
改进的Mask R-CNN在车辆实例分割的应用
2024-01-05 05:21徐福良孙传龙
青岛大学学报(工程技术版) 2023年4期
罗 勇, 赵 红, 徐福良, 孙传龙
(青岛大学机电工程学院, 山东 青岛 266071)
近年来,基于深度学习的实例分割方法在研究上取得了巨大突破,其中一个重要应用领域就是无人驾驶汽车系统。快速准确地感知和识别外界环境,更好地识别道路、车辆、行人以及其他障碍物,是实现无人驾驶系统工作的重要前提[1]。图像分割通过对输入图像中不同实例对象的分割和识别,实现无人驾驶汽车对外部环境的快速准确感知[2]。图像实例分割是基于目标检测和语义分割的基础,它不仅具备目标检测的特点,即能够定位图像中的所有实例对象,而且还具备语义分割的特点,即能够对每个像素进行分类。这种综合的分割方法能够更全面地理解图像中的场景,并为无人驾驶汽车提供更精确的环境感知能力[3],避免潜在危险,确保行驶的安全性和稳定性。许多学者研究了图像实例分割在无人驾驶汽车技术中的应用。LIU S等人[4]提出了路径聚合网络(path aggregation network,PAN)方法, 融合高层语义信息和低层位置信息,提升了图像分割任务的性能;由于PA Net的性能会受输入数据的质量和多样性的影响,WANG S等人[5]提出了RDSnet模型,充分利用目标检测和实例分割2个任务的信息交互作用,但其实例掩码的分辨率低,掩码对框和边界框的定位误差很大;Deep mask算法[6]是由Fair团队开发的一种实例分割算法,用于发现和切割单张图像中的物体,但有时在生成实例分割掩码时无法准确地捕捉物体的边界和轮廓,影响了分割的精度和准确性;2019年,BOLYA D等人[7]提出的Yolact模型,在解决同类任务中以速度著称,但计算内存需求较大,资源有限的设备上难以实时应用或部署;CHEN H等人[8]提出的Blend mask模型是近期实例分割任务中较完美的算法,但在某些场景下,该模型对小目标的分割结果不够准确或完整,并且计算复杂程度高、内存占用大。基于此,为了有效利用有限的标注数据提高实例分割算法的准确性,本文通过向Mask R-CNN网络的卷积层添加一种门控注意力机制(gated channel transformation,GCT)方法进行算法改进,并对激活函数ReLU修改为Mish函数,在保证运算速度的同时,提高了图像识别质量和整个网络架构的稳定性。该研究对无人驾驶实例分割算法的发展具有积极意义。
1 Basebone层架构
1.1 经典Mask R-CNN算法Basebone层
经典Mask R-CNN算法的Basebone层采用ResNet-50作为特征提取器提取特征,由“由底至顶”采样层(Bottom-up layers)和“由顶向底”采样层(Top-down layers)2部分组成,通过底层和顶层的特征融合获取更丰富的特征表示,提高目标检测和实例分割的性能[9]。Basebone结构如图1所示。
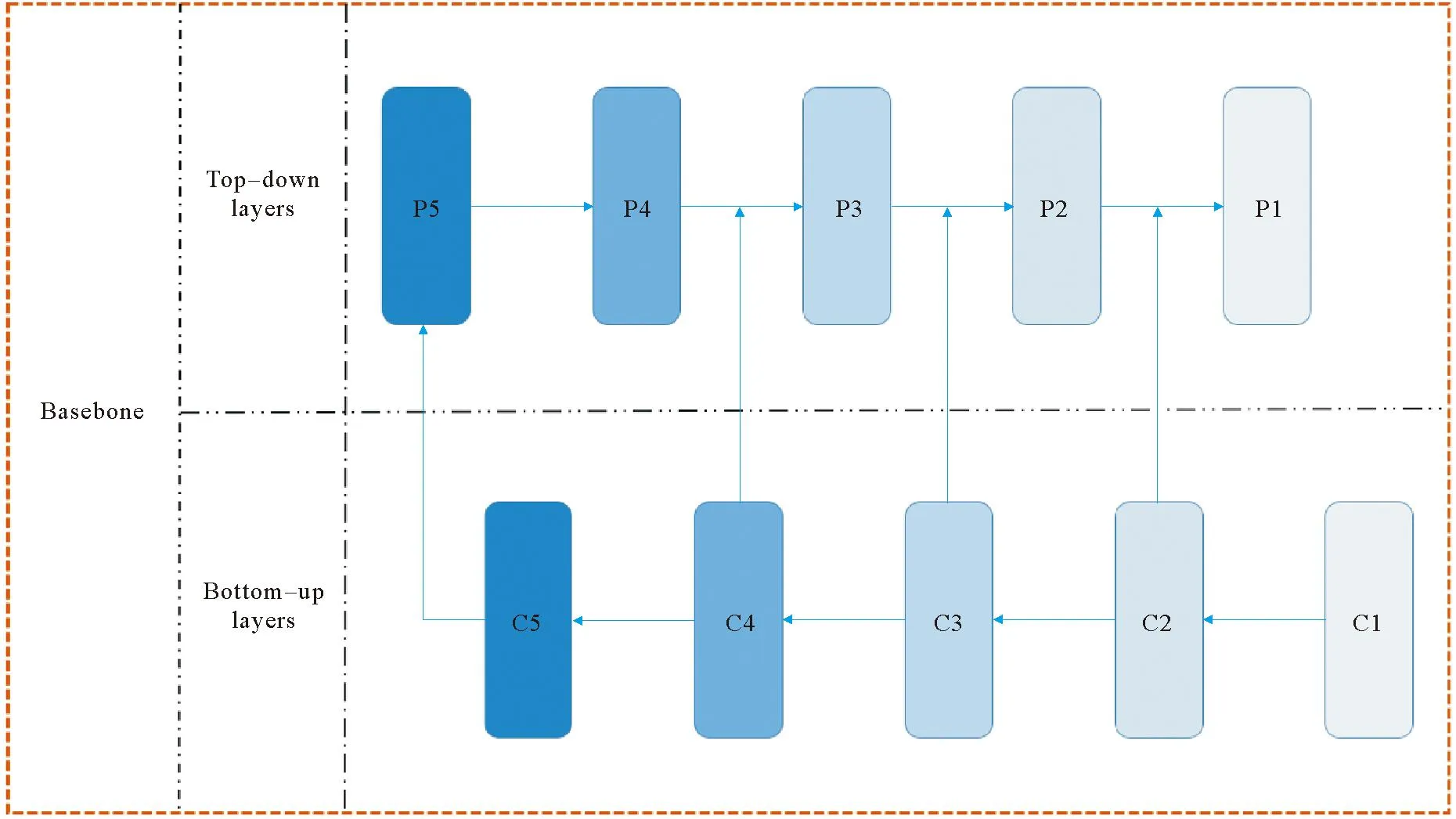
图1 Basebone结构
输入大小为H×W的图像,通过ResNet后,得到五层特征图,尺寸大小依次为
低层特征往往含有较多的细节信息,如颜色、轮廓、纹理等,同时包含许多噪声等无关信息[10],高层特征包含充分的语义信息,如类别和属性等,但空间分辨率却很小,导致高层特征信息丢失较为严重。因此,Mask R-CNN采用特征金字塔网络(feature pyramid network,FPN)结构进行特征提取[11]。图1中C1~C5是底层的特征图,即“由底至顶”采样层的输出,主要捕捉图像的低级和中级特征,如边缘和纹理等。C1是输入图像经过一次卷积操作得到的特征图,C2则是C1经过进一步卷积操作得到的特征图,以此类推得到C5。P1~P5是顶层的特征图,即“由顶向底”采样层的输出,包含了全局的语义信息和局部的细节信息,能够提供更丰富的特征表示。P1是从高级语义特征恢复的细节信息,P2则是进一步上采样得到的特征图,以此类推得到P5。通过C1~C5和P1~P5等特征图的组合和融合,Mask R-CNN的Basebone层能够捕捉到底层的细节特征和顶层的语义信息,提供更全面丰富的特征表示。该设计有助于改善目标检测和实例分割的性能,提高模型的准确度和鲁棒性。
1.2 改进Mask R-CNN算法Basebone层
针对现实中汽车行驶环境复杂多变,基于经典的Mask R-CNN算法架构,增加了对环境信息的分辨能力及算法的识别速度,可对环境精准快速地进行分析,保证自动驾驶的安全。经典的Mask R-CNN算法采取Res-FPN结构,对图像分辨能力效果较好,但细小或遮挡目标的分辨能力受卷积层数的影响[12]。在一定范围内,随着卷积层数的增加,对图像中细小目标的分辨能力增强,但卷积层数不能无限增加。此外,随着卷积层数的增加,算法的单次运行时间也增加。虽然原有Mask R-CNN卷积神经网络结构已满足基本需求,但为进一步提高检测精度,本文在原有神经网络结构的基础上,添加了一种应用在每次进行卷积之前的自适应门控通道注意力机制(gate channels transformation,GCT)[13]。GCT是一种结构简单且易于应用的注意力机制,用于增强神经网络模型的表达能力。它采用规范化方法构建通道之间的竞争或协同关系,更倾向于在浅层阶段促进合作,而在更深层次上加强竞争。一般而言,浅层学习主要用于捕捉低级属性,如纹理等一般特征,而在更深层次上,高级特征更具判别性,并与任务密切相关。此外,GCT的训练参数量较轻量级,因此GCT易于部署且不会占用过多的参数空间,同时也有助于对GCT的竞争或协同等行为进行可视化解释。GCT是一种简单有效的通道间关系建模体系结构,提高了深度卷积网络在视觉识别任务和数据集上的泛化能力,证明了其实用性。GCT结构示意图如图2所示。
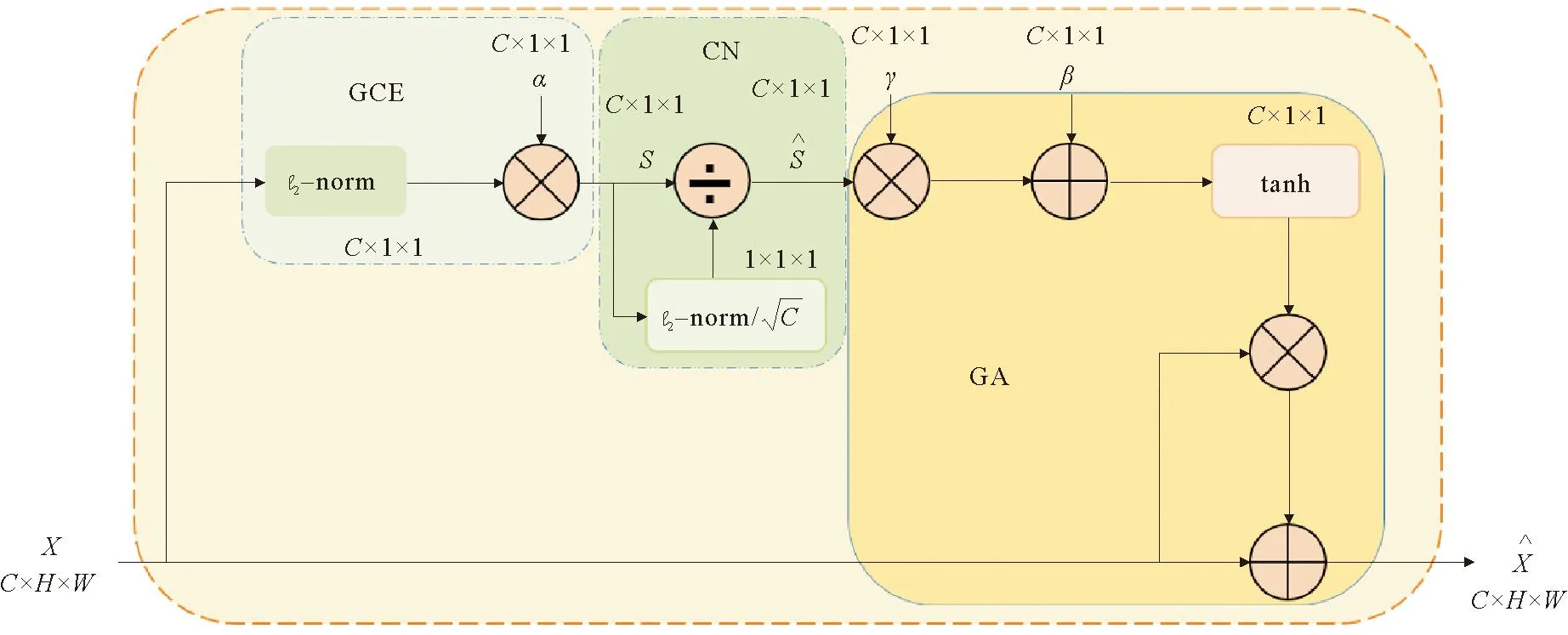
图2 GCT结构示意图
GCT由3个主要部分组成,分别是全局上下文嵌入(global context embedding,GCE)、通道规范化(channel normalization,CN)和门限机制(gating adaptation,GA)。α,β,γ为可训练参数,决定了GCT在每个通道的行为表现。其中,α有助于嵌入输出的自适应性,β和γ用于控制激活门限。
1) 全局上下文嵌入(GCE) 大感受视野有助于避免局部混淆,因此设计了一种全局上下嵌入模块,用于每个通道的全局上下文信息汇聚。给定嵌入参数α=[α1,…,αc],该模块定义为
(1)
其中,l为极小常数。
2) 通道规范化(CN) 规范化通过少量计算资源构建神经元间的竞争关系,类似于LRN。GCT采用进行跨通道特征规范化,即通道规范化。其定义为
(2)
3) 门限机制(GA) GCT在上述基础上添加了门限机制,有助于促进神经元的竞争或协同关系。其定义为
(3)
实验结果表明,将GCT插入到每次卷积操作之前,提高对图像信息的分辨能力。改进后的Basebone层在保证运算速度的同时,增加了对图像中小目标的获取能力,同时,GCT网络的加入提高了系统的鲁棒性。对于Resnet网络来说,增强效果尤其显著。改进后的Basebone 结构如图3所示。
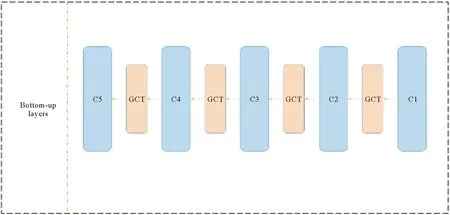
图3 改进后的Basebone 结构
经典的Mask R-CNN网络采用的激活函数是ReLU函数, ReLU函数图像如图4所示。激活函数的主要作用是改变之前数据的线性关系,如果网络中全部是线性变换,则多层网络可通过矩阵变换直接转换成一层神经网络[14]。因此,激活函数使神经网络可学习复杂的数据,表示输入输出之间非线性的复杂的任意函数映射[15]。ReLU函数的数学表达式为
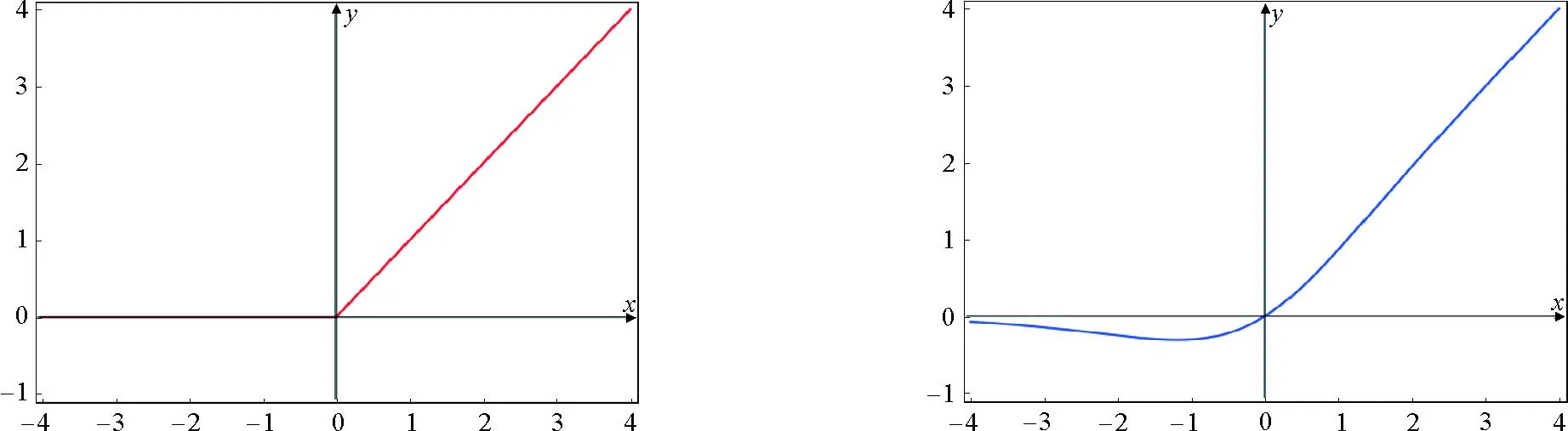
图4 ReLU函数图像
f(x)=max(0,x)
(4)
ReLU激活函数能够加快网络的训练速度,增加网络的非线性能力,此外,ReLU函数计算简单,广泛应用于卷积层和深度学习模型训练。ReLU函数的实现仅需一个max()函数,非常易于使用。另外,ReLU函数能够实现代表性的稀疏性以及线性行为。当神经网络的行为是线性或接近线性时,ReLU函数更容易优化[16]。然而,ReLU函数在输入值为负时,会导致输出为零,并且在零点处不可导。因此,当神经元的第一个输入为负时,可能导致整个神经网络的“死亡”现象。此外,当输入值为负时,所有负值都会被立即置零,从而降低了模型对数据的适应能力和训练能力[17]。也就是任何传递给ReLU激活函数的负输入都会立即将其值置零,由于负值得不到适当地映射,可能会影响结果。
为了增加网络的稳定性,本文将ReLU函数更换为平滑度更好的Mish函数, Mish函数图像如图5所示。
Mish函数的数学表达式为
f(x)=xtanh(softplus(x))=xtanh(ln(1+ex))
(5)
Mish函数使用了tanh和softplus2个函数共同实现函数的门控机制,同时利用了tanh函数的零中心对称的特性,在更多的网络模型和数据集上取得更好的性能[18]。Mish函数在零点处是可微的,且在输入值为负值时也有输出,保证了模型所需的平滑度,提高了系统的稳定性。
2 实验设置和结果分析
2.1 实验数据集
Cityscapes数据集,即城市景观数据集[19],是一个面向大型城市道路场景的常用分割数据集,它通过汽车驾驶视角采集了包含50个不同城市的立体视频图像序列,涵盖了行人、汽车、公交车及信号灯等多个场景类别。该数据集拥有5 000张精细标注的在城市环境中驾驶场景的图像(2 975张训练集,500张验证集,1 525张测试集)以及20 000张粗糙标注图像,具有19个类别的密集像素标注(97%覆盖率),其中,8个具有实例级分割,是目前公认的机器视觉领域内最具权威性和专业性的图像分割数据集之一。
2.2 实验环境及实验设置
本实验均在PyCharm 2021.3.1集成开发环境上进行,硬件平台为window10系统,CPU为i7,GPU为1块16GB的NVIDIA RTX 2070 SUPER。
2.3 评价指标
平均精度(average precision,AP)是一种常用的评估模型性能的指标,用于衡量目标检测和实例分割任务中的准确性[20]。本文采用了不同的AP变体评估模型的实例分割性能,包括AP50、AP75、APs、APm、APl。其中,AP50表示当IOU阈值为0.5时的平均精度,IOU用来衡量预测的边界框与真实边界框之间重叠程度的指标,0.5的阈值意味着预测框与真实框的重叠面积至少为真实框面积的一半;AP75表示当IOU阈值为0.75时的平均精度;APs表示面积较小的目标物体的平均准确率;APm表示面积中等的目标物体平均准确率;APl表示面积较大的目标物体的平均准确率[21]。该评估设置可提供对模型在不同场景和尺度下的表现能力的全面认知,为模型的改进和比较提供有价值的参考。
2.4 结果对比
为验证本文算法的有效性,本人对3种算法的目标检测结果和实例分割结果进行对比。3种算法分别是基准算法的Mask R-CNN原算法(M);Mask R-CNN结合GCT模块后的算法(M-GCT);Mask R-CNN结合GCT模块后并且修改激活函数后的算法(M-Mish-GCT)。3种算法的目标检测结果如表1所示,比较了不同评价指标下的性能表现。3种算法的实例分割结果如表2所示。通过对比表1和表2,可直观地评价3种算法在目标检测和实例分割任务上的表现。

表1 3种算法的目标检测结果

表2 3种算法的实例分割结果
由表1和表2可以看出,经过GCT改进后的Mask R-CNN算法,各项评价指标都有所提升,在实例识别方面表现更出色,证明了GCT在视觉识别任务中的性能提升作用。在网络推理阶段,添加了GCT模块的算法,运行速度为每秒13帧,与原始算法每秒12帧相比,并没有因添加模块而导致算法性能下降,并且文中的实验算法采用Python语言,其运行效率相对较低。但在实际应用中,可通过采用C/C++语言提高程序的执行速度,同时降低内存占用率,提高算法的运行效率。
为了更直观地展示改进后的算法在Cityscapes数据集中的分割效果,节选不同场景下的效果图进行分析。不同场景下3个车辆行驶时的原图与分割效果图对比如图6~图8所示。

图6 场景一
由图6~图8的分割效果图可以看出,改进的算法对不同类别不同个体的分割效果表现优秀,没有发生明显的漏检和错检问题。由图7可以看出,光照条件对无人驾驶识别效果和分割精度存在一定程度的影响。通过3个不同场景下的实验可以得到,改进算法为车辆提供准确有效的外部信息,可对不同物体进行精准分割,有效验证了改进算法的性能和良好的泛化能力。

图7 场景二

图8 场景三
为了对比改进算法与原始算法的分割效果,对同一张图像分别进行不同方法的识别, Mask R-CNN算法分割效果如图9所示。

图9 Mask R-CNN算法分割效果
图9中有2位处于坐立状态的行人、1位骑行者和6辆汽车。经过原Mask R-CNN算法训练识别后,虽然大目标、近处以及无遮挡的目标识别程度不错,但2位行人之间的拐杖也被识别为1位行人,且右侧汽车车窗反光处被认为不是汽车而没有标注出来。
改进的Mask R-CNN算法分割效果如图10所示;测试图像局部对比如图11所示。

图10 改进Mask R-CNN算法分割效果

图11 测试图像局部对比
对比图9~图11可以看出,图中行人之间的拐杖没有被识别成行人,车窗反光处也被纳入汽车的部分,其中车轮处被路灯遮挡部分也未被误判为汽车。结果表明,改进后的算法在目标检测和实例分割方面取得了更优的分割效果。
3 结束语
本文将视觉识别注意力模块嵌入到Mask R-CNN网络结构,并在Cityscapes数据集上进行验证。实验结果表明,在实例分割任务中,本文的改进算法比原算法识别分辨能力更强,并未降低算法效率,平均准确率提高了约13.9%,有效提高了图像识别质量和整个网络架构的稳定性。下一步的研究重点是将汽车行驶时实际场景中复杂繁多的类别进行有效精准识别,且会考虑光照条件不足或雨雪雾等复杂气象环境下的无人驾驶实例分割。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电视技术(2014年19期)2014-03-11
