
面向采购文件的跨模态图片文本命名实体识别
2024-03-03 11:21于绍文
计算机工程与应用 2024年3期
杨 赛,刘 昕,于绍文
1.鑫方盛数智科技股份有限公司,北京 102600
2.爱丁堡大学 商学院,英国 爱丁堡EH8 9JS
3.中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580
随着大数据、物联网和人工智能等技术的广泛应用,面向未来的端到端数字化供应链正在转型,打造智能化、数字化、环境升级绿色低碳化的全新采购体验是数智化采购趋势。在各行业领域存在大量电子文档和印刷后形成的纸质文档资料,如采购文件和报价文件中的营业执照、资格证书等图片,这些图片中包含一些重要的有价值的信息,如何将这些图片文字识别为含有语义的文本,提取图片文本命名实体是非常有意义的工作。
要从电子文档资料和图片中提取命名实体,需要图像到文本的跨模态处理技术。首先应用光学字符识别(OCR)技术从图片文本中识别出字符,然后针对字符构成的文本进行命名实体识别。光学字符识别是用计算机自动辨别写在或印在纸(或其他介质)上的文字。由于印刷资料随着时间推移会出现文档色彩退化、拍照或者扫描时不清晰、文档中旧的排版格式以及美工处理等问题,这些文件被OCR识别时会出现字符错误、字符错位、不同字符序列混编等情况,直接进行命名实体识别准确率不高。
传统的光学字符识别技术通常使用OpenCV 算法库[1],通过图像处理和统计机器学习方法提取图像中的文字信息,使用二值化[2]、连通域分析[3]和支持向量机[4]等技术。基于深度学习的光学字符识别技术主要有CRNN(convolutional recurrent neural network)OCR[5]和Attention OCR[6]两类技术。CRNN 由一个CNN 和一个Bi-LSTM组成。Attention OCR使用Attention LSTM作为识别算法。LSTM 非常适合于解决序列的对齐问题,广泛应用于序列模型进行编码和解码。而注意力机制在帮助模型解码特定字符时,将注意力集中在图像中该字符对应的像素点位置。目前最常用的开源OCR系统,如Calamari[7]、PERO OCR[8]和Paddle OCR都是基于卷积神经网络(CNN)和长短期记忆网络(LSTM)。光学字符识别(OCR)软件可以识别图片中的文字,但没有进一步获得文字的语义信息。
自然语言处理中的命名实体识别有成熟的研究方案,包括隐马尔可夫模型[9]、条件随机场[10]、支持向量机[11]、最大熵模型[12]、基于CNN-Bi-LSTM-CRF[13]和基于Bi-LSTM-CRF的神经网络等模型[14]。然而,自然语言处理中的命名实体识别技术只对文本类型的数据进行命名实体抽取。
光学字符识别和自然语言命名实体识别技术都相对比较成熟,但是OCR 识别出的字符直接用自然语言命名实体识别技术识别出的命名实体准确率不高,需要从字符识别到命名实体抽取的一整套技术,获取图片中的关键信息,但是跨模态的图片文本命名实体识别技术目前研究较少,大多集中在对历史报纸资料、发票、情报等少数具体行业,这些研究通常将OCR 与深度学习模型结合识别相关领域的命名实体。孙绍丹[15]使用OCR识别出历史报纸资料的文本数据,用BIOES标签方法标注文本数据后,送入Bi-LSTM-CRF 模型并识别出历史报纸资料中的人物、机构、时间等实体。Boros等[16]针对法语历史报纸资料,识别其中的人名、标题等命名实体。肖连杰等[17]面向情报学PDF 文档,使用Lighten PDF Converter OCR 软件,结合Bi-LSTM 方法实现各种情报分析方法名称识别。Rouhou 等[18]提出了一种基于Transformer 的方法进行手写文件的命名实体识别。但是由于OCR识别的文字中存在拼写错误、语法错误、不同字符序列混编等问题导致命名实体识别准确率不高。对此,有学者研究了OCR噪声对命名实体识别的影响,Miller 等[19]训练了隐马尔可夫模型,在字符级别上对OCR 数据进行识别,字符错误率越高,F1 值越低。Ahonen 等[20]使用芬兰国家图书馆的历史报纸资料作为实验对象,经过使用模糊字符串匹配算法处理OCR 产生的错误单词,通过在词典中找到更正的单词对错误单词处理,但是历史报纸资料因保存原因存在过多OCR识别错误单词,该算法准确率仍有待提高。
针对以上问题,面向采购文件和报价文件中的营业执照等资格审核资料中存在评标使用的关键信息,本文使用Paddle OCR v3模型识别文档中的光学字符,自动对不同字符序列组混编文本字符进行图片文本边界设计,将边界内文本字符映射为词向量,构建O2V2BLC跨模态命名实体识别模型,通过捕获上下文语义获得图片文本的关键信息,应用条件随机场约束字符标记序列,实现资质文档资料中的跨模态命名实体识别,能够极大节省评标时的人力劳动,提高处理效率和准确率。
1 相关工作
传统的命名实体识别技术主要指自然语言处理中的命名实体识别,是针对文本数据的命名实体进行识别,从图片中直接识别命名实体是跨模态命名实体识别,相关研究较少,本文对自然语言中的命名实体识别和跨模态命名实体识别研究进行了梳理。
1.1 自然语言中的命名实体识别
自然语言处理的命名实体识别方法主要包括基于规则的方法,基于序列标注的统计概率方法和深度学习方法。然而,基于规则的命名实体识别方法过多依赖于领域专家制定的规则方法,难以应用在不同领域。因此,国内外研究主要集中在统计概率方法和深度学习方法上。
基于统计概率的命名实体识别方法,通过分类统计模型将命名实体的识别问题转为一个分类问题进行求解,主要包括隐马尔可夫模型(HMM)、条件随机场(CRF)、支持向量机(SVM)和最大熵模型(ME)等,其中HMM 和CRF 是最常用的两种模型。一些学者使用基于隐马尔可夫模型的命名实体识别方法提取缅甸语和孟加拉语文档中的命名实体[9,21]。Li等[22]研究利用多个弱监督源的噪声标签学习命名实体识别标签的问题,提出条件隐马尔可夫模型。Mak 等[23]使用隐马尔可夫模型设计了命名实体识别系统识别《古兰经》中的姓名、地点和事件等实体。Abd等[24]对传统的特征表示方法、条件随机场和最大熵马尔可夫模型进行了比较研究,并识别了生物医学领域的命名实体。Lee等[10]研究基于字典查找的字符串匹配和条件随机场,识别风湿病患者临床记录中的症状、药物、位置等实体。Santoso 等[25]提出了一种使用混合条件随机场(CRF)和K-Means 的印度尼西亚新闻文档的NER 系统。Arora 等提出了一个神经半马尔可夫结构化的支持向量机模型对开源数据集CoNLL-2003 中的人名、地名和组织名等命名实体进行识别[11]。Konkol 等[26]使用最大熵模型研究捷克语的命名实体识别方法。
近年来,基于深度学习的命名实体识别方法占据了主导地位,主要包括卷积神经网络(CNN)[13]、循环神经网络(RNN)[27]和Transformer[20]模型。Jia 等[13]针对汉字书写的固有特点,提出一种基于CNN-Bi-LSTM-CRF的神经网络模型用于简体中文NER 任务。Gui 等[28]提出了基于卷积神经网络的命名实体识别方法,使用反馈机制合并词汇,解决潜在词之间的冲突。一些学者使用Bi-LSTM-CRF模型处理疾病以及网络安全命名实体识别任务[27,29]。Zhu 等[30]利用N 元语法在输入中加入位置标签特征,通过卷积神经网络获取单词嵌入的局部上下文,用于生物医学命名实体识别任务。Kong 等[31]提出了一个基于卷积神经网络和注意力机制方法识别中文临床命名实体。Che等[32]提出了一个时间卷积网络和一个条件随机场层用于生物医学命名实体识别。有的研究者基于BERT 预训练语言模型的Bi-LSTM-CRF 命名实体识别方法[14,33]。Agrawal 等[34]提出使用迁移学习的方法来解决嵌套命名实体识别。Emmert-Streib 等[35]研究了一个基于字典和条件随机场的混合模型用于食品和膳食成分命名实体识别,并与BERT、BioBERT 模型进行了对比,结果表明,混合模型在训练数据方面更有效率。
综上所述,对自然语言命名实体识别的研究很多,算法已经相对成熟,但是无法实现图片文本中的跨模态命名实体识别。针对图片文本的命名实体识别方法通常使用OCR 技术识别图片中的文字,将识别出的字符处理为自然语言的文本形式,采用自然语言的命名实体识别方法识别其中的关键信息。图片文本命名实体识别方法大多是将OCR技术与深度学习技术结合实现图片文本命名实体识别。
1.2 跨模态命名实体识别
Ha等[36]设计了OCRMiner系统识别英文发票文本,使用基于Bert 的命名实体识别方法识别英文发票中的人名、组织和地址等实体。Abadie等[37]将OCR识别工具应用于历史文档,手动标记OCR识别后的历史文本数据中的人名、标题和地名等实体,使用基于CNN 和Transformer的命名实体识别方法进行训练和预测,识别测试集中的命名实体。Dutta等[38]使用OCR识别14 020篇新闻文章,得到识别的文本字符后,利用基于CRF的命名实体识别方法识别其中的人名、地名和机构名。Boros等利用OCR技术处理包含法语和德语的数字化历史报纸图片获取历史文本数据,然后使用Bert和Transformer模型对文本中的机构名、地名等命名实体进行识别[16]。Huynh等[39]分析了OCR识别单词产生错误的原因,使用基于编辑距离的算法细粒度检查每个单词的拼写以便于解决噪声文本,分别构建了Bi-LSTM-CRF和Bi-LSTMCNN 模型,一定程度上提高了命名实体识别的准确率。由于最大编辑距离是根据经验确定,导致识别准确率缺少通用性。
这些图片文本的命名实体识别算法只针对某个具体领域进行研究,对于OCR 识别出的字符大多进行人工处理后采用深度学习模型进行自然语言命名实体的识别,缺乏自动的跨模态命名实体识别算法,且由于排版错位、不同字符序列混编等问题,这些方案的准确率不高。
2 跨模态的图片文本命名实体识别模型
本文针对采购文件包含的图片文本中影响命名实体识别准确率的因素,如排版错位、不同字符序列混编,设计跨模态图片文本命名实体识别模型O2V2BLC,该端到端模型结构包括OCR识别层、文本边界处理层、嵌入层、Bi-LSTM 层、全连接层、CRF 层和输出层,如图1所示。
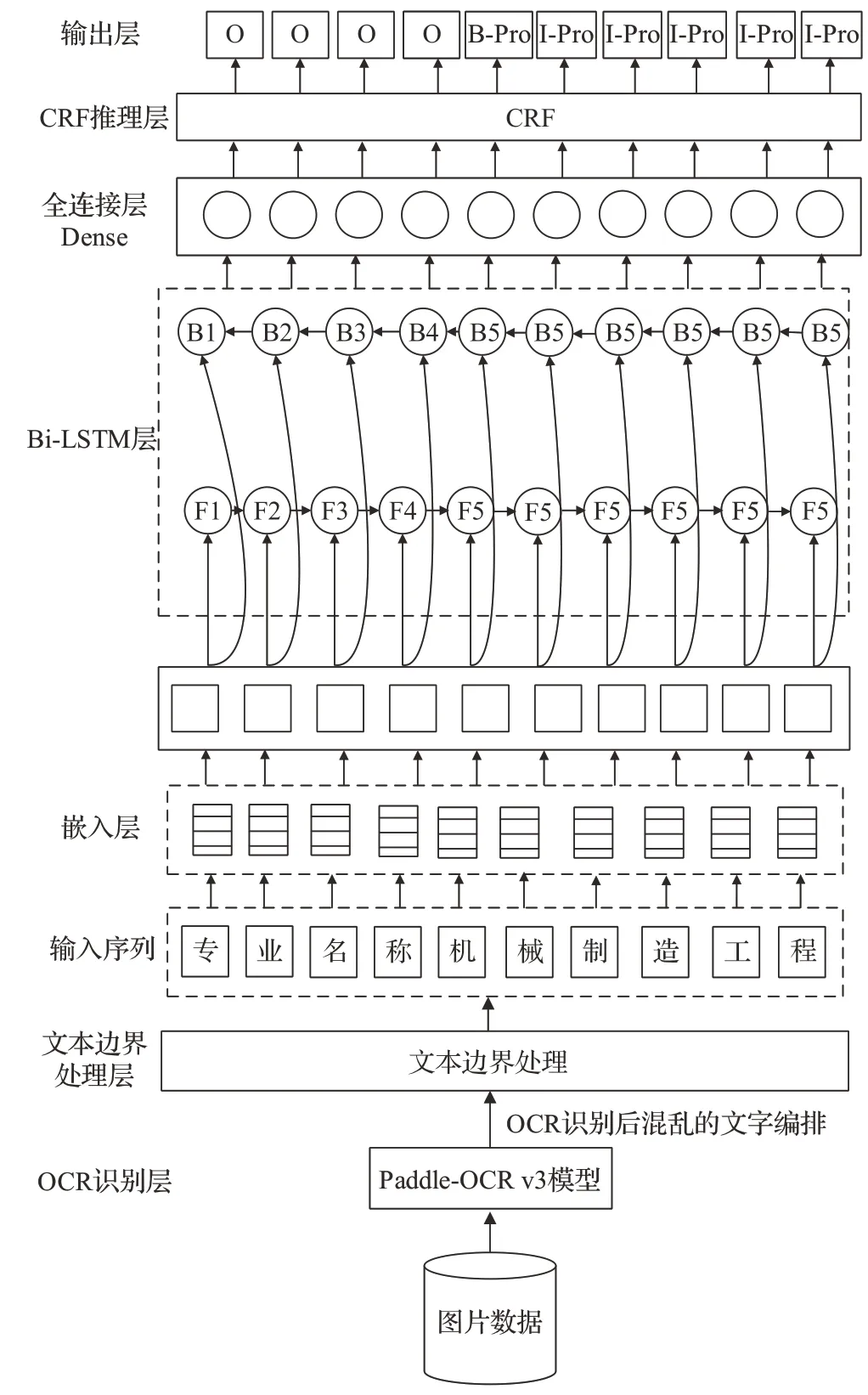
图1 跨模态的命名实体识别网络模型结构Fig.1 Cross-modal named entity recognition network model structure
(1)OCR 识别层将图片文本识别为字符,文本边界处理层用于设置字符的边界,形成不同的字符序列并对其排序。
(2)嵌入层将文本序列中的字符编码为向量。
(3)Bi-LSTM层获取上下文信息的语义特征形成语义向量,计算序列字符的类别状态分数矩阵。
(4)全连接层将高维语义向量映射为符合标签数量的维度。
(5)CRF 层对字符序列的规则进行约束,输出层输出命名实体标签序列预测结果。
模型的各层之间通过向量连接,使用O2V2BLC 模型的损失函数对各模块统一调参,实现自动的跨模态图片文本命名实体识别。
首先,使用Paddle OCR v3模型识别采购文件图片中的文本。Paddle OCR v3 模型对图像中的文字进行扫描检测,将图中可能包含文字的部分进行分割处理,每一行标记为一个检测框,对检测框进行矫正,将竖排检测框转换为横排矩形框用于后续的字符识别。由于矫正后的框体可能会被反转,使用方向分类器检测并改正文本的方向。然后识别检测框中的字符,作为本层的输出。由于图片文本的排版等情况,使用Paddle OCR v3模型识别的字符可能出现实体位置参差不齐、不同字符序列混编等。
其次,针对文本字符序列错乱的问题,本文设置边界处理算法,读取各检测框位置信息,将所有检测框的四个顶点的x轴坐标进行升序排序,取排序后x轴坐标的最小值与最大值的均值作为图片中心线的x轴坐标。如果存在被识别的检测框落在了图片中心线上的情况,即某个检测框的左上角x轴坐标小于图片中心线x轴坐标且右上角x轴坐标大于图片中心线x轴坐标,则判定该图片的检测框分布是自上而下依次排列,否则判定检测框为先左后右分布排列。如果图片的检测框为自上而下依次排列,则按照每个检测框的位置顺序拼接识别的文字内容。如果图片检测框是先左后右排列,则对图片检测框所属图片区域进行判断:若检测框的左上角x轴坐标小于图片中心线x轴坐标,则判定该文本框位于图片左半部分,若识别文本框的右上角x轴坐标大于图片中心线x轴坐标,则判定该文本框位于图片右半部分。最后按照先左后右的顺序拼接识别的字符序列。
最后,采用BIO标记格式对文本字符序列进行数据标注,标注完成后使用词嵌入层对文本序列词向量化。由于单向的LSTM 神经网络模型只能捕捉图片文本序列中的上文信息,无法获取序列的下文信息,字符序列的上下文信息对于命名实体识别都具有重要的作用。因此,本文采用双向长短期记忆网络(Bi-LSTM)模型,对输入字符序列信息进行特征提取,将两个方向的向量结果进行拼接,并且预测每个向量对应的每个标签的概率,形成状态分数矩阵。在CRF层中,将状态分数矩阵和标签转移矩阵进行加权求和计算路径分数以及所有路径总分。标签转移矩阵是类别之间的状态分数矩阵,考虑到相邻标签之间具有相关性,例如,I-PRO(专业名称)不可能出现在B-PRO(专业名称)之前。应用条件随机场对每个字符设置概率限制条件,利用CRF损失函数计算所有路径的总分数,通过回溯得到全局最优路径。在输出层中,输出分数最大的序列作为预测的命名实体标签序列。
3 实验及结果分析
为验证本文方法的有效性,本文将提出的O2V2BLC模型和两种统计概率学习方法、Bert-Bi-LSTM-CRF算法进行比较,使用准确度、精确度、召回率和F1值四种指标来评价命名实体识别方法。本文的实验在Windows 10 Professional(64位,Intel Core i7-10700CPU,@2.90 GHz和16 GB 内存)上运行,使用 Pycharm、Python 3.7 和PyTorch框架。
3.1 数据集
本文采集采购流程中的工程师资格证、安全员证和职业资格证等631张图片构建数据集,如图2所示,按照80%训练集和20%测试集的方式来划分数据集。数据集的标注工作是通过YEDDA 软件完成,初步标注了4种实体,定义了9类标签,各类实体标签如表1所示。
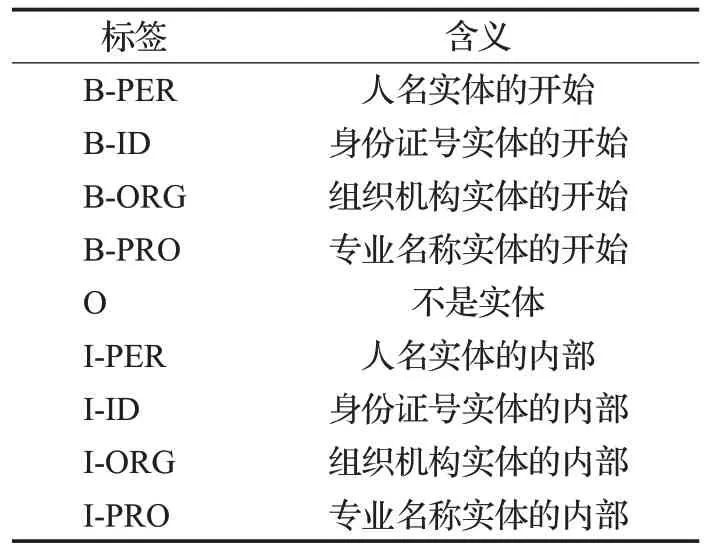
表1 各类实体标签Table 1 Various entity labels

图2 工程师证书Fig.2 Engineer certificate
3.2 实验过程
本文使用Paddle OCR v3模型识别采购文件、工程师证书、国家职业资格证书等图片文本,得到识别出的文本字符序列后,使用设计的文本边界处理方法对文本进行处理,然后采用BIO格式对文本字符进行标注得到文本输入序列,标注样例如图3所示。

图3 标注样例Fig.3 Sample markers
将图片文本输入OCR 识别层,根据模型输出的命名实体结果,利用损失函数计算标签序列的误差。根据梯度下降优化算法更新模型参数。具体的模型参数设置为:Embedding 大小设置为128,LSTM 模型的隐向量的维数为128,批处理大小(batch_size)为64,迭代次数(epoch)为30。设置网络的损失函数为交叉熵损失函数,利用Adam优化方法更新参数,使损失函数最小化,提高模型的泛化能力。模型训练的准确率和损失变化如图4所示。

图4 O2V2BLC模型准确率与损失Fig.4 O2V2BLC model accuracy and loss
为OCR 识别后字符序列经常出现错乱,去掉O2V2BLC 模型的文本边界处理层,与模型进行了对比实验,结果如图5所示。与经过字符序列编排的结果相比,模型的准确率略低。

图5 去掉文本边界处理层的O2V2BLC模型指标对比Fig.5 Comparison of metrics of O2V2BLC model with text boundary processing layer removed
为了对比模型中隐向量维数对命名实体识别模型的影响,将LSTM 隐向量的维数设置为16、32、64 和128,并进行对比实验,LSTM隐向量维数为隐藏层节点的个数,得到模型准确率和损失结果如图6所示,LSTM隐向量维数的影响不大。
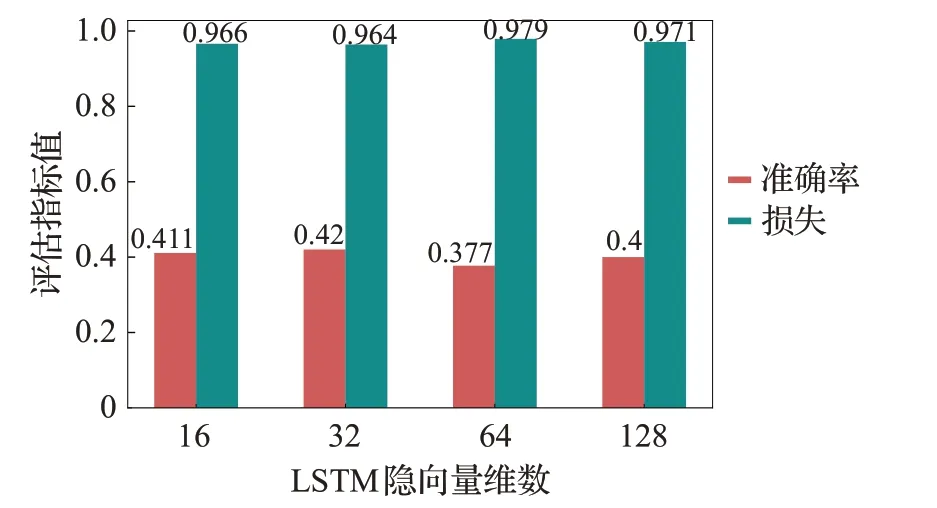
图6 LSTM隐向量维数对O2V2BLC模型准确率的影响Fig.6 Effect of LSTM hidden vector dimensionality on accuracy of O2V2BLC model
将Bert-Bi-LSTM-CRF 与O2V2BLC 模型进行对比实验,Bert-Bi-LSTM-CRF模型设置了12个Attention-head,768 个隐藏层单元,1.1×108个参数,版本为Chinese_L-12_H-768_A-12。实验效果如图7 所示,本文端到端模型准确率有明显提升。

图7 模型准确率对比Fig.7 Model accuracy comparison
3.3 实验结果分析
为验证本文模型的有效性,本文模型与其他三个广泛使用的模型进行了对比。实验评估标准使用准确率、召回率和F1值。
(1)HMM 模型:对数据集进行序列标注,该模型使用Viterbi算法进行预测,输出最终的标记结果。
(2)CRF 模型:对数据集进行序列标注,该模型使用词向量作为CRF 的输入,CRF 层输出全局最优的标记结果。
(3)Bert-Bi-LSTM-CRF模型:使用Bert预训练模型获取输入文本序列的语义表示,得到文本序列中每个单词的向量表示,将单词的向量序列输入到Bi-LSTM 层进行进一步的语义编码,最后通过CRF层输出全局最优标签序列。
(4)O2V2BLC 模型:该模型是一个端到端模型,通过对字符进行向量编码,在向量空间实现文本上下文语义特征提取,设计约束规则计算各字符对应标签的概率,通过计算损失函数实现模型的迭代优化。
本文将提出的模型与以上三个模型进行比较,性能指标结果如表2所示。

表2 四种模型的实验结果比较Table 2 Comparison of experimental results of four models
从实验结果可以看出,本文O2V2BLC 模型的准确率、召回率、F1 值比其他三个模型均有提升,说明文本构建的端到端命名实体识别模型具有较好的识别能力。
4 结束语
本文总结了基于统计概率和神经网络的命名实体识别方法,提出了一种跨模态的采购文件图片文本命名实体识别的端到端模型O2V2BLC,该模型将处理图片文本中的字符映射到向量空间,设计Bi-LSTM 网络捕获字符序列的上下文语义,通过条件随机场对字符概率进行约束,获得全局最优标记序列,并计算命名实体预测误差优化该模型的参数。本文模型自动实现跨模态命名实体识别。本文虽然针对采购文件场景提出该模型,但未使用特定领域的知识,可以广泛应用于各领域文本图片的命名实体识别。在未来的工作中,将考虑如何更好地应用注意力机制表示句子以及引入更多的实体进行实体关系抽取,进一步探索应用更加复杂的神经网络模型处理图片文本命名实体识别问题。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
小学生学习指导(低年级)(2019年12期)2019-12-04
中国外汇(2019年18期)2019-11-25
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
