有良好的计算特性[7-8]。假设X是由独立分布的N个数据对象组成的数据集合,计算熵值f(X)如式(2)所示:
其中,Wi为parzen 窗口函数,通常为高斯核函数。通过parzen 窗口估计法得到的熵通常为正数,上述定义给出的类内熵值反映了在聚类分化结果中某一类的值在不同属性数据情况下的分布状态,即一个类的类内熵越小,聚类过程的数据属性权重越大[9-10]。
互补信息熵计算公式如式(3)所示:
根据以上分析可知,通过信息匹配得到数据熵,在完成数据聚类之后确定信息的不同属性,根据不同属性实现数据分离,从而实现数据属性加权。
2 基于信息熵更新权重的数据自适应聚类
在完成基于信息熵的数据属性加权后,对数据进行自适应聚类,聚类流程如图1 所示。

图1 基于信息熵更新权重的数据自适应聚类流程
根据图1 可知,聚类过程首先构建一个数据自适应聚类器,然后完成聚类模型更新,同时进行基础聚类器更新和权重更新实现数据自适应聚类。
构造一个数据自适应聚类器流程,假设E为一个由k个基础聚类器y组成的自适应聚类器,设S表示数据总量,将S平均分成大小相等的数据块B,此时自适应聚类器开始初始化,当一个新的数据块到达时。若数据块中的所有数据都能够被识别,则可将该数据块转变为一个基础聚类器,当基础聚类器的个数未达到阈值k时,将不断转化可识别的数据块为基础聚类器,直到基础聚类器的数量达到k个[11-12]。自适应聚类器由多个基础聚类器组成,若要建立一个性能完好的自适应聚类器,则需要保证基础聚类器具有多样性与准确性。满足基础聚类器的多样性条件是数据块都建立在不同维度的子空间中,因此每个数据块的维度与空间特征都是随机的。
为了解决数据不稳定的问题,需要使用IEWU算法对自适应聚类器进行更新,更新分为基础聚类器的更新以及基础聚类器权重的更新两部分。
由于IEWU 算法的中心思想与自适应聚类器的构建过程相似,因此在相似数据的数量达到一定程度时便可组建一个数据块,通过数据块得到一个基础聚类器。基础聚类器的权重随着数据块属性与性能的变化而变化,以此解决数据不稳定问题。数据块的大小决定了基础聚类器的性能。较大的数据块可以组建成性能更好的基础聚类器,分类性能更佳。因此在基础聚类器更新过程中,需要筛选出较大的数据块来提升基础聚类器的性能[13-14]。
由于使用IEWU 算法构建了一个混合类型的自适应聚类器,因此在IEWU 算法应用过程中,需要不利用新的基础聚类器来替换旧的基础聚类器,并需要对已有的基础聚类器进行学习,结合信息熵对每个基础聚类器的权重进行更新。通过此方式可以筛选出性能更好的基础聚类器,提高整个自适应聚类器在面对不稳定数据时的处理能力[15]。信息熵为此次研究的重要参数,利用IEWU 算法计算信息熵的计算公式如下:
式中,H表示信息熵;P表示聚类器参数。采用IEWU 算法可求得当前数据属性的信息熵值,由于信息熵能够表示聚类结果的不确定性,因此信息熵越大,聚类结果的不确定性越强。当利用IEWU算法所求得的信息熵足够小时,即可判定当前聚类结果准确。由于不同数据的信息熵都不相同,因此采用动态自适应的方式对信息熵进行更新,信息熵更新阈值计算公式如下:
式中,em为信息熵更新阈值;et为信息熵的平均值;en为信息熵的最小值,et与en的值会随着数据属性的不断变化而发生改变。当IEWU 算法所求得的信息熵值小于em时,则信息熵更新停止。
通常基础聚类器刚建立时会被赋予最高的权重值,随着更多数据块的到来,每个基础聚类器会根据信息熵的阈值判断自身是否处于性能较好的基础聚类器,并实时调整自身权重,使得性能较好的基础聚类器能够被识别出,不断淘汰性能较差的基础聚类器[16]。
自适应聚类器的聚类结果由所有列举出的聚类器进行加权投票,其中IEWU 算法还使用了抛弃策略,由于基础聚类器的性能有好坏之分,性能较差的基础聚类器由于其不稳定性,参与投票后更容易导致聚类结果更加不准确,因此参与投票的基础聚类器都是性能较优的。给予一个固定的权重阈值,该算法只将性能在权重阈值以上的基础聚类器加入投票的排列之中,以此实现数据的自适应聚类[17]。
3 实验研究
为了验证所提出的基于信息熵更新权重的数据自适应聚类方法的实际应用效果,进行了相关实验测试。在实验过程中,选用此次研究的自适应聚类方法和传统的基于人工合成的自适应聚类方法、基于数据分析的数据自适应聚类方法进行实验对比。
为了更好地保证实验效果,同时选用RanTree、SEAg、poker 三个不同的数据块进行实验对比,探究不同数据块下的聚类准确性。得到的实验结果如图2-图4 所示。
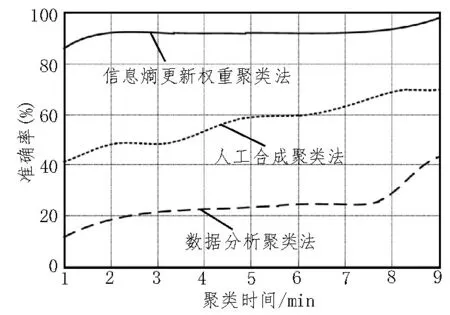
图2 RanTree数据块下聚类准确率
根据图2 可知,由于RanTree 数据块的信息环境极其不稳定,因此三种聚类方法的聚类准确率存在明显差异。对于RanTree 数据块,与实验对比方法相比较,所提出的聚类方法始终保持着较高的聚类准确性。此次提出的聚类方法通过引入信息熵进行数据聚类,在不平稳的环境下也能够很好地适应外界变化,而传统的聚类方法在聚类过程中,容易受到外界因素影响,在不稳定的环境下可能出现准确率上升或下降的问题,难以完成快速适应,甚至会出现数据漂移,导致聚类准确率下降。
与RanTree 数据块相比,SEAg 数据块更加稳定,通过分析图3 可以发现,三种聚类方法的准确率都相对较高,但是在遇见漂移点时,三种聚类方法的准确率都有所下降,此次提出的聚类方法聚类准确率仅有2%~5%的下降,而传统的基于人工合成的自适应聚类方法准确率下降超过20%,基于数据分析的数据自适应聚类方法准确率下降超过50%,由此可见,所提出的聚类方法抗干扰能力更强。

图3 SEAg数据块下聚类准确率
根据图4 可知,poker 数据块存在的漂移点极少,但是聚类过程容易受到外界干扰因素影响,因此三种聚类方法在前期的聚类准确率都相对较低,但是随着聚类时间的增加,此次所提出的聚类方法通过信息熵更新权重消除外界干扰,聚类准确率大大增加,而传统方法依旧难以满足精准聚类要求,导致聚类质量下降。

图4 poker数据块下聚类准确率
在上述基础上,为了进一步验证三种方法的聚类性能,比较了三种方法的数据聚类时间,比较结果如表1 所示。
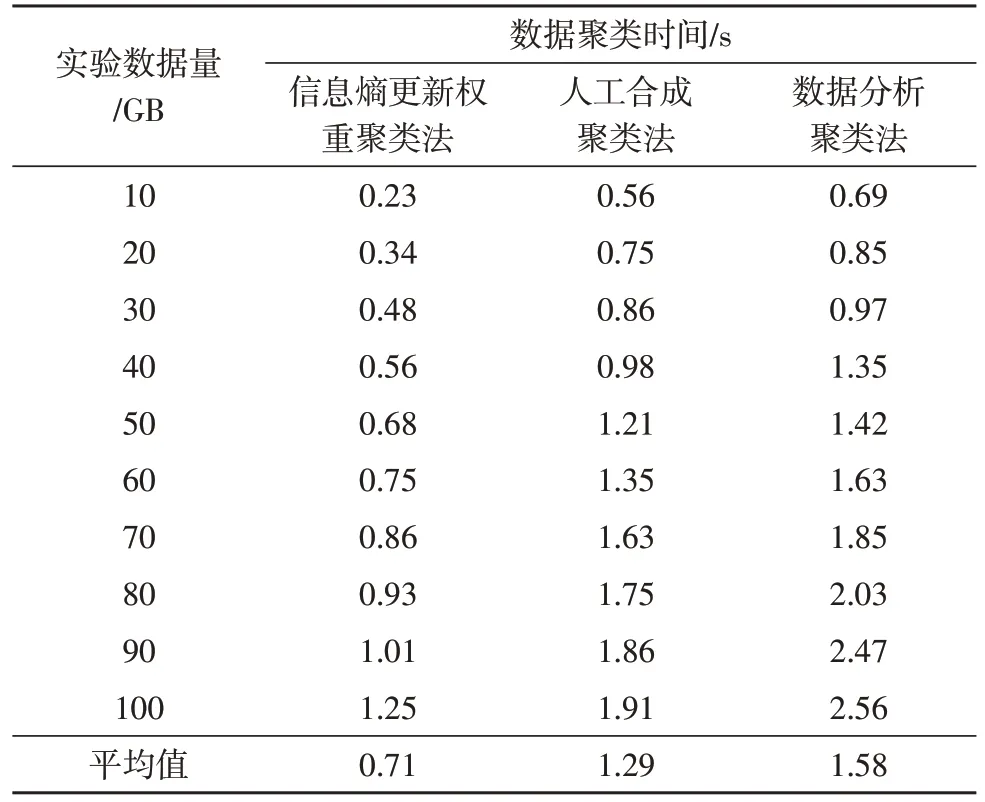
表1 数据聚类时间比较
分析表1 中的数据可知,随着实验数据量的增加,不同方法的数据聚类耗时均呈现上升趋势,当实验数据量达到100 GB 的情况下,三种方法的聚类时间均达到最大值。其中信息熵更新权重聚类法的聚类时间最大值为1.25 s,平均值为0.71 s;人工合成聚类法的聚类时间最大值为1.91 s,平均值为1.29 s;数据分析聚类法的聚类时间最大值为2.56 s,平均值为1.58 s;基于信息熵更新权重的数据自适应聚类方法的聚类时间更短,效率更高。
4 结束语
该文以解决当前聚类方法的漂移点筛选能力和抗干扰能力较弱的问题作为研究目标,设计了一种基于信息熵更新权重的数据自适应聚类方法。通过混乱数据相异性度量完成数据属性加权,构建基础聚类器,利用多个基础聚类器构建自适应聚类器,以此达到自适应聚类数据的最终目标。实验表明,此次提出的基于信息熵更新权重的自适应聚类方法解决了当前方法中存在的问题,能够在数据自适应聚类领域得到广泛应用,以此提升数据的聚类质量。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
电子测试(2017年15期)2017-12-18
电子测试(2017年12期)2017-12-18
雷达学报(2017年6期)2017-03-26
雷达学报(2017年6期)2017-03-26
池州学院学报(2015年3期)2016-01-05
