
改进YOLOv8的多尺度轻量型车辆目标检测算法
2024-03-03 11:21张利丰
计算机工程与应用 2024年3期
张利丰,田 莹
辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114000
在深度学习和计算机视觉领域,车辆目标检测一直是研究者们关注的焦点,引领着许多创新技术的发展。从自动驾驶系统的实现,到智能交通监控的发展,车辆目标检测的应用场景极其广泛[1]。车辆目标检测极大地提高了工作效率,减少了人力资源的消耗。然而,许多应用场景对车辆目标检测的实时性和准确性都提出了极高的要求,同时也对计算资源和能源消耗提出了严格的限制。因此,如何在保证车辆目标检测精度的同时,有效地降低计算和能源的消耗,已经成为研究领域中的一大挑战。
车辆检测历经三个阶段:设计特征、机器学习、深度学习。传统的设计特征检测从车辆的颜色、纹理和形状方面通过Haar[2]、HOG[3]等方法设计特征并识别。但这种方法对预设特征的依赖性较强,耗时耗力,且对于复杂场景和任务往往很难设计出有效的特征。并且泛化能力较差,需要针对不同的环境和任务重新设置特征。随着机器学习与深度学习技术的发展,更复杂的模型可以从大量的标注数据中自动学习出有效的特征,无需手工设计,而且可以更好地反映数据的分布,提升检测效果。基于深度学习的车辆目标检测主流算法大致分为二阶段和一阶段两大类。
这两种方法都是在图像中生成大量锚框,然后基于锚框进行检测和判断。二阶段方法通过候选框生成器产生候选区域,然后对候选区域进行分类,代表算法有R-CNN系列[4-6]。一阶段方法是使用卷积神经网络进行端到端的检测,直接在图像上生成多个边界框,并进行定位和分类,代表算法有YOLO系列[7-13]和SSD[14]等。二阶段检测方法具有更高的准确度,但是速度相对较慢,不适合车辆目标检测这类实时性需求较高的场景和任务。而一阶段只提取一次特征就进行检测,相对来说速度更快,但是精度会有所下降。
目前,许多国内外学者对轻量级网络和车辆目标检测进行了一系列研究。郑玉珩等人[15]基于YOLOv4 与MobileViT 提出一种新型轻量化车辆检测模型,使用CSPMobileViT 网络替换原始主干网络,然后将PANet替换成BiFPN,并且将BiFPN中的标准卷积替换成深度可分离卷积。此外,在BiFPN 与YOLO-Head 之前添加ECA 注意力机制。最后将损失函数CIoU 替换为Focal EIoU。减少参数量以及模型大小,增加精确度。刘浩翰等人[16]基于YOLOv7-tiny模型进行改进,使用ShuffleNet v1替换主干网络,降低复杂度;引入GSConv(鬼影混洗卷积)改进Neck部分;最后采用Mish激活函数,增加非线性表达,提高模型的泛化能力。Dong等人[17]提出一种改进YOLOv5的轻量化网络,在Neck部分引入C3Ghost和Ghost模块;在主干网络中引入注意力机制模块CBAM,最后针对损失函数CIoU进行改进,提高检测精度。
以上研究虽然在速度与精度上都有所提升,但对于一些小型设备的部署来说仍有不小的负担,并且大部分模型没有一个特别突出的点,无法使两者兼顾。针对这些问题,本文提出一种多尺度车辆目标检测模型RBSYOLO,首先对YOLOv8 的主干网络进行重构;其次使用改进后的BiFPN[18]以替换原有的FPN;接着在Neck部分添加注意力机制。最后使用SoftNMS[19]对候选框进行筛选,有效解决重叠目标检测困难的问题。
1 YOLOv8网络模型
YOLOv8是YOLO系列最新的模型,在YOLOv5的基础上设计网络模型架构,引入新的结构,进一步提升性能与扩展性。以深度和宽度为标准,可分为YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l 和YOLOv8x 这五个网络,模型参数量和计算量随着精度的提升大幅度提高,满足不同场景的需求。
输入端使用自适应图片缩放,调整输入尺寸,同时使用mosaic数据增强,提升模型的鲁棒性。主干网络由CBS 模块、C2f 模块和SPPF 模块组成。CBS 模块即卷积、批归一化和SiLU激活函数,这样组合能提高模型的稳定性,加快收敛速度,防止梯度消失。C2f模块相较于C3 模块增加跳层连接和额外的Split 操作,使模型的梯度流更丰富。在SPPF 模块中,通过池化和卷积操作进行特征融合,自适应地融合各种尺度的特征信息,从而增强模型的特征提取能力。
Neck 部分对从主干网络提取到的特征进行处理,使用PAN和FPN通过自顶向下与自下向顶的跨层连接使特征更充分融合。Head 部分使用解耦头结构,将检测与分类分离,根据分类和回归的分数加权得到的分数来确定正负样本,有效提升模型性能。YOLOv8模型结构图如图1所示。
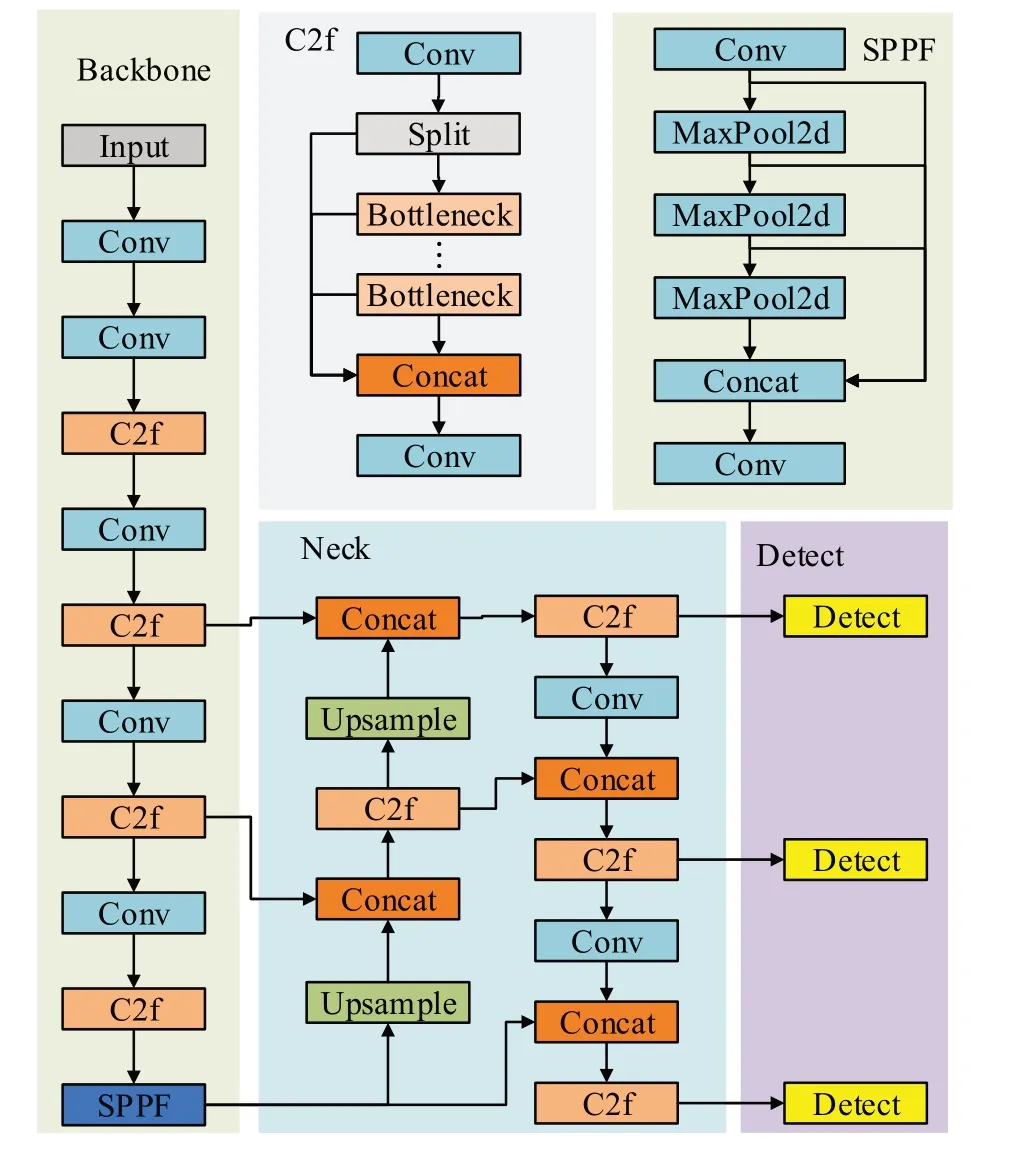
图1 YOLOv8模型Fig.1 YOLOv8 model
2 改进YOLOv8检测模型
2.1 重构主干网络
在YOLO系列以及其他大部分模型中,特征提取网络都是自上而下的,图像中的特征逐渐被压缩,在一定程度上对模型的性能造成了影响。虽然在提取特征之后使用HRNet 和FPN 等多尺度融合,使得目标检测模型的性能得到了极大的提升,但是这种方式只能应用在特征融合部分,在主干网络中用来提取特征的效果并不理想。为此,旷视科技提出可逆连接的多列网络RevColNet(reversible column networks)[20]。
RevColNet 网络是一个二维网格状的结构,相较于传统的直筒式结构,引入了新的规模化扩展维度列。且水平链接是可逆算子。通过增加列的维度,可以扩展模型的参数量。由于网络是可逆的,每当计算完一个特征图就可以将其扔掉,在反向传播的时候再计算一次,从而减少内存的占用。一般的特征提取主干会随着卷积等操作造成信息丢失等问题,影响模型对特征的学习,RevColNet 采用多输入的设计,使每一列的输入包含最多的特征信息。在列与列之间采用了可逆连接方式,可以通过后面列的信息倒推出前面列,这样能从最后一个列倒推回第一列,保证信息在每一列之间的传递是无消耗的,同时,在每一列的最末端加入监督,以此约束每一列的特征提取。对应模型结构图如图2所示。

图2 RevColNet模型Fig.2 RevColNet model
RevColNet 模型的微观架构如图3 所示,图3(a)展示了第一列每个Level 中包含的具体模块。在这一列中,网络只需自上而下通过下采样和ConvNeXt 模块进行特征提取,无需进行其他操作。图3(b)展示了第二列及之后每列的具体操作。其计算公式如下:

图3 RevColNet模型细节Fig.3 RevColNet model details
图3(b)和公式(1)描述了第二列每个Level 之间的交互。Levell 的输出Xt由三个输入得到。Levell 的上一个Level 输出Xt-1,前一列对应下一行的Level 输出结果为Xt-m+1,两个特征通过Ft(·)调整shape 与前一列的输出Xt-m一致,保留层级的优势。Ft(·)的操作包括一个融合模块以及n个纯卷积模块。Fusion Block包含下采样和上采样操作两个操作,以此调整不同层次信息的通道数使其一致,进行通道上的加和融合信息,然后经过卷积模块提取特征信息。最后将输出特征与γ倍的Xt-m进行相加,充分进行信息融合。公式(2)则展示了RevColNet的可逆性,通过后面列的信息可以倒推出之前列的特征信息。
本文使用RevColNet 重构YOLOv8 主干网络能有效地提升模型的特征提取能力。但RevColNet 的构造过于复杂与繁琐,直接引用会造成网络臃肿,不适用于轻量化,于是对网络做了如下改动:将RevColNet 中的列数更改为2;对Fusion Block 中的上采样和下采样操作重新构建,针对高层次语义特征,只进行一个复合的卷积操作来下采样,即卷积、批归一化和激活函数。针对低层次语义特征使用卷积和上采样的方式代替原有的上采样操作;使用YOLOv8 的C2f 替换Level 中的ConvNeXt 模块。并且将模块的数量改为3、6、6、9,通道数为YOLOv8 的一半。改进之后的主干模型如图4所示。

图4 重构后的主干网络Fig.4 Reconstructed backbone
2.2 多尺度特征融合
YOLO系列采用PAN[21]和FPN[22]的方式进行特征融合,通过横向连接和金字塔状的层次结构融合各个尺度的特征信息,能有效提升模型对多尺度目标的检测能力。为了使模型的性能得到提升,本文基于BiFPN结构提出CBiFPN。
原始BiFPN 的结构如图5(a)所示,相较于PANet,BiFPN删除了两端只有一条边的节点,在中间的不同层级之间引入了双向连接,这些双向连接使特征信息在不同层次之间流动,有助于改善不同尺度和层级之间的交流,提高网络处理不同尺度目标的能力,使模型的泛化能力进一步提升。

图5 BiFPN模型Fig.5 BiFPN model
图5(b)中的结构为BiFPN 在YOLO 系列中的一般用法,即在P4 层的连接中增加一个跳跃连接。本文在BiFPN 与主干网络特征之间增加了卷积操作,并且把BiFPN 的层数由五进五出改为四进三出,使其更适配YOLOv8,且增强特征提取能力。此外,特征的连接方式采用Concat 拼接,保留各层次特征信息。提出的CBiFPN如图6所示。

图6 CBiFPN模型Fig.6 CBiFPN model
2.3 注意力机制
为了使模型的性能得到进一步的提高,本文在特征融合部分之后加入注意力机制来提升模型提取特征的能力。传统注意力机制在计算通道注意力的过程中将输入张量在空间上通过池化转为像素,丢失了大量的空间信息,在单像素通道上计算注意力时,不存在通道和空间维数之间的相互依赖性。基于空间和通道注意力机制CBAM 虽然缓解了这一问题,但是二者是分离的,计算相互独立,无法更有效地利用二者的信息。Triplet Attention[23](TA)基于很少的参数来构建空间和通道模块,是一个轻量且高效的注意力机制模型。Triplet Attention 通过三分支结构来捕获不同维度进行交互计算注意力权重,并且使用旋转和残差操作来建立维度之间的依赖关系,对应模型结构图如图7所示。
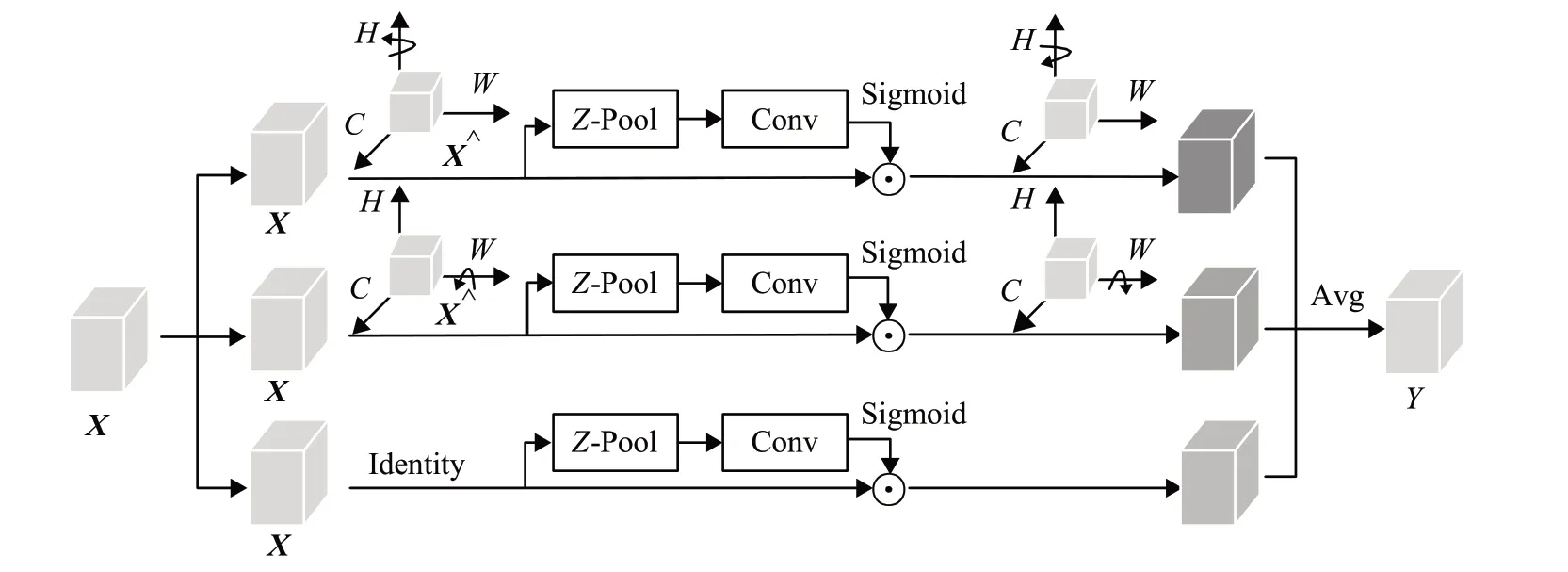
图7 TA模型结构图Fig.7 TA model structure diagram
Triplet Attention由三个平行分支构成,前两个负责通道和空间中的宽或高之间的维度交互,第三个分支类似于CBAM,用于构建空间注意力。
三个分支中,每一个分支的输入都为X。前两个分支中,首先根据输入张量X的宽或高逆时针旋转90°,然后将旋转得到X^经过Z-Pool操作将通道C的维度缩减至2,即获取维度上的最大特征值和平均特征值,然后将其拼接,得到二维张量X^*,使得该层能保留实际张量的丰富表示,同时缩小深度也进一步减少计算量。Z-Pool的计算公式如下:
接着通过卷积核尺寸为k的卷积层,进行批归一化处理,再通过Sigmoid 激活层来生成注意力权重。最后将张量沿着第一步操作对应的宽或高顺时针旋转90°,使输出张量与输入张量的尺寸保持一致。
在第三个分支中,对输入张量宽和高建立交互,去除了旋转操作。最后,将三个分支的输出张量聚合在一起,即相加之后取平均值,具体步骤如公式(4)所示:
2.4 柔性非极大值抑制
NMS 代表非极大值抑制(non-maximum suppression),是目标检测中的一个重要步骤,一般使用在训练完成之后验证阶段。用于从候选框中选出最相关的目标框,保留这些最有可能是真实目标框的候选框,并剔除掉与保留框有较大重叠的冗余框,以避免多个重叠的候选框对同一个目标进行多次检测。
YOLOv8 使用的NMS 为“硬性”NMS,根据目标检测器预测的物体置信度(或得分)对所有的候选框进行降序排序,将得分最高的框排在前面。接下来,从得分最高的框开始,使用交并比计算该框与其他剩余框的重叠度。通过计算两个框的交集面积除以它们的并集面积来衡量框的重叠程度。对于得分最高的框,保留它,并将与其重叠度大于一定阈值的其他框剔除。这样可以确保每个真实目标只对应一个检测框。
由于NMS 的操作是二进制的,要么保留要么剔除。而在车辆目标检测时,由于单向通道的特殊性,目标的重叠率较高,使用传统NMS 会导致一些高质量的目标框被错误地剔除。特别是当目标之间的重叠较大,或者目标的大小和尺寸变化较大时,NMS 可能会失效。为此,引入SoftNMS对原有NMS进行替换。
在SoftNMS 中,当候选框的重叠度超过阈值时,不直接剔除候选框,而是通过衰减函数来降低重叠框的得分来保留一些来会被抑制的框。一般使用两种函数来进行处理。第一种是线性衰减函数,其公式如下:
在上式中,M表示排序后得分最高的框,bi为去除M之后剩余的框,Nt表示NMS的阈值,IoU(M,bi)为M和bi的交并比,默认使用CIoU,si为每个框包含物体的可能性大小。当计算出的交并比不小于阈值时,通过衰减函数线性减小,IoU 越大得分越小,极端情况下会导致线性衰减等同于普通NMS。这是由于这个公式不连续,会导致bbox集合中的Score出现断层。所以采用高斯衰减函数来替换NMS,其公式如下:
高斯函数在一定范围内产生平滑的降低效果,且越接近高斯分布的中心,惩罚力度越大。通过设置参数σ的大小来调整高斯分布的中心,使NMS 更好地优化。并且通过指数的方式保证了连续性,实现了对重叠操作的优化,在一定程度上缓解了传统NMS的问题,更好地处理密集目标、重叠目标以及多尺寸目标,适应了更复杂的场景,提升了目标检测的性能。
2.5 RBT-YOLO模型
图8 展示了基于YOLOv8 重构的RBT-YOLO 模型结构。首先在特征提取的主干网络部分使用RevColNet多尺度特征融合网络进行重构,在最末尾使用YOLOv8中的SPPF 模块加强特征提取能力。此外每个Level 中的C2f模块重复的个数与YOLOv8一致,为3、6、6、3,并且通道数减半。在Neck部分进行特征融合之前使用卷积层调整通道数,使得模型的参数量和计算量大幅度下降,使得模型在小型设备上的部署具有更好的优势。相较于之前的FPN,增加了一个连接层,可以获取主干网络中更高层次的特征信息,加强信息之间的交互。同时在每个输出特征之前加入注意力机制,提升模型的特征提取能力。最后则在检测阶段使用SoftNMS 技术改进候选框的保留规则,使模型检测重叠目标的性能得到提高。

图8 RBT-YOLO模型Fig.8 RBT-YOLO model
3 实验结果与分析
3.1 实验环境
实验所用操作系统为Win10,使用Python3.8.16、CUDA11.3、Pytorch1.11.0 深度学习框架开发环境,在NVIDIA GEForce RTX 4070Ti显卡上进行训练。训练过程中使用YOLOv8s 作为基线模型,调整输入图片尺寸至640×640,Batchsize 设置为16,线程设置为2,初始学习率为0.01,使用余弦退火策略调整学习率,共训练300个epoch。
3.2 数据集介绍
实验选用两个公共数据集:Pascal VOC(visual object classes)和MS COCO(microsoft common objects in context)数据集对模型的性能进行测试。
从Pascal VOC 2007 和2012 的训练集和验证集中提取车辆数据集car、bus、train、bicycle、motorbike这5个车辆类别共3 074 张图片,按照8∶2 的比例随机划分训练集和验证集。其中训练集2 460 张,验证集614 张。从Pascal VOC 2007 测试集中随机抽取与验证集同样数量的图片作为测试集。
MS COCO 2017 数据集中共有bicycle、car、motorcycle、train、bus、truck这6个车辆类别,从训练集和验证集中随机抽取7 000 张,随机划分训练集、验证集、测试集,比例为8∶1∶1。
3.3 评价指标
本文实验结果使用目标检测常用的评估指标:准确率(precision,P)、召回率(recall,R)和平均精度均值(mean average precision,mAP),其计算公式如下:
在上式中,TP(true positive):真正例,指图片中的目标被识别为正确的目标。FP(false positive):假正例,指能识别出目标所在位置,但是目标的类别识别错误。FN(false negative):假反例,正确目标未被识别出来,被认为是其他目标,即漏检。N代表类别数。APi就是每个类Precision-Recall 曲线下面的面积,面积越大,证明分类器越优秀。mAP 就是指多个类别APi的平均值。此外,为了体现与其他模型相比在小型设备上的优势,在此基础上加入参数量、计算量和模型文件大小作为评价指标。
3.4 实验结果
为了验证所提出模型的性能,从Pascal VOC 和MS COCO 数据集中提取的车辆图像进行实验。采用3.3 节中介绍的指标作为衡量模型性能的基准,并在相同的环境条件下,对本文提出的模型与当前主流的目标检测以及轻量化模型进行对比实验。
实验结果如表1所示,首先将模型与经典检测模型Faster-RCNN、SSD、YOLOv6s 进行对比,其中Faster-RCNN 使用ResNet50 作为主干网络,SSD 使用VGG 作为主干网络。相较于主流检测模型,RBT-YOLO在参数量和计算量巨大优势的情况下,检测的性能也有一定的提升。

表1 与其他模型对比实验结果Table 1 Comparative experimental result with other models
在轻量化方面则与YOLOXs、YOLOv7-tiny、YOLOv5s和YOLOv4-tiny 四个模型进行对比。虽然RBT-YOLO在计算量上略大于YOLOv4-tiny,但其检测准确度在两个数据集上平均提升了18%。
为了更加充分地展示改进的有效性,引用其他参考文献进行对比。文献[24]和[25]分别基于YOLOv5 和YOLOX-nano 进行改进,并在相同数据集上进行实验。结果表明RBT-YOLO在各种性能上均超过文献[24],在与文献[25]进行比较时,虽然轻量化和计算量上略有不足,但是在精度方面分别提升了6.8和13.0个百分点,更加适合车辆目标检测在精准度上的要求。
通过实验对比可知,与目前主流检测和原模型相比,RBT-YOLO 在性能和轻量化上有大幅度的提升,更加适合车辆目标检测模型在小型设备上的部署与应用。
图9 和图10 展示了改进前后的模型在两个数据集上每个类以及总的mAP 值和PR 曲线。图(a)和(b)分别为原模型和RBT-YOLO 模型的PR 曲线。从图中曲线的面积可知,提出的新模型RBT-YOLO 对每个类都有不同程度的提升,体现出了模型良好的性能。

图9 YOLOv8s和RBT-YOLO在Pascal VOC车辆数据集上的PR曲线Fig.9 PR curve of YOLOv8s and RBT-YOLO on Pascal VOC vehicle dataset
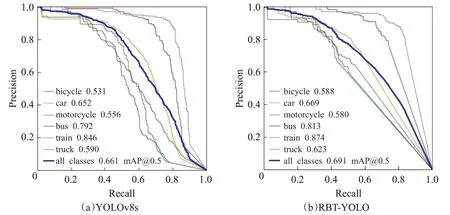
图10 YOLOv8s和RBT-YOLO在MS COCO车辆数据集上的PR曲线Fig.10 PR curve of YOLOv8s and RBT-YOLO on MS COCO vehicle dataset
3.5 消融实验
为了验证每一步改动的有效性,对相关创新模块进行消融实验,实验结果如表2 所示。在使用RevColNet重构YOLOv8主干网络之后,由于通道数和模块个数的改变导致模型的mAP 有所下降,但GFLOPs 下降了25.2%。在原模型上加入CBiFPN之后模型的性能得到了大幅度提升,多尺度的特征融合使模型学习不同层次的信息,通过主干网络之后的卷积层调整通道数,降低模型计算量。轻量注意力能在几乎不影响模型复杂度的情况下提升模型性能。NMS针对重叠目标的候选框进行优化,极大地提高了模型的召回率,使模型在车辆检测上具有更大的优势。通过对提出的模块逐个添加进行实验,表明了每个改进的模块对模型的性能都是有一定的提升,体现出改进模型的泛化能力。
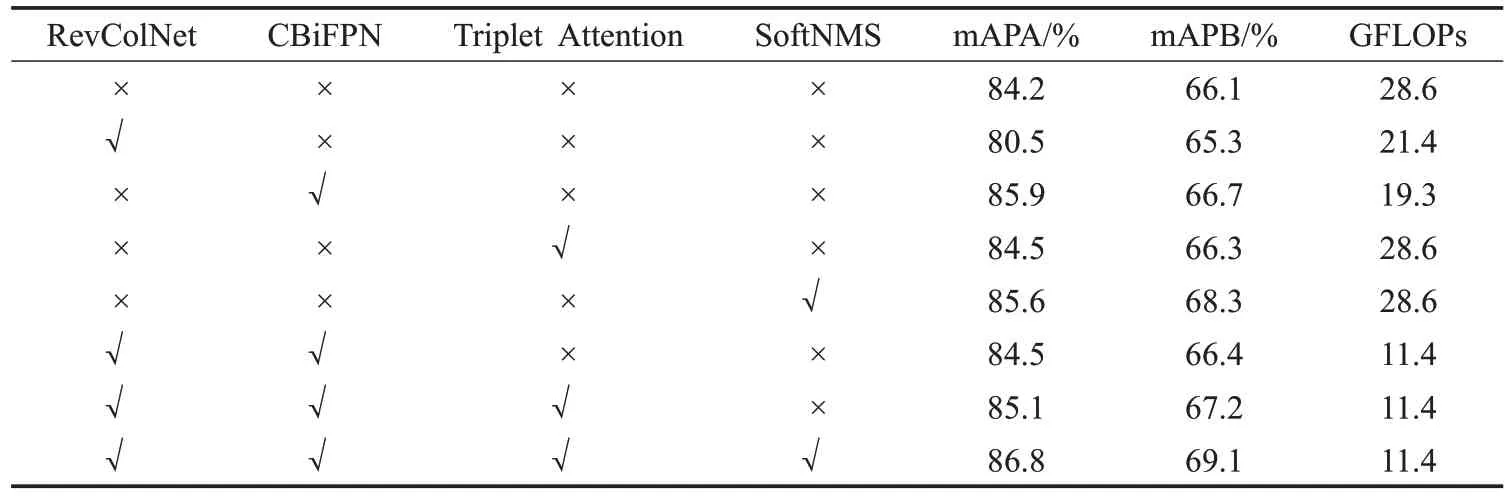
表2 消融实验Table 2 Ablation experiment
3.6 模块对比实验
为了验证本算法所用改进模块的有效性,对颈部网络中BiFPN 的融合方式以及不同注意力机制进行对比实验。实验使用Pascal VOC 数据集,在同一环境下进行比较。
3.6.1 不同BiFPN对比
针对多尺度的连接,使用不同连接方法会对模型的性能产生不同的结果,目前共有四种连接方式。
第一种为加权特征融合(Weight)。考虑到每个特征层携带的信息不同,在检测中重要性占比也不同,因此对其增加一个额外的学习权重wi,使其融合不同程度的输入信息。
第二种方式是对应通道相加(Add),该操作需要特征向量的通道数必须相同。将经过卷积的特征图沿着指定维度堆叠在一起,最后对所有特征图进行求和,将求和之后的特征图作为输出。
第三种是自适应特征融合(Adaptive)。它首先将特征图沿着通道维度进行拼接,对拼接后的结果进行Softmax 操作,生成适应性权重。将权重在上述公式中进行替换即可得到自适应特征融合结果。
第四种则是拼接(Concat),Concat方式将不同尺度的特征直接拼接在一起,有助于保留多尺度信息,使模型能够更全面地感知目标的空间层次结构,提升模型的表达能力,更好地适应复杂的目标场景。此外,将来自不同卷积层的特征拼接在一起,模型可以同时利用底层和高层的信息,提高对目标的识别和定位准确性。
在原始模型中加入改进之后的CBiFPN,并使用四种不同的融合方式进行实验,实验结果如表3所示。

表3 BiFPN不同融合方式对比Table 3 Comparison of different fusion methods for BiFPN
从表3中的实验结果可以看出,拼接不需要调整权重或者进行自适应调整,降低了模型对权重参数的敏感性,使得模型在不同情况下更加稳定。同时这一方式将来自不同输入源的特征图沿通道维度简单地拼接在一起,所有输入特征信息都被保留在最终的特征图中,有助于保留多样性的特征,得到最好的效果。
3.6.2 不同注意力机制对比
为了验证加入的Triplet Attention 模块对模型性能的影响,本实验将原始模型与不同的注意力机制结合进行对比,实验结果如表4所示。相较于其他两种注意力机制,Triplet Attention 作为轻量型的注意力机制,在模型的参数量和计算量几乎没有增长的情况下,使模型的性能提升最高。
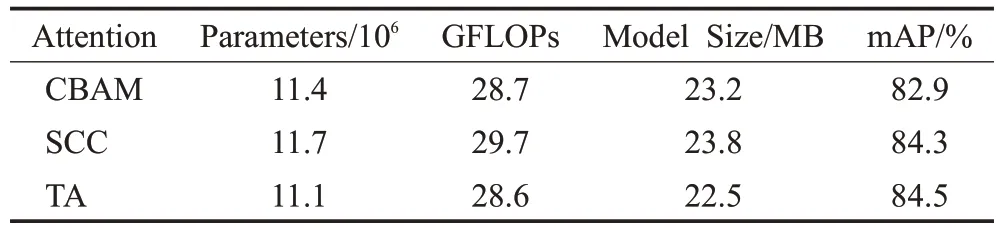
表4 不同注意力机制对比Table 4 Comparison of different attention mechanisms
3.7 实验效果展示
图11和图12分别展示了Pascal VOC和MS COCO数据集图像可视化检测结果,图中左侧为原模型检测结果,右侧为RBT-YOLO检测结果。从图中可以看出改进后的模型检测精度有明显的提升,且针对重叠目标也能精准地识别。此外还表现出了对被遮挡物体有了更精准的识别。图12第一幅对比图中原模型在检测自行车时,由于人的遮挡,显示出三个识别框。使用RBT-YOLO检测则去除了被分割的两部分,保留了一个整体。并且优化后的非极大值抑制能更好地检测出遮挡目标,使检测框更加准确。证实了提出的RBT-YOLO在精度和重叠目标的检测上的高性能以及良好的泛化能力。

图11 Pascal VOC车辆数据集的可视化对比图Fig.11 Visual comparison plots on Pascal VOC vehicle dataset

图12 MS COCO车辆数据集的可视化对比图Fig.12 Visual comparison plots on MS coco vehicle dataset
4 结束语
本文基于YOLOv8 提出一种多尺度轻量型车辆目标检测模型。在RevColNet 和BiFPN 的基础上对YOLOv8的主干网络和颈部网络进行重构,加强不同层次中特征信息的多尺度融合;使用轻量型注意力机制进一步提取特征信息;针对道路中车辆目标重叠过多等问题,使用SoftNMS对候选框进行优化筛选。通过实验可知RBT-YOLO 在Pascal VOC 和MS COCO 数据集上mAP 值分别提升了2.6 和3.0 个百分点,参数量和计算量分别下降了60.4%和60.1%,与原模型相比更加轻量以及精准。与其他模型相比,RBT-YOLO更适合在小型设备上部署,满足多样化的需求。
猜你喜欢
军事文摘(2024年2期)2024-01-10
小雪花·成长指南(2022年1期)2022-04-09
广东教育·高中(2022年1期)2022-03-16
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
新课程研究(2016年21期)2016-02-28
中国交通信息化(2015年2期)2015-06-05
