
基于提示方法与知识蒸馏方法的口语语音识别模型构建
2023-11-22 05:54彭太乐
西华大学学报(自然科学版) 2023年6期
郭 嘉,彭太乐
(淮北师范大学计算机科学与技术学院,安徽 淮北 235065)
通过大量数据预训练的语音模型[1]在各种语音处理下游任务[2-5]中展现出卓越的性能。预训练模型通过学习语音特征表示,在处理各种下游任务时能够保持较高的准确度。尽管这些模型的表现出色,但是在应用于下游任务时需要引入额外参数并使用任务特定的目标函数对预训练的模型[6-7]进行微调。这导致随着下游任务数量的增加,需要投入大量的人力和物力资源[8]。为了解决这一问题,本文提出一种新的范式,以实现高效且高精度地将语音模型应用于下游任务。提示方法[9-11]的兴起提供了另一条可供选择的道路,无须为每一个任务建立独立的下游模型。
提示方法最初在自然语言处理领域[12]引起了研究者关注。研究者发现通过大规模预训练的语言模型[13-15]在很多自然语言处理任务上都展现出了小样本学习(few-shot)的能力。具体来说,在模型的嵌入中添加一些有着特定模板的演示和一个新的问题,模型会根据这几个演示来输出新问题的答案。这些演示通常采用文本—提示—答案的形式,这种提示方法可以使预训练模型在不改变模型结构及参数的情况下,同时应用在多个下游任务上,并且拥有不错的精度。对于每个下游任务,提示方法只需要找到特定于这个任务的模板或有限数量的参数。这些模板或参数可以帮助模型在不做出改变的情况下为任务生成需要的结果。后续的研究[16-18]表明,这些提示甚至可以是人类无法理解的表达形式,如向量表示。研究者提出了在模型的嵌入中使用连续提示的提示调整方法[16-18]。这种提示方法可以将大多数自然语言处理任务重新定义为生成问题,具有相当高的准确度,并且还可以进一步提升。
目前提示方法已广泛应用于文本、图像、语音等多个领域[19-23],并取得了显著的成果。尽管提示方法在拓展模型应用于下游任务方面提供了便利,但与预训练加微调的方法相比,其准确度仍稍逊一筹。因此,研究者致力于提高提示方法在下游任务上的表现[24-26],使其可以在快速调整模型的同时也可以提供更高的精度。
在语音识别领域,研究者通过语音编码器将语音转换为语言模型可以理解的文本嵌入形式,实现了小样本学习的能力。通过这种方式实现的语音识别模型通常需要由语音模型和语言模型组成。受到知识蒸馏方法[27-31]的启发,本文提出了一种基于提示方法与知识蒸馏方法的语音识别模型(SpokenPrompt-KD 模型)。SpokenPrompt-KD 模型由语音模型Wav2Vec2.0 和语言模型GPT-2 组成,通过将训练有素的教师语言模型的知识传递给学生语音模型,改善了学生语音模型的预测性能,从而提高整体模型的性能。通过知识蒸馏,教师模型的丰富知识可以传递给学生模型,使学生模型能够受益于教师模型的经验和泛化能力,从而提高模型的精度。这种知识传递的过程可以弥补语音资源匮乏的问题,从而提高模型在资源受限情况下的性能表现。本文通过最小化文本和语音特征之间的差异来完成知识的传递。具体而言,本文选择通过缩小语言模型和语音模型输出之间的逻辑距离来提取语言模型的知识[32]。为了减少文本和语音两种模式之间固有的差异,本文采用了可学习的线性层、最近邻插值和收缩机制等方法。这些技术手段能够更好地实现语音模型知识的提取,从而在训练过程中增强整体模型的性能表现。
本文对SpokenPrompt-KD 模型进行了语音分类任务的评估,以证明这种小样本学习能力的模型在语音识别领域的有效性。此外,通过进行对比实验,进一步证明知识蒸馏方法对于模型的积极作用。特别是在资源受限的情况下,知识蒸馏方法的优势更加明显,能够显著提升模型的性能。
1 基于提示方法与知识蒸馏方法的口语语音识别模型
1.1 模型结构
如图1 所示,SpokenPrompt-KD 模型由一个语音编码器和一个自回归的语言模型组成。语音编码器负责将输入的语音转换为语言模型可以理解的文本嵌入形式。语音编码器(speech encoder)fsm使用的模型是基于Transformer 架构的Wav2-Vec2.0[33-34],它用于将输入的语音信号转换为连续的语音嵌入。语言模型是使用GPT-2 模型作为基础模型。它包含文本编码器(text encoder)和基于Transformer 的神经网络(language model)fgpt2。该模型通过利用之前的单词信息来预测下一个单词,这种逐词预测的方式被称为自回归。语音编码器fsm将语音wav 编码为连续语音嵌入w=[w1,w2,···,wm]=fsm(wav)。语言模型中的文本编码器负责将文本s=[s1,s2,···,sk]转换为文本嵌入序列,神经网络fgpt2对于文本分布p(s)的建模为
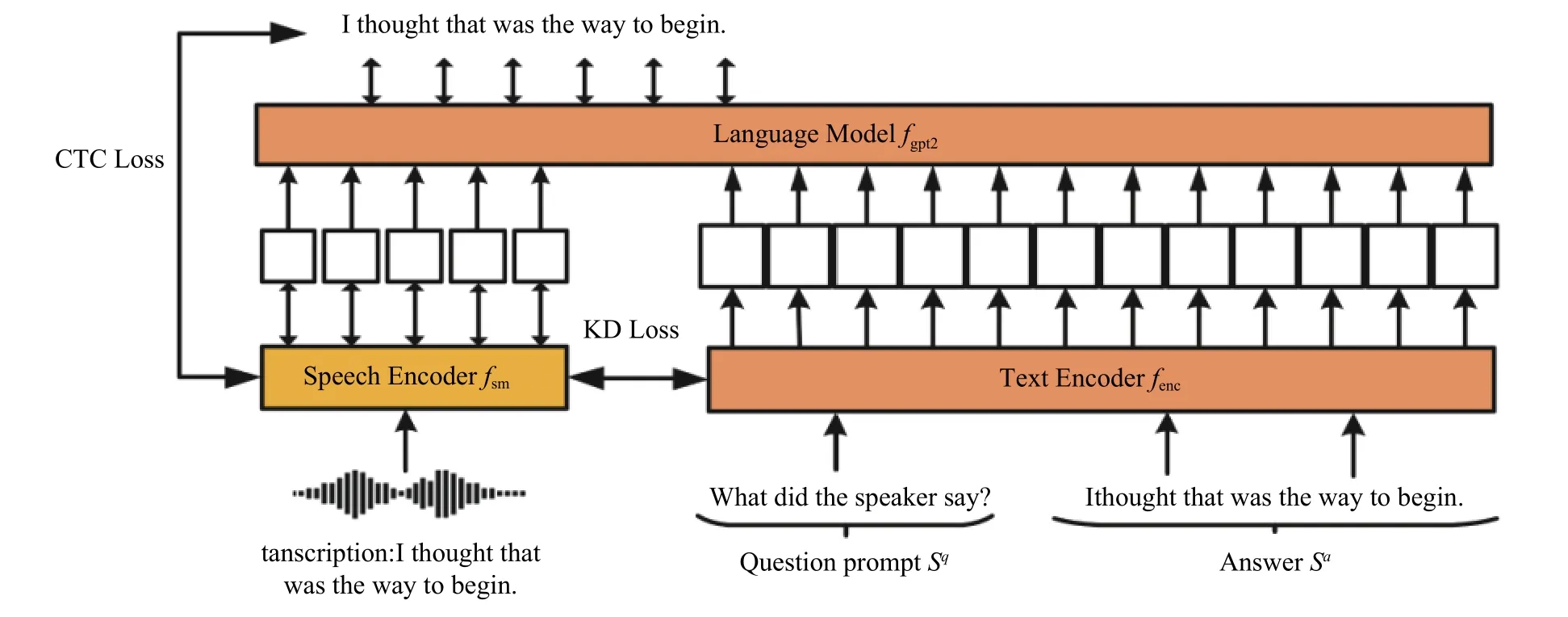
图1 SpokenPrompt-KD 预训练界面Fig.1 SpokenPrompt-KD pre-training interface
即自回归语言模型fgpt2进行预测时,基于已经生成的文本嵌入t1,···,ti-1,输出下一个单词ti的概率分布p。
1.2 语音识别预训练与评估
本文使用LibriSpeech ASR 语料库[35]进行SpokenPrompt-KD 模型的预训练。LibriSpeech ASR语料库是一个包含公共领域有声书的大规模英语语音数据集,共包含约1 000 h 的语音数据。选择100hour-train-clean 的训练集进行预训练,并从中随机采样10 h 和5 h 的数据集,以模拟低资源条件。在预训练期间,使用已经训练好的GPT-2 模型作为语言模型,并将其参数固定,不进行反向传播,只更新语音编码器Wav2Vec2.0 的参数。图1 展示了SpokenPrompt-KD 模型的预训练界面,其中双向箭头表示梯度的反向传播方向。模型同时使用了CTC 损失和知识蒸馏损失来进行预训练。在预训练过程中,模型输入的形式是文本—提示—答案。使用的问题提示是“what did the speaker say?”(演讲者说了什么?)。预训练中,首先将问题提示Sq通过文本嵌入器转换为文本嵌入序列,然后将语音输入wav 通过语音编码器fsm转换为连续语音嵌入w,最后将w与tq进行简单拼接后作为最终的输入,传入到语言模型fgpt2进行预训练。语言模型基于语音wav 和问题提示Sq得到问题答案Sa的概率建模为
即语言模型在接收原始语音wav 以及问题提示Sq后输出答案Sa的概率分布。其中w=[w1,w2,···,wm]为原始语音wav 解码后的连续语音嵌入,tq为问题提示Sq的文本嵌入序列,是自回归语言模型训练过程中已经生成的部分答案,作为生成下一个答案的前提条件。它与w和tq进行拼接,然后作为输入传递给模型。
本文在小样本二进制分类任务上来评估SpokenPrompt-KD 模型。在评估期间,模型不会更新其参数,同时给模型提供一个提示序列。这个提示序列包含了0~9 个不同的任务演示,然后将演示中使用的提示模板作为提示序列的结尾。图2展示了评估期间的推理界面。如图2 所示,任务演示由语音和文本组成,并采用特定的提示模板。语音和文本分别通过语音编码器和文本编码器进行编码,再进行简单的拼接,以生成任务演示嵌入。最后,在需要进行分类的语音演示末端留有一个输出答案标签的位置,用于生成最终的分类结果。SpokenPrompt-KD 模型会根据输入的内容来填补空白,从而将分类任务转化为生成任务。实验输出的答案是预先设置好的标签,这些标签的数量在0 到9 之间。
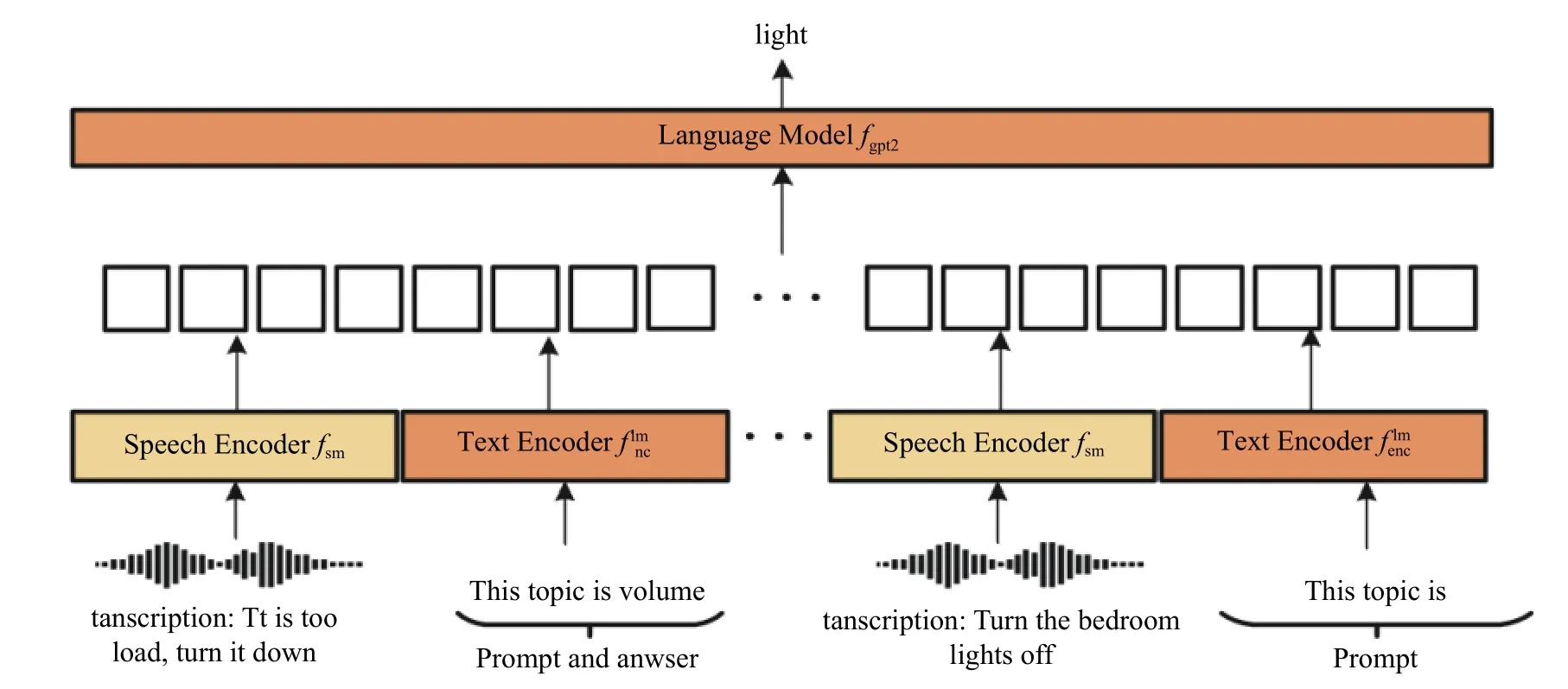
图2 SpokenPrompt-KD 推理界面Fig.2 SpokenPrompt-KD inference interface
1.3 获得CTC 损失
CTC(connectionist temporal classification)是文本和语音识别等领域常用的算法之一,用来解决输入和输出序列长度不同无法对齐的问题。本文使用pytorch 中封装的ctc_loss 接口来计算CTC 损失。首先将原始语音wav 通过语音编码器fsm进行处理,以获取包含序列级时间信息的隐藏层状态(hidden state)fi,j,同时提供对应的真实文本text 作为参考,从而计算CTC 损失。
1.4 获得知识蒸馏损失(KD Loss)
知识蒸馏方法旨在通过减小语音特征和文本特征之间的差异来实现知识的传递。本文通过时间和特征维度对齐语音和文本的隐藏层输出,并利用均方误差损失(MSE)来度量对齐后的语音和文本特征之间的差异,从而缩短两者之间的距离,以实现知识的传递目标。
1.4.1 语音特征提取
原始语音wav 通过语音编码器fsm产生隐藏层序列fi,j。本文将fi,j的特征维度通过一个可学习的线性层linear1改变为语言模型标记器的词汇大小,获得最终的语音特征的序列级隐藏状态Hwav。
其中linear1与式(3)中的linear1相同,由一个形状为的权重和形状为的偏差组成。
1.4.2 文本特征提取
式中:Dt是文本通过语言模型标记器标记后的长度;是语言模型文本编码器最后一层隐藏层输出的特征维度。
1.4.3 对齐语音特征和文本特征
为了计算知识蒸馏损失,需要对齐语音编码器输出Hwav和语言模型输出Htext的时间维度和特征维度。
1)时间维度对齐。
语音和文本之间存在固有差异,导致它们在时间维度上的对齐一直是一个挑战。模型使用CTC 损失函数训练时会产生稀疏预测,语音特征中会含有许多“ϵ”特征,也称为空白标记。而被标记的文本T被输入到语言模型时并不会产生“ϵ”的文本特征。为了解决这个问题,本文使用对齐语音和文本特征[37-38]时常用的收缩机制(shrink)[39],删除语音特征中的“ϵ”,并在相邻且相同的预测之间使用它们的平均值进行替代。语音特征Hwav通过shrink 方法在时间维度上进行收缩后得到语音特征。
由于文本标记器的词汇表通常很大,所以标记后的文本在时间维度上通常比提取的语音特征的时间维度小(即)。为了解决这个问题,本文采用常用于图像处理的最近邻插值方法(interpolate)来拓展文本特征的时间维度。这种方法通过多次复制特征来增加文本特征的时间维度。通过扩展文本特征的时间维度,确保了文本特征Htext与缩小时间维度后的语音特征具有相同的时间维度。
至此,通过收缩机制和最近邻插值方法,成功地使语音和文本特征具有了相同的时间维度。
2)特征维度对齐。
至此,语音特征和文本特征在时间和特征维度都实现了对齐。
1.4.4 知识蒸馏损失
2 实验
为了评估知识蒸馏对提示方法的影响,训练了2 个版本的模型:一个是没有使用知识蒸馏方法的SpokenPrompt-KD 模型,称为基准模型(base 模型);另一个是SpokenPrompt-KD 模型。本文使用2 种经过简单处理的数据集(Flickr8k 音频字幕语料库(Flickr8k)[40]、流利的语音命令语料库(Fluent)[41])来评估。
2.1 数据库
本文在使用Flickr8k 和Fluent 时,针对不同数据库的特点采取了不同的提示策略,并对数据库的标签进行了适当的修改。
Flickr8k 音频字幕语料库是Flickr 8k 的拓展,它包含了8 000 张自然图像的 40 000 条语音字幕。本文丢弃图像部分,只使用语音数据以及其对应的文本翻译,从中随机抽取2 000 条字幕,并为其分配man-woman、male-female、black-white、darklight 这4 个标签。对于颜色标签,问题提示使用了“The speaker is describing a person in”。对于性别标签,问题提示使用了“The speaker is describing a”。
Fluent 数据集包含与智能设备交互的语音命令,例如“播放歌曲”“增加音量”,每个命令都标有动作、对象和位置。本文将涉及语言操作的标签统一改为“语言”,而不是使用数据集原本的具体语言作为标签。其他标签与数据集的标签保持一致。在训练过程中,本文使用“the topic is”作为问题提示。
2.2 实验细节
在SpokenPrompt-KD 模型中,使用fairseq 的Wav2Vec2.0 作为语音编码器,并使用Huggingface实现的具有1.17 亿个参数的GPT-2 模型作为语言模型。在预训练阶段,本文使用了5、10 和100 h 的Librispeech 数据对SpokenPrompt-KD 模型进行训练,并与base 模型进行对比实验。
base 模型与本文提出的SpokenPrompt-KD 模型具有相同的模型结构以及训练细节,唯一区别在于它没有使用知识蒸馏方法来提高语音识别的性能,即在模型预训练过程中不使用知识蒸馏损失函数(kd_loss)。为了验证知识蒸馏对基于提示方法的语音识别模型的影响,本文从不同的训练资源环境和不同的验证数据集角度对SpokenPrompt-KD 模型和base 模型进行对比。
在评估过程中,本文从测试集中随机抽取几个样本及其正确的标签作为提示。经过预处理后,将这些提示与需要进行推理的语音和一个新的问题提示简单拼接,并传入语言模型进行推断。本文从测试集的其余部分中抽取300 个样本和它们的答案标签作为一个评估批次。由于是随机抽取样本,某些类别的样本数量可能会远多于其他类别。为了平衡评估批次中每个类别标签的样本数量,删除具有过多样本的类别中的样本。在进行提示模型时,本文使用的提示是转录的文本嵌入而不是语音嵌入。为了增强实验的可靠性,每次评估时都使用了随机种子的方法进行5 次采样,报告的分类精度是这5 个结果的平均值。
2.3 实验结果
表1 展示了SpokenPrompt-KD 模型和base 模型分别在不同规模语音资源预训练之后在2 个语音理解任务上的表现。

表1 语音识别任务结果准确率Tab.1 results of speech recognition task
本文使用在所有提示数量上获得的最佳精度来表示模型在单个标签对上的性能,以此来排除提示数量对模型小样本学习能力的影响。同时将数据集所有标签对的准确率求平均后作为最终的结果。本文在3 种预训练资源下分别进行了3 个语音理解任务。实验结果表示,SpokenPrompt-KD 模型和base 模型均在语音理解任务中表现出显著高于偶然成功率(50%概率)的准确性,这进一步验证了提示方法在语音识别领域是有效的。同时,在相同的前提条件下,SpokenPrompt-KD 模型在语音理解任务中的精度相比base 模型都有所提升。在10 h的预训练资源下,知识蒸馏对模型的语音识别精度提升最为显著,SpokenPrompt-KD 模型的语音分类精度相比base 模型最高提升了2.8%。在5 h 和100 h 数据集预训练的情况下,SpokenPrompt-KD模型相比base 模型语音识别的精度最高,分别提高了0.8%和1.9%。这进一步验证了知识蒸馏方法对基于提示方法的语音识别模型的积极作用。而且随着预训练时使用数据集规模的增加,模型语音识别的性能也会更高。推测使用更大的语言模型和更大的数据集进行预训练可能会使模型能够拥有更高的精度。
本文还通过对比试验研究了知识蒸馏方法在不同提示数量上对模型的影响。对于同一个数据集,将所有标签的同一提示数量的精度取平均作为评估标准。图3 示出了100 h 的LibriSpeech 数据集预训练下的SpokenPrompt-KD 模型和base 模型在2 个不同数据集上使用不同提示数量时的分类精度(误差在±1 之间)。经过多次实验,发现增加提示数量并不一定带来性能的提升,甚至在某些情况下可能导致性能下降。虽然SpokenPrompt-KD模型在模型评估综合性能时要优于base 模型,但在使用相同提示数量比较时,并不是所有情况下都优于后者。在提示数量≥4 时,SpokenPrompt-KD模型的性能优于base 模型,在提示数量较少时其性能比后者要略低。总体来说,在多数的情况下SpokenPrompt-KD 模型的性能是更加优越的。
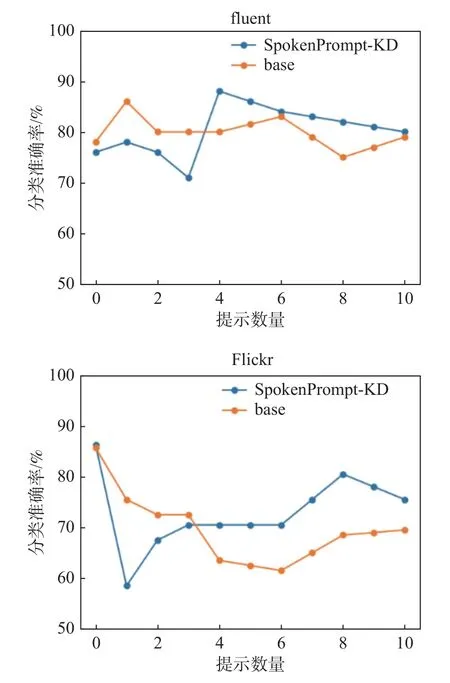
图3 不同提示数量的准确率Fig.3 Accuracy at different numbers of prompts
3 结论
本文构建了一个基于提示方法和知识蒸馏方法的口语语音识别模型(SpokenPrompt-KD 模型),并通过实验证明了自然语言处理领域的小样本学习能力可以扩展到语音识别领域。通过对比实验,发现知识蒸馏方法的使用对提示方法的应用具有积极的作用,使得模型在低资源情况下仍能表现出良好的性能。这项研究结果为口语语音识别领域的小样本学习提供了新的思路,并为在资源受限的情况下实现高效语音识别提供了有益的参考。
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
车迷(2018年11期)2018-08-30
成都信息工程大学学报(2018年3期)2018-08-29
海峡姐妹(2018年3期)2018-05-09
电子设计工程(2017年20期)2017-02-10
公民与法治(2016年10期)2016-05-17
电子器件(2015年5期)2015-12-29
