
基于改进的YOLO v5s算法多尺度包裹检测方法
2024-01-05 05:21高子凡张维忠陈程立诏张宏峰
青岛大学学报(工程技术版) 2023年4期
高子凡, 张维忠,, 陈程立诏, 张宏峰
(1. 青岛大学计算机科学技术学院, 山东 青岛 266071; 2. 中国石油大学(华东), 山东 青岛 266580; 3. 青岛点之云智能科技有限公司, 山东 青岛 266000)
目标检测[1]是通过给定图像自动提取感兴趣区域,对可能包含物体的区域进行检测分类的任务,它是机器视觉领域的核心问题之一[2],广泛应用于人脸支付或实名认证的人脸检测场景,以及大地遥感及军事检测等遥感监测领域[3]。传统目标检测主要通过基于计算机视觉的方法设计手工特征,选定候选区域,对候选区域进行特征提取并分类。但由于目标的形态、光照变化及背景多样性等因素影响,无法手工设计具备鲁棒性的特征结构,特征的提取直接影响分类的准确性。由于传统方法的鲁棒性较差,因此许多研究将卷积神经网络[4](convolutional neural network,CNN)应用到目标检测。R.GIRSHICK等人[5]提出具有CNN特征的区域(RCNN)用于目标检测;K.HE等人[6]提出了空间金字塔池化网络( spatial pyramid pooling networks,SPPNet),使CNN生成固定长度的表示;S. REN等人[7]提出了Faster RCNN检测器,集成目标检测系统于端到端学习框架中。目前,以YOLO为代表的基于回归方法的深度学习目标检测算法,如YOLO、SSD等算法,仅用一个CNN网络预测不同目标的类别与位置,在模型尺寸上占优势。基于以上研究,本文提出基于改进的YOLO v5s算法的多尺度包裹检测方法。采用数据增强策略保证数据均衡,结构上采用空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)模块,有效增加感受野;采用卷积注意力机制模块(convolutional block attention module,CBAM),在大尺度目标分类和检测上改进模型的性能。该模型通过工业扫码设备,实现了对各尺度包裹的识别,使包裹与条形码匹配对应,识别精度和效率均得到提高。
1 基于YOLO v5s的研究方法
本文提出一种改进的YOLO v5s大尺度目标检测模型,对包裹与条形码数据进行采集与处理,并定义包裹和条形码2个类别数据集。该模型针对大尺度包裹,采用ASPP模块,通过不同的空洞率构建不同感受野的卷积核,获取多尺度包裹特征信息。该模型在复杂目标与多尺度目标问题中,通过转换CBAM注意力机制,避免ASPP模块对条形码等小目标的影响。
1.1 YOLO v5s模型
YOLO v5s由主干网络[8](backbone)、颈部网络(neck)及检测头(head)3部分构成。backbone主要通过卷积神经网络对原始图像进行特征提取,供后面网络使用;Neck利用backbone提取不同层级的特征图,生成不同尺度特征并进行融合,提高模型的鲁棒性[9];head利用提取的特征进行分类检测和回归检测,得到模型预测输出结果。
1.2 多尺度模块ASPP
YOLO v5s存在3层检测层,大尺度目标的特征图所包含的语义信息相对较少,由于数据集为复杂环境下所采集的灰度图像,导致大尺度目标的语义信息相对杂乱,易出现大目标错检漏检情况。针对此现象,本文采用空洞空间ASPP模块,充分利用不同尺度特征信息,对原有的特征图以不同的采样率[10]进行空洞卷积采样,以多个尺度捕捉图像中的语义信息,特征图以4个不同的采样率进行空洞卷积,呈指数级增加感受野,不需要改变图像大小。ASPP模块如图1所示。对于所给定的输入,在卷积核中按照rate=1,6,12,18的中间空洞间隙,捕捉多尺度上下文信息,呈指数级增加感受野,精确大尺度目标的定位,但同时也影响到条形码类别,即小尺度目标的识别,因此本文加入CBAM注意力机制。
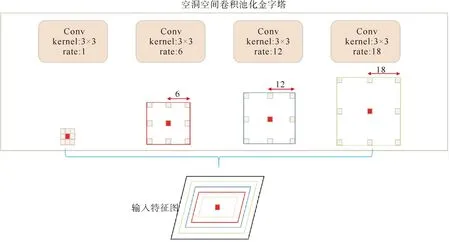
图1 ASPP模块
1.3 CBAM注意力机制
在8倍下采样特征图中,采用卷积注意力机制模块通过通道维度和空间维度[11]依次学习特征,学习后的特征图与输入特征图相乘,进行自适应特征细化,且不增加算法开销,CBAM注意力机制如图2所示。

图2 CBAM注意力机制
在通道维度输入特征图,经过并行的MaxPool层和AvgPool层,得到2个1×1通道权重矩阵,将特征图维度从C×H×W变为C×1×1,经过Shared MLP模块将通道数压缩为原来的1/ r倍,经过ReLU激活函数[12],扩张到原通道数,与原特征图相加,通过sigmoid激活函数得到Channel Attention输出结果,与原图相乘生成中间特征图,通道注意力如图3所示。

图3 通道注意力
通道注意力机制表达为
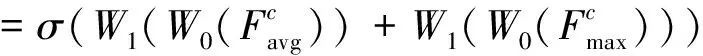
(1)
式中,σ表示sigmoid激活函数;W0∈RC/r×C,W1∈RC×C/r,且MLP的权重W0和W1对于输入是共享的;ReLU激活函数位于W0之后,W1之前。
将中间特征图通过最大池化和平均池化压缩成1×H×W的特征图,经过合并算法对2个特征图进行拼接,经过sigmoid激活函数得到Spatial Attention的特征图,将输出结果与中间特征图相乘,得到最终特征。空间注意力如图4所示。
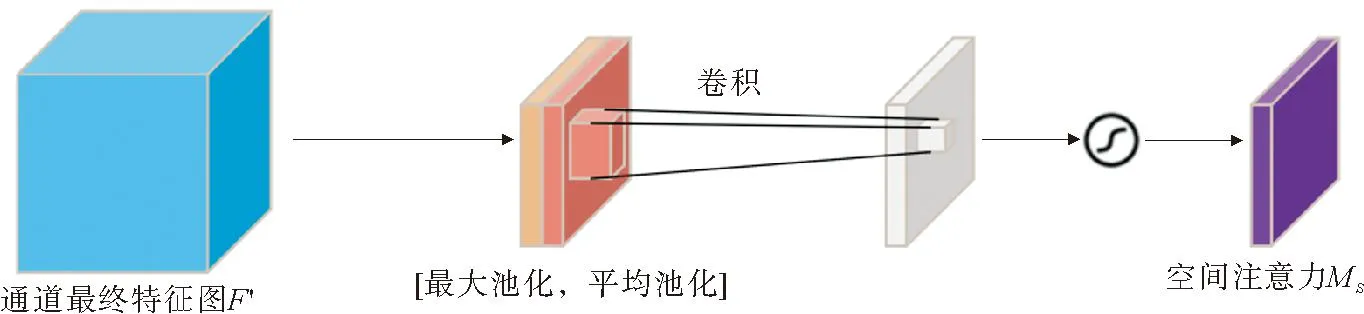
图4 空间注意力
空间注意力机制表达式为
(2)
式中,σ表示sigmoid激活函数;f7×7表示卷积核大小为7×7的卷积过程。
本研究CBAM注意力机制主要针对条形码小目标,在负责检测小目标的8倍下采样的80×80特征图中,加入CBAM注意力模块,屏蔽ASPP模块对小尺度目标产生的负面影响,提高小尺度目标的准确率。
1.4 模型的改进
针对大尺度目标检测,本文提出一种改进的YOLO v5s模型,主干网络中在最大的一层特征图学习时,嵌入卷积注意力机制模块,通过通道和空间2个维度,进行自适应特征细化修正。CBAM是轻量级模块,不增加时间开销的同时,提高小尺度目标检测能力,首先在通道维度平均池化和最大池化,将产生的特征图进行拼接,在拼接后的特征图上,使用卷积操作得到最终的空间注意力特征图;在颈部网络中加入空洞空间卷积池化金字塔模块,融合4个不同尺度的特征语义信息,增加感受野[13],提高大尺度目标的检测能力;目标检测头负责对特征金字塔进行多尺度检测,因条形码均为小尺度目标,而包裹均为大尺度目标,本文使用k-means聚类得到不同尺寸的先验框[14]。在最大的特征图上应用较小的先验框,主要负责条形码的检测,在中等和最小的特征图上应用较大的先验框,主要负责包裹检测。改进后的CA-YOLO v5网络结构如图5所示。
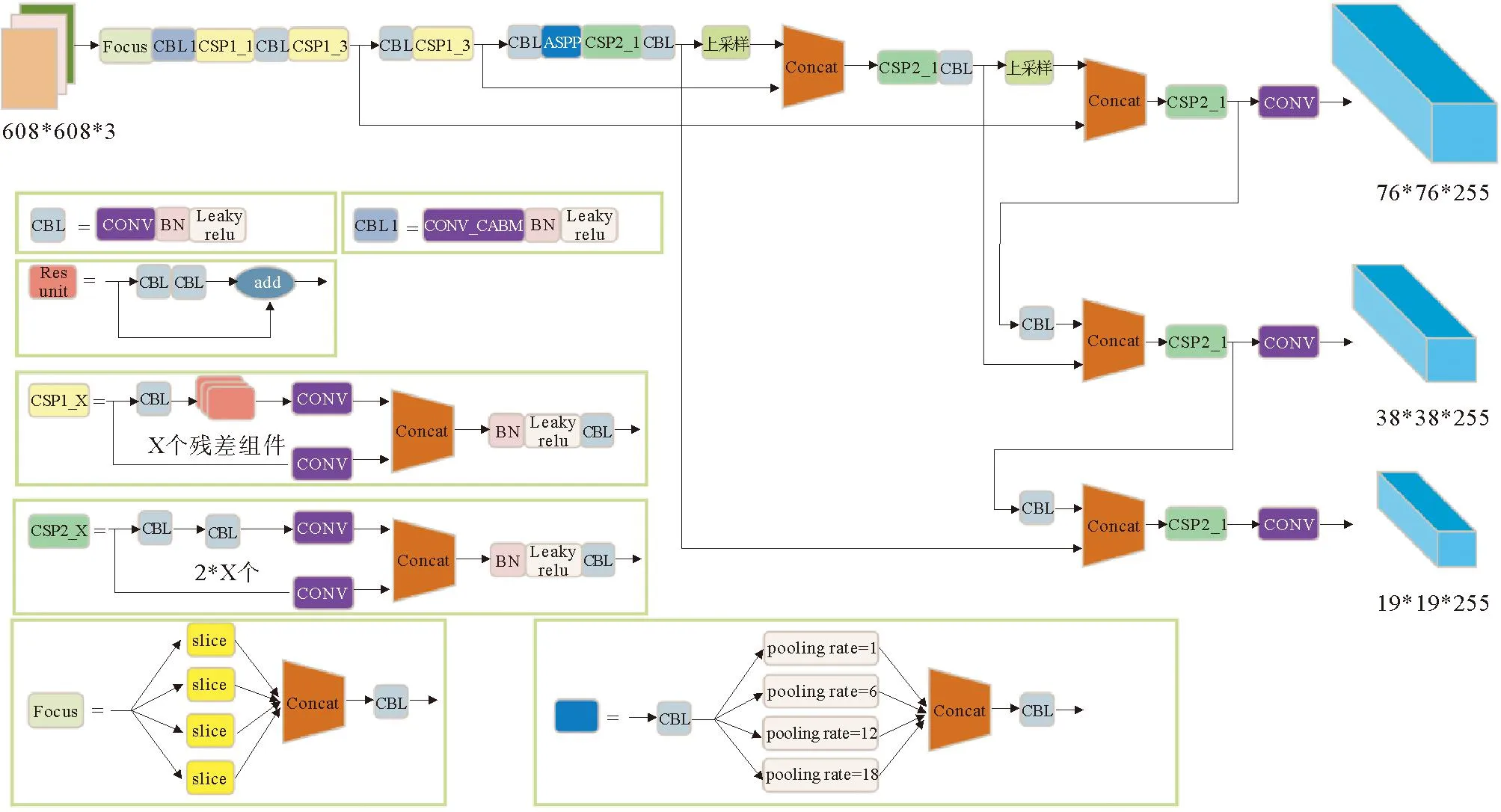
图5 改进后的CA-YOLO v5网络结构
2 实验结果
2.1 实验条件
本文实验由单独计算机完成,数据集格式为jpg图像,计算机配置GPU型号为NVIDIA GeForce GTX 1080 Ti,运行内存32 G,操作系统为64位Windows10,深度学习版本为torch1.8.0、Torchvision0.9.0,Python3.7编程语言,批量尺寸batchsize16,图像输入尺寸为640×640,总训练轮数300,置信度阈值为0.5。
2.2 数据采集
本文采用的数据集在青岛市邮局中心现场获取,数据采集设备使用海康威视的顶扫设备MV-PD01003-22摄像头,分辨率为3 072×2 048,在传送带包裹扫码场景下对包裹和条形码进行识别处理和匹配对应,现场设备配置4个摄像头,视野涵盖传送带的4个区域,本实验主要采用基于设备视角的的四个区域作为实验数据。
采集的数据包含包裹与条形码2个类别,条形码状态单一,包裹却有各种形态,大尺度目标如图6所示。由于扫码摄像头采集的图像像素较大,但视野尺度较小,容易出现大面积大尺度包裹溢满图像的大尺度情况,每一帧数据中的目标尺度越大,检测的准确率越低,且所有采集到的均是灰度图,导致图像特征严重丢失,对大面积包裹的目标检测产生严重影响,大尺度包裹无法识别,增加了模型的检测难度。
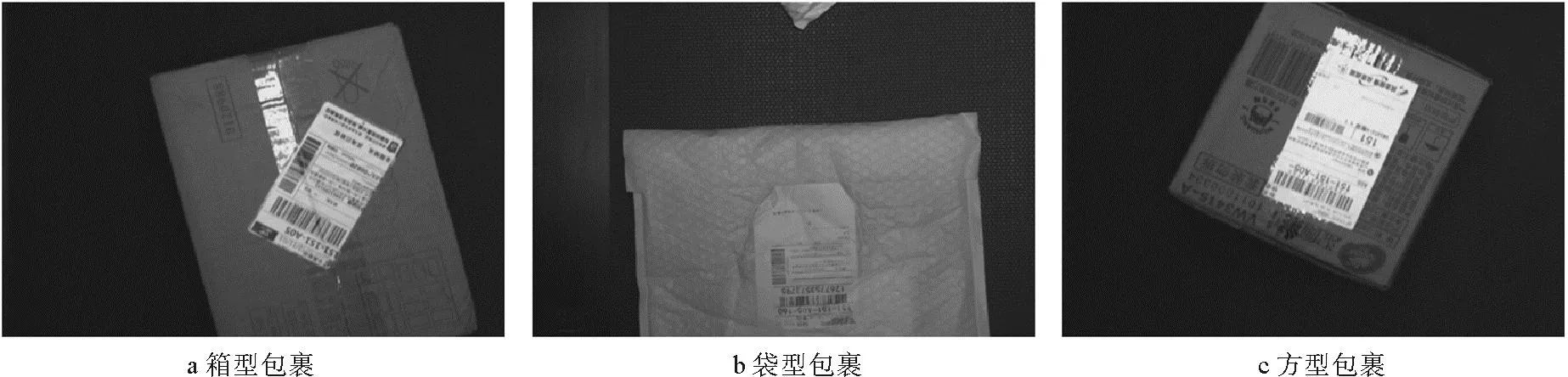
图6 大尺度目标
2.3 数据处理
本文主要针对正对传送带的区域进行实验,由工业生产线的扫码设备取得的JPG格式图像通过筛选形成包裹与条形码图像数据集,将2个类别作为图像数据库,为增加数据多样性,采集原始图像共计8 440幅。为了防止模型出现欠拟合或过拟合现象,随机抽选2 000幅测试集和6 440幅训练和验证样本,为了排除扫码时聚焦、动感模糊及过曝光等情况,利用数据增强技术对样本进行增加噪音、模糊处理及灰度变换,扩充数据量共10 000幅,增加数据多样性和模拟不同识别场景,提高模型泛化能力。通过标注[15]形成TXT格式数据集文件,按比例8∶2划分训练集和验证集,其中包裹的小尺度、大尺度及满尺度数量比例4∶4∶2,条形码类别均为小尺度,测试集1 500幅,训练总共迭代300周期,对不同角度、不同位置及不同尺度的包裹与条形码数据集进行检测。数据增强效果如图7所示。

图7 数据增强效果
2.4 CA-YOLO v5网络的检测结果
本研究基于YOLO v5s网络,采用ASPP模块和CBAM注意力机制进行改进,为证明CA-YOLO v5网络的有效性,对改进前后的目标检测网络进行试验对比分析。在条形码与包裹数据集中,CA-YOLO v5和YOLO v5s网络分别对同一大尺度包裹的图像进行识别,检测结果对比如图8所示。

图8 检测结果对比
由图8可以看出,CA-YOLO v5和YOLO v5s网络都能实现对小尺度包裹与条形码的正确识别,但对于较大尺度包裹,YOLO v5s网络会出现漏检错检,尤其大尺度包裹无法识别,尺度越大,检测效果越差,而CA-YOLO v5网络能够精准识别。
2.5 模型对比
本文提出的CA-YOLO v5网络,在时间开销[16]较少的情况下,各尺度条形码的准确率比YOLO v5s网络有所提高,对于大尺度包裹,改进模型前后对比实验结果如表1所示。

表1 改进模型前后对比实验结果
由表1可以看出,CA-YOLO v5网络的准确率提高了34%,成功解决了大尺度包裹无法识别的问题,模型的综合检测精度提高了17.7%,说明CA-YOLO v5网络模型检测准确性更高。本研究实现了包裹与条形码的匹配对应,有效提高了包裹条形码的检测效率。CA-YOLO v5网络在大尺度黑色包裹的检测中对包裹的检测效果不佳,此类包裹的条形码之外的区域与背景很难区分,在曝光不强时,CA-YOLO v5网络可能识别不到黑色包裹区域,但可以检测到条形码区域。
2.6 不同方法的效果对比
为解决大尺度目标无法识别问题,本研究分别尝试SE、CBAM及CA等注意力机制,或加入新的目标检测层,将不同方法训练后的模型对包裹与条形码进行测试,不同方法的检测结果如表2所示。

表2 不同方法的检测结果
实验结果表明,SE和CA注意力机制都是通道注意力方法,对于单通道数据集改善效果不佳。大尺度目标建立的目标检测层对大尺度目标存在识别效果,但识别效果较差,且对小尺度目标的检测产生了负面影响。
3 结束语
本文通过采用空洞空间卷积池化金字塔结构,呈指数级增加感受野,消除了灰度图像特征少的影响。此外,以卷积注意力机制屏蔽大小尺度之间的特征差异化影响,最终解决了多尺度灰度目标识别问题。为证明本模型的有效性,在自制数据集上进行了验证。试验结果表明,与现存的增加目标检测分类器、基于计算机视觉的目标识别等方法相比,本算法在有效增加有效特征的同时,提高了目标识别准确率,适配于目标尺度差异大、特征少的情况。下一步研究将对模型作改进处理,使网络模型能够识别与背景相似的目标。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
少年文艺·开心阅读作文(2021年8期)2021-09-05
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
小学科学(学生版)(2019年5期)2019-05-21
少儿美术(快乐历史地理)(2019年11期)2019-04-20
小学生导刊(2017年13期)2017-06-15
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
