
基于Tri-training的社交媒体药物不良反应实体抽取
2024-03-03 11:21何忠玻徐广义张金鹏邓忠莹
计算机工程与应用 2024年3期
何忠玻,严 馨,徐广义,张金鹏,邓忠莹
1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.昆明理工大学 云南省人工智能重点实验室,昆明 650500
3.云南南天电子信息产业股份有限公司 昆明南天电脑系统有限公司,昆明 650040
4.云南大学 信息学院,昆明 650091
5.云南财经大学 信息学院,昆明 650221
随着人们生活水平的不断提高,个人健康状况也越来越得到重视,而在医疗领域,药物不良反应(adverse drug reaction,ADR)也成为人们广泛讨论的问题。药物不良反应指的是患者在用药后,产生的有害反应。有研究表明,药物不良反应已经成为继心脏病、艾滋病和糖尿病之后的第四高死亡率的医学问题[1]。
社交媒体逐渐成为人们知识交流和情感分享的主要平台,患者可以在社交媒体上发表自己的感受及症状,以询求医生对策。这些数据是庞大且实时的,充分利用这些信息可以及时地发现药物不良反应,解决传统临床研究效率低、依赖性强等各种局限性,弥补药物上市前研究的不足,为药物上市后的风险管理提供技术支持,保障公众健康。但社交媒体文本的口语化,噪声大等特点,给社交媒体药物不良反应实体抽取带来了挑战。
ADR实体包括患者出现不良反应的身体部位及其症状,例如“涂了阿达帕林凝胶脸上起红疹脱皮”其中,“脸上起红疹脱皮”可看作是ADR实体。ADR实体抽取可以表述为命名实体抽取任务。在医疗领域,命名实体识别方法的发展整体上经历了基于规则与词典的方法、基于统计机器学习的方法和基于深度学习三个阶段。由于社交媒体药物不良反应实体抽取的开放语料比较匮乏,并且社交媒体文本标注数据量大、成本高。针对以上局限性,同时考虑到Tri-training为简洁的自动标注数据的经典方法,本文提出基于Tri-training的社交媒体药物不良反应实体抽取模型。使用Tri-training 的半监督方法充分利用社交媒体中的未标注数据。本文的贡献如下:首先,针对社交媒体大量未标注语料标注成本高的问题,采用Tri-training半监督的方法进行社交媒体药物不良反应实体抽取,通过三个学习器Transformer+CRF、BiLSTM+CRF 和IDCNN+CRF 对未标注数据进行标注,并利用一致性评价函数迭代地扩展训练集,最后通过加权投票整合模型输出标签;其次,针对社交媒体的文本不正式性(口语化严重、错别字等)问题,利用融合字与词两个粒度的向量形成一个新的向量作为模型的输入来促进语义信息提取。实验结果表明,提出的模型能够有效地促进社交媒体药物不良反应实体的抽取。
1 相关工作
基于规则与词典的方法流行于20世纪末到21世纪末期。基于规则与词典的方法依赖于相关领域专家构建的专业词典及规则模型,再通过匹配的方式进行命名实体识别。例如1994 年Friedman 等人[2]将疾病名称和修饰成分映射到语法规则词典中对其进行实体识别。但这种方法耗时耗力,同时,只适用于特定类型实体的识别,即扩展性、泛化能力不强。
基于统计机器学习的方法包括隐马尔科夫模型(hidden Markov model,HMM)、支持向量机(support vector machine,SVM)、条件随机场(conditional random field,CRF)和最大熵(maximum entropy,ME)等。Li 等人[3]将基于CRF 的方法和基于SVM 的方法在临床实体识别上的性能作比较,得出了前者优于后者效果的结论。Aramaki 等人[4]使用SVM 和CRF,利用基于词库的特征、POS标签、词链等提取药物不良反应。Tang等人[5]提出了结构化支持向量机(structed SVM,SSVM)用于识别临床记录中的实体,该算法结合了SVM和CRF,实验结果表明,在同一特征条件下,基于SSVM 的临床实体识别效果比基于CRF 的临床实体识别效果更好。Zhang等人[6]提出了一种无监督的方法从生物医学文本中提取实体,该方法不依赖于任何人工制作的规则或注释数据,在两个主流的生物医学数据集上证明了其有效性,基于统计机器学习的方法相比基于规则的方法在性能上有比较大的提高,但也依赖一些规则和词典信息,故导致在实际运用中效果欠佳。
随着深度学习的流行,研究者们发现将神经网络应用于实体识别可以降低训练代价,逐渐地,深度学习被广泛应用于自然语言处理中,药物实体抽取进入新的阶段。深度学习模型一般有卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、长短期记忆网络(long short-term memory,LSTM)和BERT 模型等。RNN 使得深度学习在文本序列处理中得到了广泛应用。后由Hochreiter 等人[7]提出的LSTM解决了RNN的梯度消失和梯度爆炸的问题。Greenberg 等人[8]使用BiLSTM+CRF 在生物医学命名实体识别上取得了较为优秀的结果。此外还有许多改良版本,如BiLSTM-CRF-attention[9]、CNN-LSTM-CRF[10]等。2018年BERT诞生,其强大的泛化能力及特征提取能力使得许多研究者认为BERT 可以代替任何RNN 模型。Dai 等人[11]用BERT-BiLSTM-CRF 模型在中国电子病历中医学命名实体识别的F1评分达到0.75。尽管深度学习模型往往表现很好,但通常是基于大量标注数据的监督学习。当面临少量的标注数据时,就会出现过拟合现象,严重影响预测的准确性[12]。而半监督方式可以利用少量的标记数据扩充训练集,进而提高模型的准确率。常见的半监督学习有self-training[13]、co-training[14]和Tri-training[15]等。Gupta 等人[16]提出了一种多任务学习方法,以self-training方法对药物不良反应事件抽取进而辅助ADR 的抽取,在Twitter 数据集上F1 值达到了0.64。Deng 等人[17]提出了一种基于co-training 的方法,从中药专利摘要文本中识别出药品名称,实验表明该方法能在较低的时间复杂度下保持较高的精度。直接把self-training 应用于其他领域的效果往往不太理想,当self-training 将错误的样本分类到训练集中时,会导致错误越来越深,使用该样本反而会对模型产生干扰。co-training 需要在两个充分冗余的视图上训练学习器。而Tri-training 是co-training 的一种改进,也是一种基于分歧的方法,它不需要冗余的视图来描述实例空间,因此它的适用性比co-training算法更好。
2 模型构建
本文提出了一个基于Tri-training 的半监督社交媒体药物不良反应实体抽取模型,整体框架如图1 所示。首先使用少量的标注数据训练三个不同的基学习器Transformer+CRF、BiLSTM+CRF 和IDCNN+CRF,三个编码器负责提取深层次的语义信息,CRF层负责学习标签之间的依赖关系,以优化模型。在大量的未标注数据上对三个基学习器进行协同训练,最后将该联合学习器对测试集的样本进行标注,得到最终的标注序列,解决社交媒体文本标注数据少导致的模型性能不足的问题。其次,采用字和词两个粒度的向量作为三个基学习器的输入。使用BERT模型来获得输入文本的字向量;利用Jieba 分词工具对输入文本进行分词处理,再使用腾讯词向量得到输入文本的词向量。融合两种向量作为模型嵌入层的输入以促进语义提取,解决社交媒体文本表达口语化的问题。

图1 改进的Tri-training训练过程Fig.1 Training process of improved Tri-training
2.1 药物不良反应实体抽取的Tri-training模型
考虑到对数据进行标注的代价较高,使用半监督学习方法,只使用一小部分带标签数据促进模型对大部分未标注数据的利用。标准Tri-training使用了三个相同的学习器,首先将已标注数据集进行重复采样(bootstrap sampling)得到三个训练集,用于分别训练三个学习器,在迭代训练过程中,如果有两个学习器预测的标签一致,则认为该数据的置信度高,将其标注并送入第三个学习器的训练集中一起训练第三个学习器。
为了更好地适用于本任务,针对标准的Tri-training进行改进。首先,采用了三个不同的学习器,以实现训练结果的差异性。其次,本文采用谢俊等人[18]提出的样本选择策略,解决标准Tri-training用于序列标注任务导致的伪标签数据少的问题。采用改进的样本选择策略可以将预测不一致的样本按照比例加入训练集中用于训练学习器,解决了标准Tri-training的三个学习器很难预测一致进而导致样本选择死循环,这相比于标准Tri-training的策略更有利于充分利用未标注数据训练模型。
该策略如下:计算任意两个学习器对某一样本的一致性得分,若存在两个学习器的一致性得分相等,则将该伪标签数据加入到第三个学习器中作为训练数据;对于任意两个学习器一致性得分都不相等的样本,按30%的比例选取两个学习器一致性最低的样本集,再按30%的比例选取另外两个学习器一致性最高的样本集,取其交集送入共有的学习器中标注,最后作为与该学习器一致性最小学习器的训练数据。
整体训练如图1 所示,其中Hj、Hk、Hl为三个学习器。
首先,利用标注样本集中的数据分别训练三个学习器Hj、Hk、Hl。
然后,利用此三个学习器分别对未标注样本集U进行标注,并根据样本选择策略选出样本子集。其过程如下:
对于输入的序列X={x1,x2,…,xn},三个学习器Hj、Hk、Hl得到的标注序列分别为L1={y11,y12,…,y1n},L2={y21,y22,…,y2n},L3={y31,y32,…,y3n},其中两个学习器对样本X的一致性评价函数Ag(Xa,Xd)为:
(1)根据Hj和Hk的评价得分对所有样本进行排序,按30%的比例选择一致性评价函数最低的样本子集。
(2)根据Hk和Hl的评价得分对所有样本进行排序,按30%的比例选择一致性评价函数最高的样本子集。
(3)取这两个子集的交集,将样本送入Hk中进行标注,再将标注后的数据作为Hj的训练数据。
对另外两个学习器进行类似的操作,可得三个扩充的标注数据集。再使用扩充的标注数据集分别训练三个分类器。
重复以上迭代过程,直到U为空。得到最终的联合学习器H。
药物不良反应实体抽取的Tri-training 算法如下所示:
算法药物不良反应实体抽取的Tri-training算法
训练结束后,采用投票机制对测试集的样本进行标注,得到最终的标注序列。计算方式如下:
2.2 基学习器
为了保持三个学习器的多样性,本文采用Transformer+CRF、BiLSTM+CRF 和IDCNN+CRF 用于社交媒体药物不良反应实体抽取。使用Transformer、BiLSTM 和IDCNN 作为编码器可以充分捕捉上下文特征,将得到的特征向量作为CRF的输入最终输出每个字的标签。同时考虑到社交媒体文本的不正式性,利用字和词两个粒度的向量作为模型的输入。学习器结构如图2所示。
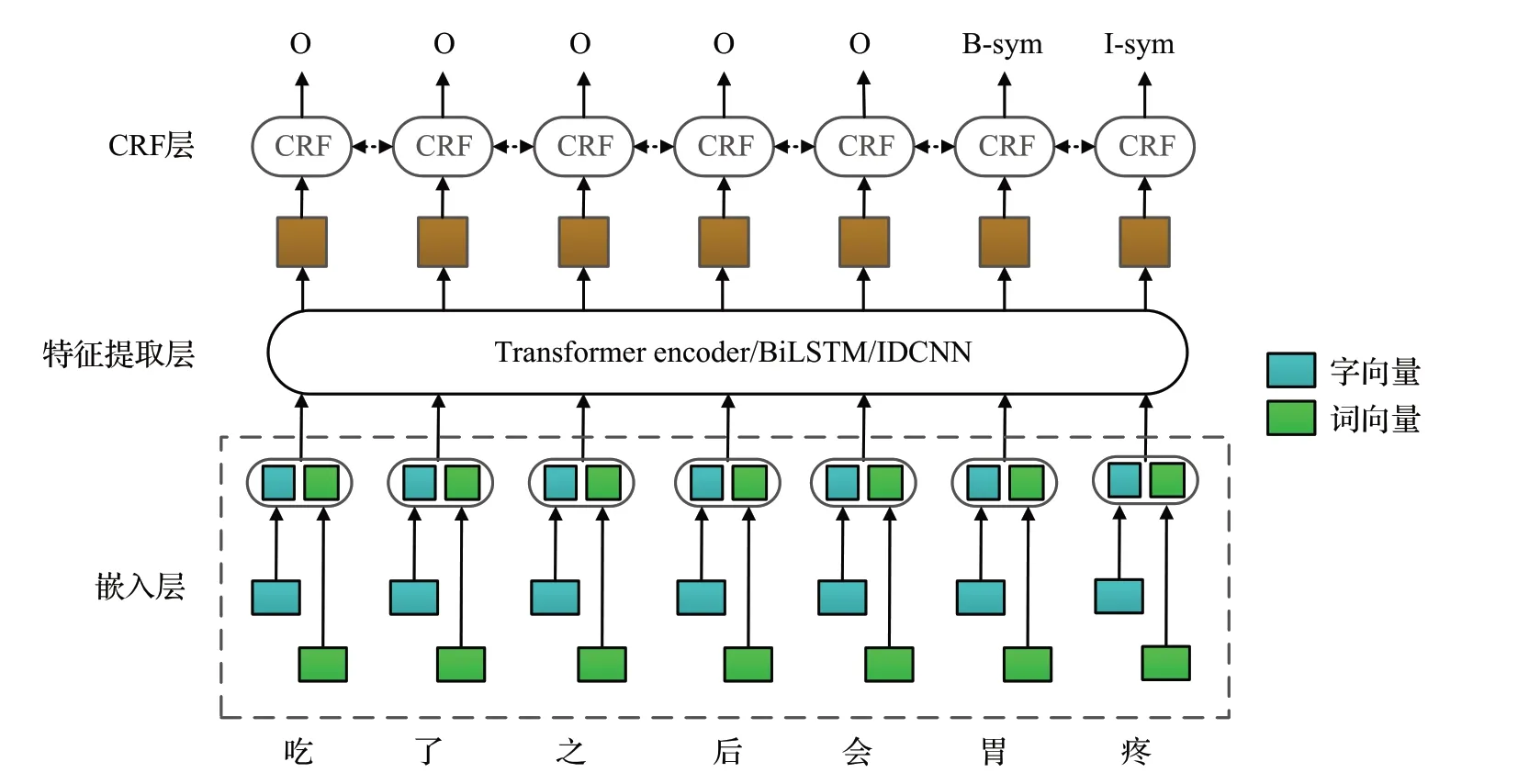
图2 三个学习器Hj、Hk、Hl 模型结构Fig.2 Structure of three learner models of Hj、Hk、Hl
2.2.1 输入层
基于深度学习的实体抽取的输入主要有字向量和词向量两种方式。对于中文来说,由于边界模糊,使用词向量产生的分词错误易产生歧义,故主要采用字向量作为输入。但是,使用字向量也有不足,字和词之间的语义表达有时差异是很大的,字向量难以捕捉到词的语义信息。由于社交媒体文本比较口语化,会导致模型性能下降,故提出结合字和词两个粒度的向量作为模型的输入来充分利用其语义信息。
BERT模型可以充分利用字符的上下文来生成字符级别的向量,充分发挥汉字的表义能力[19]。使用BERT模型来获得字向量。BERT 的输入主要由三部分组成:Token embeddings、Segment embeddings 和Position embeddings。其中,Token embeddings 是对应每个字的向量,Segment embeddings 用于区分两个句子,Position embeddings用于存储字符的位置信息。此外,在句子的开头有一个[CLS]字符,结尾有一个[SEP]字符。最后的输入是三个向量的总和。给定句子X={c1,c2,…,cn},其中ci表示句子中第i个字,最终可得到字向量Xc=。
对于词向量,首先利用Jieba分词工具对输入文本进行分词处理,再使用腾讯AI Lab 提出的腾讯词向量[20]得到词向量。由于中文的词可能包含多个字,为了使词向量与字向量对齐,为每个组成词的字重复分配该词。如图3 所示,“肚”和“子”都分配了一个“肚子”词向量。给定句子X={w1,w2,…,wn},其中wi是句子中第i个词,最终可得到词向量。
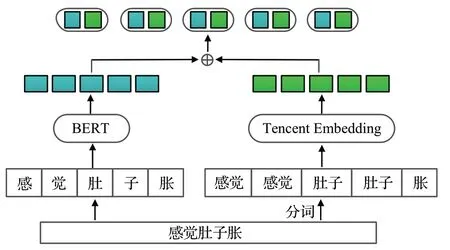
图3 模型输入表示Fig.3 Representation of model inputs
最后,将字向量与词向量拼接起来,得X=[Xc;Xw]作为编码器的输入。
2.2.2 编码器层
(1)Transformer编码器
Transformer 编码层由若干个Transformer 编码器堆叠而成,每个子层主要由多头注意力层(multi-head attention)和前馈网络层(feed forward network)组成。本文采用Transformer 编码层用于特征提取,主要是为了计算语句中字与字之间的关系从而获取全局特征信息,并且提高了模型的并行计算能力。将融合了字信息与词信息的向量X输入到Transformer 编码器中,进行特征提取。
第一个子层为多头注意力层。由于Transformer 没有卷积或递归网络结构,因此在特征提取过程中不能像它们那样对文本序列的位置信息进行编码,所以需要将位置向量嵌入到输入向量中。用不同频率的正弦码和余弦码来构造位置向量。计算方式如下:
其中,pos表示字的位置,d表示输入的维度,i为向量中每个值的索引。
将输入向量X进行线性变换,将其映射到三个不同的空间,得三个特征矩阵Q、K、V,计算方式如下:
其中,WQ、WK、WV为权重矩阵。
注意力机制为该模型的核心机制,计算方式如下:
Transformer 编码器使用的是多头注意力机制,即通过h个线性变换对Q、K、V做投影,多次经过selfattention,最后将结果进行拼接,经过线性变换之后得到输出特征矩阵Z。计算方式如下:
其中,LayerNorm为归一化函数,W1、W2为权重函数,b1、b2为偏置。
最后,得到输入序列经过编码之后的特征矩阵S作为Transformer编码器的最后输出:
为了便于后续CRF对序列的标注,在隐藏层后接入一个线性变化层,将隐状态序列从n×m维映射到n×k维,k代表标注集中所有的标签数,将结果记作矩阵A(1),计算方式如下:
(2)BiLSTM编码器
BiLSTM 是一种改进的RNN,可以解决RNN 在训练过程中的梯度消失和梯度爆炸的问题。通过引入门控机制,可以很容易发现长距离信息。通过前向和后向状态有效地利用前一个特征和后一个特征。可以更好地捕捉双向语义依赖,有效学习上下文语义信息。字嵌入序列X=(x1,x2,…,xn)作为BiLSTM的输入。
门控制单元包含遗忘门、输入门和输出门。计算方式如下:
式中,ht-1表示上一时刻的隐藏状态,xt为当前时刻的输入,Wf、Wi、Wc和Wo为权重矩阵。bf、bi、bc和bo为偏置向量。σ为sigmoid 激活函数,tanh 为双曲正切激活函数。ft表示遗忘门,决定抛弃上一时刻的那些信息。it为更新门,决定哪些值要更新。ot为输出门,决定哪些信息应该输出给外部状态ht。
BiLSTM捕获了正向语义信息和逆向语义信息,在t时刻,输出状态ht由正向LSTM 输出的ht1和反向LSTM输出的ht2连接而成:ht=[ht1;ht2]。输出隐藏状态序列H=(h1,h2,…,hn)。同样,为了便于后续CRF 对序列的标注,在隐藏层后接入一个线性变化层,将隐状态序列从n×m维映射到n×k维,k代表标注集中所有的标签数,将结果记作矩阵A(2),计算方式如下:
(3)IDCNN编码器
由于数据来自于网站的问诊,可能会包括既往病史、症状及用药情况,这就导致文本较长。尽管使用CNN在计算上有优势,但是经过卷积层之后,可能会损失一部分信息。对于长文本数据时,要提取上下文信息,就得加入更多的卷积层,这会导致网络越来越深,参数特别多,进而造成过拟合。于是采用膨胀卷积(dilated convolution)来解决这个问题。可以不通过池化加大感受野,并且减少信息的损失。膨胀卷积的概念由Yu等人[21]于2015年提出,与传统CNN在连续的窗口上滑动不同,它不需要在连续的窗口上滑动。通过在卷积核中增加一个膨胀宽度,模型的感受野随着卷积核和卷积层数的线性增加而呈指数级增加。如图4所示,图(a)与图(b)卷积核都为3,卷积层数都为两层,而膨胀卷积的上下文大小为7。不难看出,膨胀卷积可以增大模型的感受野。
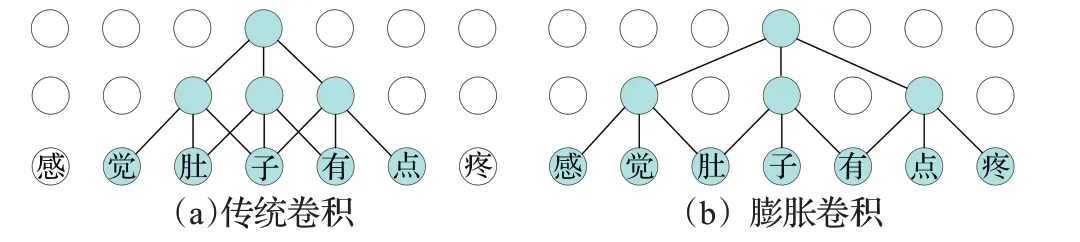
图4 传统卷积和膨胀卷积上下文大小Fig.4 Context size of traditional convolution and dilated convolution
Strubell等人[22]首次将IDCNN用于实体识别。先构建一个层数不多的膨胀模块,该模块包含几个膨胀卷积层,每一次模块的输出又作为输入重复传入模块中,即以迭代的方式重复使用相同的参数。模型既可以接收更宽的输入又具有更好的泛化能力。
对于输入序列X=(x1,x2,…,xn)首先IDCNN 第一层对输入进行转换:
其中,c(0)表示第一层的输出,表示第j层膨胀卷积,膨胀系数为δ。
然后IDCNN用Lc层膨胀卷积来构造膨胀模块,第j层膨胀卷积的输出c(j)为:
其中r()表示ReLU激活函数。
最后一层为:
将这种堆叠记作膨胀卷积块B(),IDCNN会迭代使用相同的模块Lb次提取特征,从开始,第k次迭代使用膨胀卷积块的输入为:
最终的序列输出为:
最后接入一个线性变化层,将隐状态序列从n×m维映射到n×k维,k代表标注集中所有的标签数,将结果记作矩阵A(3),计算方式如下:
2.2.3 CRF层
本文引入了条件随机场来学习标签之间的依赖关系,限制了生成标签之间的关系,得到最优标记结果。对于给定的字符序列X=(x1,x2,…,xn),定义Transformer编码器的输出为矩阵A()1,BiLSTM 编码器的输出为矩阵A(2),IDCNN编码器的输出为矩阵A(3),其大小为n×k,n为字符个数,k为标签种类。以Transformer编码器的输出A(1)为例,视作第i个字被标记为yi的概率。
输出预测结果为y=(y1,y2,…,yn)的评估分数计算方式如下:
其中,n为序列长度,M为转移矩阵,Myi-1,yi表示从yi-1标签转移到yi标签的得分。
使用Softmax函数可以得到归一化概率:
其中,为真实标签,YX表示所有可能的标签序列。
模型的目标是使正确标注序列的概率最大,训练CRF时的似然函数计算方式如下:
最终输出概率得分最大的一组序列计算方式如下:
最后,通过CRF 层输出概率最高的标签,从而得到每个字的类别。
3 实验
3.1 实验数据
目前,用于社交媒体药物不良反应实体抽取的开放语料比较匮乏,因此,自行构建了药物不良反应数据集。从“好大夫在线”网站(https://www.haodf.com/)搜集了患者的问诊记录。“好大夫在线”网站成立于2006年,旨在为患者实时提供就医参考信息。汇集了在线问诊、预约挂号、疾病知识、经验分享等功能。在线问诊又可按疾病、医院和科室找大夫问诊。用户说明疾病和用药情况等进行询问,医生在线给出相应的建议。如图5所示,问诊记录包含了用药情况、病症和接诊医生建议等信息。

图5 患者问诊记录Fig.5 Medical records of patient
根据80种常用药,包括降压药、消炎药、止痛药等,爬取了2010 年12 月31 日到2020 年3 月25 日的相关记录,得到了41 100 个文本。通过对文本进行预处理,去重整理,筛选出带药物及不良反应的文本共计6 000个,再选择其中的2 000 个文本进行人工标注,这个工作由10 名药学院的学生进行,如果对同一数据的标注不一致,则按少数服从多数的规则处理,以相同标注结果最多的标注数据作为最终的标注结果,如果对于某一数据,每个人标注结果都不同,则经过讨论后重新标注该数据,再选取相同标注结果最多的数据作为最终标注结果。将标注的2 000 个文本随机选取1 600 个作为初始训练集,另外400 个文本作为测试集。其余的4 000 个未标注文本用于Tri-training训练。
抽取出的实体为症状(Sym)实体。本文采用BIO标注法进行标注,B表示实体的开始,I表示实体的中间部分,O表示不属于实体。标注的数据分为3个类别即:“B-sym”“I-sym”“O”。表1展示了问诊记录的标注示例。

表1 样本的BIO标记示例Table 1 An example of BIO tag for sample
本文采用准确率P(Precision)、召回率R(Recall)和F1值(F1-Score)作为评价指标。其定义如下:
其中,TP表示把正例正确地预测为正例的数量,FP表示把负例错误地预测为正例的数量,FN 表示把正例错误地预测为负例的数量。
3.2 实验设置
采用pytorch深度学习框架。文本的最大长度设置为240。Bert预训练模型包含12个encoder层,多头注意力机制的头数为12,字向量维度为768。词向量维度为200。BiLSTM的隐藏单元个数为128,层数为2。IDCNN卷积核尺寸为3×3,膨胀卷积块为4,每个膨胀卷积块的膨胀卷积层为3,膨胀宽度为1、1、2。
在训练过程中,采用Adam 优化器,初始学习率为5×10-5,dropout为0.5,batch_size设置为32。
3.3 全监督模型对比实验
3.3.1 ADR实体抽取模型对比实验
为了验证三个基础学习器的有效性,分别对三个基学习器Transformer+CRF、BiLSTM+CRF、IDCNN+CRF进行了比较。还将所提出的模型与近几年来其他ADR实体抽取模型进行了比较。使用精确率、召回率和F1值作为评价指标,选取不同数量的标注数据和4 000 条未标注数据,实验结果如表2所示。

表2 ADR实体抽取模型对比结果Table 2 Results of ADR entity extraction models
BiLSTM-CRF-attention[9]:一种具有自注意机制的有监督中文医疗实体识别模型。自注意机制可以通过在每个字符之间建立直接联系来学习长期依赖关系。还在模型中引入词性标注信息来获取输入句子中的语义信息。
BERT+BiLSTM+CRF[23]:一种监督模型,通过在中文临床领域语料库上预训练BERT,并纳入了词典特征,根据汉语特征将部首特征应用于模型。
TBI+CRF:本文采用的三个学习器Transformer+CRF、BiLSTM+CRF 和IDCNN+CRF 组成的联合学习器,在训练时只使用标注数据,即进行全监督训练,训练后的联合学习器采用投票机制标注无标签数据。
由表2可知,相对于三个基学习器,联合学习器的性能有了明显的提升,其F1 值达到了0.704 7。BiLSTM+CRF+attention 模型由于加入了注意力机制,通过在每个字符之间建立直接联系来学习长期依赖关系,故相比BiLSTM+CRF 模型性能有所提升。而采用BERT+BiLSTM+CRF模型后,F1值有了明显的提升,可能是由于引入了特定领域的BERT预训练模型,而且部首特征对于药物不良实体抽取反应有一定的帮助。在标注数据量较少时,TBI+CRF 模型相比其他模型也能有较好的性能,可能是因为有三个学习器,对样本进行选择以后,准确率有所提高。随着标注数据量的增多,性能也有明显提升。这充分说明,本文的模型应用于标注数据少的社交媒体药物不良反应实体抽取任务有较好的效果,并且能充分利用未标注数据。
3.3.2 消融实验
为了进一步分析输入对学习器性能的影响,对输入进行了消融实验,实验结果如表3所示。

表3 消融实验结果Table 3 Ablation experiment results
(1)“-word”:去除输入中的词向量。直接通过BERT得到每个字的向量,作为模型的输入。
(2)“-character”:去除输入中的字向量。利用Jieba分词工具对输入文本进行分词处理,再使用腾讯AI Lab提出的腾讯词向量得到词向量,作为模型的输入。
由表3 可知,当去除词向量后,模型的性能有一定程度的下降。如前所述,字向量已经被证实对于中文社交媒体实体抽取的效果好于词向量,但是字向量可能会学不出词语间的关系。仅仅使用字向量不能充分理解句子的上下文表示。去除字向量后,模型的性能又一次下降,这表明由于社交媒体文本不正式,存在口语化内容,使用词向量存在边界模糊,产生的分词错误易产生歧义,而且词向量的信息粒度大,学不出字符级别的语义信息。
3.4 半监督模型对比实验
为了验证所提出的模型能充分利用少量的标注数据进行学习,对比了全监督方法与各半监督方法在不同标注数据情况下的性能。实验选取不同数量的标注数据和4 000条未标注数据,实验结果如表4所示。

表4 不同标注数据量下各模型对比结果Table 4 Results of each model under different amount of annotated data
co-training[24]:一种基于分歧的半监督学习方法。选择本文性能较好的两个学习器Transformer+CRF 和BiLSTM+CRF,首先利用有标签数据训练其中一个学习器,再使用该学习器挑选最有把握的数据赋予伪标签,将伪标签数据提供给另一个学习器进行训练,通过共同学习,共同进步的迭代过程,直到两个学习器不发生变化。
self-training[16]:一种简单的半监督学习方法。使用本文性能最好的一个学习器Transformer+CRF,首先利用有标签的数据训练模型,再利用该模型选出最有把握的数据进行标注,将标注的数据作为训练数据加入到模型的训练集中,重复迭代过程,得到最终的学习器。
Π-MODEL[25]:简单的一致性正则半监督模型,同一个无标签数据前向传播两次,通过数据增强和dropout加入随机噪声,得到不同的预测,Π-MODEL 希望这两个预测尽可能一致。本文通过输入两次Transformer+CRF网络,其中一次利用dropout,对比两次预测结果的差异,调整网络参数。
Tri-training:标准Tri-training模型。
Ours:本文提出的模型,在训练时加入未标注数据,即进行半监督训练。
由表4 可知,co-training 模型、self-training 模型和Π-MODEL 模型在刚开始标注数据量少时,其性能较低,随着标注数据量逐渐增多,性能逐渐提升,但是相比于本文的模型F1 值也相差了0.063 1,可能是因为模型产生的伪标签噪音非常的大,使模型朝着错误的方向发展。而本文提出的模型通过三个学习器对标签进行投票,提高了标签的质量。相比于Π-MODEL 模型,在标注数据量较少时,本文的模型也能有较高的准确率。随着标注数据量的增加,Π-MODEL模型与本文的模型性能逐渐接近。本文模型的F1 值相比于标准Tri-training模型提高了0.074 2,可能是因为标准Tri-training模型的样本选择策略为两个学习器具有相同答案才会加入另一个学习器中,不太适用于命名实体识别任务,而改进的Tri-training模型更适用于本任务,这进一步验证了改进的样本选择策略的合理性。而且,在标注数据量相等时,本文提出的模型在半监督的情况下比在全监督的情况下,性能提升了0.027 8,说明本文的模型能充分利用未标注数据,能减弱标注数据量少带来的影响。而随着标注数据逐渐增多,更是验证了这一结论。
4 结束语
本文提出了一种基于Tri-training的半监督社交媒体药物不良反应实体抽取模型。该模型利用Tri-training的半监督的方法结合三个学习器进行社交媒体药物不良反应的实体抽取,解决了社交媒体大量未标注语料标注成本高的问题,减小了研究成本且提高了预测效果。此外,利用了字向量和词向量两个粒度的丰富语义信息,解决了社交媒体文本口语化造成的噪声问题。所提出的模型在“好大夫在线”网站获取的数据集上取得了较好的结果,验证了该模型的有效性。下一步的研究工作中,将进一步融合其他特征如偏旁部首等信息进行实体抽取,探究其对模型性能的影响。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中国外汇(2019年18期)2019-11-25
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
公民与法治(2016年10期)2016-05-17
