
双套站传感器数据质量提升方法研究
2023-09-21 07:04宋美蓉梁高丽
河北软件职业技术学院学报 2023年3期
宋美蓉,谢 伟,梁高丽
(四川信息职业技术学院 电子与物联网学院,四川 广元 628000)
0 引言
双套站,即采用双套设备采集数据的站点,其应用目的是保障数据的可靠性、稳定性与可用性。其原理是通过构建两套相同传感器系统来提高原始数据质量。众所周知,通过增加传感器的数量可以提升传感器数据质量,但是增加的设备冗余越多其硬件成本与计算复杂度就会越高,因此,要想在低成本条件下最大程度上为数据质量保驾护航,就需要研究基于双套站提高传感器数据质量的方法。调研发现,当前双套站的应用模式主要是一个作为基准站,另一个则为备用站,在主站数据出现问题的时候才去使用备用站的数据。这种模式虽然大体上解决了数据缺失、严重失真等问题,同时在不增加数据处理重复度的基础上大大提高了数据质量,但仍存在一些不足,主要体现在:主站出现故障才启用备用站的数据,备用站的数据利用率不高;在现实运行中主站的数据判断并不智能,且很多时候得不到真实的反馈,故备用站的数据起不到提高传感器数据质量的作用;基于双套设备数据,可使用的数据整合算法单一,数据质量提升算法得不到提高。
数据质量的提升研究工作主要集中在数据统计规律、算法本地适用性、数据迁移、数据融合算法等方面[1],其研究方法包括范围检查、极值检查、公式检查、统计学检查、内部一致性、空间一致性等[2],在算法上研究较多的是空间一致性,而且该方向研究方法颇多,如正常比率法、最佳内插法等。双套站数据质量研究方法能够从数据融合方面继续突破,主要方法有:加权平均、选举决策法、卡尔曼滤波法、数据统计法、神经网络、D—S 等,[3-6]每种方法都有其优缺点,但是传感器数据质量提升本就是全域全过程的,一种方法解决一种问题的同时也可能会带来另一种问题。本文就以双套站中的温度传感器为例,通过卡尔曼滤波[7-9],结合数据融合算法[10-11],解决双套数据利用率不高、算法单一、数据错误识别不智能、数据质量稳定度与容错能力不高等问题。
1 方法流程
基于双套站的传感器数据质量提升方法,主要是通过软件算法提高传感器冗余的方式提高传感器数据质量,将各物理传感器数据经过算法再模拟出另一套数据,达到一变二,二变四的效果。虽然随着传感器数量的增加,传感器数据质量会有所提高,但是数据的处理与融合复杂度更高、计算量更大,故不会一味的为追求数据质量而无限制地增加传感器数量,因而本文采用的是双套站,将传感器数据由二组变为四组,研究其融合算法以达到提高传感器数据质量的目的。本方法虽然是以双套站为基础,但所得数据不分主次,经数据融合算法合成为一套传感器数据。
该方法流程如图1 所示,首先进行数据准备,每套站点独自收集数据,然后在单站内进行如格式一致性、时间一致性、极值检测等容易实现的通用数据质量控制,排除错误与粗差大的值,标记缺测值。为了建立数据预测模型,获取当前时刻之前的两个小时的分钟数据作为数据建模资源,每个传感器数据经此预测模型形成两套数据,双套站则可以形成相同要素相同类型的四套数据,最后通过数据融合算法,将四套数据融合为一套可用性强、稳定度高的数据供后续业务使用。
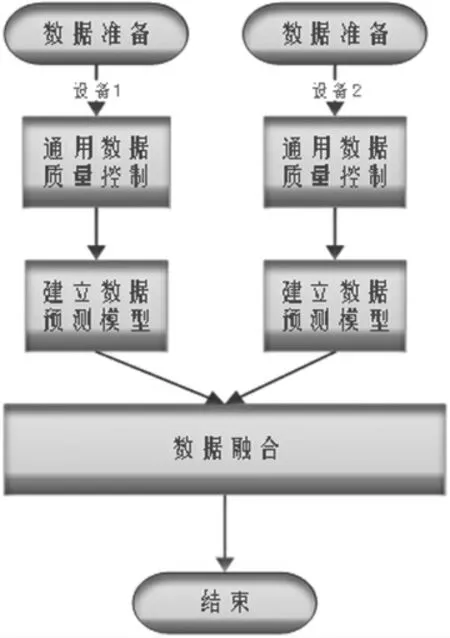
图1 方法流程图
2 方法分析
2.1 数据预测模型
在温度测量过程中,温度传感器测得在一定范围内有规律的离散值,通过这些规律设计算法对将来的温度值进行预测,从统计学上讲,预测值可能更具稳定性与可靠性。由图2 可以看出,经过卡尔曼滤波后,温度更稳定也更接近真实值,因而本文就通过卡尔曼滤波建立温度数据预测模型。通过调节超参数即调节相关权重问题,得到预测数据,此时的预测数据可作为一个模拟站点的温度,因此双套站就有两套模拟温度,加上双套站测得的两套温度数据就变成了四套温度数据。此时温度可以用式(1)与式(2)来表达。
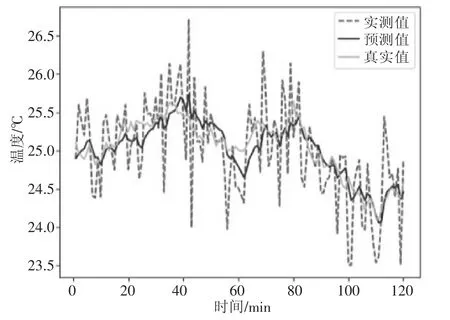
图2 温度预测仿真结果
式(1)中,X(k)代表当前时间温度实际值,X(k-1)代表上一时刻温度值,系数A为观测的状态转移矩阵,BU(k)为外部作用(比如蒸发、日照等),W(k-1)为上时刻测量过程误差;式(2)中,Z(k)代表当前时刻温度的测量值,V(k)为测量仪器自身误差,H为一系数矩阵。因为温度值预测的状态变量是一维的,所以A=1,T=1,H=1,BU(k)为零,则上述两公式转换为:
当模型建立好以后进行卡尔曼滤波,此时得到如下方程组[5]:
式(5)中,X_pre为基于上一个温度值的不确定估计,Xkf(k)为当前时刻确定的估计值,P_pre为误差协方差估计值,P为误差协方差,Z(k)为当前时刻测试值,K为卡尔曼增益,Q 为测量过程中误差的方差值,R 为测量仪器自身误差方差,本方法中使用误差为±0.1℃传感器,因此R=0.01,设定Q=0.01,即更相信测量值一些,例如要估计当前时刻的温度值,取当前温度值前两个小时的分钟数据即120 条数据进行卡尔曼滤波,调节超参数,获取当前可信温度预测值。
2.2 数据融合方法
此数据融合方法为作用于上位机的数据处理算法,接收来自双套站的两组温度数据,再加上用这两组数据经预测模型而生成的两组预测数据,此时双套站就变为了四套站,这里的预测数据可以作为两个模拟站点的数据,并且认定其可信度较高,通过域值交差判断等方式,最终将四组数据融合为一组可信的温度数据。
步骤1,计算两个站点的预测值与实测值差。
在这里为了区分双套站,分别标记为A站与B站,其中TAp与TA表示A站的温度预测值与实测值,ΔTA为A站预测与实测温度差;同理TBp与TB表示B站的温度预测值与实测值,ΔTB为B站预测与实测温度差。
温度传感器精度通常为±0.2℃或±0.1℃,此处定义传感器两两之间的允许误差范围为Range(i,j),下文称为标定域值,公式为:
其中,Acc为传感器精度,也可近似等价于测量误差,Ti与Tj表示传感器所处温度。如果ΔTX>Range(i,j),此时将X站的数据标记为怀疑值,X代表A站或者B站;如果ΔTX≤Range(i,j),此时表示两站数据均为正常值。
设定观测ΔTA与ΔTB 的监控门值,通常设定为连续5~10 分钟,即连续5~10 次,前5 次为标疑时段,后5 次为确定与尝试恢复时段,如在总次数超过10 次后仍超出标定域值,则可以标定此站点温度传感器出现问题,需要进入另一个处理流程。
步骤2,计算两两温度传感器差值。
T1,T2为A站实测值与预测值,T3,T4为B站实测值与预测值,Dij表示第i个传感器与第j个传感器之间的误差。如果Dij≤Range(i,j),此时把传感器实测值与预测值都作为真实值,取其平均值为此站温度值,不用加权是因为此时相信平均值更具有效性,不偏向算法的预测值也不侧重于实测值。即:
当D12、D13、D14、D23、D24、D34任意一个大于标定域值,A 站或B 站数据存疑,此时要分情况而论。当D12大于等于D34时,初步认为A 站出现问题,则通常情况下D13、D14、D23、D24也会出现问题,即超出标定域值,此时融合温度值计算公式如下:
虽然A 站观测值出现问题,但是预测值在一定范围可以起到稳定作用,所以此时如果D23、D24小于标定域值,则认为模拟站点即预测值有效,所以此时融合温度T经式(11)获得;如果D23、D24大于标定域值,则认为预测值偏差太大属于失效状态,没有起到稳定性作用,此时A 站的温度传感器数据值存疑确定次数加1,当前A 站温度弃用,所以此时融合温度T 经式(12)获得。
当D34大于D12,初步认为B 站出现问题,则通常情况下D13、D14、D23、D24也会出现问题,即超出标定域值,此时融合温度计算公式如下:
虽然B 站观测值出现问题,但是预测值在一定范围可以起到稳定作用,所以此时如果D24、D14小于标定域值,则认为模拟站点即预测值有效,所以此时融合温度T 可经式(13)获得;如果D24、D14大于标定域值,则认为预测值偏差太大与属于失效状态,没有起到稳定性作用,此时B 站的温度传感器数据值存疑确定次数加1,当前B 站温度弃用,所以此时融合温度T 经式(14)获得。如果Dij≥Range(i,j),则此时融合温度T 标为缺测。
3 方法验证
根据实验设计,该方法需要两套设备上相同传感器在相同时刻所采集的数据,因为本文验证没有实时性要求,所以验证数据来源于北京某双套站5 月份历史数据,获取某时刻之前两个小时数据通过预测模型进行预测,基于python 的Matplotlib 绘图,将分别对该方法的稳定性、准确性和可靠性进行分析。
3.1 稳定性分析
根据数据流方向,A 站与B 站的温度数据先进行简单质控,然后经预测模型得到预测数据,最后再根据本文数据融合算法将温度值进行融合形成一套温度数据。A 站与B 站的观测值与预测值图形如图3 所示,在传感器数据正常的情况下,预测值与观测值走向趋势相同且稳定,两者之间偏差也不大,都在有效范围之内,且预测值更平稳。
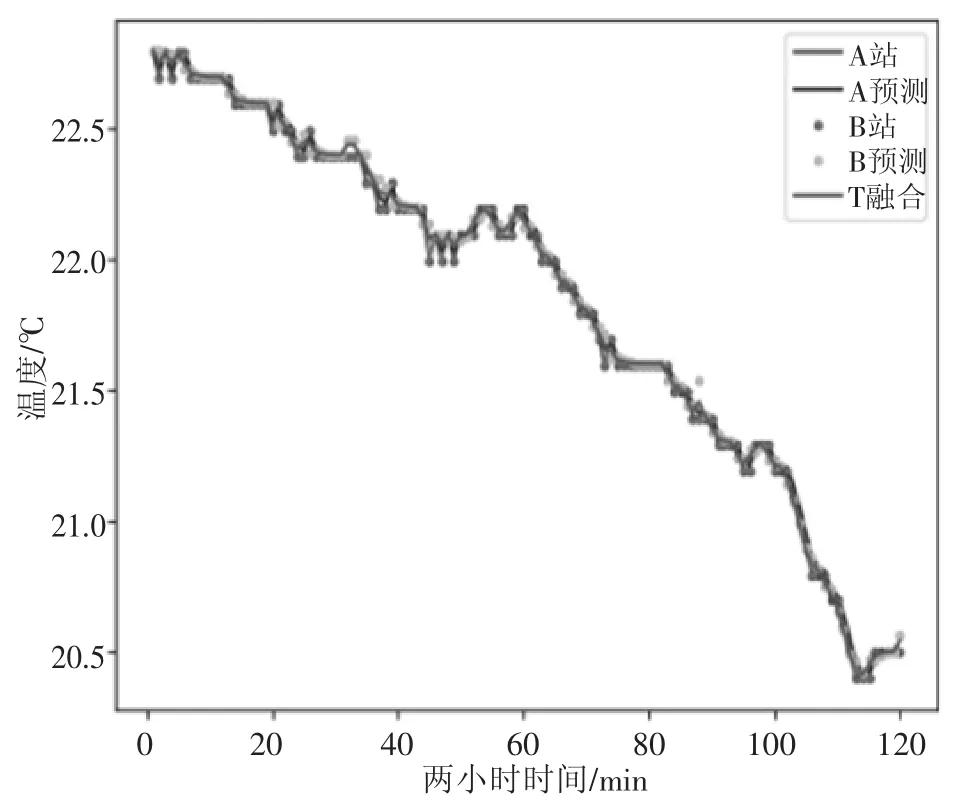
图3 每分钟温度与融合后温度
3.2 准确性分析
取两个小时的A 站数据与B 站数据,经过本文中预测模型与数据整合算法,从图4 中可以看出,在使用了本文中的算法后,融合后温度数据与其它温度误差相比,范围更小,意味着精准度更高,可见在某种程度上,本文中算法有益于提高双套站数据精准度。
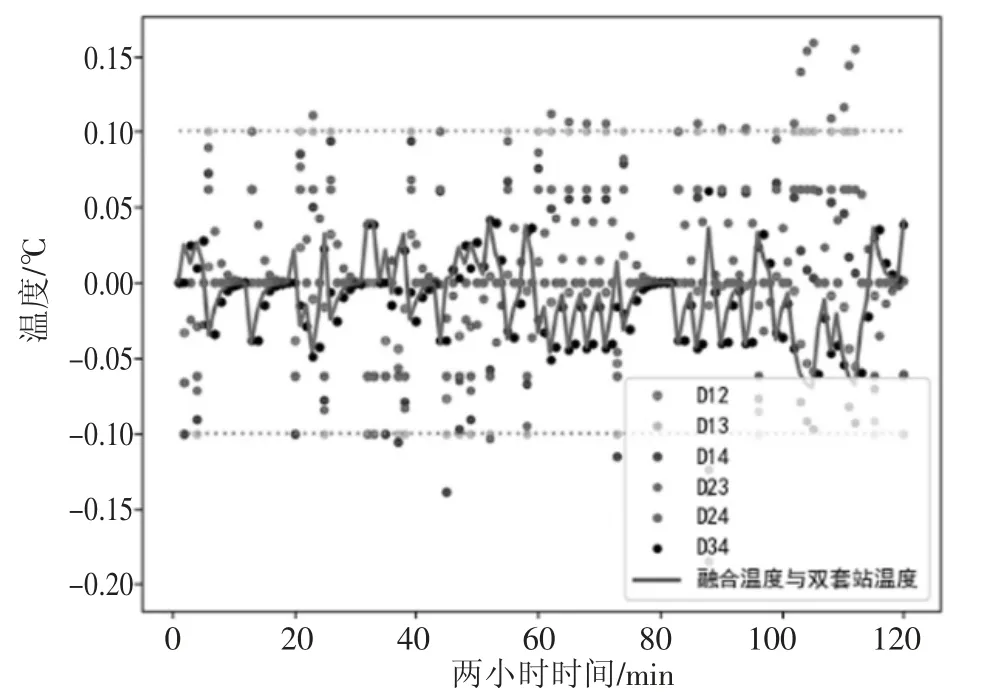
图4 各温度误差
3.3 可靠性分析
为验证本方法的容错性,将A 站数据与B 站数据不连续修改两个值,A 站数据在原来基础上下调,B 站数据在原来基础上上调,最终合成的温度如图5 所示,融合后的温度依然很稳定很平滑。由图6 也可以看出,当A 站如果出现不稳定情况或是其他外界的影响,融合温度此时会智能判断B 站数据趋于正常值,但是当双站连续数据失误超过5 次以上,融合温度会出现波动,此时就断定两站数据有误,会报警或进行其他人工等处理。

图5 AB 站与融合温度

图6 A 站误差分析
4 结论
通过对传统气象双套站提高数据质量时采取的数据质控方法进行改进,在软件算法层面模拟增加硬件设备冗余以提升数据质量,同时改变主站与备用站的思维,不再有主次之分。本文提出了从双套站的数据通过预测模型再生成两套数据,相当于在某种程度上由双套站变为了四套站,同时将四套数据进行平等对待不区分主次,提出正确判断数据融合算法,将四套数据形成一套数据。该方法的提出,能够有效提升软件数据质量,同时提高了数据的可靠性与稳定性。通过实验对比分析,该双套站数据质量提升方法能够在保证现有业务的基础上,不增加经济成本的同时,有效智能区分两站数据质量高低,用算法进行取舍,最终获得一组更具真实性的数据,由此证明该算法在一定程度上提高了传感器数据质量的稳定性、精确性、可靠性,对弥补软件算法、提高数据质量具有一定的意义。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
今日农业(2021年19期)2022-01-12
纺织科学研究(2021年1期)2021-12-03
环境保护与循环经济(2021年7期)2021-11-02
国外核新闻(2020年8期)2020-03-14
电子制作(2019年22期)2020-01-14
传媒评论(2019年5期)2019-08-30
时代英语·高一(2019年1期)2019-03-13
