
基于机器学习的基数估计技术综述
2024-02-20 08:22岳文静屈稳稳王晓玲
计算机研究与发展 2024年2期
岳文静 屈稳稳 林 宽 王晓玲
1 (华东师范大学计算机科学与技术学院 上海 200062)
2 (华东师范大学上海智能教育研究院 上海 200062)
3 (中国科学院空天信息创新研究院 北京 100190)
(wjyue@stu.ecnu.edu.cn)
基数估计(cardinality estimation)是数据库执行查询优化中的一个重要环节,用于估计在数据库中执行查询后返回的结果数. 理论上,只要提供了准确的基数估计和物理计划执行代价,并可以在巨大搜索空间中有效地枚举计划,数据库就可以在合理的时间内制定出最佳查询计划. 传统的基数估计技术一般采用像直方图等数据结构的统计方法来表示数据表上的数据分布,或者通过采样的方法估计数据的分布. 但实际上,由于复杂谓词和对多个数据表估计等复杂查询的固有难题,以及数据日益增加的复杂性,数据库的查询场景越来越复杂,其对于基数估计技术在处理多列、多谓词查询以及多表连接等情况下的能力要求逐渐增强. 尽管传统的基数估计技术可以在短时间内给出数据集的统计结果,但由于其难以兼顾空间开销与估计准确率、难以处理复杂数据分布等特性,使其在面对复杂困难的查询场景时,基数估计的性能仍有待提升.
近年来,鉴于人工智能技术在复杂的数据处理和模型学习方面的能力,数据库研究人员在基数估计技术中引入了人工智能技术,提出了基于机器学习的基数估计技术. 如何建模查询与基数之间的映射关系,以及如何建模数据、列属性与数据表之间的映射关系是目前研究中关心的2 个核心问题. 在已有的研究中,基于机器学习的基数估计方法一般分为2 类:一类方法为查询驱动的基数估计方法[1-14],此类方法直接建模查询负载和基数之间的关系;另一类方法为数据驱动的基数估计方法[15-21],此类方法通过拟合数据库中的数据联合分布函数来计算基数.
最新的研究[22-25]中对比了传统的基数估计算法和基于机器学习的基数估计算法,展示了基于机器学习的基数估计技术可以很好地提升基数估计的准确性. 但它们也继承了人工智能算法建模的一些不可解释性、鲁棒性差等问题,距离实际落地应用仍有很大的差距.
基数估计技术是查询处理中的核心技术之一,也是学术界一直关注的研究热点. 文献[25]主要介绍了传统的基数估计技术和查询驱动的基数估计技术. 文献[22]详细地介绍了传统的基数估计相关技术,并从是否使用了监督学习技术的角度讨论了基于机器学习的基数估计的相关技术,同时对相关基数估计技术中编码的内容进行了简单说明. 文献[24]侧重于比较在无数据更新和数据频繁更新的查询场景下,传统的基数估计技术与基于机器学习的基数估计技术的性能表现. 同时从技术实际落地角度出发,给出了基于学习的基数估计技术未来的研究方向. 文献[23]为基于学习的基数估计技术探索了统一的设计空间,主要介绍了查询驱动与数据驱动的基数估计技术,同时在准确率和效率2 个方面对相关技术进行了分析比较. 本文在已有综述研究的基础上:1)增加了针对基于机器学习的基数估计特征编码技术的对比、分析和总结;2)基于文献[23]中提供的设计空间,以及对基于机器学习的基数估计相关技术的总结,本文提炼了建模查询驱动和数据驱动2 类不同映射关系的核心工作流程,进一步在传统的SQL 查询和NoSQL 应用中分析了查询驱动、数据驱动的基数估计技术,同时补充了最新的前沿技术. 由于混合模型的基数估计技术的兴起,本文增加了对这类基数估计技术的介绍与分析,从而进一步完善基数估计技术的分类体系.
本文的组织结构包含4 个方面:1)全面阐述数据库中的基数、基数估计以及基于机器学习的基数估计的定义,并分析了其使用的特征编码技术及基数估计技术中的分类体系. 2)根据提炼出的查询驱动的基数估计和数据驱动的基数估计的建模流程,分别介绍了这2 类具有代表性的基于机器学习的基数估计技术,并补充了混合模型的基数估计建模流程以及相关技术. 3)在查询驱动的基数估计技术中整理了其在NoSQL 的应用技术. 4)讨论了基于机器学习的基数估计技术面临的挑战以及未来的研究方向.
1 基数估计定义及分类
1.1 基数估计
给定SQL 查询语句和数据库D,基数(cardinality)是在数据库D中执行查询q返回的结果行数,记为C(q|D)=|D′|,其中D′表示查询结果,而基数估计则表示在不执行查询q的情况下,对基数进行估计[23].Leis 等人[26]证明了代价估计的性能主要与基数估计的精度有关,而代价估计是数据库查询优化中的关键步骤. 因此基数估计对查询优化器产生最优的查询计划至关重要.
1.2 基于机器学习的基数估计
给定SQL 查询q、数据库D,基于机器学习的基数估计是要学习q和基数C之间的一个映射函数[23],或者学习一个拟合数据库中数据分布的函数[23],输入q后函数返回估计的基数,不同的任务使得函数的表现形式不同. 基于机器学习的基数估计技术的目标就是尽可能地使=C.
1.3 特征编码技术
将SQL 语句或者使用的数据表编码为特征向量作为基数估计模型的输入是基于机器学习的基数估计技术的基础. 本文对基于机器学习的基数估计技术中的特征编码技术进行了2 个维度上的分类,一类为特征编码的类型,分为谓词(运算符、查询值与列序号(id)、连接类型、数据库元数据、数据表数据和其他属性的特征. 另一类为特征的编码方式,共分为3类. 其中独热(One-Hot)编码、嵌入(Embedding)编码是最常用的编码方式,其余基于特定查询属性的编码方式归结为其他类型的编码方式. 表1 将已有研究分别对应到特征编码技术的2 个分类中. 下面本文将根据特征编码方式对已有研究中编码的特征类型进一步归纳总结.
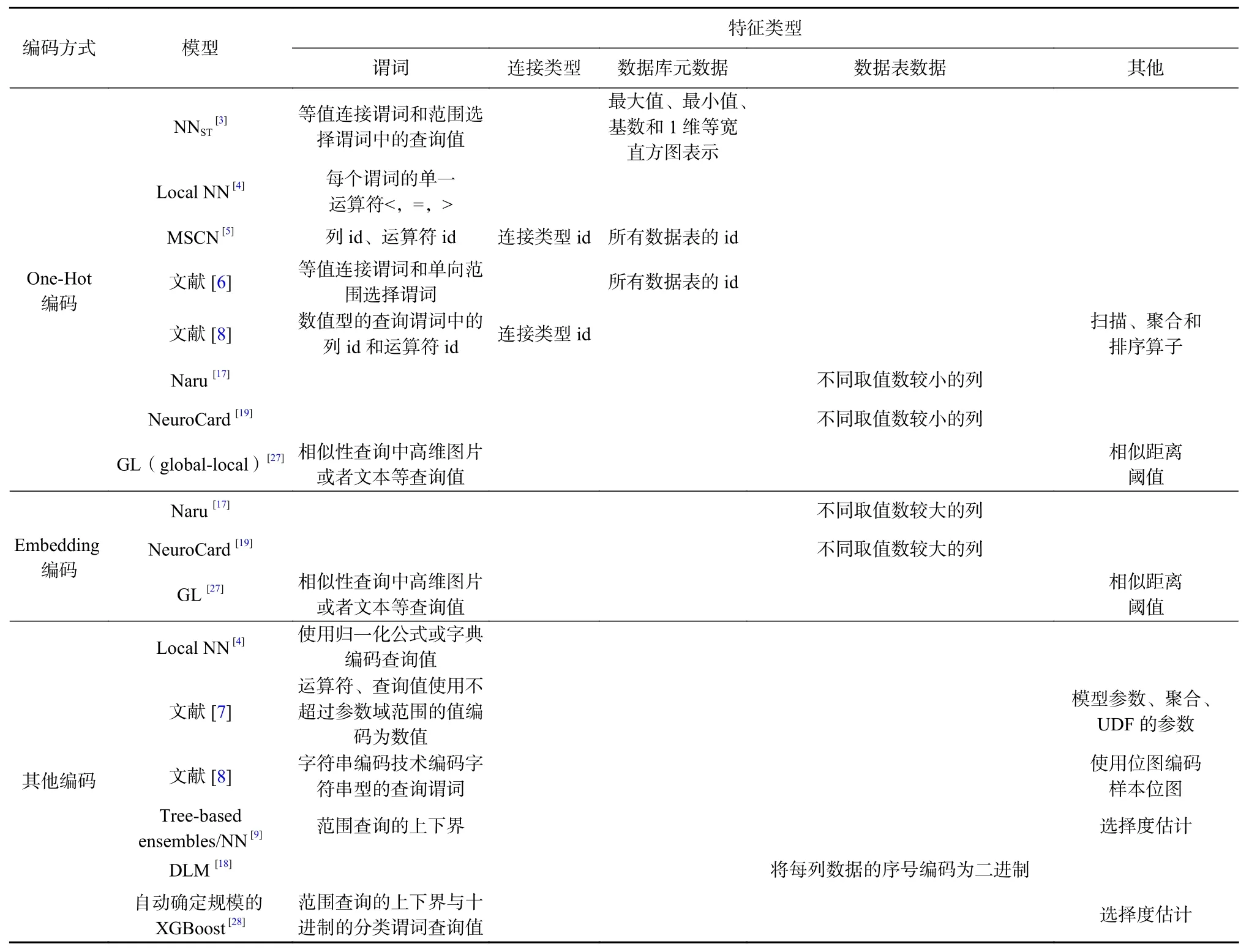
Table 1 Feature Encoding Techniques Based on Machine Learned Cardinality Estimation Techniques表1 基于机器学习的基数估计技术的特征编码技术
1.3.1 One-Hot 编码
One-Hot 编码将查询属性特征转换为同一维度的向量表示,并使用0 或1 表示. 基于神经网络(neural network, NN)的模型NNST[3]使用One-Hot 编码了查询计划,其中将查询计划根据数据库属性信息和单一操作运算符支持的谓词(即支持等值谓词编码,对于1 维范围选择谓词,仅编码了查询值)编码为子查询的特征向量,其中数据库属性信息包括最大值、最小值、基数和1 维等宽直方图表示. 不同的研究对于查询计划的属性特征定义不同,其中模型MSCN[5]编码了查询语句中表的集合、连接的集合和谓词集合的表示,并作为模型的输入. 值得注意的是,谓词集合中仅使用了One-Hot 编码列id 和运算符id,查询值使用的是归一化的数值. 而文献[6]编码了查询语句中的表id、选择谓词以及等值连接谓词,同样使用了归一化的方式将范围选择谓词中的查询值进行编码.该文献中提出的模型支持数据表的等值连接,通过选用不同的编码特征和不同的机器学习模型,使其可以适用于文献[6] 中定义的查询类型. 文献[8]由于同时可以估计查询成本,因此使用了One-Hot 编码物理操作,包括连接类型和3 类算子,同时也对数值型的查询谓词进行了编码.
1.3.2 Embedding 编码
在属性个数较多的情况下使用One-Hot 编码,特征空间维度巨大且编码稀疏,进而计算代价较大. 为了解决One-Hot 编码的缺陷,Embedding 编码将稀疏的查询特征表示变为低维稠密空间的特征表示. 文献[17,19]均编码了数据表中的数据作为模型的输入向量,对于不同取值数较大的列,均使用Embedding编码来将表内数据编码为一个稠密向量,否则使用One-Hot 编码. 模型GL(global-local)[27]将查询、提出的阈值编码为向量,同样使用了One-Hot,Embedding编码等方式将高维图片或者文本等数据编码为数据向量,然后使用神经网络将向量进一步转换为模型输入需要维度的特征向量.
1.3.3 其他编码方式
除了1.3.1 节和1.3.2 节中所述的2 种常见的编码方式之外,一些研究对特定的查询特征属性提出了特定的编码方式. 模型Local NN[4]使用了2 种方式进行编码,该模型使用One-Hot 编码技术编码运算符,对于查询中的值,若其为数值型则使用归一化公式进行编码,否则,使用字典编码将非数值型的值转换为数值型. 文献[7]利用语义模板定义了查询的多种特征,并直接使用特征的变量值作为查询的多维特征向量.其中,多种特征包括查询的属性、运算符、查询数值、模型参数、聚合和用户自定义函数(user-defined function, UDF)的参数等. 文献[8]提出使用字符串编码技术编码字符型的查询谓词,使用位图来编码样本位图,即使用固定大小的向量来判断每位对应的元组是否满足查询节点的谓词. 文献[9]中提出的2 类模型,分别为树模型和NN 模型. 将范围查询中d个数字属性的范围上下界直接拼接为1 个2d的元组作为范围特征. 此外,还将单属性直方图中的信息生成查询的选择度估计作为回归模型的额外特征. 模型DLM[18]将数据表中的一行数据看作一个序列,根据值id 将每个值编码为一个二进制向量. 而文献[28]自动确定规模的极端梯度提升(extreme gradient boosting,XGBoost)模型使用数值转换的方式将查询范围谓词和分类谓词转换为十进制数字作为查询特征,并将计算查询中单表的选择度估计值作为选择度特征.
1.4 基数估计技术分类体系
基数估计技术根据是否使用了机器学习算法分为传统的基数估计技术和基于机器学习的基数估计技术2 类,其分类体系如图1 所示.
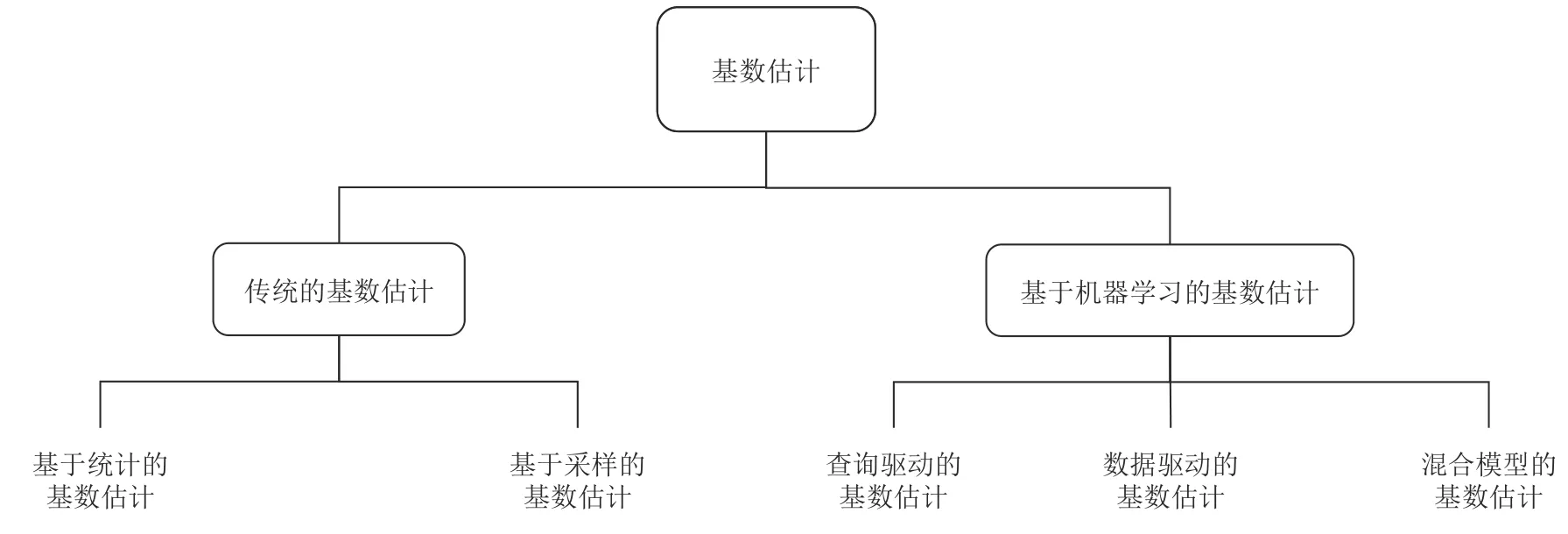
Fig. 1 The classification system of cardinality estimation图1 基数估计分类体系
传统的基数估计技术一般被分为基于统计的和基于采样的方法. 基于统计的方法[29-35]的核心是使用某种数据结构,例如直方图[29-31]、数据画像[32-35]来拟合表上的数据分布,其中,文献[29]采用了直方图来近似数据库中的数据分布,这类基于直方图的统计方法估计精度较高,但是由于其内存占用大,所以检索速度较慢. 该类方法只考虑了拟合单列的数据分布,没有考虑多列属性之间的相关性;文献[32]采用数据画像来估计数据集中不同元素的个数,使用随机哈希函数并基于随机假设,可以将任意数据集映射成服从均匀分布的随机值序列从而进行估计.HyperLogLog[33]基于基数估计器LogLog,使用调和平均数降低了方差. 相比于基于直方图的估计方法,基于数据画像的方法通常探索一个性能良好的哈希函数来拟合数据分布,占用内存较小、检索速度更快.但是这类方法仍旧仅针对单列的数据估计其基数,不适用于现实中复杂的查询应用. 基于采样的方法[36-40]的核心是通过从原始数据集中采样到小数据集来估计数据的整体分布,以反映不同表之间的关联关系. 不同于基于统计的基数估计方法,基于采样的基数估计方法不依赖于特定的假设,通过对不同的表按照一定的采样方式采集元组,并进一步利用这些元组估计基数. 但如何高效地在一个规模较大的数据集上进行采样,当底层数据发生更新后如何进行重采样,如何支持非等值连接仍然是需要解决的问题[22].
由于传统的基数估计技术计算需要存储直方图、位图、采样的元组等信息,会占用较大的存储空间;而基于机器学习的基数估计技术仅需要存储学习映射函数的模型,因此相较于传统基数估计技术,其模型占用空间小. 基于统计的基数估计技术适用于拟合单列的数据分布,而在处理任意多列组合数据之间的复杂关系,其能力较弱. 基于采样的方法可以有效支持小规模数据表的查询. 但随着数据的日益增加,基于采样的基数估计技术在大规模数据表的复杂查询场景中需要消耗大量空间存储采样的元组,同时有效采样元组会随着多表复杂的连接而减少,损失估计的性能. 因此,传统的基数估计技术在处理涉及多列、多谓词的查询,以及多表连接等复杂困难的查询场景时,常会导致较高的预测偏差[23]. 由于机器学习技术可以学习到非线性数据之间的复杂关系,因此基于机器学习的基数估计技术可以更好地表达查询特征以及拟合数据的复杂分布,进而能够支持较为复杂的查询场景.
基于机器学习的基数估计技术由于基数估计精度高、占用空间小、拟合复杂数据关系能力强等特点,受到了研究者们的广泛关注与青睐. 根据已有工作,本文将基于机器学习的基数估计技术在主流数据库中的应用分为3 类,分别为查询驱动的基数估计、数据驱动的基数估计和两者混合模型的基数估计. 此外,查询驱动的基数估计在NoSQL 中也得到了广泛应用.
2 查询驱动的基数估计技术
查询驱动的基数估计技术的核心思路是学习查询q和基数C之间映射的一个回归函数fθ(q,C),其中θ表示模型需要学习的参数. 查询驱动的基数估计技术通常使用不同的编码方式、编码查询负载的不同特征属性,基于不同的监督学习算法模型建模查询、列属性和表三者之间的关系,以支持不同数据量的查询操作. 首先,本文基于已有的查询驱动的基数估计技术,归纳出查询驱动的基数估计的一般性建模流程;然后对不同查询驱动的基数估计相关模型进行了详细的介绍,其中包括了在NoSQL 中的相关研究;最后对相关模型进行了对比和总结.
2.1 查询驱动的基数估计建模流程
查询驱动的基数估计技术的核心思想是建立一个查询驱动的基数估计模型,其一般性的建模流程如图2 所示,分为输入、输出和模型建立3 部分[23-24].

Fig. 2 General modeling flow for query-driven cardinality estimation图2 查询驱动的基数估计的一般性建模流程
1)输入
输入数据集DStrain/test{〈q,C〉}、数据库D以及模型约束参数 ϕ. 例如,对于查询驱动的代表模型MSCN[5],其输入为数据集DStrain/test和数据库D. 其中,给定SQL查询q经过查询解析器后构建出的数据集作为训练数据,同时将q对应的真实基数C作为标签.
2)输出
在数据库D中执行查询q后估计的基数. 在得到估计的基数后,经过基于代价模型的代价估计,使得数据库可以制定查询计划,进而完成查询优化.
3)模型建立
①模型训练. 如图2 中粗实线条箭头所示,模型共包含2 个模块:查询特征编码器和监督学习模型.首先模型使用查询特征编码器,根据不同的任务或者模型需求,将输入的查询q解析为具有固定维度φ的查询特征向量Q、谓词特征等,其中|Q|=φ,查询特征编码器中的编码技术如表1 所示. 将Q与真实基数C构建为输入对〈Q,C〉输入到监督学习模型中进行训练,在训练过程中构造特定的损失函数,不断优化模型的学习参数 θ.
本文以模型MSCN 为例来解释查询驱动的基数估计模型训练的流程. 首先将连接查询q分为3 部分,分别表示查询语句中表的集合、连接的集合和谓词的集合,从而将查询、列属性和表关联起来. 然后将这3 个集合分别输入到3 个2 层的神经网络中得到3个对应的特征向量. 3 个特征向量拼接后得到的查询特征向量与真实的基数一起输入到2 层的多层感知机中,并使用梯度下降算法进行训练.
②模型推理. 如图2 中细实线条箭头所示,基数估计在推理阶段同样需要经过①中的2 个模块. 不同的是,在模型推理阶段,模型参数θ已知,数据库可以直接通过已经训练好的模型估计查询q的基数.
同理以模型MSCN 为例来解释查询驱动的基数估计模型推理的流程. 当输入一个新的查询q后,MSCN 同样将q分为3 部分并利用训练好的3 个神经网络分别编码这3 个部分为特征向量,拼接这3 个特征向量后输入到训练好的多层感知机中得到最终估计的基数.
2.2 查询驱动的基数估计相关模型
在目前的研究[1-9,28]中,许多研究人员根据不同的查询需求和基于不同的监督学习方法建立了不同的基数估计模型. 本文根据监督学习类型将已有研究分为2 类,其中文献[1−6]是基于神经网络算法的基数估计模型,文献[7−9, 28] 是基于树结构的基数估计模型. 其次,本文分析了查询驱动的基数估计在NoSQL[27,41-47]上的应用研究.
2.2.1 基于神经网络算法的基数估计模型
神经网络优秀的大规模数据拟合能力和非线性建模能力可以带来更好的估计精度. 因此,许多研究将神经网络引入到查询回归模型中,用于处理不同类型的查询负载. 在基于神经网络算法的基数估计技术中,Lakshmi 等人[1]将神经网络应用到用户自定义函数的基数估计中,并将反向传播算法应用到基数估计技术. 此研究是将基数估计应用到神经网络的初步探索. 随着深度学习的发展Ortiz 等人[3]提出使用深度强化学习对子查询的属性进行编码,将执行计划转换为强化学习中的动作表示,并使用一个神经网络NNST得到在新动作下新的子查询计划的表示. 同时使用另一个神经网络预测每个状态下子查询的基数,并根据预测的基数利用强化学习优化查询. 2019 年,Ortiz 等人[6]提出使用循环神经网络(recurrent neural network, RNN)模型预测查询的基数,该模型将一个SQL 语句看作一个序列. Ortiz 等人[6]的这2 个研究可以很好地适配不同长度、不同类型的查询操作,但这2 个技术仅专注于解决左深度支持的查询计划,而对于一些其他结构支持的查询计划无法直接适用.
为了解决使用神经网络方法建模整个数据库模式带来的数据稀疏问题,Woltmann 等人[4]使用神经网络为不同且固定的查询连接条件训练了一个局部模型Local NN. 该局部模型的思想使基数估计模型可以更好地表示出数据之间的相关性,然而这种训练方式消耗较大. 不同于该模型, Kipf 等人[5]基于卷积神经网络算法,同时基于采样的思想来学习多表谓词关联性,并为整个查询训练了一个全局模型MSCN用于估计连接查询的基数以减小训练消耗.
2.2.2 基于树结构的基数估计模型
树结构由于其模型参数较小、运行时间快的特点被广泛关注. 为了使模型具有学习能力,同时模型参数或运行时间又不会太大,树结构这种模型结构被应用到基数估计模型中用于增量学习查询负载的特征属性. 在基于树结构的基数估计中,Malik 等人[7]率先提出了一种“黑盒”的方法来估计查询基数,在不了解查询执行基数和数据分布的情况下提供了准确的估计.该黑盒的主要思想是将查询分组到固定的句法组中,并使用基于树状模型等机器学习技术来学习每个句法组的查询结果大小的分布,并编码了查询的属性、运算符、模型参数、聚合和用户自定义函数的参数,该方法显著提高了Open SkyQuery 中的缓存性能.
为了适应不同结构的查询负载,Sun 等人[8]提出了一个基于树结构模型的端到端成本估计学习框架,该框架可以同时估计成本和基数. 该研究提出了有效的特征提取和编码技术. 其中,在特征提取时考虑了查询和物理操作,并将特征嵌入到树结构模型中;在特征编码时提出了一种有效的字符串值编码技术,可以提高谓词匹配的泛化能力. 同时,该研究提出了一种基于模式(pattern)的方法,用于覆盖所有的字符串值并编码其嵌入.
Dutt 及其团队分别于2019 年[9]和2020 年[28]提出了基于XGboost 算法的基数估计模型. 文献[9]为多列范围查询提出了一种轻量级的选择度估计方法,并提出了基于树模型和基于神经网络模型预测的选择度. 该研究首先将范围查询编码为范围特征,并使用启发式的基数估计器为单属性直方图中的信息计算查询的选择度来作为额外特征,并将2 类特征输入到树结构或神经网络结构的回归模型中进行训练.为解决训练集收集耗时长、模型构建时间长和为大型数据集计算选择度标签代价大的问题,从构建训练数据的角度上,文献[28]提出了一个基于霍夫丁(Hoeffding)不等式的生成近似选择度标签策略,用于增量标记数据. 该研究首先随机选择少量的训练数据并标记,然后将查询特征和单表的选择度特征输入到XGBoost 模型中计算查询的选择度,若模型的Q-error 值低于阈值的置信区间,则模型停止训练.此研究在使用回归模型预测查询基数的同时自动确定了训练数据规模大小.
2.2.3 NoSQL 中查询驱动的基数估计模型
以上的研究聚焦于传统的SQL 查询语句,模型适用于低维数据的处理,但对于NoSQL 中高维的图片、文本数据以及复杂的SPARQL 查询,以上模型不能直接适用. Sun 等人[27]将SQL 查询对象扩展到了图片、文本等更高维的数据,基于神经网络算法并结合全局和局部模型的思想,针对高维数据的相似性查询和连接任务设计了一个基数估计模型GL,用于平衡模型数量和模型参数规模. 该模型提出了查询分割和数据分割2 个策略,尽管仅使用了简单的神经网络模型进行特征编码和基数估计,但其效果显著. 该模型有效解决了神经网络方法中的数据饥饿问题,提高了高维数据在相似性查询和连接操作中的准确率. 虽然此模型相对于以往基于神经网络的模型,模型规模和参数量下降,但该模型的训练和预训练的时间仍然较长.
此外,传统SQL 查询的基数估计模型同样不能直接适用于语义网底层数据模型资源描述框架的查询语言SPARQL. 基于此挑战,Hasan[41]提出了利用机器学习技术预测 SPARQL 查询的执行时间. 该工作采用支持向量回归模型作为基数估计模型,并使用图编辑距离(graph edit distance,GED)方法提取SPARQL查询辅助的特征属性. 但是,当训练数据集很大的前提下,GED 的计算非常耗时,且系统规模较大.
针对这一问题,Zhang 等人[42]首先定义了SPARQL的代数特征和基本图模型2 类特征,该特征分别代表了查询算子的出现次数、层次信息和查询子集,并从现有的基准查询模板中挑选出具有代表性的模板,将每个模板生成的查询作为目标查询.然后根据图映射的方式建模查询和目标查询的基本图模型,并通过计算两者之间的GED 来减少计算量. 此外,该研究使用增量学习的方式进行特征选择,并验证了k近邻算法相比于支持向量回归算法更适合作为SPARQL 基数估计的模型. 虽然该研究在减少计算量上做了一些改进,但固定特征数量会损失一定的估计准确性.
由于SPARQL 中的三元组之间存在许多(自)连接,因此SPARQL 查询估计不应该基于连接一致性假设[43-44]. 为了遵循这个规则,同时适用于SPARQL查询中的多种类型的查询模式[45-46],例如星形或链式查询模式,Davitkova 等人[47]提出了一个用于资源描述框架(resource description framework,RDF)图中基数估计的学习模型框架LMKG. 具体来说,模型LMKG提出了一个子图编码方式SG-Encoding,该编码方式实现了在稠密空间中表示各种子图模式,从而可以适用各种查询模式. 同时,LMKG 提供了一种无监督的自回归模型和一个基于深度神经网络的监督模型来进行基数估计,以适应不同的查询输入. 该研究通过学习子图模型之间的相关性而不是三元组之间的相关性,打破了连接一致性假设,同时该技术通过采样的方法来生成训练数据,缓解了处理大量数据耗时长的问题.
2.3 小 结
本文首先给出了查询驱动的基数估计的一般性建模路线,详细分析了查询驱动的基数估计技术中相关的模型,这些模型使用了不同的编码方式,将查询负载编码为不同的特征,从而建立查询与数据库中列属性和表之间的联系,以支持不同的查询操作.同时,这些模型基于不同的监督学习方法,建立了查询及其基数之间的映射. 此外,在包括高维图像、文本和复杂的SPARQL 三元组的NoSQL 查询中,查询驱动的基数估计模型也得到了很好的应用. 本文对比了2 类查询驱动的基数估计中的代表模型[3,5,9,28],以及NoSQL 代表模型[27,47],如表2 所示. 基于神经网络的基数估计技术相较于基于树结构的基数估计技术,由于神经网络优越的数据拟合能力,其估计准确性较高,但模型参数较大,导致运行时间较长. 基于树结构的基数估计技术由于使用了增量学习,其模型参数相对较少,但以损失精度为代价. 从表2 中可以看到,查询驱动的基数估计模型的核心在于编码查询的特征是什么及使用哪种回归模型建模. 查询驱动的基数估计方法在准确度上取得了良好的效果,使用查询特征编码器容易建模表之间、列之间的关系,并支持多表连接估计.
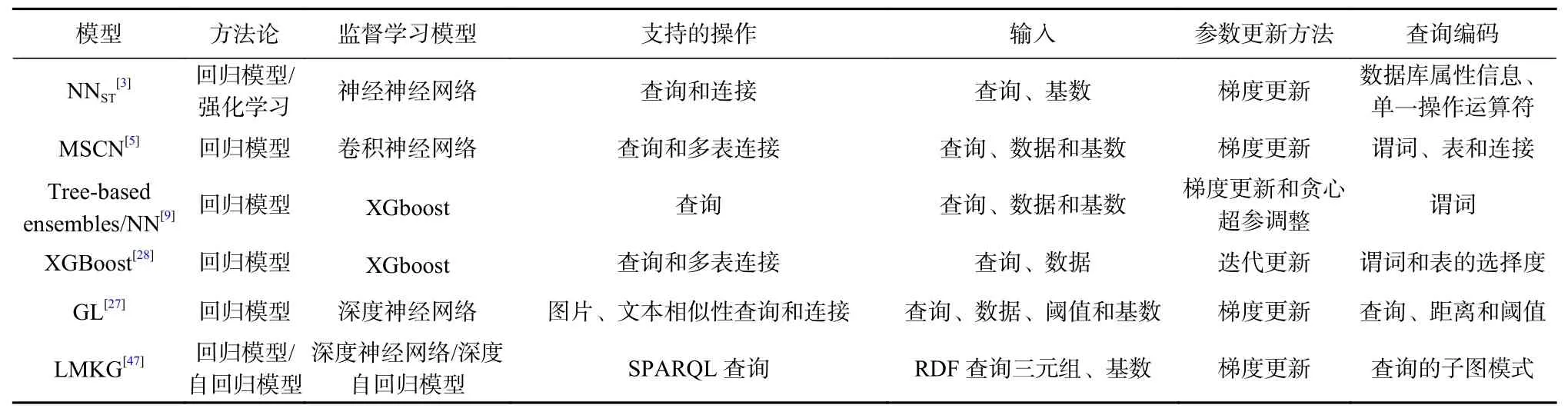
Table 2 Comparison of Query-Driven Cardinality Estimation Models表2 查询驱动的基数估计模型比较
3 数据驱动的基数估计技术
数据驱动的基数估计技术的核心是拟合数据库D中N维(即表的N列)数据的联合分布函数fθ(D)=P(A1,A2,…,AN),其中 θ表示模型需要学习的参数,Ai表示数据库表中的列属性. 数据驱动的基数估计技术通常使用不同的采样策略,通过不同的监督/无监督的模型直接建模表中所有列的关系. 首先,本文基于已有的数据驱动的基数估计技术归纳出数据驱动的基数估计的一般性建模流程;然后对不同数据驱动的基数估计模型进行了详细的介绍;最后对相关模型进行了对比和总结.
3.1 数据驱动的基数估计建模流程
数据驱动的基数估计技术的核心思想是建立一个数据驱动的基数估计模型,其一般性的建模流程如图3 所示,分为3 部分[23-24]:输入、输出和模型建立.
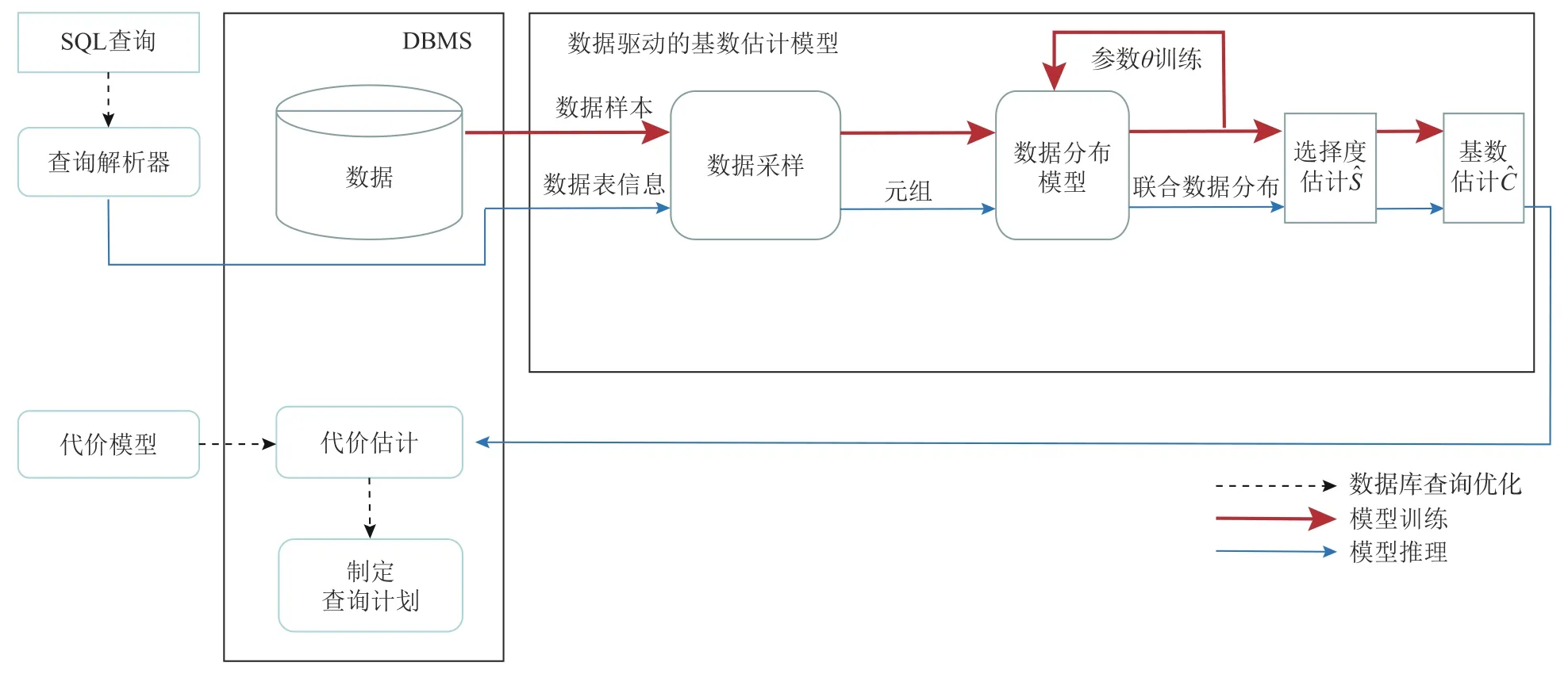
Fig. 3 General modeling flow for data-driven cardinality estimation图3 数据驱动的基数估计的一般性建模流程
1)输入
输入数据库D、查询q. 例如,对于数据驱动的代表模型Naru[17],其模型的输入为数据库D和查询q.其中,在模型推理阶段需要输入查询q,而训练阶段仅需要给定数据库(表)中存储的数据.
2)输出
输出N维数据的联合概率分布P以及查询估计的选择度.
3)模型建立
①模型训练. 如图3 中粗实线条箭头所示,数据驱动的基数估计模型包含2 个模块:数据采样和数据分布模型. 模型可选择不同的数据采样方法,并基于数据库中的数据采样合理规模的元组(多列数据).在这些高维数据的基础上,使用基于监督/无监督学习的数据分布模型拟合这些元组的分布,不断训练参数θ使得模型拟合最优的数据分布来作为整个数据库的数据分布.
本文以模型Naru 为例来解释数据驱动的基数估计模型训练的流程. 首先Naru 扫描数据表,采样合理规模的元组作为数据集,其次,Naru 编码采样的每个元组作为自回归模型的输入向量,元组在每列样本上的数据分布作为其训练标签. 对于每个元组,自回归模型以先前列的取值为输入,估计当前列的概率分布向量. 通过训练缩小该概率分布向量与该列实际的数据分布之间的误差,从而得到一个可以处理所有列之间关系的自回归函数.
②模型推理. 如图3 中细实线条箭头所示,基数估计在推理阶段同样需要经过2 个模块. 不同的是,数据分布模型已经确定,根据查询q,经过查询解析器后,根据数据表的信息(例如列的编码信息、统计信息等),采样出若干条满足查询条件的元组. 将这些元组输入到数据分布模型中计算元组对应列的联合概率分布,即为该查询q的选择度,从而计算出基数.
同理以模型Naru 为例来解释数据驱动的基数估计模型推理的流程. 对于等值查询q1,首先Naru 根据q1和每列的数据分布进行采样生成元组,并对这些元组进行编码. 对于范围查询q2,Naru 提出了一个渐进式采样的方式,在已知数据分布的情况下对范围涵盖的样本进行采样,并将采样出的元组转换为等值查询这种点查询. 将编码后的样本向量输入到训练好的自回归模型中产生n个条件概率,并将这n个条件概率相乘即为查询q的选择度,从而计算出其基数.
3.2 数据驱动的基数估计相关模型
数据驱动的基数估计模型的挑战是如何无需基于多列独立假设来建模单表多列之间的关系,以及多表连接中表与表之间的依赖关系. 从是否使用监督学习的角度来看,Heimel 等人[15]使用核函数进行监督学习,Park 等人[16]使用均匀混合模型建模多列之间的关系;文献[17−20, 48−49]使用无监督学习模型建模数据分布模型;文献[17−19]基于自回归模型拟合数据分布; Halford 等人[48]基于贝叶斯网络进行建模;Liu 等人[49]提出了基于多维直方图的模型用于范围查询的基数估计. 此外,目前大多数文献[15-18,48-49]专注于建模多列之间的依赖关系,而表之间的关系建模建立在多表独立假设之上. 最新的文献[19]基于自回归模型,以及Hilprecht 等人[20]利用和积网络建模了表之间的关系,很好地补充了查询驱动的基数估计模型中多表查询的相关工作. 因此,本文将模型根据是否建模多列之间还是多表之间的关系,分为面向多列连接查询的基数估计模型和面向多表连接查询的基数估计模型.
3.2.1 面向多列连接查询的基数估计模型
模型Feedback-KDE[15]将基于高斯核函数的密度估计器应用到基数估计技术中,用于估计单表多列查询的选择度. 该模型首先从数据库表中随机采样合理规模的元组,并基于高斯核函数初始化高斯密度模型的带宽. 接着使用训练集中的查询和其对应的真实基数训练高斯模型,来优化高斯核的带宽. 因此,模型Feedback-KDE 是一个有监督训练的模型,其为每种连接类型训练一个高斯模型. 当输入一个新的查询后,Feedback-KDE 首先解析该查询的连接类型,并根据其连接类型找到对应的高斯模型.
模型QuickSel[16]使用均匀混合模型来表示数据的分布,从而拟合给定查询的基数. 该模型支持范围查询,其查询范围由查询中的谓词定义. 首先QuickSel从查询范围中随机采样数据,并建立统一的模型. 然后计算真实查询范围和选择样本中的范围之间的重叠度并通过二次规划优化权值. 最后根据混合密度函数计算累计分布(选择度). 当输入一个新的查询后,QuickSel 首先解析该查询的连接类型,然后根据其连接类型找到对应的混合模型.
作为自回归模型中具有代表性的模型,模型Naru[17]没有引入列的独立性这一假设,提出使用自回归模型学习查询q每列样本在前一列样本条件下的条件概率分布(选择度),将所有列的选择度相乘得到查询q的选择度. 模型DLM[18]同样是基于自回归模型,与Naru 不同的是,该模型将数据表中的一行数据看作一个序列,并将序列表示为由多个二进制向量组成. 同Naru 一样,DLM 同样支持点查询和范围查询.对于点查询操作,DLM 将查询中二进制向量的条件概率相乘来估计基数;对于范围查询,DLM 使用了重要性采样策略进行采样.
不同于基于自回归的模型,模型Extended Chow-Liu trees[48]从贝叶斯网络模型角度出发,将单表多列之间的依赖关系使用贝叶斯网络转换为条件概率.该模型启发式地选择Chow-Liu 树作为最优的贝叶斯网络结构,将高维数据联合分布转换为多个2 维数据的条件概率分布. 此外,该模型提出了一个带有间隔的等高条件概率分布,用于减少存储条件概率分布的代价. 以等值查询为例,首先解析查询中包含的谓词;其次在构建好的Chow-Liu 树中,根据涉及到的列抽取Steiner 树;最后使用变量消除算法计算其选择度,从而得到基数. 同时,此模型同样适合单表的范围查询.
为了降低多维数据在查询估计中的查询成本,Liu 等人[49]提出了以RMI[50]的思想将MEH[51]转换为可学习的多维直方图模型LHist 来学习数据库的空间概要. LHist 为一个d层完全K叉树,其中d为数据的维度,K是在每维的分割数. 树中的每个节点都为一个可训练的回归模型,用于预测输入此节点数据的索引,并输出该数据在下一层的节点的位置. 以范围查询为例,当输入一个新的范围查询后,LHist 首先编码其范围谓词,并将该查询转换为一个超矩形,然后通过LHist 找到叶子节点,并计算范围谓词向量对应的索引值,最终将不同列上2 个索引值的差加和得到查询的基数.
3.2.2 面向多表连接查询的基数估计模型
模型NeuroCard[19]可以看作模型Naru 多表连接的扩展版本,该模型在所有列连接后的大表上通过使用加权抽样的方式均匀地选择样本并分批扫描大表,对于每批扫描得到的结果行,NeuroCard 首先编码每个属性值的嵌入表示输入到模型中. 其次模型更新自回归模型的参数并进行训练. 同Naru 模型一样,NeuroCard 同样考虑了点查询和范围查询. 对于范围查询,同样使用了渐进式采样策略.
模型DeepDB[20]与模型Naru 思想相似,同样是要学习所有列的联合概率分布. 不同的是,DeepDB 基于和积网络建模数据分布模型并支持多表连接. 该模型首先将数据库中所有的表连接为一个大表作为数据集,其次将该数据集中的样本按行聚类为若干个具有相似分布的数据组,然后将数据组中的样本按列分割成子节点. 对于同一组的叶子节点,使用一个乘积节点聚合其估计的选择度. 其次,使用加和节点组合成不同组的数据. DeepDB 通过拟合乘积节点中数据的联合分布概率,训练与加和节点之间边的权重,用于建模每个分组分布对整体联合分布的影响.
3.3 小 结
针对数据驱动的基数估计技术,本文首先给出了数据驱动的基数估计的一般性建模流程,其次分析了面向多列和多表连接查询的代表模型. 这些模型使用了不同的采样方式,将查询语句在数据表中相应的元组进行采样,输入到不同的数据分布模型中. 而不同的数据分布模型基于不同的学习模型,建模多维数据的联合分布概率,从而建立起查询、列和表之间的关联. 本文从多个角度对比了数据驱动的基数估计中的代表模型,如表3 所示. 从表3 中可以看到,数据驱动的基数估计模型的核心在于采用何种采样方式处理查询的元组,以及采用哪种数据分布模型建立多列、多表之间的关系. 相对于查询驱动的基数估计模型,数据驱动的基数估计模型拥有更小的训练开销,但在数据库删除和更新等操作中表现不佳.
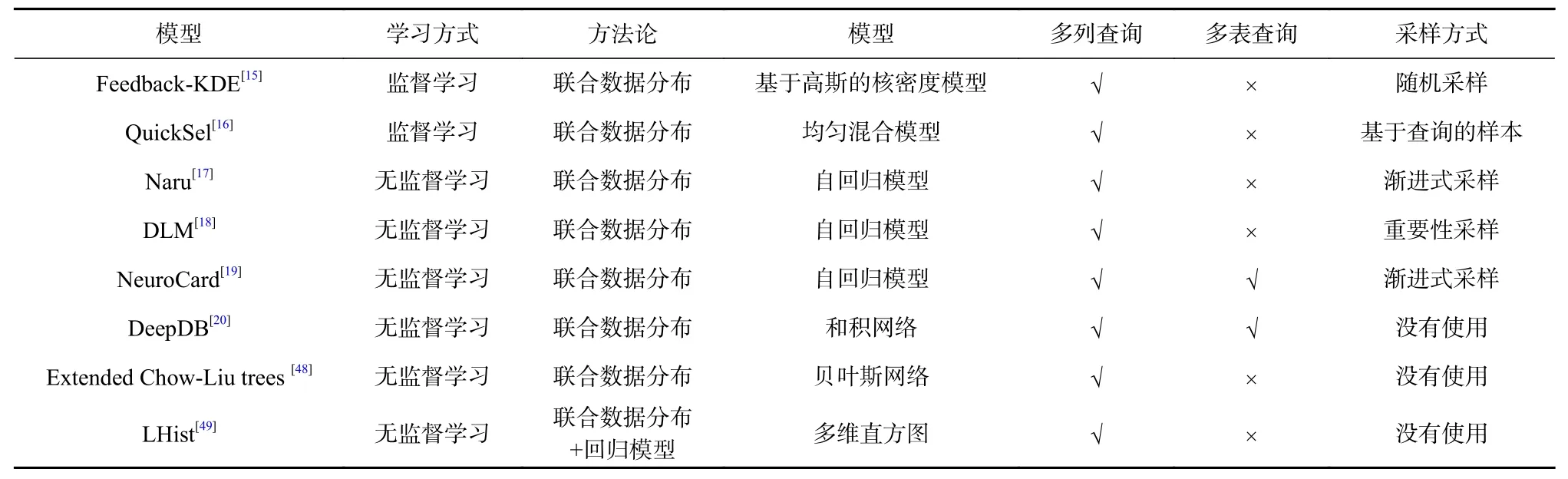
Table 3 Comparison of Data-Driven Cardinality Estimation Models表3 数据驱动的基数估计模型比较
4 混合模型的基数估计技术
查询驱动和数据驱动的基数估计技术各有利弊,而目前仅有少量研究[52]将两者之中的优点结合起来,提出将查询驱动和数据驱动结合的混合模型的基数估计技术,并相互弥补这2 类模型的一些缺点. 其核心思想是建立一个混合查询负载和数据分布的基数估计模型fθ(q,C,D),来同时处理和学习查询负载与数据样本中的信息,其中 θ表示模型需要学习的参数.本文给出了混合模型的一般性建模流程,同时对混合模型的基数估计技术中具体的混合模型进行了介绍.
混合模型的一般性建模流程包含了查询驱动和数据驱动的基数估计的建模流程,同样定义为输入、输出和模型建立3 个部分,其一般的建模流程如图4所示.

Fig. 4 General modeling flow for hybrid model cardinality estimation图4 混合模型基数估计的一般性建模流程
1)输入
涵盖了查询驱动的输入和数据驱动的输入,即输入为数据集DStrain/test{〈q,C〉}、模型约束参数 ϕ、数据库D和查询q.
2)输出
在数据库D中执行查询q估计的基数.
3)模型建立
①模型训练. 如图4 中粗实线条箭头所示,混合分析模型共包含3 个模块:查询特征编码器、数据采样和混合学习模型. 首先模型遵循查询驱动的基数估计中的建模流程,将输入的查询q进行编码. 同时遵循数据驱动的基数估计中的建模流程,将数据表中的数据采样出一定规模的元组. 其次,利用查询特征编码器和数据采样2 个模块进一步加工查询负载和数据样本的信息. 具体来说,既可以通过将元组输入到查询特征编码器中进行元组编码后作为查询q特征属性的一部分,又可以通过查询q来采样更加精准的元组以拟合数据表中数据的分布. 将真实的基数和采样后的元组输入到混合学习模型中,使用监督学习和无监督学习的损失函数同时优化模型的学习参数 θ.
UAE 模型[52]是第一个同时考虑查询驱动和数据驱动的模型,其既包含数据驱动的无监督学习,又拥有查询驱动的有监督学习的能力. 该模型创造性地在模型Naru[17]的基础上融合了查询驱动的回归模型,共同学习数据分布概率参数. 本文以UAE 模型为例来解释混合模型分析的训练流程. UAE 分为2 个部分UAE-D 和UAE-Q. 其中UAE-D 为数据驱动的基数估计模型Naru,直接学习数据表中列数据之间的联合分布概率及得到数据分布在Naru 的损失. 同时,将查询及其真实的选择度作为输入,首先使用与Naru同样的渐进式采样策略,将查询的元组进行采样,并使用One-Hot 编码为向量;其次使用混合模型将不可微的采样元组向量转换为可微的元组向量输入到Naru 的自回归模型中得到预测的选择度,并分析与真实选择度之间的误差和计算损失值. UAE 将2 部分损失加和作为总损失,然后使用梯度更新的方式来优化自回归模型的参数.
②模型推理. 如图4 中细实线条箭头所示,基数估计在推理阶段同样需要经过3 个模块. 不同的是,混合学习模型的参数已经确定. 根据查询q可以得到其编码后的向量表示、采样的元组及其向量表示这3 个元素,将这3 个元素根据混合学习模型的设计,全部或部分输入到混合模型中直接估计出查询q的基数.
同样以UAE 为例,UAE 将查询q采样的元组输入到自回归模型中得到估计的选择度,从而得到估计的基数. 这种混合模型的基数估计技术可以同时处理新增的数据以及具有新分布查询负载的情况.对于增量数据,仅需要最小化UAE-D 即对数据驱动的损失函数进行增量训练. 而UAE 与训练查询负载相比,具有不同分布的查询,仅需要最小化UAE-Q 即查询驱动的损失函数进行增量训练.
5 未来研究方向和展望
尽管基于机器学习的基数估计技术已经涌现出大量的研究,但其仍面临着4 个挑战:
1)模型的训练成本和模型的可解释性. 针对查询驱动的基数估计模型,这类方法建模任务简单,占用空间小,仅使用简单的回归模型即可达到不错的效果. 然而,由于在收集训练数据时构建模型时间长,所以这类模型比较耗时,即使在文献[28]提出了方法来减轻开销,也以损失一定的精度为代价. 此外,由于建模技术基于监督学习,其模型的核心仍然是一个“黑盒”模型,因此模型的可解释性较弱. 因此,模型的训练成本和模型的可解释性是查询驱动的基数估计模型面临的两大重要挑战.
2)多表之间的复杂关系. 针对数据驱动的基数估计模型,这类方法相比于查询驱动的技术估计方法,其训练开销小,仅需要根据原始数据进行训练,且支持的查询范围更广泛. 虽然已有研究已经对多表之间的关系进行了建模并取得了一定的进展,但是这些研究均是直接将多个表连接为一个大表,进而转换为多列连接查询的思想进行建模,因此对于多表之间复杂关系的探索依然不足. 因此,多表之间的复杂关系是数据驱动的基数估计模型面临的一个重要挑战.
3)动态变化的数据库环境. 无论是查询驱动还是数据驱动的基数估计模型,目前的研究均不能适应动态变化的数据库环境[24]. 由于查询驱动的基数模型继承了监督学习的一些固有缺陷,使模型不适用于没有见过的查询,因此在频繁更新的数据库系统中该类模型估计的误差较大. 对于数据驱动的基数估计模型,由于其直接拟合数据库中的数据分布,因此该类模型可以支持新的查询. 但是,这类方法仍然不能支持数据的删除和更新等动态操作. 因此,支持动态变化的数据库环境是数据驱动和查询驱动的基数估计模型面临的一个共同挑战.
4)基数估计benchmark 和评价体系. 目前,对已有方法进行评价的文献[23-24]仍然不丰富,所以设计benchmark 对已有方法进行对比和评价也是基数估计领域中研究的一个重要挑战.
针对以上分析,基于机器学习的基数估计技术的未来研究方向可以包含4 个方面:
1)考虑使用可解释的增量学习方法. 如何降低学习模型的成本和如何提高模型的可解释性是查询驱动的基数估计技术研究的两大方向. 文献[28]证明了增量学习可以降低查询驱动的基数估计模型的学习成本,但其估计准确性有所下降. 因此,探索可以提升估计精度的增量学习模型是降低模型学习成本有效且直观的解决方式. 随着可解释模型在人工智能领域的发展,机器学习模型逐渐从“黑盒”走向“透明”. 因此,将增量学习与可解释性模型相结合有助于探索一个全新的基于增量学习且拥有可解释性的查询驱动的基数估计模型.
2)建模多表之间的复杂关系. 针对于在数据驱动的基数估计技术中仍然缺乏探索的多表复杂关系,应当考虑设计可以建模多表之间关系的数据分布模型,以更好地估计多表连接查询的基数.
3)探索更加优越的混合模型. 混合查询驱动和数据驱动的基数估计技术可以结合两者优点,互补两者的缺点,文献[52]证明了混合模型的估计效果优于独立的查询驱动的基数估计模型和数据驱动的基数估计模型,但是混合模型目前成果较少,因此结合哪些机器学习模型或者数据结构,如何结合查询驱动的基数估计模型和数据驱动的基数估计模型也是未来研究的热点.
4)加快机器学习模型训练速度应部署到实际数据库进行应用. 由于基于机器学习的模型更新速度较慢,无法适应频繁更新的动态数据库环境,距离实际落地应用还有一定的差距[24]. 因此,基于机器学习的基数估计技术作为一个重要的研究方向应以实际落地应用为目标进行设计,探索可以加快机器学习模型训练速度的算法,以减少模型参数调优的时间和提高模型查询效率,最终适应动态变化的数据库环境.
6 总 结
本文首先介绍了基于机器学习的基数估计技术的相关背景;接着介绍了基数估计的相关定义、特征编码技术以及基数估计技术中的分类体系;然后分别从查询驱动、数据驱动和混合模型的角度出发,给出了3 类基数估计的一般性建模流程;并基于建模流程,分别讨论了查询驱动、数据驱动和混合模型这3 类基于机器学习的基数估计的代表性模型,并总结了其利弊;最后,本文还讨论了基于机器学习的基数估计技术中存在的挑战和未来的研究方向. 基于机器学习的基数估计技术近年来涌现了大量的研究,但距离落地到实际动态变化的数据库环境还有一定的差距,未来会有更多的方法和研究成果出现,在数据库实际应用中占有一席之地.
作者贡献声明:岳文静负责论文主要内容的调研和撰写,以及论文的校验;屈稳稳辅助调研相关内容并提供指导意见;林宽、王晓玲对文章的结构和内容提供指导意见.
猜你喜欢
四川劳动保障(2021年9期)2022-01-18
电脑报(2021年14期)2021-06-28
数码设计(2020年16期)2020-12-08
无锡职业技术学院学报(2019年4期)2019-12-27
计算机与生活(2019年5期)2019-07-18
小学生必读(中年级版)(2018年6期)2018-09-05
吉林大学学报(理学版)(2018年2期)2018-03-29
小学生学习指导(低年级)(2017年9期)2017-08-07
电子技术与软件工程(2016年8期)2016-07-10
中兴通讯技术(2016年2期)2016-03-24
