
基于PCA-BP算法的机械钻速预测研究*
2023-10-17 03:09王汉昌何世明张光福孔令豪
石油机械 2023年10期
汤 明 王汉昌 何世明 张光福 孔令豪
(西南石油大学油气藏地质及开发工程国家重点实验室)
0 引 言
机械钻速(ROP)是反映钻井效率的重要指标。为优化钻井相关作业,降低钻井成本,需要准确预测机械钻速,到达实时优化的目的。精确建立机械钻速与影响因素之间的模型,对预测机械钻速、优化工程参数具有重大意义。
钻速预测模型分为:①基于钻速方程的预测模型。基于物理过程,针对不同参数与钻速的关系,建立数学模型预测钻速。例如F.S.YOUNG[1]建立钻压、可钻性、转速、钻头磨损系数以及进尺与机械钻速之间的量化关系。M.K.MORAVEJI等[2]在传统钻速方程基础上引入机械参数、水力参数和流变参数等6个量优化钻速方程。LI W.Y.[3]基于分形理论修正钻速方程,提高预测精度。U.J.F.AARSNES等[4]通过引入岩石力学参数、压力和水力参数,修正钻速预测模型。N.BILIM等[5]基于岩石可钻性,建立岩石单轴抗压强度、密度、硬度、孔隙度与机械钻速的数学模型。G.HARELAND等[6]基于切削齿和岩石的相互作用,建立了机械钻速与切削齿数量、切削面积和钻头直径之间的关系,为钻头选型提供了参考思路。DENG Y.等[7]使用岩石动态抗压强度代替静态抗压强度,提高牙轮钻头钻速预测模型的精度。②基于机器学习的钻速预测模型。基于现场大数据,M.C.SEIFABAD等[8]利用模糊类的机器学习算法,建立了Ahvaz油田不同层位的钻速回归模型,但该模型的普适性和泛化性较弱,仅仅适用于Ahvaz油田。为提高模型预测精度和泛化性,ZHOU Y.等[9-13]归纳了神经网络(ANN)、支持向量机(SVM)、支持矢量回归(SVR)、极端机器学习(ELM)和梯度增强决策树(GBDT)等算法在钻井工程中的适用性,提高了不同情况下对应模型的泛化能力和可靠性。
上述用于预测机械钻速的钻速方程模型存在建模困难、求解困难和对井场大数据利用率低下等问题。基于机器学习的钻速预测模型存在模型输入层参数过多,寻找隐藏层最优的节点数困难、计算成本高、预测结果稳定性差且无法实现实时反馈参数合理性等问题。为实现钻速准确高效预测,本文提出一种基于主成分分析(Principal Component Analysis,PCA)[14]优化的BP(Back Propagation)神经网络机械钻速预测新模型。该模型以现场数据为基础,首先采用小波滤波法对数据进行降噪处理,其次采用PCA提取数据集主成分,降低输入层参数个数,缩小隐藏层节点数的寻找范围,并将主成分作为模型输入参数,预测机械钻速。最后,基于预测结果实时反馈参数合理性并加以调整,以期为提高机械钻速提供科学的指导意见。
1 基于主成分分析的BP神经网络
基于主成分分析法,对BP神经网络输入层参数进行降维,有利于缩小隐藏层最优节点数的寻找范围,降低计算成本,优化模型计算过程,提高模型预测结果的稳定性。
1.1 主成分分析法(PCA)
主成分分析属于降维算法,目的是将多个变量指标类型转化成少数几个主成分,且这些主成分是原始变量的最大线性无关组合,因此能代表原始数据的绝大部分信息。主成分分析原理是将离散的数据点(信息)尽可能地集中在一个方向(本质为找出数据中心,旋转坐标轴),并以该方向的信息作为描述系统内离散数据点的主要特征。以二维情况为例,原始变量为x1、x2,由二维正态分布可知,样本点分布在一个平面椭圆内。若长轴方向取F2,短轴方向取F1,效果相当于将原坐标轴按照一定角度进行旋转,使更多的样本点都分布在坐标轴方向,如图1所示。

图1 主成分几何关系图Fig.1 Geometric relationship of principal components
由图1可以看出,坐标旋转后有如下性质:①新坐标F1、F2非相关。②平面样本点的波动可以归结为F2轴上的波动,而F1轴上波动较小,称F1、F2为x1、x2的主成分。若椭圆长径远大于短径,则短径上的综合变量F1可忽略不计,可只考虑长径(F2)方向的波动,因此二维平面可降维成一维线性,故F2即为x1、x2的主成分。③基于数学角度,找出主成分即为找出样本数据集较大特征值对应的特征向量。
1.2 BP神经网络
BP神经网络的原理是通过修正实际值和预测值之间的误差,通过反向调节机制改变神经网络的权值和阈值,使预测值不断接近实际值。如果误差较大,则重新选择连接权值进行计算,直到误差满足要求。该方法解决了隐藏层不易确定的问题,具有较强的实用价值。
1.3 PCA-BP模型
机械钻速受到众多因素综合影响,利用PCA方法可有效降低多影响因子间的冗余程度,从而获得机械钻速与影响因子间的本质关系,然后将数据集主成分作为BP神经网络的输入参数,进行机械钻速预测。
PCA优化BP神经网络算法步骤如图2所示。
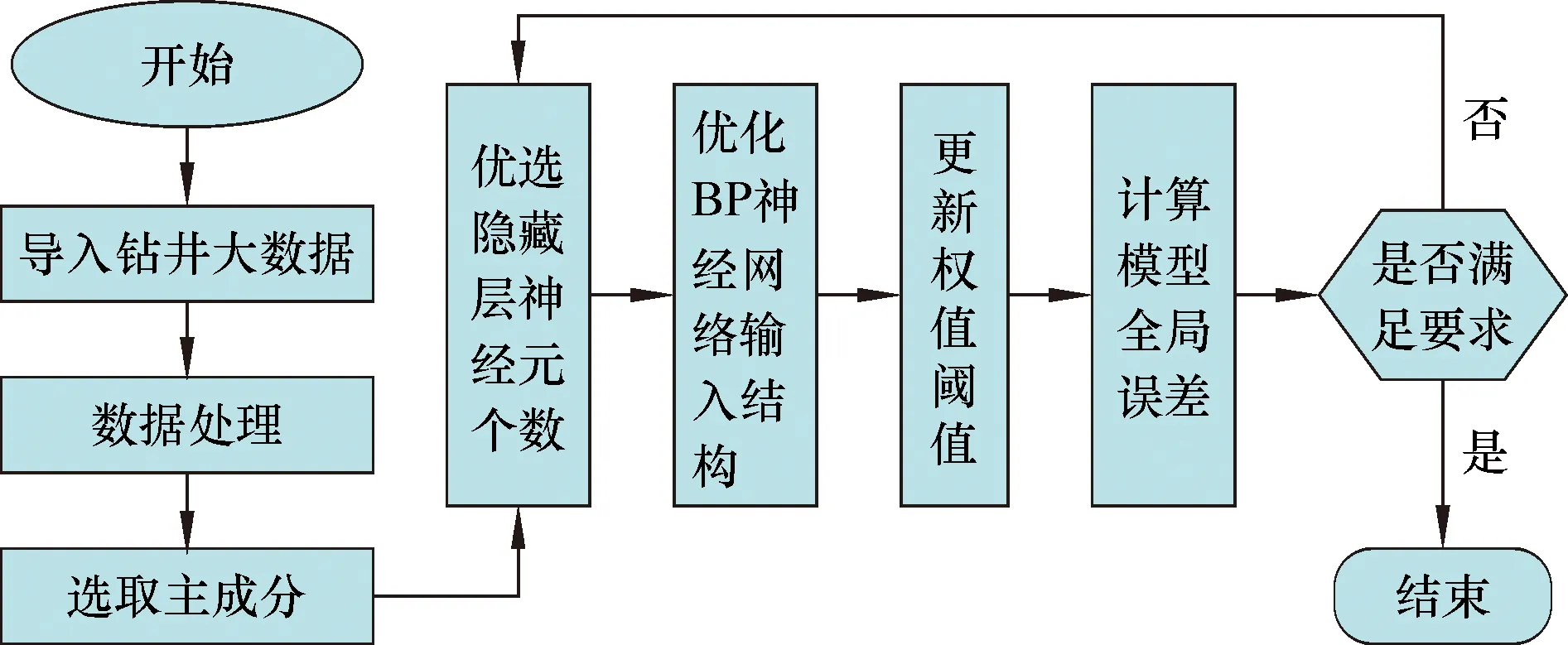
图2 基于PCA优化的BP神经网络机械钻速预测模型流程图Fig.2 Flow chart of ROP prediction model based on PCA-BP
2 基于PCA-BP的机械钻速预测建模
基于PCA-BP的机械钻速预测建模步骤具体为:首先对钻井大数据进行预处理,清洗掉数据中的异常值、错误值等;其次对后处理数据进行主成分分析,降维输入层参数,缩小隐藏层神经元最优节点数的寻找范围;最后以数据集主成分作为BP神经网络的输入参数,机械钻速作为输出参数,进行机械钻速的预测研究。
2.1 钻井数据预处理
井场中通过数字电路传输录、测井等数据。由于高频数字电频的影响,信号中会出现大量带有尖峰或突变的异常“噪声”,为提高原始数据中信息利用率,需除去噪声干扰成分[15-18]。小波滤波法同时具备“局部化、窗口大小随频率变换”的优点,可对高频部分“高时间分辨率、低频率”影响产生的白噪声进行有效去除。将分析信号X(t)作为小波变换,即有:
(1)
式中:Wf(τ,a)为经过小波变换后的去噪数据;a(a>0)为尺度因子,作用是实现基本小波φ(t)的伸缩变换;τ为平移因子,作用是实现基本小波在时间轴上的平移变换。
2.2 主成分分析
现场数据种类繁多冗杂,数据之间大多为非线性关系,为便于计算和现场简化应用,采用主成分分析对数据降维,简化计算。PCA方法的计算步骤如下。
步骤1:标准化处理。假设有n个样本,p个指标,则可以构成大小为n×p的样本矩阵x:
(2)
对式(1)按列计算均值再求标准差,得到数据集标准阵:
(3)

(4)
式中:Sj为变量j的标准差。
对数据进行标准化处理:
(5)
式中:Xij为变量j的标准化数据。
故原始样本矩阵经标准化后变为:
(6)
步骤2:计算标准化样本的协方差矩阵并求对应的特征值和特征向量。
(7)
(8)
式中:rij为变量标准化后的协方差;R为数据集的协方差矩阵。
计算特征向量:
(9)
式中:λi为协方差矩阵的特征值;ap为协方差矩阵的特征向量
步骤3:计算主成分贡献率及累计贡献率。
(10)
(11)
式中:contribution为主成分贡献率;contribution_sum为主成分累计贡献率。
步骤4:分析主成分代表意义。在实际应用中,主成分的选取原则为,选取累计贡献率超过80%的特征值对应的第一、第二、……、第m(m≤p)个主成分[19-20]。
第i个主成分为:
Fi=a1iX1+a2iX2i+…+apiXp(i=1,2,…,m)
(12)
2.3 PCA-BP机械钻速预测建模
PCA-BP机械钻速预测模型框架结构如图3所示。PCA-BP机械钻速预测模型建模过程共分为4个部分:第一个部分为数据预处理部分,作用是收集整合现场实测数据并对数据进行降噪,提高数据可信度;第二部分为数据主成分分析部分,其目的是完成数据集的主成分分析,简化数据结构;第三部分为BP神经网络的结构确定与训练部分,该部分的输入变量为第二部分中计算所得数据集主成分,输出变量为机械钻速;第四部分为预测误差分析和效果评价,若预测误差精度达到精度要求,则输出预测结果、保存训练网络,并将PCA-BP模型与传统的BP模型进行横向对比,反之则调整网络结构,直到达到精度要求并进行模型的横向对比。
3 实例分析
大多数机械钻速类研究均以单井钻速作为预测,泛化性差,因此为增强模型泛化性,需扩大训练数据的范围。本次建模预测选用某区块6口井(J1~J6井)的二开一趟钻数据作为训练集数据,数据量为13 678组。
3.1 参数预处理
本次实例数据来自四川盆地川中地区J井区,对完钻井中的录井、测井数据加以分析,筛选出钻压、扭矩、转速、排量、密度、切削深度、弹性模量、机械钻速等8组数据。表1列举了J1~J6井部分训练数据。
钻井现场环境复杂多变,使得数字电路中存在白噪声的干扰,现利用滤波法对数据进行降噪处理,以J2井部分数据集处理结果为例,如图4所示。
在图4中,不同参数原始数据曲线包含许多尖峰状的异常值,应用滤波法降噪后,数据曲线光滑且轮廓清晰,数据曲线中的尖峰状异常值被有效消除。
3.2 J井区影响钻速的主成分
将滤波后的数据进行主成分分析,其相关系数矩阵的特征值、对应的特征向量以及贡献率和主成分如表2所示。

表2 相关系数矩阵特征向量Table 2 Correlation coefficient matrix eigenvector
从表2可以看出,前4个主成分的累计贡献率达92.6%,因此可以考虑只取前面的4个主成分代表原始数据特征。数据集主成分如表3所示。

表3 数据集主成分Table 3 Principal components of data set
数据集主成分及其载荷为:
Fi=X·λi(i=1,2,3,4)
(13)
F1~4=[X1X2X3X4X5X6X7]
(14)
第一主成分F1在钻压、扭矩、转速上有中等成分的正载荷,而在切削深度上有中等程度的负载荷,其余变量上载荷都较小,可称第一主成分为机械参数成分。
第二主成分F2在弹性模量上有较大程度的正载荷,在密度上有较大程度的负载荷,其余变量上载荷都较小,可称第二主成分为地层因素成分。
第三主成分F3在排量上有较大程度的正载荷,在弹性模量上有中等程度的负载荷,其余变量上载荷都较小,可称第三主成分为水力参数成分。
第四主成分F4在密度上有中等程度的正载荷,在弹性模量上有较大程度的负载荷,在扭矩、排量、密度上有中等程度的负载荷,其余变量上载荷都较小,可称第四主成分为密度因素成分。
3.3 机械钻速预测及误差分析
PCA-BP模型的数据集按照训练集80%、验证集20%的方式送入模型训练,设置误差精度为0.001,迭代次数为8 000,学习速率为0.01。测试集和训练集精度如图5所示。
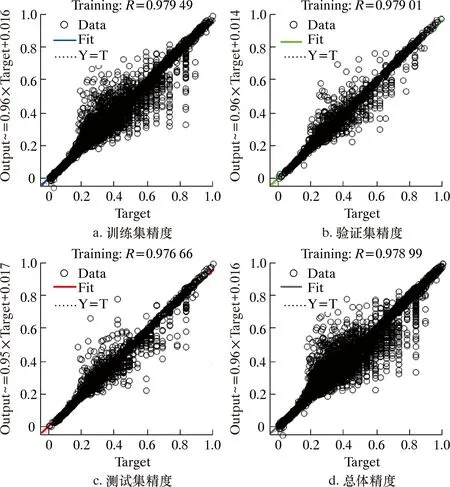
图5 PCA-BP模型验证图集Fig.5 Collective drawings of PCA-BP model verification
BP神经网络精度受隐藏层数和隐藏层节点数影响,故提高网络预测精度方法有2种:①增加隐藏层数;②优选隐藏层节点数[21-26]。增加隐藏层可提高计算精度,但随着隐藏层的增加,网络训练时间和过拟合概率将会大大增加。因此本文采用优选隐藏层节点数的方式提高网络预测精度。隐藏层神经元个数受到输入层参数的影响,以Kolmogorov和Gorman[27]分别作为隐藏节点数上、下限,做出不同输入参数数量下的隐藏层神经元节点数和节点数对应的误差曲线图,如图6、图7所示。从图6可知,输入层参数范围为[1,7],隐藏层神经元范围为[1,15],可见隐藏层神经个数优选范围较大。但是通过主成分降维后,不仅可保留大部分原始数据的有效信息,还可有效缩小最优节点数的寻找范围。由图6和图7可知:隐藏层节点数为7,对应误差最小仅为0.000 232;输入参数个数为3,代表原始变量84.8%的信息,对应隐藏层神经元范围为[3,7];输入参数个数为4,代表原始变量92.6%的信息,对应隐藏层神经元范围为[3,9]。综合考虑网络误差和原始变量信息反映程度,选择输入层参数个数为4,隐藏层节点数为7。
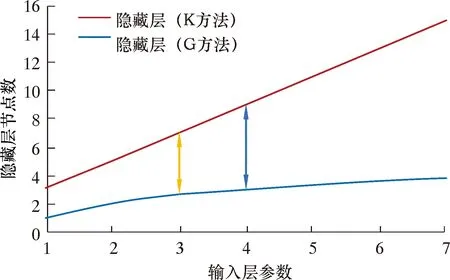
图6 输入参数个数与节点数关系Fig.6 Relation between input parameters and nodes

图7 节点数与误差关系图Fig.7 Relation between node number and error
其中,Kolmogorov法为:
h=2m+1
(15)
Gorman法为:
h=log2(2m)
(16)
式中:h为隐藏层神经元个数;m为输入层神经元个数,适用于单层网络的隐藏层节点数确定。
图8为机械钻速预测结果横向对比。图9为不同模型误差频率分布。从图8和图9可以看出,PCA-BP模型的预测结果相较于BAS-BP、BP和RF的预测结果,真实值和预测值间的符合度更高,变化趋势更接近,并且模型预测产生的误差更小。其中PCA-BP模型误差在10%以内的频数占比为90.74%,由此可见该模型预测结果的误差大多数都在10%以下。而BAS-BP、BP和RF在10%以内的误差频数占比为80.9%、77.2%和69.5%,表明计算精度相较于PCA-BP明显降低;在10%~30%内的误差频数占比分别为14.1%、13.1%和20.4%,相较于PCA-BP其误差频数占比分别增大7.81%、6.81%和14.11%。由此可见,PCA-BP模型误差范围更小、预测精度更高、适用性更强。

图9 不同模型误差频数占比分布图Fig.9 Different models error frequency and prcentage layout
为验证PCA-BP模型相较于BAS-BP、BP和RF模型的优越性,在预测结果和误差统计的基础上,选取拟合优度(R2)、均方根误差、平均绝对百分比误差和迭代次数作为评价模型的指标[28-29],横向对比各模型的优势,结果如表4所示。

表4 不同模型评价指标Table 4 Evaluation indices of different models
在表4中,PCA-BP模型的迭代次数与BAS-BP相同,但其均方根差和平均绝对百分比误差较BAS-BP模型分别降低23.88%和35.45%,拟合优度提高5.7%,表明在算力接近的情况下,PCA-BP的预测精度高于BAS-BP。相较于BP模型,PCA-BP的均方根差、平均绝对百分比误差和迭代次数分别降低30.3%、56.7%和73.0%,拟合优度提高9.4%;相较于RF模型,分别降低43.6%、61.5%和88.7%,拟合优度提高18.7%。以上分析表明,本文提出的PCA-BP机械钻速预测模型预测精度高,迭代速度快,便于应用。
3.4 影响机械钻速的参数实时评价
基于机械钻速预测结果,开展影响机械钻速的参数实时评价,如表5中所示的A、B和C这3点位于水平段(2 550~3 340 m),可以看出机械钻速变化较大。A点到B点,机械参数成分加强,水力参数成分减弱,其他成分变动较小,机械钻速降低;B点到C点,机械参数成分减弱,水力参数成分加强,其他成分变动较小,机械钻速升高。由此可见,水平段中水力参数成分是导致机械钻速变化的主要原因,增大水力参数有利于提高机械钻速。
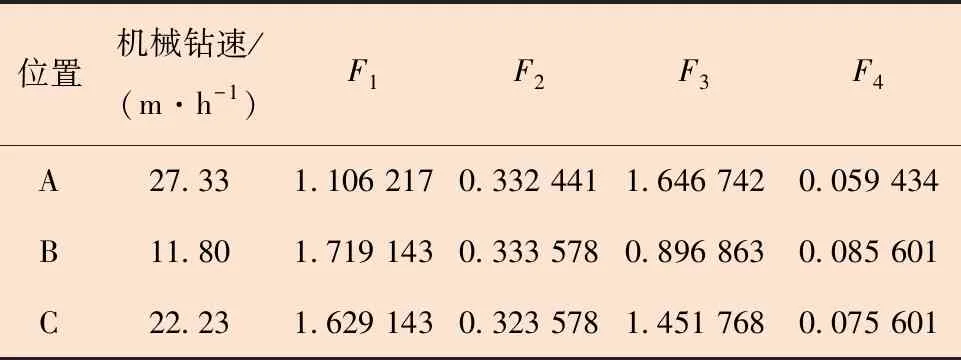
表5 不同钻速下的主成分Table 5 Principal components at different ROPs
4 结 论
(1)以J井区为例,采用主成分分析法,选取4个主成分,可涵盖92.6%的原始数据特征,能有效降低数据集的维度,节省大量的计算时间,提高数据集使用效率。
(2)基于PCA-BP神经网络,建立机械钻速预测模型,与BAS-BP、BP和RF等智能算法相比:均方根误差分别降低23.88%、30.3%和43.6%;平均绝对百分比误差分别降低35.45%、56.7%和61.5%;拟合优度分别提高5.7%、9.4%和18.7%,表明PCA-BP模型预测精度高、迭代速度快。
(3)在实际钻井过程中,基于PCA-BP算法的预测结果,反演任意井深下主成分中的工程参数对机械钻速的影响,并以此为依据调整工程参数,可有效提高机械钻速,提升钻井效率。
猜你喜欢
石油研究(2020年1期)2020-05-22
科学与财富(2020年5期)2020-05-06
电子制作(2019年19期)2019-11-23
科学与技术(2019年3期)2019-03-05
科学与财富(2018年7期)2018-05-21
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
现代电子技术(2014年10期)2014-07-19
