
基于异构图嵌入的论文个性化推荐算法
2023-12-24 10:35赵成亮陈远平
数据与计算发展前沿 2023年6期
赵成亮,陈远平
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100049
引 言
快速增长的论文为科研人员带来了更多可参考的科研成果,同时也为快速查找感兴趣的论文造成了一定的困扰。
论文个性化推荐旨在通过技术手段提供查找论文的精度和准确度,减少搜索返回的次数,使研究人员得以从浩如烟海的文献资料中解放出来,并根据不同研究人员的兴趣推荐出不同的结果,使推荐更具个性化。
近年来,越来越多的研究使用基于图的方法进行论文推荐研究。传统的基于图的方法使用基于随机游走的算法[1-4](如PageRank和RWR)得到网络中节点的收敛的得分。随着深度学习技术的广泛应用,图嵌入技术得到了研究人员更多的关注。DeepWalk[5]等模型在节点分类、商品推荐等领域得到了广泛的应用,之后也被应用于论文推荐问题中。
当前基于图嵌入的工作仍存在一些不足,具体包括两方面:(1)缺少异构图嵌入模型:主流的图嵌入模型如DeepWalk 和node2vec 都面向同构图,而基于异构图的方法通常使用元路径的相似性进行推荐,Shi等[6]认为元路径的相似依赖于路径的可达性,在路径稀疏时是不可靠的。(2)面向无查询的研究较少:在综述[7]中调研的62篇论文中,其中50篇论文(81%)都要求用户向系统输入一个查询(关键词、摘要、一篇论文)。
针对上面提到的问题,本文的目的是研究一种异构图嵌入模型,解决面向用户的论文个性化推荐问题(无查询的场景)。根据作者发表的论文对作者的兴趣建模,并推荐他们可能感兴趣的论文。本文的主要贡献如下:
(1)提出了一种新型的异构图嵌入模型,称为BFMR2vec,该模型通过设计的BFMR随机游走获得论文层的关系,同时获得作者层的关系。
(2)提出了一种基于BFMR2vec论文推荐方法,用于解决面向用户的论文个性化推荐问题。
(3)在DBLP 数据集上进行了广泛的实验,实验结果证明了BFMR2vec的有效性。
1 相关工作
论文推荐中的方法可以分为四类:基于内容的(content-based),基于协同过滤的(collaborative filtering based),基于图的(graph-based)和混合方法(hybrid)。
基于内容(CB)的方法通常通过用户产生过交互的论文对用户的兴趣进行建模,这里的交互可能是阅读、下载、发表、引用等行为。协同过滤(CF)可分为两类:基于用户的协同过滤和基于物品的协同过滤。Yang 等[8]根据用户阅读图书的记录建立用户与图书的交互矩阵,并计算用户的相似度,使用基于用户的协同过滤产生图书推荐。基于图的方法(GB)可以分为基于随机游走的方法[1-4,9-12]、基于元路径的方法[12-16]和基于embedding的方法。其中,基于随机游走的方法可细分为PageRank、PaperRank 和RWR(Random walk with Restart)。基于embedding 的方法包括DeepWalk[17]、node2vec[18]和Struc2vec[19]等。混合方法即选择上述介绍的算法中的两种或者多种进行组合。方法的组合可以消除单独使用某个方法带来的缺点,例如通过引入CB减轻CF的冷启动问题。
根据图中节点和边的类型数量可以将图分为同构图和异构图。同构图指图中仅包含一种类型的节点,且节点之间的边也仅有一种类型,异构图指图中包含多种类型的节点和多种类型的边。
使用同构图进行论文推荐研究时面向的推荐场景通常较为受限,分为:(1)针对引文网络中一个或几个目标论文节点进行推荐;(2)推荐引文网络中较为重要的节点,即“权威论文”。Gori等[2]针对某个特定的主题构建论文数据集,假定这些论文是某个作者在进行该主题下论文写作时所引用的参考文献,随机选取一部分论文作为该作者已经引用的论文,使用PaperRank算法计算引文网络中论文的得分,并推荐得分较高的论文。Kong等[19]同时使用论文的文本信息和引文网络进行论文推荐,对于一篇目标论文分别选出网络结构相似的n篇论文和文本相似的m篇论文组成一个子图,之后使用Deep-Walk 算法对子图中的节点进行相似度排序,推荐与目标论文相似的论文。Zhou 等[9]使用贪婪集团扩展算法(Greedy Clique Expansion algorithm)来发现引文社区,使用PaperRank 算法计算社区中文章的分数,将得分较高的论文作为“权威论文”进行推荐。
由于同构图仅包含论文的信息,因此仅使用同构图不能完成针对用户的个性化推荐,使用异构图可以解决上述问题。在进行个性化推荐时通常有两个推荐场景:(1)根据用户输入的查询(关键字、标题、摘要、参考列表等)进行推荐;(2)根据用户发表的论文或引用过的论文进行推荐(无查询)。当前绝大部分的研究都是面向有查询的场景,例如Cai 等[18]使用node2vec 获得不同类型节点的向量表示,并设计了相关性得分函数计算查询(包括文本和当前用户)与论文之间的得分,向用户推荐得分较高的论文。也有部分研究是面向无查询的场景,例如Ma 等[16]使用Doc2vec 获得论文的初始向量表示并用作者发表的论文对作者进行表示,之后使用matepath 来更新他们的向量表示,最后计算作者和文章的相似度进行论文的个性化推荐。
本文主要关注无查询的场景下的论文个性化推荐问题,尝试完全使用图的方式对论文推荐进行研究。与当前把异构图中不同层子图当做同构图,并使用同构图的嵌入算法获取节点向量的方式不同,本文设计的异构图嵌入模型将异构图作为整体进行处理,最终获得论文节点的向量表示,之后使用用户发表的论文对该用户的兴趣进行表示,通过计算用户兴趣与论文的相似度向该用户进行推荐。
2 模型与方法
2.1 异构图的构建
本文首先构建了一个两层的异构图,异构图的结构如图1 所示。异构图包含2 种类型的节点(作者节点和论文节点)和3 种类型的关系(co-work、write和cite)。其中co-work关系使用不带箭头的虚线表示,write 关系使用带箭头的实线表示,cite关系使用带箭头的虚线表示。

图1 两层异构网络结构Fig.1 The structure of two-layer heterogeneous graph
用G=(Ga,Gp,Rap)表示图,其中Ga表示作者层,Gp表示论文层,Rap表示作者节点与论文节点之间的关系(write)。 作者层表示为Ga=(Va,Ew),其中Va表示作者节点,Ew表示作者节点间的关系(co-work)。论文层表示为Gp=(Vp,Ec),其中Vp表示论文节点,Ec表示论文节点间的关系(cite)。
2.2 BFMR2vec模型
BFMR2vec 可以分为两步:(1)通过BFMR随机游走获得每个论文节点的游走序列;(2)使用Skip-gram得到论文节点的嵌入表示。
BFMR 随机游走策略的设计源于以下几个思想:
(1)论文与其引文有较大相关性;
(2)论文与其任一引文相关性相同;
(3)论文与该论文中其他作者发表的论文具有相关性;
(4)距离起始节点跳数越多的论文与起始节点的相关性越小。
根据思想1 和2 设计了广度优先的游走策略,根据思想3 引入了元路径的机制,思想4 设计了重启机制。根据上述思想,本文设计了BFMR(Breadth First then Metapath with Restart)的游走策略,BFMR随机游走策略为首先广度优先,其次是带重启的元路径游走。一个元路径模式定义为:
其中,Ri表示节点Vi与节点Vi+1之间的关系,这意味着在游走时不是一个完全随机的行为,而是在确定的关系类型上的一个受限的游走,那么第i步的转移概率就可以表示为公式(2)。
对于一个起始节点Pi,首先使用广度优先,将该节点有直接引用关系的论文节点以随机的顺序加入到游走序列中。以图1中的节点P1为例,从节点P1开始产生的路径可能是P1→P4→P3或P1→P3→P4。
接下来是元路径游走。图2 给出了通过APP 路径模式产生的游走序列的示意。从起始节点Pi的作者中随机选择一位Ai,之后从作者Ai发表的论文中随机选择一篇Pk将其加入路径,然后根据论文的引用关系将后续引用链上的论文加入路径中。需要注意的是作者节点只在查找关系时被用到,实际不会将其加入到路径中。后续的实验中共尝试了3 种元路径的路径模式(包括APP、PP 和PAPP),以研究不同的路径模式对推荐结果的影响。

图2 BFMR随机游走序列示意Fig.2 Some example walk sequences of BFMR walk
在元路径游走阶段如果不断地按路径模式游走下去,会导致路径上的点与起始节点Pi的关系越来越小,因此为了更好地表示Pi引入了重启的思想。在元路径游走阶段,每一次游走时有一定的概率1-alpha按照当前的游走模式游走到下一个节点,同时也有一定的概率alpha回到起始节点重新开始游走。
得到图中每个论文节点的游走序列后,使用Skip-gram学习论文节点的嵌入表示。
2.3 面向用户的推荐
通过BFMR2vec得到了论文节点的表示,之后通过作者发表过的论文对该作者的兴趣进行表示,作者兴趣向量通过公式(3)进行计算。其中,n表示作者发表过的论文数量,表示论文i的向量。
之后使用余弦相似度计算作者兴趣向量与论文向量的相似度,按照相似度进行排序,向作者推荐前N篇论文,其中N∈{10,20,30}。
3 实 验
3.1 数据集
本文选择DBLP v13版本[20]的数据集,该版本数据集包含5,354,309 篇论文数据和48,227,950条引用关系。为了对比在不同规模网络上算法的表现,本文构建了两种大小不同的数据集,记为Small 和Big。其中Small 数据集包含18,481篇论文,Big数据集包含161,303篇论文。
之后对数据集进行训练集与测试集的划分,分别记为Train 和Test。测试集论文选择的规则为:(1)测试集中的论文不应该被训练集的论文引用;(2)每个作者被选择作为测试的论文数量应小于等于该作者的论文量的1/5。
之后分别使用Train-Small和Train-Big构建了异构图,图中节点和关系的统计信息如表1所示。

表1 异构图节点和关系个数统计Table 1 Statistics of nodes and relationships in heterogeneous graphs
3.2 基线模型
本文采用DeepWalk 和node2vec 作为基线模型。
(1)DeepWalk:使用深度优先的游走方式获得游走序列。
(2)node2vec:结合了深度优先和广度优先的游走方式获得游走序列,通过参数p和q控制游走策略。本文的参数设置为p=0.25,q=100。
基线模型和本文提出的模型都基于相同的算法思想,即先产生游走序列,再使用Skip-gram算法学习得到嵌入向量,因此为了公平,实验中为他们设置了相同的基础参数,具体的参数设置如表2所示。
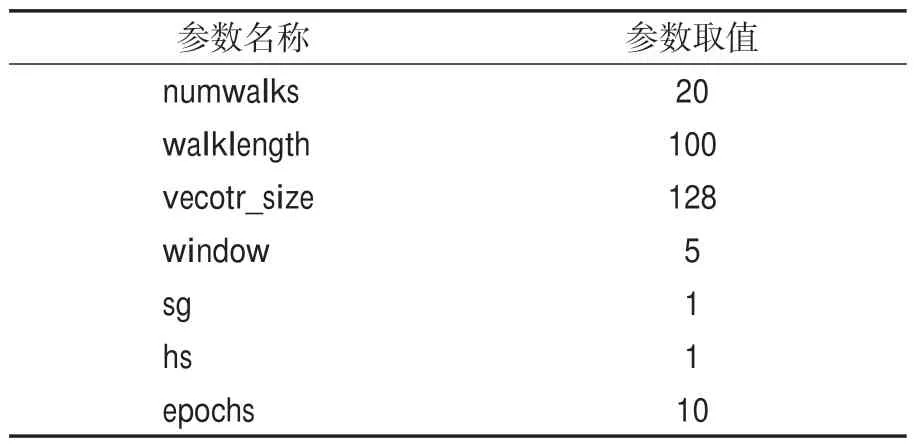
表2 基础参数取值Table 2 The values of basic parameters
3.3 评价方式
如果向某一个作者推荐的论文被该作者引用过,则认为该推荐是有效的。使用作者在测试集中引用的文献列表作为ground-truth。实验使用3 个指标进行评价,分别为Precision@N、Recall@N和F1@N。
其中,Ri表示第i个作者的ground-truth的集合,表示针对第i个作者推荐结果的前N个结果组成的集合,N∈{10,20,30}。
3.4 实验结果及分析
将使用不同路径模式的BFMR2vec 分别记为BFS、BFS-papp、BFS-pp 和BFS-app。其中BFS 表示仅通过宽度优先获取游走序列。为了公平的对比每种方法,为其选择表现最好时的重启概率(alpha)作为实际的取值,最终BFS-pp的alpha=0.4,BFS-papp 的alpha=0.2,BFS-app 的alpha=0.3。
表3展示了在Small数据集上不同算法的对比,表中加粗的数据为当前数据集上最好的结果。其中BFS 相较于DeepWalk 在P@10、R@10和F1@10 上分别提升了33.3%、30%和20.3%,相较于采用偏向BFS 游走策略的方法node2vec在P@10、R@10 和F1@10 上分别提升了9%、9.2%和9.1%。这证明了广度优先的策略在论文推荐问题中是有效的。

表3 Small数据集上的算法对比Table 3 Performance Comparison on Big datasets
观察发现BFS-*的方法相较于BFS 有了一定的提升,证明元路径的引入对模型提供了正面影响。其中BFS-app得到了最优的效果,相比于node2vec,P@10 提升了16.1%,R@10 提升了17.5%,F1@10提升了17%。
表4 展示了在Big 数据集上不同算法的对比,表中加粗的数据为当前数据集上最好的结果。node2vec 算法更加逼近BFS 的结果,通过对路径长度的统计(表5)发现node2vec 的平均路径长度从6.41 增长到了18.93,这为node2vec带来了更丰富的语义信息,使得其更加接近BFS的结果,同时虽然其路径的平均长度比BFS 的平均路径长度大2.88,但其结果仍略低于BFS,证明了广度优先策略在当前问题中的适用性。在Big 数据集上仍然是BFS-app 的表现最好,同node2vec 相比P@10 提升了15.1%,R@10 提升了14.3%,F1@10提升了14.4%。

表4 Big数据集上的算法对比Table 4 Performance Comparison on Big datasets

表5 DeepWalk、node2vec、BFS和BFS-app在两个数据集上的平均路径长度Table 5 The average path length of DeepWalk,node2vec,BFS and BFS-app on two datasets
对比两个数据集上P@10的表现,可以发现Big 数据集上的结果均好于Small 数据集,表明网络规模的增大为图嵌入的表达带来了正向的影响,同时也证明了BFMR2vec模型在不同规模的图中均具有优越性。
4 总结与展望
本文提出了一种新型的异构图嵌入模型BFMR2vec,该模型使用BFMR游走策略获得节点的游走序列,之后使用Skip-gram 获得节点的嵌入表示。基于该模型,本文设计了一种面向用户的论文个性化推荐算法,通过用户发表的论文对用户的兴趣进行表示,并根据用户的兴趣向其推荐可能感兴趣的论文。在DBLP 数据集上的实验证明了本文提出的模型和算法的有效性。
当前的研究仅使用了论文和作者的信息构建了一个两层的异构图,未来考虑加入更多的信息(如期刊信息等)以丰富游走序列的信息。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
浙江大学学报(工学版)(2015年11期)2015-03-01
浙江大学学报(工学版)(2015年5期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
