
基于情感特征增强的中文隐式情感分类模型
2024-03-03 11:21谈光璞朱广丽韦斯羽
计算机工程与应用 2024年3期
谈光璞,朱广丽,韦斯羽
安徽理工大学 计算机科学与工程学院,安徽 淮南 232001
情感分析作为自然语言处理领域中的一个研究热点,主要是对带有情感色彩的主观文本进行情感识别的过程,在评论分析、民意分析和基于内容推荐等领域具有巨大的实际应用潜力。它根据人们情感的主观性和客观性将情感分为显式情感和隐式情感。显式情感分析受到学术界和工业界的广泛关注和研究,但隐式情感分析仍处于起步阶段,面临着一定的挑战。
显式情感与隐式情感的主要不同在于表达情感时是否包含显示情感词。显式情感具有明显的显性情绪词,能够直接剖析和研究表达文本所包含的情感倾向。然而,通常情况下,人们倾向于以一种含蓄的方式来表达自己的情感,文本中不包含情感词语,但所包含的情感却丰富而抽象,很难直接判别情感极性。表1给出了隐式情感文本的两个例句。

表1 隐式情感文本例句Table 1 Implicit sentiment example sentence
句1 中包含一种隐式的积极情绪,“包揽”“所有金牌”两词虽然不带情感色彩,实则表达开心;句2中包含一种隐式的消极情绪,对不能参观奥运而表示遗憾。虽然在语句中找不出明确的情感词,却仍能表达出不同的情感类别。
目前,有关隐式情感分析逐步受到外界的关注,隐式情感文本所面临的主要挑战有:(1)缺乏情感词,情感特征提取困难;(2)无法深入挖掘文本的语义特征。
基于以上考虑,本文提出一种基于情感特征增强的中文隐式情感分类模型。目的是通过构建积极和消极情感词库,并将情感词进行位置嵌入得到情感特征增强的句子,进而提高分类准确率。本文提出CISC 模型的具体框架如图1所示。

图1 CISC模型框架图Fig.1 CISC model
主要由预处理层、数据处理层、特征处理层、分类层组成:
(1)预处理层:采用Jieba工具对文本进行预处理和分词,通过自注意力机制对句子中的每个词进行权重分配,并将两种词库中的词分别加入到词语序列中权重值最大的词前方,得到两个新的词语序列。
(2)数据处理层:将结合后的词语序列输入到数据处理层,利用Word2Vec 和多层注意力网络(hierarchical attention networks,HAN)对其进行情感特征增强的句子的构建。
(3)预处理层:采用Jieba工具对文本进行预处理和分词,通过自注意力机制对句子中的每个词进行权重分配,并将两种词库中的词分别加入到词语序列中权重值最大的词前方,得到两个新的词语序列。
(4)数据处理层:将结合后的词语序列输入到数据处理层,利用Word2Vec 和多层注意力网络(HAN)对其进行情感特征增强的句子的构建。
(5)特征处理层:通过Bi-GRU对句子的深层特征表示进行获取,并使用AOA抽取多种信息中的重要特征,后输入到分类层中。
(6)分类层通过Softmax 对句子进行情感倾向的概率计算,通过将结合积极词句子的正向情感概率与结合消极词句子的负向情感概率进行均值计算并比较,得到最终的情感倾向。
本文的主要贡献包括:
(1)构建两种情感词库和多层注意力网络以增强句子中的情感特征。将原始句子的词语序列分别结合积极词库中的积极词和消极词库中的消极词,并利用多层注意力网络来生成对应的情感特征增强的句子,有利于对隐式情感文本的情感极性进行更好判断。
(2)使用Bi-GRU-AOA 模型以深入挖掘语义特征。使用Bi-GRU对句子深层特征表示进行获取,使用AOA抽取多种信息中的重要特征,提高针对隐式情感文本进行分类的准确率。
1 相关工作
目前,有关情感分析的研究大多只关注显式情感,对隐式情感的研究极其有限,因此对隐式情感分析的研究仍处于初始阶段。然而随着对自然语言处理领域的深入研究,对隐式情感分析研究的关注度也逐步提高。相关工作主要从情感分析和隐式情感分析两个方面对隐式情感分析工作进行研究。
1.1 情感分析方法
情感分析对蕴含情感特征的文本进行分析处理的一个过程,对于文本进行情感分析,可以更好地了解到人们对于某件事情或是某个物件的接受程度。Dauphin等人[1]利用卷积神经网络对较长的文本进行分析,这个过程是基于门控机制的。Zhang等人[2]通过对单层CNN的敏感性进行分析,探讨了超参数这个指数对文字情绪分类的影响。Ma 等人[3]旨在从低维异构网络中学习有意义的表示向量,从而实现网络结构和属性特征的提取。Yao 等人[4]构建了一种文本分类模型,该模型基于图卷积神经网络,利用词语之间的共现关系与待分析文本的联系,从而构造了文本图谱。Chen等人[5]使用图卷积神经网络和注意力机制对方面级的情感分类任务进行处理分析。
Wang等人[6]为了解决CNN 和RNN 的缺点,提出了一种DRNN模型,它能够同时获得长距离依赖性以及关键文本信息。Devlin等人[7]设计了一种具备更高泛化能力的BERT 模型,并在后续的应用中得到了广泛的应用。Sun 等人[8]对句子情绪极性差异进行了分析,并给出了一种以多极正交注意力为基础的LSTM 隐式情感分析方法。Wang 等人[9]构建了一种HKEM 模型,利用分层知识强化将文本中的不同层面的知识信息进行全面的整合,从而减轻了“弱特征”的问题。Zhuang等人[10]为了更好地获取句子的语义信息,考虑了上下文信息、句法信息和语义信息的融合,并提出了一种新型神经网络模型。
在利用卷积神经网络对隐式情绪特征进行提取时,池化运算将失去句子的位置特征[11],注意力机制在这时将发挥着关键作用[12]。Xiang 等人[13]在此基础上,提出了一种以注意力神经网络为基础的事件隐式极性分析方法,此模型首先使用门控神经网络的学习句子来表达,再利用注意机制捕捉到与情绪极性紧密有关的多个方面。赵容梅等人[14]利用卷积神经网络对文本进行特征提取,与LSTM结构的上下文信息相结合,并运用注意力机制,建立了一种新的混合神经网络模型,从而实现了对隐式情感的分析。
1.2 隐式情感分析方法
隐式情感分析是指文本在不具有明确的情感词下进行的任务分析,且大多数语料库资源是针对隐式情感分析任务进行构建的。He等人[15]采用一种改进的贝叶斯模型,对文字中的隐藏题材和情绪极性进行分析。Liao 等人[16]通过对事实型隐式情感在句子层次的识别分析,给出了一种以表达学习的多级语义融合法来学习识别特征。郭凤羽等人[17]在认知学相关理论的基础上,给出了一种基于语境的交互感知与模式筛选的隐式篇章关系识别方法(MATS),可以有效地提高模型的识别能力。Rana等人[18]利用了一种基于共现和相似的技术,对隐含情绪任务极性分析,并基于共现和相似性的技术,提出了一种对文字隐含的情绪进行识别的方法,着重于对使用者观点的隐含线索和使用者观点的实际目标隐含的方面线索进行分析。Zhang等人[19]提出了一种以视点信息单位为基础的层次情绪分类方法,以关键语作为隐式评估对象的识别依据。有助于使用者在方面层次上的情感分析做出较好的决定。
随着神经网络的迅速发展,采用神经网络模型对隐式情感文本进行分析,从而有效地改善对于中文隐式文本的进行分类的准确率。Wei等人[20]提出了一种多极性正交注意的BiLSTM 模型,相对于传统的单一注意模式,采用多极性注意可以辨识出词与情感化趋势的不同,并运用正交限制机制来确保优化过程中可以有效地提高性能。可以较好地应用于隐式情感分析。Zhao等人[21]提出了一种融合CNN和门限值递归单元的的情感分析模型。具有很好的应用前景。Yuan 等人[22]构建了中文隐式情感分类模型GGBA,利用门控卷积神经网络(GCNN)对隐式情感句进行局部重要的信息提取,并利用门控循环单元(GRU)网络提高特征的时序信息。黄山成等人[23]针对隐式情感文本极性与句中实体、情感特征增强的句子和外部知识的相关特征,提出了一种ERNIE2.0-BiLSTM-Attention(EBA)隐式情感分析方法,可以很好地反映出隐式情感句的语义和上下文信息,从而有效地提高其识别能力。Chen等人[24]针对目前的序列化模型,对中文隐式情感分析中特性信息的提取不精确性,给出了一种基于双向长短时神经网络与上下文感知的树形递归神经网络的并行混合模型,该模型能有效地改善分类精度、时间代价少、性能得到较好的改善。
Yang 等人[25]第一次提出层次注意力网络。杨善良等人[26]提出基于图注意力神经网络的隐式情感分析模型ISA-GACNN,通过构建文本和词语的异构图谱,使用图卷积操作传播语义信息,并利用注意力机制针对词语对在整体情感上的影响程度进行计算。潘东行等人[27]根据隐式表达对上下文内容的依赖性,设计了一种融合上下文语义特征和注意力机制的分类模型,增强了部分中立性隐式表达句的分类效果。
基于以上研究分析,目前的方法虽能很好地对包含隐式情感的文本进行分类,但是仍然存在着一些缺陷,例如:分类精度较低等。本文通过引入情感词来增强句子中的情感特征以及加入Bi-GRU-AOA 模型来提高分类准确度。
2 情感特征增强方法
针对隐式情感语句进行情感分析时,由于缺乏情感词,句子中所表达的情感一般比较含蓄,不容易去进行分析,传统的分析中文隐式文本的方法主要是结合语义分析或上下文特征来进行的,没有考虑到情感特征增强的句子的问题,因此,本文考虑将情感词作为一个重要的特征加入到原有的词语序列,传入到多层次注意力网络中,构建出更符合隐式情感文本语义的情感特征增强的句子,从而提高中文隐式情感句子的分类准确率。
2.1 情感词库构建
情感词库的构建方法主要有人工标注、基于词典的方法和基于语料库的方法,但由于人工标注费时费力,因此基于词典和基于语料的方法使用较多。将使用基于词典的方法对本文所需词库进行构建,且该词典为网上公开资源的“情感词典及分类”词典。基于已有的词典,下面将给出积极和消极两个词库的构建过程。
(1)情感种子词库构建
使用TF-IDF 算法构建种子词库,并选定少量初始正面种子词和初始负面种子词,且选定的种子词情感性倾向较为强烈,具有代表性,以免混入过多噪声。例如:积极词为“好”,消极词为“差”。部分情感种子词如表2所示。

表2 部分情感种子词Table 2 Part of sentiment seed word
(2)情感倾向点互信息算法(SO-PMI算法)
通过SO-PMI算法输出积极情感候选词词库和消极情感候选词词库。
先计算两个不同的词在已有词典中同时出现的概率,如公式(1)所示:
接着计算已有词典中的每个词与积极和消极情感种子词库中的每个词的PMI,观察这个词是更接近积极情感词库,还是更接近消极情感词库,如公式(2)所示:
其中,word1,word2表示已有词典中两个不同的词,P(word1)、P(word2)分别表示在已有词典中word1、word2出现的概率,PMI 为word1与word2同时出现的概率,且两个词出现的概率越大,其相关性越大。公式(2)中,num(pos)和num(neg)分别指的是积极基准词的总数和消极基准词的总数。PMI(word)表示在已有词典中word 出现的概率,PMI(Posj)表示第j个积极基准词出现的概率,PMI(Negj)表示第j个消极基准词出现的概率,word指随便一个词。当SO-PMI >0,表示这个词更接近正向,即为积极词;当SO-PMI=0,表示这个词为中性词;当SO-PMI <0,表示这个词更接近负向,即为消极词。
(3)情感词库
经过计算,按照SO-PMI值对情感词进行从大到小的排序,并根据情感强度进行抽取,从1 到5 分为五档,1 表示强度最小,5 表示强度最大。分别各选取20个形容词性积极和消极情感词构建成积极情感词库和消极情感词库。情感词库构建的部分算法如算法1所示,积极情感词库如表3 所示,消极情感词库如表4所示。

表3 积极情感词库Table 3 Positive sentiment lexicon

表4 消极情感词库Table 4 Negative sentiment lexicon
算法1情感词库构建部分算法
2.2 多层注意力网络
中文隐式情感句子中所蕴含的情感表达,通常不止是依赖于句子本身的语义,如表5 所示,句子所处的不同语境对句子中所表达的情感也是有很大影响的。中文隐式情感句的语境信息在判断句子本身情感时起到了关键作用。

表5 不同语境下的隐式情感句Table 5 Implicit sentiment sentences in different contexts
为了更好地构建隐式情感句的情感特征增强的句子,本文将两种极性的情感词分别加入到隐式情感句中,并构建多层注意力网络来更好地生成情感特征增强的句子。
多层注意力网络的整体网络结构如图2所示。

图2 多层注意力网络Fig.2 Hierarchical attention networks
3 基于情感特征增强的中文隐式情感分类模型
为了解决隐式情感语句缺少情感词以及情感分类准确率低的问题,本文提出一种基于情感特征增强的中文隐式情感分类模型,如图3 所示,对中文隐式情感语句进行判别,有效地提高了情感分类效果。
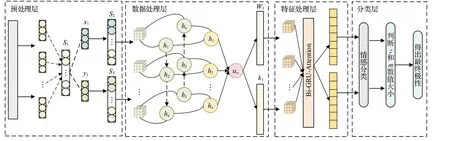
图3 CISC模型示意图Fig.3 Illustration of CISC
3.1 模型介绍
本文首先将待处理句子输入到预处理层进行预处理,排除影响句子进行情感分析的一些因素,例如:删除特殊字符、繁体字转简体字等。随后对预处理后的句子进行分词,从而得到词语序列S1。然后,在数据处理层将两种词库中的词分别加入到词语序列S1中,得到词语序列S2和S3,使用Word2Vec 将S2、S3转换为词序列,借助多层注意力网络(HAN)构建出S2、S3的情感特征增强的句子并输入到特征处理层;进一步,在特征处理层将处理后文本使用Word2Vec 转换为词向量后利用双向门控循环单元(Bi-GRU)+交互注意力机制(attention-over-attention)充分提取语义特征,输入到分类层;最终在分类层中通过计算分别得出两个句子的两种极性概率,并对两种情感词库中的情感词分别结合文本所得出的情感极性概率进行平均值计算,通过对比隐式情感句子结合两种词库所得到的平均值,得出隐式文本的最终情感极性。
3.2 数据预处理层
设原始语句为S,使用Jieba 工具对语句S进行去除特殊字符、繁体字转简体字等预处理操作,并分词后得到的词语序列设为S1,用Wi表示词语序列中的第i个词。词语序列S1如式(3)所示:
在词语序列S1的基础上,设积极情感词库为xa,消极情感词库为ya,其中a∈[1,20]。利用自注意力机制的情感词检测方法,将句子中的每个单词经过Encoder编码,对句子中权重最大的词进行定位,设为Wβ,其中β∈[1,i],然后将积极和消极情感词库中对应位置的第一个词x1、y1分别加入该词前方,得到词语序列S2、S3,如式(4)、(5)所示:
预处理部分算法如算法2所示,具体的处理过程如图4所示。

图4 预处理示意图Fig.4 Illustration of preprocessing
算法2预处理部分算法
3.3 数据处理层
设隐式文本句子分别和两种情感词构成句子的情感特征增强的句子为jv、kv。
使用Word2Vec 将词语序列S2、S3分别转换为词向量并输入到多层注意力网络中去,从而得到隐式文本句子分别和两种情感词构成句子的情感特征增强的句子为jv、kv。
多层注意力网络由词序列编码层、词级注意力层、句子表示层,三个层次组成。
(1)词序列编码层
设词语序列S,用Wi表示词语序列中的第i个词,t表示词语序列中的词语的数量。使用Word2Vec 工具将Wi映射为词向量Ci,词语序列中第i个词的双向隐藏层拼接矩阵Ri的计算公式如公式(6)、(7)、(8)所示:
其中,GRU为正反向读取每个单词的嵌入向量,hri和hli分别为前一时刻获得的正反向隐藏层输出。
(1)词级注意力层
设词语序列S的词权重矩形为DW,使用单词级别的注意力权重计算方式,具体计算公式如公式(9)、(10)所示:
其中,∂i为词语序列S中第i个单词的注意力分值,Si表示隐藏层向量,ui表示Si在词注意力层的隐含表示;uw表示一个初始化用以表示上下文的向量。
(3)句子表示层
句子S的编码如公式(11)所示:
3.4 特征处理层
如公式(12)、(13)、(14)所示,使用Bi-GRU,在两个不同方向的GRU 上进行计算,从而提取出构建语句中的重要特征,最终将两个不同方向的隐藏层计算结果合并输出。
其中,Bi-GRU在t时刻的隐藏层输出ht是hrt和hlt的串联。
为了加强对句子内部结构的特征学习,使注意力权重矩阵分布更加准确,本文采用了交叉注意力机制。计算公式(15)、(16)如下:
其中,Ke为关键词矩阵,Ve为值矩阵,ma∈{1,2,…,he},ja∈{1,2,…,he},he为多头注意力head的数量,为交叉注意力,dke为ke的维度。
将所有head 特征拼接并使用线性变换进行特征学习,得到Hmulti,并输入到分类层中。计算公式如式(17)所示:
其中,Wo用于将串联的多头特征转换到词嵌入的维度后。
3.5 分类层
设加入积极词后隐式文本为积极的概率为Mv,加入消极词后隐式文本为消极的概率为Nv。设v=1,情感词库中词的个数为q。
使用softmax分类器对隐式情感句子分别结合两种情感词所构成的句子进行情感极性的判断,分别得出Jv为积极和Kv为消极的概率Mv、Nv,并进行求和计算,求和结果如式(18)、(19)所示:
将v+1 后,重复3.1 至3.4 节步骤,当v=q时,将Z和G分别除以q,得到平均值并比较,最终得出隐式情感句子的情感极性。对句子进行情感分析的具体步骤如图5所示。
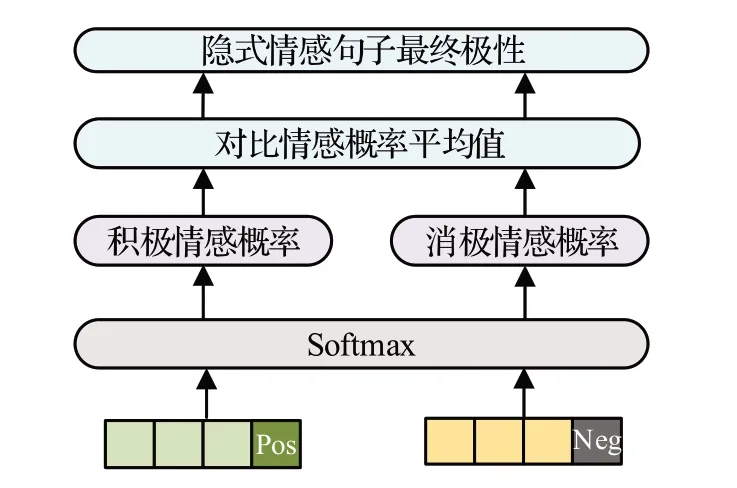
图5 情感分析层Fig.5 Sentiment analysis layer
使用softmax分类器进行情感分类步骤如下:
其中,T为隐式情感句子分别结合两种情感词所构成句子的隐含表示,Q为概率值,wT为权重,bT为偏置。
本文使用的损失函数为:
其中,LOSS表示损失函数输出的结果,egc为真实标签,e为预测标签。
4 实验及结果分析
为了验证本文提出的基于情感特征增强的中文隐式情感分类模型的效果,选取了网上公开的SMPECISA2019(https://download.csdn.net/download/qq_41479464/85825618?spm=1001.2014.3001.5503)数据集进行对比实验。
4.1 实验数据
数据集:选用公开的SMP-ECISA2019数据集,包含超过20 000 多条各种极性的隐式情感句子。数据来源主要包括评论网站、休闲网站、产品交流,主要领域包括比赛、节日、评论、旅游等。部分实验数据如表6 所示,数据标注详情如表7所示。

表7 实验数据统计Table 7 Statistics of experimental data
4.2 评价指标
实验采用准确率P、召回率R以及F1 指数。如公式(23)~(25)所示:
其中,TP为被模型预测为正类的正样本;TN为被模型预测为负类的负样本;FP为被模型预测为正类的负样本;FN为被模型预测为负类的正样本。
4.3 实验方法
为了验证本文提出的基于情感特征增强的中文隐式情感分类模型的效果,本文以网上公开的SMPECISA2019数据集为研究对象进行实验,设v=1,情感词库中词的个数为q,具体实验操作如下:
步骤1对于原始句子进行预处理。去除特殊字符、繁体字转简体字等并分词,得到词语序列S1,将两个词库中对应位置的第一个词Xv、Yv分别加入词语序列中,得到词语序列S2、S3。
步骤2构建情感特征增强的句子。利用层注意力网络根据词语序列2、3 分别构建情感特征增强的句子Jv、Kv。
步骤3特征处理。利用Bi-GRU+AOA 分别提取wv、kv句子深层特征并并输入到下一层进行情感分析。
步骤4情感分类。使用softmax 分类器对Jv、Kv进行情感极性的判断,分别得出Jv为积极和Kv为消极的概率Mv、Nv,并进行求和计算。
步骤5将v+1 后,重复步骤1~步骤4,直到v=s为止,然后将Z和G分别除以q,得到平均值并比较,最终得出隐式情感句子的情感极性。
为了验证本文提出的基于情感特征增强的中文隐式情感分类模型的有效性,将本文提出的模型得到的实验结果与GGBA[22]、EBA[23]、CA-TRNN[24]、ISA-GACNN[26]四种模型进行对比实验。
4.4 实验结果及分析
根据4.3节的实验方法,本文做了如下实验:
从NLP的官方数据集中选择了SMP-ECISA2019数据集,采用Jieba 和Word2Vec 获取两组词向量,将这两组词向量传入层注意力网络中,得到对应的情感特征增强的句子,将其输入到Bi-GRU-AOA 模型中去,得到对应的特征向量,将特征向量输入到分类层中求取不同极性的概率,并计算平均值后进行对比,从而得出最终极性。本文提出的模型CISC 与GGBA、EBA、CA-TRNN三种模型进行了对比实验,实验环境基于相同的硬件设施和环境配置。实验结果如表8所示。
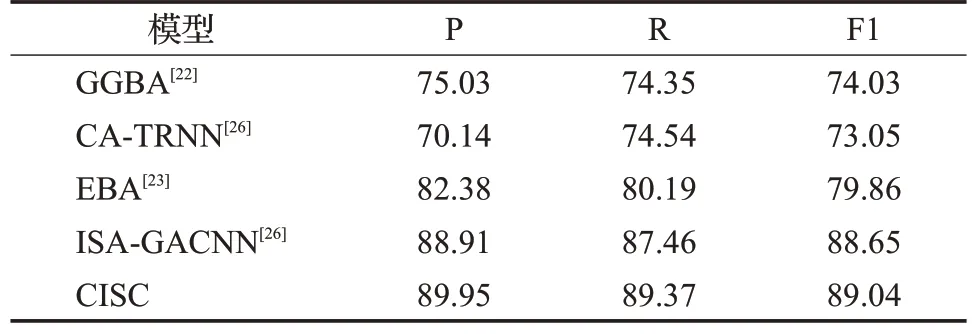
表8 在SMP-ECISA2019数据集上对比实验结果Table 8 Results on SMP-ECISA2019 单位:%
从表8 中关于“SMP-ECISA2019 数据集”的实验结果中可以得出以下结论:提出的模型在SMP-ECISA2019数据集上的F1 值达到89.04%,比ISA-GACNN 模型高出约0.39个百分点,P值提升了1.04个百分点,R值提高了1.91 个百分点。基于情感特征增强的中文隐式情感分类模型在P值、R值以及F1值上均有一定提升。对于隐式文本的情感分类准确率得到提升的一个重要原因是本文提出的模型考虑了情感词的引入,并利用层注意网络生成情感特征增强的句子,充分考虑了待分析句子与不同情感词的关联度,深度挖掘了隐式文本的语义特征。
4.5 消融实验
为验证本文提出的基于情感特征增强的中隐式情感分类模型的有效性,进行了消融实验,实验结果如表9所示。
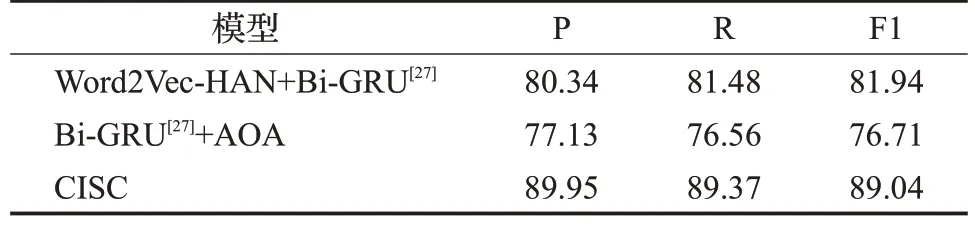
表9 消融实验结果Table 9 Results of ablation experiment 单位:%
(1)Word2Vec-HAN+Bi-GRU。为了验证交互注意力对于深入挖掘语义特征方面的影响,对比了在没有交互注意力机制下的效果。从表9中可见,F1值与本文提出模型CISC相比降低了7.1个百分点,由此可以证明交互注意力在本文情感分类模型中的有效性。
(2)Bi-GRU+AOA。为了验证层次注意力网络对于隐式情感分类模型中情感特征增强的作用,本模型在使用Bi-GRU 的基础上,只保留了AOA。从表9 中可见,F1值与本文提出模型CISC相比降低了12.33个百分点,由此可以证明构建的情感特征增强的句子在本文提出模型CISC中的有效性。
上述实验分析表明,本文所提的一种基于情感特征增强的中文隐式情感分类模型表现最佳。
5 总结与展望
为了更好地对隐式文本进行分析处理,提高针对隐式情感文本进行极性判断的准确率,了解人们的深层语义,本文提出了一种基于情感特征增强的中文隐式情感分类模型,将不同的情感词分别引入到待处理句子中去,共同生成上下文语义,通过判断两个合成句子的情感极性,得出最终的情感极性,提高了对于隐式情感文本进行分类的准确率。
未来,针对本文提出的基于情感特征增强的中文隐式情感分类模型,将对分类效率进行进一步改进,推进隐式情感文本的语义挖掘、特征提取等工作。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
小雪花·成长指南(2022年1期)2022-04-09
小天使·一年级语数英综合(2020年4期)2020-12-16
动漫界·幼教365(大班)(2020年7期)2020-06-26
传媒评论(2017年3期)2017-06-13
电脑爱好者(2017年5期)2017-05-04
英语知识(2016年1期)2016-11-11
第二课堂(课外活动版)(2016年2期)2016-10-21
传奇故事(破茧成蝶)(2015年7期)2015-02-28
网友世界(2009年12期)2009-03-05
