
基于希尔伯特-黄变换的音频信号复制粘贴篡改检测算法
2023-11-22 05:54孙先峰李孝杰史沧红牛宪华王冬宇
西华大学学报(自然科学版) 2023年6期
孙先峰,彭 锴,李孝杰,史沧红*,牛宪华,王冬宇
(1.西华大学计算机与软件工程学院,四川 成都 610039;2.成都信息工程大学计算机学院,四川 成都 610225)
随着数字媒体技术的发展,音频作为数字证据在法院和其他特殊场合被大量使用[1]。然而,一些不具备音频处理专业技术的普通用户也能够使用功能强大的编辑软件对音频进行篡改。复制粘贴篡改操作是一种常用的语音篡改方法[2-4]。攻击者可以很容易地复制音频记录的一些片段,并将这些片段粘贴到同一音频文件的其他位置,以改变句子的语义信息。例如,“我去过成都”可以很容易地改为“我没去过成都”,只是将“没”复制粘贴到“我”和“去过”之间就完全改变了音频的语义信息,这种伪造通常是难以察觉的。在没有有效的复制粘贴检测工具情况下,通过反复听这些录音或者直接看音频信号的波形图来检测语音复制粘贴篡改,不但花费大量的时间,而且识别篡改准确性不高。尤其是在执行一些后处理操作来抹除伪造的痕迹后,复制粘贴伪造检测更加困难[5]。
因此,有后处理的音频信号复制粘贴篡改检测受到了许多研究者的关注,但是现有大部分文献中的方法仍存在检测精度不高、抗干扰能力不强等问题。例如:Mannepalli 等[6]提出了一种基于动态时间规划的音频复制粘贴检测方法,其利用梅尔倒谱系数作为音频特征,使用动态时间规整(dynamic time warping,DTW)来计算2 个音频序列之间的距离和相似度,可以有效地检测和判断音频是否篡改,但对于后处理过的篡改音频信号检测精度不高;Xiao 等[7]提出了一种基于计算每2 个音频段的相似度来检测音频复制粘贴伪造的方法,利用快速卷积算法提高了计算效率,但对受到干扰后的音频检测精度较低;Imran 等[8]应用局部二进制模式检测音频记录中的复制粘贴伪造,将图像检测的方法应用到音频上,实现了对音频篡改的盲检测,但该方法检测精度依赖于其中的声学活动检测模块;Liu 等[9]提出了一种基于离散傅里叶变换(discrete fourier transform,DFT)的数字音频快速复制粘贴检测方法,对每个有声段提取后的DFT 特征序列快速排序,对排序后的音频特征序列进行两两相似度计算,从而减少了检测时间的消耗,但对强后处理技术的鲁棒性不高。这些方法对于没有任何后处理操作的篡改音频可以达到很好的检测效果,但当攻击者采用后处理操作来消除篡改痕迹时,它们就不那么有效了。如何有效地检测音频信号复制粘贴篡改是音频取证中亟待解决的问题。
为此,基于希尔伯特-黄变换(Hilbert-Huang transform,HHT),本文提出一种音频复制粘贴篡改检测方法,以提高检测准确率和抗干扰能力。该算法首先利用音高跟踪算法YAAPT[10]做声学活动检测,将音频的有声段和无声段区分开,进而使用HHT 将得到的有声段进行经验模态分解(empirical mode decomposition,EMD),在获得若干个本质模态函数(intrinsic mode function,IMF)后,对每一个满足条件的IMF 分量做希尔伯特变换,得到相应的希尔伯特谱,然后汇总所有IMF 的希尔伯特谱,得到音频信号的希尔伯特谱和希尔伯特特征序列,通过比较希尔伯特谱和使用相似度算法DTW[1]来计算每2 个有声段的希尔伯特特征序列的相似程度,谱图越相似,DTW 值越小,说明这2 个部分的相似度越高,最后将得到的DTW 值和设定的阈值比较,如果2 个有声段的DTW 值小于设定的阈值,那么这2 个片段将被认为是一组复制粘贴的片段,从而来检测和定位该音频信号中存在的复制粘贴篡改操作。本文的创新点主要有2 方面。
1)将希尔伯特-黄变换用于音频的复制粘贴篡改检测,实现了在加噪、滤波和MP3 压缩等后处理操作下对音频复制粘贴篡改的检测。
2)与其他复制粘贴篡改检测算法相比,本文算法精确度和召回率都较高,且抗干扰能力强。
1 相关工作
近年来,数字音频信号的真实性取证技术受到许多研究者的关注,有关音频取证的大量工作也被报道。然而,现有的文献大多集中在音频拼接篡改检测[11]、录音识别[12]、音频压缩历史分析[13]和说话人识别[14]。此外,文献[15-18]提出了各种方法用于图像复制粘贴篡改检测,但对语音记录中复制粘贴篡改检测的研究相对较少。
在以往的研究[19-22]中,HHT 广泛用于信号处理系统和通信系统中,用来构建解析信号,使信号频谱仅含有正频率成分,从而降低信号的抽样率。HHT 结果反映了信号时频特征,即信号频域特征随时间变化的规律。相对于傅里叶变换得到的信号频率组成,HHT 还可以获取频率成分随时间的“变化”,因此能很好地对音频信号的变化规律进行捕捉。
HHT 主要包含EMD 和希尔伯特变换2 部分内容。HHT 处理非平稳信号的基本过程是:首先利用EMD 方法将给定的信号分解为若干IMF,这些IMF 是满足一定条件的分量,然后对每一个IMF 进行希尔伯特变换,得到相应的希尔伯特谱,最后汇总所有IMF 的希尔伯特谱就会得到原始信号的希尔伯特谱。HHT 可以对局部特征进行反映,这点主要得益于EMD 的作用[23]。EMD 可以自适应地进行局部时频分析,有效提取原信号的特征信息,有利于将关注的特征从复杂的混合信号中分离出来。基于以上分析,针对有后处理的音频信号复制粘贴篡改,本文提出了一种基于HHT 的鲁棒的音频复制粘贴篡改的检测方法。
2 基于HHT 的音频复制粘贴篡改的检测算法
本文提出了一种基于HHT 的鲁棒的音频复制粘贴篡改检测方法。其思路是:首先通过对音频信号进行声学活动检测,将音频信号划分为有声段和无声段,然后对有声段部分进行希尔伯特-黄变换,得到希尔伯特谱和每个有声段部分的希尔伯特特征序列,通过分析和对比希尔伯特谱图,并使用相似度算法来计算每2 个有声段部分的相似程度,得到的谱图越相似,DTW 值越小,说明这2 个部分的相似度越高,最后将得到的DTW 值和设定的阈值比较,从而检测和定位音频信号中的复制粘贴篡改。方法的检测流程图如图1 所示。
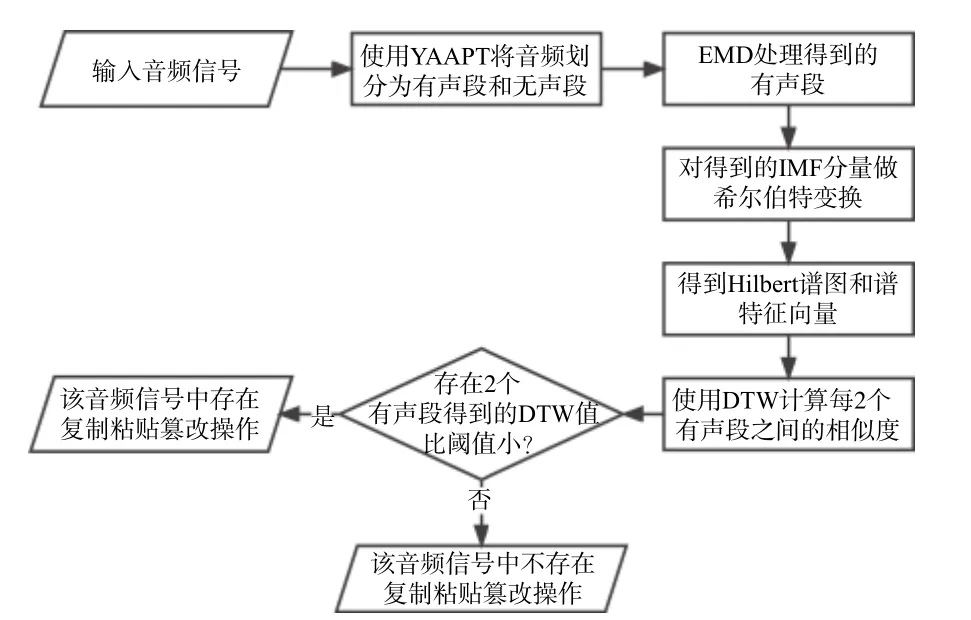
图1 本文方法的检测流程图Fig.1 The detection flow chart of the method in this paper
2.1 声学活动检测
本文采用音高跟踪方法YAAPT 将音频分割为有声段部分和无声段部分。音高是指基频的一种度量。它代表发声时的振动频率,即使一个人把同一个词说2 次,从这2 个词中提取的音高序列也会彼此不同。该方法的主要步骤如下。
步骤1,预处理。使用2 种非线性处理创建信号的多个版本,计算信号的绝对值和平方值,然后利用这2 种经过非线性处理的信号进行基音提取,这样可用于恢复部分丢失的音高。
步骤2,利用谱信息估计音高轨迹。利用谱谐波相关(spectral harmonics corr-elation,SHC)[1]技术估计一个近似的音高轨迹。SHC 定义为
式中:S(t,f)为帧t在f频率处的幅谱;NH为谐波数;WL为谱窗长;SHC(t,f)是将每一帧都归一化为[0,1]。同时计算归一化低频能量比NLFER,用于辅助音高评估和区分有声帧和无音帧。NLFER 定义为
式中:T为总帧数,F0_min和F0_max是音高的范围。
步骤3,候选音高估计。使用归一化互相关函数(NCCF)从时域的原始信号和非线性处理信号中提取候选音高。NCCF 定义为:对于给定一帧采样语音信号s(n),0 ≤n≤N-1,有
式中:N为样本帧长;K_min和K_max是用来适应音高搜索范围的滞后值。
步骤4,动态规划确定最终音高。对步骤2 和步骤3 中的信息进行动态规划,得到最终音高。
由以上步骤得到音高序列后,确定一个音高序列数组索引切换到音频索引的参数(通过大量实验,本文设置该参数为160),进而对得到的音高序列数组进行处理,数组值为零的样本段将被标注为无声段部分,其他样本段被标注为有声段部分。最后,利用确定为有声段部分的音高序列数组下标和之前设定的参数相乘,就能得到音频的有声段部分。
2.2 特征提取
本文使用HHT 将声学活动检测后得到的有声段通过EMD 分解为若干个IMF,进而对每一个满足条件的IMF 分量做希尔伯特变换,得到相应的希尔伯特谱和谱特征序列,最后汇总所有IMF 的希尔伯特谱和谱特征序列,得到音频信号的希尔伯特谱和谱特征序列。以公开的复制-粘贴伪造数据库中经过中值滤波处理的篡改音频“sa1_1-6.wav”为例,提取的希尔伯特谱图如图2 所示。

图2 篡改音频“sa1_1-6.wav”的希尔伯特谱图Fig.2 The Hilbert spectrum of the tampering with audio“sa1_1-6.wav”
2.2.1 经验模态分解(EMD)
对声学活动检测后得到的有声段部分进行经验模态分解。EMD 是依据数据自身的时间尺度特征来进行信号分解,无须预先设定任何基函数,具有自适应性。它依据信号特点自适应地将任意一个复杂的音频信号分解为一列IMF,且IMF 须满足2 个条件:
1)信号极值点的数量和零点数相等或相差为1;
2)信号由极大值定义的上包络和由极小值定义的下包络的局部均值为0。
EMD 的具体步骤如下。
1)找到音频有声段信号x(t)的所有极大值点,通过三次样条函数拟合出极大值包络线emax(t);同理,找到信号x(t)的所有极小值点,通过三次样条函数拟合出信号的极小值包络线emin(x)。所有的极值点必须保证被上部和下部包络线包含。
2)计算上、下包络的平均值m1(t)。
3)将原信号x(t)减去m1(t)就得到一个去掉低频的新信号,判断是否满足IMF 定义的2 个条件,如满足则进行下一步,否则对重复上述2 步骤和操作式(7),直到经过k次之后得到满足IMF 条件,则原信号x(t)的一阶IMF 分量为c1(t)。
4)用原信号x(t)减去c1(t)得到一个去掉高频成分的新信号r1(t)。
进而将r1(t)当成新的原始信号,重复上述操作,得到第2 个IMF 分量c2(t)以及r2(t),如此反复进行。
5)直到rn(t)为单调信号或者只存在一个极值点,EMD 分解过程停止。最后,原始信号x(t)经EMD 分解,可以表示为
2.2.2 希尔伯特变换和谱特征提取
对得到的IMF 分量做希尔伯特变换,对于IMF 信号ci(t)做希尔伯特变换得到信号H[ci(t)],为
以ci(t)为实部,H[ci(t)]为虚部,构造解析信号yi(t),为
于是,得到瞬时幅值ai(t)和瞬时相位φi(t),为
对瞬时相位求导可以求出瞬时频率ωi(t),为
与傅里叶变换不同,得到的瞬时频率ωi(t)和瞬时幅值ai(t)是代表时间的函数,从而以此为基础构建特征序列。
在信号分析中,除了频率分布外,能量分布也具有重要的分类价值,瞬时能量Ei为
最后,取信号x(t)的前5 阶IMF,即在式(15)和式(16)中取i=1,···,5 构建特征序列F,为
2.3 相似度计算
使用动态时间规整(DTW)算法来计算得到的不同希尔伯特特征序列的相似度。DTW 值计算如下:假设给定2 个序列X和Y,长度分别为m和n,其中
则这2 个序列的DTW 距离为D(M,N),用动态方法计算为
式中:D(i,j)是xi和yj之间的DTW 距离;d(xi,yj)为xi和yj之间的距离,且
在本文中,X和Y为提取的2 个有声段的希尔伯特特征序列,得到的DTW 值代表这2 个有声段的相似程度。
2.4 篡改检测和定位
经过以上步骤后,得到每2 个有声段对应的DTW 值,进而由每个DTW 值对应的有声段索引能够得到其在声学活动检测中每个有声段部分的音频索引,每个有声段部分的起始索引和结束索引对应着其在音频中的具体位置。因此,将得到的DTW 值和设定好的阈值比较,如果存在一组有声段的DTW 值小于设定的阈值,那么这一组有声段将被认为是一组复制粘贴的片段,且由DTW 值对应的有声段索引可以得到复制粘贴片段在音频中具体的位置,从而检测和定位音频信号中的复制粘贴篡改操作。
3 实验结果与分析
3.1 复制-粘贴伪造数据库
复制-粘贴伪造数据库[10]是利用TIMIT 数据库生成的。TIMIT 数据库是由2 s 到6 s 不等的英文音频组成,通过随机复制一段语音片段,并将复制的语音片段粘贴到同一段语音的其他位置,从而形成一个伪造的音频文件。此外,为了模拟真实的复制粘贴伪造场景,该数据库还对伪造音频实行了一些常见的后处理操作。例如:对每个伪造音频分别添加30 dB 和20 dB 的高斯白噪声;对每个伪造音频都用中值滤波器进行处理;伪造的音频被压缩成2 种不同的比特率,即32 kb/s 和64 kb/s。本文从中随机选取了3 条语音未经处理过的伪造语音和对应5 种后处理操作下的15 条语音进行实验。
3.2 实验衡量指标
为了评估所提出方法的性能,本文使用精度和召回率来检测伪造音频和定位伪造音频中重复段方法的性能。
精度(Precision)的定义为
召回率(Recall)的定义为
式中:TP 表示被正确检测为重复语音段的重复语音段数;FP 表示被检测为重复语音段的非伪造语音段的数量;FN 表示被检测为非伪造语音段的重复语音段的数量。
3.3 实验分析和比较
3.3.1 一个检测实例
以公开的复制-粘贴伪造数据库中的篡改音频“sa1_1-6.wav”为例。首先,经过声学活动检测后,音频被分为7 个有声段,再经过上述步骤,最终得到每2 个有声段对应的DTW 值,如表1 所示。如果存在2 个有声段的DTW 值小于设定的阈值(通过大量的实验,本文设定阈值为0.08),那么这2 个片段将被认为是一组复制粘贴的片段,且由DTW值对应的有声段索引可以确定对应复制粘贴片段在音频中的具体位置,从而检测和定位音频信号中的复制-粘贴片段。
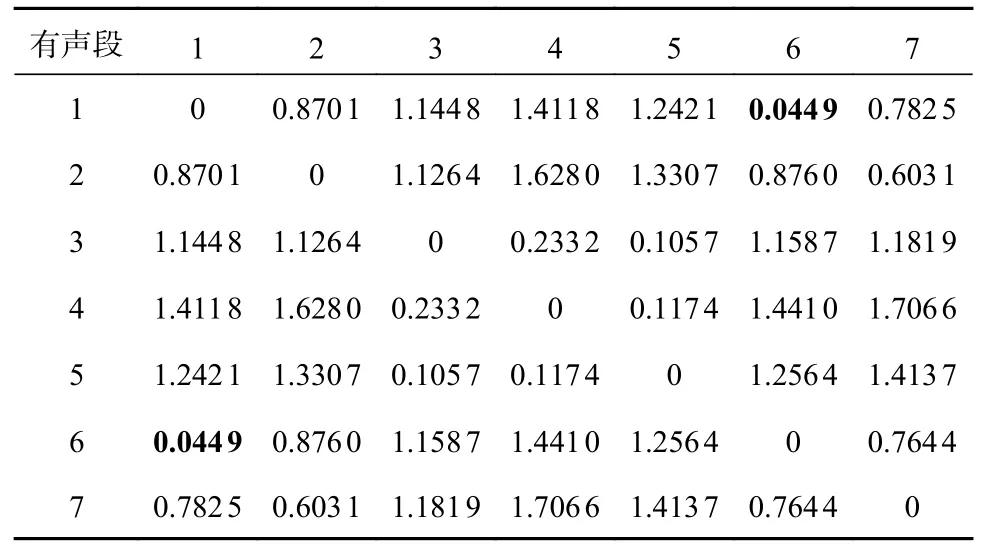
表1 篡改音频“sa1_1-6.wav”每个有声段之间的DTW 值Tab.1 Tampering with the DTW values between each audible segment of the audio "sa1_1-6.wav"
从表1 可知,第1 个有声段和第6 个有声段之间的DTW 值明显小于设定的阈值,从而定位到第1 个有声段和第6 个有声段是一组复制粘贴篡改的片段。
3.3.2 阈值的选择
一个合适的阈值对于判断语音片段是否为重复片段是极其重要的。如果阈值太小,则可能会导致检测精度降低;如果阈值太大,则会导致高误检率。因此,本文进行以下实验来选择合适的阈值。
首先,从TIMIT 数据库中提取了300 个不同的单词,复制这些单词得到了300 对重复片段。然后从TIMIT 数据库中提取300 个不同的单词(和之前的300 个完全不同),并对其采用5 种后处理操作:分别添加20 dB 和30 dB 高斯白噪声、中值滤波、MP3 压缩(32 kb/s,64 kb/s)。最后,得到了1 800 对重复片段,1 800 对非伪造片段。从这些片段中提取希尔伯特特征序列并计算它们的DTW值,得到的结果如表2 所示。

表2 DTW 值的统计结果Tab.2 Statistical results of DTW
由表2 可以看出,94.21%的重复语音片段的DTW 值小于0.08,而只有7.79%的非伪造语音片段的DTW 值小于0.08。由图3 分析可知,当DTW值在0 到0.08 之间时,对于重复语音片段和非伪造语音片段的区分效果相对较好,因此,选择0.08作为本文方法的阈值。如果2 个语音段的DTW值小于0.08,则认为这2 个语音片段为重复的语音片段。如果2 个语音段的DTW 值大于0.08,则认为这2 个语音片段是非伪造语音片段。
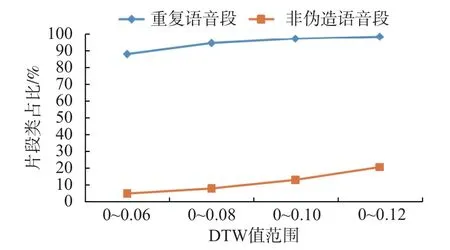
图3 阈值分析Fig.3 Analysis of thresholds
3.3.3 与其他检测方法的比较
在公开的音频复制-粘贴伪造数据库上将本文方法和文献[6]的基于梅尔谱图的音频信号复制粘贴篡改检测方法相比较。表3 为本文方法和文献[6]方法在该数据库中的检测效果。可以看出,本文方法在不加后处理操作和加各种后处理操作情况下的检测效果都高于文献[6]的方法。在不进行后处理操作的情况下,本文方法检测精度为96.45%,召回率为98.21%。当对复制粘贴篡改后的音频使用后处理操作时,本文方法在鲁棒性方面表现优异。当检测添加20 dB 高斯白噪声的篡改音频时,检测精度为91.66%,召回率为92.68%。当检测添加30 dB 高斯白噪声的篡改音频时,检测精度为93.22%,召回率为95.57%。当检测添加中值滤波的篡改音频时,通过本文算法提取的有声段的希尔伯特特征序列变化较大,从而使得DTW 值变化较大,进而导致设置的阈值对重复语音段和非伪造语音段的区分出现误差,使本文方法的检测效果略微下降,检测精度为82.87%,召回率为83.12%。当检测添加MP3 压缩(32 kb/s)的篡改音频时,检测精度为93.46%,召回率为94.54%,当检测添加MP3 压缩(64 kb/s)的篡改音频时,检测精度为94.62%,召回率为96.78%,可以看出MP3 压缩对本文方法的检测性能影响不大。
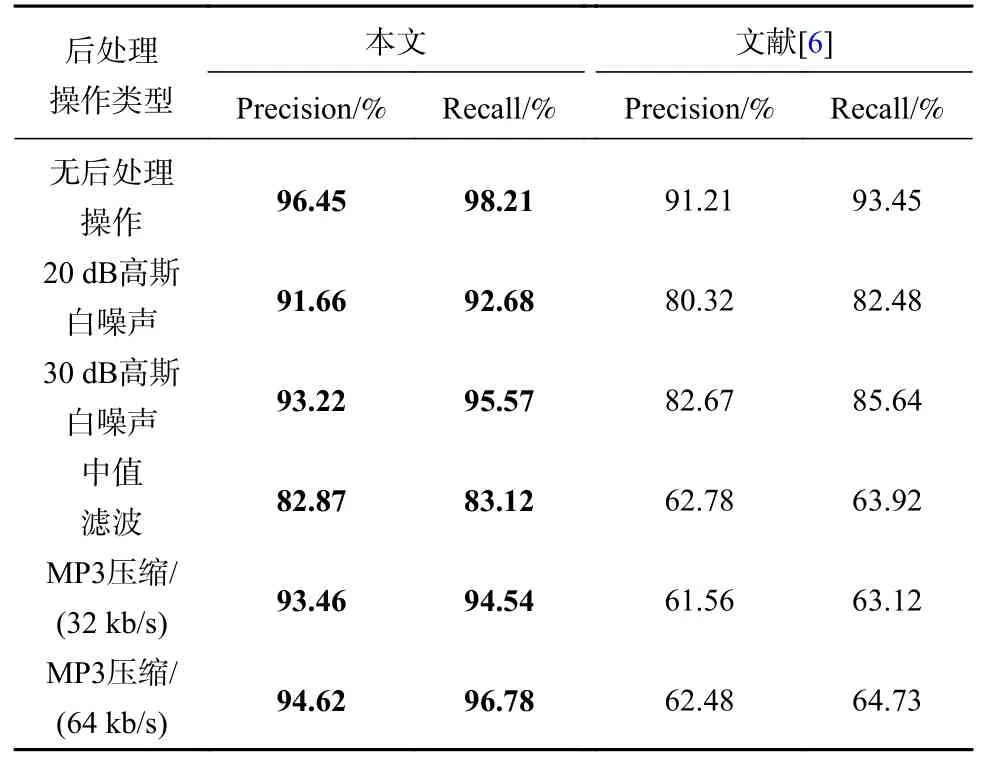
表3 本文方法和文献[6]方法的检测效果Tab.3 The detection effect of the method in this paper and the method in the literature [6]
4 结论
本文提出了一种基于希尔伯特-黄变换的音频复制粘贴篡改检测算法,首次将希尔伯特-黄特征应用到音频篡改检测中,根据实验结果表明,该特征能准确地提取出各种后处理操作后的音频信息,使检测效果得到了提升。与文献[6]的基于梅尔谱图的音频信号复制粘贴篡改检测方法相比,本文方法更贴近实际情况,而且鲁棒性更好,检测效果也更高。
猜你喜欢
逻辑学研究(2021年3期)2021-09-29
乐府新声(2021年1期)2021-05-21
智族GQ(2020年7期)2020-08-20
计算机与网络(2019年3期)2019-09-10
计算机应用(2018年8期)2018-10-16
乐府新声(2017年1期)2017-05-17
学与玩(2017年5期)2017-02-16
发明与创新(2016年6期)2016-04-17
电测与仪表(2016年7期)2016-04-12
中国惯性技术学报(2015年1期)2015-12-19
